
A Compact Parallel Pruning Scheme for Deep Learning Model and Its Mobile Instrument Deployment


Abstract
:1. Introduction
- (1)
- In this paper, the random-erasure algorithm in the image preprocessing method is used to preprocess the data set to obtain images with different occlusion degrees, which further increases the number of training samples, which greatly improves the generalization ability of the network and reduces the risk of over fitting.
- (2)
- A parallel pruning algorithm combining channel pruning and filter pruning is proposed. Firstly, according to the restriction of compression capacity in structured pruning, the channel pruning method is adopted to permanently remove some parameters in the depth neural network, so as to reduce the amount of calculation and maintain the accuracy of model classification as much as possible. Secondly, in order to obtain a better compression effect, the filter pruning method is used for further compression optimization, and the network is pruned without removing the model parameters.
- (3)
- Combining the characteristics of channel pruning and filter pruning, the two are organically combined to maintain the balance between the accuracy and complexity of the model. The network compressed by this pruning method is applied to the mobile terminal to realize the classification and real-time target detection of the mobile terminal.
2. Related Work
2.1. Introduction of Deep Convolutional Neural Network
2.2. Image Preprocessing
2.3. Network Pruning
2.4. Transfer Learning
3. Parallel Pruning Algorithm Based on Image Preprocessing
