
The Sufficient Conditions for Orthogonal Matching Pursuit to Exactly Reconstruct Sparse Polynomials
Abstract
:1. Introduction
1.1. Compressed Sensing and the Reconstruction of Sparse Polynomial
1.2. The Recovery Guarantee for OMP to Recover Sparse Signals
1.3. The Recovery Guarantee for OMP to Reconstruct Sparse Polynomials
1.4. Contributions
2. Preparation of Manuscript
2.1. Uniformly Bounded Orthonormal System
2.2. Orthogonal Matching Pursuit Algorithm
| Algorithm 1. Orthogonal matching pursuit algorithm. |
| Input: Measurement matrix , observation vector , sparsity s, tolerance Output: Recovered vector Initialization: while or do match: identify: update: end while |
2.3. Mutual Coherence and Cumulative Coherence Function
2.4. Bernstein Inequality
3. The Recovery Guarantee and Reconstruction Error for OMP to Reconstruct Sparse Polynomials
3.1. The Estimation for the Upper Bound of the Mutual Coherence
3.2. The Recovery Guarantee for OMP under the Noiseless Condition
3.3. The Recovery Guarantee and the Reconstruction Error for OMP under the Noisy Condition
4. Numerical Experiments
4.1. Commonly Used Uniformly Bounded Orthonormal Systems
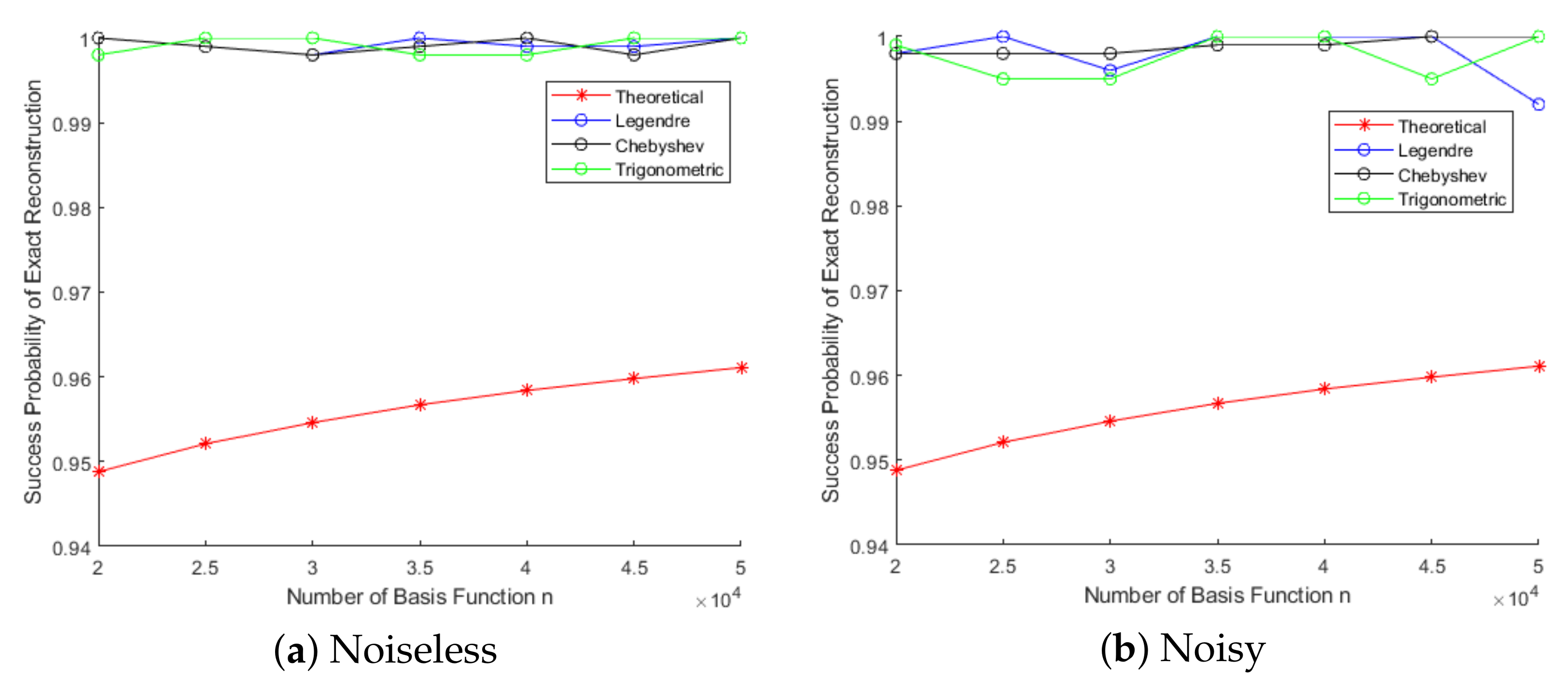
4.2. The Verification of Recovery Guarantee and Success Probability of OMP Algorithm
4.3. Verification of the Accuracy of the Reconstruction Error Estimation When Sampled Data Contain Noise
4.4. Verification of the Accuracy of OMP to Recover Coefficient Vectors When Sampled Data Contain Noise
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Foucart, S.; Lai, M.-J. Sparsest solutions of underdetermined linear systems via ℓq-minimization for 0 < q ≤ 1. Appl. Comput. Harmon. Anal. 2009, 26, 395–407. [Google Scholar]
- Rauhut, H.; Ward, R. Sparse Legendre expansions via l(1)-minimization. J. Approx. Theory. 2012, 164, 517–533. [Google Scholar] [CrossRef] [Green Version]
- Rauhut, H.; Ward, R. Interpolation via weighted ℓ1 minimization. Appl. Comput. Harmon. Anal. 2016, 40, 321–351. [Google Scholar] [CrossRef]
- Xu, Z. Deterministic sampling of sparse trigonometric polynomials. J. Complex. 2011, 27, 133–140. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.; Zhou, T. On Sparse Interpolation and the Design of Deterministic interpolation points. SIAM J. Sci. Comput. 2014, 36, 1752–1769. [Google Scholar] [CrossRef] [Green Version]
- Ho, L.; Schaeffer, H.; Tran, G.; Ward, R. Recovery guarantees for polynomial coefficients from weakly dependent data with outliers. J. Approx. Theory 2020, 259, 105472. [Google Scholar] [CrossRef]
- Candes, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z. Compressed sensing: A survey. Sci. Sin. Math. 2012, 42, 865–877. (In Chinese) [Google Scholar] [CrossRef]
