
Recent Iris and Ocular Recognition Methods in High- and Low-Resolution Images: A Survey

Abstract
:1. Introduction
1.1. Background of Biometrics
1.2. Motivation
1.3. The Scope of this Study
- The pros and cons of traditional iris and ocular recognition using high-resolution images are classified according to the approach taken, and the problems arising when a low-resolution image is input, are discussed.
- Iris and ocular recognition studies that have adopted the SR method to solve the low-resolution problem are classified according to the approach taken, and the pros and cons of each method are investigated.
- Iris and ocular recognition approaches that have applied the state-of-the-art deep learning SR methods have performed well.
2. Iris and Ocular Recognition Methods Using High-Resolution Images
2.1. Iris Recognition Methods with High-Resolution Images
2.1.1. Image Processing Method
2.1.2. Machine Learning-Based Method
2.1.3. Deep Learning Method
2.2. Ocular Recognition Using High-Resolution Images
2.2.1. Image Processing-Based Method
2.2.2. Machine Learning Method
2.2.3. Deep Learning Method
2.3. Analysis and Discussions
- –
- It may be difficult to implement a system to acquire high-resolution iris and ocular images. Camera devices and lenses for capturing high-resolution images are generally expensive and require mandatory subject cooperation to capture images. If the subject moves, a low-quality image will be obtained due to motion blurring, despite using an expensive high-quality device.
- –
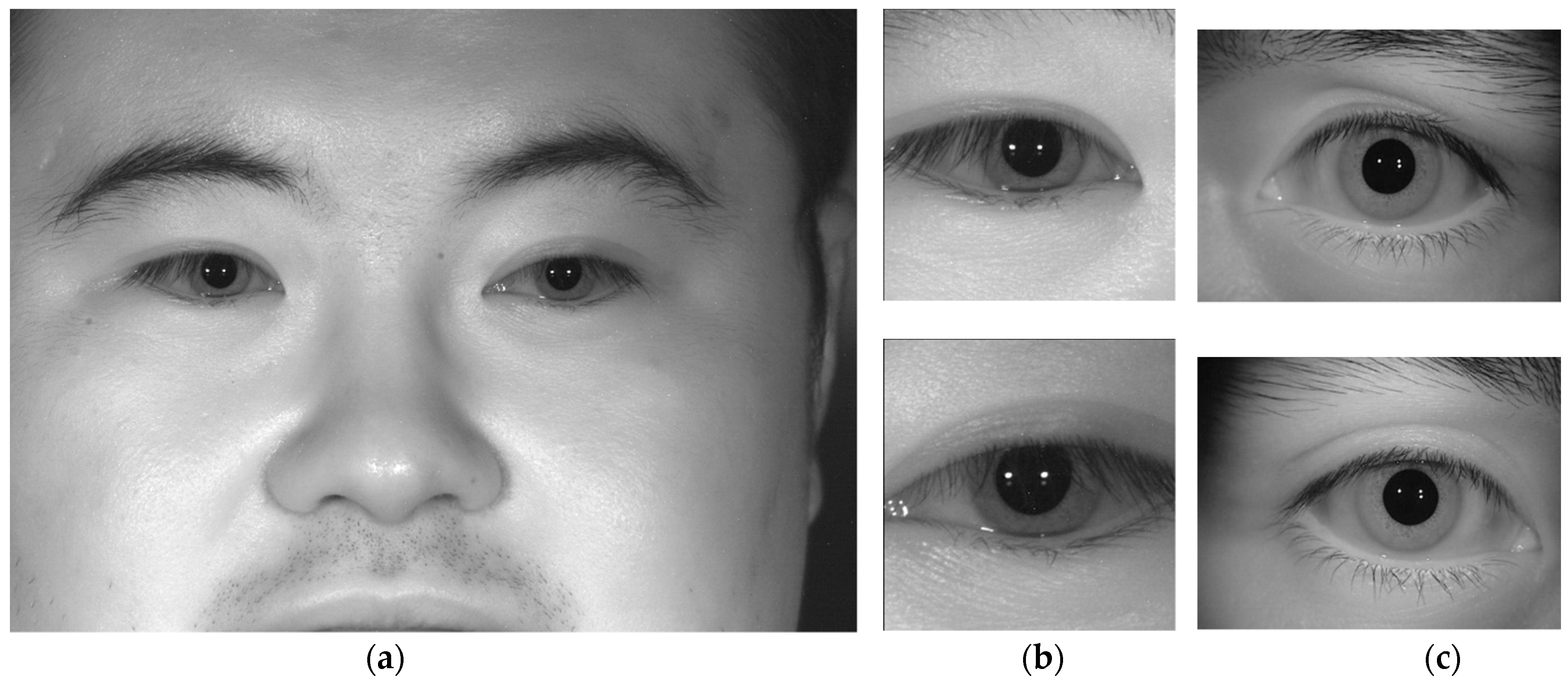
- In general, iris colors differ among individuals and light irises show more detail than dark ones. When attempting to identify a dark iris, the recognition performance may be poor. Therefore, most iris recognition systems are implemented in environments using NIR lighting. This increases the system’s implementation cost and also its size.
- –
- Because high-resolution images are used, a computer with high computing power is required when the system is implemented. Compared with low-resolution, high-resolution captures more information and requires greater computation for processing. This creates the possibility of performance degradation in low-resolution mobile and embedded systems.
- –
- Since ocular image recognition systems do not require accurate eye region segmentation, they mitigate the complexity of conventional iris recognition systems. In another sense, however, this means that important iris features cannot be properly exploited, resulting in lower recognition performance compared to iris recognition systems. Therefore, a method that can better extract the features of the iris and the surrounding eye region is required to solve this problem.