3.1. The Random-Erasure Algorithm in Image Preprocessing Is Introduced to Preprocess the Data Set
3.2. Parallel Pruning Algorithm
- (1)
- Channel pruning method based on batch normalization layer
- (2)
- Filter pruning method based on geometric median
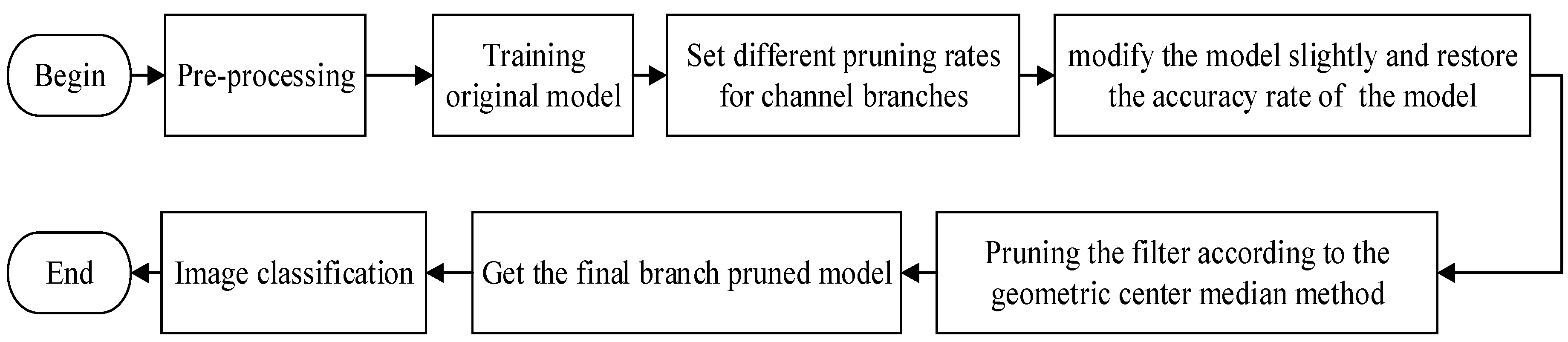
3.3. Algorithm Flow Chart
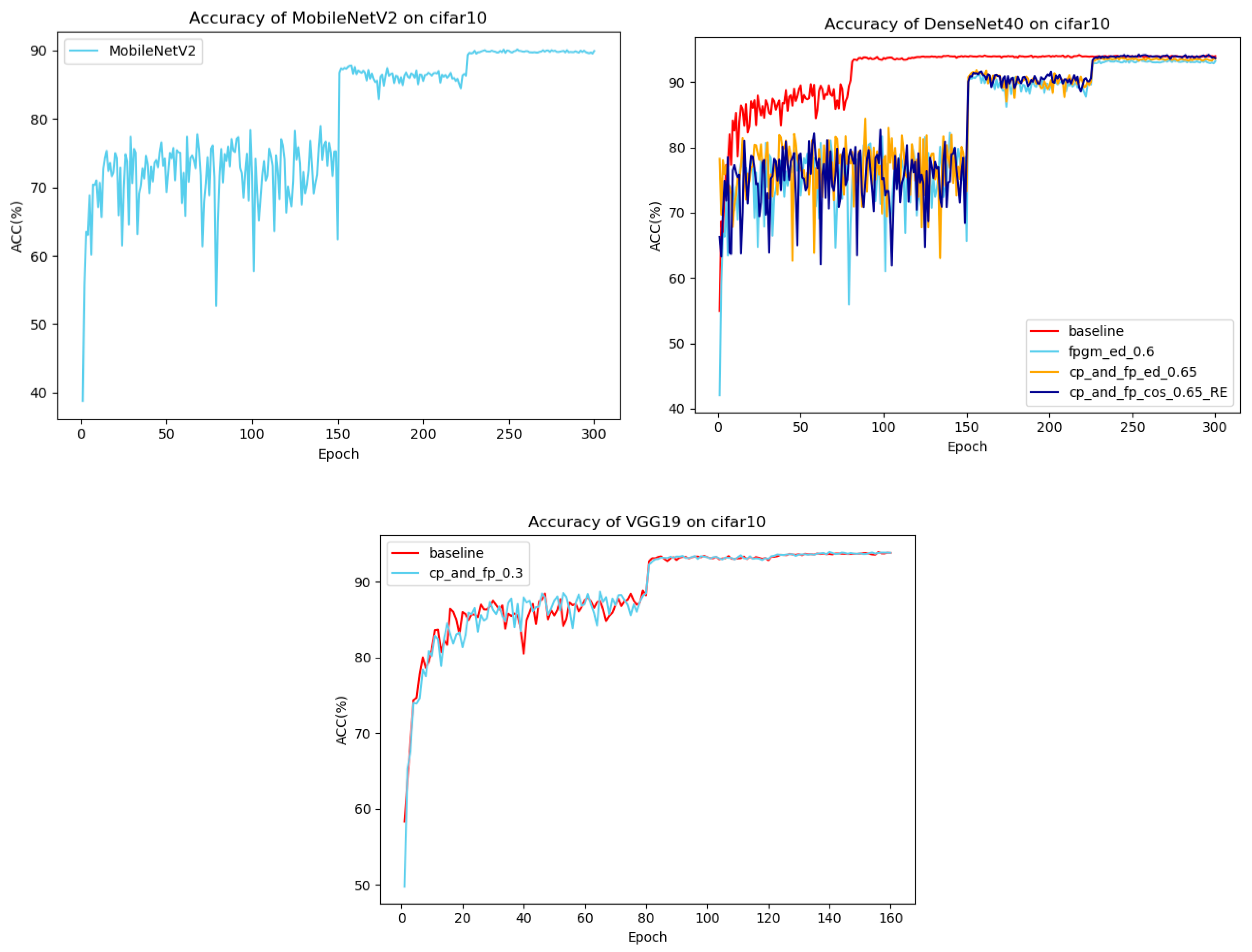
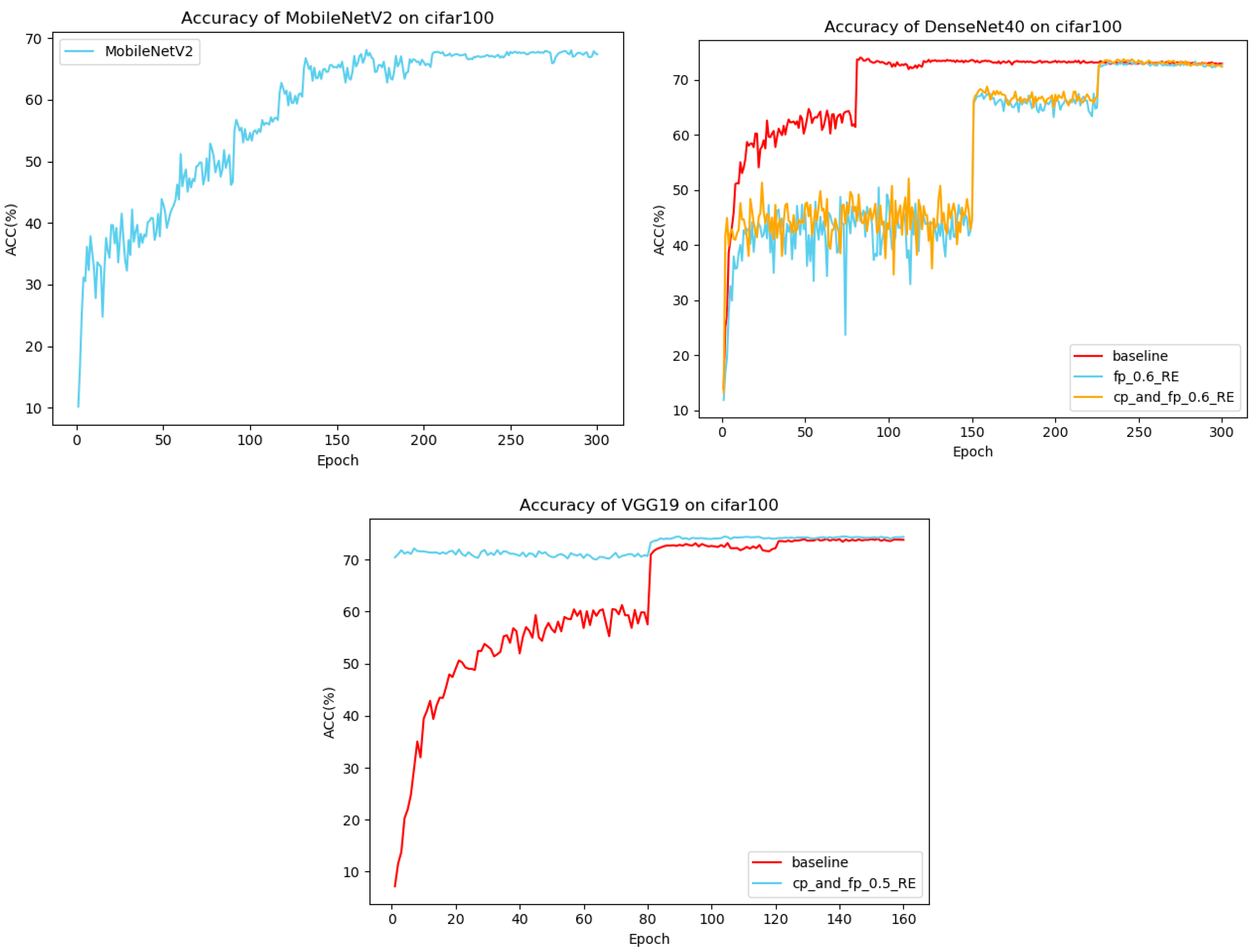
4. Experimental Results and Analysis
5. Case Study
5.1. Image Classification Based on Mobile Terminal
5.2. Mobile Traffic Object Detection Combined with Transfer Learning
