1. Introduction
Over the past few decades, the finance research related to volatility modelling has produced a tremendous number of studies. Among numerous employed methodologies, the GARCH model proposed in the seminal work of [
1] has become one of the most popular methods. Its popularity is largely due to the ability to capture characteristics of financial time series such as time-varying heteroskedasticity and volatility clustering [
2]. Various extensions have been developed and widely used to investigate different features of finance time-series. In this research, we focus on the component GARCH (CGARCH) model studied in Engle and Lee [
3]. The CGARCH model constitutes a convenient method of incorporating long-memory-like features into a short-memory model via fitting a permanent and transitory component within the GARCH framework.
Originally, all GARCH-type models are constructed based on the assumption that the financial time series follows a Normal (Gaussian) distribution. However, significant evidence suggests that the financial time series is rarely Gaussian, but typically leptokurtic, and exhibits heavy-tail behaviour [
4,
5,
6,
7]. Theoretically, GARCH model can accommodate for fat-tailedness through its specification [
8]. In practice, however, there is still excess kurtosis left in the standardized residuals in most cases [
9]. To solve this problem, a common solution is to employ a fat-tailed distribution such as the Student’s t-distribution or General Error Distribution (GED) [
10,
11,
12,
13]. Compared to the GARCH model with Normal distribution, estimates of which are believed to be consistent even when the true distribution is fat-tailed [
8], a GARCH model with true distribution can lead to more efficient results [
4].
Motivated by those studies, a CGARCH model with a fat-tailed distribution should always be employed in practical finance research. This is particularly important in accurately forecasting financial volatility, which is critical to portfolio risk-management such as measuring risks with Value-at-Risk and/or Conditional-Tail-Expectation. However, a recent study by Calzolari et al. [
9] argues that the widely used Student’s t-distribution and GED are problematic. Their most outstanding drawback is that those distributions lack stability under aggregation, which is of particular importance in portfolio applications and risk management. This leaves the following question still open for academics and practitioners: which fat-tailed distribution should we use for the CGARCH model when the true distribution is unknown? We aim to address this with simulation and empirical evidence in the subsequent sections.
As a replacement of Student’s t and GED, the
-stable distribution is recommended by Calzolari et al. [
9], which has the stability-under-aggregation feature. Additionally, they argue that similar to the Student’s t and GED,
-stable distribution can be easily adapted to account for many properties of volatility such as asymmetry in the underlying financial time-series. Unfortunately, since the second moment of
-stable distribution does not exist in most cases, a GARCH model with this distribution will lead to problematic interpretation. Hence, the sought-after alternative distribution would be of particular interest for the application of a GARCH model.
The tempered stable distribution is a natural substitution of the
-stable, and its effectiveness has been studied for various GARCH family models [
14,
15,
16]. Firstly introduced (In this case, the associated Levy processes are called “truncated Levy flights”, the appropriateness of which for application in the GARCH model is also discussed in Constantinides and Savel’ev [
17]) in Koponen [
18], tempered stable distribution covers several well-known subclasses such as Variance Gamma distributions, bilateral Gamma distributions and CGMY distributions [
19]. The advantage of this distribution is that it retains most of the attractive properties of the
-stable distribution and has a defined second moment.
The application of tempered stable distribution in financial risk-management has become an important topic in existing research. In their influential work, Kim et al. [
20] were among the first to employ tempered stable distribution within the GARCH modelling framework. Other earlier attempts include the application of modified tempered stable distribution [
21], the discussion on tempered infinitely divisible GARCH model Kim et al. [
22], proposition of numerical method for estimation [
23], and others. More recently, tempered stable distribution has been systematically studied for influential extensions of GARCH models, such as the Markov Regime-switching GARCH [
24], Fractionally Integrated GARCH Feng and Shi [
16] and Asymmetric Power GARCH [
25]. Over the past few years, Kim et al. [
26] investigated the case with time-varying exponential tails, and Kurosaki and Kim [
27] and Xia and Grabchak [
28] focused on application of tempered stable distribution on the multivariate GARCH models.
In this paper, we explore the feasibility of classical tempered stable distribution (also known as the CTS distribution) for the CGARCH model and argue that it outperforms both the Gaussian and commonly used fat-tailed distributions (Student’s t and GED). To demonstrate this, we conduct a series of simulation studies to compare the performance of GARCH model with different distributions. First, we set the true distribution as Student’s t and GED, respectively. Via six combinations of different parameters and sample size, CGARCH models with Gaussian and three distinct fat-tailed distributions are systematically analysed. It is demonstrated that when the true distribution is Student’s t or GED, the CGARCH model with tempered stable distribution generates very similar results to that with true distribution. More importantly, it outperforms all the other competitors in terms of consistency, efficiency and overall performance. Second, we let the tempered stable be the true distribution. Six sets of simulations are further constructed, including different choices of CGARCH and tempered stable distribution parameters. In this scenario, none of the CGARCH models with Gaussian, Student’s t or GED distributions perform as well as that with the tempered stable.
