1. Introduction
Flexible production is a typical representative of high-end manufacturing. Here, “flexible” refers to the flexibility consumers have in customizing products. Compared with traditional production methods in which consumers can only purchase finished products, flexible production can quickly meet the individual needs of different consumers. In traditional production, cost reduction is achieved through mass production, which means it often cannot support customization. Although customization is possible for a small number of production methods, the associated production cost is usually high. With the rapid development of various technologies in recent years, such as industrial Internet, robots, and edge computing, the dynamic self-reconfiguration of production lines has become an option. Low-cost, flexible production has overcome the technical bottleneck, and an increasing number of flexible job shops have been put into use, achieving considerable economic benefits [
1]. As an example, the flexible job shop in a Chinese heavy equipment manufacturing company, is equipped with eight assembly lines, which can achieve customized production for 69 types of products, showing a threefold increase in output value.
A flexible job shop contains multiple production lines, and each is composed of multiple machines. To make our proposed algorithm applicable to more industrial systems, our system model is defined broadly. Although there is a strict order for all operations in a job, multiple operations may be executed on the same machine, i.e., the job may not follow a linear fashion. Hence, our problem is not a flow shop scheduling problem. Details are shown in
Section 4. In our system, after a customer’s order is received, the machines are reconfigured and scheduled according to customization needs and delivery time, such that the production process can be dynamically adjusted to meet order demand. As a result of different order-specific requirements, random order placement times, and the large number of machines, simple production scheduling can no longer meet production needs in such complex situations. Therefore, flexible job shop scheduling has become a key issue in the industry and has been investigated by numerous studies.
In an industrial system, there are many types of dynamic events, such as process-related, order-related and machine-related dynamic events. However, no algorithm can handle multiple dynamic events simultaneously (shown in
Section 2). Therefore, in this study, a time-fine-grained state model was used to represent the complete characterization of system dynamics, and the model allowed changing the relationship between products and orders. Based on the time-fine-grained model and the flexible correspondence between products and orders, aiming at the lowest cost loss, a theoretical description of the optimization problem was given, and a priority scheduling algorithm based on completion time analysis was proposed to realize emergent scheduling to meet production needs. Since the model described the system state in a time-discrete manner and transformed the states at different times through our proposed efficient algorithm, this study can flexibly respond to multiple dynamic events.
The remainder of this paper is organized as follows.
Section 2 introduces relevant works.
Section 3 details the system model and our problem.
Section 4 describes our algorithms.
Section 5 evaluates the algorithms based on extensive orders. Finally,
Section 6 concludes this paper.
2. Relevant Works
For the flexible job shop problem, there are two types of scheduling algorithms, namely static scheduling algorithm and dynamic scheduling algorithm.
In 1954, Johnson formulated the job shop scheduling problem and proposed the first static scheduling algorithm [
2]. Static scheduling means that the production process is determined and there are no dynamic events. Since then, the static scheduling problem has been extensively studied. In the case of a single-objective static scheduling problem, improved meta-heuristic algorithms have typically been used to minimize the maximum completion time [
3,
4], number of machines [
5], and machine usage time [
6]. However, a flexible job shop involves a large number of complex processes, and multi-objective optimization has also been a key research topic in flexible scheduling. For example, an evolutionary algorithm has been used to simultaneously optimize completion time, energy consumption, and cost [
7]. An improved multi-group NSGA-II algorithm was used to simultaneously optimize completion time, machine efficiency, and total machine load [
8]. Further, hybrid particle swarm optimization was used to optimize completion time and total machine delay [
9]. One study used the genetic algorithm to optimize total machine load and bottleneck machine load [
10]. Meanwhile, Change et al. used the concept of “residual value subsidy + out-of-stock penalty” to optimize the economic benefits of multiple enterprises at the same time [
11]. Wu et al. used the batch rolling optimization method to optimize production processes and production plans [
12]. All of the above-mentioned studies regarded machines as the scheduling resources. Some studies have considered automatic guided vehicles as movable resources for optimization. For example, considering both automatic guided vehicles and machines, one study proposed using discrete particle swarm optimization to minimize the maximum completion time [
13]. Considering the working capacity limitations of automatic guided vehicles, Li et al. proposed an artificial bee colony optimization algorithm for the multi-objective optimization of completion time and energy consumption [
14]. These studies solved some of the scheduling problems in flexible job shops but failed to consider the dynamic situation of sudden production needs. One of the prerequisites of flexible job shops is that the production process can be dynamically adjusted to produce efficiently according to demand.
