This section is dedicated to providing the results on the binary supervised classification problem introduced in
Section 1, in which we aim to predict whether or not a CFIR construct is assigned to a given fragment of the transcription of the focus group of the PVS Programme. This was accomplished making use of four well-known supervised classification methods detailed in
Section 4.2: logistic LASSO regularisation [
10], the C5.0 decision tree [
9], artificial neural networks, and support vector machines [
31]. We refer to them simply as LASSO, decision tree, ANNs, and SVM, respectively. We also made use of the naive Bayes classifier [
8] and linear LASSO [
26], but the results were not competitive. We do not report them in this paper; however, they are available from the authors upon request.
In order to apply the supervised classification methodology, we first divided the dataset into training and test sets. In doing so, we considered the chronological order of the text fragments and not a random order, as is common in the literature. This is because our aim was to study the extent to which it is necessary to manually code the participant transcription. Therefore, we used as the training set different percentages of the studied dataset and increased them by enforcing the order of their occurrence in the transcription. In other words, we are interested in determining the percentage of text fragments that need to be manually coded so that the labels of the remaining percentage of text fragments can be predicted with a high success rate using supervised classification methods. In the following, we explain this formally.
A further preprocess was performed on the fragments to transform them into numerical features. This is a common preprocess, which was explained in [
7]. However, to make this paper self-contained, we describe it in
Section 4.1. Let
denote the amount of unique words in the training set. Then, according to this preprocess, for each
is transformed into a vector in
containing the
tf–idf scores (see Equation (
1)) of the
g unique words in
computed within the
j-th text fragment. The resulting
t vectors in
are the input features of the supervised classification methods. Consequently, the training set can be represented by a
matrix, whose rows are the
g-dimensional vectors representing the different text fragments
together with their corresponding labels. For example, if we consider the training set consisting of the first 5% of text fragments of the original dataset, we have 9 text fragments and a total of 155 unique words. In addition, we have 3 text fragments that have been labelled with a 1, and the remaining 6 fragments have been labelled with a 0. Therefore, we can represent the collection of text fragments
as a
matrix.
5.1. Initial Analysis
Table 5 and
Table 6 show the results of applying the four classification models under consideration. Columns 3 to 5 of
Table 5 report the results for the LASSO and Columns 6 to 8 for the decision tree. On the other hand, Columns 3 to 5 of
Table 6 report the results for the ANN and Columns 6 to 8 for the SVM. For each of these models and each percentage of the dataset in the training set (first column), the accuracy (third and sixth columns), the area under the ROC curve (AUC; fourth and seventh columns), and kappa statistics (fifth and eighth columns) corresponding to the test set are reported. These are well-known metrics; however, their definitions are provided in
Section 4.3.
Before proceeding, we should mention that after an optimisation process of the parameters defining the neural network, we chose a topology consisting of two hidden layers in addition to the input and output layers. It was found that the best results were obtained when there were
neurons in each hidden layer, where
g is the number of unique words in the training set. Note that
g is reported in the second column of
Table 6. There, we can observe that for
of the fragments in the training set,
Thus, in this case, there are two hidden layers, each with 424 neurons.
It is observable from
Table 5 and
Table 6 that the three reported metrics generally improve as the size of the training set increases. This is to be expected, because at each increment, the training set has about nine new text fragments (third column of
Table 4), resulting in an information gain that potentially improves the predictions of the models.
Similarly, an increase in the number of unique words defining the dimension of the vectors in the training set (second column of
Table 5 and
Table 6) can be observed as the percentage increases. As mentioned in
Section 4.1, the whole dataset consists of 1024 unique words in total. Note that if 5% of the dataset is used as the training set, the total number of unique words is 155, which is approximately 15% of the unique words in the whole dataset. Furthermore, if 90% of the dataset is used for training, there are 957 unique words, which is more than 93% of the unique words in the entire dataset.
