We illustrate the performance of the proposed methods with two data sets. The first one is related to the classification of Spanish wines according to its origin and year, and the second is related to the prediction of the presence of some spiders species from the environmental characteristics of a sample of sites.
5.1. Origin of Spanish Wines
Data for the example were taken from [
34]; 45 young red wines from appellations in Spain,
Ribera de Duero and
Toro, were analysed. Some chemical characteristics, as opposed to the common sensory analysis which is mostly subjective, were used for the characterization of the wines. The variables measured were: conventional enological parameters, phenolics and color-related variables. The samples used in the paper correspond to young red wines from 1986 and 1987 for the two origins. The wines were obtained directly from the cellars to the Regulating Councils. A short description of the variables is shown in
Table 1. The complete description of the variables and the whole set of data is displayed in the original article.
The original paper uses logistic regression and HJ-biplot [
35] (separately) to search for the differences between the two origins of the wine. In this case, the predictors are highly collinear, and there is a separation problem. Therefore, the maximum likelihood estimators do not exist, and the proposed method is more adequate to study the relation among the binary variables (Origin and Year) and the chemical characteristics. We obtain the linear combinations of the predictors that best explain the responses. As we have seen before, that produces a biplot. The variance of the predictors explained by the decomposition is shown in
Table 2.
The first two dimensions account for the 57.32% of the variance of the predictors. This means that there is an important part of the variability that explains the responses.The rest of the PLS components are much less important for the prediction.
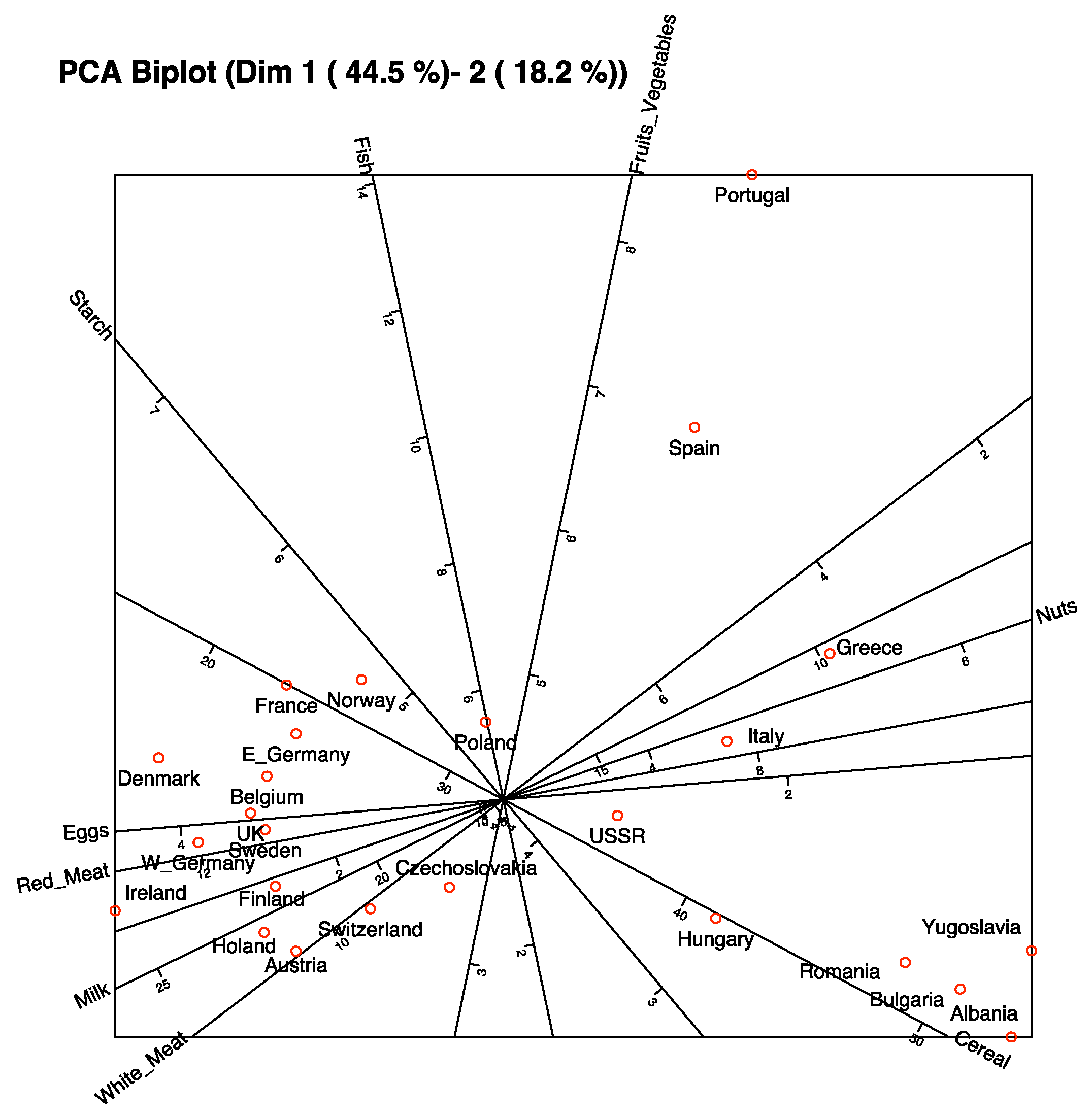
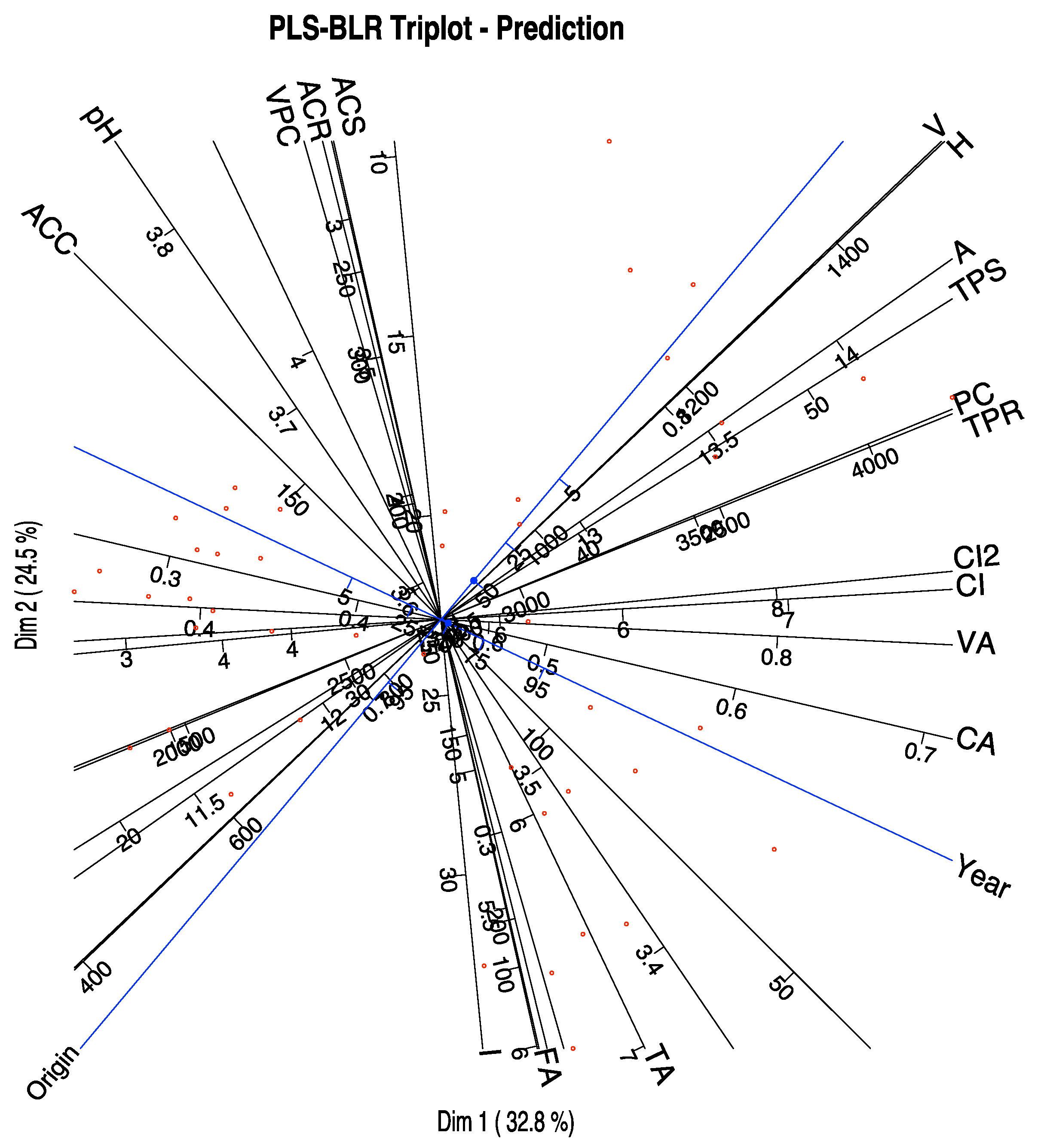
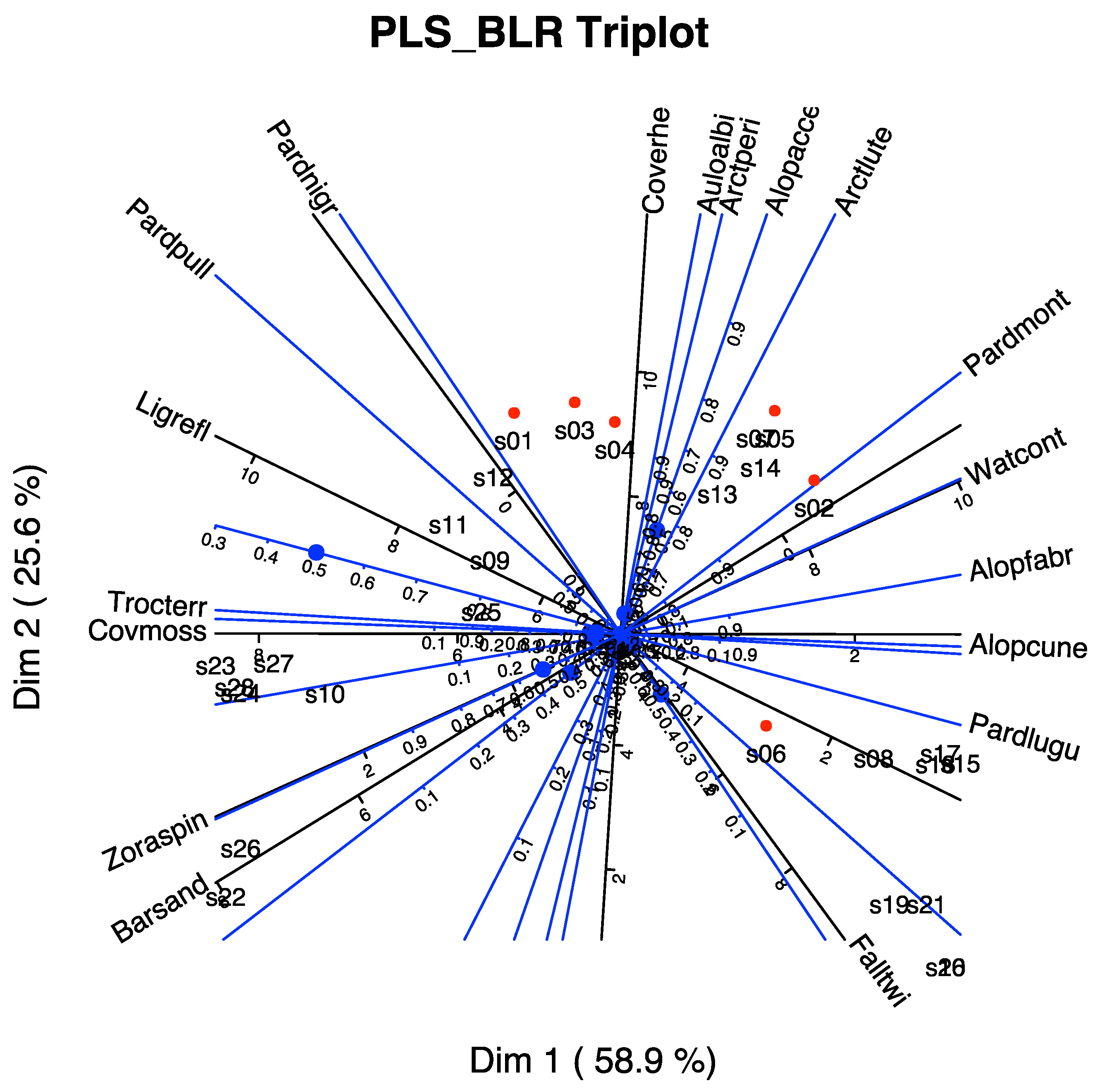
The graphical representation of the first two dimensions is shown in
Figure 5. The plot includes not only the predictors but also the responses.
