
Safety Margin Prediction Algorithms Based on Linear Regression Analysis Estimates



Abstract
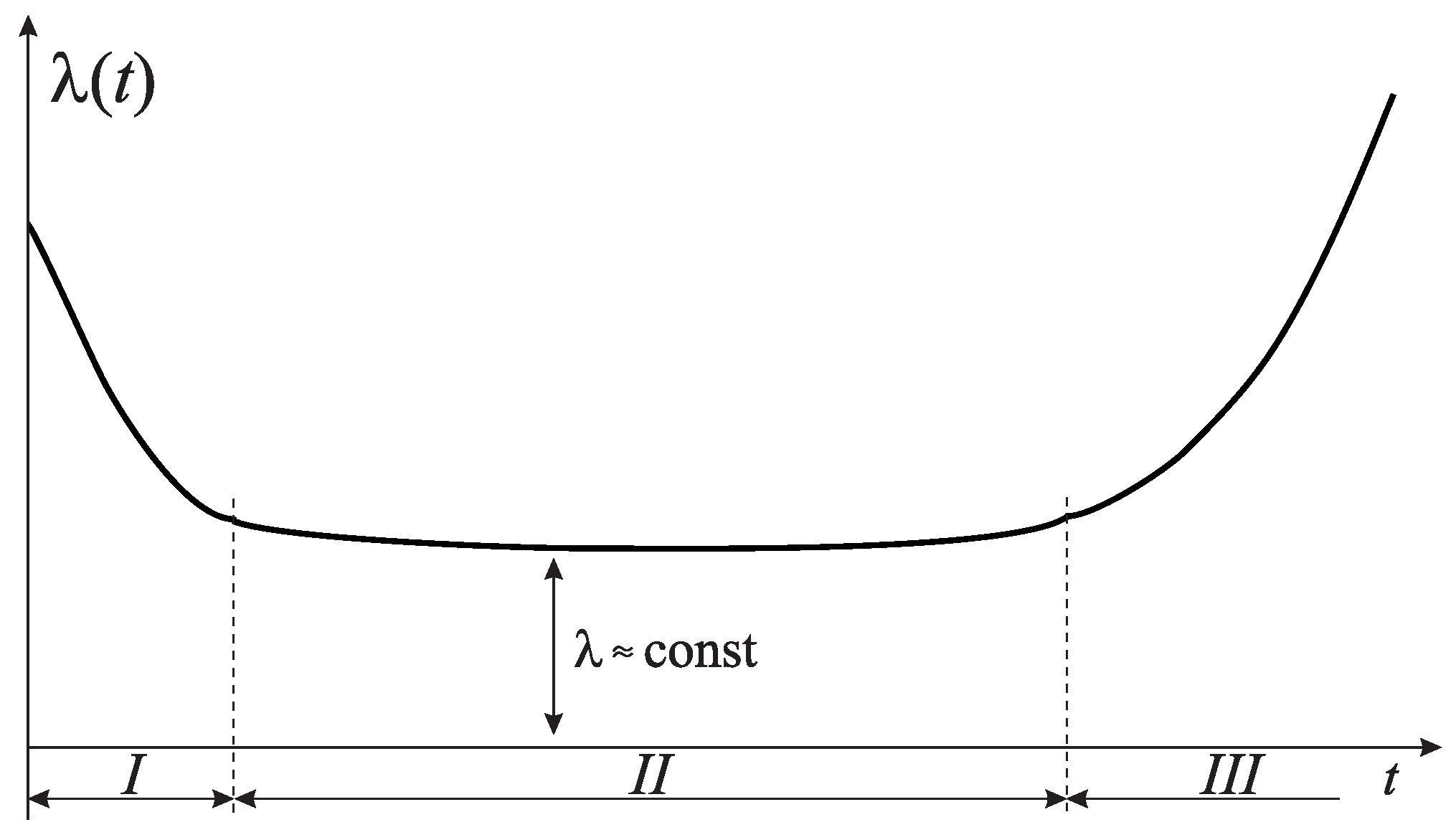
:1. Introduction
2. Calculation of Coefficients of a Polynomial
3. Estimation of the Values of the Polynomial and Its Derivatives from Inaccurate Observations
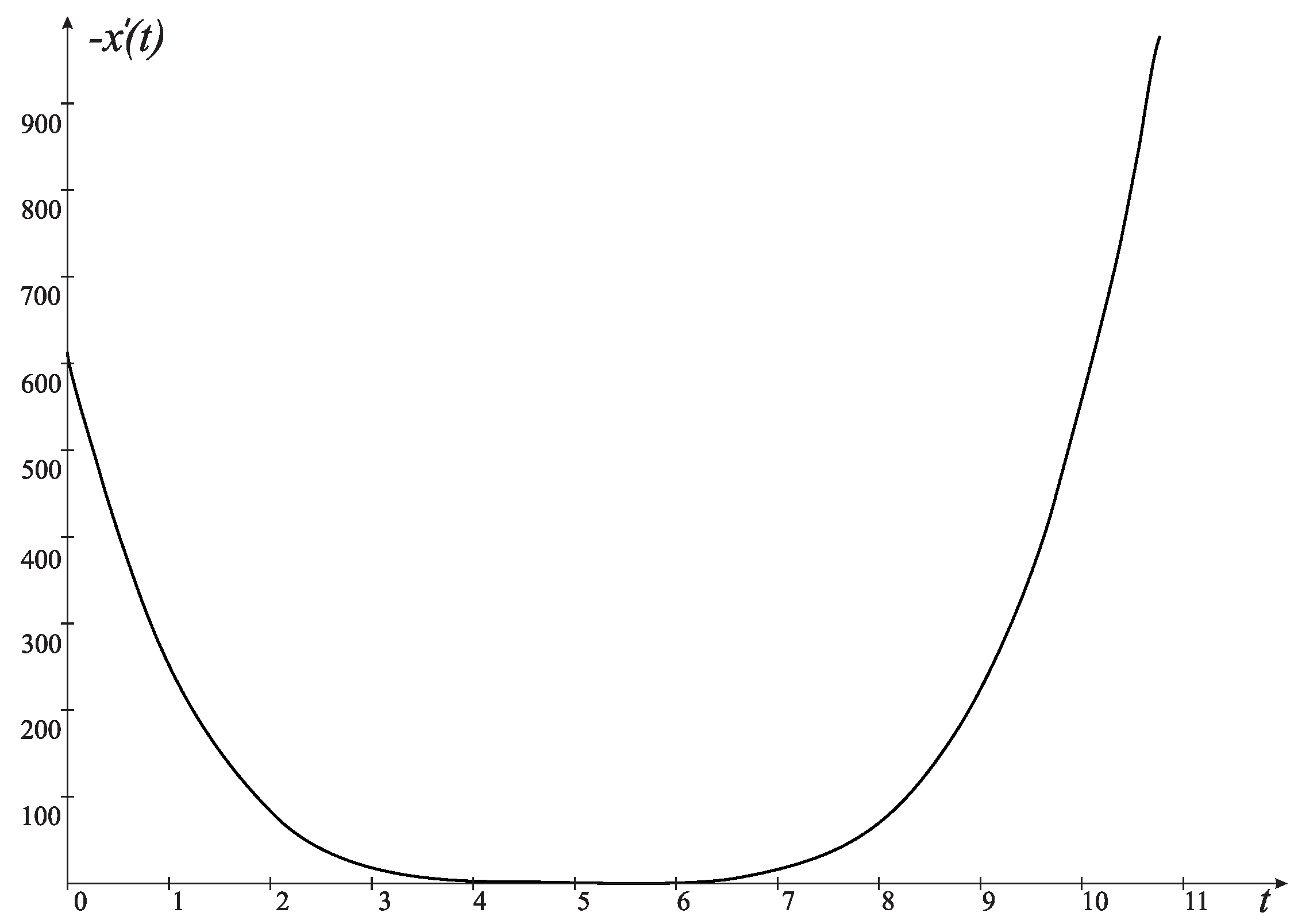
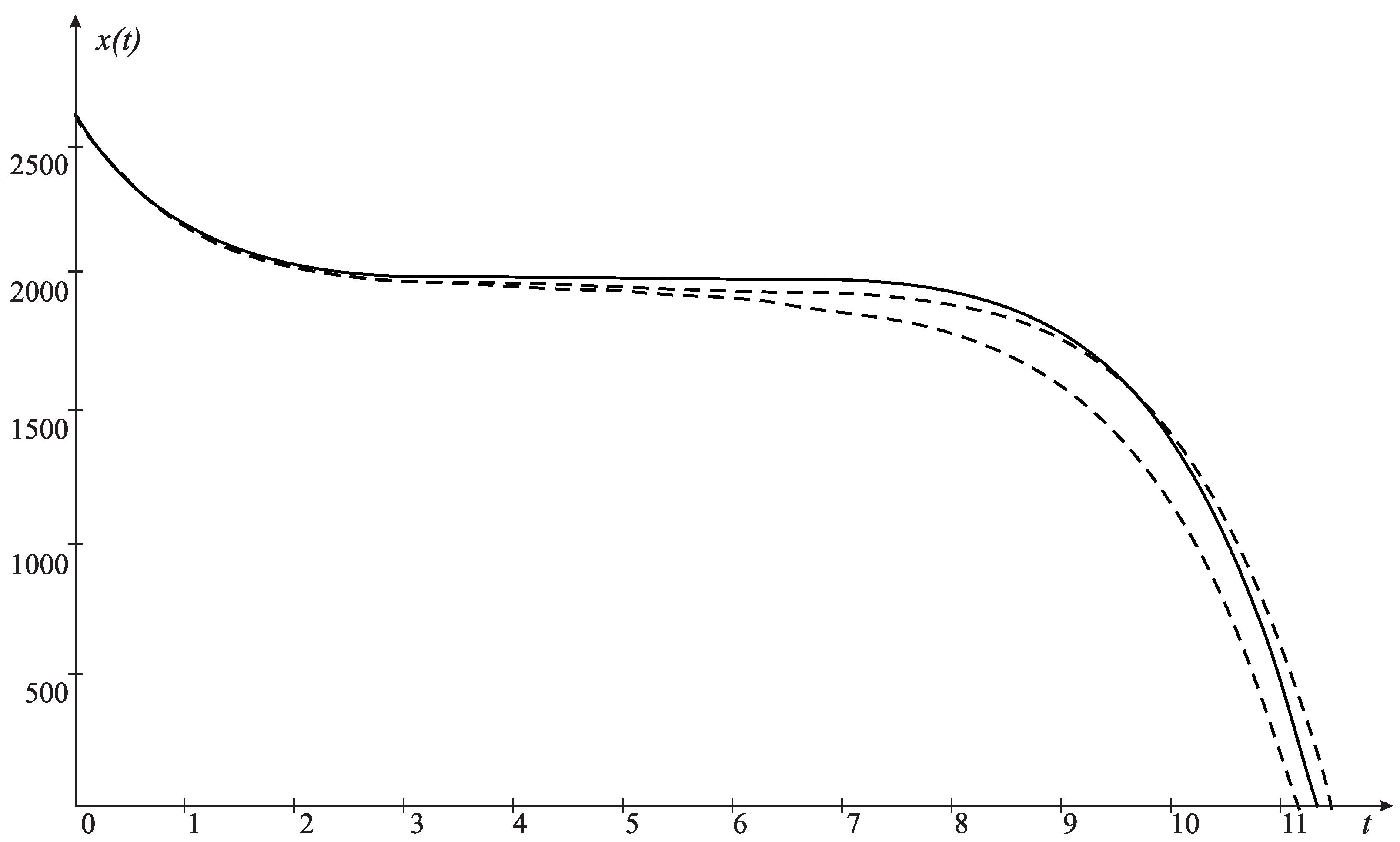
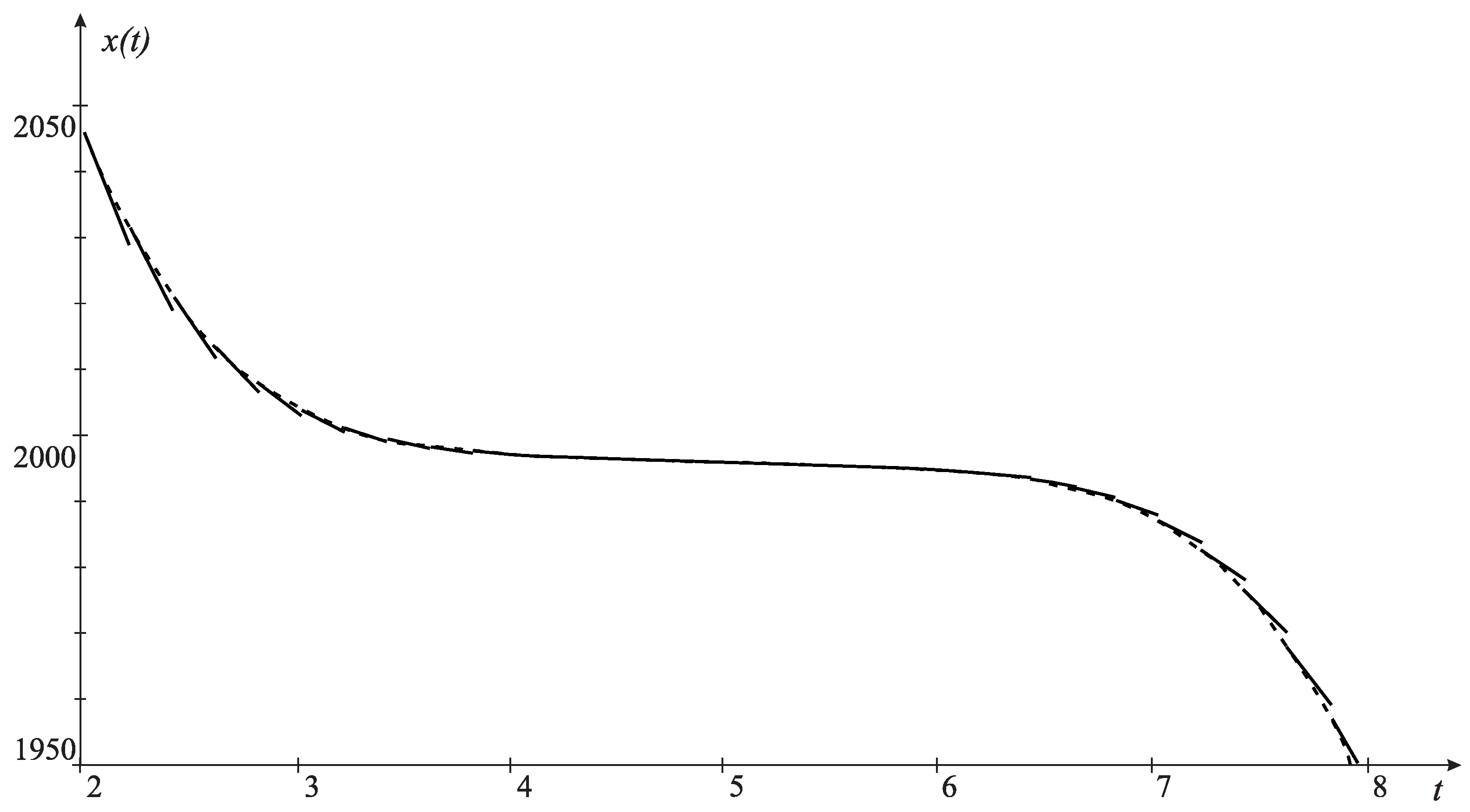
4. Computational Experiments
5. Conclusions
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Proschan, F. Theoretical Explanation of Observed Decreasing Failure Rate. Technometrics 1963, 5, 375–383. [Google Scholar] [CrossRef]
- Barlow, R.; Proschan, F. Mathematical Theory of Reliability; J. Wixey and Sons: New York, NY, USA, 1965. [Google Scholar]
- Finkelstein, M. Failure Rate Modelling for Reliability and Risk; Springer Series in Reliability Engineering; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–84. [Google Scholar]
- Goble, W.M.; Van Beurden, I. Safety Instrumented System Design: Techniques and Design Verification; International Society of Automation: New York, NY, USA, 2018. [Google Scholar]
- Chen, K.; Xin, L.; Peng, L.; Leon, Z.J. News-induced Dynamic Networks for Market Signaling: Understanding Impact of News on Firm Equity Value. Inf. Syst. Res. 2021, 32, 356–377. [Google Scholar] [CrossRef]
