
Constructing a Matrix Mid-Point Iterative Method for Matrix Square Roots and Applications


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introductory Notes
2. Existing Iterative Methods
3. Improved Mid-Point Method for the Matrix Square Root
3.1. An Improved Mid-Point Method
3.2. Construction for the Sign Function
3.3. Competitors from the Padé Family
3.4. Global Convergence
3.5. Application to the Matrix Square Root
3.6. Error Estimate
3.7. Asymptotical Stability
3.8. Scaling
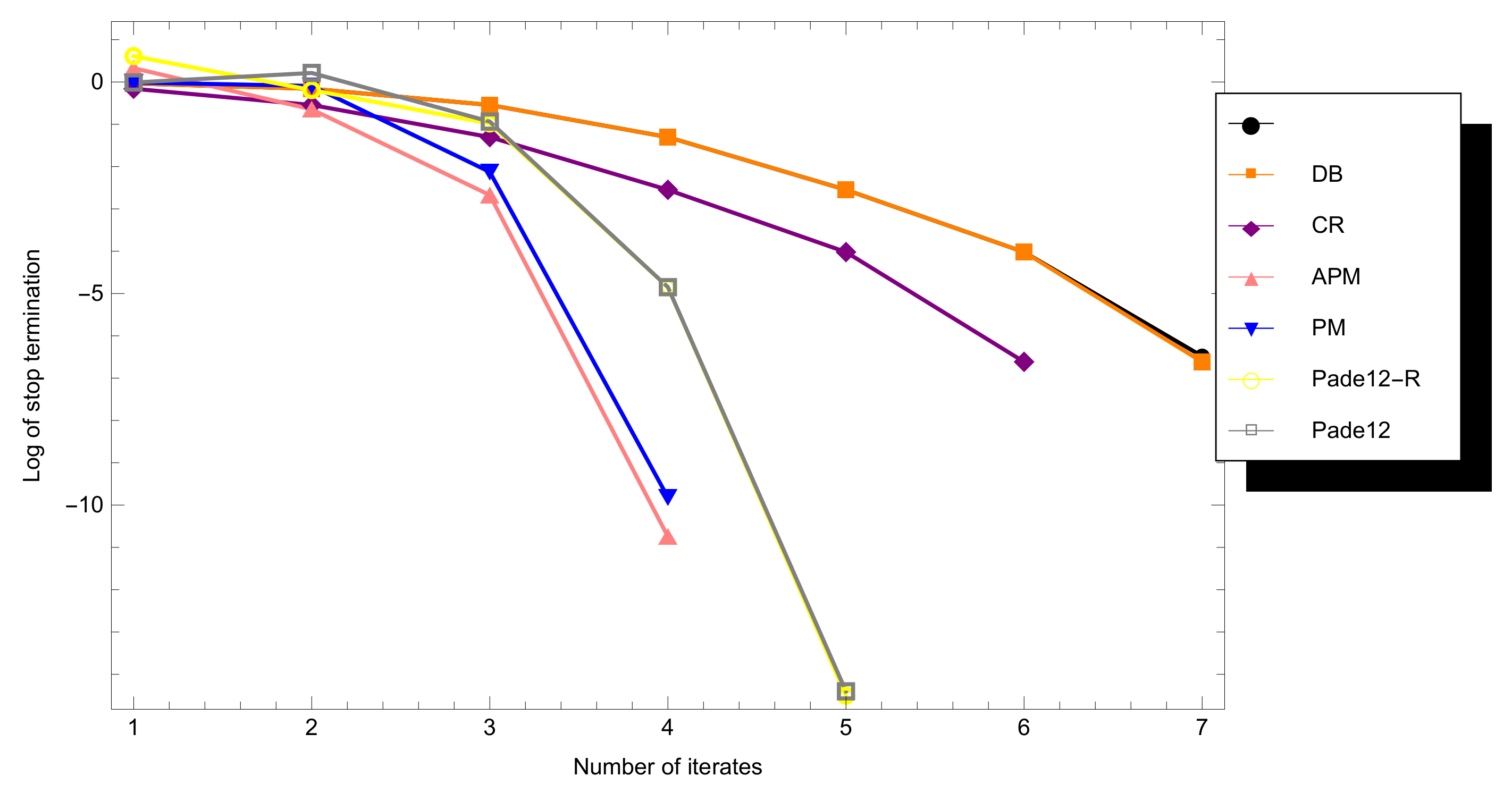
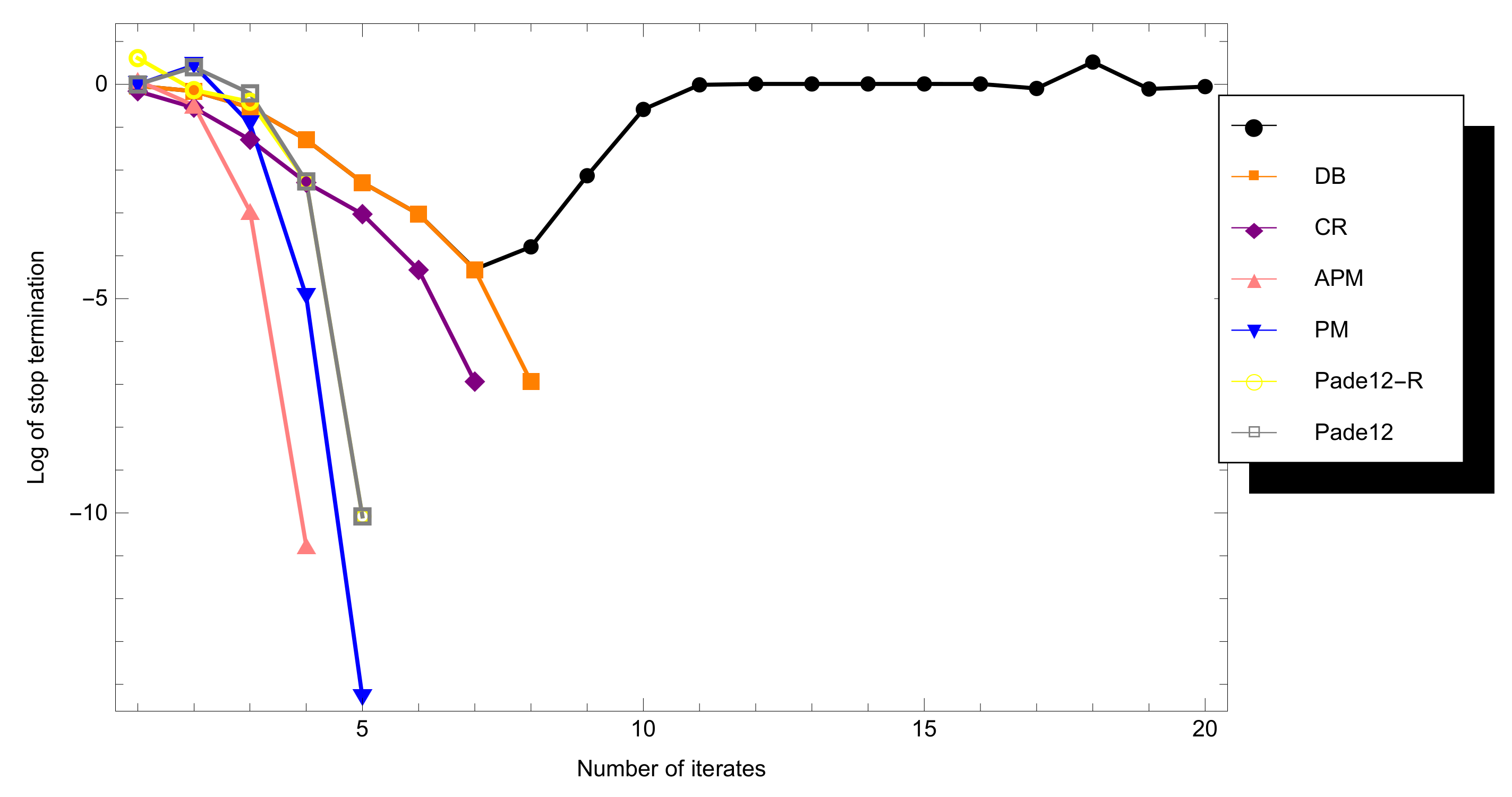
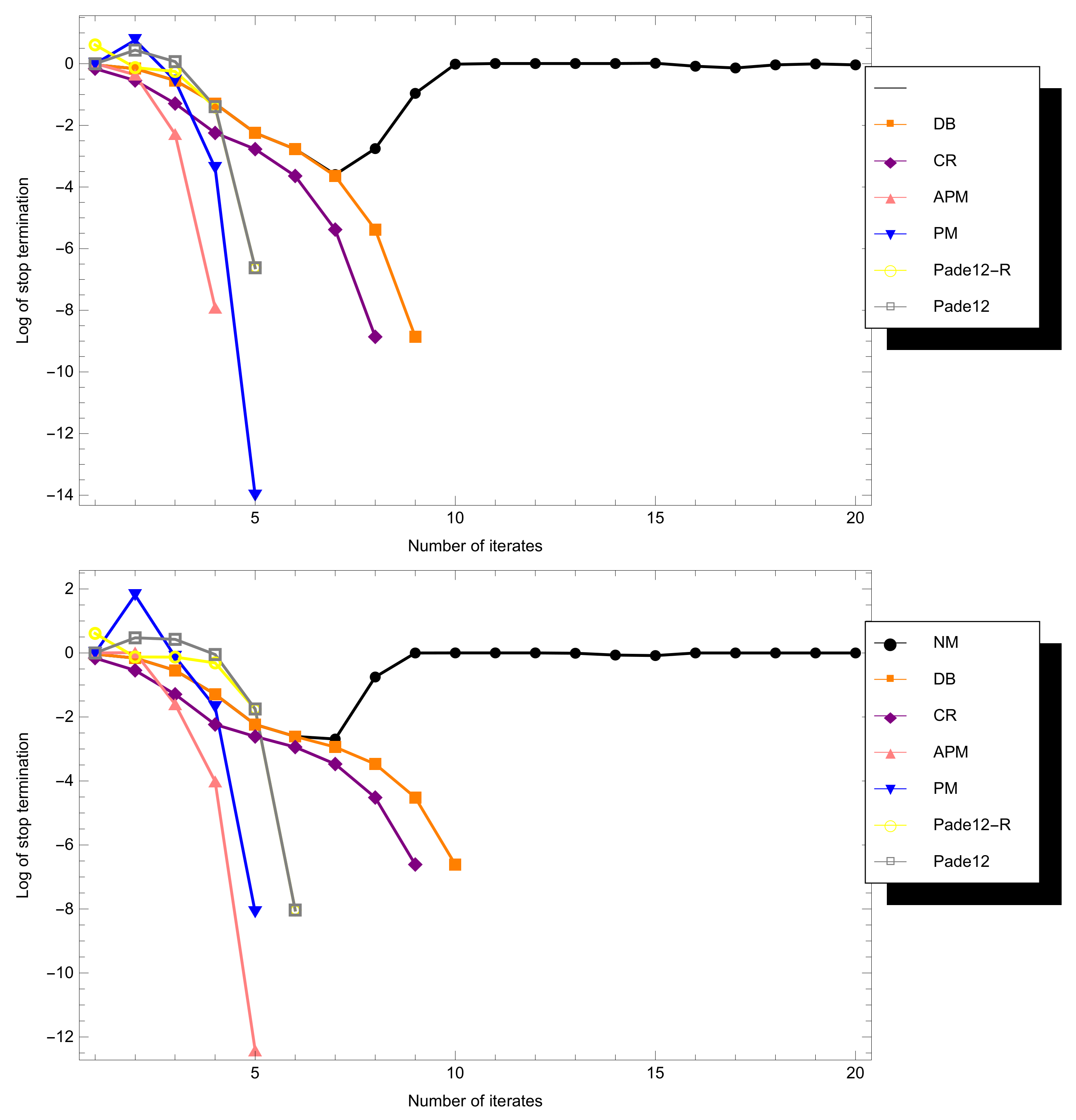
4. Benchmark Tests
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Higham, N.J. Functions of Matrices: Theory and Computation; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2008. [Google Scholar]
- Cordero, A.; Neta, B.; Torregrosa, J.R. Memorizing Schröder’s method as an efficient strategy for estimating roots of unknown multiplicity. Mathematics 2021, 9, 2570. [Google Scholar] [CrossRef]
- Deadman, E.; Higham, N.J. Testing matrix function algorithms using identities. ACM Trans. Math. Softw. 2016, 42, 1–16. [Google Scholar] [CrossRef]