Table 3 shows some measures of the quality of representation for the binary variables, including a test for the comparison with the null model, three pseudo R-squared measures and the percent of correct classifications.
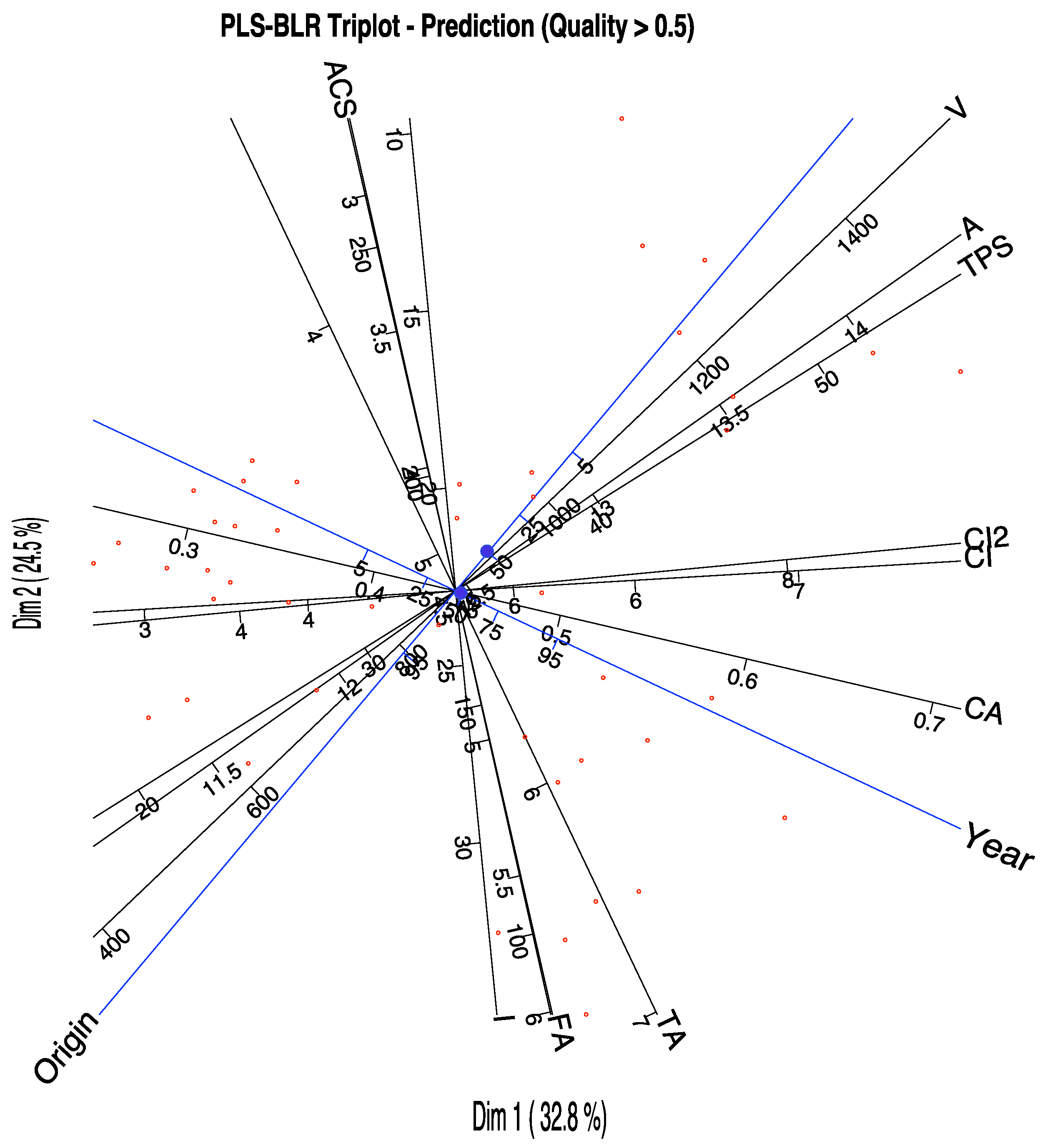
The picture can help in the identification of the most important variables for the prediction. We can select on the graph only the variables with high qualities of representation, for example higher than 0.6. (
Figure 6). The actual qualities are in
Table 4.