- Tropp, J.A. Greed is good: Algorithmic results for sparse approximation. IEEE Trans. Inf. Theory 2004, 50, 2231–2242. [Google Scholar] [CrossRef] [Green Version]
- Feng, R.; Huang, A.; Lai, M.J.; Shen, Z. Reconstruction of Sparse Polynomials via Quasi-Orthogonal Matching Pursuit Method. J. Comput. Math. 2021. [Google Scholar] [CrossRef]
- Huang, A.; Feng, R.; Zheng, S. Recovery Guarantee for Orthogonal Matching Pursuit Method to Reconstruct Sparse Polynomials. Numer. Math. Theor. Meth. Appl. 2022, 15, 793–818. [Google Scholar] [CrossRef]
- Lin, J.; Li, S. Nonuniform support recovery from noisy random measurements by orthogonal matching pursuit. J. Approx. Theory 2013, 165, 20–40. [Google Scholar] [CrossRef] [Green Version]
- Fornasier, M. Theoretical Foundations and Numerical Methods for Sparse Recovery; DE GRUYTER: Berlin, Germany, 2010. [Google Scholar]
- Mo, Q.; Shen, Y. A remark on the restricted isometry property in orthogonal matching pursuit. IEEE Trans. Inf. Theory 2012, 58, 3654–3656. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Shim, B. On the recovery limit of sparse signals using orthogonal matching pursuit. IEEE Trans. Signal Process 2012, 60, 4973–4976. [Google Scholar] [CrossRef]
- Mo, Q. A sharp restricted isometry constant bound of orthogonal matching pursuit. arXiv 2015, arXiv:1501.01708. [Google Scholar]
- Wen, J.; Zhou, Z.; Wang, J.; Tang, X.; Mo, Q. A sharp condition for exact support recovery with orthogonal matching pursuit. IEEE Trans. Signal Process 2017, 65, 1370–1382. [Google Scholar] [CrossRef] [Green Version]
- Tropp, J.A.; Gilbert, A.C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef] [Green Version]
- Cai, T.T.; Wang, L. Orthogonal matching pursuit for sparse signal recovery with noise. IEEE Trans. Inf. Theory 2011, 57, 4680–4688. [Google Scholar] [CrossRef]
- Cai, T.T.; Wang, L.; Xu, G. Stable recovery of sparse signals and an oracle inequality. IEEE Trans. Inf. Theory 2010, 56, 3516–3522. [Google Scholar] [CrossRef]
- Kunis, S.; Rauhut, H. Random sampling of sparse trigonometric polynomials ii: Orthogonal matching pursuit versus basis pursuit. Found. Comput. Math. 2008, 6, 737–763. [Google Scholar] [CrossRef] [Green Version]
- Random sampling of sparse trigonometric polynomials. Appl. Comput. Harmon. Anal. 2007, 22, 16–42. [CrossRef] [Green Version]
- Xu, Z.; Zhou, T. A gradient-enhanced ℓ1 approach for the recovery of sparse trigonometric polynomials. Commun. Comput. Phys. 2018, 24, 286–308. [Google Scholar] [CrossRef]
- Davis, G.; Mallat, S.; Avellaneda, M. Adaptive greedy approximations. Constr. Approx. 1997, 13, 57–98. [Google Scholar] [CrossRef]
