1. Introduction
Birnbaum and Saunders [
1,
2] developed an important two-parameter lifetime distribution for fatigue failure caused under dynamic load. The probability density function (pdf) of the Birnbaum–Saunders (BS) distribution is given by
where
,
,
is the pdf of the standard normal distribution,
is the shape parameter, and
is a scale parameter. We use the conventional notation to denote this distribution, that is,
. Extensions of the BS distribution have been studied for many authors, for example, [
3,
4,
5,
6,
7,
8,
9].
In addition to the work mentioned above, recent proposals were made by Balakrishnan and Kundu [
10], who made a detailed review of the developments that have taken place in relation to the BS distribution. In particular, the authors addressed different aspects, including interpretations, constructions, generalizations, inference processes, and extensions to multivariate cases, among others. The authors also presented some open problems that could be considered in future research. Furthermore, Athayde et al. [
11] studied the failure rate shape of the Birnbaum–Saunders-logistic distribution. In addition, the authors discussed and compared some robustness issues related to the Birnbaum–Saunders, Birnbaum–Saunders-logistic, and Birnbaum–Saunders-t distributions. On the other hand, Arrué et al. [
12] built an extension of the BS distribution from the skew-normal model and gained flexibility in skewness and kurtosis. The characterization of this new distribution was presented and they illustrated the usefulness of their proposal with a motivating example of fatigue life data.
A more recent extension of the BS distribution to the case of bimodal data was presented by Reyes et al. [
13]. This proposal has proven to be useful for the analysis of data from the environment and medical sciences, which demonstrates the wide field of applicability for this model in the different areas of knowledge by considering not only data from engineering, for example.
The BS distribution has also been extended to models suitable for fitting data in the interval
as rates, proportions, or indices. Mazucheli et al. [
14], for example, presented a type of BS distribution with support in the unit interval
, which is a new alternative to the beta and Kumaraswamy distributions. These authors have called it as unit-Birnbaum–Saunders (UBS) distribution. The UBS distribution is obtained from the transformation
, where
. The pdf of the UBS distribution is given by
where
,
is the shape parameter, and
is a scale parameter. The corresponding cumulative distribution function (cdf) is given by
where
is the cdf of the standard normal distribution. We use the notation
.
The BS distribution has also been used to define linear regression models, known as log-BS models. In this framework, it is assumed that
, where
, and the errors of the log-linear model follow the sinh-normal (SHN) distribution of Rieck and Nedelman [
15]. The pdf of the SHN distribution is given by
where
,
,
is the shape parameter,
is a location parameter, and
is a scale parameter. We use the notation
. Extensions of the SHN distribution are reported in Martínez-Flórez et al. [
8], Barros et al. [
16], Leiva et al. [
17], Lemonte [
18], and and Santana et al. [
19].
Extensions of the BS distribution to the bivariate setup were given by Kundu et al. [
20] and, for the multivariate case, Lemonte et al. [
21] introduced the multivariate skew-normal distribution. Likewise, for the log-BS regression model, Lemonte [
22] proposed the multivariate BS regression model, Kundu [
23] studied the bivariate SHN distribution, and Martínez-Flórez et al. [
24] considered the asymmetric multivariate BS regression model. In addition, Martínez-Flórez et al. [
25] proposed an exponentiated multivariate extension of the BS log-linear model, that is, an extension to the alpha-power family of distribution.
To study the relationship between variables when the dependent variable is observed in the unit interval, such as indices, rates, or proportions, the most widely known and used model is the beta regression model. Other authors developed works in this same direction using the beta distribution; see, for example, [
26,
27,
28,
29,
30,
31,
32]. On the other hand, situations in which the limits of the interval
are included in the support of the response variable have also been considered; see, for example, [
33,
34,
35,
36,
37].
The chief goal of this paper is to introduce a bivariate regression model to deal with response variables in the unit interval. To do so, we first introduce a bivariate probability distribution supported on the unit interval which arises from the bivariate SHN distribution. The article is organized as follows.