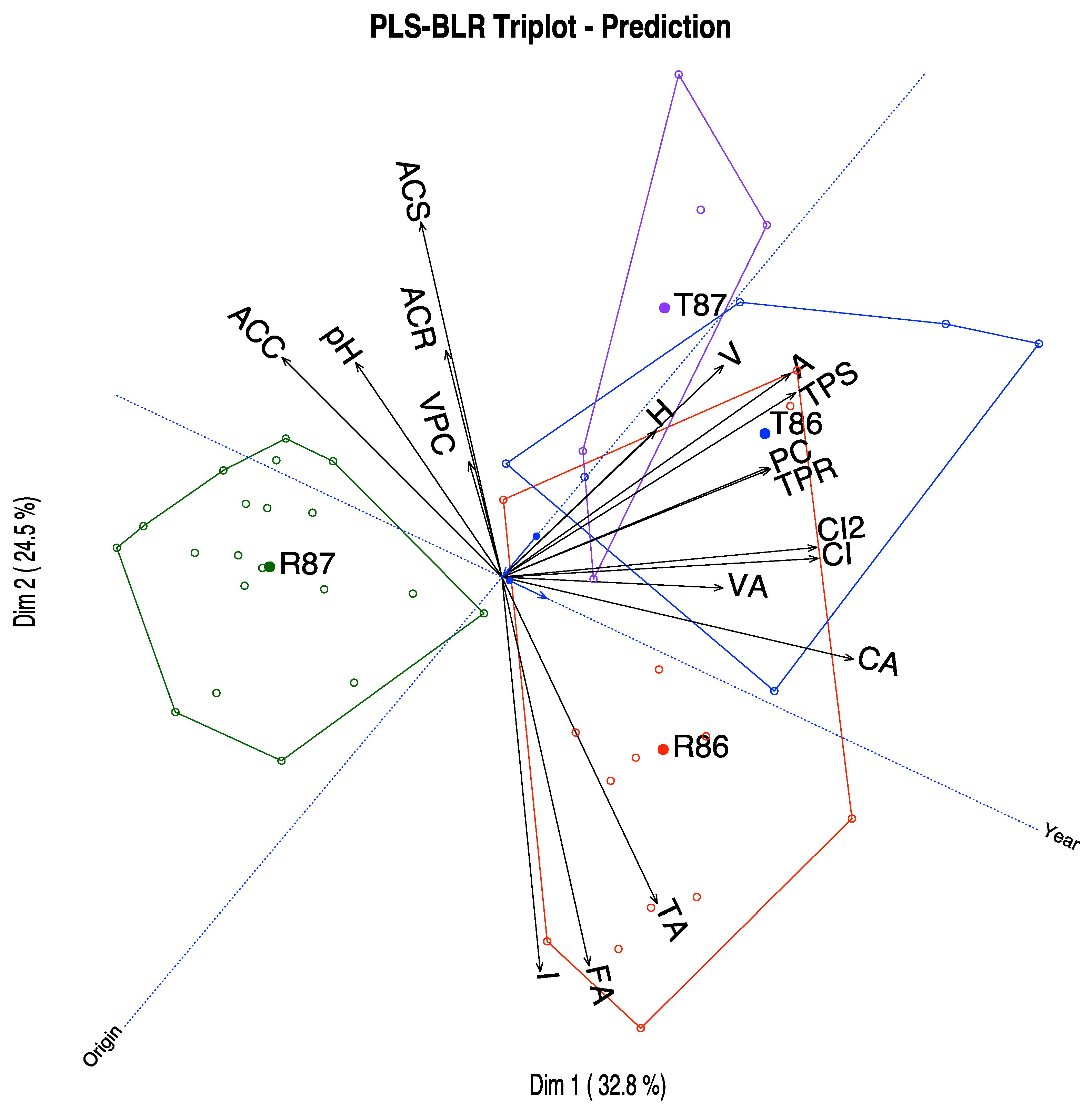
We can have a simpler graph removing the scales for each variable and changing the lines by vectors as in
Figure 7. The scales may be useful when we want to know the approximate values of the variables for each wine or group of wines, but for a general interpretation, the last graph is also useful and more readable. The software package allows for the selection of variables to represent to clean the final picture. That is intended to explore the triplot on the computer screen, but it is sometimes difficult to do the same in the limited space of a piece of paper.
The variables that better predict the responses are those with higher qualities, in order, Chemical Age (CA), Alcoholic content (A), Total phenolics-Somers (TPS), Fixed acidity (FA), Degree of Ionization (I), Colour density (CI & CI2), Total Anthocyanins (ACS), Total titratable acidity (TA), Substances reactive to vanillin (V), Total phenolics-Folin (TPR), Procyanidins (PC) and Malvidin (ACC).
A closer inspection of the graphic shows that VA, A, TPS, PC and TPR are more closely related to the Origin and are higher in Toro. Variables CA and ACC are related to the Year, the first being higher in 1986 and the second in 1987. The variables CI and CI2 that are actually two measures of the colour are somewhat associated to both Origin and Year, being higher for the wines of Toro in the first year. ACS is associated to the second year, and Toro and FA and TA with the first year and Ribera de Duero.
In summary, Toro wines are darker, with higher alcohol content, higher phenolics and procyanidins, in comparison to the Ribera de Duero wines. Color also changes with the year as well as the chemical age and malvidins. Anthocyanins and acidity change with both origin and year.
