1. Introduction
To solve the optimal control problem of any safety-critical systems (e.g., autonomous vehicles, intelligent robots, etc.), safety should be the basic requirement. Failure to ensure the safety of such systems may result in serious consequences, such as casualties, environmental pollution, and equipment damage. The safety control design refers to the control strategy which satisfies the safety specification stipulated by the physical or environmental constraints of the system. The barrier function (BF) method [
1,
2] has been proved to be an effective method to realize the system safety constraints or state constraints, and have attracted a wide amount of attention in recent years. For the optimal control problem in the modern control domain, it usually relies on solving the complex Hamilton–Jacobi–Bellman (HJB) equation [
3,
4,
5]. However, there is no effective mathematical method to solve the HJB equation due to its own properties. When designing the controllers that are both safe and optimal, the proper combination of safety and performance goal is an issue worth studying.
It has been proved that the dynamic programming (DP) method is a feasible and effective method to solve the HJB equation and derive the optimal solution. However, as the dimension of the variables increases, the dynamic programming method suffers from the “dimension curse”. Adaptive dynamic programming (ADP) [
6,
7,
8,
9,
10] uses the function approximation, such as neural network (NN) approximation methods, to approximate the cost function in the HJB equation, which has been proved to be a valid method to solve the dimension curse of dynamic programming method. It is an emerging method combining the development of artificial intelligence and control field, and has become a hotspot of international optimization research in recent years [
11,
12,
13,
14,
15]. In [
11,
12,
13], the authors studied the optimal control problem with disturbance by using the reinforcement learning (RL) method. Aiming at the random differential equations systems with coexisting parametric uncertainties and severe nonlinearities, Zhang et al. [
14] studied the problem of event-triggered adaptive tracking control. Vamvoudakis et al. [
15] proposed an online continuous time learning algorithm based on policy iteration to learn the optimal control solutions of known nonlinear systems. In [
16,
17,
18], the robust control problem was transformed into the optimal control problem of the nominal system by selecting an appropriate utility function. On the other hand, game theory [
19,
20,
21,
22,
23,
24] has become a powerful tool to optimize the coordination and cooperation of multiple controllers, and has been proved in many practical control problems. In fact, many systems in the real world have the idea of the non-zero-sum (NZS) game, where each controller of the system tries to minimize its cost function. Many researchers translate the non-zero-sum game problem [
25,
26] into the problem of solving the coupled HJB equation, but it is still a great difficulty to solve the coupled HJB equation [
27,
28,
29]. The development of adaptive dynamic programming and game theory has prompted many scholars to conduct relevant research. For robust trajectory tracking multiple input control of uncertain nonlinear systems, Qin et al. [
28] proposed a new adaptive online learning method to learn the Nash equilibrium solution. Song et al. [
29] developed a non-strategic integral reinforcement learning (IRL) method to effectively solve the NZS game control problem with unknown system dynamics. Ming et al. [
30] proposed a single-network adaptive control method to obtain the optimal solution of NZS differential game for autonomous nonlinear systems. All of the above methods can effectively solve the NZS game optimal control problem. However, few studies have been done on the NZS game with disturbance and time-varying safety constraints. This prompted the author to study this problem.
For the safety constraints, the existing methods based on barrier function and adaptive dynamic programming have received a lot of attention in recent years. Marvi et al. [
31] proposed a barrier certified method to learn the safety optimal controller and ensure the operation of the safety-critical system within its safety zone while providing the optimal performance. By introducing the barrier function into utility function, Xu et al. [
32] augmented the penalty mechanism to the utility function, and solved the state constraints problem that was difficult to be dealt with by the traditional ADP method. Liu et al. [
33] proposed an adaptive control method to obtain the safety solution of nonlinear stochastic systems. In addition, the barrier function transformation method has proved that it is possible to transform the safety-critical system with safety constraints into a general system without constraints in different scenarios, such as zero-sum game [
34], non-zero-sum game [
35], tracking control [
36], and event-triggered control [
37]. However, without exception, the above results must satisfy the implicit assumption that the safety constraints are constant. In fact, the constant constraint is only a special case of time-varying constraints. In practical applications, the time-varying constraints also have a wide range of application scenarios, such as UAV or manipulator working in some more complex environments.
For the constrained optimal control problem with time-varying safety constraints and uncertain disturbances, the constrained Nash equilibrium solutions are obtained by introducing a novel barrier function transformation and constructing coupled HJB equations. The novelty of this paper is reflected in the following points:
(1). A novel barrier function transformation method is proposed by introducing a smooth safety boundary function and a barrier function with a single variable. Compared to previous works [
34,
35], the proposed method no longer strictly requires the time-invariance of safety constraints and can deal with both time-invariance and time-varying safety constraints.
(2). In order to obtain the constrained optimal Nash equilibrium solution of the multi-input barrier transformation system with uncertain disturbances, the reasonable performance index function and coupled HJB function are designed for the nominal system by introducing a disturbance-related term. It is proved that the obtained constrained Nash equilibrium solution can make the safety-critical system asymptotically stable under the uncertain disturbances and time-varying safety constraints.
(3). The single critical neural network is used to approximate the performance index function online to obtain the constrained control input. It is proved theoretically that the proposed barrier function transformation and neural network approximation method can make the system state and NN parameters uniformly ultimately bounded (UUB) under the condition of satisfying the time-varying safety constraints. In addition, two simulation examples also verify the feasibility and effectiveness of the proposed method.
The remainder of this article is organized as follows: Problem formulation and barrier transformation are given in
Section 2.
Section 3 employs the coupled Hamilton–Jacobi–Bellman equation to obtain the approximate optimal solution online.
Section 4 shows the efficiency of the proposed method by giving two simulation examples. Finally, conclusions are given in
Section 5.
2. Problem Formulation and Barrier Transformation
Consider the following nonlinear multi-input safety-critical system:
where
is the system state,
,
are the control inputs,
is the uncertain disturbance,
,
,
and
.
C indicates the set of acceptable system state, and
indicates the set of acceptable system inputs. It is supposed that
is Lipschitz continuous, and
. It is also assumed that the system (
1) is stabilizable. The uncertain disturbance term
d satisfies
, where
is a given function,
and
satisfy that
is a fixed function denoting the uncertainty.
Given the initial system state , the purpose of this article is to find the constrained control inputs to make the system state x converge to the ideal value under the impact of the uncertain disturbances and time-varying safety constraints.