Section 2 presents the bivariate BS and SHN distributions. The bivariate UBS distribution is introduced in
Section 3, and some of its structural properties are also derived. The results of a simulation study and its respective discussion are presented in
Section 6. In
Section 4, we introduce the bivariate unit SHN distribution, and we derive some of its properties. The bivariate unit SHN regression model is introduced in
Section 5. Applications to real data are provided in
Section 7.
3. The Bivariate UBS Distribution
We now introduce the bivariate UBS distribution and study some of its properties and the process of estimating its parameters. The bivariate random vector
is said to have a bivariate UBS distribution with parameters
,
,
,
, and
if the joint cdf of
is given by
where
,
, and
Hence, the joint pdf of
which is obtained by deriving (
1) can be expressed as
where
For the joint pdf given in (
2), we use the notation
, where
is the correlation coefficient. The bivariate distribution
is obtained from the vector transformation
, where
From the previous definition, it follows that
with
where
denotes the bivariate standard normal distribution with correlation coefficient
. Therefore, for the marginal distributions, it follows that
and, hence, if
, then
We have the following theorem.
Theorem 1. Let . Hence:
- (i)
for
- (ii)
The cdf of , given , is - (iii)
The pdf of , given , is - (iv)
The joint survival function of is
Remark 1. We can generate random samples from the BVUBS distribution according to the algorithm described below:
- (i)
For , obtain following the described algorithm in Kundu et al. [20]. - (ii)
For each value of , compute Hence, .
Since the marginal
for
, the mean and variance of
are
The product moments of
, say,
, are complicated to obtain in closed-form expression and, hence, they have to be obtained from numerical calculations. However, for
, it follows that
We say that a function defined in
is totally positive of order 2 (abbreviated
) for
and
with
if
We have the following theorem.
Theorem 2. Let . For , we have that is .
Proof. The proof follows from the fact that for
it follows that
. Furthermore, let
and
be the joint pdfs of the BVBS and BVUBS distributions, respectively. Then,
. Since
is TP2, then for
and for
and
, we have that
and
. Note that
and, hence,
Therefore, for , is TP2. □
Parameter Estimation
Estimating the unknown parameters of a parametric model lies at the heart of distribution theory and its applications. In this section, the estimation of the BVUBS model parameters is investigated by the maximum likelihood (ML) method.
Let
be a sample of size
n from the
distribution. The log-likelihood function for the parameter vector
is given by
Since
, it follows that
where
We have that, given
and
, the ML estimators of
,
, and
become
where
,
, and
To estimate
and
, we consider the following profiled log-likelihood function
The ML estimates for
and
need to be obtained through a numerical maximization using optimization algorithms such as, for example, the Newton–Raphson iterative technique. The optimization algorithms require the specification of initial values to be used in the iterative scheme. Our suggestion is to use as initial guesses the estimates obtained from the modified moments of the marginal distributions of
for
, given that
. More details about these values, which are denoted by
, and
, can be found in Kundu et al. [
20].
Let
denote the ML estimator of
. For
, we have that
, where
is the Fisher information matrix, whose elements are the same as those given for the Fisher information matrix of the BVBS distribution provided in Kundu et al. [
20], just replacing
by
.
4. The Bivariate Unit SHN Distribution
The SHN distribution studied by Rieck and Nedelman [
15] is defined on the set of real numbers. Similarly, the bivariate SHN distributions of Kundu [
23] and Martínez-Flórez et al. [
24] are defined on
. Therefore, its application to sets of variables that are distributed between zero and one would not always be a convenient option.
We now introduce a bivariate distribution for rates or proportions as an alternative to bivariate datasets supported by the unit rectangle
. Since the SHN distribution is defined on the set of real numbers, to obtain an adequate transformation that allows us to define a random variable with a distribution in the unit interval
, we use the log-log complement transformation. We say that the variable
Y follows the unit SHN (USHN) distribution with parameters
if
Thus, the pdf of a random variable
Y with a USHN distribution is given by
with
where
is the shape parameter,
is a location parameter, and
is a scale parameter. We use the notation
.
