2.1. Forecasting Stock Market through Emotions
Numerous fascinating investigations have been undertaken on this topic by researchers. Some of the analyses have shown positive findings, while others have yielded less than ideal results. One research [
5] discovered an essential link between the stock price of Microsoft and its tweets. For interpreting public emotions in tweets, this research employed two independent textual concepts: Word2Vec and N-gram. Abbreviations, emojis, and useless information such as photos and URLs were used in tweets. In addition, tokenisation, stopwords elimination, and regex matching were used in the preprocessing. The features were then supplied to the classifier and, subsequently, constructed using Random Forest. However, due to its strong performance on massive datasets and definite meanings, the model trained with N-gram attained an accuracy of 70.5%. To categorise nonhuman annotated tweets, the model coupled with Word2Vec was selected. The assumption that favourable attitudes in tweets about a business mirror its stock price is bolstered by the findings above, indicating that further study will be promising. Similar studies are being carried out in various parts of the world.
The work in [
6] investigated the people’s perceptions of the Brazilian stock market based on tweets generated by the general public. The dataset used in this study consists of 4516 Portuguese tweets on the BOVESPA primary index [
7]. Each tweet was tagged according to Plutchik’s Psych evolutionary Theory of Basic Emotions [
8], even though the sample was imbalanced since most of the tweets were unlabelled. The first phase, known as preprocessing, sifts the crucial words from the tweet by converting them to lowercase and removes unnecessary and unlabelled tweets before calculating TF-IDF feature vectors. To reduce the dimensionality of TF-IDF vectors and provide a visual interpretation of the tweets, Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbour Embedding (t-SNE) [
9] were utilised. The K-means method, Local Discriminant Analysis (LDA), and Non-negative Matrix Factorisation (NMF) were used to reveal close relationships and important patterns among clusters, extracted themes, and feelings in tweets. The method was unable to discover the differentiating characteristics of each emotion because the used dataset was imbalanced. In the absence of emotions, however, the categorisation systems worked effectively. According to empirical data, the targeted sentiment classification might predict sentiments in tweets on the BOVESPA in Portuguese. Random Forest and SVM displayed the findings for neutral opinions because the number of tagged neutral tweets is more significant than the number of other emotive tweets. For SVM (neutral), precision, recall, and F1-score are 61%, 48%, and 54%. In the same way, the accuracy rate for Random Forest is (neutral): precision 59%, recall 40%, and F1-score 48%.
The work of [
10] explored sentiment analysis to discover people’s predominant emotions while sharing their thoughts on Twitter about the COVID-19 epidemic. Sentiment analysis on tweets connected to COVID-19 was utilised in similar research [
11] to foresee the market movements or predict investor responses through assessing emotions underlying tweets sent by users on equities. This study was carried out to increase prediction skills and foresee recessions. In addition, the study found that analysing Internet searches for consumer sentiment on the economy may accurately forecast financial activity and demand [
12,
13]. Moreover, the study discovered that the entrance and spread of Coronavirus in a country increased economic anxiety and stress—the sample set of data represented the whole population of the United States. The research focuses on the pharmaceutical business because of its importance in the US financial industry. According to researchers, increasing news coverage of the spread of infectious disease outbreaks has a beneficial impact on the buying and selling of pharmaceutical company stock. Pharmaceutical businesses, in general, react to the demand for vaccines and medications to prevent communicable illnesses by spending significant amounts on R&D. Government appropriations are recognised for allowing large-scale manufacture of medications, sanitisers, and protective masks. Reddit, a US-based aggregator, provided data for social news and discussions. Yahoo Finance was used to obtain financial data and information. TextBlob was well-suited for sentiment analysis when it comes to text processing. Its function evaluates two main characteristics: polarity and subjectivity. The former is between −1 and 1, whereas the latter is between 0 and 1. This study rated news headlines as positive, negative, or neutral using TextBlob. The Naive Bayes algorithm was used to categorise the data after tokenisation, tagging, abbreviation processing, and N-gram word combinations.
Another research [
14] focused on using bigrams, a step up from the basic model that was thought to take up a higher amount of semantic information. Due to data density issues, the trigrams were not valuable. Instead, NLP techniques such as stemming and tokenisation were used to preprocess the obtained textual data. In other words, the study focused on using news information to estimate stock price movement or the exact value of a future item. The direction of asset volatility could be predicted more accurately using data from news sources than the price movement’s position. Two machine learning models, LDA and Naive Bayes, were used to represent information from news streams and forecast the direction of the stock price. The predicting accuracy for volatility was 56%, while the closing price of the assets did not reach 49%. As a result, the report indicated that asset price changes are less probable than unpredictability measures.