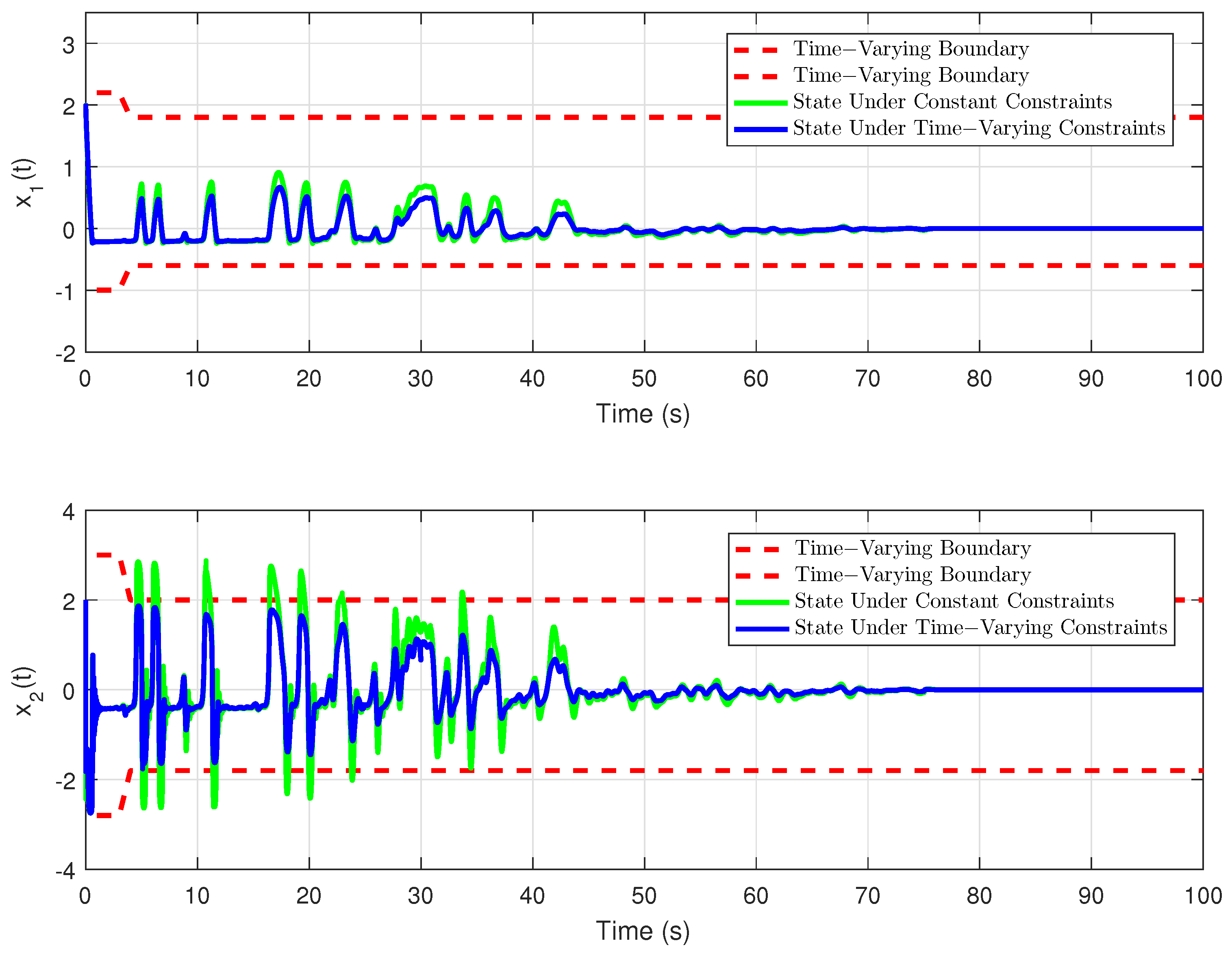
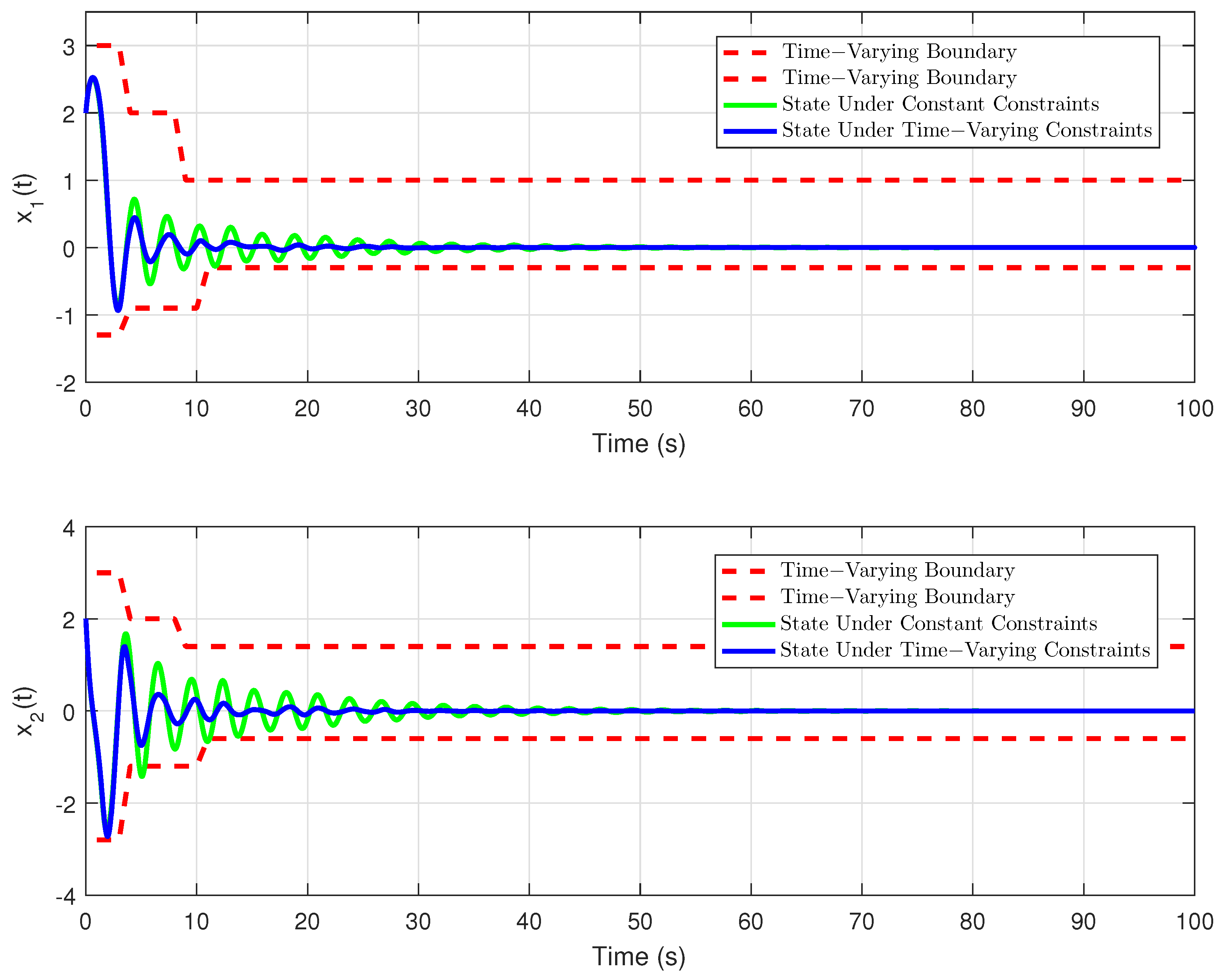
Remark 1. In some papers, for example [31,35], the system state is constrained by the constant, that is, , where represent the upper and lower bounds of system state. We consider a more complex and interesting case where the system safety constraints are time-varying and can be mathematically expressed as , where represent the bounded smooth time-varying functions. In order to satisfy the time-varying safety constraints, we define the following barrier function with a single independent variable
,
where
,
,
,
. The defined barrier function should satisfy the following assumption.