- Feng, J.; Xin, L.; Zhang, X.M. On-line Product Reviews-Triggered Dynamic Pricing: Theory and Evidence. Inf. Syst. Res. 2019, 30, 1107–1123. [Google Scholar] [CrossRef]
- Wang, F.K. A new model with bathtub-shaped failure rate using an additive Burr XII distribution. Reliab. Eng. Syst. Saf. 2000, 70, 305–312. [Google Scholar] [CrossRef]
- Almalki, S.J.; Yuan, J.S. A new modified Weibull distribution. Reliab. Eng. Syst. Saf. 2013, 111, 164–170. [Google Scholar] [CrossRef]
- Ahmad, A.B.; Ghazal, M.G.M. Exponentiated additive Weibull distribution. Reliab. Eng. Syst. Saf. 2020, 193, 106663. [Google Scholar] [CrossRef]
- Shakhatreh, M.K.; Lemonte, A.J.; Moreno–Arenas, G. The log-normal modified Weibull distribution and its reliability implications. Reliab. Eng. Syst. Saf. 2019, 188, 6–22. [Google Scholar] [CrossRef]
- Izvekov, Y.A.; Gugina, E.M.; Shemetova, V.V. Analysis and evaluation of technogenic risk of technological equipment of metallurgical enterprises. IOP Conf. Ser. Mater. Sci. Eng. 2018, 451, 012177. [Google Scholar] [CrossRef]
- Molarius, R. Managing Technogenic Risks with Stakeholder Cooperation. In Risk Assessment; Sergeev Institute of Environment Geoscience, Russian Academy of Sciences: Moscow, Russia, 2018; pp. 189–203. [Google Scholar]