- –
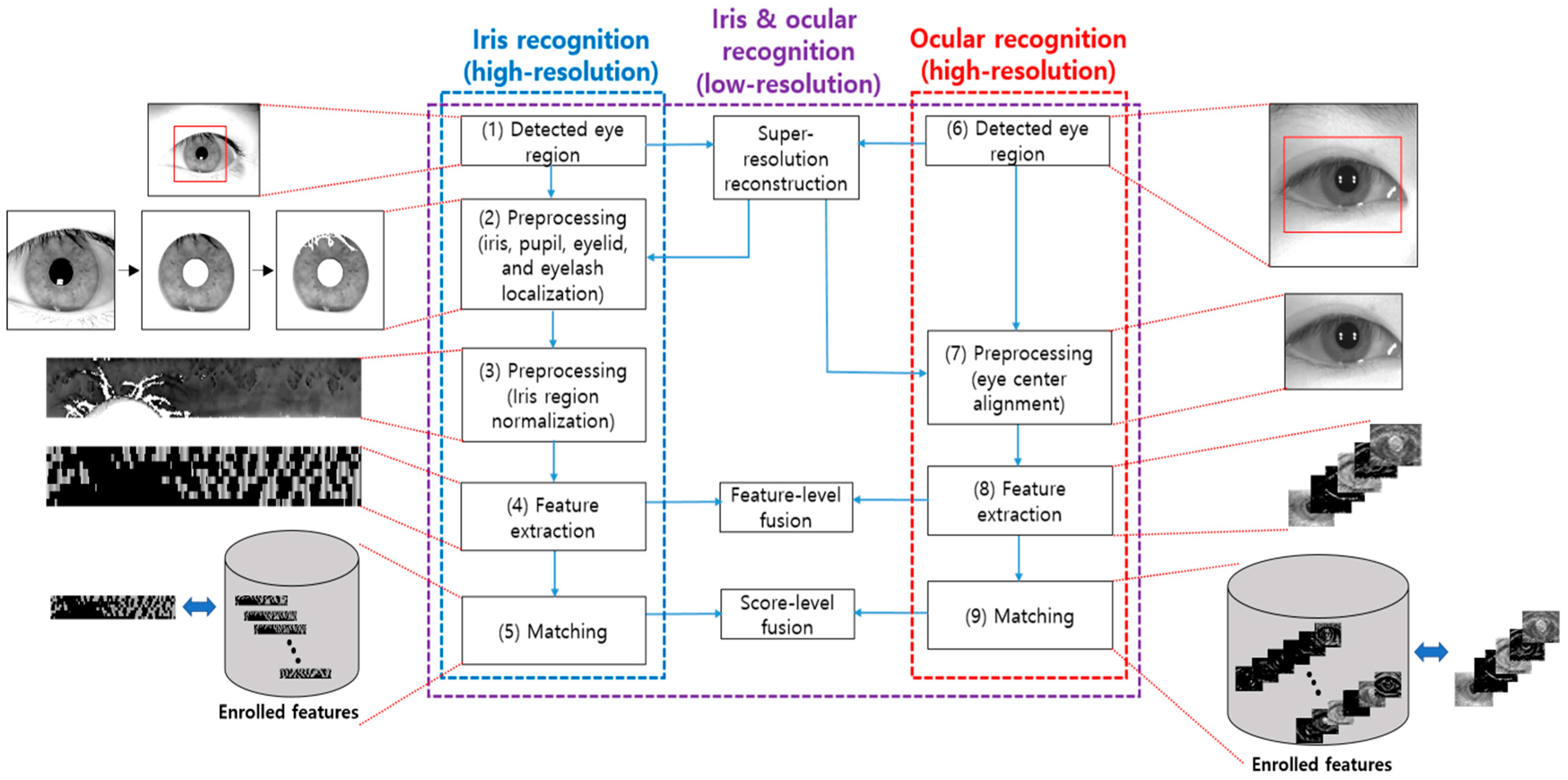
- To supplement the drawbacks of iris and ocular recognition, their information may be combined and used, as shown in the dashed purple box in Figure 2. To this end, as shown in Figure 2, PCA and linear discriminant analysis (LDA) feature-level fusion methods are used with feature sets respectively extracted from the iris and ocular recognition systems. Score-level fusion methods based on the weighted SUM, weighted PRODUCT, and SVM could also be used with the matching scores obtained from each recognition system. In general, compared to using iris or ocular recognition alone, multimodal biometrics combined with them produce a higher recognition performance. Conventional multimodal biometrics, such as face + fingerprint and iris + fingerprint, are less convenient for subjects because biometric information is input twice. However, iris + ocular recognition is highly convenient because both types of biometric information can be obtained simultaneously from a single high-resolution camera. When using a low-resolution camera, it is difficult to obtain the iris + ocular information simultaneously from a single image. Therefore, the constraint arises that either a high-resolution camera or two aligned cameras (one each for the iris image and the ocular image) must be used simultaneously. In the future, additional research should be conducted to overcome this constraint.