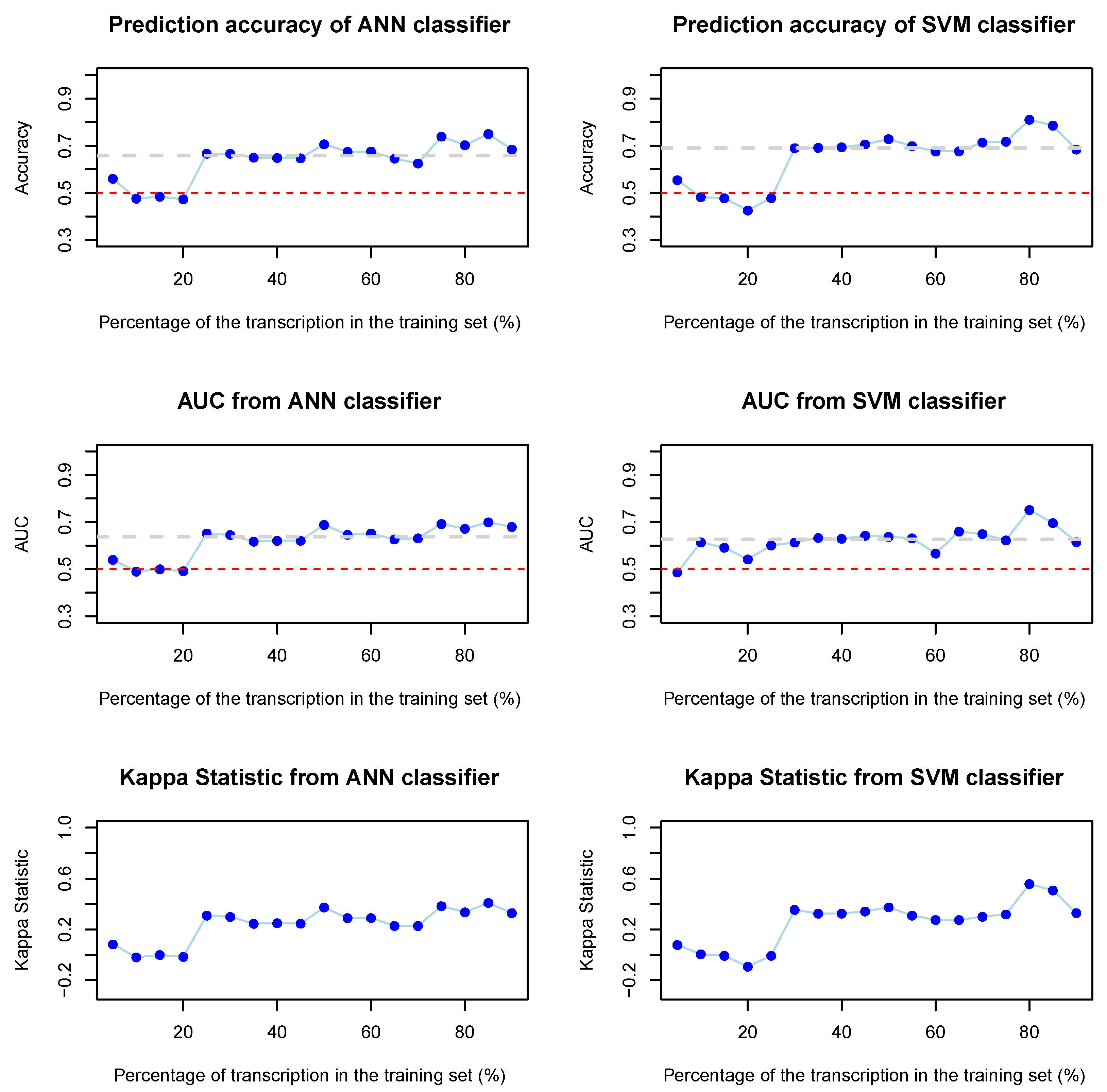
The results in
Table 5 and
Table 6 are also displayed in
Figure 2 and
Figure 3, respectively, for better visualisation and comparison. The left column plots of
Figure 2 account for the LASSO classifier results, while the right ones for the decision tree. Analogously, the plots in the left column of
Figure 3 refer to the results of the ANN, while the right column represents the results of the SVM. For each of these classifiers, we plot the evolution of the prediction accuracy (first row), the area under the curve (second row), and the kappa statistic (third row) as the percentage of the dataset in the training set (ordinate axis) increases. The red dashed lines in the plots symbolise the worst-case scenario in which the classifier has no predictive value, i.e., an accuracy of 50% and an AUC of 0.5. Moreover, the light grey dashed line represents the obtained median values of the displayed metric. The latter coloured lines are not shown in the graphs of the kappa statistic because this metric is much more subjective than the other two in the sense that there is no exact point representing the case where the classifier has no predictive value. Furthermore, this metric is only useful for tracking possible random assignments for a given case, which results in its median not being very informative.