Assumption 1. The proposed barrier function has the following characteristics:
(1) , are two smooth functions and satisfy for any ;
(2) For any , the barrier function takes finite value when is satisfied;
(3) For any , as the function tends to the prescribed region , approaches infinity, i.e., ,
;
(4) For any , the barrier function also converges when the function converges.
It is worth noting that the constraints given by
can be many common trajectories, including sinusoidal waveforms, damping sinusoids, ramp, and so on. In our study, we will discuss a more useful form. We design the constraints
as the following smooth transformation functions, and satisfy the following conditions:
where
,
,
,
,
, and
,
. We can find many similar practical applications where the similar constraints are imposed (e.g., vehicle entering a narrow road from a wide road, drone entering a tunnel, robotic arm working in a narrow space, etc.).
Remark 2. A reasonable choice of parameters can be such that , when designing a smooth transformation function. In other words, the proposed method can also impose time-invariant safety constraints on the system state when some parameters are selected properly. In addition, according to the defined smooth transformation function, it can be extended to scenarios with more complex safety requirements, such as more frequent transformation of constraints and different types of constraints.
Considering the system (
1) with the uncertain disturbances and time-varying safety constraints, we use the proposed barrier function and smooth transformation function to convert the multi-input safety-critical system
x with the uncertain disturbances and time-varying safety constraints into the transformation system with uncertain disturbances only. We define
According to the chain rule and Equations (
6) and (7), the transformed system dynamics
can be defined as
where
Based on Formula (
8), the transformation system
⋯;
can be written as
where
⋯;
,
⋯;
,
⋯;
,
. For convenience, we use
d to represent
and use
s to represent
in the following description.
After the proposed barrier transformation, we have transformed the problem from the constrained optimal control problem for the safety-critical system (
1) with uncertain disturbances and time-varying safety constraints to the constrained optimal control problem for the transformation system (
9) with uncertain disturbances only. Before proceeding, we need to make the following proof about the transformation system (
9).
Theorem 1. Based on the proposed barrier transformation (6) and (7), the transformation system (9) obtained from the system (1) satisfies the following properties: (1) is Lipschitz with , and satisfies , where is a constant;
(2) , are bounded, and there exists constants , , makes , . The transformation system (9) has zero state observability. Proof of Theorem 1. (1) Based on Equation (
8), we can obtain
where
,
. Based on Assumption 1, we know that, as long as
, then the transformation system state
s is bounded, that is,
is bounded. We can derive
where
represents the upper bound of
. Based on the assumptions about the system (
1), we can obtain
where
,
is the Lipschitz constant of
. Based on the property of the barrier function, we can deduce that
and
are bounded as long as
. For any
, there is always a constant
that makes
. Considering the fact that
, we can deduce that
where
is the Lipschitz constant of
. Based on the Lipschitz condition [
38],
is Lipschitz continuous. Based on the boundedness of
and the assumptions about system (
1), we can obtain that every term in
is bounded with
. Therefore, we can say that
is also bounded, and there is a constant
such that
.
(2) Based on the boundedness of
and Equation (
8), we can obtain that
are bounded with
. Considering the fact that
, there are constants
and
, such that
,
. Given the initial system state
, the initial state of transformed system (
9) can be obtained from Equation (
6), which proves the zero state observability of transformed system (
9).
This completes the proof. □
Based on the transformation system, the nominal system of (
9) can be defined as
The performance index function related to the design of
can be defined as
where
are positive definite matrices,
,
represents the partial derivative of the performance index function
with respect to s,
is the nonquadratic penalty function of
,
is the nonquadratic penalty function of
,
represents the disturbance-related term.
The performance index function related to the design of
is defined as
where
are positive definite matrices,
,
represents the partial derivative of the performance index function
,
is the nonquadratic penalty function of
,
is the nonquadratic penalty function of
, and
represents the barrier-disturbance related term.