To empirically compare the CGARCH model with different distributions, we apply them to the daily return of the Shanghai Stock Exchange index. The results suggest that the CGARCH model with tempered stable outperforms all the other competing alternatives, including a CGARCH model with Copula transformation, under various criteria. When in- and out-of-sample forecasting performance is analysed, CGARCH model produces the smallest forecasting error in both cases. Finally, comparing the fitted Value-at-Risk (VaR) among all models, we find that the two-sided 95% VaR produced by CGARCH model with tempered stable distribution is the least biased statistic.
The contributions of this paper are threefold. First, consistent with existing literature, our simulation evidence systematically demonstrates that the CGARCH model with the Gaussian distribution is consistent but not efficient, when the true distribution is not Normal. Second, if fitted incorrectly, we show that CGARCH model with the widely employed Student’s t and GED may introduce considerable biases. In contrast, the CGARCH model with tempered stable distribution can generate desirable results. Therefore, for a financial time-series with an unknown fat-tailed underlying distribution, the tempered stable should always be employed within a CGARCH framework. This finding satisfactorily answers our research question and significantly contributes to the existing literature. Finally, as evidenced by our empirical study, the CGARCH model with tempered stable distribution consistently outperforms all other competitors. For financial practitioners, our result implies that using the tempered stable distribution may largely increase the accuracy of their risk measures with the CGARCH model. This can further benefit their portfolio management and other enterprise risk-management issues, where accurate risk measure is the major concern.
The remainder of this paper proceeds as follows.
Section 2 describes the specification of the CGARCH model.
Section 3 explains how the Student’s t, GED and tempered stable distributions can be applied to the CGARCH model. We conduct three independent simulation studies in
Section 4. The empirical results are discussed in
Section 5.
Section 6 concludes the paper.
2. CGARCH Model
The GARCH model is proposed in the seminal work of Bollerslev [
1]. Because of its capability to capture some important characteristics of financial time-series (for example, time-varying heteroskedasticity and volatility clustering), extensions of the GARCH model have become a standard way of studying financial volatility [
2]. In particular, the component GARCH (CGARCH) model developed by Engle and Lee [
3] decomposes the conditional variance into a permanent and transitory component. This allows the investigation of the long- and short-run movements of volatility affecting securities in finance research. For the CGARCH(1,1) specification, we have that
where
is the error at time
t.
is an identical and independent innovation sequence following a certain distribution, with zero mean and unit standard deviation.
is the conditional variance of
at time
t, which is composed of a transitory component
and a permanent component
.
and
measure the autoregressive persistence of the transitory and permanent components, respectively.
and
stand for the immediate impacts of volatility shocks (
) on the short- and long-run components, respectively. It is constrained
to distinguish between the two components. In other words, the persistence of
should be stronger than that of
. Similarly, we let
, so that immediate impact of volatility shocks of the long-run component is smaller than that of the short-run component.
The stationarity and non-negative conditional variance conditions of the CGARCH model are straightforward. According to Engle and Lee [
3], a CGARCH(1,1) process is stationary with non-negative
if
,
,
and
. Under such conditions,
will converge to
in the long run.
In order to estimate the parameters of the CGARCH model, Maximum Likelihood Estimation (MLE) is employed. Therefore, the series
needs to follow a specific distribution. Originally, the CGARCH model is developed based on the Standard Normal (Gaussian) distribution. In other words,
(Since the mean of
is 0,
is sometimes named as standardized residual). Hence, the conditional density of
can be constructed as follows.
Then, the log-likelihood function corresponding to Equation (
2) is:
and MLE estimator
is obtained by maximising Equation (
3). Additionally, standard deviation of
is acquired by taking the square root of diagonal terms of the inversed Fisher information (As suggested in Engle and Lee [
3], the CGARCH(1,1) model is a special case of the GARCH(2,2) model. Hence, the asymptotic properties and conditions of the ML estimator follow those discussed in Bollerslev [
1]).
4. Comparisons between Distributions: Simulation Studies
In this section, we will conduct three simulation studies to compare the performance of the CGARCH models with Normal, Student’s t, GED and tempered stable distributions. The data-generation process is CGARCH(1,1) in all cases. True distributions are therefore Student’s t, GED and tempered stable, respectively. We examine two scenarios as follows in each study:
Scenario 1: , () and ;
Scenario 2: , () and .
