1. Introduction
The major inconvenience of using stable laws is the absence of expressions for the probability density and distribution function in terms of elementary functions. There are only five cases known where the density is expressed in terms of elementary functions: the L
vy distribution (
), the symmetric L
vy distribution (
), the Cauchy distribution (
), the Gaussian distribution (
), and the asymmetric Cauchy distribution (
) (see Formulas (
5) and (
8)). Here
is a characteristic exponent of the stable law that
is a parameter of asymmetry. The latter distribution was first described in a book by V.M. Zolotarev [
1] (see formula (2.3.5a)) and was later examined in works [
2,
3]. Different representations for stable laws are required to calculate the probability density or distribution function in other cases.
Paper [
4] shows that if values of the characteristic exponent
and the asymmetry parameter
are limited by values of rational numbers (
,
, where
are positive integers), then in this case, it is possible to express the probability density of a strictly stable law in terms of special functions. Papers [
4,
5,
6,
7,
8,
9,
10] are devoted to obtaining such representations. The limitation of this approach lies in the fact that it is possible to obtain an expression for the probability density only for rational values of the parameters
and
and only for strictly stable laws. The application of the fast Fourier transform algorithm is another method of calculating density. This approach has been examined in papers [
11,
12]. However, this method provides an opportunity for the calculation of the probability density on a grid of equidistant points. In this paper, linear interpolation must be used to calculate the density at intermediate points or irregularly spaced points.
The use of integral representations is the main method for calculating the probability density and the distribution function of stable laws. This approach is based on the inversion Formula (
2). There are two possible ways of inverting the characteristic function. The first way is to directly calculate the integral in (
2). As a result, the probability density is expressed in terms of the integral of the oscillating function [
13,
14]. However, since the integrand is an oscillating function, this leads to difficulties in numerical integration in the cases
,
, and
and in the case of large values
x [
13]. Modernization of the standard quadrature method of numerical integration makes it possible to reduce the lower boundary of the parameter
from the value
to the value
[
14]. It has been proposed to use the representation of the density in the form of a power series to calculate the density for large values of
x.
The second way of obtaining integral representations is the application of the stationary phase method when calculating the integral in (
2) (see [
1,
3,
15,
16]). The advantage of this method of inverting the characteristic function is that the resulting integral representation is expressed in terms of a definite integral of a monotonic function. Such integral representations were obtained for stable laws with different parameterizations of the characteristic function. These were obtained for the parameterization “B” in works [
1,
15], for the parameterization of “M” in paper [
16], and for the parameterization of “C” in paper [
3]. Here the notation of various parameterizations of the characteristic function is given in accordance with the designations introduced in the book by V.M. Zolotarev [
1]. These integral representations are more convenient from a practical point of view and allow calculating the density in a wide range of parameter values
, and coordinates
x. The integral representation obtained in the work [
16] served as a foundation for developing several software products [
17,
18,
19,
20,
21].
From a theoretical point of view, these integral representations are valid for all values of
x. However, in practice, it is not possible to calculate the probability density and distribution function for all values of
x. The reason for this lies in the behavior of the integrand. The integrand has the form of a very sharp peak with small and large values of
x. As a result, numerical integration algorithms cannot correctly calculate the integral in this range of
x. To settle this issue, in papers [
16,
18,
19] the use of various numerical methods to increase the accuracy of calculations was proposed. However, all proposed approaches increase the accuracy of the calculation but do not completely eliminate the problem. To calculate the probability density and distribution function in this range of values of
x, it is expedient to use other representations for stable laws which do not have any specific features in the indicated areas. The approach used in papers [
12,
14] seems to be the most suitable, which consists of applying expansions in a power series for probability density and distribution function with
and
.
Such expansions are well known and are obtained, as a rule, for the parametrization “B”. Depending on the value of the parameter
, the obtained power series is either convergent or asymptotic. The expansion of the probability density of a stable law into a convergent series in the case
and
was firstly mentioned in paper [
22]. Later, in paper [
23] a generalization of this density expansion was given for
in the case
. In this range of values of the parameter
, this series turns out to be asymptotic. In the same paper, the expansion of the density in a series in the vicinity of the point
was obtained for the case
. The resulting power series is asymptotic in the case
and convergent in the case
. Expansions for
in the cases of
and
were also obtained in the work [
5] as a result of expansion into a power series of the probability density, expressed in terms of the Fox function. The same expansions were given in the books [
24] (see Chapter 17, §7) and [
1] (see §2.4 and §2.5). Expansions of the density of a stable law in a power series for the characteristic function in parameterization “M” were obtained in paper [
14]. An interesting result was obtained in paper [
25]. In this paper, expansions of the power series were obtained for the probability density of a symmetric stable law at
and
for the cases
and
. A distinctive property of this expansion is that these power series for all
are convergent.
The purpose of this work is to obtain power series expansions of the probability density and distribution function of a strictly stable law with the characteristic function
where
,
,
. This parameterization of the characteristic function, according to the book [
1], is called parameterization “C”. Obtaining such expansions turns out to be necessary in connection to the problem of calculating the probability density and distribution function of stable and fractionally stable laws. In fact, in the article [
3], integral representations were obtained for the probability density and distribution function of a strictly stable law with the characteristic function (
1). Because these integral representations were obtained using the stationary phase method, the integrand has the form of a very sharp peak when the value of the coordinate
x is either large or small. This causes difficulties for numerical integration algorithms and leads to incorrect integration results. Therefore, to calculate the probability density and distribution function in these coordinate regions, it is expedient to use representations in the form of a power series for the corresponding quantities. This work is devoted to obtaining such expansions.
The solution to this problem will turn out to be useful not only when calculating the density of strictly stable laws but also in the task of calculation the density and distribution function of a fractional-stable law [
2,
26,
27] (for more details see
Appendix A). These distributions are expressed in terms of the Mellin convolution of two strictly stable laws. Correct calculation of the probability density will make it possible to use an algorithm for statistical estimation of the parameters of these laws based on the maximum likelihood method. Such an algorithm for estimating parameters will provide an opportunity to correctly describe various experimental data. It is known that the distribution of gene expression is described by laws with a power-law decrease in density [
28,
29,
30]. Since the stable and fractionally stable densities decrease according to the power law
at
, then these classes of distributions were used to describe the distribution of gene expression (
Appendix A). In the works [
31,
32], fractional stable distributions were used to describe the expression of genes obtained using microarray technology. In the work [
33], these distributions were used to describe the results obtained using next generation sequencing technology. To describe these experimental data, it is necessary to have algorithms for the statistical estimation of parameters, the most effective of which is the maximum likelihood method. To construct such an algorithm, it is necessary to be able to correctly calculate the density of a strictly stable law for any values of
x.
2. Preliminary Remarks
The major purpose of this work is to obtain the expansions of the density and distribution function of a strictly stable law in a power series in the vicinity of the point
. This paper deals with strictly stable laws with the characteristic function (
1). Without loss of generality, we will assume that the scale parameter
. Strictly stable laws with the parameter
are commonly called standard strictly stable laws. Designation abbreviations are accepted for standard strictly stable laws. The characteristic function will be designated by
, the probability density distribution will be designated by
, and the distribution function will be designated by
.
To perform the inverse Fourier transform and obtain the probability density distribution, the following lemma is useful, which defines the inversion formula
Lemma 1. The probability density function for any admissible set of parameters and any x can be obtained using the inversion formulas The proof of this lemma can be found in paper [
3]. To obtain the probability density, there is no fundamental difference based on which formula is used on the right side (
2). The result will differ only in the sign of the parameter
. Without loss of generality, in this paper we will use the first Formula (
2). Such a choice results from the fact that in works [
1,
3,
34], this formula was used to invert the characteristic function. This will provide us with an opportunity to compare the results obtained below with the results of the mentioned papers without any additional transformations.
In article [
3], the inverse Fourier transform of the characteristic function (
1) was performed and expressions for the probability density and distribution function of a strictly stable law were obtained. In the case
and
for any admissible
, the following integral representation is true for the probability density
where
and
If
, then for any admissible
the probability density has the form
If
, then
.
The following expressions are valid for the distribution function. If
, then for any admissible
where
and
is determined by expression (
4). If
, then for any
In the point
, for any admissible
and
To obtain the density representation
in the form of power series, the integral obtained in the book [
35] (see §1.5. formula (31)) turns out to be useful.
under the conditions
. If we use Euler’s formula
, then this integral can be represented in the form
under the conditions
or
.