5.2.1. Transfer Learning of BDD100K Dataset and YOLO Network
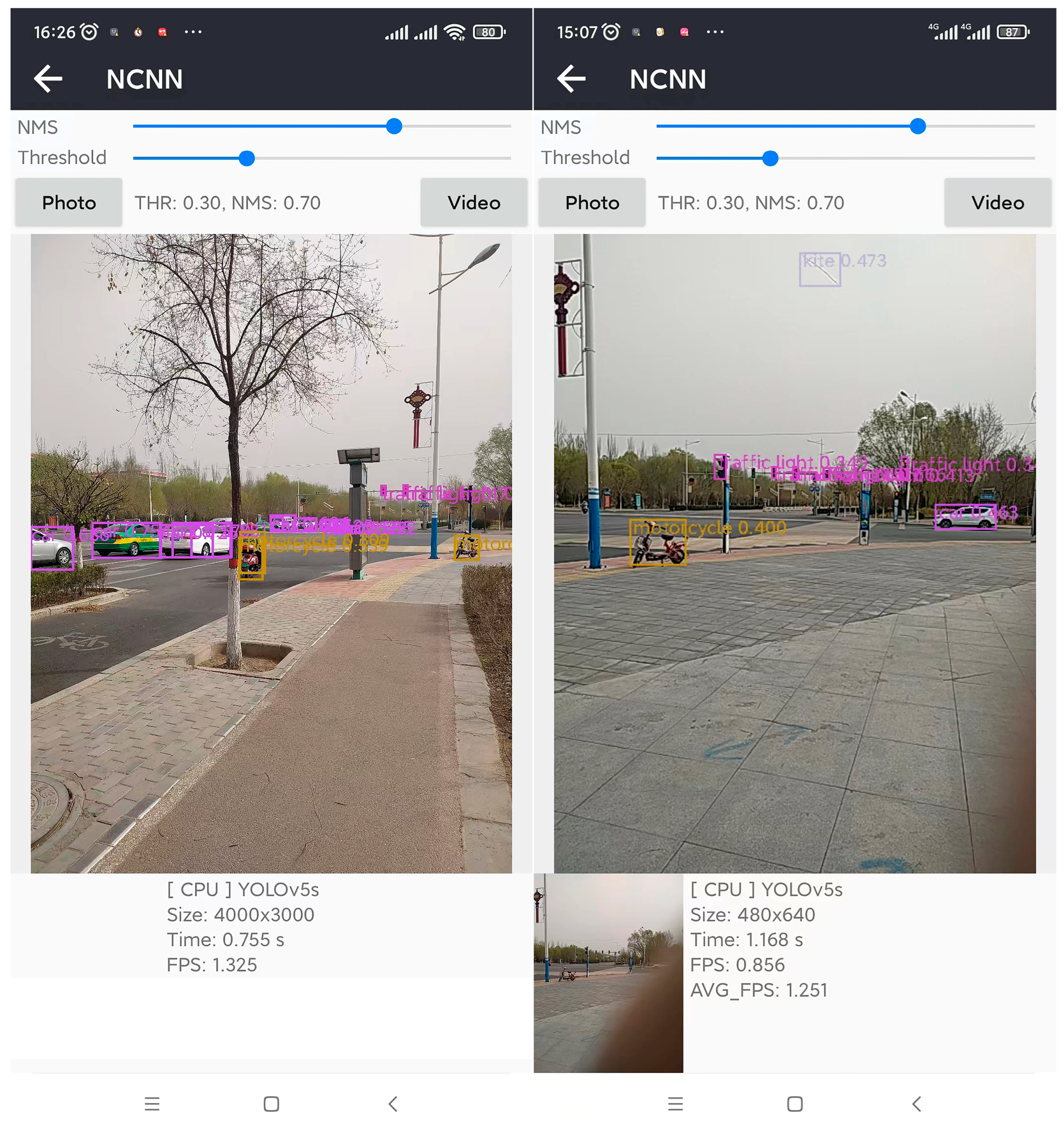
5.2.2. Application of Mobile Object Detection
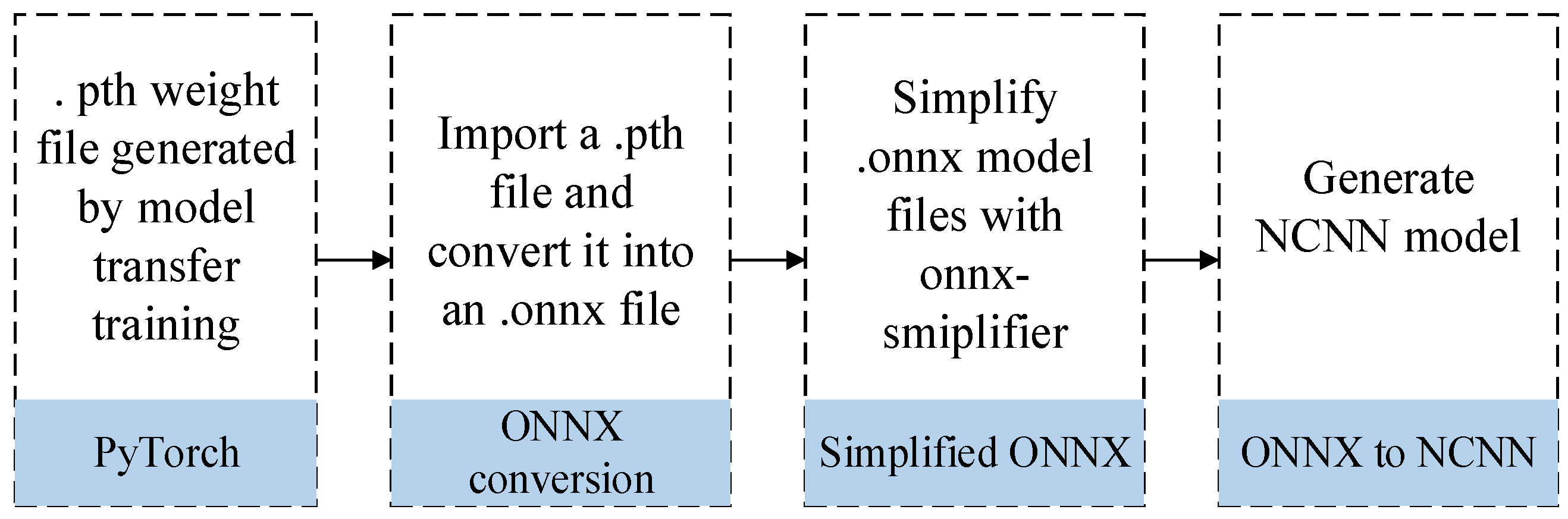
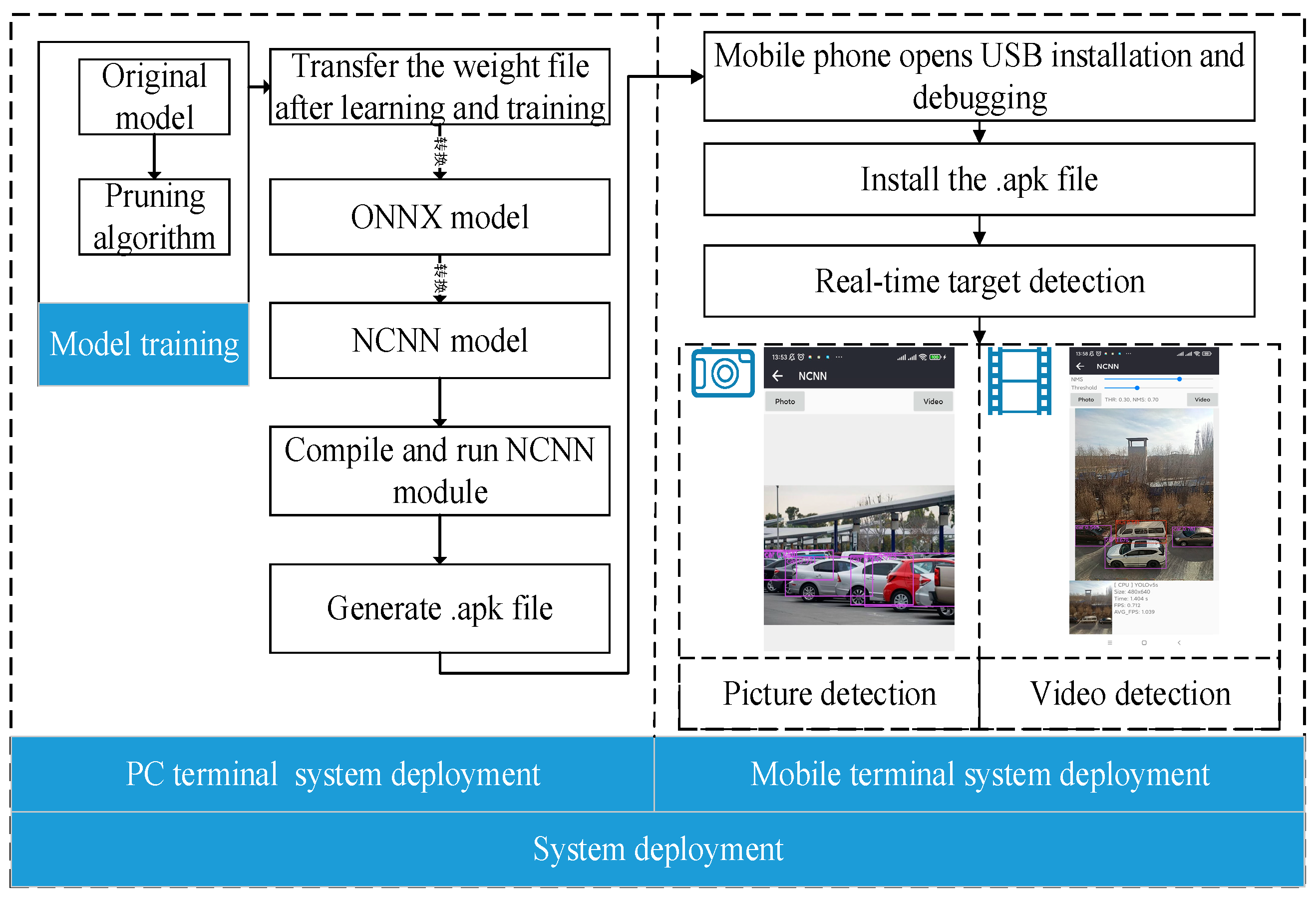
Model Transformation
System Deployment
Traffic Detection and Recognition Effect
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, M.; Hu, M.; Li, M.; Peng, S.-L.; Tan, J. A Novel Fusion Pruning Algorithm Based on Information Entropy Stratification and IoT Application. Electronics 2022, 11, 1212. [Google Scholar] [CrossRef]
- Gong, K.; Zhang, C.; Zeng, G. Convolutional neural network model pruning combined with tensor decomposition compression method. Comput. Appl. 2020, 40, 3146–3151. [Google Scholar]
- Wang, Z.; Xu, Z.; Song, C.; Zhang, H.; Cai, Y. Deep network pruning algorithm based on gradient. Comput. Appl. 2020, 40, 1253–1259. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets. arXiv 2016, arXiv:1608.08710. Available online: https://arxiv.org/abs/1608.08710 (accessed on 27 December 2021).