3. Iris and Ocular Recognition Methods with Low-Resolution Images
3.1. Iris Recognition Methods with Low-Resolution Images
3.1.1. Image Processing Method
3.1.2. Machine Learning Method
3.1.3. Deep Learning Method
3.2. Ocular Recognition Methods with Low-Resolution Images
Deep Learning Method
3.3. Analysis and Discussions
- –
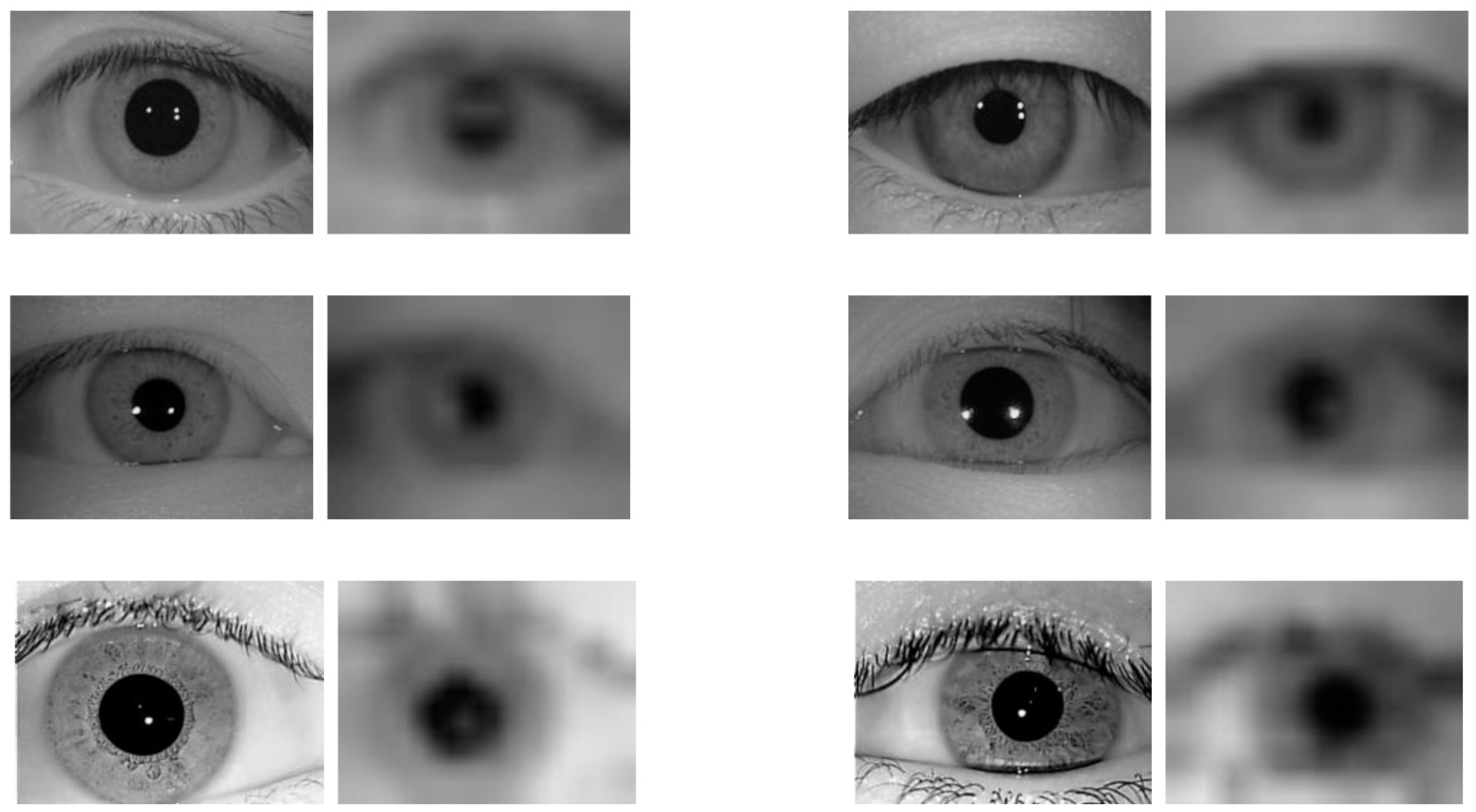
- Basically, even if low-resolution images are downscaled from high-resolution images, much information is lost, causing difficulty in reconstructing high-resolution images using only the low-resolution images’ information. Therefore, a database containing both low and high-resolution images is needed when implementing a reconstruction method.
- –
- Deep learning SR research requires a database consisting of many images because the deep learning models must be trained. However, because of privacy concerns due to the characteristics of biometric images, many images, especially low-resolution images, are difficult to obtain. Consequently, artificial augmentation methods are used but may lead to overfitting in training. Therefore, alternative methods must be studied to solve this problem.