Hence, the persistences in Scenario 2 is higher than those in Scenario 1. We also set and in all cases. Under each scenario, we further vary the sample size T to be 3000, 4000 and 5000.
4.1. Simulation Study: Student’s t-Distribution
First, we set the true distribution as Student’s t with three degrees of freedom. Altogether, six sets of simulations of the CGARCH(1,1) process with different true parameters and sample sizes T, and the number of replicates for each set is 1000 in all cases. To avoid the starting bias, 10,000 points are generated for each simulation, and then only the last 3000, 4000 or 5000 are kept. Moreover, to avoid simulation bias, 1500 such replicates are produced for each combination, while the first 500 are discarded.
The simulated data are fitted into CGARCH model with Normal (CGARCH-N), Student’s t (CGARCH-t), GED (CGARCH-G) and tempered stable (CGARCH-S) distributions, respectively. In
Table 1, the log-likelihood (LL), bias, standard error (SE) and root-mean-square-error (RMSE) of
,
and
are reported. The bias is the mean difference between the true parameter and its estimate, SE is the standard error of the estimates, and RMSE is the square root of the mean of squared difference between the true parameter and its estimate. Since it is well known that RMSE is approximately equal to square-root of the summation of squared bias and variance, RMSE is able to work as an overall accuracy measure, considering both the central tendency and spread of an estimator. Therefore, RMSE is employed as the key performance indicator while comparing results across competing models.
In the case of consistency comparison, all absolute biases are relatively small, suggesting consistent estimates of all models. Some differences, however, are still distinct. For instance, in Panel A of
Table 1, when
,
is only −0.0016 and −0.0067 for CGARCH-N and CGARCH-S, respectively. Their absolute values are smaller than those of CGARCH-N (−0.0291) and CGARCH-G (−0.0215). Comparing numbers among different sample sizes, however, no regular patterns can be concluded. In other words, biases do not necessarily reduce with increasing sample sizes. This is consistent with the usual asymptotic properties, as biasness is normally not affected by the sample size.
SE is widely used to measure the estimation efficiency. It is observed that SEs of CGARCH-t, CGARCH-G and CGARCH-S are roughly on the same scale and all comparatively smaller than those of CGARCH-N. For example, when , in Panel A are at around 0.03 for CGARCH-t, CGARCH-G and CGARCH-S, whereas that of CGARCH-N is 0.0442. Hence, this result is consistent with the argument that QMLE of GARCH-type model is not efficient. More specifically, in all cases, CGARCH-S generates smaller SE than CGARCH-G and CGARCH-N for all , and , which are only marginally larger than those of the true model CGARCH-t. In addition, we observe that for each model, when T increases from 3000 to 5000, the resulting SE for all parameters reduce to some degree. Thus, this is consistent with the asymptotic properties of ML estimators of GARCH-type models, which suggest that efficiency increases with the sample size.
Further, RMSE is a combination of bias and SE, which is employed as the overall performance indicator in many existing simulation studies. Consistent with the results of SE, CGARCH-N has the largest RMSE in all cases. All RMSEs of the CGARCH-S model are smaller than those of CGARCH-G across all parameters. When compared with RMSEs of the CGARCH-t model, those of CGARCH-S are very similar. For instance, in Scenario 2 (Panel B of
Table 1), when
, the resulting
are 0.1008 (CGARCH-t), 0.1046 (CGARCH-S), 0.1162 (CGARCH-G) and 0.1225 (CGARCH-N).
Turning to the average log-likelihood, not surprisingly, the CGARCH-N model has the smallest values in all cases. The results of CGARCH-G are consistently smaller than those of CGARCH-t. It is also worth noticing that CGARCH-S can yield slightly greater log-likelihood compared to the true model CGARCH-t. Although the tempered stable distribution has four more parameters than the Student’s t, the improvement of log-likelihood still implies that CGARCH-S can lead to satisfied results even when the true distribution is not tempered stable.
To sum up, when the true model is CGARCH-t, the CGARCH-S model almost uniformly outperforms CGARCH-N and CGARCH-G in terms of consistency, efficiency and overall performance of MLE. Nevertheless, it can produce similar results to CGARCH-t in most cases.
4.2. Simulation Study: GED
Next, we set the true distribution as GED with one degree of freedom. Six sets of simulations with the same combinations of parameters as those in
Section 4.1 are constructed. Replicates and each simulation are also truncated in the same manners to avoid simulation bias. Simulation results are reported in
Table 2.