- Cross, G.W.; Lancaster, P. Square roots of complex matrices. Lin. Multilinear Alg. 1974, 1, 289–293. [Google Scholar] [CrossRef]
- Gomilko, O.; Greco, F.; Ziȩtak, K. A Padé family of iterations for the matrix sign function and related problems. Numer. Lin. Alg. Appl. 2012, 19, 585–605. [Google Scholar] [CrossRef]
- Shirilord, A.; Dehghan, M. Closed-form solution of non-symmetric algebraic Riccati matrix equation. Appl. Math. Lett. 2022, 131, 108040. [Google Scholar] [CrossRef]
- Soleymani, F.; Shateyi, S.; Haghani, F.K. A numerical method for computing the principal square root of a matrix. Abst. Appl. Anal. 2014, 2014, 525087. [Google Scholar] [CrossRef]
- Soheili, A.R.; Soleymani, F. Iterative methods for nonlinear systems associated with finite difference approach in stochastic differential equations. Numer. Algor. 2016, 71, 89–102. [Google Scholar] [CrossRef]
- Soleymani, F.; Soheili, A.R. A revisit of stochastic theta method with some improvements. Filomat 2017, 31, 585–5966. [Google Scholar] [CrossRef]
- Soheili, A.R.; Toutounian, F.; Soleymani, F. A fast convergent numerical method for matrix sign function with application in SDEs. J. Comput. Appl. Math. 2015, 282, 167–178. [Google Scholar] [CrossRef]