Definition 1. The control strategy set is a Nash equilibrium control strategy set ifhold for any admissible control policies and . Based on the performance index function (
15) and (
16), the Hamilton functions associated with the control input
and
are defined as
We define the optimal performance index functions of
,
as
Considering the nominal system (
14) and the Formulas (
15) and (
16), the constrained optimal control strategys
and
can be obtained according to the stationarity condition of optimization:
where
and
are obtained by solving the following coupled HJB equations:
Lemma 1. Assume that are the continuously differentiable function satisfying for all and , and there exist two bounded functions satisfying , and two control laws , such thatwhere , . Then, the transformation system (9) can achieve asymptotic stability under the control laws and . Proof of Lemma 1. We can use the chain rule to obtain
According to Formula (
26), we can obtain
for any
. We can derive that
is a Lyapunov function for the transformation system (
9), which proves that the transformation system can be asymptotic stability. As long as
satisfies the condition of Formula (
26), it is concluded that the control law
can realize the asymptotic stability of the transformation system. Similarly, we can prove that the control law
can realize the asymptotic stability of the transformation system. □
Lemma 2. Under Assumption 1, if the constrained optimal control problem of the transformation system (9) can be solved by the constrained optimal control laws , then the system (1) satisfies the time-varying safety constraints provided that the initial state of the system (1) satisfies time-varying safety constraints. Proof of Lemma 2. Based on Lemma 1, one can obtain
and
, such that
According to the properties of the barrier function in Assumption 1, we can derive that the performance index functions
and
are finite when the initial value
of the safety-critical system (
1) satisfies the time-varying safety constraints
, and
satisfies the condition of Formula (
26). That is, the performance index functions
and
are finite. Therefore, based on Assumption 1, we obtain
This proof is completed. □
According to Lemmas 1 and 2, the constrained optimal control laws (
22) and (23) can make the safety-critical system (
1) with the uncertain disturbances and time-varying safety constraints asymptotically stable based on the proposed barrier transformation and disturbance-related term. Based on (
22) and (23), we only need to use the proposed coupled HJB Equations (