In 1957, Jackson distinguished the difference between dynamic scheduling and static scheduling, and he pointed out that the main feature of dynamic scheduling is to consider dynamic events [
15]. In terms of the dynamic scheduling problem, researchers have conducted studies from multiple perspectives [
16]. For process-related dynamic events, Wei et al. proposed a closed-loop scheduling mechanism for detection and adjustment based on the brainstorming algorithm to ensure completion time [
17]. Li et al. proposed a novel affinity calculation method to handle high levels of uncertainty [
18]. Xu et al. proposed an adaptive discrete flower pollination algorithm to handle the uncertainty of parameters during a flexible industrial process [
19]. Zhong et al. proposed a new artificial bee colony algorithm to minimize the maximum fuzzy makespan [
20]. Lei proposed a random key genetic algorithm to solve job shop scheduling problems with fuzzy processing time [
21]. Liu et al. proposed a fast distribution estimation algorithm [
22]. For order-related dynamic events, Luo et al. employed reinforcement learning-based methods to dynamically adjust production processes [
23]. Luo and Wang proposed a double loop deep Q-network method with an exploration loop and exploitation loop to solve job shop scheduling problems under random order arrivals [
24,
25]. Zhuang et al. proposed a network-based dynamic dispatching rule generation mechanism to assign dynamic orders [
26]. For machine-related dynamic events, scheduling must consider the cost of machine recovery; a few algorithms have been proposed to deal with this problem. Nouiri et al. proposed a fast, energy-efficient rescheduling method [
27], and Chen et al. proposed a machine parameter readjustment method based on knowledge libraries and self-learning [
28,
29]. Zhang et al. designed an improved empire competition algorithm to minimize completion time and machine energy consumption while repairing the machine [
30]. Shahrabi et al. used a machine learning algorithm to achieve real-time production scheduling [
31]. Ghaleb et al., meanwhile, adopted an event-based rescheduling approach to address uncertainties in job arrivals and machine breakdown [
32]. A predictive approach was proposed by Iwona et al. to deal with possible failures before they occur [
33].
Although the above-mentioned studies investigated the dynamics of flexible job shops, they have some limitations. In actual production, unpredictable dynamic events such as machine breakdown, product defects, and order changes may arise, and any existing single algorithm is unable to deal with multiple events (as shown in
Figure 1). Although the likelihood of multiple events occurring at the same time is very low, this still requires the system to support multiple scheduling methods. Thus, when a single dynamic event occurs, the scheduling method for the specific event can be used to solve it. However, the scheduling methods must be coordinated with each other. Otherwise, the results of one scheduling method will compromise existing scheduling outcomes. Therefore, compared with multiple scheduling algorithms, it is more effective to use one scheduling algorithm to handle multiple dynamic events. In this study, such a scheduling algorithm is proposed.
