

Accelerating Extreme Search of Multidimensional Functions Based on Natural Gradient Descent with Dirichlet Distributions

Abstract
:1. Introduction
2. Preliminaries
2.1. Gradient Descent with Step-Size Adaptation
| Algorithm 1 Gradient Descent with Step-Size Adaptation |
|
2.2. Adam Algorithm
| Algorithm 2 Adam algorithm |
|
2.3. Background on Riemannian Gradient Flow
2.4. Natural Gradient Descent and K–L Divergence
3. Theoretical Calculations
Fisher Matrix for Dirichlet and Generalized Dirichlet Distributions
| Algorithm 3 Natural Gradient Descent with Dirichlet and Generalized Dirichlet Distribution |
|
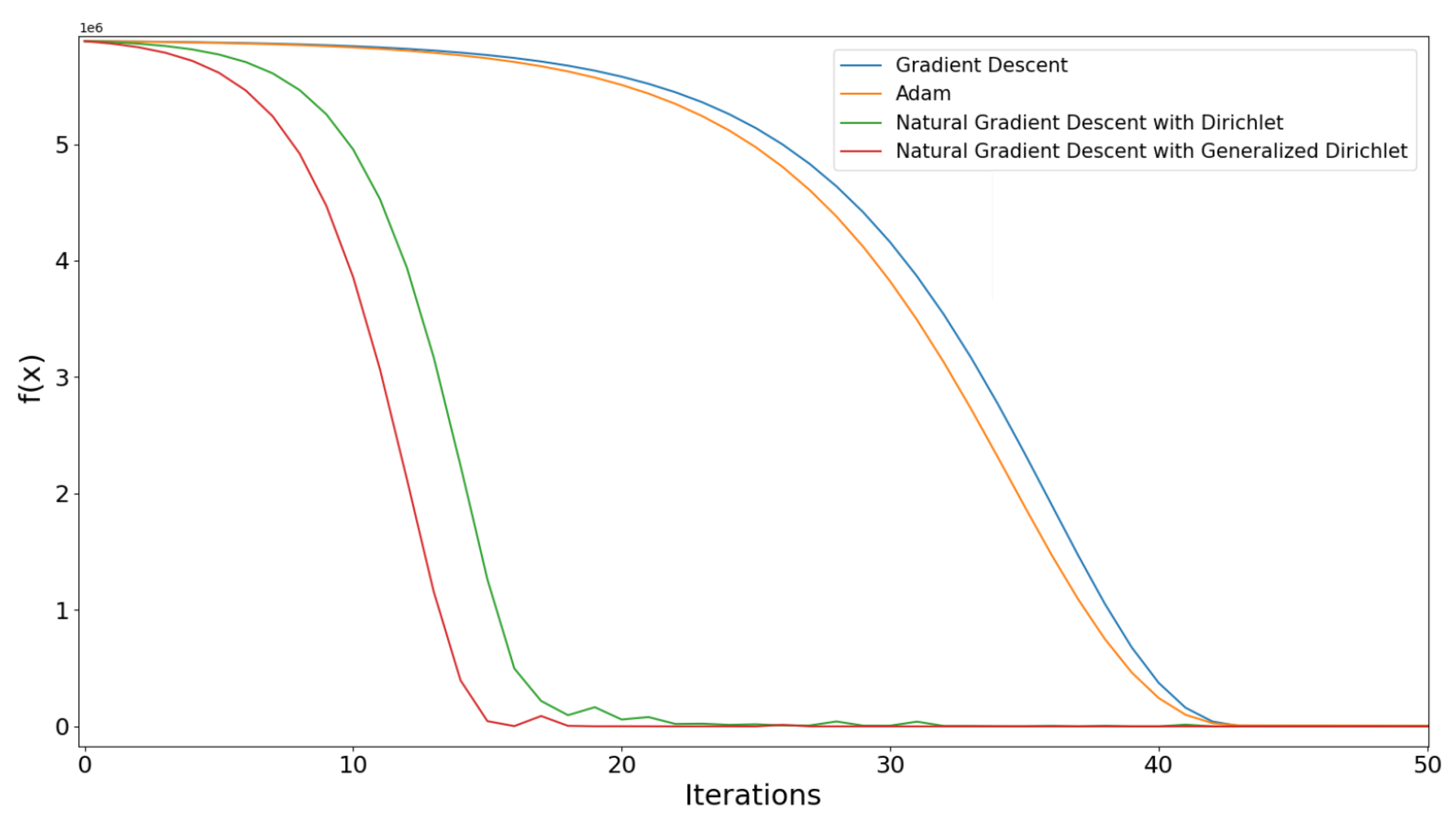
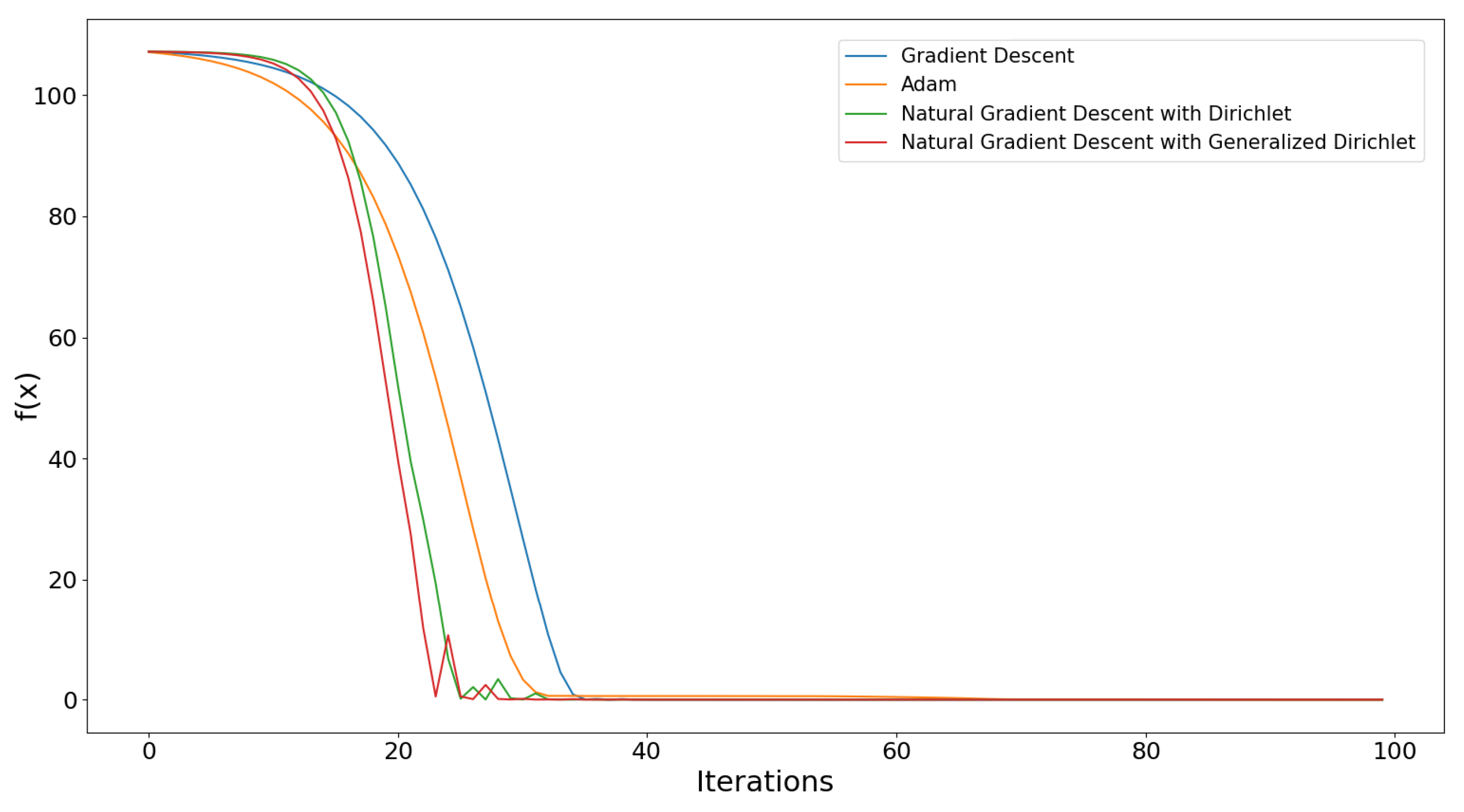
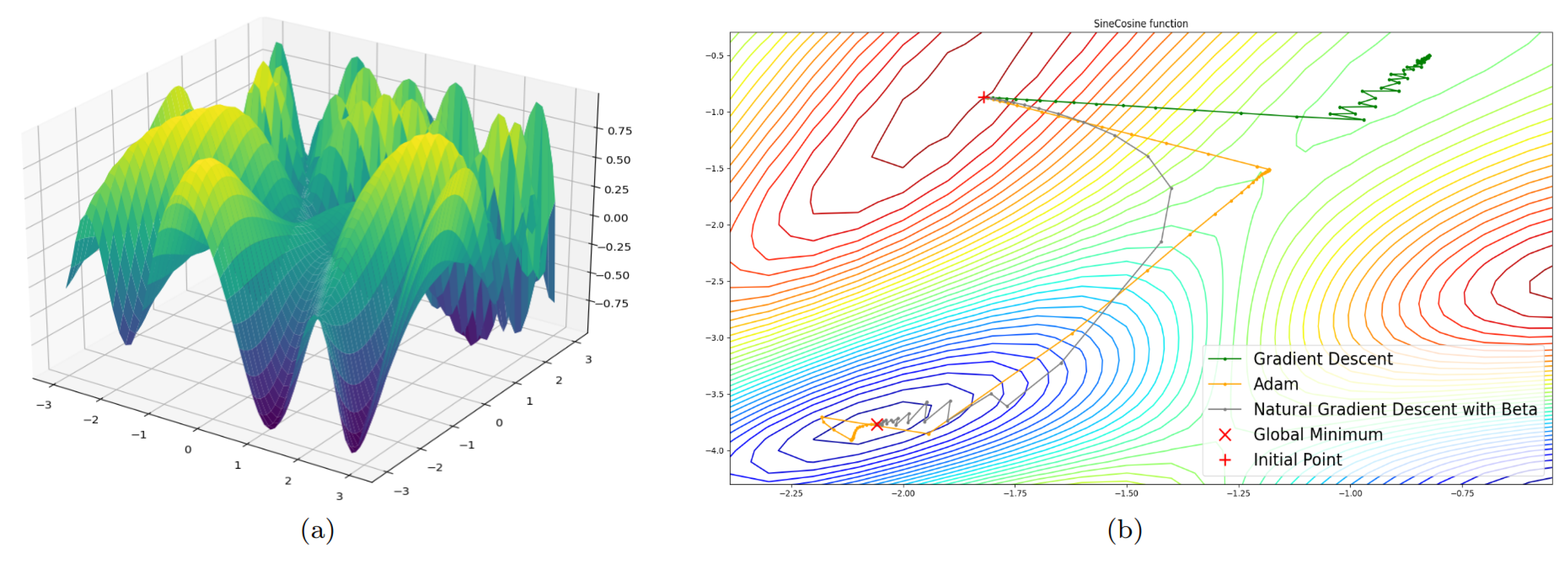
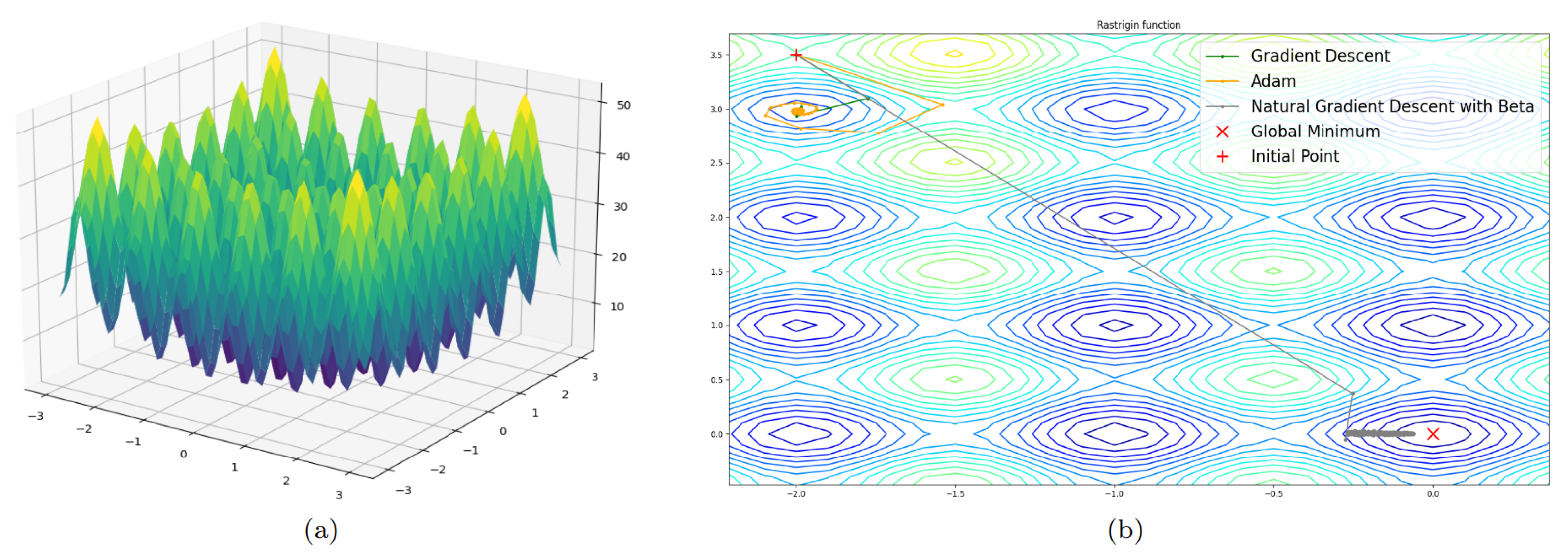
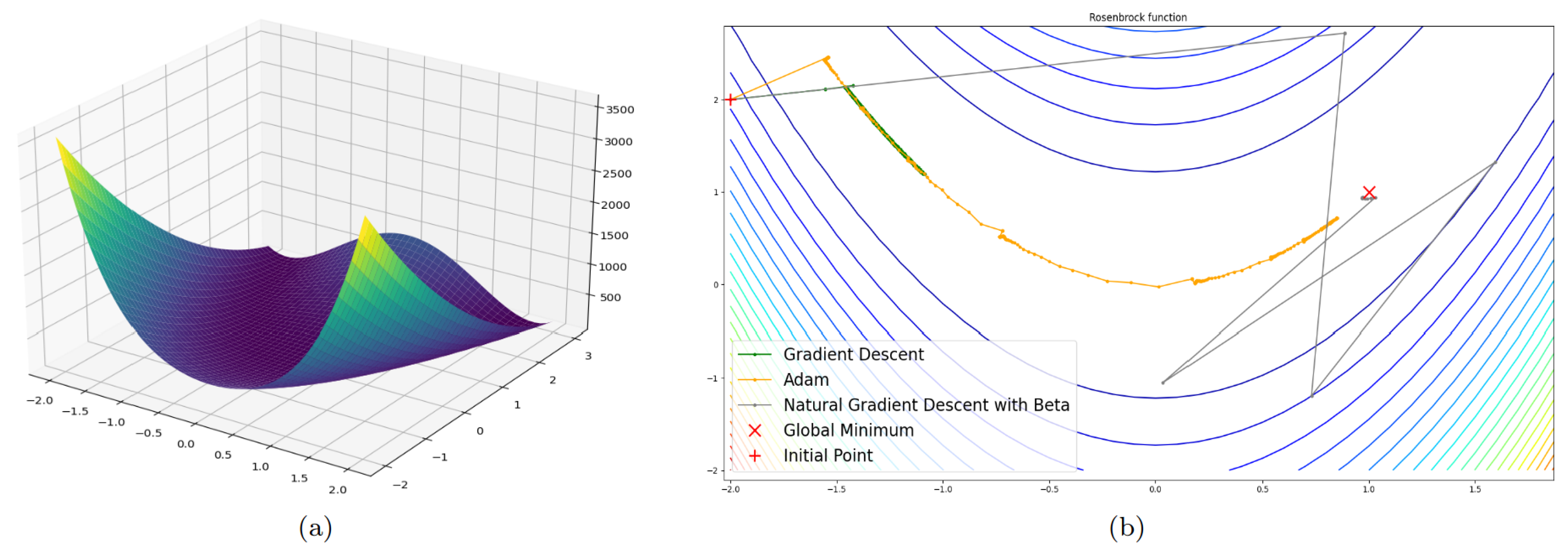
4. Experimental Part
4.1. Four-Dimensional Case
4.2. Three-Dimensional Case
