2. Related Work and Motivation
To achieve both simplicity and efficiency, most of the recent research in the field of NN compression have focused on post-training quantization, rather than on quantization-aware training [
5,
6]. The core idea of post-training quantization reflects on the compression of NN model weights after training the NN. Since the original NN parameters are typically stored in FP32 format, quantization can bring unique opportunities in implementing compressed NN models, as long as the quantized NN parameters have relatively close values as the original ones [
19]. Despite the high difference between the QNN model and the original one (NN before quantization), it has been shown in [
19] that the accuracy of the neural network can be slightly degraded after the quantization is performed. Admittedly, the accuracy gap between the full-precision NN and QNN can be still very large in some cases, with the apparent space for improvements, especially for the extremely low-bit QNNs [
6,
10,
17,
24,
25].
Generally, in low-bit quantization, a very small number of bits per sample is used to represent the data being quantized (less than or equal to 3 bit/sample) [
20]. Relying on plenty of quantization models from the signal processing area, quantization has proved to be an efficient technique that can perform signal compression according to some of the underlying criteria [
15,
21,
22,
23]. Many efforts in classical compression by means of quantization have been made towards the minimization of an inevitable quantization error for a given bit-rate. The main goal in compression is actually to minimize the bit-rate. However, in general, the smaller the bit-rate, the lower the storage cost and computation requirements, but the higher the quantization error [
20]. These conflicting requirements mean quantization is a very intriguing area of research, specifically the choice of the quantization model itself and specification of its key parameters (the support region, quantization steps, bit-rate, decision and representation levels [
15,
20,
21,
22,
23]) affect the amount of the total quantization error, that is, the total distortion. Following the main aspect of signal coding and compression, which is the bit-rate shrinkage, we can expect that for non-uniform sources, such as the Laplacian one assumed in this paper, non-uniform quantization allows better utilization of the available bit rate. Additional constraints, especially for low-bit conditions, include non-uniform quantizers that should be well suited to the lower design complexity and implementation requirements.
Unlike in our previous works, where we addressed low-bit uniform quantizer (UQ), two-bit and three-bit UQ [
18,
19], respectively, in this paper, we propose two novel non-uniform two-bit quantization models and we analyze QNN performance for the same classification task as the one reported in [
18,
19]. Our goal is to improve both the SQNR and the accuracy of the QNN model, compared to two-bit UQ from [
18]. In this research, we show that this goal is achievable by utilizing the novel NUQs that will be specified in detail in the following. Let us highlight that to provide a fair comparison with the results from [
18,
19], in this paper, the identical multilayer perceptron (MLP) architecture is assumed, while the identical weights (stored in FP32 format) are non-uniformly quantized according to completely novel quantization rules by also using only two bits per sample. Our motivation to address the two-bit NUQs stems from the fact that non-uniform quantizers are more convenient for non-uniform distributions, as the Laplacian pdf. Having in mind that the weights distribution can closely fit some of well-known probability density functions (pdfs), as the Laplacian pdf is [
7,
8,
12]; in this paper, as in [
18,
19], we assume the Laplacian-like distribution for experimental weights distribution and the Laplacian pdf for the theoretical distribution of weights, for estimating the performance of our two novel non-uniform quantizers in question. The main reason why we chose to utilize two-bit quantizers lies in an already confirmed premise for the two-bit UQ [
18], that quantizer parameterization has been shown to be crucial not only for the performance of the quantizer alone but also for the QNN model accuracy, due to only four representations being available. In brief, the performance gain over UQ is relatively easily achieved by means of high-bit non-uniform quantization [
22], where this is not a case with low-bit non-uniform quantization due to the small number of representations available. This makes low-bit non-uniform quantization, as the one addressed in this paper, more intriguing to research.
To alleviate the shortage of UQ applied to non-uniform distributions, reflected in uniform quantization of all weight values with most of them aggregated near the mean, in this paper, we specify the novel quantization rules for two-bit NUQs. More precisely, in our first novel NUQ, the quantization cell that lies inwardly closest to the mean, is of width Δ, while the width of subsequent cell, that lies in the rest of the support region is 2Δ, so that the quantizer’s support region ranges [−3Δ, 3Δ]. Hereinafter we utilize notations simplest power-of-two quantizer (SPTQ) for the first quantizer and modified simplest power-of-two quantizer (MSPTQ), as it is the modified and enhanced SPTQ version. Both aforementioned quantization models, SPTQ and MSPTQ, follow the same predefined rule for defining the support region ranging [−3Δ, 3Δ] or [−3Δ
mod, 3Δ
mod], respectively, while differing in the way of specifying the decision and representation levels of the quantizer. In SPTQ design, the representation levels are the midpoints of the quantization cells, as it is the case in the simplest UQ design, while its quantization cells are not of equal widths, as is the case with UQ. In MSPTQ design, the quantizer decision thresholds are centered between the nearest representation levels, similar to the UQ design. However, unlike UQ, the quantization cells of MSPTQ are not of equal widths and the representation levels are not midpoints of the quantization cells. More details about SPTQ and MSPTQ models will be provided in the following sections. Intending to determine the parameters of the novel quantizers more favorably and as precise as possible, we also provide a studious analysis and the description of the optimization procedure of two-bit SPTQ and MSPTQ. Specifically, we describe their design for the assumed Laplacian source and perform their optimization in an iterative manner, as well as by performing numerical optimization procedure. Afterwards, we perform post-training quantization with the implementation of SPTQ and MSPTQ, study the viability of QNN accuracy and present the benefits in the case where two-bit UQ from [
18] is utilized for the same classification task. We believe that both NUQs are particularly substantial for memory-constrained devices, where simple and acceptably accurate solutions are one of the key requirements.
The rest of this paper is organized as follows:
Section 3 and
Section 4 describe the design of symmetrical SPTQ and MSPTQ for the Laplacian source.
Section 5 briefly describes the application of novel NUQs in post-training quantization.
Section 6 provides the discussion on the numerical results for two novel NUQs specified in
Section 3 and
Section 4. Finally,
Section 7 summarizes the paper contributions and concludes our research results.
3. Symmetric SPTQ Design for the Laplacian Source
Quantization is ubiquitous in signal processing, and it specifies a mapping of continuous data to a discrete set of
N quantization or representation levels [
20]. The primary goal of quantization is to minimize the distortion, i.e., the deviation of the quantized signal (
QN(
X)), compared to the original (
X), for a given
N and bit-rate
R, where
R = log
2N [
20]
Specifically, the choice of the quantizer model itself and its parameterization affect the total amount of the quantization error. Therefore, in the following, we describe two novel NUQs and we specify the expressions to quantify their quantization error.