3. Representation of the Probability Density in the Form of a Power Series
We obtain the expansion of the probability density in a series at . The following theorem is valid:
Theorem 1. In the case for any admissible set of parameters except for the values for the probability density , the following representation in the form of a series is validwhere Proof. We will perform the inverse Fourier transform of the characteristic function (
1). To perform this, we make use of the first relation in (
2). We have
Because the considered case is
, we expand
in a series in the vicinity of the point
. As a result, we obtain:
where the
N-th partial sum
and the remainder
of a series have the form
Here
is the remainder in the Lagrange form.
We then consider the
N-th partial sum
. To calculate the integral in (
15), we change the order of summation and integration in some places and we will substitute the integration variable
. As a result, we obtain
Next, we examine the range of valid values of the argument
. The range of admissible values of the parameter
is determined by the inequality
. Hence, if
, then
, and if
, then
. Thus,
Combining (
18) and (
19), we obtain
As we can see, extreme values of this range are reached in the cases
and
.
Taking into consideration (
20), it is clear that on can use Formula (
10) to calculate the integral in (
17). We obtain
From the relation (
10) it follows that for the arbitrary value
it is necessary to exclude the case
from consideration, which is implemented at values
. Now using expression (
21) in (
17), we obtain
Considering that now
, we finally obtain
Now we consider the remainder
. From expression (16), we obtain
It is not possible to calculate this integral, as the exact value of the quantity
is not known. It is only known that
. However, one can obtain an estimate for this integral. We have
To obtain the third inequality, it was taken into consideration that
. Next, the integration variable was substituted
. To calculate the resulting integral, Formula (
10) was used. The obtained expression completely proves the theorem. □
We need to make one small remark. When proving the theorem, it was pointed out that it was necessary to exclude the case
from consideration, which corresponds to the values of parameters
. As part of the proof of the theorem, this was done so that the range of admissible values of the argument
of the integral in (
17) should coincide with the range of admissible values of the argument
included in the integral (
10). However, the exception of the case
from the integral (
10) is related to the fact that in these points the integral (
10) will diverge (for details see [
36]). Therefore, it should be assumed that
and
, and the integral in (
17) will diverge. This in its turn leads to a degenerate probability density at that point. As a result, we arrive at the well-known fact that the probability density with the characteristic function (
1) is degenerate at the points
.
As noted in the introduction, depending on the value of the parameter
, the expansion of the probability density of the stable law in a power series turns out to be either convergent or divergent. Exactly the same situation occurs in the case considered here. The determine under what values of
the expansion (
11) is convergent and for which it is divergent we formulate as a corollary
Corollary 1. In the case , the series (12) is divergent at . In this case, for the density , for any admissible θ, the asymptotic expansionis valid. In the case , the series (12) converges for any x, satisfying the condition . In the case of the density , for any admissible it is possible to represent in the form of an infinite series In the case , the series (12) converges for any x. In this case, for the density for any admissible θ it possible to represent in the form of an infinite series Proof. We examine the convergence of the series (
12). As we can see, this series is a sign-alternating series. Consequently,
We apply the Cauchy criterion in the limiting form to the resulting series.
Here Stirling’s formula was used
From the result obtained we can see that for the values
the series (
12) diverges for any
x; with the value
, the series (
12) converges for any values of
x, satisfying the condition
; and in the case
, the series (
12) converges for any
x.
We consider the case
. In this case, the series (
12) diverges at
. However, from expression (13) it follows that for some fixed
N Thus, with every
N we have
As a result, we have obtained the definition of an asymptotic series. Consequently,
We consider the case
. From expression (
11) it follows that
We will set some arbitrary
x and consider the limit of the right-hand side of this inequality under the condition
. We have
Thus, the right-hand side (
24) represents an element of an infinitesimal sequence. This means that the sequence
at
converges to the density
. Therefore, in the case
for any fixed
x for the density
the representation in the form of an infinite series is valid
Now we consider the case
. From expression (
11) it directly follows that
We fix some arbitrary value of
x and find the redistribution under the condition
. As a result, we obtain
Thus, the right side of the previous expression at
is an element of an infinitesimal sequence. Therefore, the sequence
converges to the density
at
and
. Substituting the value
, in the series (
12), we now obtain (
22). □
The proven corollary shows that in the case
of the interval
, the series (
22) converges to the density
. It is important to show that in this case the series (
22) converges to the density (
5). We formulate this result in the form below.
Remark 1. In the case for any in the region the series (22) converges to the density (5). Proof. To prove this remark we will consider the density (
5) and show that the expansion of this density in a Taylor series in the vicinity of the point
has the form (
22). For the convenience of further presentation, we use the reduction formulas
,
and represent the density (
5) in the form
Now we expand the density
in a Taylor series in the vicinity of the point
. Because this density is an infinitely differentiable function, we have
We will draw attention to the fact that the function
is a complex function. We will introduce the designations
In view of the introduced designations, the density (
5) takes the form
To calculate the
n-th derivative, we use the Bruno formula
where
are the Bell polynomials (see [
37])
Here
,
and the sum is taken over all solutions to the equation
and
Taking into account (
26), we obtain
For coefficients
, we have
This shows that in expression (
28), the sum contains the summands that satisfy the equation
Indeed, in expression (
28) the summation is done over all solutions to Equation (
29). In this case, if the solution
, then the corresponding term in the sum will be equal to zero, as
,
. If
,
. Then, the multiplier
, because
. Consequently, in expression (
28) there are summands that satisfy the solution to Equation (
32). This significantly simplifies the summation. It follows from Equation (
32) that
. Taking into consideration that
and
, we obtain
, where
means the integer part of the number
A. This provides an opportunity to introduce directly the summation index in the sum (
28). In view of the aforementioned work, Formula (
28) takes the form
where the relation
is used and the summation index
is introduced. Substituting this relation in (
27) and using (
30) and (
31), we now obtain
Now we calculate the value of this derivative in the point
. It is easy to see that
where it is taken into account that
.
Next, we use the general formula for
(see, for example, [
38])
Using this formula in (
34), we obtain
Using this expression now in (
25), we obtain
Thus, the expansion of the density (
5) into an infinite Taylor series in the vicinity of the point
agrees exactly with the series (
22). This completely proves the corollary. □
Theorem 1 gives an opportunity to determine the range of values
x within which the absolute error of the density calculation using the series (
12) and for some fixed
N will not exceed the predetermined value
. This turns out to be very convenient when calculating the probability density. Indeed, from the relations (
11) and (13) we obtain
If, for a given value of
N we set the absolute value of the error
, then it becomes possible to introduce the threshold coordinate
This value shows that for coordinates
the absolute value of the density calculation error using the series (
12) will not exceed
, i.e.,
Thus, to calculate the probability density we can use the
N-th partial sum (
12) in the range of coordinates
. In this case, the magnitude of the absolute error at a fixed
N will not exceed the chosen value
.
