
A Weighted Surrogate Model for Spatio-Temporal Dynamics with Multiple Time Spans: Applications for the Pollutant Concentration of the Bai River
Abstract
:1. Introduction
2. Methodology
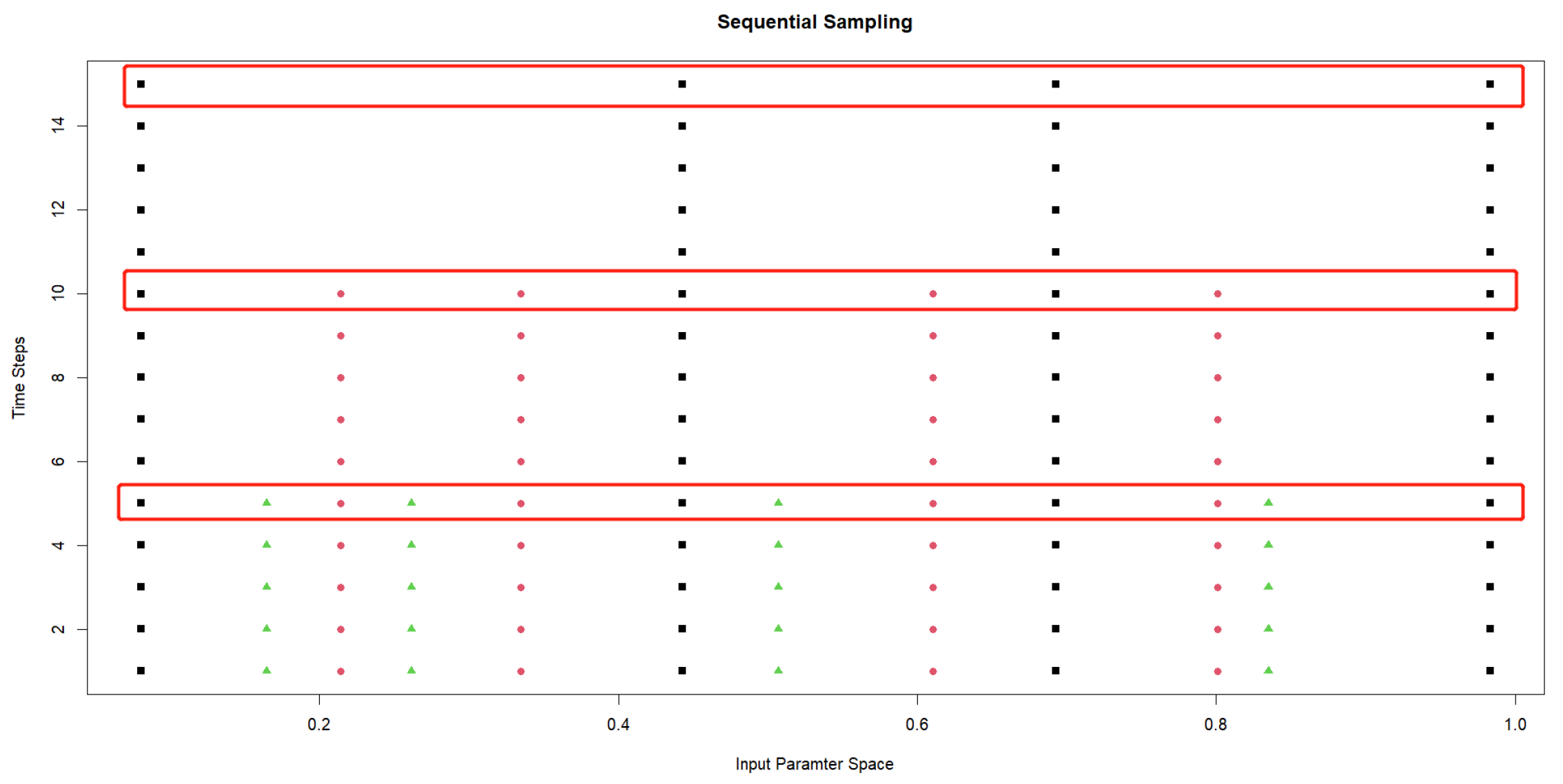
2.1. The Reverse Sequential Sampling Scheme
2.2. The Proposed Model
2.2.1. The Surrogate Model for Time-Varying Coefficients
2.2.2. The Weighted Surrogate Model for Time-Varying Coefficients
2.2.3. The Prediction of System Dynamics with New Input Parameters
- Determine the input parameters and their ranges and map the input parameter space to , where p is the dimension of the input parameters.
- Determine the spatial extent and time span of the spatio-temporal data , and make discrete divisions of the spatio-temporal field with appropriate precision, which is denoted as .
- Determine the different ending times of the simulation of spatio-temporal data and the corresponding number of training samples .