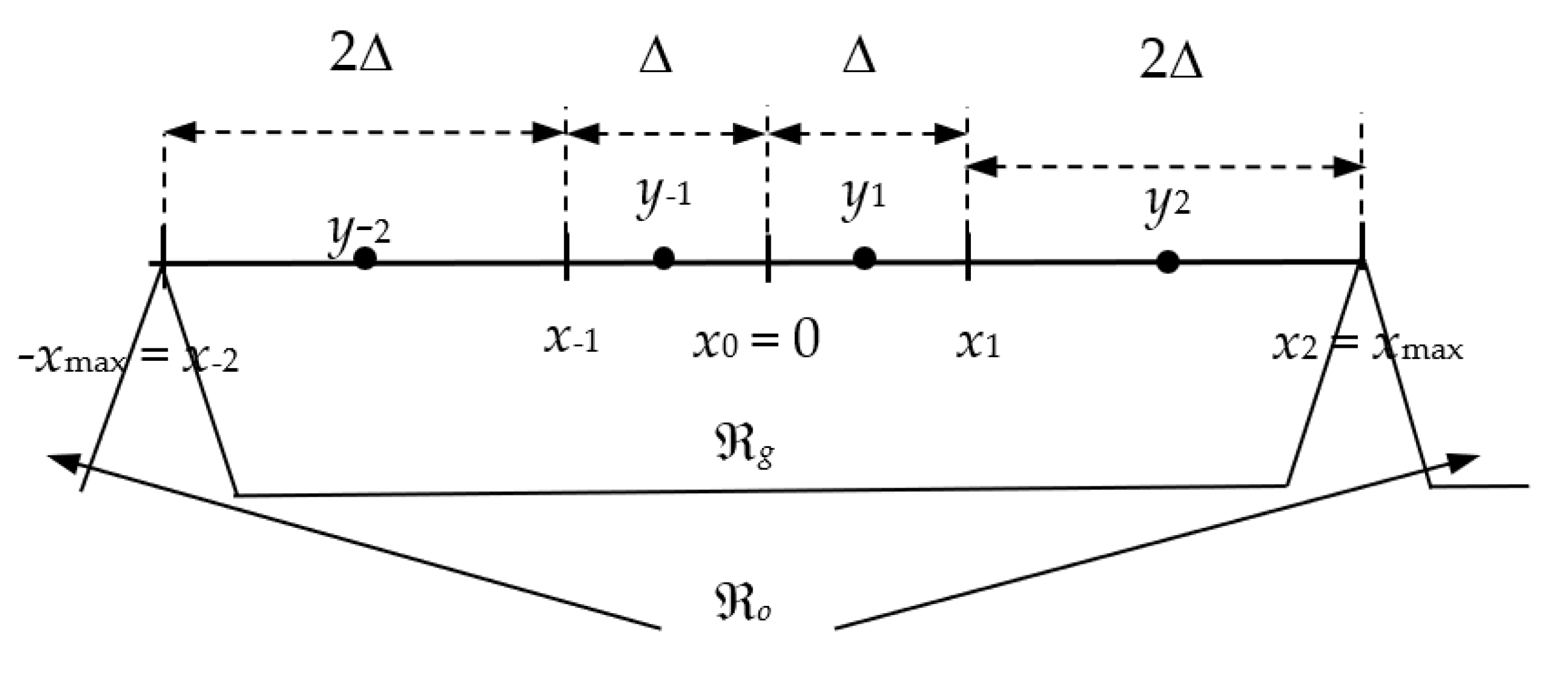
Let us first specify the key parameter of an
N-level symmetrical quantizer
QN. By the quantization procedure, an input signal amplitude range is divided into a granular region ℜ
g and an overload region ℜ
o (see
Figure 1 for SPTQ). For any symmetric quantizer, as those we design here, these regions are separated by the support region thresholds denoted by −
xmax and
xmax, respectively [
20]. The granular region ℜ
g
consists of
N nonoverlapped limited in width quantization cells, where the
ith cell is:
while
yi denotes the
ith representation level and
and
denote the granular cells from the negative and positive amplitude regions, which are symmetrically placed around the zero mean. In symmetric quantization, the quantizer’s main parameter sets are halved, since only the positive or the absolute values of the quantizer’s parameters should be determined and stored. The symmetry also holds for the overload cells, that is, for a pair of quantization cells unlimited in width in the overload region, ℜ
o, defined as
If the cells are of nonequal width, then the quantizer is non-uniform [
20], as is the case with the two-bit SPTQ we address here.
Let us denote with Δ the step size of the cells of our symmetrical two-bit SPTQ that are the closest ones to the mean (see
Figure 1). We further assume that the decision thresholds are not equidistant, as it is the case in UQ design. Specifically, suppose that the width of the adjacent cells is multiplied by two (observe only the positive half of the amplitude region and take into account that symmetry holds). As SPTQ is two-bit quantizer, from
for the quantization step size, we have
The decision thresholds of our two-bit SPTQ are specified by:
The code book of our two-bit SPTQ,
, contains
N = 4 representation levels
yi (see
Figure 1), specified as midpoints of cells by:
Recall that
xmax denotes the support region threshold of our two-bit SPTQ, and it is one of the key parameters of the quantizer. From Equations (5)–(8) one can conclude that
xmax or the step size, Δ, completely determine the decision thresholds,
xi, and the representation levels,
yi, of the proposed two-bit SPTQ. In other words, the quantizer in question is completely determined by knowing the support region threshold,
xmax =
xmaxSPTQ. Therefore, we introduce the following notation of our transfer characteristic of the symmetric two-bit SPTQ,
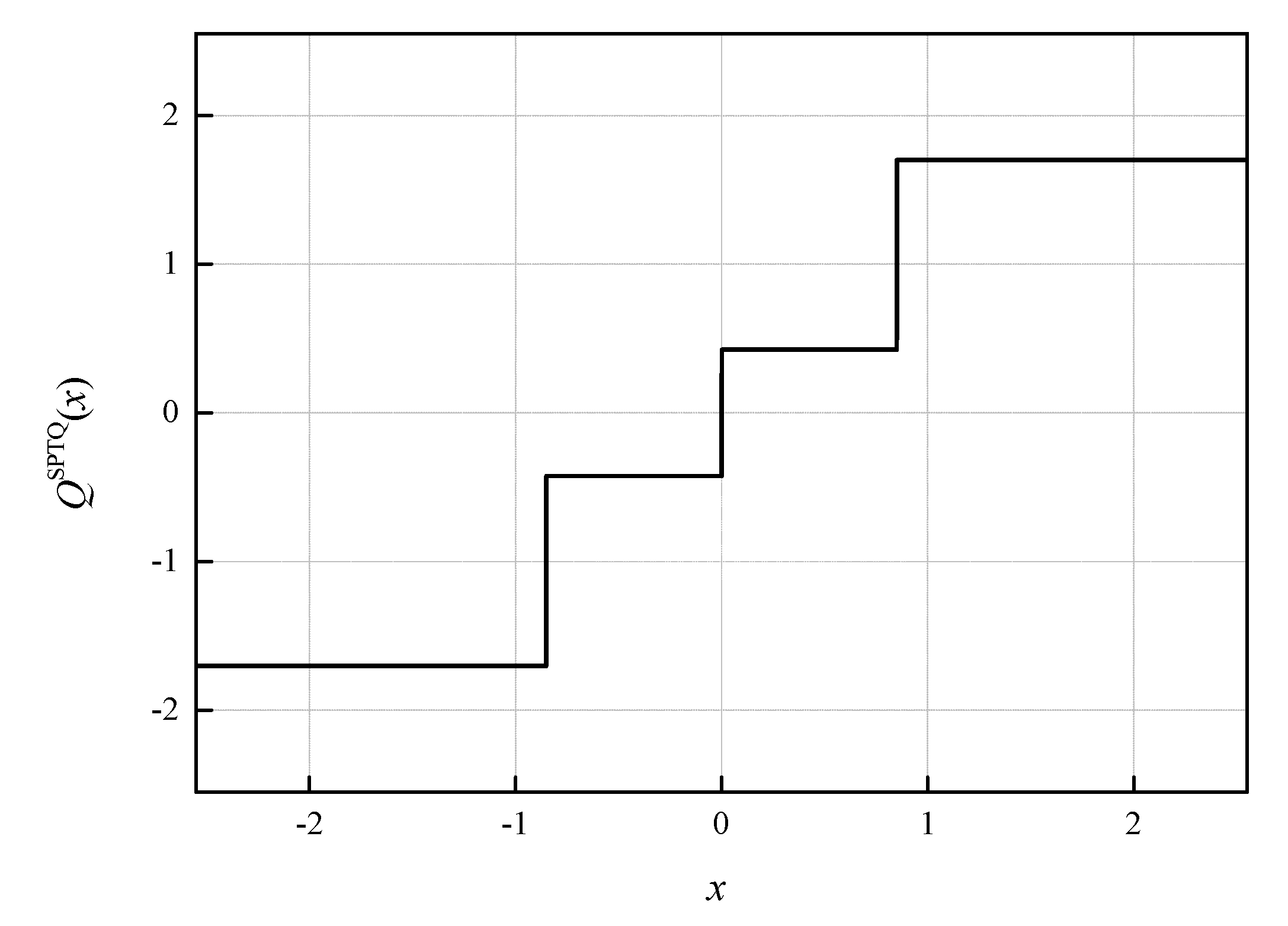
QSPTQ(
x;
xmax) (see
Figure 2, where the characteristic of the symmetric two-bit SPTQ is presented for
xmax = 2.5512, where the notation [J] comes from the name of the author of [
20]).
Let us highlight here that due to the symmetry of the unrestricted Laplacian pdf,
p(
x) of zero mean and variance
σ2 = 1
for which we intend to optimize the design of our SPTQ, the decision thresholds and representation levels of SPTQ are assumed to be symmetric in relation to the zero-mean value.
To determine the total distortion of our symmetrical two-bit SPTQ, composed of the granular and the overload distortion,
, we begin with the basic definition of distortion, given by Equation (1) [
20], where the granular distortion,
, and the overload distortion,
, for symmetric two-bit SPTQ in question are:
Foremost, to simplify our derivation, let us define that it holds
x3 = ∞, denoting the upper limit of the integral in Equation (11). Then, the total distortion of our symmetrical two-bit SPTQ can be rewritten as:
For the Laplacian pdf, specified in Equation (9), from Equation (12), we derive:
By further reorganizing Equation (13), we have:
Eventually, by substituting Equations (7) and (8) into Equation (14), we derive:
By minimizing distortion, that is, by setting the first derivative of so obtained distortion,
DSPTQ, with respect to Δ equal to zero:
we derive:
and we determine Δ iteratively from:
Taking a second derivative of
DSPTQ with respect to Δ yields:
It is trivial to conclude that for
and
it stands that
. We will now pay special attention to
, where we can expect the minimum of
. By further taking the derivative of expression (19) with respect to Δ and equating the result to zero.
we derive:
and we determine the roots of Equation (21) as
. As for
the inequality does not apply
, the minimal value of