24) and (25) to obtain the optimal performance index function, and then obtain the constrained optimal control solution. However, Equations (
24) and (25) are often difficult or impossible to solve due to their inherently nonlinear nature. In view of this problem, an approximate structure based on NN is proposed to learn the solutions of the coupled HJB equations online.
3. Approximate Optimal Solution of Coupled Hamilton–Jacobi–Bellman Equations
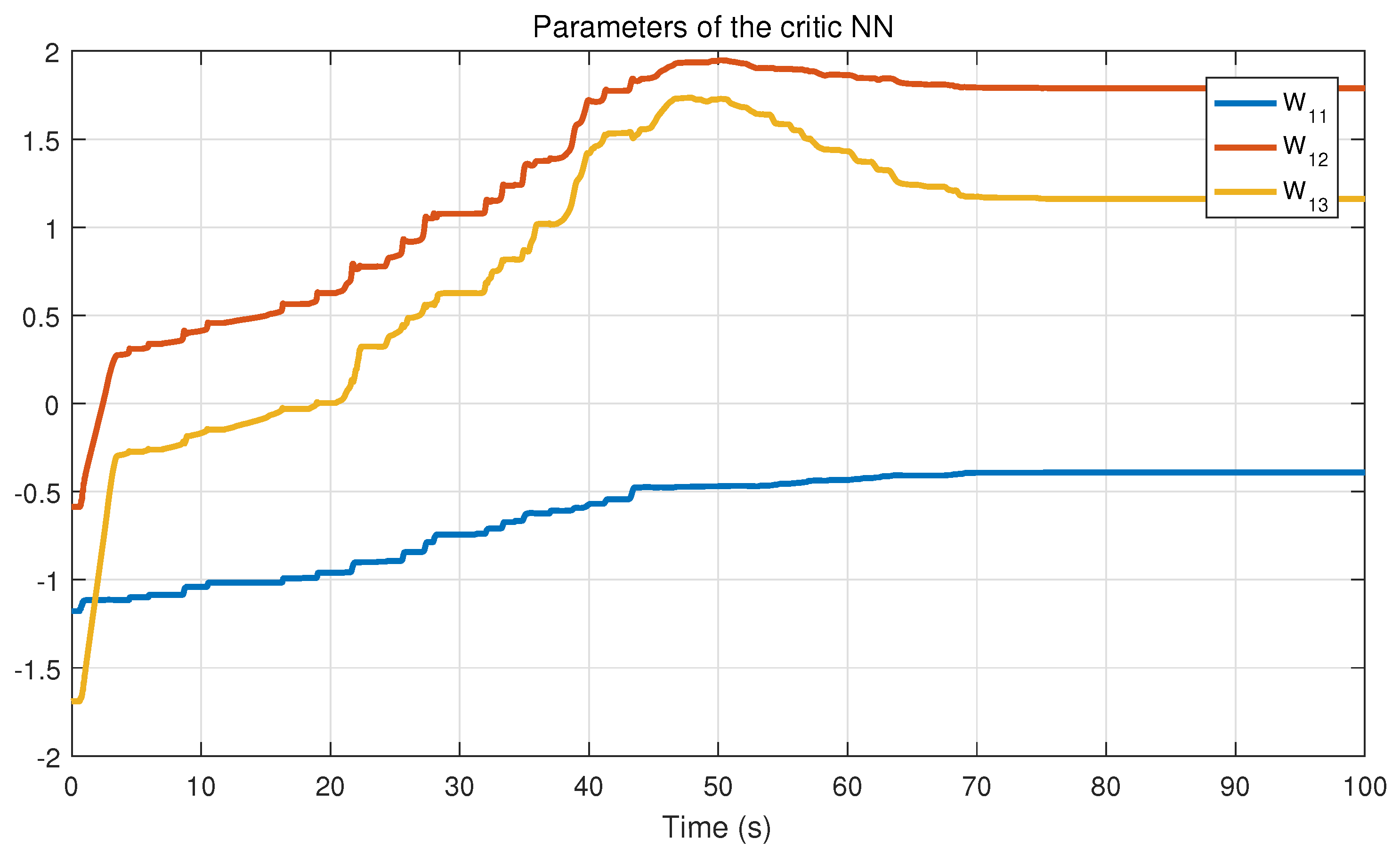
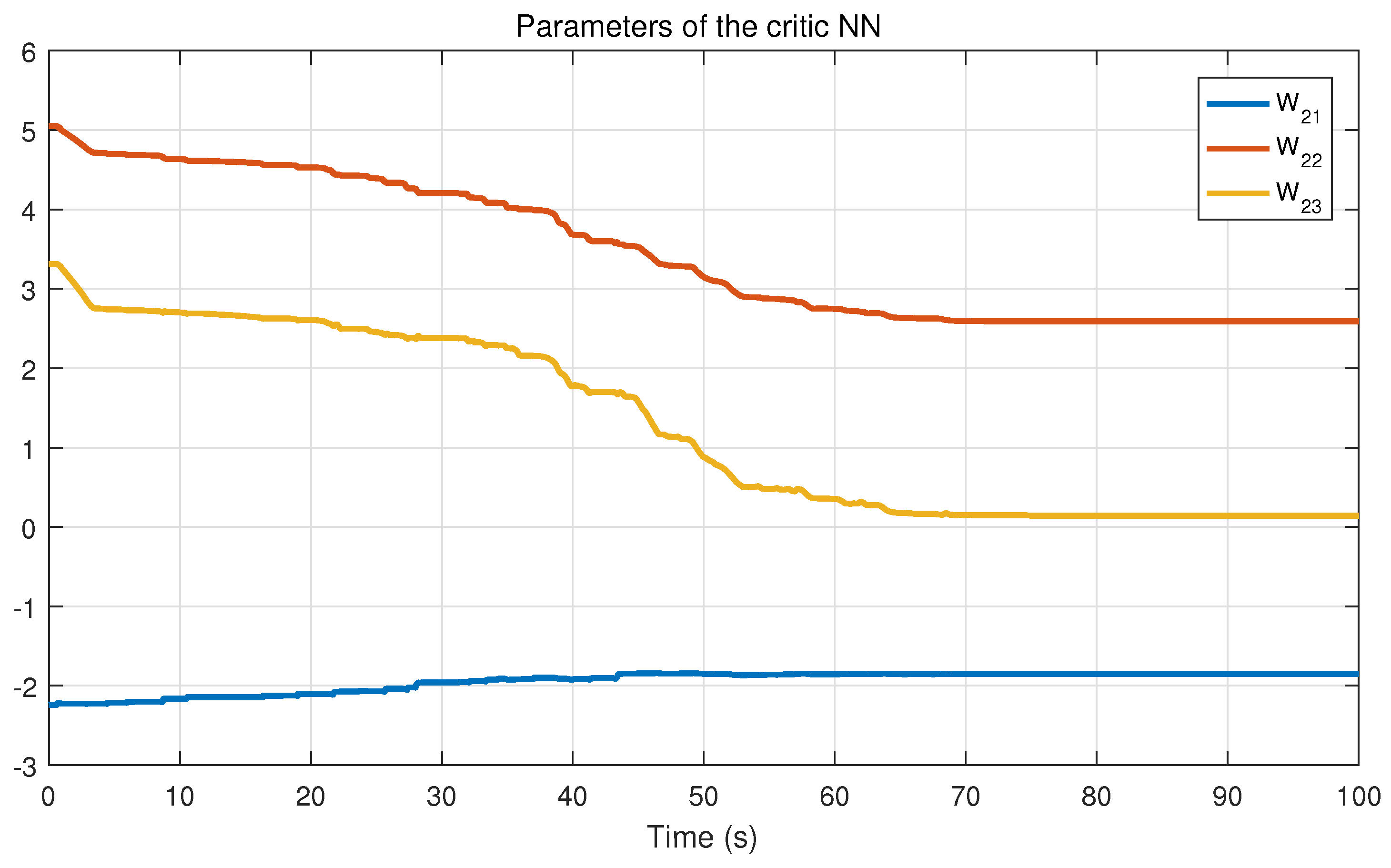
In this section, an online approximation method is proposed by constructing a single critic network. Based on the universal approximation property of NN, the optimal performance index functions (
20) and (21) and their partial derivatives can be approximated as follows:
where
represents the ideal weight,
represents the neural network activation function,
represents the partial derivative of
,
L represents the number of hidden layer neurons,
represents the NN approximation error, and
represents the partial derivative of
.
Assumption 2. It is assumed that the ideal weights are limited to constants, i.e., , and the neural network approximation residuals satisfy , , and the neural network activation functions satisfy , .
Based on Formula (
30), the Bellman approximation errors of the neural network approximation can be expressed as
Remark 3. The Bellman approximation errors and will be equal to 0 with the number of hidden neurons . When the number of L is a constant, the Bellman approximation errors is bounded, i.e., . In the later proof, we will consider the influence of Bellman approximation errors and .
Since the ideal weights
and
are unknown, we use the estimates of ideal weights to construct the critic neural network:
According to Formulas (
22), (23) and (
32), the approximate optimal control strategys are
Substituting (
32)–(34) into (
18) and (19), the approximate Hamiltonian function can be obtained
The estimates of ideal weights need to be adjusted so that
and
can minimize the squared residual error
. In general, the online adaptive learning algorithm usually requires a persistence excitation (PE) condition to achieve convergence. In order to satisfy this condition, we redefine the residual squared error as
, where
represent the past data with
. We choose the normalized gradient descent algorithm as the tuning laws of the estimates to minimize the residual squared error,
where
and
are learning rates that determine the convergence speed of the estimate,
,
,
,
,
,
, and
are all obtained by storing the past data.