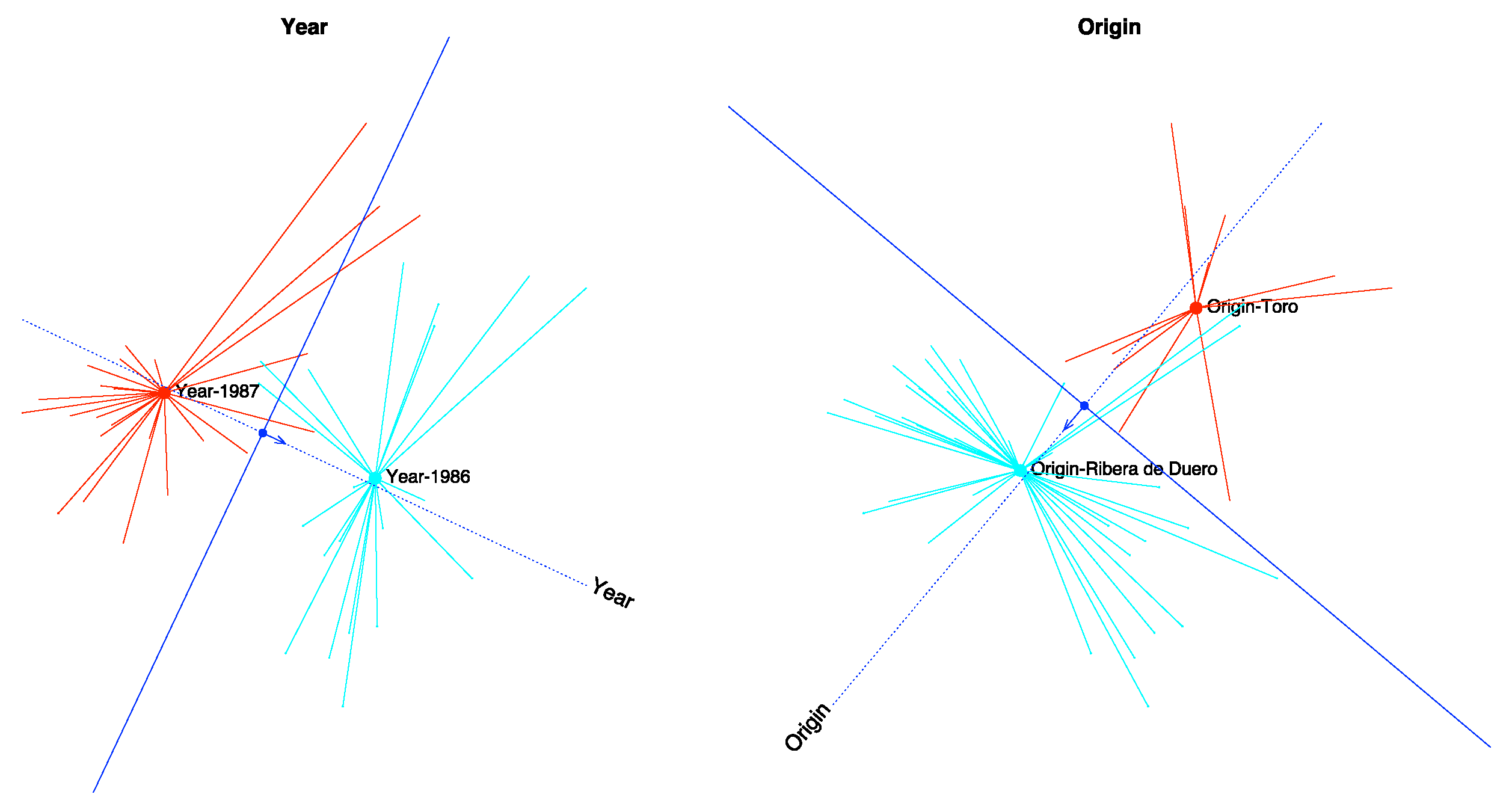
We obtain 90% of correct classifications, 86.67% for the year and 93.33% for the origin respectively. Together with the values of the pseudo
, we can state that the prediction is accurate (See
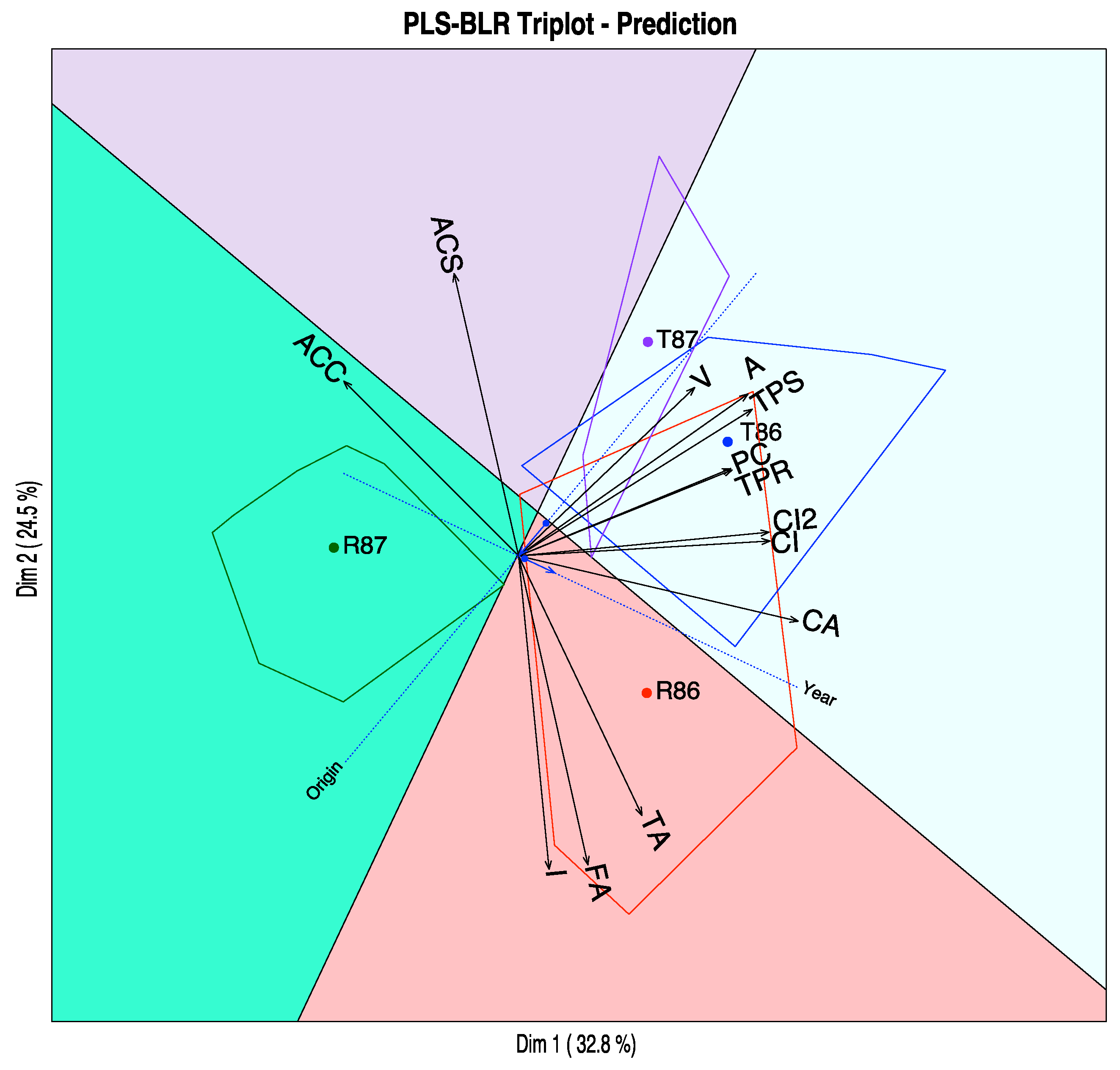
Table 3). We can check that graphically in
Figure 8 where the dotted lines are the directions that best predict the probability, the arrows show the direction of increasing probabilities and the perpendicular line the limits of the prediction region. The arrows start at the points predicting 0.5 and end at the points predicting 0.75. If we classify an individual into a group when the expected probability is higher than 0.5, we can observe that most of the points are on the right prediction region.