is achieved for
and amounts to 0.263. Thus, we can conclude that
DSPTQ is a convex function of Δ. Moreover, to confirm that we end up iteratively with the unique optimal value for Δ in the numerical result section, we provide the results of numerical distortion optimization per Δ.
5. Application of Two Novel Non-Uniform Quantizers in Post-Training Quantization
The MNIST handwritten digits database [
26] was used in [
18,
19] for the experimental evaluation of the post-training low-bit UQ performance in weights compression of the three-layer fully connected (FC) NN model (shortly, our NN model). We chose to work with the MNIST dataset as it provides a large number of handwritten digit instances, which is a prerequisite for the highly accurate NNs. We consider that it is interesting to research whether with QNN this high accuracy can be preserved. More precisely, the MNIST dataset consists of 70,000 grayscale images, divided as 60,000 training images and 10,000 images in the test set [
26,
27], while these sets do not have overlapping instances. All the images used for training and testing the NN are previously standardized and normalized according to their mean value and standard deviation so the pixel values, ranging between 0 and 255, are mapped to a range between 0 and 1. Each image contains 28 × 28 pixels with a size-normalized digit or number (0–9). All digits are positioned in a fixed size with the intensity at the center.
Figure 4 illustrates the process of our experiments: MNIST training and testing datasets are loaded and then reshaped (flattened) into 1-dimensional vectors of 784 (28*28) elements. Each component of the vector is a binary value, which specifies the intensity of the pixel. Our NN model architecture is the same as those specified in [
18,
19] for comparison reasons and it consists of three FC (Dense) layers. First two FC layers consist of 512 nodes, where the first layer accepts an input shape of (784). These layers are called the hidden layers, as we do not directly consider their outputs. After both hidden layers ReLU activation function is applied. To reduce overfitting, we introduced dropout regularization that randomly sets outputs of 20% of the total nodes in the layer to zero. Output of the second hidden layer is fed to the output layer, which consists of ten neurons that determine the input digit in the range from 0 to 9. Since the output layer uses SoftMax as an activation function, it classifies the output digit according to the highest probability value of the SoftMax function at the output layer [
28].
Training and accuracy evaluation of our NN model is implemented in TensorFlow framework with Keras API, version 2.5.0 [
28]. Our MLP model consists of 669,706 trainable parameters, which are quantized by using the two-bit novel NUQs after training. Training is conducted in 10 epochs, with a batch size of 128, resulting in 469 iterations per epoch to complete the training over 60,000 training examples. The validation set accuracy after the training amounts to 0.981, meaning that the MLP model made accurate predictions for 98.1% of the images in the validation set. It is well-known that different sizes of the fully connected layers would result in different accuracies obtained. Although NN with a large number of layers and a lot of hidden neurons per layer can achieve better accuracy, smaller NNs run much faster. As already mentioned in this paper, we use the same three-layer FC MLP model as in [
18,
19]. Our goal is to test the performance of two novel NUQs in post-training quantization and to provide a fair comparison with the results from [
18,
19].
For the specified NN model, training, accuracy analysis and quantization have been implemented in Python programming language [
28]. In our QNN model, all trained weights have been quantized using one of the proposed novel NUQs (SPTQ or MSPTQ) and our QNN model’s accuracy, as well as SQNR, has been evaluated for compressed/quantized weights to represent post-training two-bit NUQ (SPTQ or MSPTQ) performance (see Algorithm 1). We can evaluate the experimental performance of SPTQ and MSPTQ by determining the distortion or SQNR, defined similarly as in [
19]:
where * refers to the application of SPTQ or MSPTQ.