In [
15], a BERT model on Chinese stock views is suggested to enhance sentiment categorisation. BERT is used to analyse views at the sentence level. The dataset contains a total of 9204 opinions or emotions. Different models were employed to achieve a more successful classification model, including BERT + Linear (92.50%), BERT + LSTM (91.97%), and BERT + CNN (91.97%), with BERT + Linear being chosen for sentiment analysis. Another study [
16] aims to extract both emotions and BoW information from annual reports of US-based businesses. Diction 7.0 [
17] and a dictionary by Loughran and McDonald [
18] were at the core of the discussion. The efficacy of a multilayer perceptron neural network was compared to that of four commonly used text classification methods: Naive Bayes, decision tree, K-NN classifier, and SVM. On lower-dimensional data, SVM and K-NN performed well. For BoW with more significant features, Naive Bayes, decision trees, and neural network (NN) performed better. NN (101%) was the most popular, followed by SVM (97%), decision tree (82%), K-NN (72%), and Naive Bayes (85%). In [
19], Linear Regression, SVM, Naive Bayes, and Random Forest were considered for predicting stock market values, with SVM performing the best. Tweets were gathered over a period of time and may include irrelevant information. In order to clean this irrelevant information, preprocessing techniques, such as tokenisation, stopwords and regex, were implemented.
2.2. The Stock Market Predictive Analytics
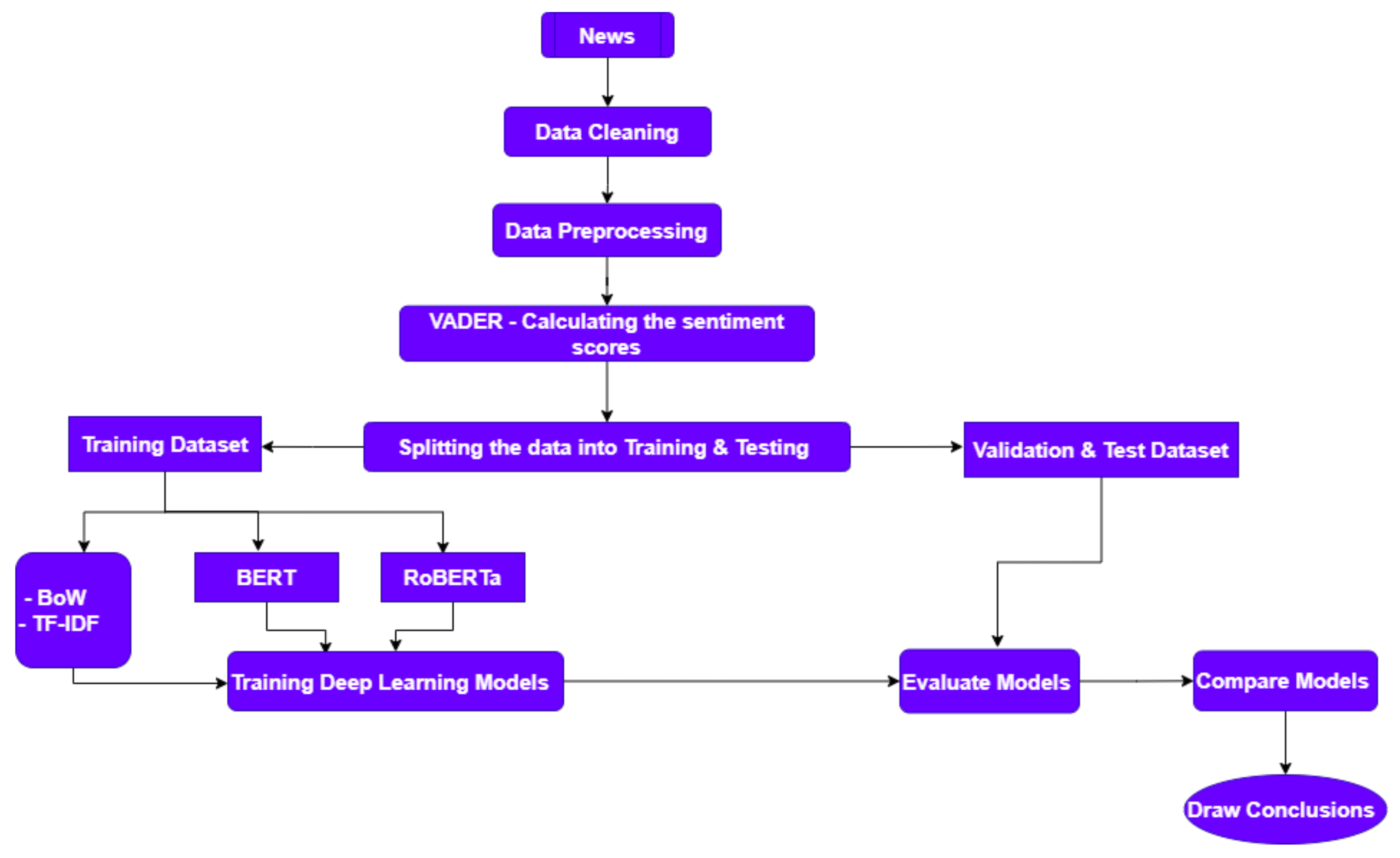
Predictive analytics makes use of cutting-edge Artificial Intelligence (AI) technologies to scan, clean, organise, transform, and analyse data from a range of sources in order to help long-term investors make the best decisions. It is useful for predicting future hazards, making strategic decisions, and enhancing financial capacities. A wide range of stock market statistics can be employed with predictive analytics. To achieve the greatest outcomes, it employs a variety of computational models. Predictive analytics provides traders and analysts with more than regular company reports by learning from extensive historical data [
20]. Traders and research analysts may be able to receive more accurate stock price movements if new technology is deployed. The authors in [
21] proposed a deep learning strategy for forecasting future stock movement. Two Recurrent Neural Networks (RNNs) (i.e., LSTM and Gated Recurrent Unit (GRU)) were configured and compared to the Blending Ensemble model, with the latter outperforming the former. The stock data comes from the S and P 500 index, while news data comes from
fortune.com,
cnbc.com,
reuters.com, and