- –
- Most SR method studies have often used conventional methods such as PSNR or SSIM to evaluate the quality of reconstructed images. However, when these are used, whether an image has been properly reconstructed is difficult to evaluate because it cannot be known whether the image has been reconstructed. Therefore, for accurate recognition performance, methods should be researched to determine the degree to which an image has been reconstructed.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chanda, K. Password security: An analysis of password strengths and vulnerabilities. Int. J. Comput. Netw. Inform. Secur. 2016, 8, 23. [Google Scholar] [CrossRef] [Green Version]
- Choudhury, B.; Then, P.; Issac, B.; Raman, V.; Haldar, M.K. A survey on biometrics and cancelable biometrics systems. Int. J. Image Graph. 2018, 18, 1850006. [Google Scholar] [CrossRef] [Green Version]
- Ali, M.M.; Mahale, V.H.; Yannawar, P.; Gaikwad, A.T. Overview of fingerprint recognition system. In Proceedings of the IEEE International Conference on Electrical, Electronics, and Optimization Techniques, Chennai, India, 3–5 March 2016; pp. 1334–1338. [Google Scholar]
- Wu, W.; Elliott, S.J.; Lin, S.; Sun, S.; Tang, Y. Review of palm vein recognition. IET Biom. 2019, 9, 1–10. [Google Scholar] [CrossRef]
- Sapkale, M.; Rajbhoj, S.M. A biometric authentication system based on finger vein recognition. In Proceedings of the IEEE International Conference on Inventive Computation Technologies, Coimbatore, India, 26–27 August 2016; pp. 1–4. [Google Scholar]
- Adiraju, R.V.; Masanipalli, K.K.; Reddy, T.D.; Pedapalli, R.; Chundru, S.; Panigrahy, A.K. An extensive survey on finger and palm vein recognition system. Mater. Today 2021, 45, 1804–1808. [Google Scholar] [CrossRef]
- Hadid, A.; Evans, N.; Marcel, S.; Fierrez, J. Biometrics systems under spoofing attack: An evaluation methodology and lessons learned. IEEE Signal Process. Mag. 2015, 32, 20–30. [Google Scholar] [CrossRef] [Green Version]
- Kortli, Y.; Jridi, M.; Al Falou, A.; Atri, M. Face recognition systems: A survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef] [Green Version]
- Nigam, I.; Vatsa, M.; Singh, R. Ocular biometrics: A survey of modalities and fusion approaches. Inf. Fusion 2015, 26, 1–35. [Google Scholar] [CrossRef]
- Rattani, A.; Derakhshani, R. Ocular biometrics in the visible spectrum: A survey. Image Vis. Comput. 2017, 59, 1–16. [Google Scholar] [CrossRef]
- Khaldi, Y.; Benzaoui, A.; Ouahabi, A.; Jacques, S.; Taleb-Ahmed, A. Ear recognition based on deep unsupervised active learning. IEEE Sens. J. 2021, 21, 20704–20713. [Google Scholar] [CrossRef]
- Daugman, J. Information theory and the iriscode. IEEE Trans. Inf. Forensic Secur. 2015, 11, 400–409. [Google Scholar] [CrossRef] [Green Version]
- ISO/IEC 19794-6; Information Technology, Biometric Data Interchange Formats—Iris Image Data. ISO: Geneva, Switzerland, 2005.
- Matey, J.R.; Naroditsky, O.; Hanna, K.; Kolczynski, R.; LoIacono, D.; Mangru, S.; Tinker, M.; Zappia, T.; Zhao, W.Y. Iris on the move: Acquisition of images for iris recognition in less constrained environments. Proc. IEEE 2006, 94, 1936–1946. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems, Lake Tehoe, NV, USA, 3–8 December 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Wang, Z.; Chen, J.; Hoi, S.C. Deep learning for image super-resolution: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3365–3387. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Thomas, T.; George, A.; Devi, K.I. Effective iris recognition system. Procedia Technol. 2016, 25, 464–472. [Google Scholar] [CrossRef] [Green Version]
- Ak, T.A.; Steluta, A. An iris recognition system using a new method of iris localization. Int. J. Open Inform. Technol. 2021, 9, 67–76. [Google Scholar]
- Frucci, M.; Nappi, M.; Riccio, D.; di Baja, G.S. WIRE: Watershed based iris recognition. Pattern Recognit. 2016, 52, 148–159. [Google Scholar] [CrossRef]
- Singh, G.; Singh, R.K.; Saha, R.; Agarwal, N. IWT based iris recognition for image authentication. In Proceedings of the International Conference on Computing and Network Communications, Trivandrum, India, 18–21 December 2019; pp. 1–9. [Google Scholar]
- Thumwarin, P.; Chitanont, N.; Matsuura, T. Iris recognition based on dynamics radius matching of iris image. In Proceedings of the International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Phetchaburi, Thailand, 16–18 May 2012; pp. 1–4. [Google Scholar]
- Salve, S.S.; Narote, S.P. Iris recognition using SVM and ANN. In Proceedings of the International Conference on Wireless Communications, Signal Processing and Networking, Chennai, India, 23–25 March 2016; pp. 474–478. [Google Scholar]
- Nalla, P.R.; Kumar, A. Toward more accurate iris recognition using cross-spectral matching. IEEE Trans. Image Process. 2016, 26, 208–221. [Google Scholar] [CrossRef]
- Adamović, S.; Miškovic, V.; Maček, N.; Milosavljević, M.; Šarac, M.; Saračević, M.; Gnjatovićec, M. An efficient novel approach for iris recognition based on stylometric features and machine learning techniques. Futur. Gener. Comp. Syst. 2020, 107, 144–157. [Google Scholar] [CrossRef]
- Gangwar, A.; Joshi, A. DeepIrisNet: Deep iris representation with applications in iris recognition and cross-sensor iris recognition. In Proceedings of the IEEE international conference on image processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 2301–2305. [Google Scholar]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation functions: Comparison of trends in practice and research for deep learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Zhao, Z.; Kumar, A. Towards more accurate iris recognition using deeply learned spatially corresponding features. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3809–3818. [Google Scholar]