Dex* and SQNR
ex* are experimentally determined distortion and SQNR,
Ŵ = {
wj}
j = 1, 2, …, W denotes the vector of weights represented in FP32 format and
Ŵ*= {
wj*}
j = 1, 2, …, W denotes the vector of weights to be loaded in QNN. In brief, at the very beginning of the post-training quantization, NN weights are normalized to zero mean and unit variance, forming the vector
ŴN= {
wjN}
j = 1, 2, …, W. After all normalized weights are quantized by applying SPTQ or MSPTQ and denormalized to the original range,
Ŵ* = {
wj*}
j = 1, 2, …, W is loaded into the QNN model (see Algorithm 1).
| Algorithm 1: Weights compression by means of post-training quantization using SPTQ/MSPTQ |
Notation: wj—pretrained weight, wjSPTQ—quantized weight using SPTQ, wjMSPTQ—quantized weight using MSPTQ
Input: Ŵ = {wj}j = 1, 2, …, W, weights represented in FP32 format, εmin = 10−4
Output: Quantized weights for SPTQ—ŴSPTQ = {wjSPTQ}j = 1, 2, …, W, Quantized weights for MSPTQ—ŴMSPTQ = {wjMSPTQ}j = 1, 2, …, W, , , , , AccuracySPTQ, AccuracyMSPTQ
Algorithm steps:
1: load initial pretrained and stored weights Ŵ = {wj}j = 1, 2, …, W
2: normalize weights and form ŴN = {wjN}j = 1, 2, …, W,
3: wmin← minimal value of the normalized weights from ŴN
4: wmax ← maximal value of the normalized weights from ŴN
5: select SPTQ model to quantize normalized weights
6: initialize εSPTQ ← 1, Δ(0) = ΔSPTQ ← 1 (or some other given value), i ← 1
7: while εSPTQ ≥ εmin do
8: calculate Δ(i + 1) by using (18)
9: calculate εSPTQ =abs (Δ(i + 1)-ΔSPTQ)
10: ΔSPTQ ← Δ(i + 1)
11: i ← i + 1
12: end while
13: Δ ← ΔSPTQ
14: xmaxSPTQ ← 3 Δ
15: calculate {x-2, x-1, x0, x1, x2} by using (7) for xmaxSPTQ
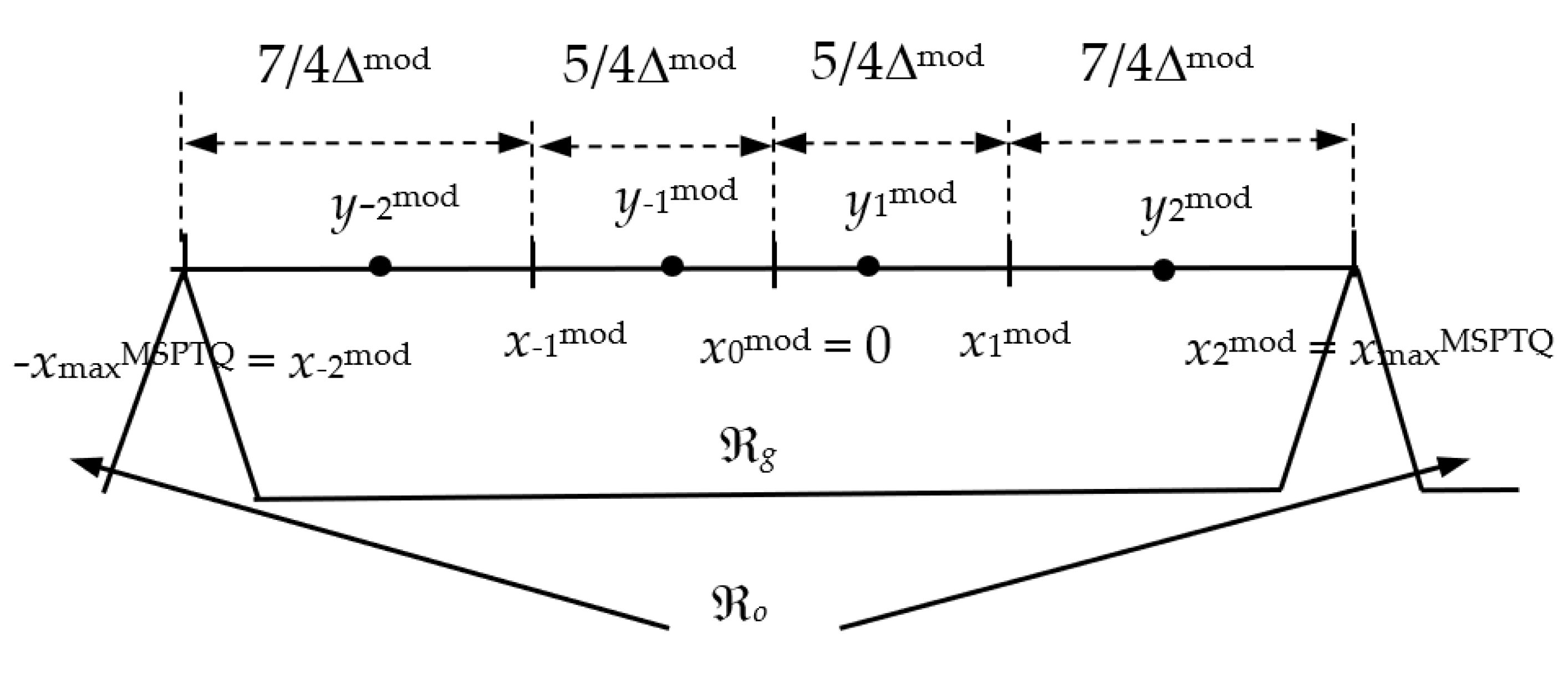
16: form codebook YSPTQ = {y-2, y-1, y1, y2} by using (8) or Table 1a)
17: quantize normalized weights by using codebook YSPTQ
18: denormalize quantized weights and form vector ŴSPTQ = {wjSPTQ}j = 1, 2, …, W
19: select MSPTQmodel to quantize normalized weights
20: initialize εMSPTQ ← 1, Δmod(0) = ΔMSPTQ ← ΔSPTQ, i ← 1
21: while εMSPTQ ≥ εmin do
22: calculate Δmod(i + 1) by using (28)
23: calculate εMSPTQ =abs (Δmod(i + 1)-ΔMSPTQ)
24: ΔMSPTQ ← Δmod(i + 1)
25: i ← i + 1
26: end while
27: Δmod ← ΔMSPTQ
28: xmaxMSPTQ ← 3 ΔMSPTQ
29: calculate {x-2mod, x-1mod, x0mod, x1mod, x2mod} by using Table 1b) for xmaxMSPTQ
30: form codebook YMSPTQ ≡ {y-2mod, y-1mod, y1mod, y2mod} by using Table 1b)
31: quantize normalized weights by using codebook YMSPTQ
32: denormalize quantized weights and form vector ŴMSPTQ = {wjMSPTQ}j = 1, 2, …, W
33: calculate , , , by using Equations (15), (25), (30)–(33), estimate accuracies of QNNs. |
Let us finally define the theoretical SQNR as:
which will also be calculated and compared with the experimentally determined SQNR. Recall that
DSPTQ and
DMSPTQ are specified by Equations (15) and (25), respectively.