3. Problem Statement
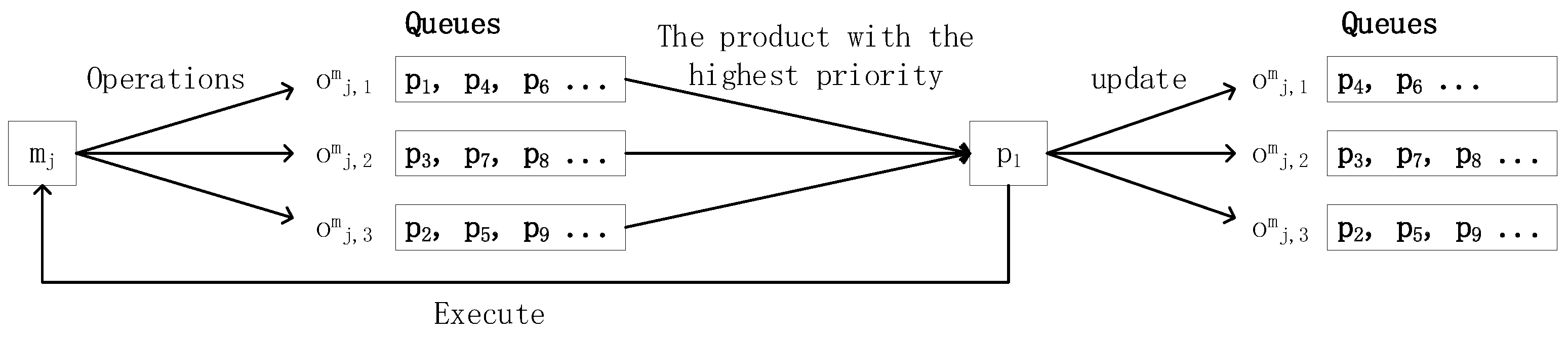
We considered the dynamic problem model in four dimensions: machines, operations, products, and orders. The machine set available to the job shop is , and the set of supported operations is . Each machine supports several operations—for example, . Operations corresponding to the machine are marked with a superscript m to distinguish them from the original operation set O (i.e., . However, might not be equal to (). It takes time to complete the operation (). The product set is , and each product is produced after multiple steps of sequential operations, . The user can place an order at any time, and the order specifies the product and the latest delivery time . The product consists of a series of operations, . The set of orders is expressed as . The state model of the job shop at time t is , where each quadruple means that machine is performing the gth operation of product pk at time t, and the operation has been performed for time. Note that some products might already be in the production plan, but the production has not yet started, and this state is expressed as . When the production plan of some products is canceled, the state is expressed as . If a machine is idle, its state is represented as . Once some operations are interrupted, they need to be restarted, and for such operations, . The above states can be jointly expressed using ; special algorithmic processing is not needed, and thus, they will not be considered in the sections that follow.
The system model includes the following assumptions:
All pieces have arrived before the operation starts.
The next operation cannot be started until the current operation is completed for the same product.
There is no time gap between adjacent operations for the same product.
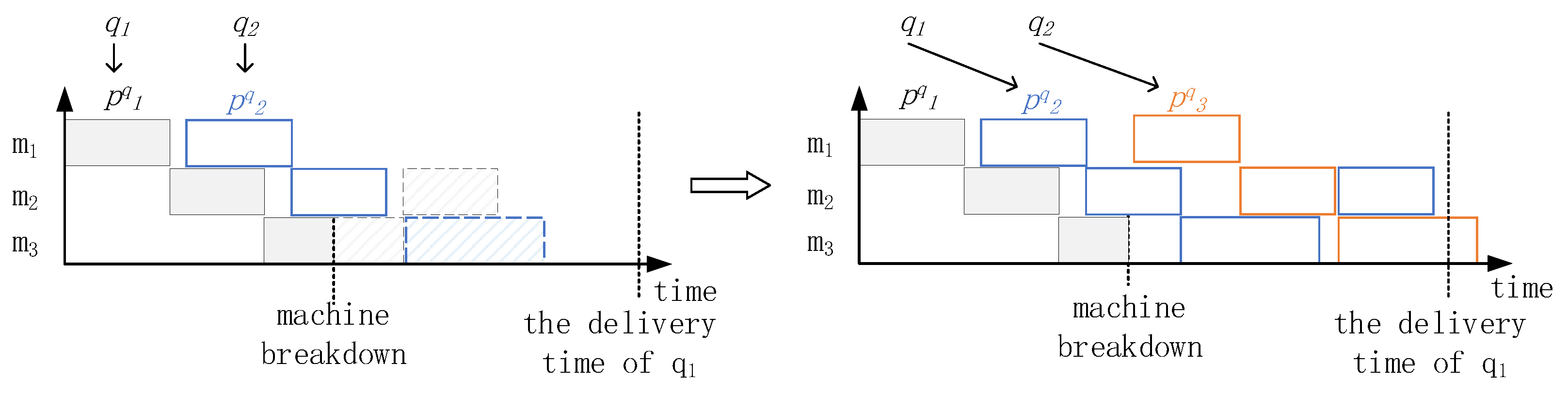
This study separated products and orders to flexibly adjust operations during the production process. While product demand comes from orders, products can be adjusted at the operation level when dynamic events occur. For example, in
Figure 2, the semifinished product
in order
is damaged due to machine breakdown in the third operation, and product delivery cannot be guaranteed within the specified time in the case of reproduction. In this case, if there is product
in the same operation as the operation of
, and the delivery time of
is later, then the subsequent operation of product
is adjusted to that of product
such that order
can be delivered on time. At the same time, a new
is reproduced. Based on the idea of product–order separation, the scheduling method in this study generates a subsequent schedule
according to the shop state
at time
t. Products produced according to this schedule must meet the delivery requirements of the order set
Q as much as possible, with minimum cost loss. The cost loss of order
failure is expressed as
, which includes the cost of reproduction, the cost of machine repair and maintenance, and compensation to consumers. The cost loss can be defined by the user of the algorithm.