- Wang, K.; Kumar, A. Toward more accurate iris recognition using dilated residual features. IEEE Trans. Inf. Forensic Secur. 2019, 14, 3233–3245. [Google Scholar] [CrossRef]
- Minaee, S.; Abdolrashidiy, A.; Wang, Y. An experimental study of deep convolutional features for iris recognition. In Proceedings of the IEEE Signal Processing in Medicine and Biology Symposium, Philadelphia, PA, USA, 3 December 2016; pp. 1–6. [Google Scholar]
- Zhao, T.; Liu, Y.; Huo, G.; Zhu, X. A deep learning iris recognition method based on capsule network architecture. IEEE Access 2019, 7, 49691–49701. [Google Scholar] [CrossRef]
- Lee, M.B.; Kim, Y.H.; Park, K.R. Conditional generative adversarial network-based data augmentation for enhancement of iris recognition accuracy. IEEE Access 2019, 7, 122134–122152. [Google Scholar] [CrossRef]
- Wang, K.; Kumar, A. Cross-spectral iris recognition using CNN and supervised discrete hashing. Pattern Recognit. 2019, 86, 85–98. [Google Scholar] [CrossRef]
- Tahir, A.A.; Anghelus, S. An accurate and fast method for eyelid detection. Int. J. Biom. 2020, 12, 163–178. [Google Scholar] [CrossRef]
- Zhao, Z.; Ajay, K. An accurate iris segmentation framework under relaxed imaging constraints using total variation model. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3828–3836. [Google Scholar]
- Parizi, R.M.; Dehghantanha, A.; Choo, K.K.R. Towards better ocular recognition for secure real-world applications. In Proceedings of the 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering, New York, NY, USA, 1–3 August 2018; pp. 277–282. [Google Scholar]
- Vyas, R.; Kanumuri, T.; Sheoran, G.; Dubey, P. Towards ocular recognition through local image descriptors. In Proceedings of the International Conference on Computer Vision and Image Processing, Jaipur, India, 27–29 September 2019; pp. 3–12. [Google Scholar]
- Liu, P.; Guo, J.M.; Tseng, S.H.; Wong, K.; Lee, J.D.; Yao, C.C.; Zhu, D. Ocular recognition for blinking eyes. IEEE Trans. Image Process. 2017, 26, 5070–5081. [Google Scholar] [CrossRef]
- Lee, Y.W.; Kim, K.W.; Hoang, T.M.; Arsalan, M.; Park, K.R. Deep residual CNN-based ocular recognition based on rough pupil detection in the images by NIR camera sensor. Sensors 2019, 19, 842. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reddy, N.; Rattani, A.; Derakhshani, R. Ocularnet: Deep patch-based ocular biometric recognition. In Proceedings of the IEEE International Symposium on Technologies for Homeland Security, Woburn, MA, USA, 23–24 October 2018; pp. 1–6. [Google Scholar]
- Reddy, N.; Rattani, A.; Derakhshani, R. Robust subject-invariant feature learning for ocular biometrics in visible spectrum. In Proceedings of the IEEE 10th International Conference on Biometrics Theory, Applications and Systems, Tampa, FL, USA, 23–26 September 2019; pp. 1–9. [Google Scholar]
- Vizoni, M.V.; Marana, A.N. Ocular recognition using deep features for identity authentication. In Proceedings of the International Conference on Systems, Signals and Image Processing, Niteroi, Brazil, 1–3 July 2020; pp. 155–160. [Google Scholar]
- Zanlorensi, L.A.; Lucio, D.R.; Britto, A.D.S., Jr.; Proença, H.; Menotti, D. Deep representations for cross-spectral ocular biometrics. IET Biom. 2020, 9, 68–77. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Pearson Education: London, UK, 2008. [Google Scholar]
- Stathaki, T. Image Fusion: Algorithms and Applications; Academic Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Salomon, D. Data Compression: The Complete Reference, 4th ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality evaluation: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Liu, N.; Liu, J.; Sun, Z.; Tan, T. A code-level approach to heterogeneous iris recognition. IEEE Trans. Inf. Forensic Secur. 2017, 12, 2373–2386. [Google Scholar] [CrossRef]
- Deshpande, A.; Patavardhan, P.P. Super resolution and recognition of long range captured multi-frame iris images. IET Biom. 2017, 6, 360–368. [Google Scholar] [CrossRef]
- Alonso-Fernandez, F.; Farrugia, R.A.; Bigun, J. Eigen-patch iris super-resolution for iris recognition improvement. In Proceedings of the European Signal Processing Conference, Nice, France, 31 August–4 September 2015; pp. 1–5. [Google Scholar]
- Alonso-Fernandez, F.; Farrugia, R.A.; Bigun, J. Very low-resolution iris recognition via eigen-patch super-resolution and matcher fusion. In Proceedings of the International Conference on Biometrics Theory, Applications and Systems, Niagara Falls, NY, USA, 6–9 September 2016; pp. 1–8. [Google Scholar]
- Deshpande, A.; Patavardhan, P.P.; Rao, D.H. Super-resolution for iris feature extraction. In Proceedings of the International Conference on Computational Intelligence and Computing Research, Coimbatore, India, 18–20 December 2014; pp. 1–4. [Google Scholar]
- Jillela, R.; Ross, A.; Flynn, P.J. Information fusion in low-resolution iris videos using principal components transform. In Proceedings of the Workshop on Applications of Computer Vision, Kona, HI, USA, 5–7 January 2011; pp. 1–8. [Google Scholar]
- Liu, J.; Sun, Z.; Tan, T. Code-level information fusion of low-resolution iris image sequences for personal identification at a distance. In Proceedings of the International Conference on Biometrics: Theory, Applications and Systems, Arlington, VA, USA, 29 September–2 October 2013; pp. 1–6. [Google Scholar]