Additional results are also provided in the paper for specified NN trained on the Fashion-MNIST dataset [
29]. Fashion-MNIST is a dataset comprising of 28 × 28 grayscale images of 70,000 fashion products from 10 categories, with 7000 images per category [
29]. The training set has 60,000 images and the test set has 10,000 images. Fashion-MNIST shares the same image size, data format and the structure of training and testing splits with the MNIST. It has been highlighted in [
30] that although Fashion-MNIST dataset poses a more challenging classification task, compared to MNIST dataset, the usage of MNIST dataset does not seem to be decreasing. Moreover, it has been pointed out at the fact that the reason MNIST dataset is still widely utilized comes from its size, allowing deep learning researchers to quickly check and prototype their algorithms.
The CNN model, also considered in the paper, consists of one convolutional layer, followed by ReLU activation, max pooling and flatten layer, whose output is fed to the previously described MLP with two hidden FC layers and the output layer. The images for MLP are being flattened into 1-dimensional vectors of 784 (28 × 28) elements to match the shape accepted by our first NN, while for a proper CNN input, one additional dimension is being added to represent the channel. Convolutional layer contains 16 filters with kernel size set to 3 × 3, while the max pooling layer utilizes a pooling window of size 2 × 2. The output of the pooling layer is further flattened into a one-dimensional vector for feeding it forward to the FC dense layer. The only difference between the previously described MLP and the dense layers utilized in CNN is in the dropout percentage, which is in the case of CNN set to 0.5, to further prevent overfitting of the FC layers. Therefore, the CNN model consists of three hidden layers and the output layer with the total of 1,652,906 trainable parameters. The training is performed for the Fashion-MNIST, in the same manner as for the MLP, with the total of 10 epochs, while the batch size is equal to 128 training samples.
6. Numerical Results and Analysis
Referencing Algorithm 1 for both previously described novel NUQs, we firstly analyze the number of necessary iterations for iterative determination of Δ and Δ
mod, or equally, for determining
xmaxSPTQ and
xmaxMSPTQ. To initialize Algorithm 1 for determining Δ, we use different values of Δ
(0), specified in
Table 2. To determine Δ
mod, we use the result of the first iterative process, that is, we assume Δ
mod(0) = Δ. The same condition as in [
22], that two adjacent iterations differ by less than 10
−4 is used as the output criterion of algorithm. By observing statistics of the trained and normalized NN weights, we have found that the minimum and maximum weights in original FP32 amount to
wmin = ™7.063787 and
wmax = 4.8371024. Following a predefined rule for specifying the support region of SPTQ ranging in [−3Δ, 3Δ], we use Δ
(0) = |
wmax|/3 = 1.61237 and Δ
(0) = |
wmin|/3 = 2.3546 to initialize Algorithm 1 for SPTQ. Moreover, we assume that Δ
(0) =
xmax[H]/3 = 0.6536 and Δ
(0) =
xmax[J]/3 = 0.7249, where
xmax[H] and
xmax[J] are optimal and asymptotically optimal
xmax values for UQ given by Hui [
23] and Jayant [
20] (see
Table 2). It is worthy highlighting that different initializations require around 40 iterations (see
Table 2 and
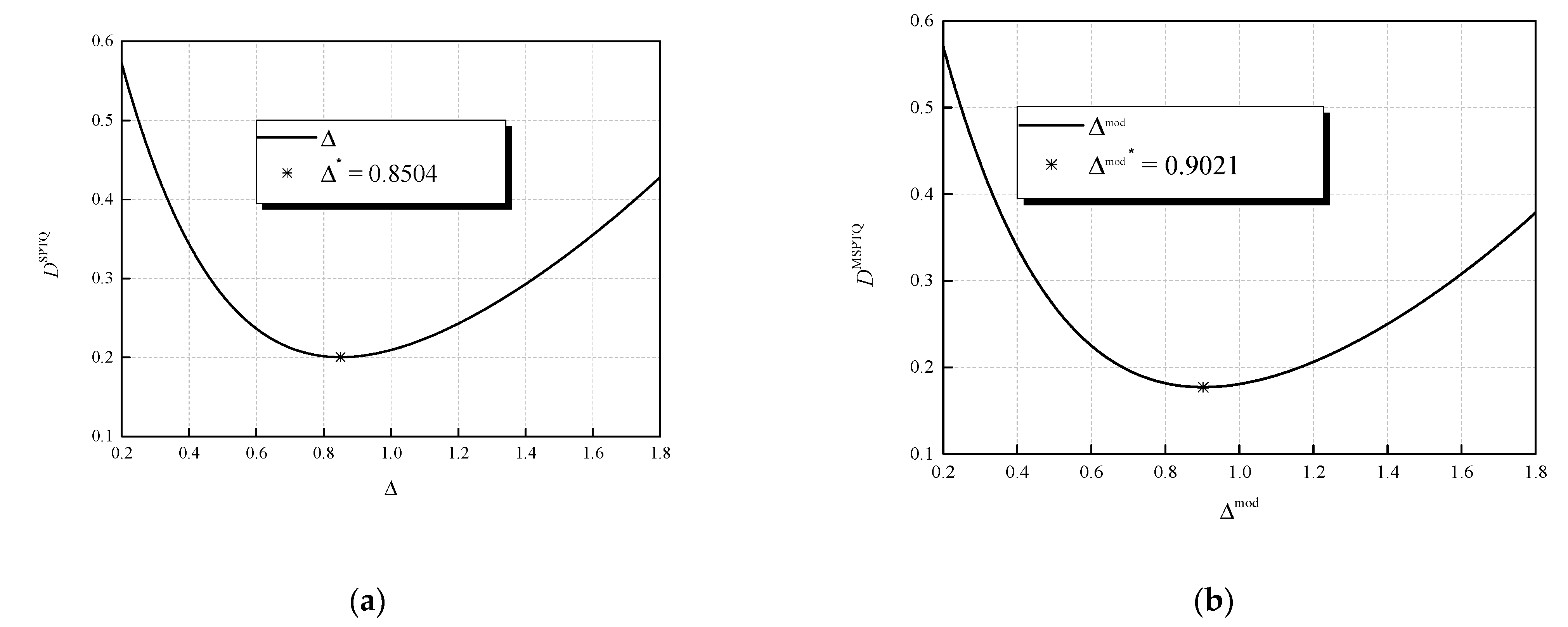
Figure 5). Moreover, we should highlight that all the observed initializations lead to the unique final value of Δ (Δ = 0.8504) and
xmaxSPTQ = 3Δ = 2.5512. If we further use Δ
mod(0) = Δ = 0.8504 for iteratively determining Δ
mod, given the same output algorithm criterion, we only need seven iterations. As a result of the second iterative process, we determine Δ
mod = 0.9021, as well as
xmaxMSPTQ = 3Δ
mod = 2.7063. To additionally confirm that with the output criterion of Algorithm 1 we ended up with the optimal values for Δ and Δ
mod; one can observe in
Figure 6, the depiction of the dependences of the distortion of the applied quantizers on the corresponding basic step sizes. Iteratively obtained values for Δ and Δ
mod are marked with asterisks in
Figure 6 and are indeed optimal as they give the minimum of
DSPTQ and
DMSPTQ.