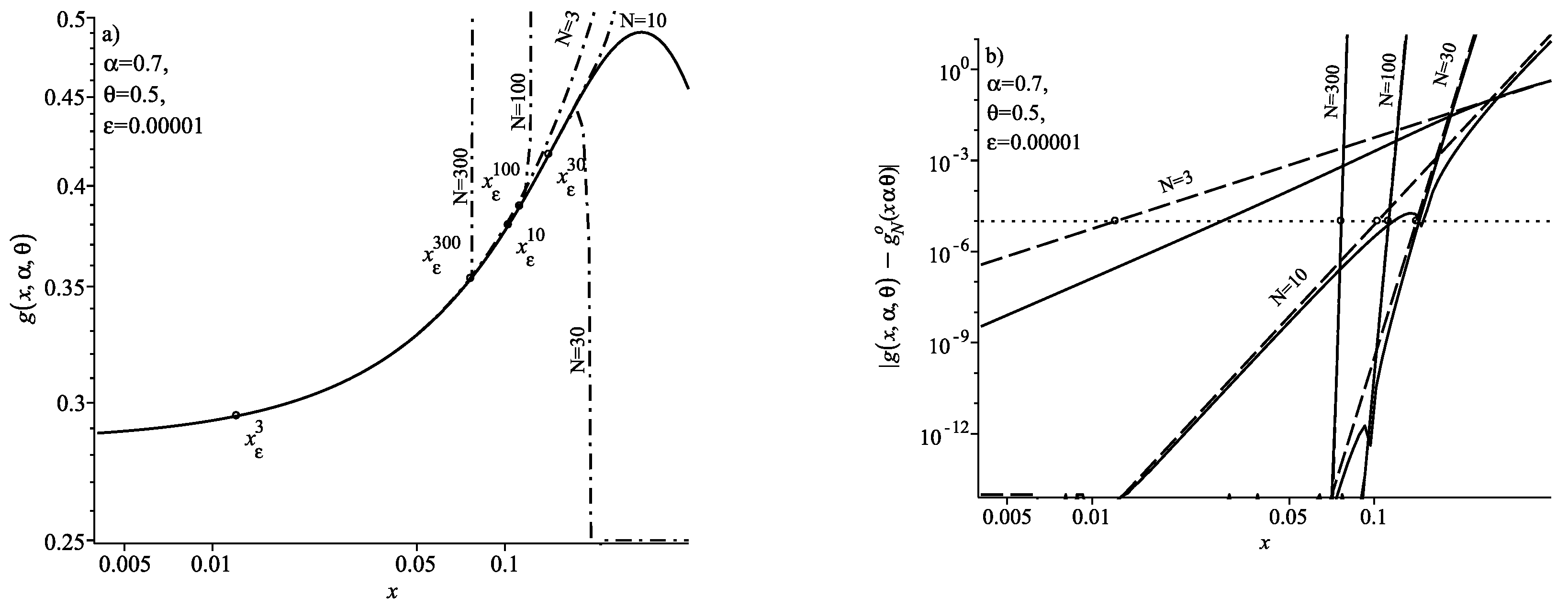
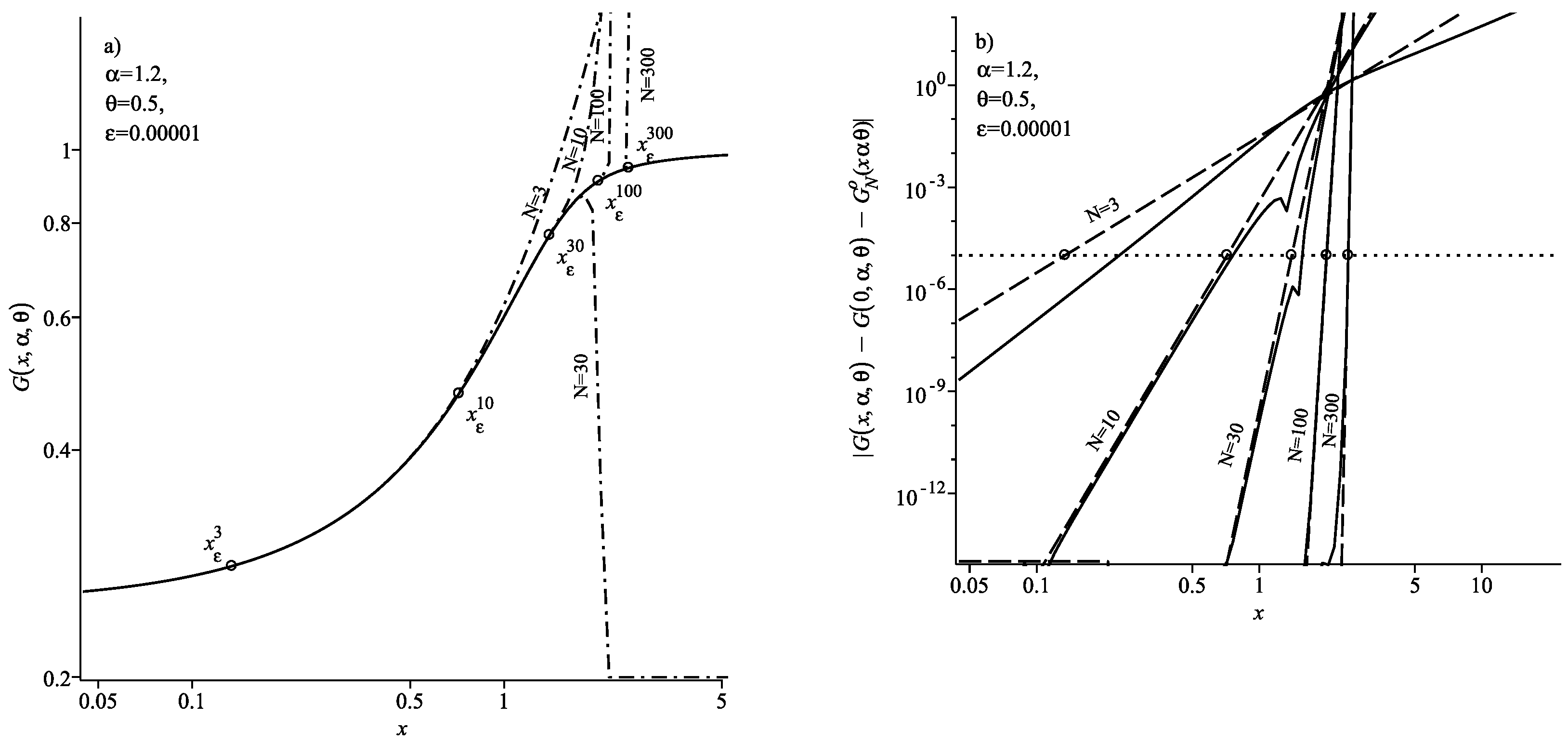
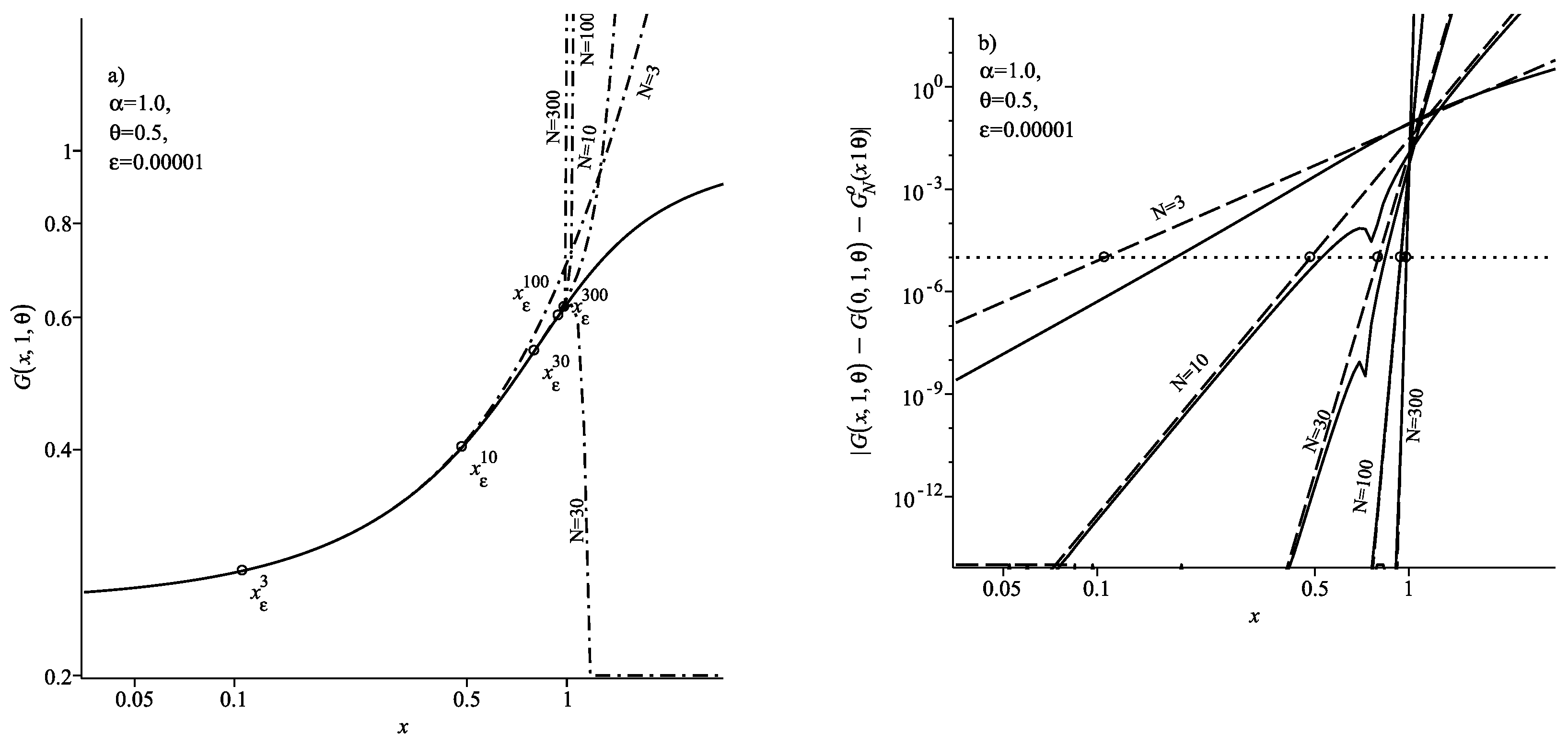
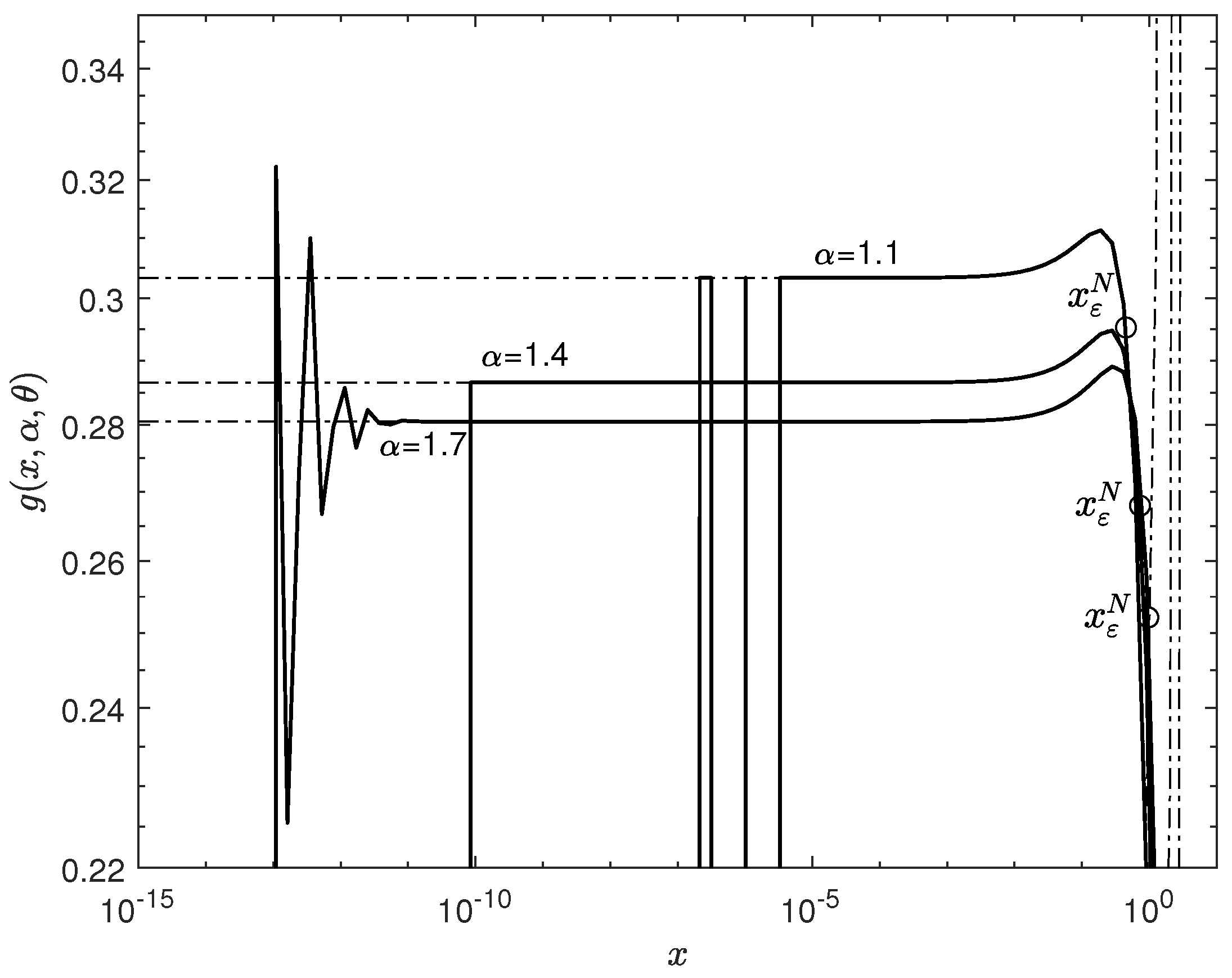
Figure 1a and
Figure 2a show the results of calculating the probability density
using the series (
12). In these figures, the solid curve corresponds to the exact density values
calculated with the help of (
3) and the dash-dotted curves correspond to the density calculation results using the series (
12) for the specified values of
N.
Figure 1b and
Figure 2b show the results of the calculation of the absolute error
. In these figures, the solid curves correspond to the exact value of the absolute error
where
—the exact density value calculated when using (
3),
—for series (
12) and the dashed curve corresponds to the estimate of the remainder term (13). The calculation results are given for the specified values of
N in the figures. In all these figures, the circles show the position of the threshold coordinate
for the selected level of accuracy
and each number of summands
N. It is clear from
Figure 1b and
Figure 2b that in the region
the absolute magnitude of the error does not exceed the specified level of accuracy
for all
N. This means that at
the expansion (
12) can be used to calculate the density.
Corollary 1 shows that in the case
, the series (
12) is divergent at
, and in the case
, this series converges. The cause of this behavior lies in the ratio
, which is present in this series. At
, this ratio turns out to be more than unity and, as
n increases, this ratio only rises. Therefore, to achieve the specified calculation accuracy
one has to decrease the value of
x. This can clearly been seen from the behavior of the threshold coordinates
.
Figure 1a,b show that the addition of summands in the expansion (
12) first leads to an increase in the range of
x for which the inequality
is satisfied. The fact that
evidences this. However, further addition of summands leads to an increase in the ratio
and, thus, an increase in the absolute calculation error. Therefore, to achieve the specified level of accuracy, it is necessary to decrease the value of the coordinate
x. This causes the threshold coordinate
to start decreasing and we see that
.