The LASSO classifier provides a median accuracy of 80.7% and a median AUC of 0.85. Despite some isolated downshifts, we observe a general improvement in the latter performance metrics as the amount of training samples increases. When we take a look at the plot of the kappa statistic of the LASSO classifier (first column, last row plot), we notice that the downshifts in the previous metrics are accompanied by a decrease in the kappa statistic. Thus, in these particular cases, the probability of a random match is higher, leading to a worsening of the predictions.
It is also worth noting that these drops in the performance metrics occur more frequently as the percentage of training samples increases. In some way, this makes sense, because, as the cardinality of the training set increases, the cardinality of the test set decreases while containing a high percentage of short text fragments. This increases the probability of the random assignment of test samples, because, occasionally, none of their words appear in the set of unique words of the training set.
To exemplify the above reasoning, if the training set is 70% of the original dataset, as reported in the second column of
Table 4, we have that
and
. Thus, there are 56 text fragments in the test set and 23 that consist of less than 5 words (see the fifth column of
Table 4). Among the 23,
are two text fragments in the test set whose words are not in the set of unique words within the training set. Thus, they are classified at random because their representation is the null vector. However, when considering 80% of the dataset as the training set, the text fragment
although still in the test set, does have words in the set of unique words within the training set. Thus, no random classification occurs.
In the case of LASSO, it is noteworthy that for training sets consisting of more than 55% of the original dataset, the accuracy and AUC values computed in the test samples at issue are higher than the median values. The same is true for the SVM classifier applied to training sets with more than 50% of all text fragments. According to the conventions proposed in
Section 4.3, the classification is excellent in terms of the AUC and substantial with regard to the kappa statistic.
On the other hand, the median prediction accuracy of the decision tree algorithm is 71.2% and the median AUC is 0.67. Just as in the case of the LASSO classifier, we observed some downshifts in the performance metrics, which are more pronounced this time. Once again, this behaviour can be explained by the evolution of the values of the kappa statistic.
Regarding the performance of the ANN, it is worth mentioning that it provides a median prediction accuracy of 70% and a median AUC of 0.67. These results are very similar to those of the decision tree, with the main difference being that the downshifts are now smoother. There is also a clearer tendency for the ANN to improve over the decision trees as the training set increases. However, the ANN cannot outperform LASSO, even when the training set is large. In addition, it was verified that ANNs are more time consuming than the other methods studied in this manuscript, since a huge number of parameters need to be adjusted.
As for SVM, it is a method that generally performs well. In particular, the median accuracy is 77% and the median AUC is 0.82, which means that SVM significantly outperforms both the decision tree and the ANN. Even more remarkable is the stability of the method, as evidenced by the absence of downward trends in the metrics examined, particularly in the kappa statistic. In fact, both the prediction accuracy and the AUC values for the SVM monotonically increase when the percentage of text fragments used as the training set increases.