In the case of consistency comparison, the GARCH-S model still has smaller absolute biases compared with CGARCH-N and CGARCH-t models, and this is robust across , and . Additionally, biases of CGARCH-S are very close to those of the true model CGARCH-G. As for the SE comparison, SEs of CGARCH-S are generally uniformly smaller than those of CGARCH-N and CGARCH-t and are still similar to those of CGARCH-G. Apart from that, most SEs also decrease with the increase in T in all cases. Finally, the overall performance indicator RMSE suggests that CGARCH-N is the least-preferred model, whereas the performance of CGARCH-S is close to that of CGARCH-G. Turning to the log-likelihood, it is interesting to note that of CGARCH-S is the smallest in all of the six sets.
To sum up, the CGARCH-S model outperforms CGARCH-N and CGARCH-t models in terms of consistency, efficiency and overall performance in almost all cases. Additionally, the results of the CGARCH-S model are very close to those of the true model CGARCH-G.
4.3. Simulation Study: Tempered Stable Distribution
In this section, we set the true distribution as the tempered stable with three sets of different parameters (all the
ps are set to 0.5), including one case of CGMY distribution (when
and
and two general cases. Altogether, six sets of simulations are constructed, where the combinations of CGARCH parameters are the same as those in
Section 4.1 and
Section 4.2. The sample size is set to 5000 in all cases. Replicates and each simulation are further truncated in the same manners as in
Section 4.1 and
Section 4.2 to avoid simulation bias. The simulation results are reported in
Table 3.
In the case of consistency comparison, CGARCH-N, CGARCH-t and CGARCH-G lead to mixing results with a similar scale. For instance, for the CGMY set in Scenario 1,
are at around −0.04 for all the three models. Absolute values of those results, however, are uniformly larger than those of the true value CGARCH-S. For example, many of the biases displayed in Panel A of
Table 3 are under 0.01 for CGARCH-S, whereas those of the other competing models are over 0.06. For the efficiency comparison, CGARCH-S is still the best performing model, as expected. In Panel B of
Table 3, SEs of
are all under 0.09 for CGARCH-S, and those of all other models are at least 0.01 (over 10%) greater. Since RMSE accounts for the impact of both bias and SE, it is not surprising that CGARCH-S consistently outperforms the other models. In both Panels A and B of
Table 3, almost all
of CGARCH-S are under 0.04, whereas those of other tree models are at least 0.05. Nevertheless, CGARCH-S produces the greatest log-likelihoods in all cases. It is also interesting to notice that
of CGARCH-t is the largest among the three competing models for the CGMY distribution. For the other two tempered stable distributions, CGARCH-G generates the larger average log-likelihood than CGARCH-N and CGARCH-t.
We have the following conclusions for our findings of the simulation studies. When the true distribution is Student’s t or GED, the CGARCH-S model uniformly outperforms the competing models except for the true model. Additionally, the results of CGARCH-S and those of the true model are very close in almost all cases. Nevertheless, CGARCH-S can even generate larger log-likelihoods than the true model. When the true distribution is tempered stable, none of the CGARCH-N, CGARCH-t and CGARCH-G models can perform as well as the CGARCH-S model. All the above observations are robust across different combinations of CGARCH parameters and sample sizes. Therefore, we argue that for a given financial time-series with an unknown fat-tailed distribution, the CGARCH-S model is an optimal candidate to study its short- and long-run second moment properties simultaneously.
5. Empirical Results
To empirically compare CGARCH models with Normal, Student’s t, GED and tempered stable distributions, we fit them for the daily Shanghai Stock Exchange Index (SSE). The daily closing prices for SSE over the period from 1 January 2011 to 31 December 2018 are obtained from the Thomson Reuters Tick History (TRTH) database. Note that due to major macro economic, social and political events (e.g., the US presidential election and COVID-19), the data from 2019 and beyond may very possibly have structural changes, which may not be well captured by a uni-regime CGARCH model. This is noted as a limitation and a potential future research direction in the last section of this paper.
The corresponding return in the percentage series is defined as the logarithm of the daily closing price differences times 100; that is, .