Further in this section, we present experimentally obtained results of applying both SPTQ and MSPTQ in post-training quantization of NN model’s weights. As mentioned, we utilize the same NN model as in [
18,
19] with the same weights stored in FP32 format. Therefore, by conducting experiments with the novel NUQs, we can fairly compare the performance with the case of applying two-bit UQ under the same circumstances. To analyze the performance of the proposed quantizers in NN quantization, we conduct experiments for multiple specific choices of the support region threshold of NUQs. These experiments aim to provide insights on the impact of different support region thresholds on both NUQs performance and QNN accuracy.
The support region in our Case 1 is defined as [−min(|
wmin|,|
wmax|), min(|
wmin|,|
wmax|)], which is in our experiment simply [−
wmax,
wmax]. Therefore, in Case 1, the support region depends on the maximum value of the normalized trained model weights in full precision, which for the observed trained weights (for MNIST dataset) amounts to
wmax = 4.8371024. By setting the support region of SPTQ and MSPTQ as stated, it includes 99.988% of all the normalized weights. One can notice from
Table 3 that thus defined Case 1 provides the highest QNN model’s accuracy of all the observed cases, amounting to 97.61% of correctly classified validation samples of MNIST dataset. By comparing it to the application of simple UQ, we can conclude that with the applied SPTQ, we provide an increase in the accuracy of 0.64% (see
Table 4). This represents a significant increase in accuracy, especially taking into account that the only difference is in the applied quantizers, while the same bit rate is assumed and we are very close to the full precision accuracy of the baseline NN. Similarly, the experimental and theoretically obtained SQNR of SPTQ is higher, compared to UQ, providing gain in SQNR of 1.8078 dB and 2.5078 dB, respectively. We can notice that theoretically determined SQNR has lower values than experimentally determined SQNR. As explained in [
18,
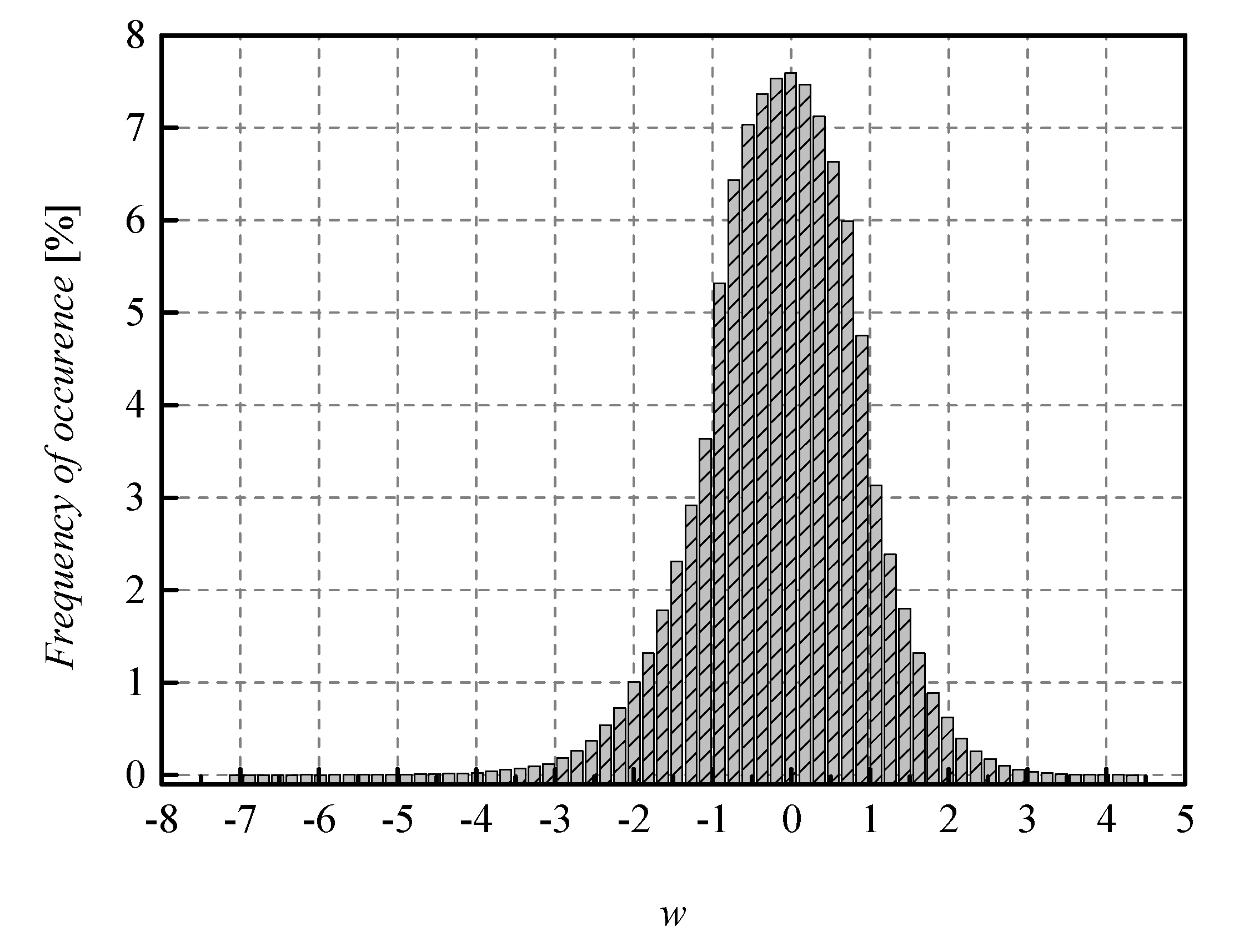
19], the reason is that in the experimental analysis, the weights originating from the Laplacian-like distribution being quantized are from the limited set of possible values [−7.063787, 4.8371024] (see
Figure 7), while in the theoretical analysis, the quantization of values from the unrestricted Laplacian source is assumed, causing an increase in the amount of distortion, that is, the decrease in the theoretical SQNR value. In summary, Case 1 already shows the benefits of implementing SPTQ over the UQ providing increase in all significant performance indicators observed.
In Case 2, the support region is [−max(|
wmin|, |
wmax|), max(|
wmin|, |
wmax|)], and it is defined as it is in [
31]. In our experiment, it can be expressed as [−|
wmin|, |
wmin|], which in practice becomes [
wmin, −
wmin], forming the support region (in case of MNIST dataset) as [−7.063787, 7.063787]. It can be observed that the support region in Case 2 includes 100% of the weights and even goes beyond the maximum value of the normalized weights, which makes it unnecessarily wide and representative of an unfavorable choice of ℜ
g.