- Zhdanov, V.; Kosolapov, A.; Ibragimova, F. The concept of technogenic risks of a mining transport complex as a tool of lowering the level of its ecological load. E3S Web Conf. 2021, 315, 03017. [Google Scholar] [CrossRef]
- Pilotto, A.; Boi, R.; Petermans, J. Technology in geriatrics. Age Ageing 2018, 47, 771–774. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abramov, O.; Dimitrov, B. Reliability Design in Gradual Failures: A Functional Parametric Approach. Reliab. Theory Appl. 2017, 4, 39–48. [Google Scholar]
- Abramov, O.V. On the Assessment of the Probability of Occurrence of a Risk Event: A Functional-Parametric Approach. Reliab. Qual. Complex Syst. 2016, 1, 24–31. (In Russian) [Google Scholar]
- Abramov, O.V.; Nazarov, D.A. A Software System for Acceptability Region Construction and Analysis. In Proceedings of the 3rd Russian-Pacific Conference on Computer Technology and Applications (RPC), Vladivistok, Russia, 18–25 August 2018; pp. 1–6. [Google Scholar]
- Abramov, O.V.; Tsitsiashvili, G.S. Forecasting the moment of failure of a controlled technical system. Informatics Control. Syst. 2018, 3, 42–49. (In Russian) [Google Scholar]
- Tsitsiashvili, G.S.; Osipova, M.A. Variances of Linear Regression Coefficients for Safety Margin of Technical System. Reliab. Theory Appl. 2020, 15, 57–62. [Google Scholar]
- Shih-Kung, L. Planning Behaviour. Theories and Experiments; Cambridge Scholars Publishing: Cambridge, UK, 2019. [Google Scholar]