Having said that, the performance of the LASSO classifier is better than that of the decision tree and ANN classifiers (in agreement with the performance metrics analysed in this manuscript). In order to find a reason for this fact, we resorted to the mathematical foundations of these classification methods. The main advantage of the LASSO classifier, which is not implemented in the decision tree algorithm nor in the ANN, is feature selection. As reported in the second column of
Table 5 and
Table 6, the dimension of the features used to feed our classification models ranges from 155 to 957, depending on the percentage chosen as the training set. This means that we are working with high-dimensional spaces, up to dimension 957. While the LASSO method alone is able to select the features that are more discriminative for the analysis by shrinking to zero some beta coefficients in Equation (
2) of
Section 4, this is not the case for the decision tree algorithm or ANN. This results in the tree not growing properly when it is decided to split upon certain features that may not be too relevant in the corpus or whose discriminative power is not as strong. Something similar happens with the ANN, where these non-informative variables contribute to making decisions based on noise. Furthermore, the LASSO regularisation helps to generalise better to new observations [
7], which may explain the better performance of LASSO over the decision tree algorithm or ANN when evaluating the test samples.
In summary, both LASSO and SVM perform quite well on this dataset, the performance of SVM being comparable to that of LASSO. In particular, LASSO is slightly better in the 55–65% range, while SVM is better in the 70–90% range.
5.2. Analysis with Filtering
It is well known that not all words in a certain corpus contain the same amount of information, nor do they have the same discriminative power. Thus, a possible solution to this excess of irrelevant features is to filter the set of words in the analysis by removing the so-called stop words. The concept of stop words, coined by Hans Peter Luhn in 1960 [
37], refers to common words that carry little or no significant information [
7]. These words—typically determiners, articles, prepositions, and/or conjunctions—are stored in what we call a stop list and are usually filtered out before any task of processing data coming from natural language. Keeping in mind that there is no a universal stop list, we used the list of Spanish stop words available in the
tm (acronym for Text Mining) R package [
38].