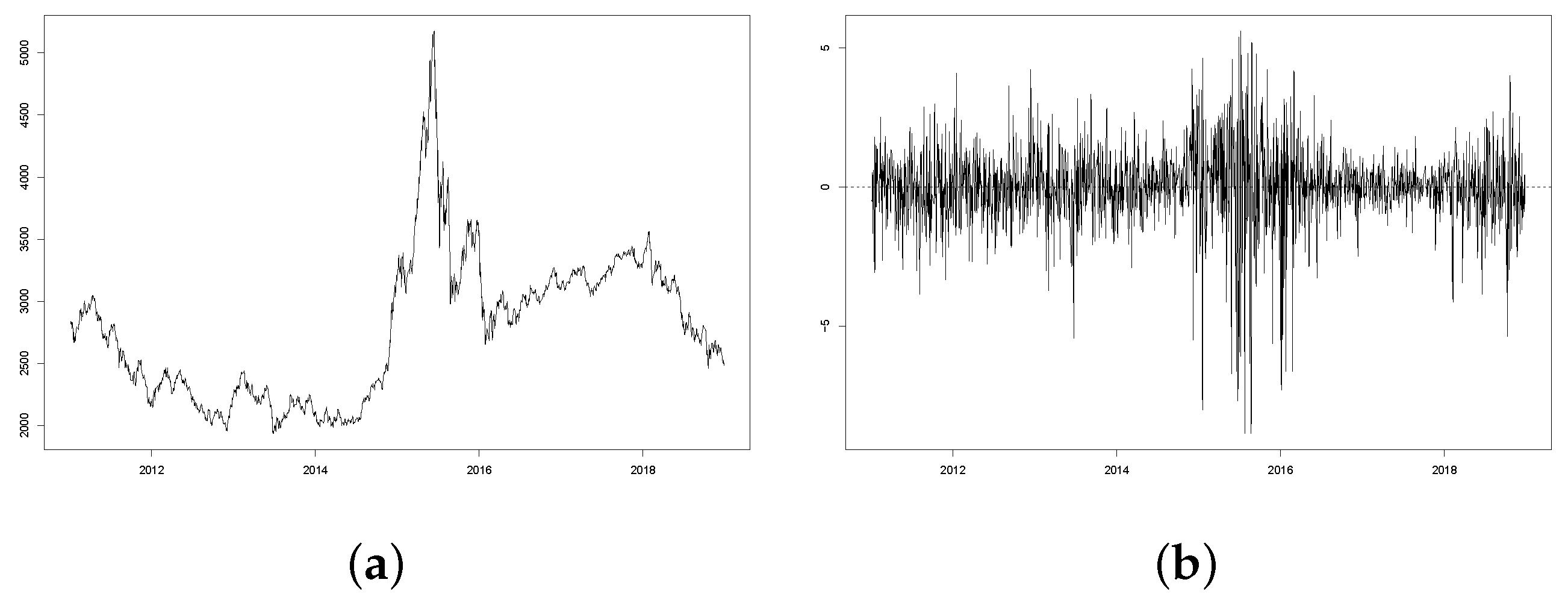
The daily closing prices and returns of SSE are plotted in
Figure 1. In the closing price plot, SSEs generally have ranged between 2000 and 3500 over 2011–2018, except for a spike from 2500 to 5000 in early-2015. This spike has led to large variations of return, as observed in
Figure 1b. Additionally, most daily returns vary in the [−4%,4%] range, with the largest negative (positive) value below −7% (above 5%) in late-2015. After fitting a standard GARCH(1,1) with Normal assumption, we find that the standardized residuals have a kurtosis of 2.11, suggesting a non-Gaussian distribution. Thus, we perform the Kolmogorov–Smirnov and Jarque–Bera normality tests, where the null hypotheses indicating normality are rejected in both cases (
p-values are 0.0000). As a result, CGARCH models with non-Gaussian distributions are expected to outperform the CGARCH-N model.
The estimates of CGARCH(1,1) models with four different distributions are presented in
Table 4. In addition, we also consider the Gaussian copula transformation of the CGARCH-t, the in-sample estimates of which will be identical to those of CGARCH-t without transformation. Overall, estimates of those CGARCH models are close to each other. More specifically, except for
, all GARCH parameters are estimated to be significantly different from zero at 5% significance level. Estimated
of CGARCH-t (0.9441) and CGARCH-G (0.9452) are slightly greater than those of CGARCH-N (0.9051) and CGARCH-S (0.8546). In contrast, the magnitudes of estimated
of CGARCH-N (0.0019) and CGARCH-S (0.0059) are greater than those of CGARCH-t (0.004) and CGARCH-G (0.0004).
Since the SSE returns are not Normally distributed, we focus on the results of the three fat-tailed CGARCH models. Both transitory and permanent components are quite persistent to their own shocks. Estimated
are at least 0.90, whereas estimated
are all over 0.99. Hence, we expect that shocks to both
and
will not quickly die away [
2]. As for the impacts of immediate volatility shocks, fitted results suggest the influence on the permanent component is very much close to zero (all smaller than 0.01). Although such influences on transitory component are all estimated to be significant, the magnitudes are limited at around 0.05. To compare the three fat-tailed models, log-likelihood, Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) are presented. It can be seen that CGARCH-S is the best performing model based on all criteria. Additionally, CGARCH-G slightly outperforms CGARCH-t, both of which are preferred to CGARCH-N. Hence, the results of the CGARCH-S model are more reliable, which suggest the volatility persistence of the transitory component (0.9029) is around 10% smaller than that of the permanent component (0.9983). In contrast, both CGARCH-t and CGARCH-G suggest those persistences are almost identical and close to one.