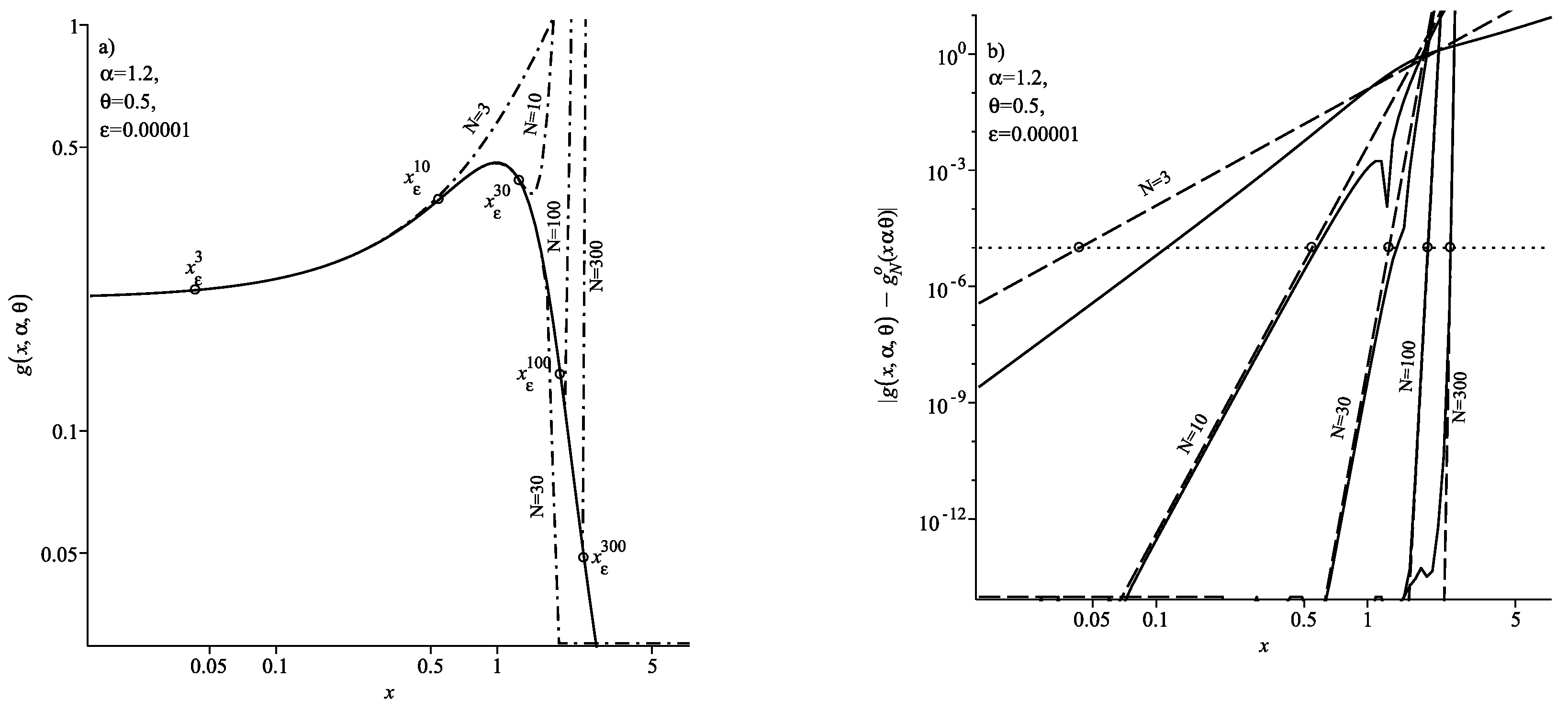
In the case
, the situation changes. In this case, the ratio
, and as
n increases, this ratio only decreases. Consequently, the increase in the number of summands in (
12) increases the accuracy of the density calculation. This leads to the fact that the range of values of
x, for which the condition
is met increases with the addition of the number of summands
N in the sum (
12). This is clearly seen from the location of the threshold coordinates
, shown in
Figure 2a,b. We can see from the figures that
. Thus, in the case
, the series (
12) is convergent for all
x at
.
The results of calculations for the case
are given in
Figure 3. This figure shows
. Thus, an increase in the number of summands
N in the sum (
12) leads to an increase in the interval
x, within which the relation
is satisfied. Here Formula (
5) was used to calculate the density. It can also be observed from the figure that for all presented
N at
, the partial sums of the series diverge. This is in full agreement with the statement of Corollary 1, which states that in the case
, the series (
12) converges at
.
4. Representation of the Distribution Function in the Form of a Power Series
Now we will try to obtain the representation of the distribution function in the case in the form of a power series. We will formulate the result obtained as a theorem.
Theorem 2. In the case for any admissible set of parameters , except for the values for the distribution function , a representation in the form of a power series is valid.where Proof. From the definition of the distribution function, it follows
Here
is the value of the distribution function in the point
and is determined by Formula (
9). Using the expansion (
14) for the density
we obtain
where
Here
and
are determined by expressions (
12) and (16), respectively.
To calculate the partial sum
we will make use of the results of theorem 1. It was obtained in this theorem that the partial sum
has the form (
12). Substituting expression (
12) in (
41) and changing the order of integration and summation, we obtain
Now we obtain the expression for the remainder
. Substituting expression (16) in (42) and changing the order of integration, we obtain
where
. This integral cannot be calculated directly, as the exact value of
is not known. It is only known that
. However, one can obtain an estimate of this integral.
To obtain an estimate for the integral, we use the inequality
. As a result, we obtain
Here, to calculate the outer integral, the integration variable
was first substituted, and then Formula (
10) was used. It should be noted that the case
,
must be excluded from consideration. Indeed, for such parameter values, the argument
and integral (
10) will diverge. Substituting expressions (
43) and (
44) in (
43) we now get the statement of the theorem. □
The proven theorem shows that in the vicinity of the point
, the expansion (
37) is valid for the distribution function of a strictly stable law with the characteristic function (
1). However, as in the case of the probability density, the obtained power series diverges for all
x at
and in the case
is convergent for all
x. In the case
, this series converges at
and diverges at
. In this regard, for the values
the representation (
37) is asymptotic, and for the values
, the expansion
can be represented in the form of an infinite power series. We formulate this result as a corollary.
Corollary 2. In the case , the series (38) diverges for all x at . In this case, the asymptotic expansion is valid for the distribution function for any admissible θ In the case , the series (37) converges at . In this case, the distribution function for any can be represented as an infinite series In the case , the series (38) at converges for any x. In this case, the representation in the form of an infinite power series is true for the distribution function for any admissible θ Proof. We examine the convergence of the series (
38). It is clear that this series is a sign-alternating series. Consequently,
We apply the Cauchy criterion in the limiting form to the obtained series. Using Stirling’s formula (
23) and taking into consideration that
at
, we obtain
This shows that in the case
, the series (
38) diverges for all
x; in the case
, the series converges for all
x, and in the case
the series (
38) converges if
.
Now we consider the case
. In this case, the series (
38) diverges at
. However, it follows from expression (39) that for some fixed
N Consequently, for each
N we have
Thus, we have obtained the definition of an asymptotic series. Consequently,
Now we consider the case
. In this case, the series (
38) is convergent. It follows from expressions (
37) and (39) that
We will find the limit at
of the right-hand side of this inequality. Using Stirling’s Formula (
23) and taking into account that
at
, we obtain
Thus, in the two cases
and
, the right side of the inequality (
46) is an element of an infinitesimal sequence. In turn, this means that in the above two cases, for any fixed
x, the sequences
converge to the distribution function
. Therefore, in the considered case
for any fixed
x the distribution function can be represented as an infinite series.
Now we consider the case
. As shown above, in this case, when the condition
is met, the right side (
46) is an element of an infinitesimal series. Therefore, for any fixed
the representation in the form of an infinite series is true for the distribution function
Thus, the corollary has been proven completely. □
As in the case of the probability density, the proven property shows that in the case
and
, the series (
45) converges to the distribution function
. It is possible to show that this series converges to the distribution function (
8). We will formulate this result as a remark.
Remark 2. In the case for any in the region , the series (45) converges to the distribution function (8). Proof. To prove this remark, we proceed in the same way as in the proof of remark 1. Let us show that the expansion of the distribution function (
8) into a Taylor series in the vicinity of the point
has the form (
45). We will use the reduction formulas
and
, and we will write the distribution function (
8) in the form
Note that the function
is infinitely differentiable, therefore, expanding it into an infinite series, we obtain
For the derivative of the order
n we have
Thus, the problem has been reduced to calculating the derivative
of the probability density
. However, this problem has been solved by us when proving Remark 1. Using Formula (
33), we get
Substituting this expression in (
48) and calculating the value of the obtained derivative in the point
and then using (
35), we obtain
where it was taken into account that
.