| Algorithm 1: The framework for the spatio-temporal surrogate model. |
 |
3. Simulation Studies
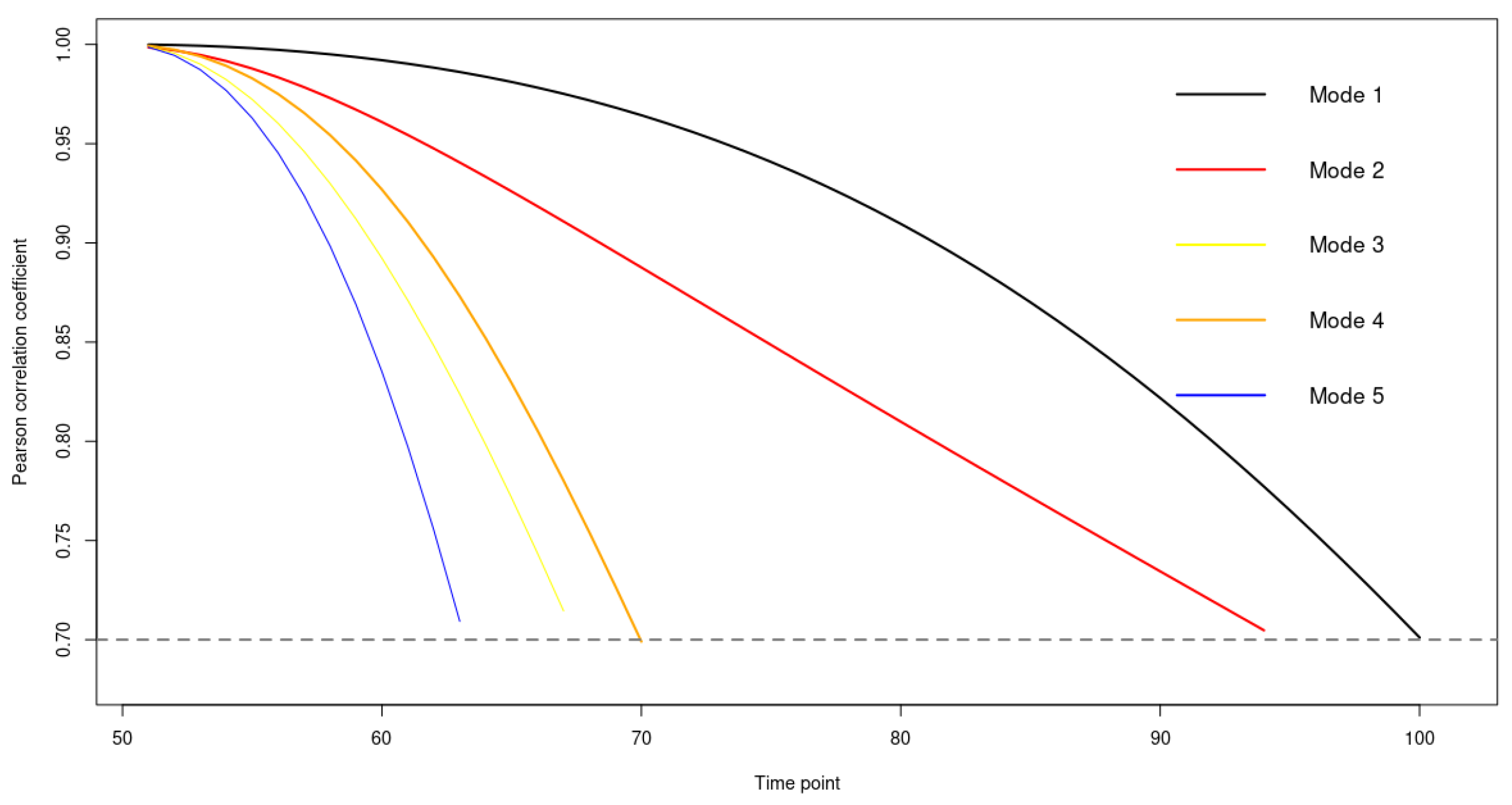
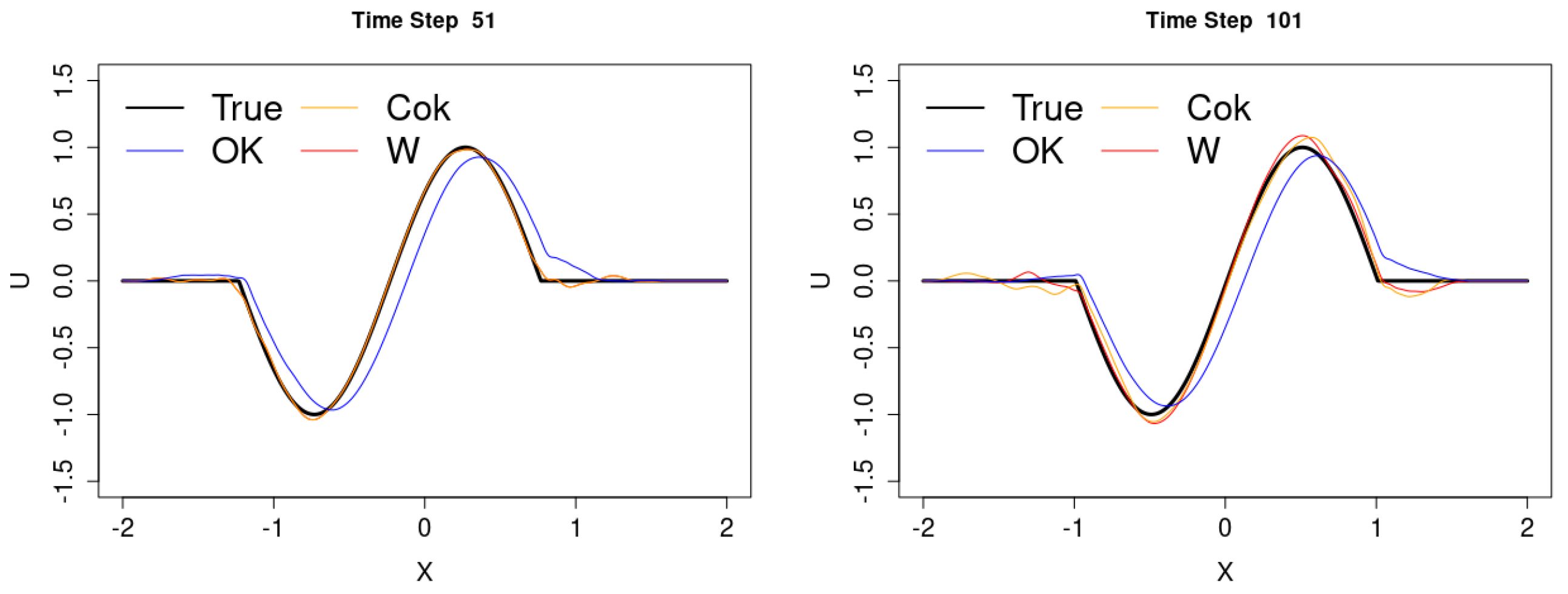
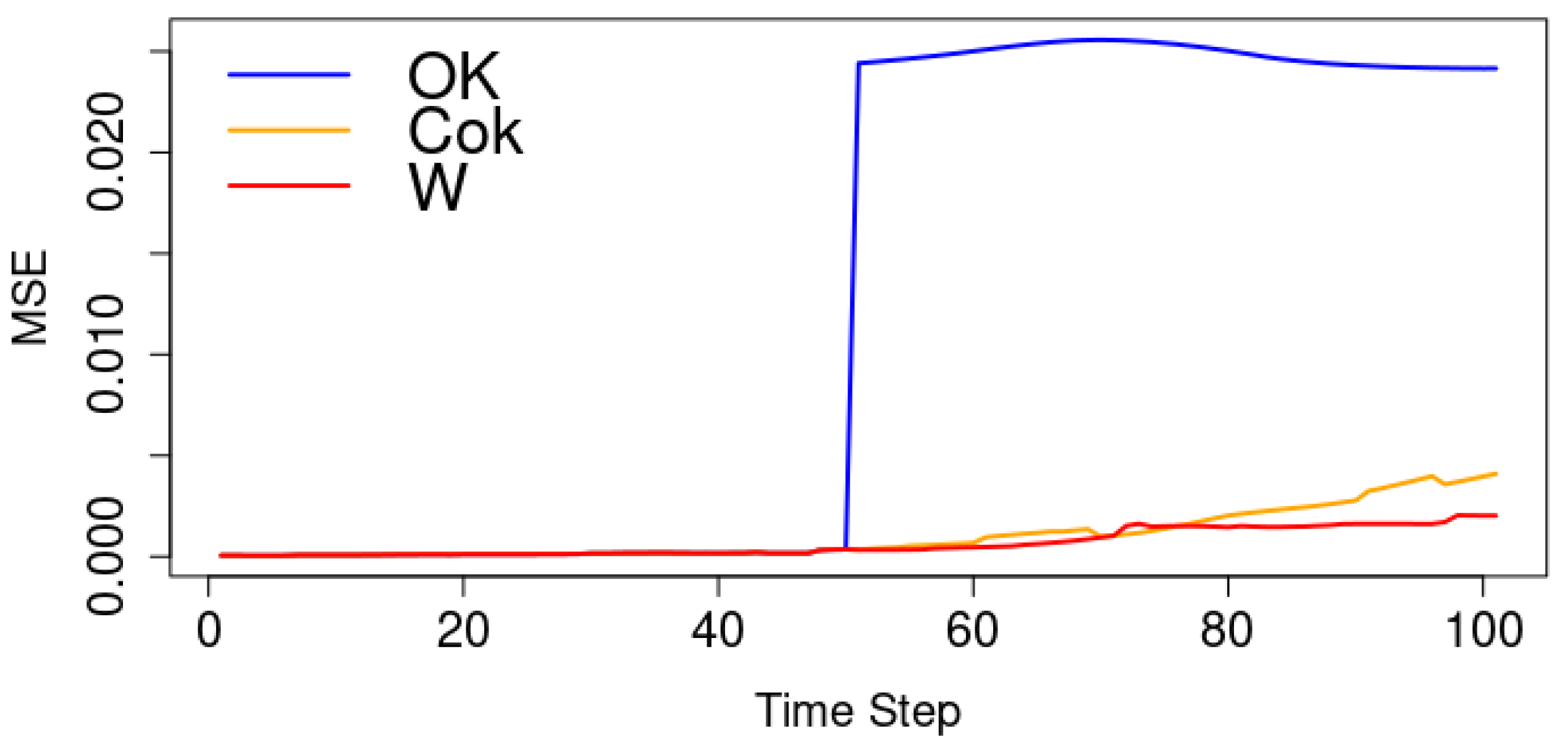
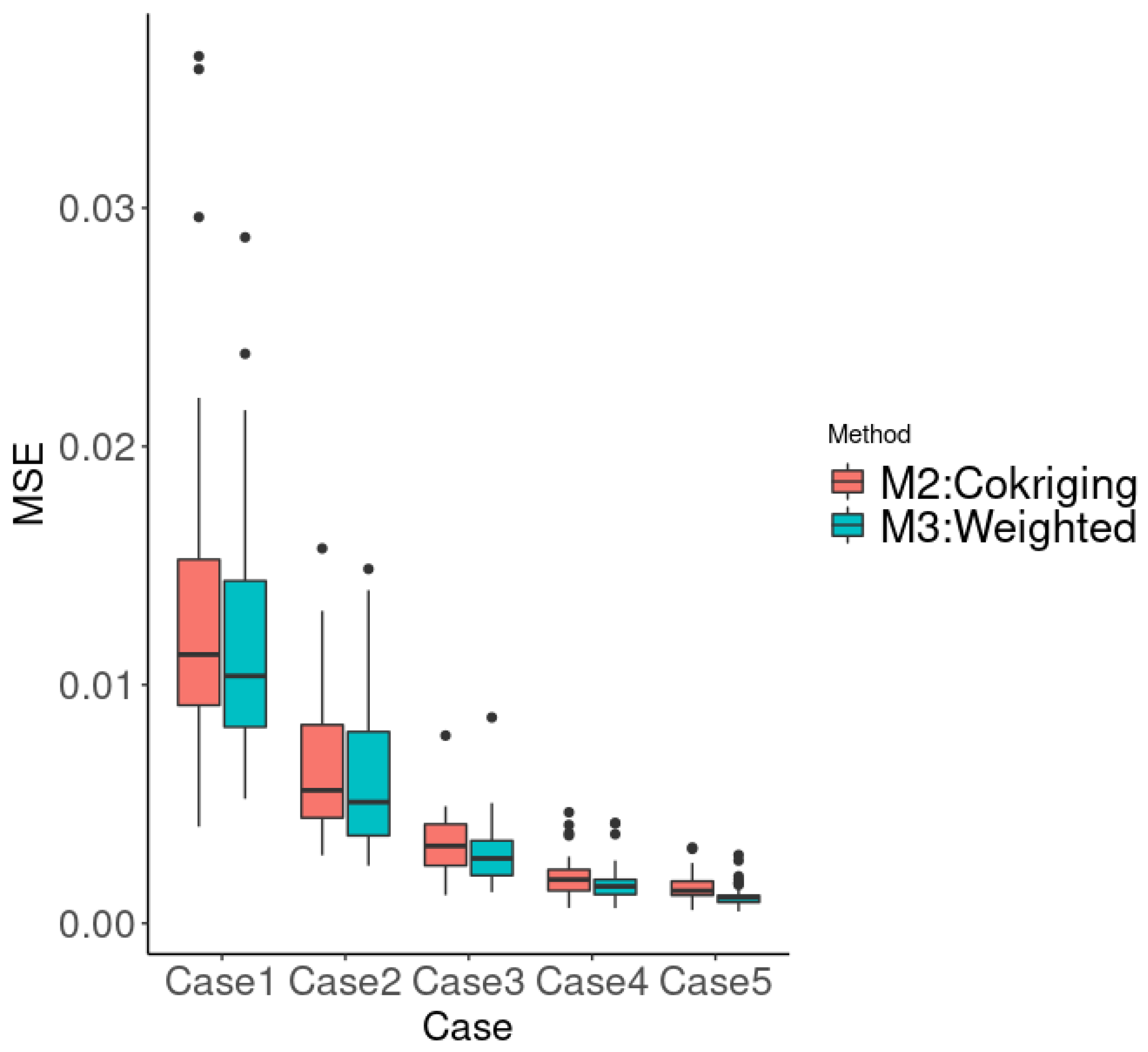
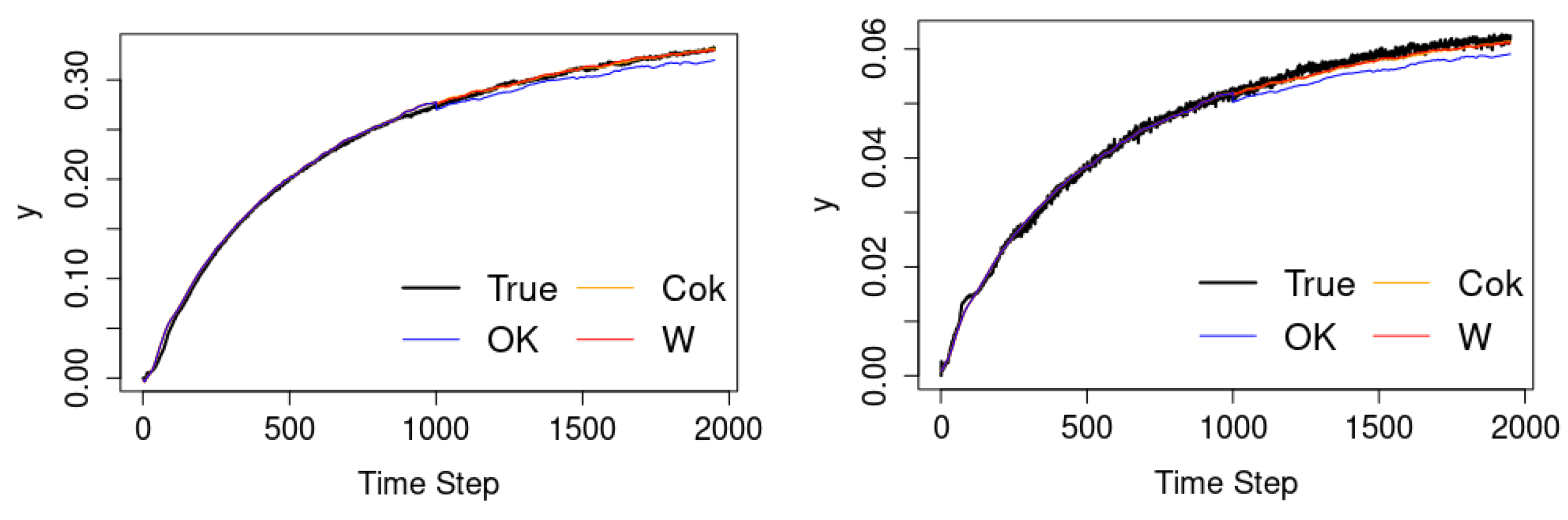
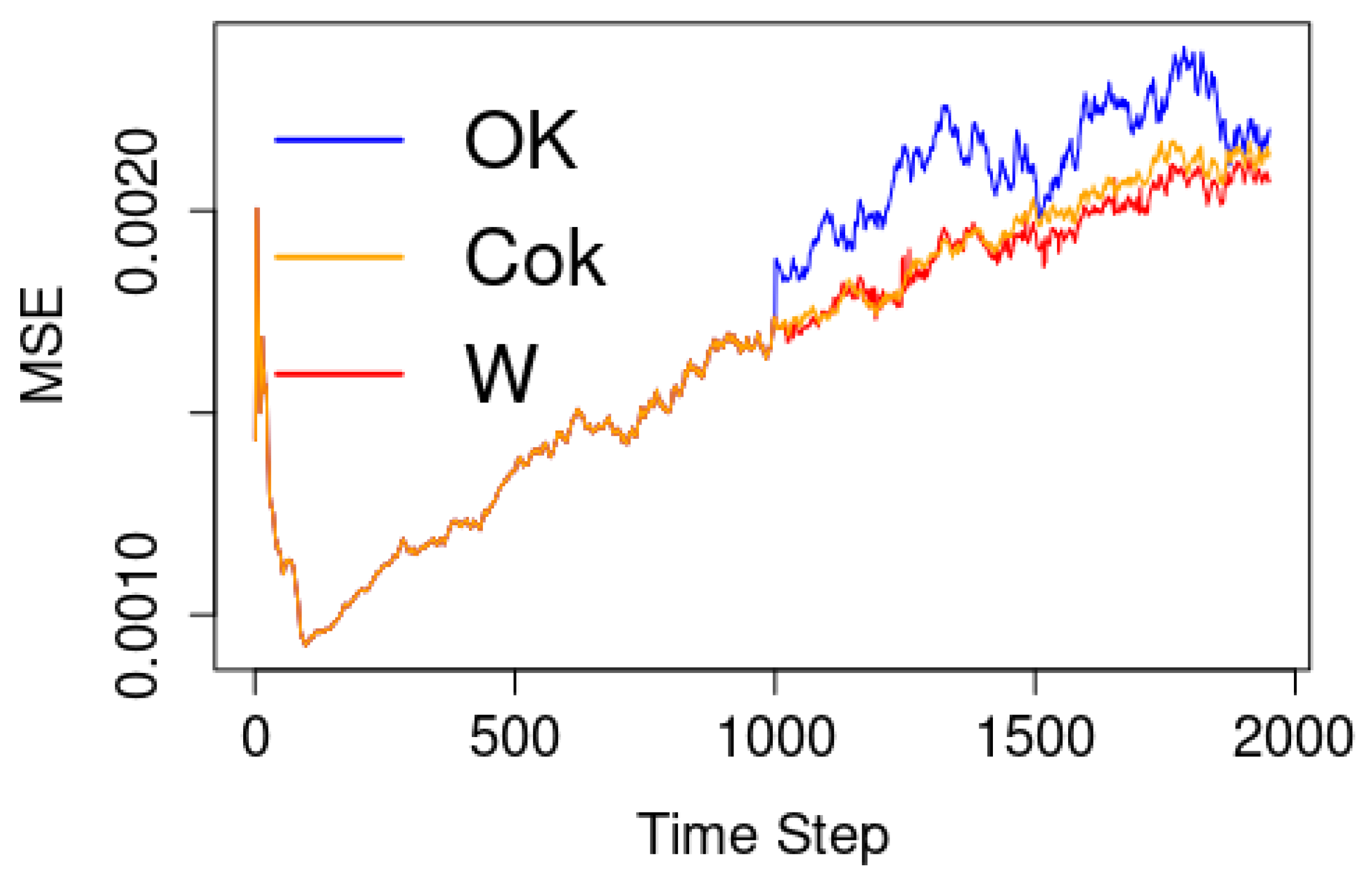
3.1. The Case of 2D Input Parameters for Spatio-Temporal Data
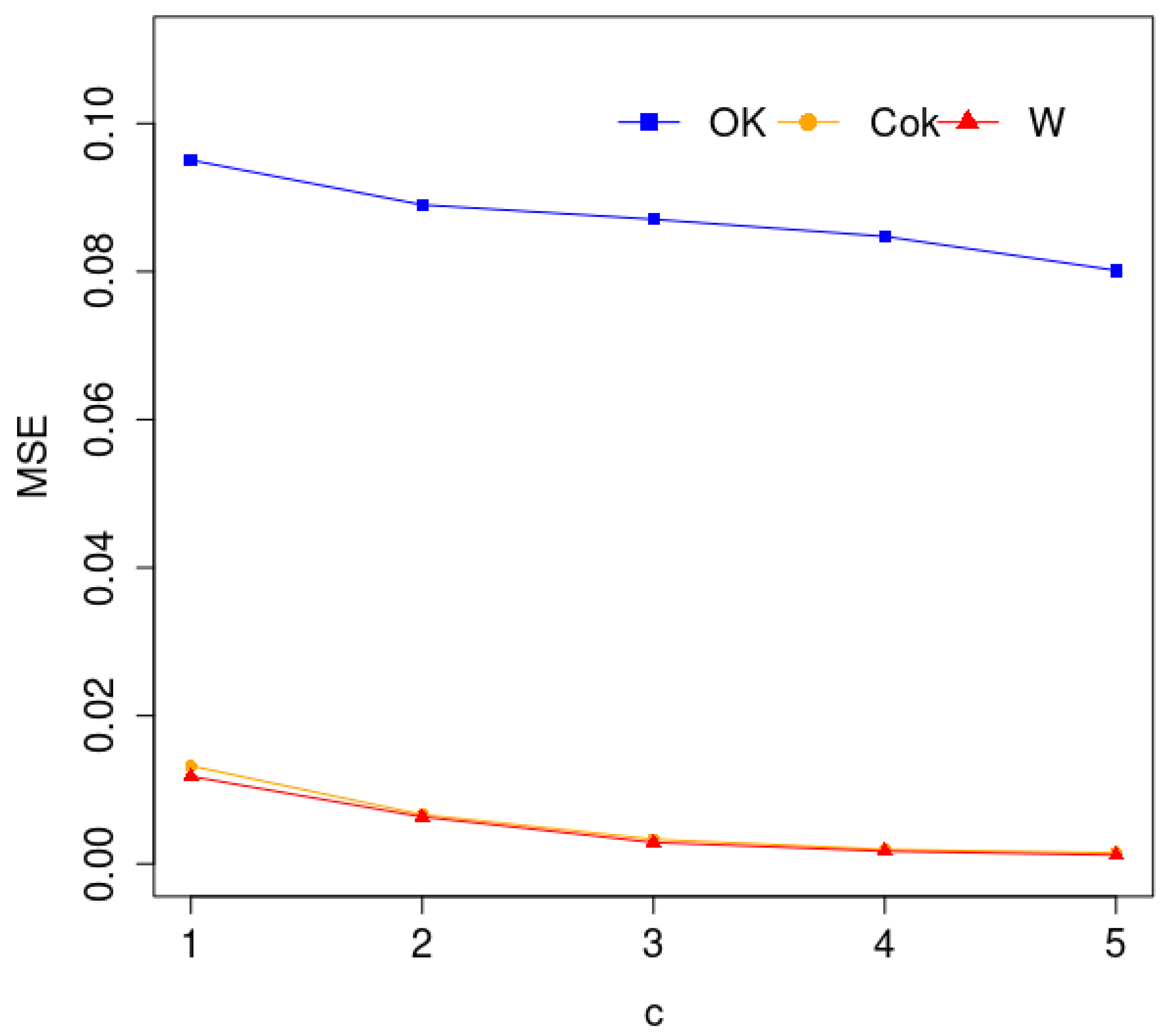
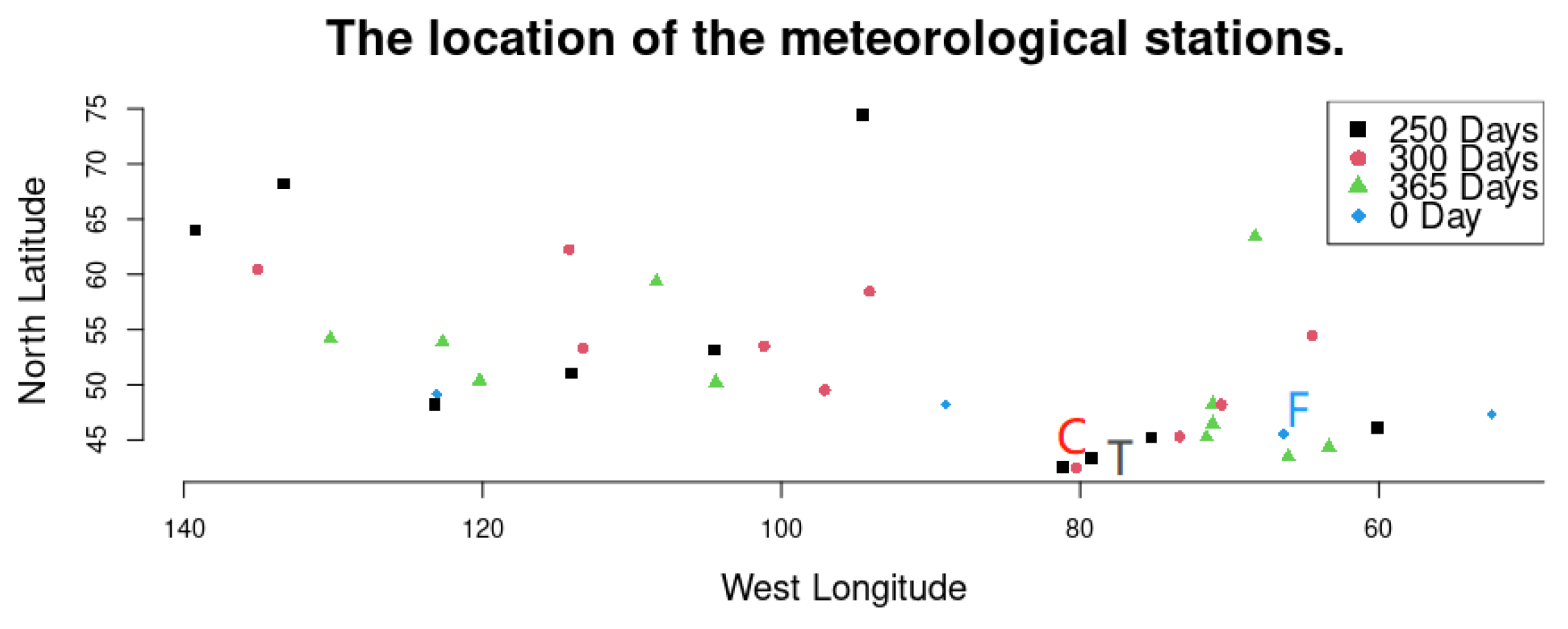
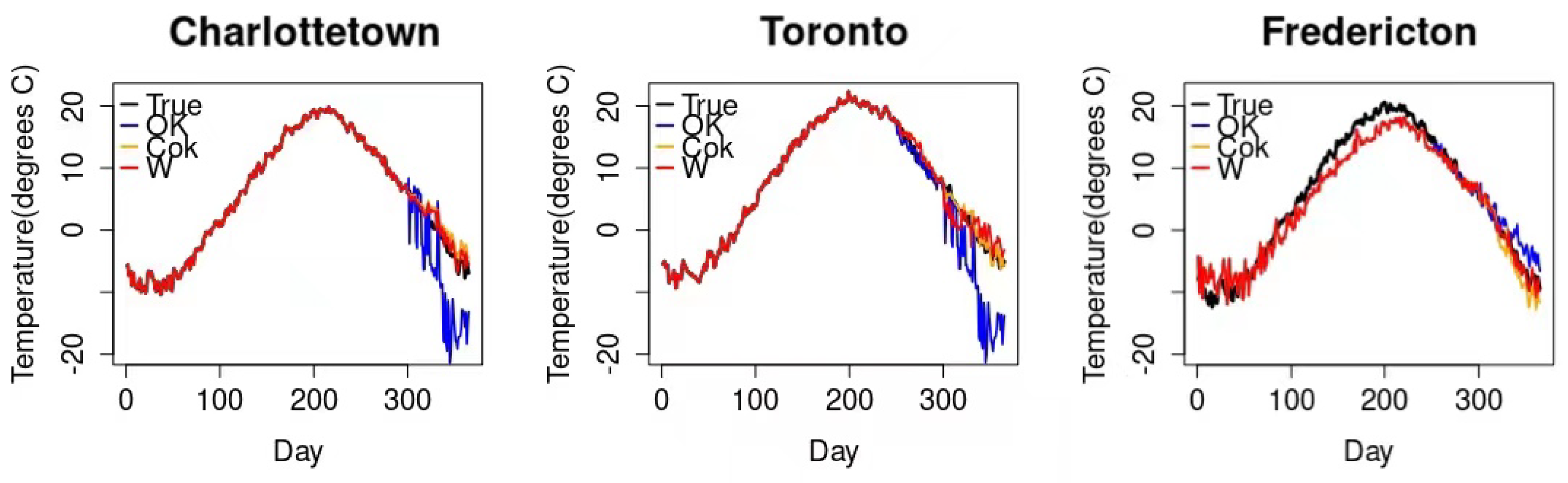
3.2. The Case of Canadian Weather
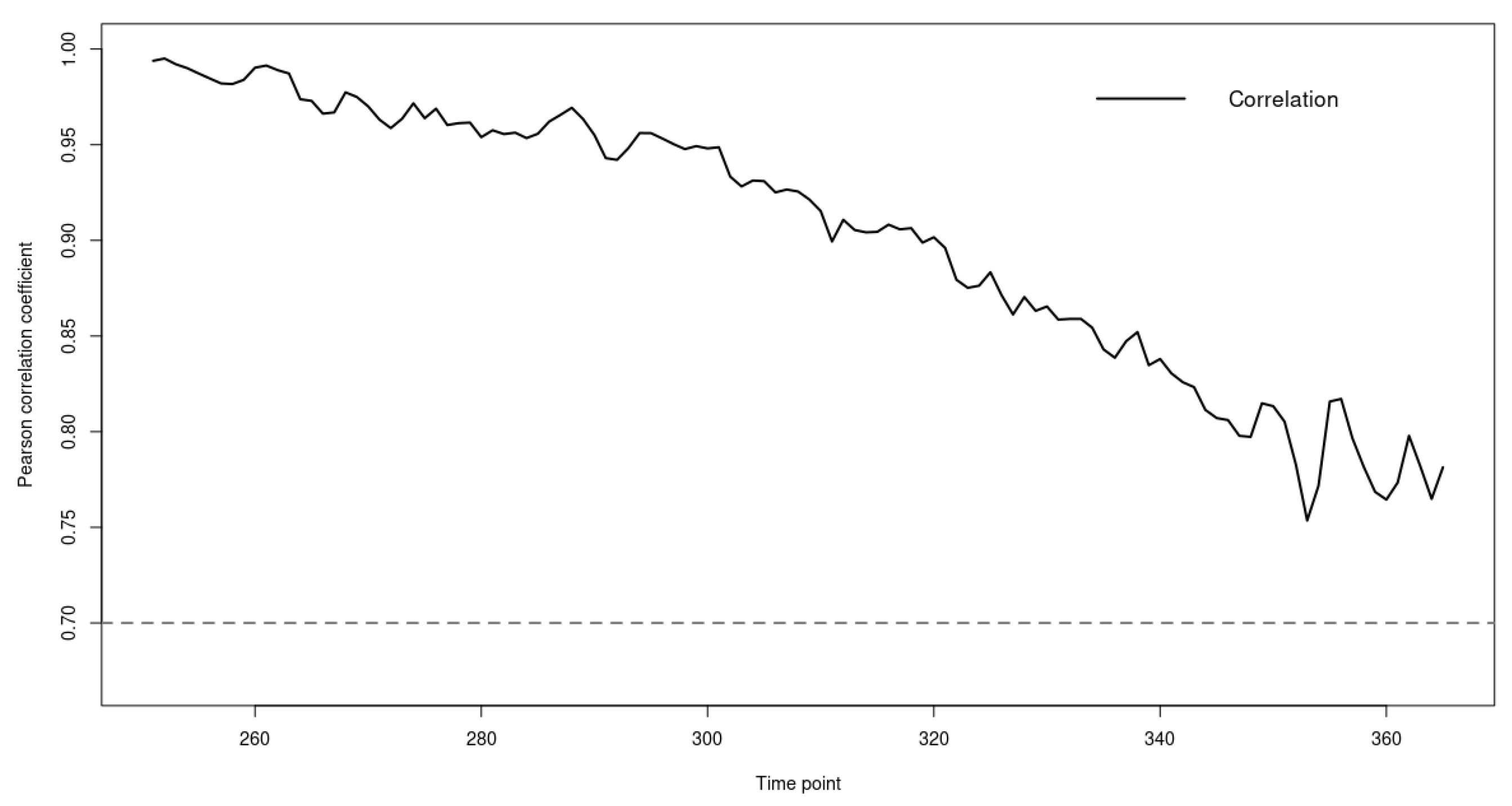
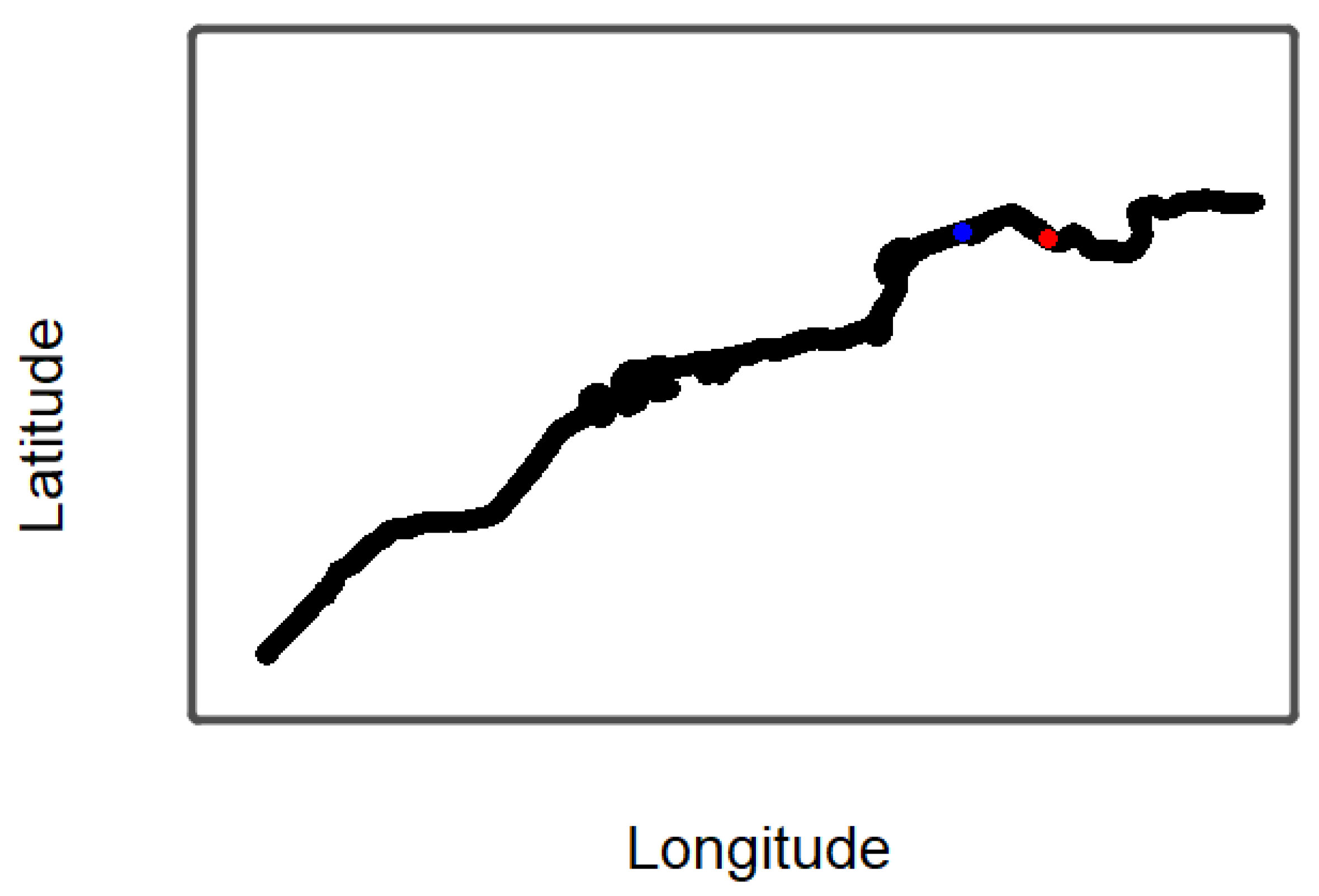
4. Application of the Model to Bai River Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| POD | Proper Orthogonal Decomposition |
| ROM | Reduced Order Modeling |
| LHD | Latin Hypercube Design |
| GP | Gaussian Process |
| OK | Ordinary Kriging |
| MSE | Mean Square Error |
References