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- He, Y.; Dong, X.; Kang, G.; Fu, Y.; Yan, C.; Yang, Y. Asymptotic Soft Filter Pruning for Deep Convolutional Neural Networks. IEEE Trans. Cybern. 2019, 49, 4501–4564. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, J.; Chen, Q.; Amudula, E. Research on point target tracking technology based on correlation filtering and CNN. Laser Infrared 2021, 51, 244–249. [Google Scholar]
- Zhang, X.; Wei, Y. Detection and extraction of key targets in driving scenes based on deep learning. J. East China Univ. Sci. Technol. 2019, 45, 980–988. [Google Scholar]
- Guo, J. Research on Pruning Method of Deep Convolution Neural Network Model; Beijing Jiaotong University: Beijing, China, 2020. [Google Scholar]
- Pang, S.; Huang, C. Research on Image Classification Based on Convolutional Neural Network. Mod. Comput. 2019, 23, 40–44. [Google Scholar]
- Gao, Q.; Li, C.; Jin, X.; Li, Y.; Wu, H. Research on weed classification and model compression method in tea garden based on depth residual network. J. Anhui Agric. Univ. 2021, 48, 668–673. [Google Scholar]
- Xie, X. Research on Driver Fatigue Detection Based on Machine Vision; Central South University: Changsha, China, 2010. [Google Scholar]
- Zhang, W.; Sun, X.; Qiao, Y.; Bai, P.; Jiang, H.; Wang, Y.; Du, C.; Zong, H. Tobacco disease identification based on incidence v3. Acta Table Sin. 2021, 27, 61–70. [Google Scholar]
- Jiang, Y.; Zhang, H.; Chen, L.; Tao, S. Image data enhancement algorithm based on convolutional neural network. Comput. Eng. Sci. 2019, 41, 2007–2016. [Google Scholar]
- Lian, C.; Zhong, S.; Zhang, T.; Zhou, N.; Xie, M. Transfer learning classification of optical coherence tomography retinal images. Adv. Laser Optoelectron. 2021, 58, 270–276. [Google Scholar]
- Guan, S.; Zhang, Q.Y.; Xie, H.; Qiang, Y.; Cheng, Z. Convolutional neural network model for CT image recognition. J. Comput. Aided Des. Graph. 2018, 30, 1530–1535. [Google Scholar] [CrossRef]
- Jin, C.; Wang, H.; Chen, S. Pedestrian reidentification method based on random erasure pedestrian alignment network. J. Shandong Univ. 2018, 48, 67–73. [Google Scholar]
- Yu, X.; Bing, X.; Meng, J.Z. Self-adaptive particle swarm optimization for large-scale feature selection in classification. ACM Trans. Knowl. Discov. Data 2019, 13, 1–27. [Google Scholar]
- Jin, L.L.; Yang, W.; Wang, S.; Cui, Z.; Chen, X.; Chen, L. A hybrid pruning method for convolutional neural network compression. Minicomput. Syst. 2018, 39, 2596–2601. [Google Scholar]
- Cai, Z.; Ying, N.; Guo, C.; Kuoray, Y.P. Multi-person attitude estimation of YOLOv3 pruning model. J. Image Graph. 2021, 26, 837–846. [Google Scholar]
- Lu, H.; Xia, H.; Yuan, X. Dynamic network pruning based on filter attention mechanism and characteristic scaling coefficient. Minicomput. Syst. 2019, 40, 1832–1838. [Google Scholar]
- He, Y.; Liu, P.; Wang, Z.; Hu, Z.; Yang, Y. Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration. arXiv 2019, arXiv:1811.00250. Available online: https://arxiv.org/abs/1811.00250 (accessed on 3 October 2021).