The cdf of the random variable
takes the form
where
is the cdf of the
distribution. In addition, if
, then
Finally, the generation of a random variable with a distribution can be obtained from the previous expression.
Bivariate Extension
The bivariate USHN distribution can be directly obtained from the transformation
The bivariate vector
is said to have a bivariate USHN distribution with parameters
,
,
,
,
,
, and
if the joint cdf of
is given by
where
The joint pdf of
which follows from (
3) can be expressed as
where
The notation used is
, where
is the correlation coefficient. From the previous definition, it follows that
where
We have the following theorems.
Theorem 3. Let . Hence:
- (i)
for
- (ii)
The cdf of , given , is - (iii)
The pdf of , given , is - (iv)
The joint survival function of is
Theorem 4. If , then the conditional hazard function of , given , is a non-decreasing function of for all values of and ρ when and
Marshall [
38] defined the bivariate hazard rate of
and
as
Theorem 5. If , then:
- (i)
For fixed and , is a non-decreasing function of
- (ii)
For fixed and , is a non-decreasing function of
Remark 2. We can generate samples from the distribution according to the algorithm described below:
- (i)
For , generate according to the algorithm given by Kundu [23]; - (ii)
For each value of , compute Hence, .
5. Bivariate Unit SHN Regression Model
Suppose that
are
n independent bivariate vectors of proportions, where for each bivariate vector we assume that
where
is a
p-dimensional vector with values of the explanatory variables associated with the
j-th observable response
, such that
. In addition,
is a vector of size
p of unknown parameters for
. In other words, we assume that, for each
and
, the location parameter of the response variable
satisfies the functional relationship
which corresponds to the log-log complement link function.
Let be of size and be of size , where is the vec operator, and be a -vector of unknown parameters.
5.1. Parameter Estimation
The estimation of the parameter vector
of size
can be carried out by maximizing the log-likelihood function
where
with
We have that
for
and
. Thus,
For
,
, and
fixed, with
it follows that
and
Thus, to estimate
,
, and
, we use the profiled likelihood approach; that is, the estimates of these parameters are obtained by maximizing
regarding
,
, and
. This maximization procedure requires iterative numerical methods such as Newton–Raphson or quasi-Newton.
Denoting the estimators of , and by , and , respectively, then the estimators of ,and are given by , and , respectively. The elements of the Fisher information matrix can be obtained by calculating the second derivatives of the log-likelihood function regarding the parameters of the model and thus finding the expectation numerically.
5.2. Two-Step Estimation
From (
5), it follows that
for
and
; that is, the bivariate USHN regression model can be seen as
where
for
and
. Since
for
and
, we can use the two-step method presented in Kundu [
23] to estimate the parameters of the bivariate USHN regression model.
The two-step estimation method was provided by Joe [
39] and it is an interesting procedure because it reduces the dimension of the parameter space in each of its stages. In our case, the estimation of the parameters will be determined in two independent stages, where in the first stage, the estimates of the marginals of each variable under study will be obtained, that is,
will be estimated in the marginal distribution and, in the second stage, the association parameter
will be estimated. The ML estimators obtained by the two-stage procedure are consistent and the variance-covariance matrix is obtained using the methodology presented in Joe [
39].