- Xiao, C.; Leeuwenburgh, O.; Lin, H.X.; Heemink, A. Non-intrusive subdomain POD-TPWL for reservoir history matching. Comput. Geosci. 2019, 23, 537–565. [Google Scholar] [CrossRef] [Green Version]
- Lumley, J.L. The structure of inhomogeneous turbulent flows. In Atmospheric Turbulence and Radio Wave Propagation; NAUKA: Moscow, Russia, 1967; pp. 166–178. [Google Scholar]
- Ioannidis, V.N.; Romero, D.; Giannakis, G.B. Inference of Spatio-Temporal Functions over Graphs via Multikernel Kriged Kalman Filtering. IEEE Trans. Signal Process. 2018, 66, 3228–3239. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, H.; Katzfuss, M.; Cressie, N.; Braverman, A. Spatio-temporal data fusion for very large remote sensing datasets. Technometrics 2014, 56, 174–185. [Google Scholar] [CrossRef]
- Shi, Q.; Dai, W.; Santerre, R.; Liu, N. A Modified Spatiotemporal Mixed-Effects Model for Interpolating Missing Values in Spatiotemporal Observation Data Series. Math. Probl. Eng. 2020, 2020, 1070831. [Google Scholar] [CrossRef]
- Guo, M.; Hesthaven, J.S. Data-driven reduced order modeling for time-dependent problems. Comput. Methods Appl. Mech. Eng. 2019, 345, 75–99. [Google Scholar] [CrossRef]
- Yeh, S.T.; Wang, X.; Sung, C.L.; Mak, S.; Chang, Y.H.; Zhang, L.; Wu, C.F.; Yang, V. Common proper orthogonal decomposition-based spatiotemporal emulator for design exploration. AIAA J. 2018, 56, 2429–2442. [Google Scholar] [CrossRef] [Green Version]
- Chang, Y.H.; Zhang, L.; Wang, X.; Yeh, S.T.; Mak, S.; Sung, C.L.; Jeff Wu, C.F.; Yang, V. Kernel-smoothed proper orthogonal decomposition-based emulation for spatiotemporally evolving flow dynamics prediction. AIAA J. 2019, 57, 5269–5280. [Google Scholar] [CrossRef]
- Chang, Y.H.; Wang, X.; Zhang, L.; Li, Y.; Mak, S.; Wu, C.F.J.; Yang, V. Reduced-Order Modeling for Complex Flow Emulation by Common Kernel-Smoothed Proper Orthogonal Decomposition. AIAA J. 2021, 59, 3291–3303. [Google Scholar] [CrossRef]