Finally, we have placed the convex hulls containing the points for each combination of origin and year as well as the regions that predict the same combinations on the graph. We can see that most of the points lie on the correct prediction region, see
Figure 9.
5.2. Spiders Data
As a second example, we have a data set published in [
36]. The data have been used by several authors to illustrate different ordination techniques, for example by [
37] in its original paper about Canonical Correspondence Analysis.
The original matrix contained the abundances of 12 species of wolf spiders captured at 100 sites (pitfall traps) in an area with dunes in The Netherlands. We have the abundances at 28 sites where a set of environmental variables were also available. The names of the actual species as well as the data tables can be found in [
11].
Initial data have been converted into a binary format. Our responses will be presences or absences of the spider species. Our predictors are a set of six environmental variables measured at the same sites that may explain the presence or absence of the species. Names of the variables as well as the data tables can also be found in [
11].
Components for the predictors are the linear combinations of the variables that better predict the presence and absence of the species. Both species and environmental variables are represented together on the same biplot.
Table 5 contains the amount of variability of the environmental data explained by the PLS components. The first two dimensions explain an 84.53% of the variance.
In this analysis, all the environmental variables are well represented. The qualities are shown in
Table 6.
The information for the fit of the responses is in
Table 7. Most species have a good percentage of correct classifications. The pseudo
coefficients are acceptable except for the
Pardosa lugubris species. This may be due to the fact that it is present in most of the sites, and then it does not have any discriminant power.
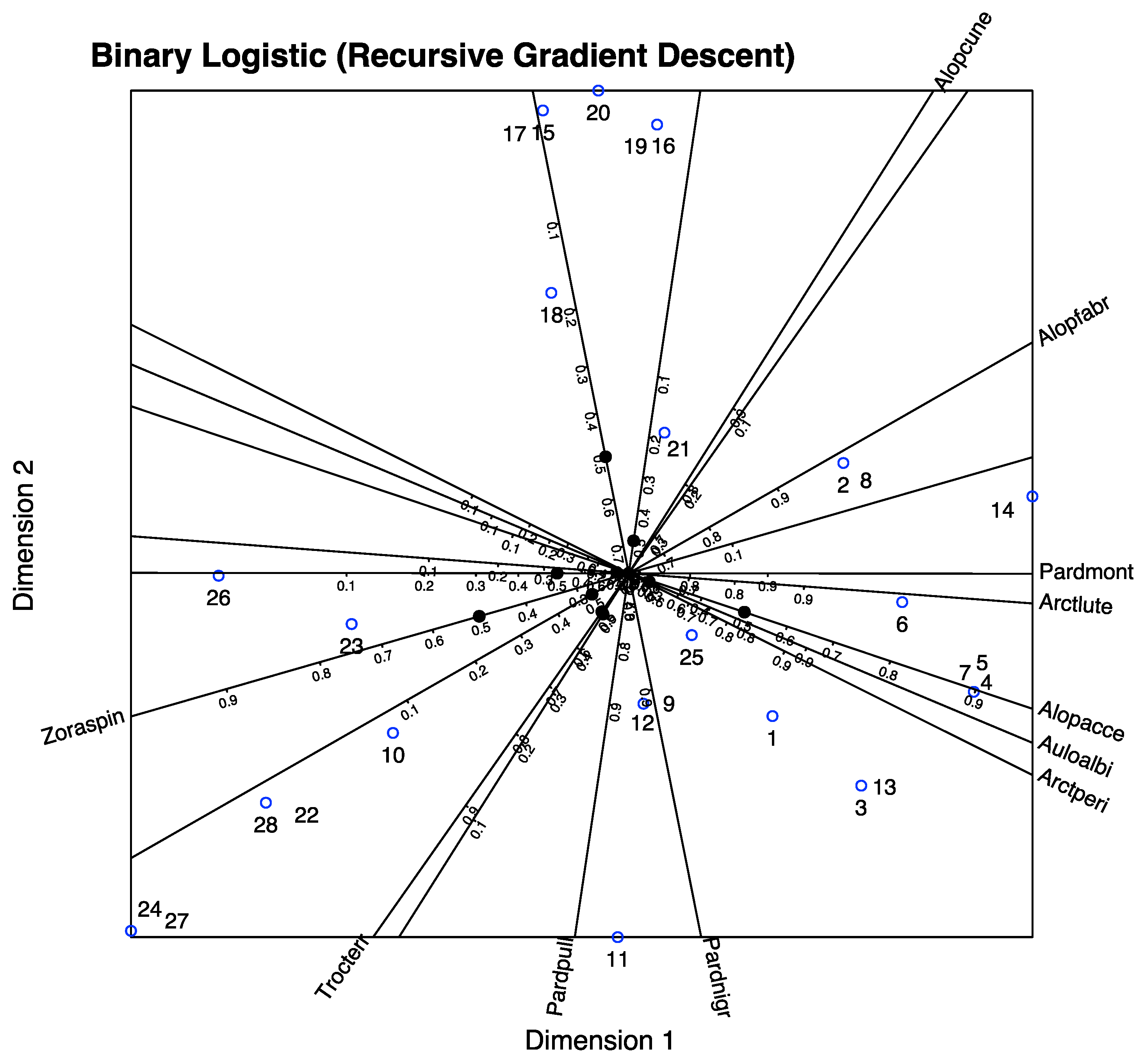
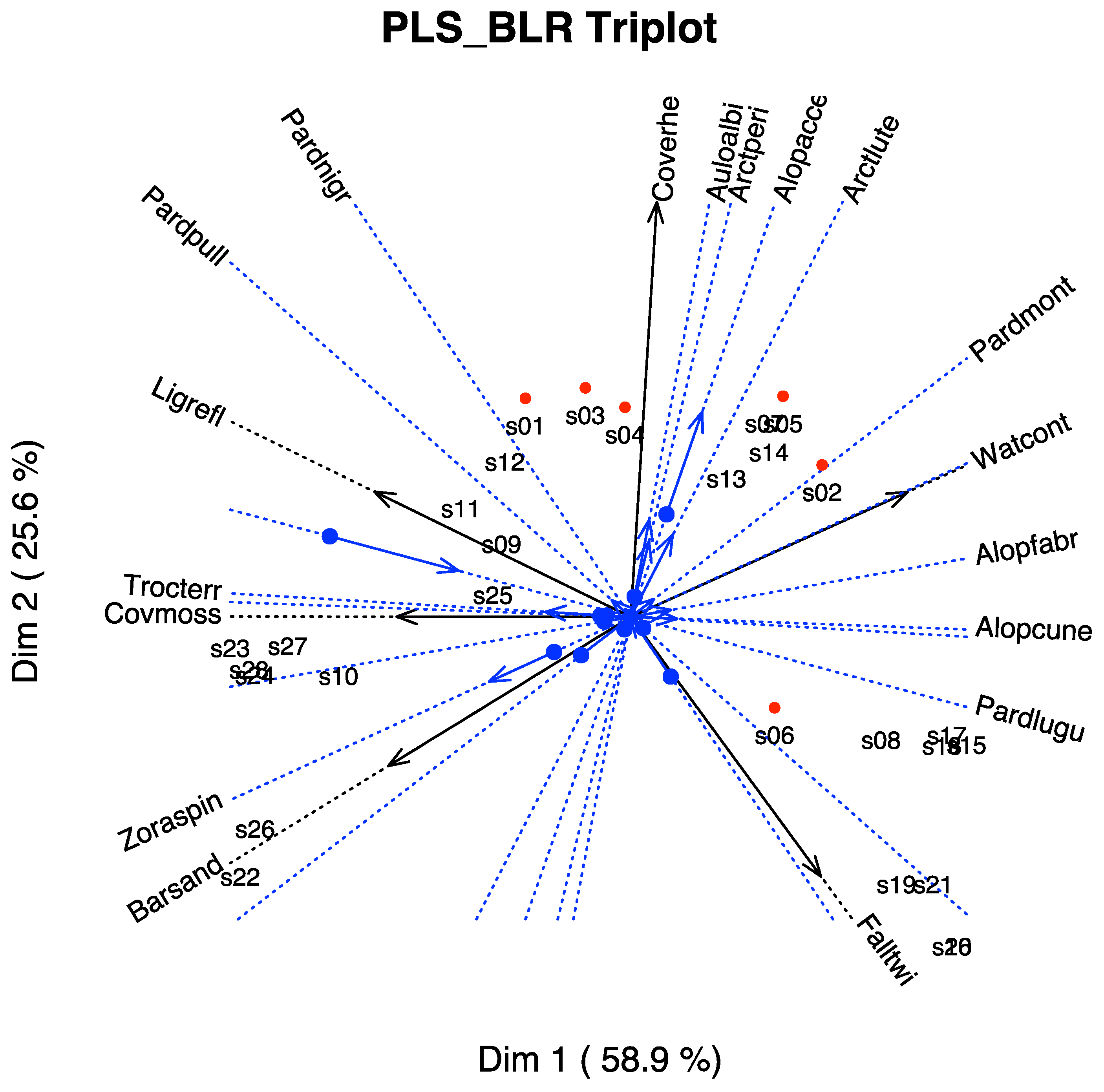
In
Figure 10, we have the biplot representation for the spiders data. We have three sets of markers: for the responses (spider species), for the predictors (environmental variables) and for the individuals (sampling sites). A simplified version with arrows nis shown in
Figure 11. In the graph, we have a whole picture of the problem. The interpretation is similar to the previous case. For example, higher values of
Covermoss are associated to a higher presence of
Trocterr and a lower presence of
Alopcune. A closer inspection of the biplot permits establishing the relations among the predictors and the responses as well as clusters of sites and their main characteristics.
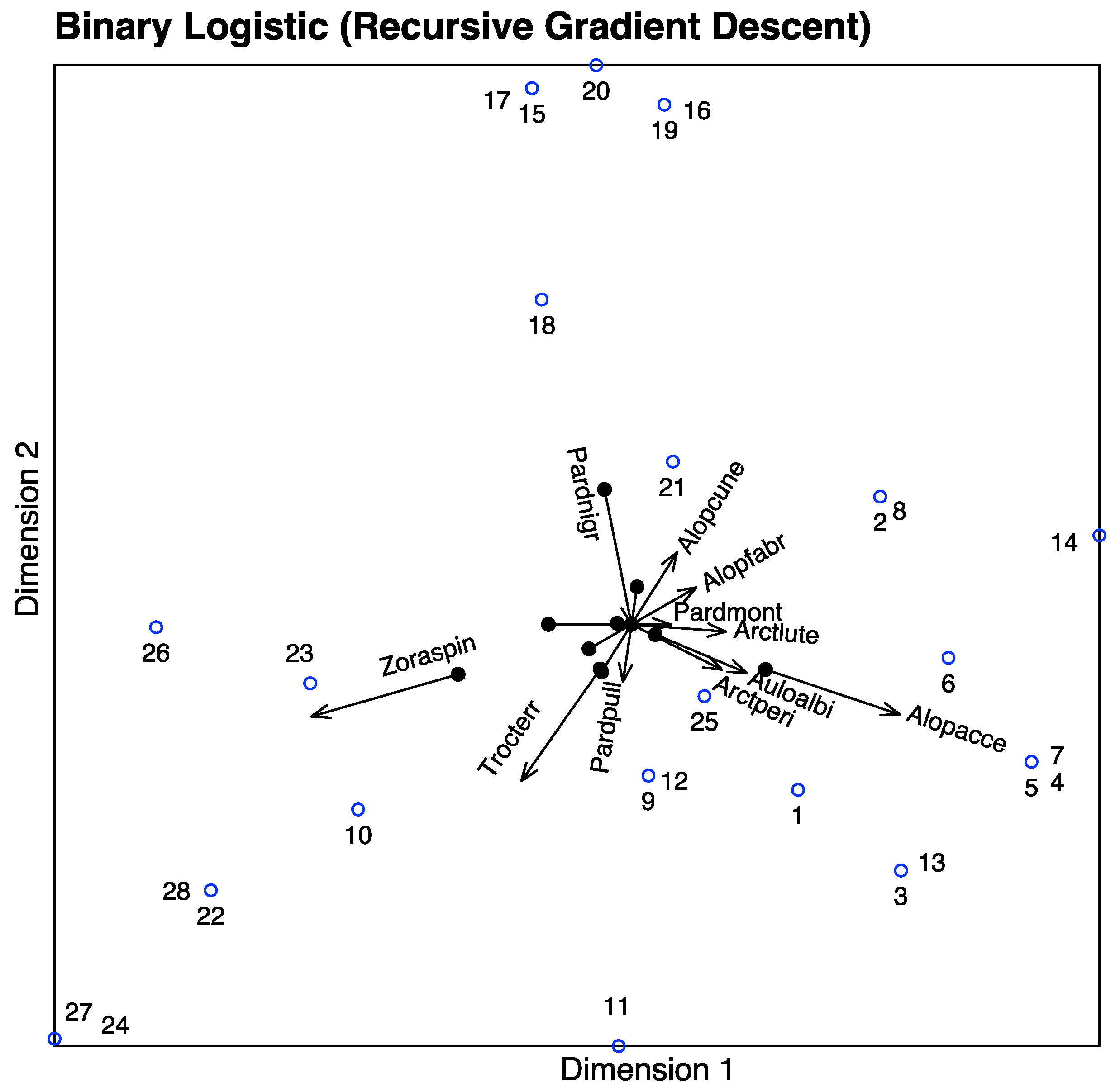
The graph can also be simplified for readability if we do not want to use the scales of the variables. We have extended the directions of the arrows to place the labels outside.