Substituting now the obtained expression for the
n-th derivative in (
47) and taking into consideration (
9), we get
Here, in the last equality, the summation index
was changed. Thus, the expansion of the distribution function (
8) into a Taylor series in the vicinity of the point
exactly coincides with the series (
45). This completely proves the remark. □
Theorem 2 provides an opportunity to find the range of values of the coordinate
x within which the absolute error of calculating
using the expansion (
37) will not exceed the prespecified value. Indeed, from (
37) and (39) we have
If we now set the absolute magnitude of the error for a specified fixed
N as
then it is possible to introduce the threshold coordinate
This value shows that for all
x satisfying the condition
, the absolute magnitude of the error in calculating the distribution function using the expansion (
37) will not exceed the value
:
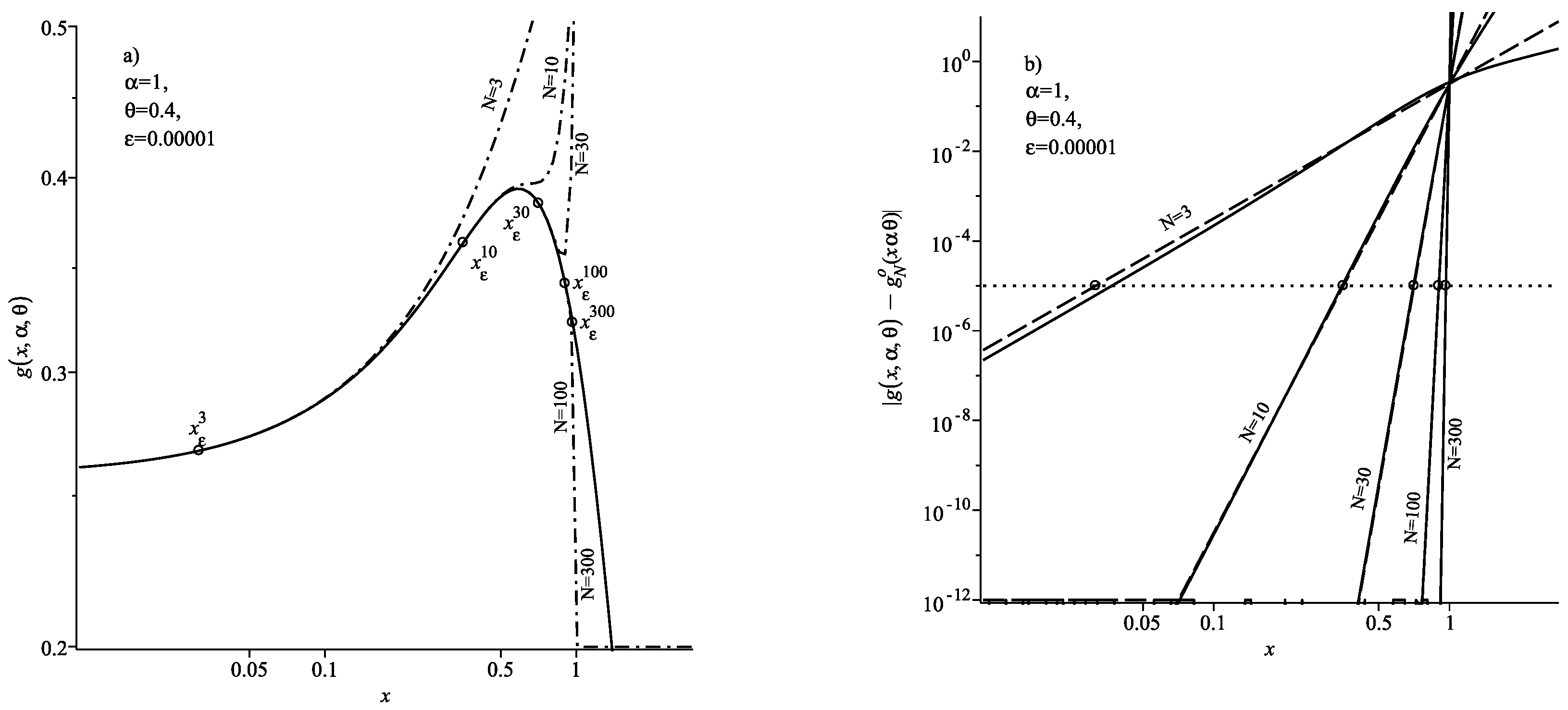
Figure 4a and
Figure 5a show the calculation results of the distribution function using the integral representation (
6) (solid curves) and using the expansion (
37) (dash-dotted curves) for parameter values
,
and
,
, respectively. These figures contain the results of calculating the distribution function using the expansion (
37) for the values
.
Figure 4b and
Figure 5b show the results of calculating the absolute error. In these figures, the dashed curve corresponds to the estimate of the remainder (39), and the solid curves correspond the exact value of the absolute error
for the values
. Here
is the exact value of the distribution function calculated using the representation (
6),
is determined by (
38).
From
Figure 4b and
Figure 5b it is clear that the condition (
50) is met for all given values of
N. In these figures, the location of the threshold coordinate
is marked with circles and the dotted line corresponds to the specified level of accuracy
. We can see from the presented figures that for all values of
x satisfying the condition
, both the estimate of the remainder (39) (dashed lines), and the exact value of the absolute error (solid curves) are below the specified level of accuracy
. This confirms the validity of the condition (
50) and shows that Formula (
49) can be used to estimate the boundary value of the coordinate in the expansion (
37) at which the specified level of accuracy is achieved.
It should be noted that in the case
and
, the threshold coordinate
behaves differently as the number of summands
N in the expansion (
37) increases. In the case
(
Figure 4), an increase in
N first increases the threshold coordinate
(
), but with further increase in
N, the threshold coordinate
decreases
. The threshold coordinate
behaves quite differently in the case
. In this case, with an increase in
N the value of the threshold coordinate increases:
(see
Figure 5). Such behavior of the threshold coordinate
is due to the fact that in the case (
) the series (
38) is divergent, and in the case
this series converges (see Corollary 2).
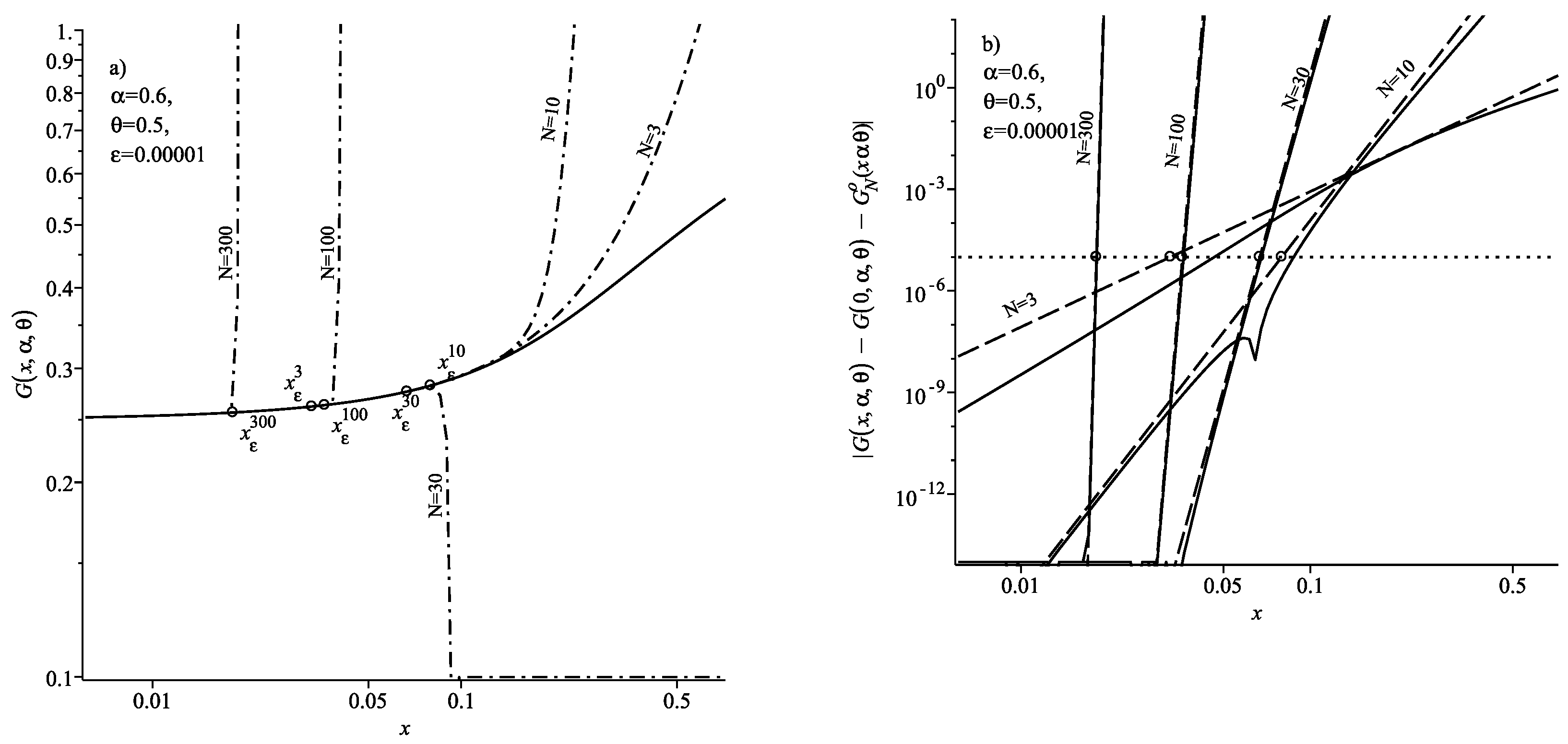
In the case
, the threshold coordinate behaves in the same way as the case
. With an increase in the number of summands of
N in the expansion (
37) the value of the threshold coordinate
increases. We can see this from
Figure 6, which contains
. However, unlike the previous case,
. Indeed, in the case
Formula (
49) takes the form
. Thus,
Such behavior of the threshold coordinate
is a consequence of the proven Corollary 2. Indeed, in the case
the series (
38) and, therefore, the representation (
37) converges in the region
.