- Chatterjee, A. An introduction to the proper orthogonal decomposition. Curr. Sci. 2000, 78, 808–817. [Google Scholar]
- Xiong, F.; Xiong, Y.; Chen, W.; Yang, S. Optimizing Latin hypercube design for sequential sampling of computer experiments. Eng. Optim. 2009, 41, 793–810. [Google Scholar] [CrossRef]
- Garud, S.S.; Karimi, I.A.; Kraft, M. Design of computer experiments: A review. Comput. Chem. Eng. 2017, 106, 71–95. [Google Scholar] [CrossRef]
- Joseph, V.R.; Gul, E.; Ba, S. Maximum projection designs for computer experiments. Biometrika 2015, 102, 371–380. [Google Scholar] [CrossRef]
- Carnell, R.; Carnell, M.R. Package ‘lhs’. CRAN. Available online: http://cran.stat.auckland.ac.nz/web/packages/lhs/lhs.pdf (accessed on 22 March 2022).
- Santner, T.J.; Williams, B.J.; Notz, W.I.; Williams, B.J. The Design and Analysis of Computer Experiments; Springer: New York, NY, USA, 2003; Volume 1. [Google Scholar]
- Simpson, T.W.; Mauery, T.M.; Korte, J.J.; Mistree, F. Kriging models for global approximation in simulation-based multidisciplinary design optimization. AIAA J. 2001, 39, 2233–2241. [Google Scholar] [CrossRef] [Green Version]
- Kleijnen, J.P. Kriging metamodeling in simulation: A review. Eur. J. Oper. Res. 2009, 192, 707–716. [Google Scholar] [CrossRef] [Green Version]
- Vicario, G.; Craparotta, G.; Pistone, G. Meta-models in computer experiments: Kriging versus artificial neural networks. Qual. Reliab. Eng. Int. 2016, 32, 2055–2065. [Google Scholar] [CrossRef]
- Kennedy, M.C.; O’Hagan, A. Predicting the output from a complex computer code when fast approximations are available. Biometrika 2000, 87, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Gratiet, L.L.; Garnier, J. Recursive co-kriging model for design of computer experiments with multiple levels of fidelity. Int. J. Uncertain. Quantif. 2014, 4, 365–386. [Google Scholar] [CrossRef]