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ward, R.; Wu, X.; Bottou, L. AdaGrad Stepsizes: Sharp Convergence Over Nonconvex Landscapes. J. Mach. Learn. Res. 2020, 21, 1–30. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Xu, D.; Zhang, S.; Zhang, H.; Mandic, D.P. Convergence of the RMSProp deep learning method with penalty for nonconvex optimization. Neural Netw. 2021, 139, 17–23. [Google Scholar] [CrossRef] [PubMed]
- Qu, Z.; Yuan, S.; Chi, R.; Chang, L.; Zhao, L. Genetic Optimization Method of Pantograph and Catenary Comprehensive Monitor Status Prediction Model Based on Adadelta Deep Neural Network. IEEE Access 2019, 7, 23210–23221. [Google Scholar] [CrossRef]
- Wu, H.-P.; Li, L. The BP Neural Network with Adam Optimizer for Predicting Audit Opinions of Listed Companies. IAENG Int. J. Comput. Sci. 2021, 48, 364–368. [Google Scholar]
- Toussaint, M. Lecture Notes: Some Notes on Sradient Descent; Machine Learning & Robotics Lab, FU Berlin: Berlin, Germany, 2012. [Google Scholar]
- Wang, S.; Teng, Y.; Perdikaris, P. Understanding and Mitigating Gradient Flow Pathologies in Physics-Informed Neural Networks. SIAM J. Sci. Comput. 2021, 43, 3055–3081. [Google Scholar] [CrossRef]