The results of calculating the absolute error in the case
are given in
Figure 6b. In this figure, the value of the threshold coordinate
for different values
N is shown with a circle. We can see from the presented results that for the values
both the estimate of the remainder (39) (dashed lines), and the exact value of the absolute error (solid curves) turn out to be less than the specified accuracy level
(dotted line). This demonstrates that the use of Formula (
49) to estimate the values of the boundary coordinate leads to the validity of the condition (
50).
5. Calculation of the Probability Density and Distribution Function for Small
We return to the problem of calculating the probability density of a strictly stable law. As mentioned in the introduction, the main approach to the calculation of the probability density is to use the integral representation. For a strictly stable law with the characteristic function (
1), such an integral representation is determined by Formula (
3). This formula is valid for any
and any admissible values of parameters
and
except for
. However, in practice it is not possible to calculate the integral in (
3) numerically for all values of
x. The reason for this lies in the behavior of the integrand.
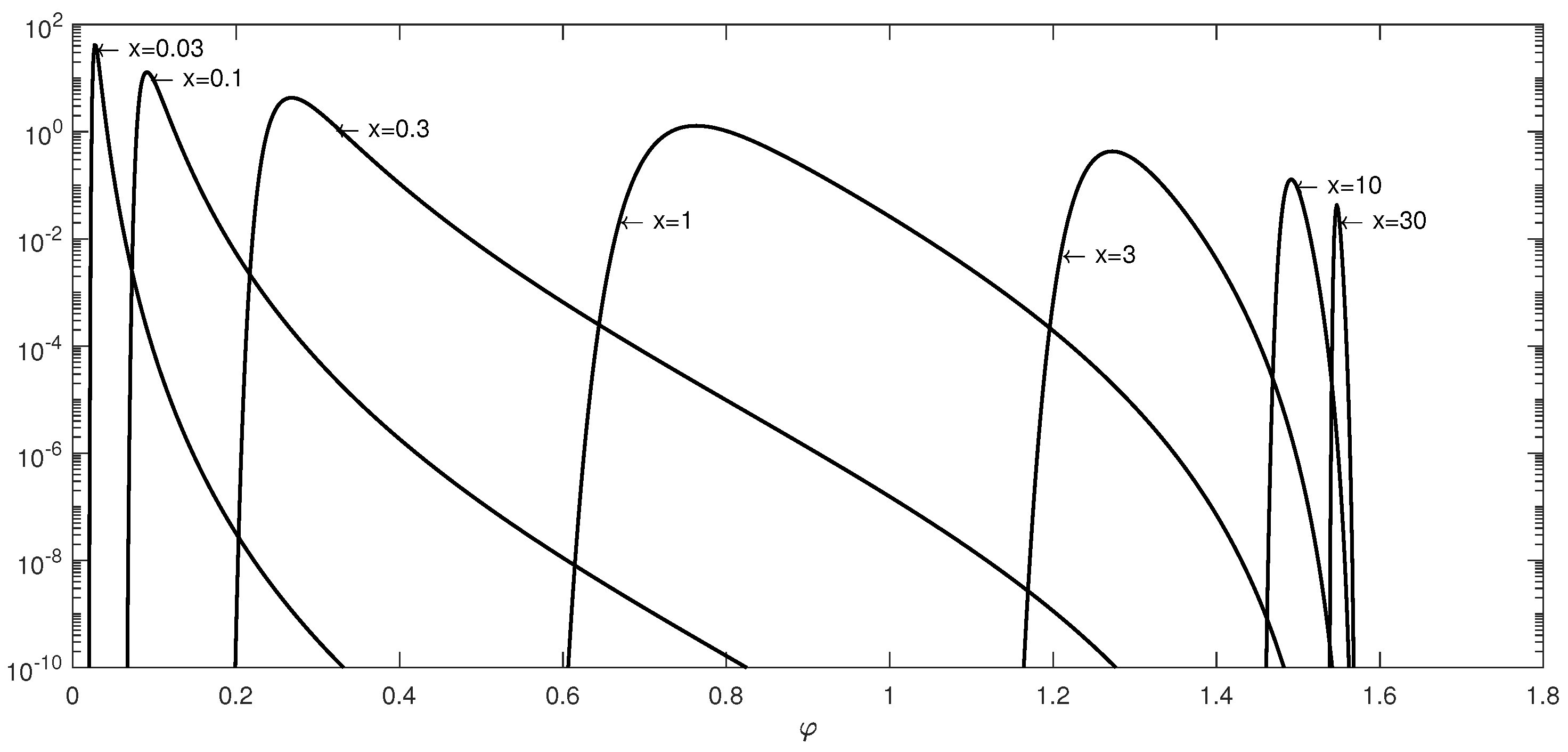
Figure 7 shows the graph of the integrand in Formula (
3) depending on the integration variable
for different values of
x. The graph of the function is plotted on a semi-logarithmic scale. We can see from this figure that as the value of
x decreases, the integrand turns into a function with a very narrow and sharp peak. With a further decrease in
x, this peak becomes even narrower and higher. The same behavior of the integrand is also observed for large values of
x. This leads to the fact that for very small and for very large values of
x numerical integration algorithms cannot calculate the integral of this function.
Figure 8 and
Figure 9 show the results of calculating the probability density using the integral representation (
3) (solid curves).