Removing the stop words from the original dataset drastically reduces the number of unique words used to compute our input features, i.e., the dimension of the vectors containing the tf–idf statistics. Our dataset originally contained 1024 unique words, but after filtering out the stop words, the number of unique words decreased to 883. Specifically, the stop words accounted for more than 10% of the original set of unique words.
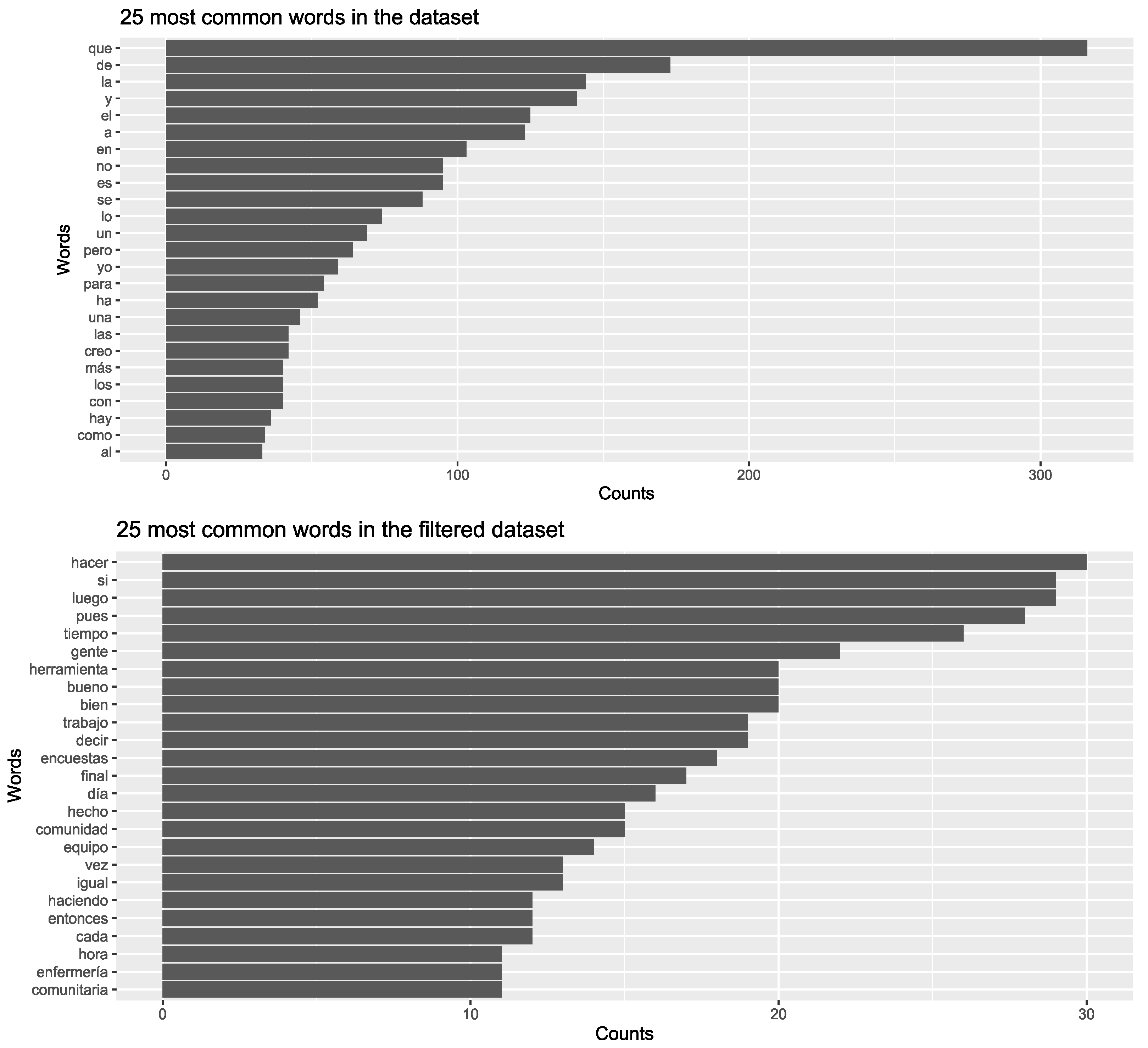
In
Figure 4, we plot the 25 most common words in our dataset before (top plot) and after (bottom plot) filtering out the stop words. Not only do we see that the raw counts (horizontal axis) of most frequent words decreases dramatically (from hundreds to dozens), but also that the frequency of the words that passed the filter is similar. While there were words in the original dataset that repeated significantly more frequently than others, the most frequent words in the filtered dataset occur more or less equally often in the corpus, i.e., they are quite balanced. As will be seen below, this filtering of the dataset will improve the performance of the C5.0 decision tree algorithm by avoiding splitting because of words that contain little information and/or are irrelevant in the corpus.
In addition to removing stop words, further limiting the number of words in the analysis would be an added bonus for the decision tree methodology. Indeed, restricting the number of words before calculating the tf–idf statistics would result in a much simpler model by not creating too many variables (dimension reduction) that sometimes contain irrelevant information.
It should be noted, however, that filtering the dataset is a double-edged sword, especially in a problem where the categories are defined by context. Indeed, it may happen that reducing the number of unique words helps to build a less complex method, but the price is the loss of information. Sometimes, this loss of information leads to a degradation in the performance of some classifiers. We will see below that this is precisely what happens for the LASSO, ANN, and SVM classifiers applied to the dataset under study.
Next, we performed another analysis, keeping only the 100 most-frequent words of the dataset after filtering out the stop words. The results are listed in
Table 7 and
Table 8, which are similar in structure to
Table 5 and
Table 6, respectively. Note that the performance metrics generally improve as the size of the training set increases, except for some isolated downshifts due to the same reasons explained for the unfiltered case. These results are illustrated in
Figure 5 and
Figure 6, which again have the same format as
Figure 2 and
Figure 3.