- Martens, J. New Insights and Perspectives on the Natural Gradient Method. J. Mach. Learn. Res. 2020, 21, 1–76. [Google Scholar]
- Huang, Y.; Zhang, Y.; Chambers, J.A. A Novel Kullback–Leibler Divergence Minimization-Based Adaptive Student’s t-Filter. IEEE Trans. Signal Process. 2019, 67, 5417–5432. [Google Scholar] [CrossRef]
- Asperti, A.; Trentin, M. Balancing Reconstruction Error and Kullback-Leibler Divergence in Variational Autoencoders. IEEE Access 2019, 8, 199440–199448. [Google Scholar] [CrossRef]
- Heck, D.W.; Moshagen, M.; Erdfelder, E. Model selection by minimum description length: Lower-bound sample sizes for the Fisher information approximation. J. Math. Psychol. 2014, 60, 29–34. [Google Scholar] [CrossRef]
- Spall, J.C. Monte Carlo Computation of the Fisher Information Matrix in Nonstandard Settings. J. Comput. Graph. Stat. 2012, 14, 889–909. [Google Scholar] [CrossRef]
- Alvarez, F.; Bolte, J.; Brahic, O. Hessian Riemannian Gradient Flows in Convex Programming. Soc. Ind. Appl. Math. 2004, 43, 68–73. [Google Scholar] [CrossRef]
- Abdulkadirov, R.; Lyakhov, P. Improving Extreme Search with Natural Gradient Descent Using Dirichlet Distribution. In Mathematics and Its Applications in New Computer Systems; MANCS 2021; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2022; Volume 424, pp. 19–28. [Google Scholar]
- Lyakhov, P.; Abdulkadirov, R. Accelerating Extreme Search Based on Natural Gradient Descent with Beta Distribution. In Proceedings of the 2021 International Conference Engineering and Telecommunication (En&T), Online, 24–25 November 2021; pp. 1–5. [Google Scholar]
- Celledoni, E.; Eidnes, S.; Owren, B.; Ringholm, T. Dissipative Numerical Schemes on Riemannian Manifolds with Applications to Gradient Flows. SIAM J. Sci. Comput. 2018, 40, A3789–A3806. [Google Scholar] [CrossRef]