Expressing the joint cdf of
and
in terms of the normal copula, we have that
where
denotes the Gaussian copula. In addition,
and
for
is the cdf of
. Then, let
be the pdf of the Gaussian copula. It follows that the log-likelihood function can be expressed as
where
is the pdf of
for
and
with
Then, to implement the algorithm in two stages, we initially estimate
, and
by maximizing
Setting
and
, the maximization of the previous function with respect to
can be obtained as
where
was defined before. Then, the estimates of
and
, say,
and
, can be obtained by maximizing
In a similar way, we estimate
, and
by maximizing
Finally, to estimate
, we maximize
where
and
, where
and
are the ML estimates of
,
, and
obtained in step 1. After intensive calculations, it is found that the ML estimator of
is given by
where
and
6. Simulation Study
This section presents the results of a simulation study carried out with the aim of studying the asymptotic behavior of the parameter estimators in the BVSHN regression model as well as in the proposed method. We considered the regression model given by
where
,
, and
. In this study, there were 5000 Monte Carlo samples of sizes
, and 1000 from the model given in (
6). The values of the covariate
x were generated independently from a uniform distribution
, and the following three scenarios for the parameter vector
were considered:
Scenario 1: , , , , , and .
Scenario 2: , , , , , and .
Scenario 3: , , , , , , and ; and , , , , , , and .
Maximum likelihood estimates were obtained using the maxLik function of the statistical software R Development Core Team [
40]. For the optimization of the log-likelihood function, iterative methods based on the Newton–Raphson algorithm were considered. To evaluate the performance of the estimators, the absolute value of the bias (AVB) and the root of the mean square error (RMSE) were considered, which are given by:
respectively, where
is the estimator of
for the
jth sample, for
.
To generate the random sample within the simulation process, we implemented Algorithm 1 based on the distribution function method. We initially defined:
n: the number of rows of the .
a random vector with a distribution.
a random variable with a standard normal distribution, in short.
a random variable with a standard normal distribution, in short.
a random variable with a uniform distribution, in short.
an auxiliary random variable.
an auxiliary random variable.
| Algorithm 1: Algorithm to generate a random sample from the regression model |
![Mathematics 10 03125 i001]() |
For
, we generated
according to the algorithm given by Kundu [
23]. For each value of
, we computed
Hence, .
The results of the simulation study are presented in
Table A1,
Table A2 and
Table A3 given in the
Appendix A. The
Figure 1 shows the behavior of the AVB and the RMSE for each of the parameter estimators for scenario 1, while the
Figure 2 does the same for scenario 2. It should be clarified that, for scenario 3, the respective graphs are not presented for reasons of space; however, these graphs can be constructed from
Table A3.
In the
Figure 1 (and in
Table A1), it can be seen that, in general, when the sample size increases, both the AVB and the RMSE of the MLE decrease and tend to zero. This behavior can be seen for all estimators of the components of the parameter vector
. In particular, for small sample sizes (
or 60), the estimators
and
present relatively high AVB and RMSE, compared to the other estimators; however, these quantities decrease considerably when
. In relation to the estimators of the coefficients,
and
for
; these present low AVB for small sample sizes and approach zero as
n increases. Something similar occurs with the RMSE of these estimators. Finally, the
estimator of
shows a stable behavior, with considerably low AVB and RMSE.
The above comments are generally equally valid for scenarios 2 and 3 and can be seen in
Table A2 and
Table A3, respectively. In particular, for simulation scenario 2, it can be better appreciated in the
Figure 2.
7. Real Data Applications
Proportion, rate, or indices data arise in different areas of knowledge such as economics, agriculture, medicine, engineering, and social sciences, among others. Some practical situations in these fields include, for example: the Human Development Index or the illiteracy rate in a given country, the proportion of diseased teeth (periodontal disease) in patients, the mortality rate due to traffic accidents, the proportion of deaths caused by smoking or other exposure factors, the proportion of non-compliant items on a production line, and the percentage of a family’s salary spent on entertainment, among others. In this section, the usefulness of the proposed models is presented. The BVUBS distribution and BVUBS regression models are fitted to real datasets.