- Husin, S.F.; Mamat, M.; Ibrahim, M.A.H.; Rivaie, M. An Efficient Three-Term Iterative Method for Estimating Linear Approximation Models in Regression Analysis. Mathematics 2020, 8, 977. [Google Scholar] [CrossRef]
- Tsitsiashvili, G.S.; Osipova, M.A.; Kharchenko, Y.N. Estimating the Coefficients of a System of Ordinary Differential Equations Based on Inaccurate Observations. Mathematics 2022, 10, 502. [Google Scholar] [CrossRef]
- Grcar, J.F. How ordinary elimination became Gaussian elimination. Hist. Math. 2011, 38, 163–218. [Google Scholar] [CrossRef] [Green Version]
- Pan, V.; Reif, J. Technology Report TR-02-85; Harvard University Center for Research in Computing: Cambridge, MA, USA; Aiken Computation Laboratory: Cambridge, UK, 1985. [Google Scholar]
- Horn, R.A.; Johnson, C.R. Topics in Matrix Analysis; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar]
- Schabauer, H.; Pacher, C.; Sunderland, A.G.; Gansterer, W.N. Toward a parallel solver for generalized complex symmetric eigenvalue problems. Procedia Comput. Sci. 2010, 1, 437–445. [Google Scholar] [CrossRef] [Green Version]
- Bernstein, D. Matrix Mathematics; Princeton University Press: Princeton, NJ, USA, 2005. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distribution | Relative | Distribution | Relative |
| Intervals | Frequencies | Intervals | Frequencies |