- Liao, Z.; Drummond, T.; Reid, I.; Carneiro, G. Approximate Fisher Information Matrix to Characterize the Training of Deep Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 15–26. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wong, T.-T. Generalized Dirichlet distribution in Bayesian analysis. Appl. Math. Comput. 1998, 97, 165–181. [Google Scholar] [CrossRef]
- Wang, X.; Lin, X.; Dang, X. Supervised learning in spiking neural networks: A review of algorithms and evaluations. Neural Netw. 2020, 125, 258–280. [Google Scholar] [CrossRef] [PubMed]
- Abbas, A.; Sutter, D.; Zoufal, C.; Figalli, A. The power of quantum neural networks. Nat. Comput. Sci. 2021, 1, 403–409. [Google Scholar] [CrossRef]
- Guo, Y.; Cao, X.; Liu, B.; Gao, M. Solving Partial Differential Equations Using Deep Learning and Physical Constraints. Appl. Sci. 2020, 10, 5917. [Google Scholar] [CrossRef]
- Klakattawi, H.S. The Weibull-Gamma Distribution: Properties and Applications. Entropy 2019, 21, 438. [Google Scholar] [CrossRef] [PubMed]
- Bantan, R.A.R.; Jamal, F.; Chesneau, C.; Elgarhy, M. Theory and Applications of the Unit Gamma/Gompertz Distribution. Mathematics 2021, 9, 1850. [Google Scholar]
- Gómez, M.Y.; Bolfarine, H.; Gómez, H.W. Gumbel distribution with heavy tails and applications to environmental data. Math. Comput. Simul. 2019, 157, 115–129. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdulkadirov, R.; Lyakhov, P.; Nagornov, N. Accelerating Extreme Search of Multidimensional Functions Based on Natural Gradient Descent with Dirichlet Distributions. Mathematics 2022, 10, 3556. https://doi.org/10.3390/math10193556
Abdulkadirov R, Lyakhov P, Nagornov N. Accelerating Extreme Search of Multidimensional Functions Based on Natural Gradient Descent with Dirichlet Distributions. Mathematics. 2022; 10(19):3556. https://doi.org/10.3390/math10193556
Chicago/Turabian StyleAbdulkadirov, Ruslan, Pavel Lyakhov, and Nikolay Nagornov. 2022. "Accelerating Extreme Search of Multidimensional Functions Based on Natural Gradient Descent with Dirichlet Distributions" Mathematics 10, no. 19: 3556. https://doi.org/10.3390/math10193556