7.1. First Application
In the first illustration, we consider a dataset obtained from [
41]. The data are related to the time in minutes
elapsed until a soccer team scores a first kick goal, while
records the time of the first goal scored by either of the two teams in dispute, either through a penalty kick, a free kick, or any other direct kick. To confirm that the observed data belong to the interval
, all the measurements were divided by the total time that a soccer game lasts, that is, 90 min. The interest in this case is therefore to model the proportion of time that any team and the home team score the first kick goal.
To fit these bivariate data, we consider the bivariate distributions: the BVBS, bivariate log-normal (BVLN), and BVUBS distributions. To compare these bivariate distributions, we consider the AIC and BIC, given by
where
k is the number of parameters and
means the maximum value of the log-likelihood function. For fitting the bivariate distributions, we use the maxLik function of R Development Core Team [
40] like in
Section 6.
The ML estimates (standard errors between parentheses) are presented in
Table 1.
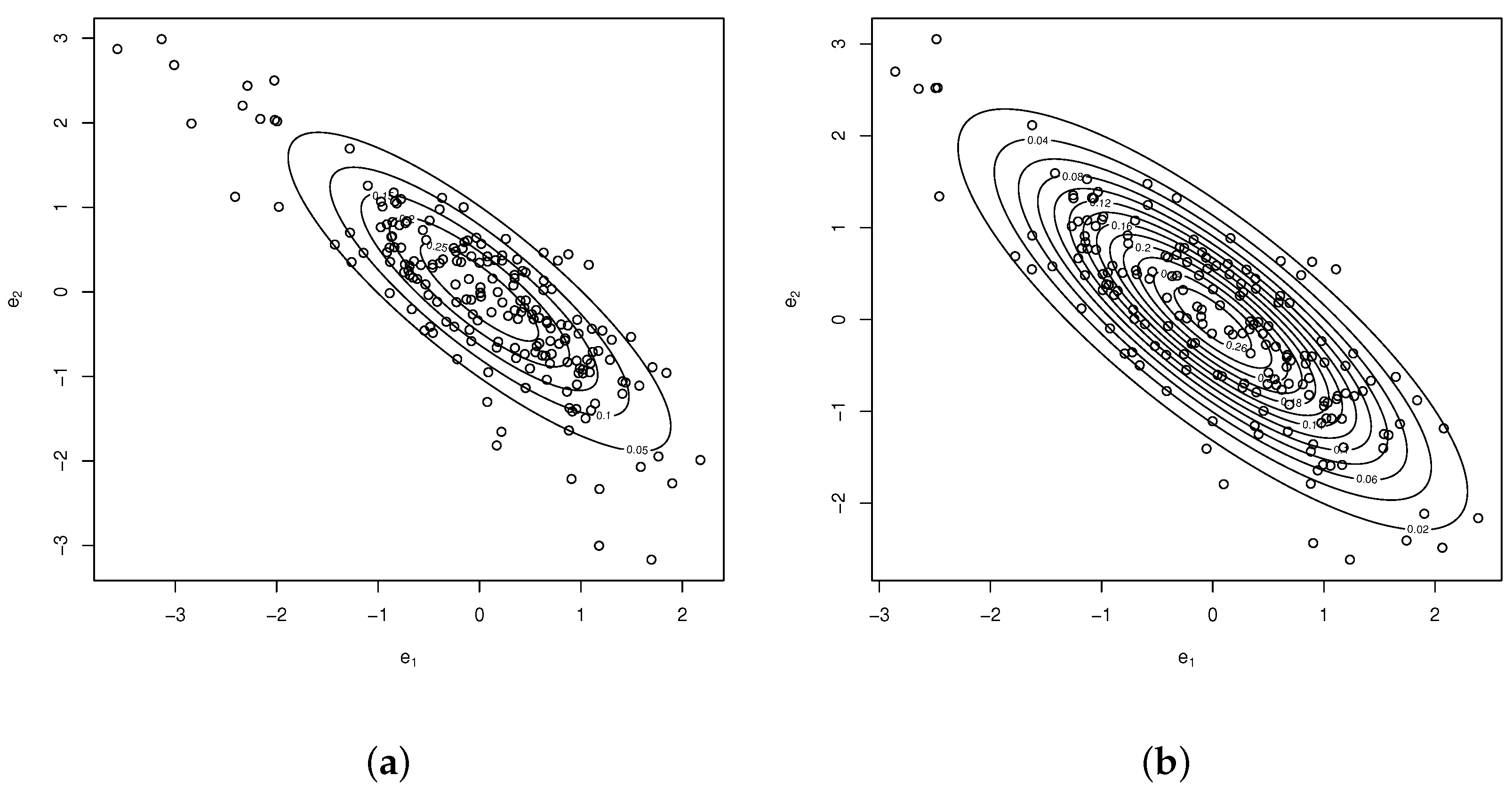
Therefore, according to the AIC and BIC values, the BVUBS distribution outperforms the other bivariate distributions and so should be preferable to fit these data. Contour plots for the BVLN, BVBS, and BVUBS distributions are presented in Figure
3.