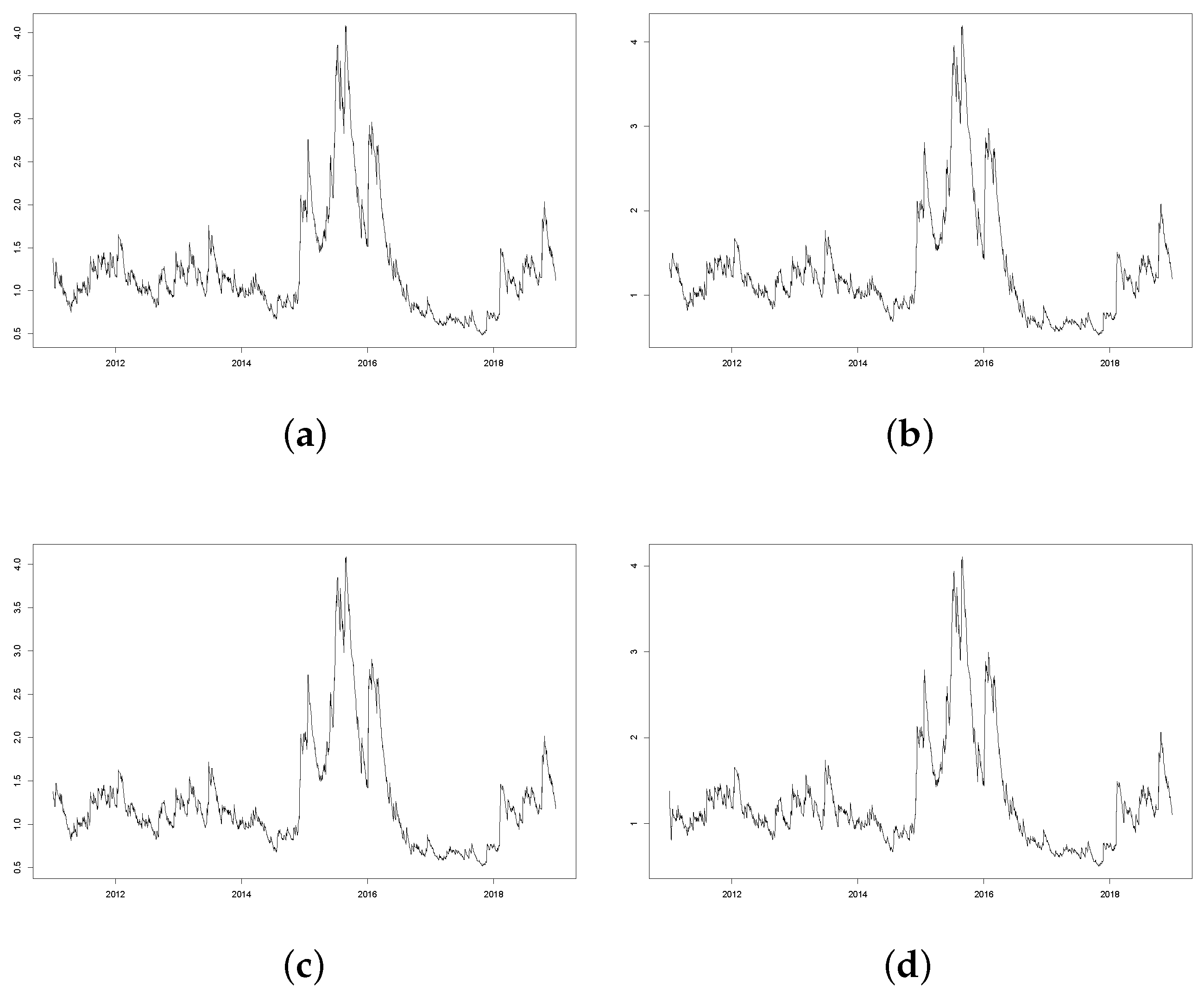
To further explore the models, all the four estimated conditional volatility series (We report conditional volatility here as the square root of
, so that it has the same scale as
) are plotted in
Figure 2. Despite their different model performances, the four estimated conditional volatility series demonstrate shapes fairly close to each other. Consistent with our previous observations, large variations are found over 2015–2016. Further, due to the impact of large volatility persistences, influences of those shocks do not quickly die away and cause clustering on the conditional volatility.