- Higham, N.J. Newton’s method for the matrix square root. Math. Comput. 1986, 46, 537–549. [Google Scholar]
- Denman, E.D.; Beavers, A.N. The matrix sign function and computations in systems. Appl. Math. Comput. 1976, 2, 63–94. [Google Scholar] [CrossRef]
- Meini, B. The Matrix Square Root from a New Functional Perspective: Theoretical Results and Computational Issues; Technical Report 1455; Dipartimento di Matematica, Università di Pisa: Pisa, Italy, 2003. [Google Scholar]
- Ghorbanzadeh, M.; Mahdiani, K.; Soleymani, F.; Lotfi, T. A class of Kung-Traub-type iterative algorithms for matrix inversion. Int. J. Appl. Comput. Math. 2016, 2, 641–648. [Google Scholar] [CrossRef] [Green Version]
- Kenney, C.S.; Laub, A.J. Rational iterative methods for the matrix sign function. SIAM J. Matrix Anal. Appl. 1991, 12, 273–291. [Google Scholar] [CrossRef]
- Zainali, N.; Lotfi, T. A globally convergent variant of mid-point method for finding the matrix sign. Comp. Appl. Math. 2018, 37, 5795–5806. [Google Scholar] [CrossRef]
- Iannazzo, B. Numerical Solution of Certain Nonlinear Matrix Equations. Ph.D. Thesis, Universita degli Studi di Pisa, Pisa, Italy, 2007. [Google Scholar]
- Iannazzo, B. On the Newton method for the matrix pth root. SIAM J. Matrix Anal. Appl. 2006, 28, 503–523. [Google Scholar] [CrossRef] [Green Version]