- Foucart, S.; Rauhut, H. A Mathematical Introduction to Compressive Sensing; Springer: New York, NY, USA, 2013. [Google Scholar]
- Dunkl, C.F.; Xu, Y. Orthogonal Polynomials of Several Variables; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Rivlin, T.J. The Chebyshev Polynomials; Dover: Mignola, NY, USA, 1974. [Google Scholar]
- Zygmund, A. Trigonometric Series; Cambridge University Press: Cambridge, UK, 1959. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | Lower Bound of the Number of Sampling Points m | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Preconditioned Legendre | Chebyshev | Trigonometric | |||||||
| p | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| 5000 | 3748 | 3918 | 4089 | 2499 | 2612 | 2726 | 1250 | 1306 | 1363 |
| 10,000 | 4053 | 4237 | 4421 | 2702 | 2825 | 2948 | 1351 | 1413 | 1474 |
| 15,000 | 4231 | 4424 | 4616 | 2821 | 2949 | 3078 | 1411 | 1475 | 1539 |
| 20,000 | 4358 | 4556 | 4754 | 2906 | 3038 | 3170 | 1453 | 1519 | 1585 |
| 25,000 | 4456 | 4659 | 4861 | 2971 | 3106 | 3241 | 1486 | 1553 | 1621 |
| 30,000 | 4536 | 4743 | 4949 | 3024 | 3162 | 3299 | 1512 | 1581 | 1650 |
| 35,000 | 4604 | 4814 | 5023 | 3070 | 3209 | 3349 | 1535 | 1605 | 1675 |
| 40,000 | 4663 | 4875 | 5087 | 3109 | 3250 | 3391 | 1555 | 1625 | 1696 |
| 45,000 | 4715 | 4929 | 5143 | 3143 | 3286 | 3429 | 1572 | 1643 | 1715 |
| 50,000 | 4761 | 4978 | 5194 | 3174 | 3319 | 3463 | 1587 | 1660 | 1731 |
| n | Lower Bound of the Number of Sampling Points m | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Preconditioned Legendre | Chebyshev | Trigonometric | |||||||
| p | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| 20,000 | 17,431 | 18,223 | 19,015 | 11,621 | 12,149 | 12,677 | 5811 | 6075 | 6339 |
| 25,000 | 17,823 | 18,634 | 19,444 | 11,882 | 12,423 | 12,963 | 5941 | 6212 | 6482 |
| 30,000 | 18,144 | 18,969 | 19,794 | 12,096 | 12,646 | 13,196 | 6048 | 6323 | 6589 |
| 35,000 | 18,416 | 19,253 | 20,090 | 12,277 | 12,835 | 13,393 | 6139 | 6418 | 6697 |
| 40,000 | 18,615 | 19,498 | 20,346 | 12,434 | 12,999 | 13,564 | 6217 | 6500 | 6782 |
| 45,000 | 18,858 | 19,715 | 20,572 | 12,572 | 13,144 | 13,715 | 6286 | 6572 | 6858 |
| 50,000 | 19,043 | 19,909 | 20,774 | 12,696 | 13,273 | 13,850 | 6348 | 6637 | 6925 |
| n | p | Preconditioned Legendre | Chebyshev | Trigonometric | |||
|---|---|---|---|---|---|---|---|
| Upper Bound | Error | Upper Bound | Error | Upper Bound | Error | ||
| 20,000 | 0.2 | 5.9420 | 1.8612 | 5.9226 | 2.3162 | 5.9950 | 3.3156 |
| 0.3 | 5.9346 | 1.8189 | 5.9223 | 2.2176 | 5.9860 | 3.2614 | |
| 0.4 | 5.9347 | 1.7854 | 5.9195 | 2.1832 | 5.9863 | 3.1439 | |
| 40,000 | 0.2 | 5.9415 | 1.7713 | 5.9179 | 2.2273 | 5.9893 | 3.2066 |