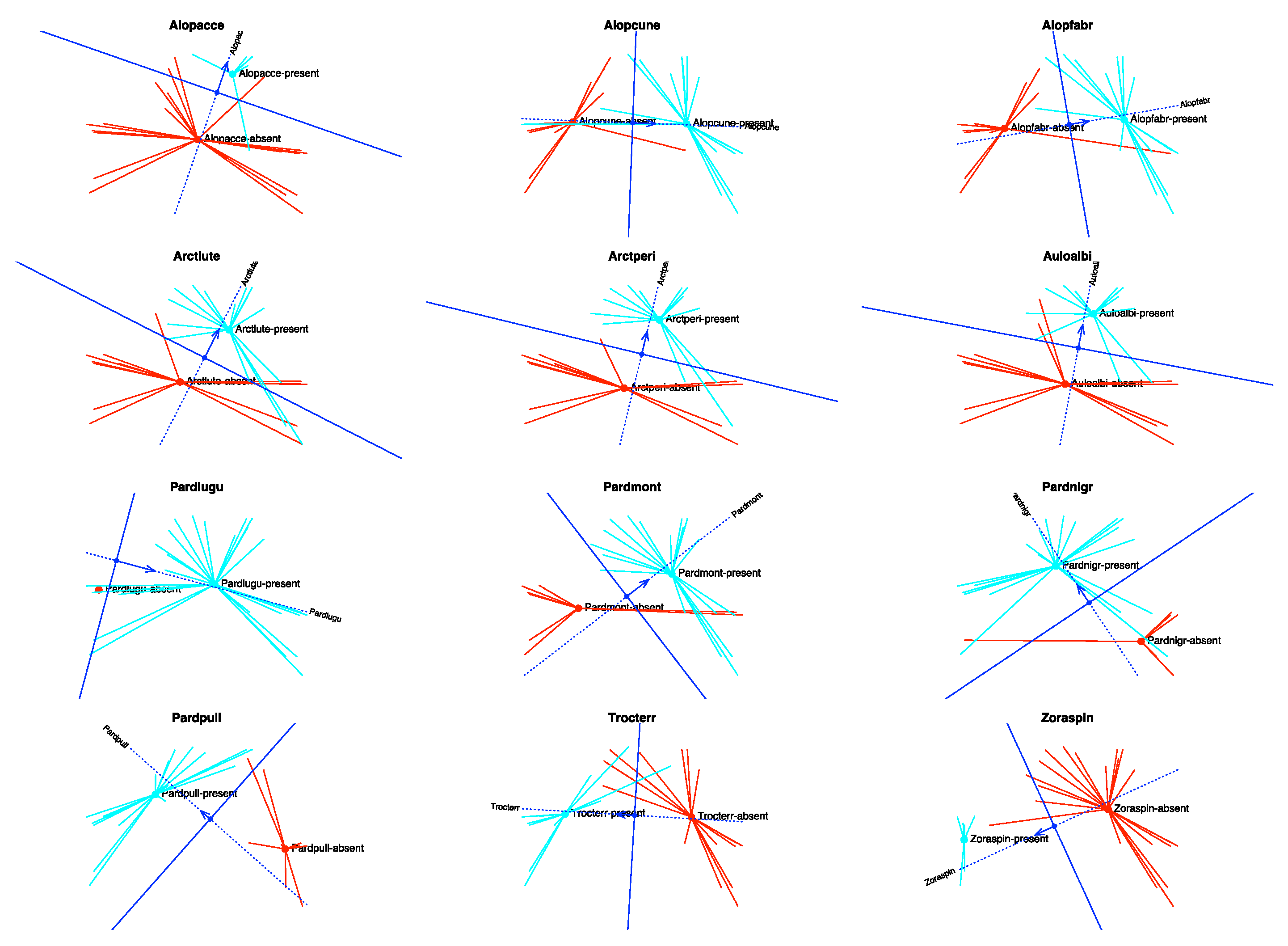
Finally, we show the prediction regions for each response separately (
Figure 12). In the graph, the points with observed presences have been represented in blue, the star joins each point with the centroid of the presences. The absences have been coloured in red. As before, the dotted line is the direction that best predicts the expected probability, and the arrow shows the direction of increasing probabilities. The perpendicular line is the separation between the regions predicting presence and absence, the side of the arrow being the prediction of presence.
We can see that most of the observed values lie in the correct prediction regions. This means that the proposed technique correctly captures the structure of the data and the relations among species and environmental variables.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}