- Alonso-Fernandez, F.; Farrugia, R.A.; Bigum, J. Iris super-resolution using iterative neighbor embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1–9. [Google Scholar]
- Zhang, Q.; Li, H.; Sun, Z.; He, Z.; Tan, T. Exploring complementary features for iris recognition on mobile devices. In Proceedings of the International Conference on Biometrics, Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Ribeiro, E.; Uhl, A.; Alonso-Fernandez, F.; Farrugia, R.A. Exploring deep learning image super-resolution for iris recognition. In Proceedings of the 25th European Signal Processing Conference, Kos Island, Greece, 28 August–2 September 2017; pp. 2176–2180. [Google Scholar]
- Ribeiro, E.; Uhl, A.; Alonso-Fernandez, F. Iris super-resolution using CNNs: Is photo-realism important to iris recognition? IET Biom. 2019, 8, 69–78. [Google Scholar] [CrossRef] [Green Version]
- Kashihara, K. Iris recognition for biometrics based on CNN with super-resolution GAN. In Proceedings of the IEEE Conference on Evolving and Adaptive Intelligent Systems, Bari, Italy, 27–29 May 2020; pp. 1–6. [Google Scholar]
- Ribeiro, E.; Uhl, A.; Alonso-Fernandez, F. Super-resolution and image re-projection for iris recognition. In Proceedings of the IEEE 5th International Conference on Identity, Security, and Behavior Analysis, Hyderabad, India, 22–24 January 2019; pp. 1–7. [Google Scholar]
- Guo, Y.; Wang, Q.; Huang, H.; Zheng, X.; He, Z. Adversarial iris super resolution. In Proceedings of the International Conference on Biometrics, Crete, Greece, 4–7 June 2019; pp. 1–8. [Google Scholar]
- Mostofa, M.; Mohamadi, S.; Dawson, J.; Nasrabadi, N.M. Deep GAN-based cross-spectral cross-resolution iris recognition. IEEE Trans. Biomet. Behav. Identity Sci. 2021, 3, 443–463. [Google Scholar] [CrossRef]
- Ipe, V.M.; Thomas, T. Periocular recognition under unconstrained conditions using CNN-based super-resolution. In Proceedings of the International Conference on Advanced Communication and Networking, Rabat, Morocco, 12–14 April 2019; pp. 235–246. [Google Scholar]
- Tapia, J.; Gomez-Barrero, M.; Lara, R.; Valenzuela, A.; Busch, C. Selfie periocular verification using an efficient super-resolution approach. arXiv 2021, arXiv:2102.08449. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Approach | Ref. | Illum. | Segmentation Methods | Recognition Methods | Performance | Databases | Pros | Cons |
|---|---|---|---|---|---|---|---|---|
| Image processing-based | [20] | NIR | RANSAC | PSLR * | Only graphs exist, and no accuracy is reported | WVU | Ellipse fitting algorithm with RANSAC enables accurate pupil detection | The remaining process is similar to the existing methods, and a specific performance table is not provided |
| [21] | NIR | R-C-E-S [36] | Hamming distance * | Accuracy and EER of 96.48% and 1.76% (CASIA v1), 95.1% and 2.45% (CASIA v4), 93.6% and 3.2% (SDMULA) | CASIA (v1, v4 Lamp), SDUMLA-HMT | Can accurately detect pupil region unaffected by specular reflection using morphological filtering, and define iris ROI by canny edge detector and Hough transform | Requires a high-resolution image with detectable edges | |
| [22] | Visible | Watershed | Hamming distance, cosine distance * | Measured decidability of 2.0335 (UBIRISv1), 1.3850 (UBIRISv2) | UBIRIS v1 session 2, Subset of UBIRIS v2 | Can define iris ROI region even in a noisy visible environment | Inconclusive that accurate iris ROI provides high recognition performance in noisy images, and implementation is complicated | |
| [23] | NIR | Handcrafted segmentation algorithm | Integer wavelet transform (IWT) | EER of 0.12% | UBIRIS v2 | Not require additional computation devices (e.g., GPU) | High performance of iris segmentation is needed | |
| [24] | NIR | Dynamic radius matching | Accuracy of 94.89% | CASIA v1.0 | Can be used when the size of the iris region is variable | This method is based on gray pixel values, so preprocessed image is required (e.g., removing specular reflection) | ||
| Machine learning-based | [25] | NIR | Canny edge detector and Hough transform | SVM or ANN * | SVM classification Accuracy of 94.6% (polynomial kernel), 95.9% (RBF kernel) | CASIA-iris-v4 Interval, Lamp, Syn, Thousand, and Twins | Performance is less affected by test data than by image processing method | The number of test images is small and the test is conducted in a closed-world scenario |
| [26] | Visible + NIR | Handcrafted segmentation algorithm | EDA-NBNN * | Bi-spectral iris recognition (EER) of 3.97% (NIR), 6.56% (Visible) | IIIT-D CLI, ND Cross sensor 2012 iris, PolyU cross-spectral iris | Can use cross-spectral images from a learning-based feature | Performance is not much higher than single spectral recognition | |
| [27] | NIR | Handcrafted segmentation algorithm | OneR, J48, SMO, MultiboostAB, Random Forest, Support Vector Classification, Gradient Boosting | Accuracies of 0.9926~0.9997 (CASIA-iris-v4) | CASIA-iris-v4 MMU, IITD | Reduces the computation costs and increase the ability of discrimination by using the Base64 encoder for feature extraction | Preprocessing is still required, and it raises a security problem which comes from the small number of iris codes | |
| Deep learning-based | [28] | NIR | Osiris | DeepIrisNet * | EER on two merged databases of 1.82% | ND-iris-0405, ND-CrossSensor-Iris-2013 | Exhibits high accuracy based on deep features | Requires input image to be preprocessed |
| [30] | NIR | Relative total variation-L (RTV-L) [37] | Triplet-loss with Two FCN * | EER of 0.99% (ND-iris-0405), 3.85% (CASIA-iris-v4 distance), 0.64% (IITD), 2.28% (WVU Non-ideal) | ND-iris-0405, CASIA-iris-v4 Distance, IITD iris, WVU Non-ideal | Extracts more sophisticated features using two CNNs | Performance is affected by Daugman’s rubber-sheet model | |