- Zhang, M.; Lu, Q.; Li, W.; Song, H. Deep neural network compression algorithm based on joint dynamic pruning. Comput. Appl. 2021, 41, 1589–1596. [Google Scholar]
- Liu, G.; Xu, C.; Chen, S.; Wu, C. Image classification method combining deep confidence network and hybrid neural network. Minicomput. Syst. 2017, 38, 2146–2151. [Google Scholar]
- Xue, Y.; Tang, Y.; Xu, X.; Liang, J.; Neri, F. Multi-objective feature selection with missing data in classification. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 6, 355–364. [Google Scholar] [CrossRef]
- Huang, T.; Xiang, G.; Yang, X. Research progress of pedestrian detection technology based on deep learning. J. Chongqing Univ. Technol. 2019, 33, 98–109. [Google Scholar]
- Zhao, W.; Xu, C.; Wang, C. Domain adaptive target detection for domain confrontation. Electron. Meas. Technol. 2020, 43, 45–49. [Google Scholar]
- Wang, D.-X. Research on Multi-Target Detection and Tracking Method Based on Deep Learning; Dalian University of Technology: Dalian, China, 2021. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Method (Pruning Rate.%) | Test Acc (%) | Param (M) | Prune (Acc. %) | Flops (G) |
|---|---|---|---|---|---|
| VGG-19 | Baseline | 93.66 | 20.04 | — | 7.97 |
| LECNN (70%) | 93.80 | 2.30 | 88.5 | 3.91 | |
| Cp-and-FpRe (70%) | 94.90 | 3.25 | 83.8 | 2.31 | |
| Densenet-40 | Baseline | 93.89 | 1.05 | — | 5.33 |
| LECNN (40%) | 94.89 | 0.69 | 34.3 | 3.81 | |
| FPGM (40%) | 93.57 | 1.05 | — | 2.87 | |
| Cp-and-Fp (40%) | 94.04 | 0.88 | — | — | |
| Cp-and-FpRe (40%) | 94.99 | 0.88 | 16.2 | 2.49 | |
| Cp (60%) | 87.32 | 0.49 | 53.3 | 1.53 | |
| Fp (60%) | 93.43 | 1.05 | — | — | |
| Cp-and-Fp (60%) | 93.30 | — | — | 1.76 | |
| Cp-and-FpRe (60%) | 94.30 | 0.59 | 43.8 | 1.76 | |
| Cp-and-Fp (65%) | 93.77 | 0.59 | — | — | |
| Cp-and-Fp-Cos (65%) | 93.81 | — | — | — | |
| Cp-and-FpRe (65%) | 94.21 | 0.59 | 43.8 | 1.76 | |
| MoblieNetV2 | — | 90 | 4.133 | — | 6.08 |
| Network | Method | Test Acc (%) | Param (M) | Prune (Acc.%) | Flops (G) |
|---|---|---|---|---|---|
| VGG-19 | Baseline | 73.26 | 20.08 | — | 7.97 |
| LECNN (50%) | 73.48 | 5.0 | 75.1 | 5.01 | |
| Cp-and-Fp (50%) | 74.50 | 7.24 | — | — | |
| Cp-and-FpRe (50%) | 75.67 | 7.24 | 63.9 | 3.0 | |
| Densenet-40 | Baseline | 74.64 | 1.06 | — | 5.33 |
| Cp (40%) | 74.72 | 0.66 | 37.5 | 3.71 | |
| Fp (40%) | 73.89 | 1.06 | — | 2.87 | |
| Cp-and-Fp (40%) | 74.90 | — | — | — | |
| Cp-and-FpRe (40%) | 76.40 | 0.76 | 28.3 | 2.49 | |
| MoblieNetV2 | — | 68.08 | — | — | — |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Zhao, M.; Luo, T.; Yang, Y.; Peng, S.-L. A Compact Parallel Pruning Scheme for Deep Learning Model and Its Mobile Instrument Deployment. Mathematics 2022, 10, 2126. https://doi.org/10.3390/math10122126
Li M, Zhao M, Luo T, Yang Y, Peng S-L. A Compact Parallel Pruning Scheme for Deep Learning Model and Its Mobile Instrument Deployment. Mathematics. 2022; 10(12):2126. https://doi.org/10.3390/math10122126
Chicago/Turabian StyleLi, Meng, Ming Zhao, Tie Luo, Yimin Yang, and Sheng-Lung Peng. 2022. "A Compact Parallel Pruning Scheme for Deep Learning Model and Its Mobile Instrument Deployment" Mathematics 10, no. 12: 2126. https://doi.org/10.3390/math10122126