| (2626.02318; 2626.02326) | 0.076 | (−26.00609; −26.00434) | 0.040 |
| (2626.02326; 2626.02334) | 0.440 | (−26.00434; −26.00259) | 0.280 |
| (2626.02334; 2626.02341) | 0.376 | (−26.00259; −26.00085) | 0.484 |
| (2626.02341; 2626.02349) | 0.102 | (−26.00085; −25.99910) | 0.174 |
| (2626.02349; 2626.02357) | 0.006 | (−25.99910; −25.99736) | 0.022 |
| Distribution | Relative | Distribution | Relative |
| Intervals | Frequencies | Intervals | Frequencies |
| (4.93801; 4.96285) | 0.030 | (−0.39637; −0.37248) | 0.022 |
| (4.96285; 4.98770) | 0.280 | (−0.37248; −0.34810) | 0.156 |
| (4.98770; 5.01254) | 0.492 | (−0.34810; −0.32472) | 0.474 |
| (5.01254; 5.03739) | 0.176 | (−0.32472; −0.30083) | 0.298 |
| (5.03739; 5.06223) | 0.022 | (−0.30083; −0.27695) | 0.050 |
| Distribution | Relative | Distribution | Relative |
| Intervals | Frequencies | Intervals | Frequencies |
| (2626.26350; 2626.26352) | 0.027 | (−626.09609; −626.09557) | 0.043 |
| (2626.26352; 2626.26353) | 0.221 | (−626.09557; −626.09506) | 0.270 |
| (2626.26353; 2626.26354) | 0.483 | (−626.09506; −626.09455) | 0.455 |
| (2626.26354; 2626.26356) | 0.243 | (−626.09455; −626.09403) | 0.201 |
| (2626.26356; 2626.26357) | 0.026 | (−626.09403; −626.09352) | 0.031 |
| Distribution | Relative | Distribution | Relative |
| Intervals | Frequencies | Intervals | Frequencies |