wsj.com. The news data accounted for headlines since stories or articles might add extra noise. As a result, the model has the potential to underperform. The adjusted closing price was utilised as it is considered to reflect the true worth of the asset and is commonly employed in a detailed analysis of previous gains. The study found a blended ensemble deep learning model outperformed the top-performing model using the same dataset. It decreased the mean squared error (MSE) by 57.55%, raised the F1-Score by 44.78%, boosted recall by 50%, precision rate by 40%, and movement direction accuracy (MDA) by 33.34%. VADER is used to construct sentiment scores during data preprocessing. The purpose of this study was to prove that traders, fund managers, and other short-term investors can make better investment decisions utilising ensemble deep learning technology than they can using traditional approaches.
Another study [
22] proposed a deep learning strategy that combines CNN and RNN for day trading directional movement prediction using financial news and technical indicators as inputs. According to this study, CNN outperforms RNN in detecting semantics from text and content connotations. However, RNN remains one step ahead in detecting contextual information and constructing complex features for stock market forecasting. Another deep learning-based method for event-driven stock market prediction is proposed in [
23]. The proposed prediction model termed EB-CNN (event embedding input and CNN prediction model) outperformed other models and achieved an index prediction of 64.21%. The Word2Vec model was chosen to get ready for word embedding. An integration of BoW and SVM models gives an accuracy of 56.38%. The obtained results in [
24] indicated that CNN outperforms RNN in collecting lexical bits from content, while RNN outperforms CNN in perceiving relative information. To predict the stock price of Chevron Corporation, two models were tested. The first is a hybrid model termed SI-RCNN, which combines a CNN for news and an LSTM for technical indicators. The second is named I-RNN, which has only an LSTM network for technical indicators. These methodologies show that financial data plays an integral part in balancing outcomes and guiding traders in selecting whether to buy or sell a share. The SI-RCNN model could make a reasonable profit of 13.94%, and its accuracy is 56.84%, which is higher than that of the I-RNN model, which is 52.52%.
The work in [
25] confirmed the link between business news and stock prices. According to the results, the SVM forecasted stock movements with an accuracy of up to 73%. A trading simulation was created during this study to analyse profitability through simulating real-world conditions. The initial investment was estimated to be 100 million VND, and each transaction was assessed as 0.25% of the trading money. The system executed four transactions in two weeks to develop the prediction model, earning 105,314,500 VND, a profit of over 5 million VND. BoW was employed for tokenisation. To boost the relevance of words that were randomly assigned positive and negative classifications, delta TF-IDF was constructed instead of the traditional TF-IDF approach. Data on stock prices were gathered from
cophieu68.com. In addition, websites such as
vietstock.cn,
hsx.vn, and
hsn.vn were used to collect a total of 1884 news articles.