Therefore, in this case we obtain the lowest observed SQNR value among all cases, while being significantly higher than the one obtained by UQ, which reaches negative values. Unlike the low SQNR value, the accuracy in Case 2 is very high with 97.42% achieved, especially taking into consideration that for UQ observed in the same case, the accuracy amounts to only 94.58%. This highlights the benefits of utilizing non-uniform quantization, which provides better QNN performance even in the case of choosing an overly wide support region.
In Case 3, the support region, ℜg, is determined for the iteratively calculated optimal quantization step, Δ = 0.8504. The support region threshold of SPTQ is defined as follows:
xmaxSPTQ = 3Δ, and xmaxSPTQ amounts to 2.5512. This value represents the theoretically optimal support region threshold value, therefore, providing the maximal theoretical SQNR value for this case. Although Case 3 yields the highest theoretical and higher experimental SQNR, compared to the previous cases, the QNN model’s accuracy is significantly lower. This further confirms the premise that the quantizer that provides the highest SQNR does not necessarily provide the highest accuracy of the QNN, which highly depends on the ℜg choice as well.
Cases 4 and 5 utilize well-known, optimal and asymptotically optimal support region thresholds from the literature, which are determined for UQ by Hui [
23] and Jayant [
20]. Although these values are not optimal for our SPTQ, we include them into our analysis to obtain a better insight on the influence of the ℜ
g choice to both SQNR and QNN performance. One can notice that although not optimal for SPTQ, support region thresholds specified in Cases 4 and 5 provide the highest experimental SQNR values, with theoretical SQNR being relatively close to the optimal value with the maximum difference from it of about 0.4 dB. Unlike SQNR, in these two cases we obtain the lowest QNN model’s accuracy. The maximum accuracy difference in these two cases is about 4%, compared to the best performing Case 1, which represents a significant NN performance degradation. Lower accuracy is a direct result of overly narrow support region threshold, with 94.787% and 96.691% of the weights being within the ℜ
g for the Cases 4 and 5, respectively.
By analyzing all the observed cases, one can conclude that ℜ
g has a very strong influence on the QNN accuracy and obtained SQNR. Moreover, it has been shown that SPTQ performs much better than UQ for the case of using wider ℜ
g, which we intuitively expected, and it is generally known for non-uniform quantization [
20]. In contrast, it can be observed that the accuracy of the QNN with the application of UQ outperforms the QNN with SPTQ in Cases 3–5, with Case 3 being the most significant one, as it represents the optimal solution for the theoretical SQNR of the SPTQ. Based on the SQNR analysis of SPTQ, we can conclude that SPTQ designed in Case 3 could be greatly applicable in traditional quantization tasks. To overcome the mentioned imperfection of SPTQ in post-training quantization, in this paper, we have introduced a simple, yet efficient modification and optimization of the SPTQ, denoted by MSPTQ, which performance is presented and analyzed in the following.
As previously described, MSPTQ introduces a simple modification in specifying one decision threshold to improve the performance of SPTQ for the cases of narrower ℜ
g, including the one constructed with the optimal support region threshold value. The performances of the modified SPTQ and MSPTQ are presented in
Table 5 for slightly different Cases of the support region threshold, as previously defined Cases 4 and 5 are not relevant to the non-uniform quantization. Cases 1 to 3 are the same as in the previous analysis, so that we can conduct a direct comparison of performance. One can notice that MSPTQ outperforms both SPTQ and UQ in all the observed performance indicators for Cases 1 and 3, while QNN with the application of SPTQ obtains a higher accuracy with the margin of 0.44% for Case 2. Moreover, MSPTQ provides the gain in both theoretical and experimental SNQR values for all comparable cases over the QNN with the implementation of UQ. Case 2 is a specific one, being an example of an unfavorable choice of ℜ
g, and QNN with SPTQ performs better, compared to its modified counterpart. On the other hand, for carefully designed ℜ
g, by applying the modified SPTQ and MSPTQ, we obtain a significant increase in both SQNR and QNN accuracy, compared to the SPTQ. The gain in the accuracy is specifically large in Case 3, which utilizes the support region threshold, optimally determined for SPTQ, and it amounts to 1.42%. For the ℜ
g specified in Case 3, MSPTQ obtains the highest experimental SQNR value, with an increase of 0.874 dB, compared to SPTQ and 0.4514 dB, in comparison to UQ. Case 4 implements the numerically optimized ℜ
g width for the MSPTQ, with the support region threshold value being close to the one obtained for SPTQ. Expectedly, theoretically obtained SQNR is highest for this case, while experimentally obtained SQNR, as well as the accuracy, take the second highest value among all the cases by having 99.001% of the normalized weights within the ℜ
g. As the degradation of the accuracy in Case 4 amounts to about 0.9%, compared to the full precession case (98.1% − 97.23% = 0.87%), we can conclude that with the simple modification we have managed not only to improve SQNR, but also to increase the accuracy of the QNN, compared to the case where UQ and SPTQ are implemented.
We can additionally compare our results with the ones from [
16]. In particular, in [
16], 2-bit logarithmic quantization of neural network weights has been addressed, where MLP (multilayer perceptron) has also been trained for the MNIST dataset. Specifically, paper [
16] addressed a two-bit
μ-law logarithmic quantizer, parameterized to achieve increased robustness, which is particularly important for the variance-mismatched scenario, where the designed for and applied to variance of data being quantized do not match. However, by performing normalization, which is commonly applied in NNs, this problem reduces to optimization of the quantizer models, typically for the zero mean and unit variance, as with the ones we address in this paper. Although the robustness of the logarithmic quantizer has been recognized as the main advantage, it has been shown in [
16] that the higher robustness causes the lower SQNR, compared to the uniform quantizer in the zero mean and unit variance case (see Figure 13 from [
16] for
σ =
σref, that is, for 20 log10(
σ/
σref) = 0). In [
16], SQNR was calculated for different representative values of parameter,
μ, in wide dynamic range of variances. By comparing achieved SQNR values from Table I given in [
16] (SQNR = 4.44 dB for
μ =255) and SQNR values from our
Table 3 and
Table 5 (SQNR = 7.8099 dB for SPTQ Case 3 and SQNR = 8.5608 dB for MSPTQ Case 4), we can conclude that with SPTQ and MSPTQ, we have achieved higher SQNR values, compared to
μ-law logarithmic quantizer from [
16]. This confirms that the advantages of the logarithmic quantizer do not come to the forefront in the case of lower bit rates.