| (250.03414; 250.03838) | 0.041 | (−50.17271; −50.16861) | 0.031 |
| (250.03838; 250.04262) | 0.271 | (−50.16861; −50.16451) | 0.169 |
| (250.04262; 250.04686) | 0.458 | (−50.16451; −50.16041) | 0.441 |
| (250.04686; 250.05110) | 0.203 | (−50.16041; −50.15631) | 0.289 |
| (250.05110; 250.05534) | 0.027 | (−50.15631; −50.15221) | 0.070 |
| Distribution | Relative | Distribution | Relative |
| Intervals | Frequencies | Intervals | Frequencies |
| (4.94005; 4.94861) | 0.034 | (−0.19552; −0.19550) | 0.031 |
| (4.94861; 4.95717) | 0.287 | (−0.19550; −0.19548) | 0.333 |
| (4.95717; 4.96572) | 0.495 | (−0.19548; −0.19547) | 0.521 |
| (4.96572; 4.97428) | 0.175 | (−0.19547; −0.19545) | 0.112 |
| (4.97428; 4.98284) | 0.009 | (−0.19545; −0.19543) | 0.003 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsitsiashvili, G.; Losev, A. Safety Margin Prediction Algorithms Based on Linear Regression Analysis Estimates. Mathematics 2022, 10, 2008. https://doi.org/10.3390/math10122008
Tsitsiashvili G, Losev A. Safety Margin Prediction Algorithms Based on Linear Regression Analysis Estimates. Mathematics. 2022; 10(12):2008. https://doi.org/10.3390/math10122008
Chicago/Turabian StyleTsitsiashvili, Gurami, and Alexandr Losev. 2022. "Safety Margin Prediction Algorithms Based on Linear Regression Analysis Estimates" Mathematics 10, no. 12: 2008. https://doi.org/10.3390/math10122008