- Hu, F.Q.; Hussaini, M.Y.; Rasetarinera, P. An analysis of the discontinuous Galerkin method for wave propagation problems. J. Comput. Phys. 1999, 151, 921–946. [Google Scholar] [CrossRef]
- Vadyala, S.R.; Betgeri, S.N.; Betgeri, N.P. Physics-informed neural network method for solving one-dimensional advection equation using PyTorch. Array 2022, 13, 100110. [Google Scholar] [CrossRef]
- Shen, H.; Parsani, M. Positivity-preserving CE/SE schemes for solving the compressible Euler and Navier–Stokes equations on hybrid unstructured meshes. Comput. Phys. Commun. 2018, 232, 165–176. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| v | v | ||||
|---|---|---|---|---|---|
| 0.133 | 0.760 | 0.176 | 0.662 | ||
| 0.259 | 0.555 | 0.688 | 0.186 | ||
| 0.782 | 0.268 | 0.951 | 0.338 | ||
| 0.564 | 0.143 | 0.405 | 0.891 | ||
| 0.460 | 0.417 | 0.327 | 0.456 | ||
| 0.641 | 0.014 | 0.043 | 0.608 | ||
| 0.081 | 0.920 | 0.820 | 0.079 | ||
| 0.878 | 0.729 | 0.545 | 0.975 |
| Case | Number |
|---|---|
| Case 1 | |
| Case 2 | |
| Case 3 | |
| Case 4 | |
| Case 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huan, Y.; Tian, Y.; Wang, D. A Weighted Surrogate Model for Spatio-Temporal Dynamics with Multiple Time Spans: Applications for the Pollutant Concentration of the Bai River. Mathematics 2022, 10, 3585. https://doi.org/10.3390/math10193585
Huan Y, Tian Y, Wang D. A Weighted Surrogate Model for Spatio-Temporal Dynamics with Multiple Time Spans: Applications for the Pollutant Concentration of the Bai River. Mathematics. 2022; 10(19):3585. https://doi.org/10.3390/math10193585
Chicago/Turabian StyleHuan, Yue, Yubin Tian, and Dianpeng Wang. 2022. "A Weighted Surrogate Model for Spatio-Temporal Dynamics with Multiple Time Spans: Applications for the Pollutant Concentration of the Bai River" Mathematics 10, no. 19: 3585. https://doi.org/10.3390/math10193585