The weight estimation errors
and
can be defined as
Based on (
37)–(
39), we have
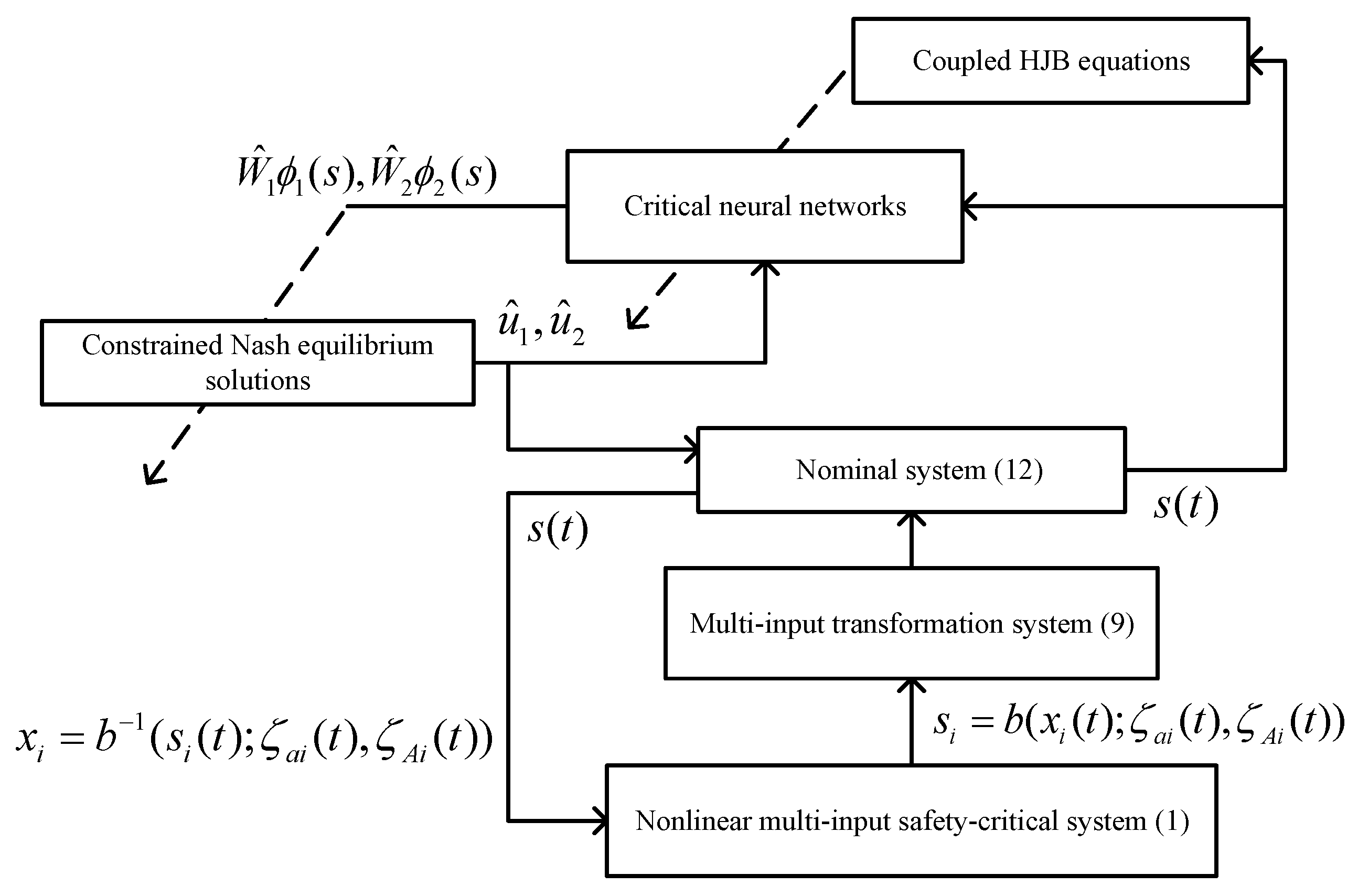
Combined with the previous content, the proposed multi-input safety-critical system structure diagram is shown in
Figure 1.
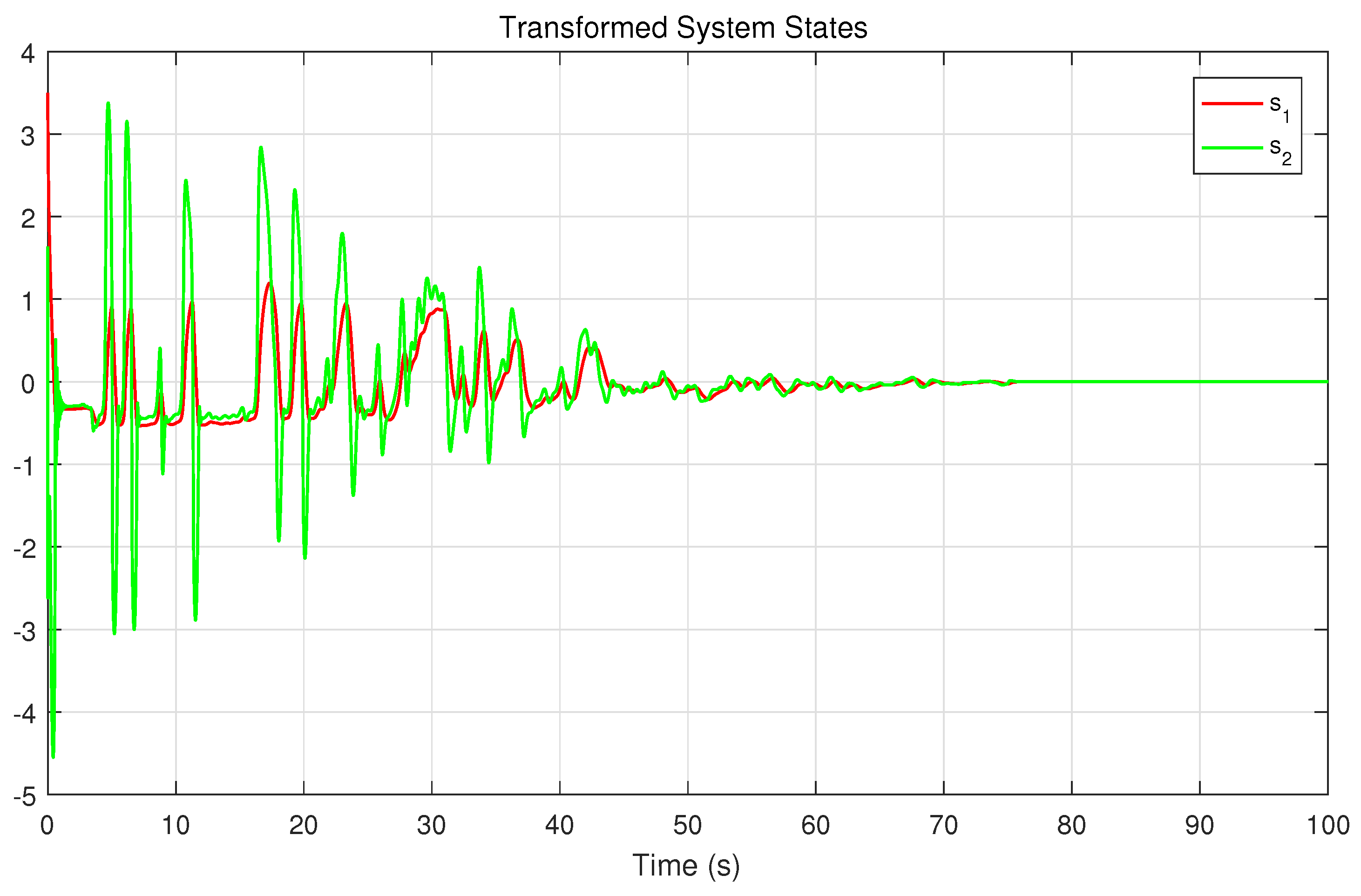
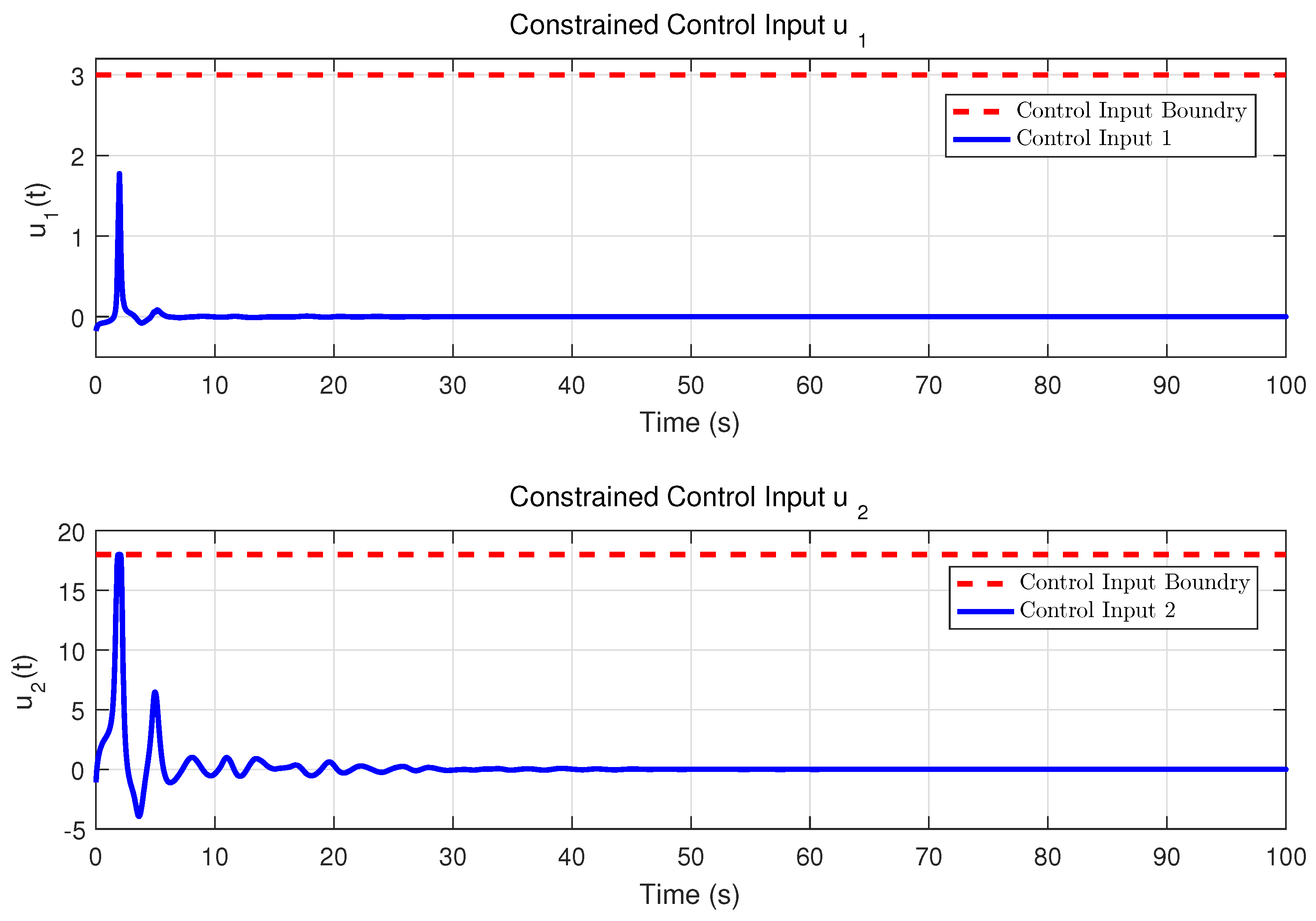
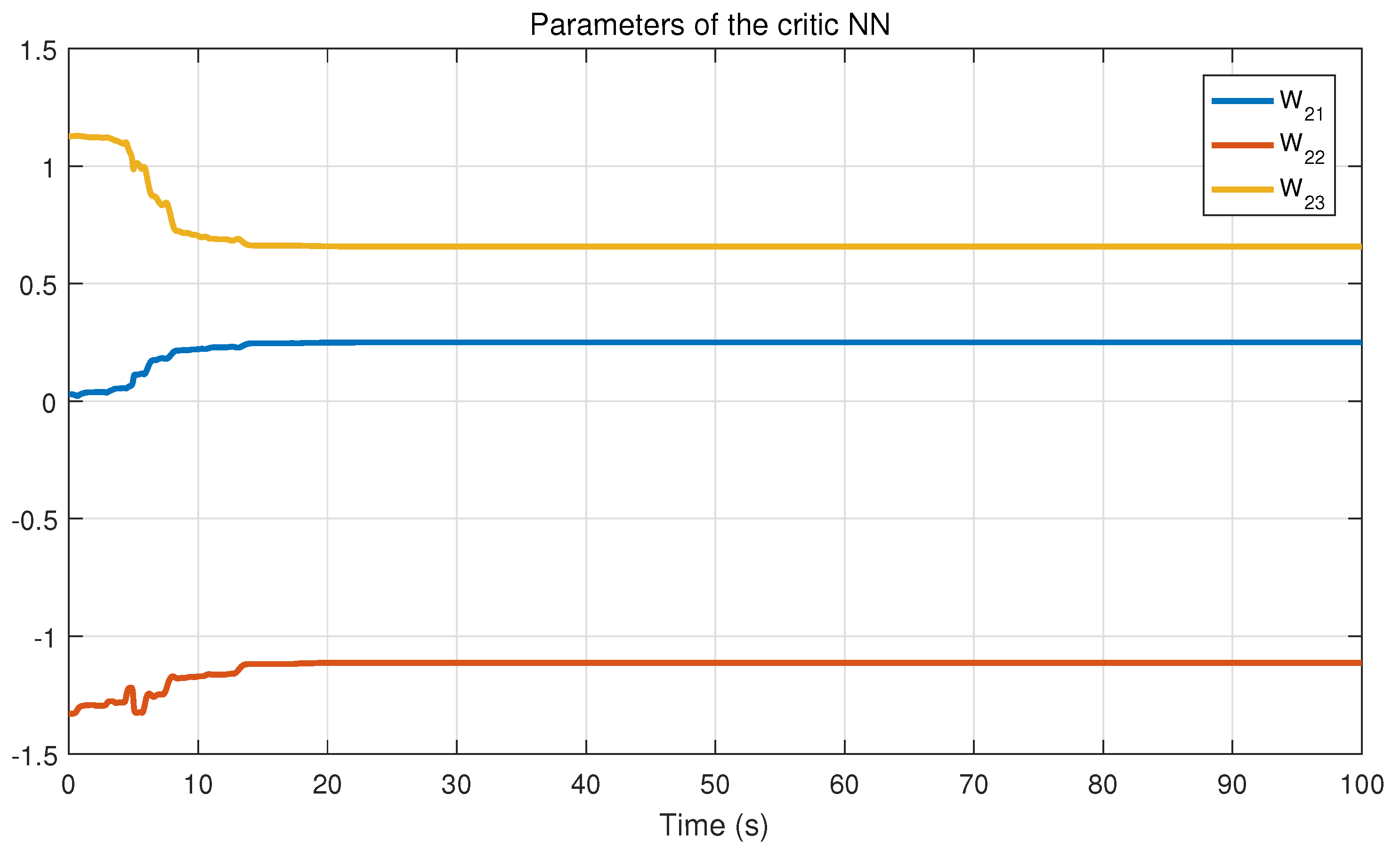
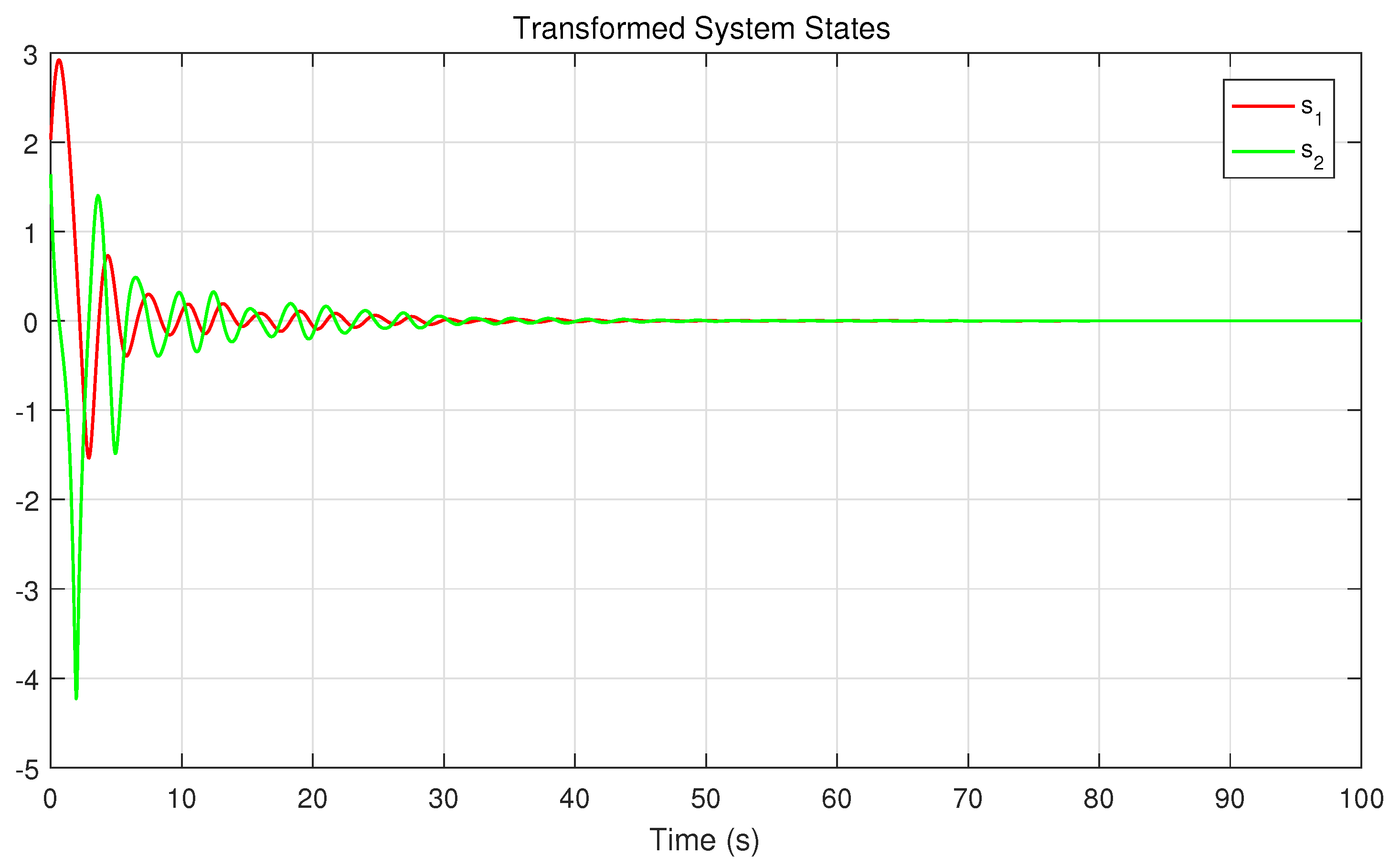
Theorem 2. Consider the system (9), the approximate optimal control strategy (33) and (34), and the weight tuning laws (37) and (38). Suppose that , , , , , , , are all uniformly bounded. Assume that the Assumptions 1 and 2 hold. Then, the system state s, the neural network weight errors , can be guaranteed to be UUB under the time-varying safety constraints and uncertain disturbances. Remark 4. According to the result of Theorem 2, we can obtain that the neural network weight errors are UUB. According to formulas (33), (34), and (39), we can easily derive that, as , , then the control input , . That is, the control strategy can be approximately optimal. Remark 5. Compared with [35], this work considers a more complex and interesting constrained control problem, that is, the safety constraints change with time. In addition, we establish the coupled HJB equation to obtain the constrained optimal solution, so that the system state can complete convergence under the condition that the time-varying constraints are satisfied. Remark 6. In [34,36], the safety optimal control problem with external disturbance is considered, and the control scheme based on barrier transformation is designed. However, all of the external disturbances mentioned are known. In this work, the safety control problem with uncertain disturbance is further studied, and it is proved that the system state can complete convergence under the proposed control strategy. 

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