In comparison to the non-filtered case, less sharp downshifts are seen in the plots of
Figure 5 and
Figure 6, with the exception of the SVM classifier. However, it is worth noticing no superior behaviour in the median within the analysed performance metrics, neither for LASSO, nor for the decision tree, ANN, or SVM. On the one hand, LASSO yields a median accuracy of 74.6% and a median AUC of 0.72, whereas the decision tree produces a median accuracy of 72.8% (just slightly higher than the unfiltered case) and a median AUC of 0.66. On the other hand, the median values of accuracy and AUC for ANN are 66% and 0.64, respectively, while the SVM classifier yields a median accuracy of 69% and a median AUC of 0.63. This clearly indicates that ANNs and SVMs perform significantly worse when filtering the dataset. Despite this, from
Figure 5, we see that the performance of the decision tree classifier has clearly improved, as expected, for high percentages with respect to that of
Figure 2. In light of the above, the LASSO and decision tree classifiers can be considered as roughly acceptable with respect to the AUC and moderate in terms of the kappa statistic in the filtered case, whereas the ANN and SVM are poor with regard to AUC and fair in terms of the kappa statistic (see
Section 4.3). When the filtered and unfiltered cases are compared at each percentage, we observe that the prediction accuracy and the AUC for the LASSO, ANN, and SVM are slightly higher before filtering out the stop words. One explanation for this is that we actually lose information when we reduce the number of features in our analysis. Indeed, we took out some words from our original dataset that we assumed are generally irrelevant, but might be important in context, especially in an analysis such as that conducted in this manuscript, where the categories are abstractions of what is being said. Since the LASSO classifier itself is capable of performing feature selection—and therefore, can manage larger datasets with less risk than decision trees, ANNs and SVMs—this manual filtering does not make the difference. In fact, it follows from the data available that the results are marginally worse.
We also performed the analysis by filtering out only the stop words, without limiting the number of unique words in the model to the 100 most-frequent words in the dataset. The results are not reported here because they do not represent a large improvement and are somewhat worse for the LASSO and SVM as random assignments slightly increase. We attributed this to the fact that, when ordering the words from most frequent to less, the words from 101 to the less-frequent ones are uncommon in the corpus. In fact, their absolute frequency in the entire corpus is less than five counts, so their tf–idf statistics are small (close to zero). Thus, the fact that these words increase the dimensionality of the problem while having low discriminative power results in an increase of the probability of random classification.
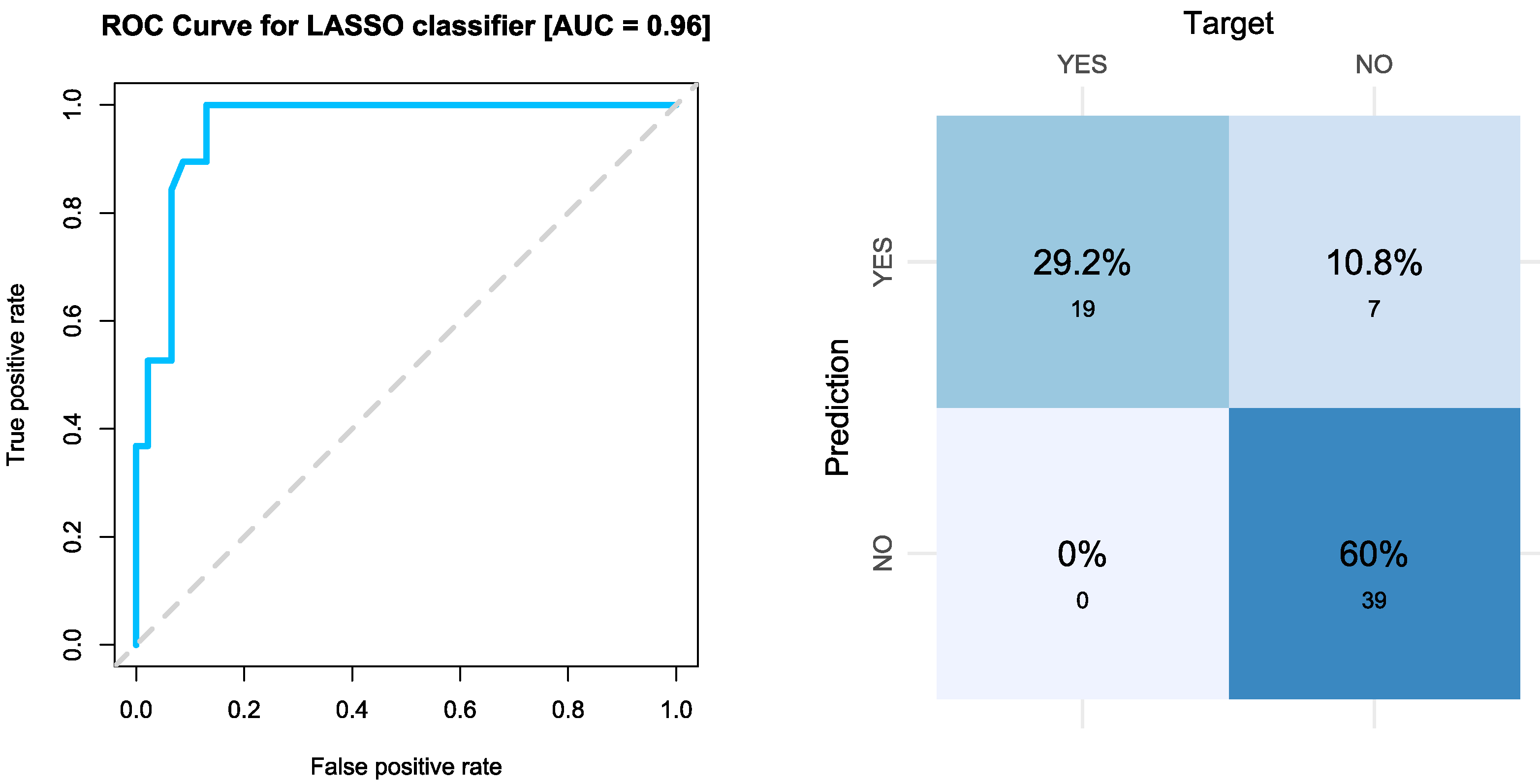