| [31] | NIR | Haar cascade eye detector | DRFNet with ETL * | EER of 1.30% (ND-iris-0405), 4.91% (CASIA-iris-v4 distance), 1.91% (WVU Non-ideal) | ND-iris-0405, CASIA-iris-v4 Distance, WVU | Uses more spatial features by dilated convolution | Requires converting iris image to Daugman’s rubber-sheet model by preprocessing | |
| [32] | NIR | No segmentation | VGG feature extraction-based iris recognition | Accuracy of 99.4% | CASIA-iris-v4, Thousand, IITD iris | Requires no iris segmentation | Uses a conventional VGG-16 model for feature extraction | |
| [33] | NIR | Handcrafted segmentation algorithm | Capsule network architectures | Accuracy of 99.37% and EER of 0.039% (JluV3.1), Accuracy of 98.88 and EER of 0.295% (JluV4), Accuracy of 93.87% and EER of 1.17% (CASIA-iris-V4 Lamp) | JluV3.1, JluV4, CASIA-iris-v4 Lamp | Outstanding performances have been shown | Preprocessing and sophisticated algorithm implementation are needed | |
| [34] | Visible | Three CNNs | EER of 8.58% (NICE-II), EER of 16.41% (MICHE), EER of 2.96% (CASIA-iris-v4 Distance) | NICE-II, MICHE, CASIA-iris-v4 Distance | Shows the better performances using the data augmentation based on the deep generative model to the noisy images | Requires more computational costs because that needs preprocessing, data augmentation, and three CNNs | ||
| [35] | Visible +NIR | CNN and SDH | EER of 5.39% | PolyU cross-spectral iris | Achieves a more accurate performance using CNN while reducing the size of iris template by supervised discrete hashing | Preprocessing for input images and additional training of supervised discrete hashing parameters are required |
| Approach | Ref. | Illum. | Regions | Feature Extraction | Recognition Methods | Performance | Databases | Pros | Cons |
|---|---|---|---|---|---|---|---|---|---|
| Image processing-based | [39] | NIR, visible | Periocular, iris, ocular | Statistical or transform-based feature descriptor | Same or cross-spectral matching | EER of 4.87% (visible to visible match), 6.36% (NIR to NIR match), 16.92% (visible to NIR match) | Cross-Eyed | Implements cross-spectral periocular, iris, and ocular recognition | Cannot achieve high performance because features are handcrafted |
| Machine learning-based | [40] | Visible | Ocular, skin texture, eyelids | ULBP, WT-LBP, geometric features, the probabilities of eyelids single- or double-fold, and combinations of these methods | SVM | F1 score of 0.9969 (“lights” subset), 0.868 (“Yale face database), 0.8694 (MBGC database), 0.8108 (FRGC 2.0 database) | “lights” subset of CMU PIE, Yale Face, MBGC, FRGC v2.0 | Offers high performance by multiple combinations of feature extraction and SVM | The combination of specific algorithms is required |
| Deep learning-based | [41] | NIR | Ocular | Deep residual CNN | Feature extraction by CNN and Euclidean distance matching | EER of 2.1625% (CASIA-iris-Distance), 1.595% (CASIA-iris-Lamp), 1.331% (CASIA-iris-Thousand) | CASIA-iris-v4 Distance, Lamp, Thousand | Achieve a high accuracy without accurate segmentation by deep residual CNN | High-resolution input is required and huge dataset is needed for training the model |
| [42] | NIR | Ocular | PatchNet based on landmark points | Euclidean distance matching | EER of 16.04% (Cross-Eyed), 10.22% (UBIRIS-I), 10.41% (UBIRIS-II) | UBIRIS-I, UBIRIS-II, Cross-Eyed | Exploits various ocular features by dividing region patches and CNNs | Each patch requires a CNN, which increases memory and computational costs | |
| [43] | Visible | Ocular | Autoencoder with EFL and KL divergence | Matches cosine similarity or Hamming distance | EER of 14.46% (VISOB database with Resnet-50 fine-tuned on UBIRIS-II, UBIPr, MICHE) | UBIRIS-II, UBIPr, MICHE, VISOB | Demonstrates high accuracy by EFL loss and modified autoencoder | Input size is limited and conversion to grayscale is required | |
| [44] | Visible | Ocular | CNN (ResNet50, VGG16, VGG19, etc.) | Cosine distance or Euclidean distance matching | EER of 3.18% (SVM), 12.74% (cosine distance), 15.25% (Euclidean distance) | UBIPr | High recognition accuracy and reliability using the pairwise approach | Performance enhancement is limited by conventional CNNs | |
| [45] | NIR, visible | Periocular, Iris | CNN, feature fusion | Cosine distance matching | EER on cross-spectral and iris-periocular fusion by Resnet-50 of 0.49% (PolyU), 1.4% (Cross-Eyed) | PolyU, Cross-Eyed | Many experiments are done in various cross-spectral environments, which confirm good accuracy | Insufficient analysis of experimental results |
| Approach | Ref. | Illum. | SR and Feature Extraction Method | Recognition Method | Performance | Databases | Pros | Cons |
|---|---|---|---|---|---|---|---|---|
| Image processing-based | [50] | NIR | Modified Markov networks | Code-level feature matching | EER is plotted only in the figure. 98.74% (GAR@FARs = 10−3) 95.94% (GAR@FARs = 10−4) | Q-FIRE, Notre Dame database | Resolution-independent recognition by modified Markov network | Still requires Daugman’s rubber-sheet model |
| [51] | NIR | GPR, EIBP | Neural network classifier | Accuracy of 96.14 | CASIA-iris-database | Reduces the image acquisition difficulty by using multi-frame images | Implementation is difficult and it needs much preprocessing | |
| [52] | NIR | Eigen-path hallucination | 1-D Gabor filter | EER of 0.66% (downscale ×1/6, patch size ×1/32) | CASIA-iris-Interval v3 | Not require a huge datasets | Not much restores the image of very low-resolution | |