Despite their similarities, the difference between the fitted conditional volatilities can be described as the different in-sample forecasting performance of the fitted models. To quantitatively compare this performance, we measure the prediction error for each model by
, where
is the fitted
for each model, and
is employed to proxy the true conditional volatility. The results are reported in Panel A of
Table 5. Moreover, to consider the out-of-sample forecasts, we use the last 100 observations as the prediction sample and the others as the training sample. Then, we fit each model for the training sample and calculate the one-step ahead forecast of
. After that, we include the first observation in the prediction sample and generate another one-step-ahead forecast. We repeat this rolling-window approach until 100 such one-step-ahead forecast
are produced. After that, we calculate the absolute difference between them and the corresponding
, which measures the out-of-sample forecasting errors. The results are reported in Panel B of
Table 5. It is observed that CGARCH-S leads to the smallest average forecasting errors in both the in-sample and out-of-sample cases. This is confirmed by the RMSE, which is defined as
and widely used as an overall forecasting performance indicator. Additionally, CGARCH-S produces small variations in the forecasting errors, which is the second smallest for in-sample forecasting and the smallest for out-of-sample forecasting. In addition, when considering
, the 95th percentile of the forecasting errors, CGARCH-S leads to the smallest extreme errors in both cases. Nevertheless, it is worth mentioning that he copula-transformed CGARCH-t and the original CGARCH-t result in much identical performance. Therefore, this copula model is skipped in the following Value-at-Risk analysis.
Finally, we consider an important practical application of the CGARCH model: the Value-at-Risk (VaR) analysis. This is particularly useful when measuring the financial risks, such as the investment risk of a portfolio. In this paper, we consider the two-sided 95% VaR, which is constructed as the [
,
], where
and
are the 2.5th and 97.5th percentile of the fitted innovation distribution, respectively. Using the estimated parameters reported in
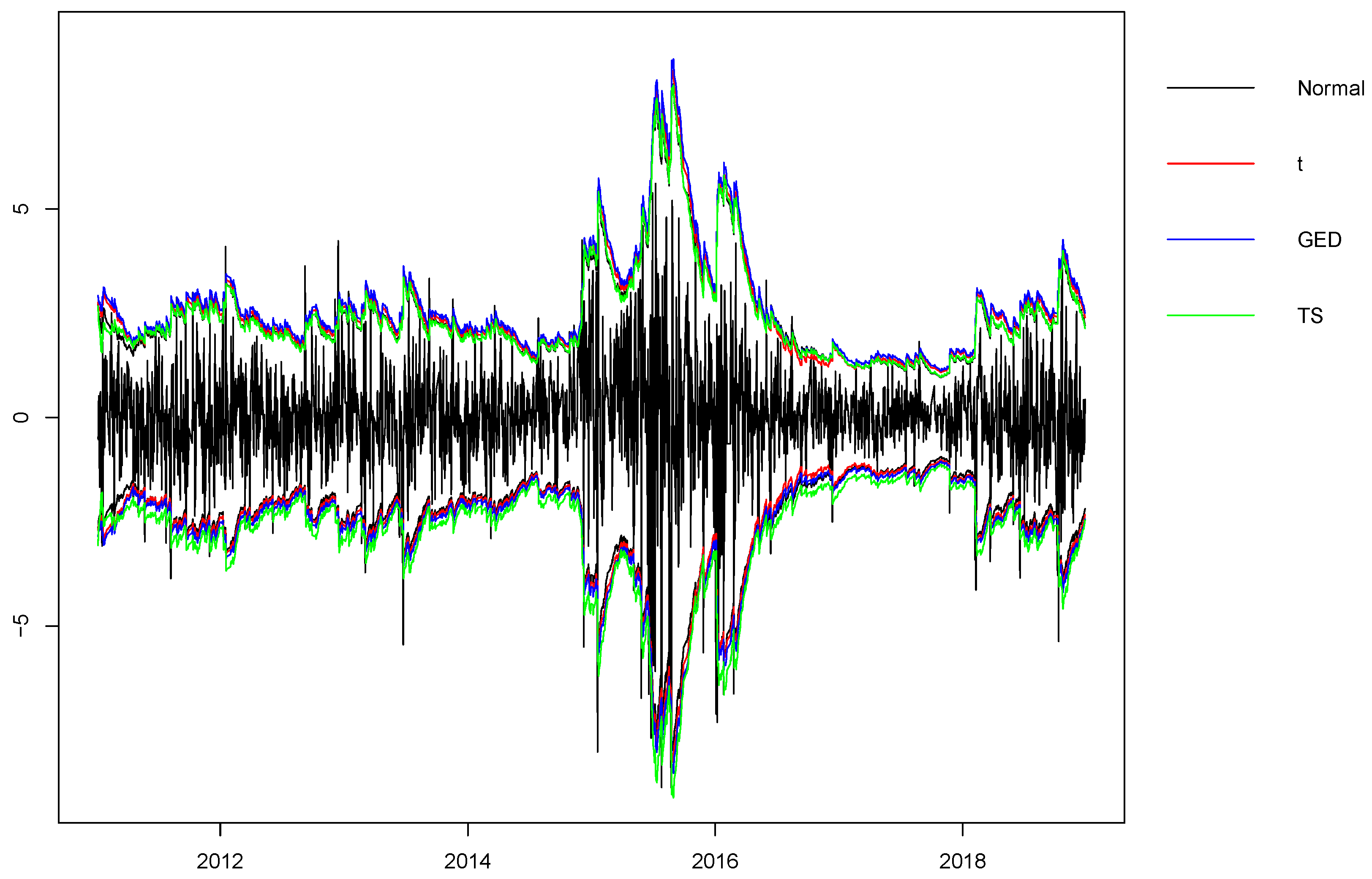
Table 4, it is straightforward to construct the time-varying two-sided 95% VaR for each CGARCH model. The results are plotted in
Figure 3. Due to the similarities of
as observed in
Figure 2, those VaR are again not quite visually distinct from each other. Despite this, it can be seen that both the negative and positive VaR of CGARCH-S are generally smaller than those of the other CGARCH models. Among the total 1944 observations, there are 40 positive (
positive VaR) and 48 negative (