Even though the performance of the decision tree algorithm improved after filtering the dataset, the LASSO classifier without filtering appears to be the most appropriate method to deal with our initial binary classification problem. Indeed, the results obtained with LASSO are remarkably good and outperform even those obtained with the ANN and SVM, since after analysing and hand labelling only 65% of the unfiltered dataset, we can predict the labels of the 35% remaining text fragments with over 88% accuracy. The goodness of this classification is justified with an AUC of 0.96 (outstanding discrimination between classes) and a value for the kappa statistic of 0.77 (substantial strength of the agreement), as indicated in
Table 5.
Finally, as an example,
Figure 7 shows the ROC curve (left plot) and the confusion matrix (right plot) when evaluating the test samples
in the model trained using the LASSO method and 65% of the original dataset. We can observe that there are no false negatives. This is particularly good in practice as the fragments that should be classified by the coders are all in the set of fragments predicted as containing a CFIR construct.
It is worth noting that LASSO was chosen because it is the method that provides the better performance with a lower percentage of participant transcription used as the training set. The reason is that our main goal is to find out to what extent it is necessary to manually code the text fragments in order to predict the remaining ones in an acceptable way. If we were looking for better prediction in classification, regardless of the amount of transcript to be read, the SVM would be the best candidate since its performance is higher in the 70–90% range of transcription used in the training set.
The proposed methodology has some limitations that we aim to tackle in future work. In particular, (i) to obtain the text fragments in
Section 3, we made use of the pieces labelled by the trained coders. (ii) That the procedure allows saving time is only true if the fragments can be coded with validity outside of the contextual text that is being ignored. We justify them in that this work is a first venture into analysing this type of dataset from a statistical point of view. It is our understanding that these limitations can be solved by making use of whole paragraphs and not only of fragments of them. However, this would require having a larger amount of paragraphs, which in turn would allow extending this analysis to multi-classification methods to predict whether a text fragment belongs to one of the five possible domains proposed in the CFIR framework, rather than limiting ourselves to merely detecting the presence of any CFIR construct. Furthermore, it is worth noticing that the performed supervised classifications can be considered as problems in the high-dimensional misspecified binary classification framework, as the required assumptions have not been checked. This is a framework studied in [
39] for the particular case of logistic regression.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}