| [53] | NIR | Eigen-transformation | Log-Gabor filter, SIFT | EER of under 6% (Log-Gabor filter), under 8% (SIFT), under 5% (Log-Gabor+SIFT) | CASIA-iris-Interval v3 | Adopts preprocessing and eigen-transformation compared to [52] | It still shows the low performance when reconstructing high-resolution images on very low-resolution | |
| [54] | NIR | Papoulis-Gerchberg (PG) and projection on to convex sets (POCS) | Gray Level Co-occurrence Matrix (GLCM) | Not reports as specific measurements | CASIA-iris-database | Simple and it shows faster processing | It just enhances the image edges and features on the polar iris images not low-resolution | |
| [55] | NIR | Principal components transform | Template matching | EER of 1.76% | Multi-Biometric Grand Challenge (MBGC) | Image level fusion and principal components transform show the better performance | Requires the image sequences (e.g., videos), and preprocessing | |
| Machine learning-based | [56] | NIR | Markov network model | Hamming distance matching | EER of close to 0.9% (at FAR@GAR = 10−2, code-level fusion) | Q-FIRE | Robust to the image noises because image features are transformed into iris code | Cannot exactly know whether the images are correctly restored, and specific measurement results are not reported. Moreover, preprocessing is still required |
| [57] | NIR | Multi-layer Locality-Constrained Iterative neighbor embedding (M-LINE) | Log-Gabor filter, SIFT | EER of under 4% (Log-Gabor filter), under 3.6% fusion of Log-Gabor filter and SIFT) | CASIA-iris-Interval v3 | Obtains high performances using learning-based method compared to previous method [53] | Bigger size of images is not tested. It is good if the experiments are performed using bigger high-resolution and smaller low-resolution images | |
| Deep learning-based | [58] | NIR | Pairwise CNN | Ordinal measures features, pairwise features | EER of 0.64%, 0.69%, and 1.05% (20–20 cm, 20–25 cm, 20–30 cm) | Newly composed database on the mobile device | Obtains the high performance using ordinal features and pairwise features | Needs preprocessing of detection for eye region and converting polar image |
| [59] | NIR | CNN with three convolutional layers | Normalized Hamming distance | EER (downscale ×1/4, 1/8, 1/16) of 0.68%, 1.41%, 11.46%, respectively | CASIA-iris-v3 Interval | Obtains higher accuracy by stacked autoencoder | Shows low accuracy in cases of very low downscaling rates | |
| [60] | NIR | VDCNN, SRCNN, and SRGAN | WAHET, QSW, CG | EER (downscale ×1/2, ×1/16) of 3.78%, 32.03% (VDCNN), 3.84%, 30.17% (SRCNN), 4.27%, 38.41% (SRGAN) on CASIA-iris-Interval database, respectively | CASIA-iris-v3 Interval, Lamp (v4), UBIRIS v2, Notre Dame, etc. | Various experiments are conducted according to downscaling rates, architectures, and databases | Does not demonstrate high SR performance in cases of very low downscaling rates | |
| [61] | Visible | Fast-SRGAN (SRGAN custom for iris SR) | DCNN | ANOVA significant difference (F(9,40) = 39.47; p < 0.01). | UBIRIS v1 | Deep learning-based classifier shows good accuracy | Entirely restored images are not shown and the experiment with very low downscaling rates is not conducted | |
| [62] | Visible, NIR | VDCNN, DCSCN, SRGAN | Log-Gabor filter and SIFT fusion | EER of 5.37%, 8.86%, 5.52% (VDCNN, DCSCN, SRGAN), respectively | CASIA-iris-v3 Interval, DTD, VSSIRIS | Repeated image input according to upscaling factor simplifies implementation | SIFT shows low performance at every scaling factor | |
| [63] | NIR | IrisDnet | LightCNN29 and SIFT | EER (downscale ×2, ×4, ×8) 1.25%, 1.70%, 5.70% (CASIA-iris-V1), 3.75%, 4.17%. 8.09% (Thousand), respectively | CASIA-iris-V1, Thousand | Obtains a good accuracy by LightCNN26 and IrisDnet | Structurally, two additional CNNs are used, which leads to increased computation | |
| [64] | Visible + NIR | cpGAN | Euclidean distance matching | EER of 1.28%, 1.31% (on the cross-resolution and cross-spectral) | PolyU, WVU databases | Supports iris recognition on the cross-spectral and cross-resolution based on conditional GAN | Still requires iris segmentation to whole processing and needs high computational costs |
| Approach | Ref. | Illum. | SR and Feature Extraction Method | Recognition Method | Performance | Databases | Pros | Cons |
|---|---|---|---|---|---|---|---|---|
| Deep learning-based | [65] | Visible | VDSR, AlexNet | SVM classifier | Rank-1 accuracy 91.47% | UBIRIS v2 | Implements the end-to-end method by connecting VDSR, AlexNet, and SVM classifiers | Only the SVM classification performance is presented |
| [66] | Visible | DCSCN, WDSR-A, SRGAN, ESISR | FaceNet, VGG-FACE | EER of 8.90% (ESISR ×3) 9.90% (ESISR ×4), respectively | Selfie database by Samsung device, Set-5E, MOBIO | Shows good recognition accuracy with images in noisy mobile environments, with low computational load | Only focuses on noise improvement without conducting experiments in a low-resolution image environment |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.W.; Park, K.R. Recent Iris and Ocular Recognition Methods in High- and Low-Resolution Images: A Survey. Mathematics 2022, 10, 2063. https://doi.org/10.3390/math10122063
Lee YW, Park KR. Recent Iris and Ocular Recognition Methods in High- and Low-Resolution Images: A Survey. Mathematics. 2022; 10(12):2063. https://doi.org/10.3390/math10122063
Chicago/Turabian StyleLee, Young Won, and Kang Ryoung Park. 2022. "Recent Iris and Ocular Recognition Methods in High- and Low-Resolution Images: A Survey" Mathematics 10, no. 12: 2063. https://doi.org/10.3390/math10122063