| 0.3 | 5.9288 | 1.7402 | 5.9160 | 2.1478 | 5.9808 | 3.1279 | |
| 0.4 | 5.9308 | 1.7416 | 5.9150 | 2.1179 | 5.9810 | 3.0817 | |
| 50,000 | 0.2 | 5.9307 | 1.7897 | 5.9201 | 2.2058 | 5.9869 | 3.1696 |
| 0.3 | 5.9301 | 1.7361 | 5.9149 | 2.1592 | 5.9777 | 3.0936 | |
| 0.4 | 5.9258 | 1.7054 | 5.9106 | 2.0830 | 5.9787 | 3.0729 | |
| n | p | Preconditioned Legendre | Chebyshev | Trigonometric | |||
|---|---|---|---|---|---|---|---|
| Upper Bound | Error | Upper Bound | Error | Upper Bound | Error | ||
| 20,000 | 0.2 | 5.9530 | 1.3369 | 5.8490 | 1.1562 | 5.9638 | 2.2914 |
| 0.3 | 5.9462 | 1.3542 | 5.8489 | 1.1564 | 5.9590 | 2.3235 | |
| 0.4 | 5.9176 | 1.2626 | 5.8494 | 1.0587 | 5.9622 | 2.2498 | |
| 40,000 | 0.2 | 5.9412 | 1.2278 | 5.8480 | 1.0481 | 5.9567 | 2.2734 |
| 0.3 | 5.9063 | 1.2800 | 5.8443 | 1.1113 | 5.9534 | 2.1706 | |
| 0.4 | 5.9037 | 1.2962 | 5.8419 | 9.9783 | 5.9500 | 2.1759 | |
| 50,000 | 0.2 | 5.9082 | 1.3328 | 5.8454 | 1.0770 | 5.9634 | 2.2618 |
| 0.3 | 5.9097 | 1.2813 | 5.8436 | 1.0537 | 5.9548 | 2.1822 | |
| 0.4 | 5.9085 | 1.3133 | 5.8403 | 1.0581 | 5.9489 | 2.1657 | |
| n | p | Actual Error | ||
|---|---|---|---|---|
| Preconditioned Legendre | Chebyshev | Trigonometric | ||
| 20,000 | 0.2 | 5.7726 | 5.7793 | 5.7755 |
| 0.3 | 5.7735 | 5.7718 | 5.7818 | |
| 0.4 | 5.7751 | 5.7731 | 5.7799 | |
| 40,000 | 0.2 | 5.7864 | 5.7733 | 5.7849 |
| 0.3 | 5.7796 | 5.7784 | 5.7782 | |
| 0.4 | 5.7814 | 5.7792 | 5.7792 | |
| 50,000 | 0.2 | 5.7791 | 5.7772 | 5.7792 |
| 0.3 | 5.7802 | 5.7801 | 5.7798 | |
| 0.4 | 5.7773 | 5.7774 | 5.7840 | |
| n | p | Actual Error | ||
|---|---|---|---|---|
| Preconditioned Legendre | Chebyshev | Trigonometric | ||
| 20,000 | 0.2 | 5.7782 | 5.7756 | 5.7753 |
| 0.3 | 5.7681 | 5.7793 | 5.7703 | |
| 0.4 | 5.7734 | 5.7900 | 5.7753 | |
| 40,000 | 0.2 | 5.7788 | 5.7762 | 5.7760 |
| 0.3 | 5.7771 | 5.7810 | 5.7816 | |
| 0.4 | 5.7781 | 5.7659 | 5.7760 | |
| 50,000 | 0.2 | 5.7765 | 5.7721 | 5.7711 |
| 0.3 | 5.7734 | 5.7763 | 5.7856 | |
| 0.4 | 5.7765 | 5.7808 | 5.7711 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, A.; Feng, R.; Wang, A. The Sufficient Conditions for Orthogonal Matching Pursuit to Exactly Reconstruct Sparse Polynomials. Mathematics 2022, 10, 3703. https://doi.org/10.3390/math10193703
Huang A, Feng R, Wang A. The Sufficient Conditions for Orthogonal Matching Pursuit to Exactly Reconstruct Sparse Polynomials. Mathematics. 2022; 10(19):3703. https://doi.org/10.3390/math10193703
Chicago/Turabian StyleHuang, Aitong, Renzhong Feng, and Andong Wang. 2022. "The Sufficient Conditions for Orthogonal Matching Pursuit to Exactly Reconstruct Sparse Polynomials" Mathematics 10, no. 19: 3703. https://doi.org/10.3390/math10193703