negative VaR) violations for CGARCH-S. Those are quite satisfactory results, standing for 2.1% and 2.5% chances of violation, respectively, which are close to the 2.5% as designed. For the rest, we find 39 positive (2.0%) and 66 negative (3.4%) violations for CGARCH-N, 35 positive (1.8%) and 62 negative (3.2%) violations for CGARCH-t, and 27 positive (1.4%) and 58 negative (3.0%) violations for CGARCH-G. Such results are close to each other and are not as good as those of CGARCH-S. The resulting VaR is clearly biased upwardly for CGARCH-N, CGARCH-t and CGARCH-G models, leading to smaller positive and larger negative violations than expected. The advantage of CGARCH-S on other competing CGARCH models is largely due to the more flexible parametric structure of the tempered stable distributions. In short, the five parameters allow different shapes at each tail and in the middle. Thus, the fitted tempered stable distribution would accommodate more features of the empirical data, such as leptokurtic kurtosis, asymmetric tails and skewness. This leads to more accurate VaR analysis, which is critical for accurate risk-measurement and other risk/portfolio management applications.
6. Concluding Remarks
The CGARCH model has enjoyed particular popularity in finance research for simultaneously studying long- and short-run components. Despite its effectiveness, in practice, the CGARCH model can produce more efficient estimates when appropriate fat-tailed distribution is employed. This paper aimed to find an optimal distribution for disturbances of the CGARCH model, when the underlying distribution was a fat-tailed but unknown type.
Inspired by Calzolari et al. [
9], our paper investigated the applicability of the tempered stable distribution within the CGARCH framework. Via systematically designed simulation studies on the CGARCH(1,1) process, we contrasted the performance of CGARCH models with Normal (CGARCH-N), Student’s t (CGARCH-t), GED (CGARCH-G) and tempered stable (CGARCH-S) distributions. The first two studies assumed that the true distributions were the Student’s t and GED, respectively. In such cases, results of CGARCH-S are close to those of the true models, and CGARCH-S uniformly outperforms the other competing models in terms of consistency, efficiency and overall performance. We constructed different combinations of the tempered stable distribution to simulate the CGARCH process in the third study. Our results suggest that none of the CGARCH-N, CGARCH-t and CGARCH-G can perform as well as the CGARCH-S model.
Empirical evidence is further provided to check the robustness of our simulation results in practice. We fit the daily return of the Shanghai Stock Exchange (SSE) index over 2011–2018 into the four CGARCH models, respectively. Our results indicate that CGARCH-S is still preferred to the rest under different model performance criteria, in- and out-of-sample forecasting comparison and Value-at-Risk (VaR) analysis. Nevertheless, the limitations of this research are two-fold. First, we focused on the analysis of SSE index, and more evidence on the feasibility of CGARCH-S model needs to be verified for other financial equities. Second, the current CGARCH framework is limited to a uni-regime model. To cope with empirical structural changes recently caused by major events such as COVID-19, a regime-switching CGARCH model may be proposed and studied. Addressing those limitations sheds light on systematic validation of the practical usefulness of the CGARCH model in areas such as portfolio management and other enterprise risk-management issues.






{kind=link}
{kind=link}
{kind=link}