- Wagon, S. Mathematica in Action, 3rd ed.; Springer: New York, NY, USA, 2010. [Google Scholar]
- Janssen, A.J.E.M.; Strohmer, T. Characterization and computation of canonical tight windows for Gabor frames. J. Fourier Anal. Appl. 2002, 8, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Maralani, E.M.; Saei, F.D.; Akbarfam, A.A.J.; Ghanbari, K. Computation of eigenvalues of fractional Sturm-Liouville problems. Iran. J. Numer. Anal. Optim. 2021, 11, 117–133. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Golzarpoor, J.; Ahmed, D.; Shateyi, S. Constructing a Matrix Mid-Point Iterative Method for Matrix Square Roots and Applications. Mathematics 2022, 10, 2200. https://doi.org/10.3390/math10132200
Golzarpoor J, Ahmed D, Shateyi S. Constructing a Matrix Mid-Point Iterative Method for Matrix Square Roots and Applications. Mathematics. 2022; 10(13):2200. https://doi.org/10.3390/math10132200
Chicago/Turabian StyleGolzarpoor, Javad, Dilan Ahmed, and Stanford Shateyi. 2022. "Constructing a Matrix Mid-Point Iterative Method for Matrix Square Roots and Applications" Mathematics 10, no. 13: 2200. https://doi.org/10.3390/math10132200