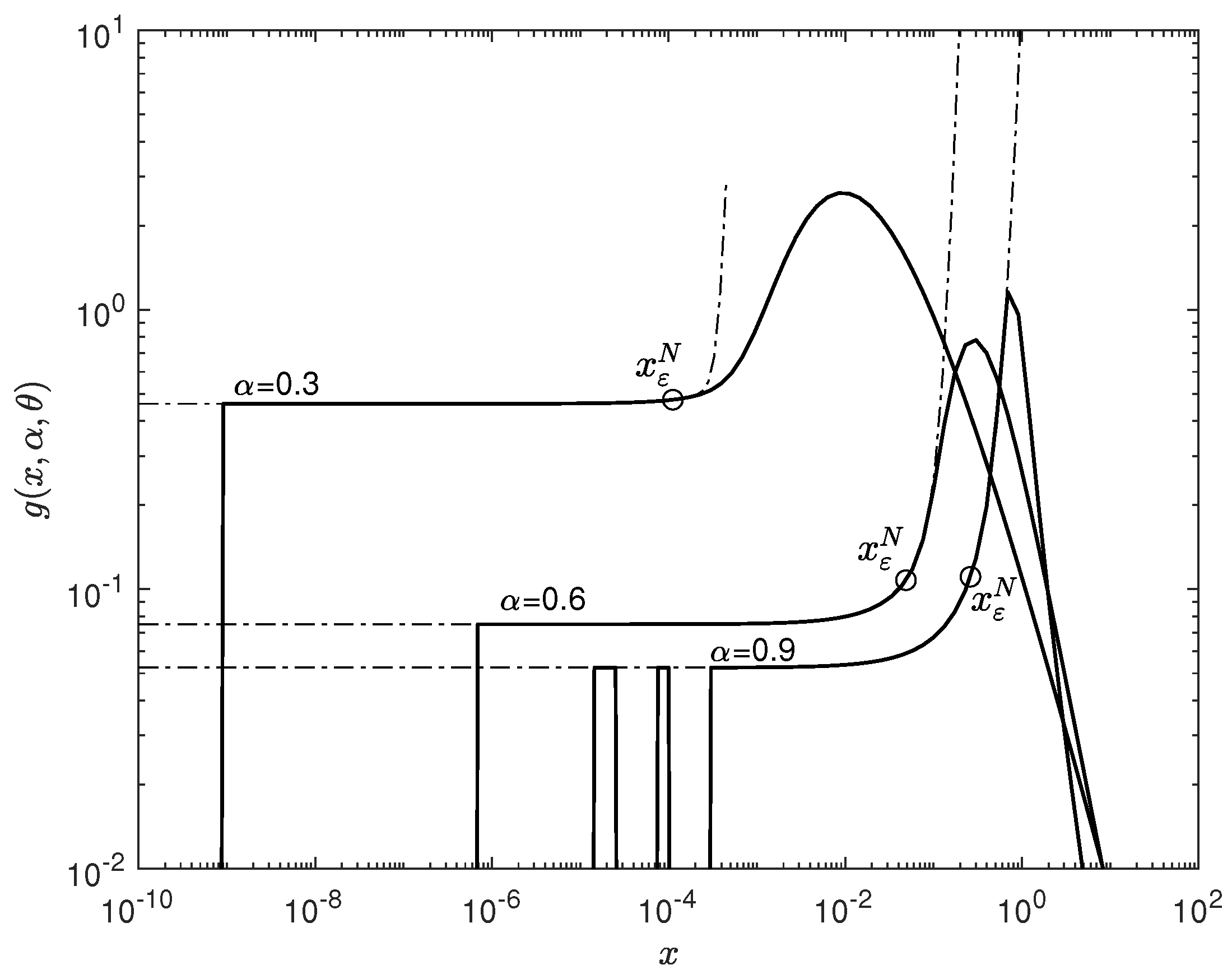
Figure 8 shows the case
,
Figure 9 shows the case
. The Gauss–Kronrod algorithm was used to calculate the integral in Formula (
3). It is clear from the presented calculations that for small values of
x the numerical integration method used cannot calculate the integral in (
3). The critical value of the coordinate
at which the numerical integration algorithm used begins to produce an incorrect result for
is
; for
, it is
; and for
, it is
(see
Figure 8). In the case
(see
Figure 9), for the value
, the critical value is
, for the value
, it is
; and for the value
, it is
. Consequently, at
it is necessary to use other methods to calculate the probability density. The same problem exists for integral representations of the density of stable laws in other parameterizations of the characteristic function (see [
14,
16,
18,
19]). To solve this problem in these works, the authors used various numerical methods that make it possible to increase the accuracy of the calculation. However, these methods increase the accuracy of the calculations but do not solve the problem completely.
To calculate the density for the values
, one should use other representations that do not have any singularities in this area. The most suitable option for this purpose is the power series representation obtained in Theorem 1 for the probability density. The estimate of the remainder (13) obtained in the same theorem make it possible to obtain the formula for the threshold coordinate
(
36) at which the given value of the absolute error
is achieved for a fixed
N. This means that in the region
, the absolute error of the density calculation using the series (
11) will not exceed the specified value
. In
Figure 8 and
Figure 9 the dash-dotted curves show the results of calculating the probability density using the series (
12) for the specified values of
. The position of the threshold coordinate
is shown with circles. The values
are calculated for the absolute error
and
. These figures show that, in the region
, the results of calculating the probability density using the integral representation (
3) and using the series (
12) coincide. For the values
, the numerical integration algorithm no longer allows for the obtainment of the correct density value. At the same time, the calculation of the probability density using the series (
12) does not cause any difficulties. It follows that for the values
, it is expedient to use the series (
12) to calculate the probability density. Thus, using theorem 1 and, in particular, the series(
12), completely solves the problem of calculating the probability density at
.
Similar problems arise when calculating the distribution function using the integral representation (
6). The integrand in this integral representation also has some singularities at
. In the general case, the integrand in (
6) (see also (
7)) behaves in the following way. In the point of the lower limit
, the integrand is equal to 1, and in the point of the upper limit
the value of the integrand is equal to 0. As the variable
increases from the value
to the value
, the integrand decreases monotonically from 1 to 0. However, for very small values of
x, the integrand in (
7) decreases very sharply from 1 to 0 in a very narrow range
. As a result, some numerical integration algorithms cannot recognize such a sharp decrease in the function and will return an incorrect integration result. To exclude the possibility of incorrect results completely for small values
x, it is expedient to use the expansion of the distribution function into a series obtained in Theorem 2. The estimate of the remainder obtained in this theorem make it possible to obtain Formula (
49) for the threshold coordinate. The value
enables us to determine the range of
x at which the inequality (
50) is satisfied. In other words, in the range of values
, the absolute error of calculating the distribution function using the expansion (
37) will not exceed the value
where
is given in advance. Therefore, when calculating the distribution function in the range of values
, it is expedient to use the expansion (
37), while for the range of values
, it is advantageous to use the integral representation (
6).
6. Conclusions
The major approach to the calculation of the probability density and the distribution function of stable laws is the use of integral representations. Theoretically, these representations are valid for all values of the coordinate x. However, it is not possible to calculate the density numerically for all x. Problems arise in the domain of very small and very large values of x. Therefore, it is expedient to use other methods for numerical calculations.
This paper considers the problem of calculating the probability density and distribution function in the case of
for a strictly stable law with a characteristic function (
1). To solve this problem, expansions of the probability density and distribution function in a power series and estimates of the residual terms for each of the expansions were obtained. Estimates of the threshold coordinates
were obtained for the expansion of the probability density and the distribution function, which are defined by expressions (
36) and (
49), respectively. The threshold coordinate allows one to determine the domain of coordinates
within which the absolute computational error will not exceed the specified accuracy level
. The performed calculations showed that the value of the critical coordinate
at which the numerical integration algorithm used starts giving an incorrect result is significantly less than the threshold coordinate
(see
Figure 8 and
Figure 9). This fact shows that in the domain
, it is possible to use Theorems 1 and 2 to calculate the probability density and distribution function.
The analysis of the obtained series made it possible to confirm both the known properties of these series and to establish new properties, as well as to improve the known estimates of the remainder terms. It was shown that in the case
, the power series were divergent for any
x at
. In this case, these series are asymptotic at
. In the case
, the obtained series are convergent for all admissible
x. In this case, representations in the form of infinite series are valid for the probability density and distribution function (see Corollaries 1 and 2). These results are known and were previously obtained for the characteristic function in parameterization <<B>> in works [
23,
24] (see Chapter 17, §7), [
1] (see §2.4 and §2.5), and [
34] (see §4.2, §4.3). It can be shown that the expansions from Corollaries 1 and 2 in the cases
and
completely correspond to the expansions in the mentioned works. Examining the case
helped us in establishing that the expansions of the probability density and distribution function converged to the probability density (
5) and the distribution function (
8) in the domain
for any
(see Remarks 1 and 2).
This paper improves the estimates of the remainder terms in the expansions of the probability density and the distribution function defined by the formulas (13) and (39). The estimate of the remainder term obtained earlier (see [
1], formula (2.5.2)) refers to the expansion of the probability density in parameterization <<B>> and in the case of
, it has the form
We will take the relation
into account, where
, which relates the asymmetry parameter
in parameterization <<B>> to the asymmetry parameter
in parameterization <<C>>. In the case
, this relation gives
. Now comparing (
51) and (13) we can see that
The sign of equality is achieved here only in the case
.
Finishing this paper, the following should be noted. In the previous article [
3], it was noted that when calculating the integral in the representation (
3), numerical integration algorithms have difficulties in the domain of small values of the coordinate
x, in the domain of large values of the coordinate
x and in the domain of values of the characteristic parameter
. The first problem of these three has been solved in this paper. The assumption made in the work [
3] that the cause of the problem is associated with the behavior of the integrand in (
3), was correct. Indeed, this integrand starts acting as a singular function at smaller values of
x, which makes it impossible to use numerical algorithms for calculation of its integral. Therefore, to calculate the density in the indicated domain
x, it is necessary to use the series expansions of the density. The reason for the calculation difficulties in the second case is also the behavior of the integrand in the representation (
3). As shown in
Section 5, with large
x it behaves as a singular function. Therefore, to calculate the density in this domain of the coordinate, it is also expedient to use expansions of the density in a series. To solve the third problem, one can use the method proposed in paper [
39]. In this paper, to calculate the density, the authors propose the use of a series expansion of a strictly stable law in view of the parameter
. However, the solutions to each of the remaining two problems require further research that is beyond the scope of this paper.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