7.2. Second Application
The interest in this application is to model the Human Development Index, denoted by
, and illiteracy rate,
, as functions of the natural logarithm of life expectancy measured in years (
, which is denoted by
) and the percentage of people with high poverty level (HPL, in this case denoted by
) by using the BVUSHN regression model. This dataset was taken from 195 districts in Peru and more details about this dataset can be found at
http://www.pe.undp.org.
The ML estimates (standard errors between parentheses) are given in
Table 2.
From the previous estimates, we compute
Therefore, we have that
The Shapiro–Wilk and Doornik–Hansen bivariate normality tests for the vector
return the values 0.97669 (
p-value
) and
(
p-value
), respectively; that is, the assumption of multivariate normality is rejected. The contour plot for the BN distribution is presented in Figure
4a. Calculating the Mahalanobis distance, we find that the observations {11, 13, 14, 27, 142, 143, 192, 193, 195} are considered outliers. Eliminating this set of observations, we estimate the parameters of the model, obtaining now the ML estimates (standard errors between parentheses) presented in
Table 3.
The Shapiro–Wilk and Doornik–Hansen bivariate normality tests for the vector return the values 0.9914 (p-) and 3.9346 (p-), respectively; that is, the assumption of multivariate normality is not rejected.
8. Concluding Remarks
The statistical modeling of proportions, rates, or indices data is a very common activity in many areas of knowledge, such as medicine, economy, engineering, or social sciences. Although there are some proposals for modeling this type of data, in the statistical literature there are few alternatives capable of jointly modeling two or more variables of this type, even less so with the possibility of considering covariates to explain the variability of the responses.
In this work, from a transformation applied to a vector with a bivariate unit-Birnbaum–Saunders distribution, we have obtained a new bivariate distribution which is called the bivariate unit-sinh-normal (BVSHN) distribution. The new distribution is an absolutely continuous distribution and is useful for modeling data as described previously, that is, responses over the region
jointly. Based on the introduced proposal, the extension to the case of the regression model for bounded responses in
was proposed, which was called the BVUSHN regression model. In particular, for the introduced distribution, the joint probability density function and joint cumulative distribution were specified. Conditional distributions and the joint survival function were also presented. The estimation of the model parameters was carried out from a classical approach by using the maximum likelihood method together with the two-step method proposed by Joe [
39]. A Monte Carlo simulation study was also carried out to evaluate the benefits and limitations of the introduced proposals, yielding good asymptotic results for the parameter estimators.
The BVUSHN distribution and the BVUSHN regression model showed great flexibility in fitting data to , which is frequently encountered in many practical scenarios. The results obtained in the two applications showed better results than other existing methodologies in the literature, and therefore we conclude that our proposals are viable alternatives in the field of distribution theory and regression models.
Future works based on the results of this proposal could contemplate the extension to the case of more than two response variables and make inferences in the models considering a Bayesian perspective.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