In [
32], ternary uniform quantization is considered, where binary coding is used, which we also used in this paper, while in [
33], ternary coding is applied. Unlike our previous research [
18], in which the design of UQ is optimized for the Laplacian pdf of zero mean and unit variance; in [
32], the support region threshold of the ternary quantizer is not optimized. However, by introducing the scale factor,
α, in [
33], a kind of optimization of the considered ternary quantizer model is performed. In order to provide a fair comparison of our results with those from [
32] and [
33], we assume the same weights for quantization, the same NN, as well as the same support region threshold settings, as in the case of SPTQ and UQ given in
Table 3 and
Table 4, where we apply the ternary quantization from [
32]. Since the number of cells into which the support region is divided in the case of the ternary quantizer is smaller by one (
N = 3) than the case of dividing the same support region in the case of the two-bit UQ (
N = 2
2 = 4), our anticipation was that the ternary quantizer will provide a lower SQNR value, as well as a lower accuracy, compared to UQ, which the numerical results shown in
Table 6 confirm. Namely,
Table 6 shows the results of the application of ternary quantization to the NN weights of the considered previously trained MLP, where part of the results, shown in part (a) assumes the same support region, as in the case of optimal UQ (Case 5), asymptotically optimal UQ (Case 4) and optimal SPTQ (Case 3), while part (b) illustrates the importance of choosing the value of the scale factor,
α, which serves to scale the entire model of the ternary quantizer with the aim to perform its adaptation. In [
20], the optimal support region threshold value for the ternary quantizer is given, which for the assumed Laplace pdf is 3/sqrt(2). By setting
α = 1, we indeed determined the highest theoretical value of SQNR for the ternary quantizer. However, as it has been shown in [
18], the highest SQNR does not always guarantee the highest accuracy; we have varied the value of the scale factor from 1/4 to 7/4 with steps of 1/4, and we have ended up with the conclusion that, for the observed values of α, the highest accuracy is achieved for α = 3/2, providing the accuracy of the observed QNN that amounts to 97.51%. In short, both of our new models of non-uniform quantizers (SPTQ and MSPTQ) have superior performance (higher SQNR and accuracy), compared to the quantizer models from [
32] and [
33], which is not only a consequence of the fact that the number of cells in our quantizers is greater by one but also that with the wise distribution of the cell width, as well as the optimization of the support region threshold, we really provided significant step forward in the field of quantization.
Table 7 provides additional results for specified NNs trained on the Fashion-MNIST dataset, for the case of applying the proposed two novel NUQs (SPTQ and MSPTQ). As our MLP model achieves the accuracy of 88.96% on the Fashion-MNIST validation set, obtained after 10 epochs of training, we can conclude that similar to the case of the MNIST dataset, with the application of MSPTQ, we have managed to achieve closer to the accuracy obtained in the full precession case. Moreover, we have managed to preserve the original accuracy to a great extent. In addition, as with the results discussed for MNIST dataset, in quantization of weights of MLP trained on Fashion-MNIST dataset, we have ascertained that the theoretically and experimentally obtained SQNR values achieved with the application of MSPTQ are higher than ones obtained with the application of SPTQ.
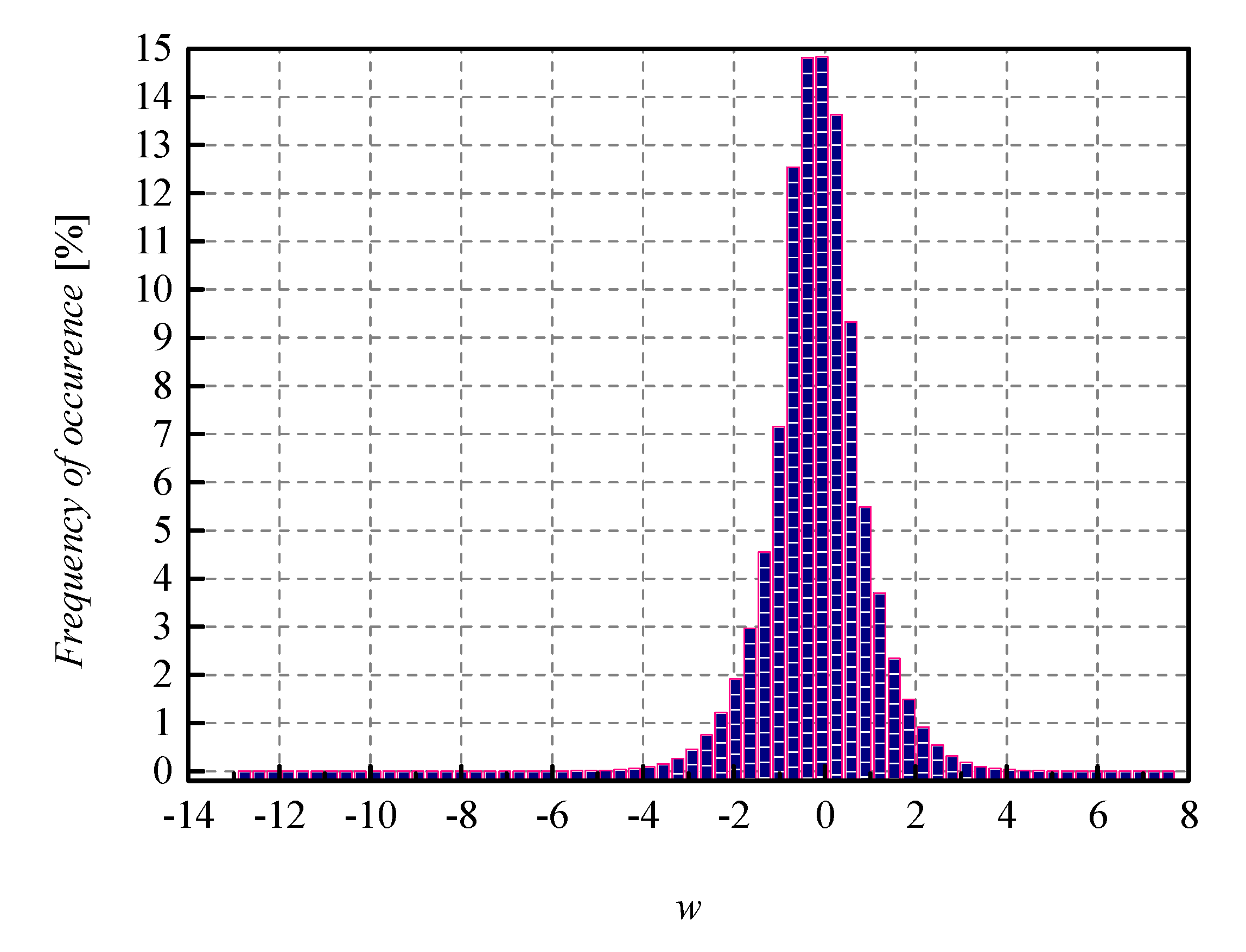
Compared to MLP, the CNN model achieves a higher accuracy of 91.53%, obtained on the Fashion-MNIST validation set, with weights also represented in FP32 format. Normalized histogram of weights that are being quantized for CNN trained on Fashion-MNIST dataset is shown in
Figure 8. It has been shown in [
19] that with the application of optimal three-bit UQ, the accuracy degradation of the quantized CNN model amounts to about 3.5% (91.53% − 87.97% = 3.56%). In the case of applying the two-bit UQ to the same weights of the CNN (trained on Fashion-MNIST), we have calculated an even higher accuracy degradation that amounts to about 9.5% (91.53% − 82.039% = 9.491%). As one can observe from
Table 7, for the two novel NUQs, we have ascertained the accuracy of 83.69% and 83.72%, respectively. In other words, we have again overperformed UQ in terms of accuracy, and the mentioned accuracy increased amounts to about 1.7%.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}