The work of [
26] examined the predictive impact of considering the environmental, social, and governance (ESG) events from financial news on stock fluctuation. ESG2Risk, a unique deep learning system, was proposed to estimate future stock market volatility. The language-based algorithm effectively extracted information from ESG events to forecast market volatility. The model sentiments and test embeddings were examined for two weeks, and the findings revealed that ESG2Risk outperforms the Senti approach by a significant margin. According to the findings, ESG events significantly impacted future returns and were crucial for investors to consider when investing. The study also revealed that incorporating ESG events into investing strategies might benefit outcomes. This work [
27] examined data from various web sources, including Twitter, Yahoo Finance, and news articles. Sentiment analysis is used on messages, tweets, and news by implementing Naive Bayes in the combination of BoW and part-of-speech (POS) tagging. Then, aggregating sentiments for the predictor to provide trading signals for buying and selling to anticipate price fluctuations. Finally, after accounting for 833 virtual transactions, the model outperformed the S and P 500 index, yielding a positive return on investment of 0.49% per trade or 0.24% when the market was changed.
2.3. International News in Forecasting Stock Prices
News is critical for analysing stock prices because it offers qualitative information that impacts market expectations. The uniqueness in economic news influences stock returns. The news article or story must include something distinctive to change the price up or down. Financial statistics and textual content featuring originality significantly impact stock values. As a result of the Internet, the quantity of data has been publicly accessible, and many investors have felt overwhelmed when following the news. As a result, the importance of automated document categorisation of the most crucial information is growing [
28]. Automated news report grouping is a kind of text analysis that converts unstructured data into a machine-readable format or a language that the computer can understand and then utilises different machine learning approaches to categorise texts by emotions, subjects, and aims [
29]. A similar research work [
30] conducted a similar analysis, but with a different experiment, using news articles to forecast short-term stock price fluctuations. This study categorised price movement and each news segment as up, down, or unchanged, referring to stock movements in the timespan surrounding the story’s publication. The findings revealed a strong link between stock price and news stories from 20 min before to 20 min after publicly available financial news. Announcing a news report and the results in price movements is a typical catalyst for investment speculation. Since news is a persuasive source of information for forecasting, they impact the market by raising and dropping prices.
In [
31], the Multiple Kernel Learning (MKL) approach was used to combine information from a single stock and sub-industry-specific news articles to forecast impending price movement. For evaluation, SVM with different kernels and KNN were used for stock-specific datasets and sub-industry-specific datasets. In order to extract features, the BoW method was utilised. Finally, TF-IDF was used to characterise the transformation of each document into a vector.
The authors of [
32] suggested a mechanism for converting newspaper coverage into Paragraph Vector [
33], and used LSTM to analyse the temporal impact of prior incidences on many stocks’ opening pricing. The research used data from 50 businesses listed on the Tokyo Stock Exchange (TYO/TSE) to anticipate asset values using distributed representations of news stories. According to empirical findings, the distributed models of word-based material outperformed the mathematical-data-only technique and the BoW methodology. LSTM effectively captured the time-series impact of input data and forecast stock prices for firms in the same industry. The news dataset came from the Nikkei newspaper from 2001 to 2008, while the top 10 company dataset came from Nikkei 225, which was connected to news items during the same period. The work in [
34] aimed to investigate the relationship between news and stock movement. Both BoW and TF-IDF were employed to identify emotion and text representation (see
Table 1 for various ways of text representation considered in the literature). Then, three alternative classification models—Random Forest, SVM, and Naive Bayes—were used to explain the text polarity. According to the findings, the stock trend could be predicted using financial news items and historical stock prices.
Table 2 summarises the different machine/deep learning methods employed in different research works in the literature.
In this work [
41], deep neural networks were considered to extract rich lexical characters from news text to work on sentiment signal characteristics. A Bidirectional-LSTM was used to encode text and get contextual information. The At-LSTM model employed financial news headlines to forecast the direction of the S and P 500 indexes, as well as the stock values of other companies. The planned model’s highest accuracy was 65.53%, with an average accuracy of 63.06% lower than the KGEB-CNN model (Knowledge Graph Event Embedding-CNN) [
45]. Based on the experimental results, the model is valuable and feasible compared with the state-of-the-art models. Future work should forecast price swings over a longer time horizon and be related to the news. Skip-gram and BoW were used for word and phrase embedding. The authors of [
43] examined the correlation between news stories and stock prices. It tried to determine whether news had anything to do with the KSE-100 index (Karachi Stock Exchange). This research used two methodologies: correlation and regression analysis. This analysis relied on sixteen years of data (1999–2014). Consequently, both the KSE and its index had a casual connection with words. In [
44], the authors researched and analysed the impact of technical analysis, Internet news, and tweets on the stock price prediction. The link between the closing price and the time series of news articles and the closing price and Twitter views was investigated. Both linear regression and SVM were applied, but SVM attained better results than linear regression.
Table 3 summarises the various datasets considered in different research work along with more details.


 ,
, 




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}