To clearly describe the above problems, we first present problem description P1 based on optimization modulo theories (OMT) at the start of the system; subsequently, the description is expanded to the handling of dynamic events to formalize the final problem description P2. This study used the following 0–1 variable to describe the relationship between elements, as shown in
Figure 3.
- 1.
If order has no deliverable product at the final delivery time, then ; otherwise, .
- 2.
If product is available for the delivery of order , then ; otherwise, .
- 3.
If the operation of product can start on at time t, then ; otherwise, .
- 4.
If the gth operation of product is , then ; otherwise, . This variable enables the product to change the final product type according to the needs of dynamic events.
First, we consider the situation at the start of the system. The set of orders
Q, set of machines
M, set of products
P, and cost loss value
(
) are known. All machines are idle, and there is no product currently in the production process. The objective function of problem P1 is
where
can be obtained by
:
The value of is divided into two cases: (1) If all products cannot be delivered as part of order (i.e., ), then . (2) If there are products that can be delivered for order , (i.e., ), then .
Problem P1 needs to satisfy the following constraints:
(1) One product can only be delivered for one order:
(2) One operation can only be performed on one machine:
(3) Each operation of a product is unique:
(4) Only products that meet the requirements of the order can be used for order delivery; that is, the operation steps and sequences of the product are exactly the same as those of the order requirements:
(5) There are no conflicts regarding machine usage time. The usage time of operation
on machine
is defined as
:
If an operation does not involve the use of machine
, then its usage time is expressed as
. Any two operations on the same machine cannot overlap in time:
(6) Multiple steps for a product must be operated in sequence; that is, the completion time of the previous step must be earlier than the start time of the subsequent step:
(7) The product must be completed before delivery; that is, the completion time of the last step of the product must be earlier than the order delivery deadline:
The state at time
t is denoted
. If a dynamic event causes production to fail, such as the machine breakdown in
Figure 2, the product is removed from
. If the order is canceled, it is removed from the set of orders. Based on the type of dynamic event, the following three modifications are made to problem P1 so that it can describe scheduling problem P2 after the occurrence of the dynamic event:
(1) The elements in
that do not include
indicate that the operation has been executed on the machine, and the corresponding
and
cannot be changed or optimized. Therefore,
and
are given fixed values, and the constraints on related operations are removed from the problem description:
In addition, although the values of , , and other are also affected, they can be calculated by Equations (4) and (7).
(2) If a product fails to be produced and needs to be reproduced, a corresponding number of products need to be added to P. Since the production steps for the additional products can be obtained in the algorithm, there is no need for constraints on product type.
(3) If an order is canceled, it is removed from Q.
This study focused on scheduling problem P2 after the occurrence of dynamic events. If the decision version of the problem does not consider the situation in which products can be transferrable to other orders, and the delivery time of all orders is limited to the shortest schedulable time, then the decision problem can be reduced to the traditional job shop scheduling problem. Since the job shop scheduling problem is an NP-hard problem, problem P2 is at least NP-hard, and the optimal solution cannot be obtained in polynomial time.
To validate the above model, we used a third-party solver Microsoft Z3 [
34] to solve it. However, owing to the complexity of the model, the optimal solution can only be found within two hours for very small-scale variables. Since the focus of this study was emergency responses to dynamic events, the algorithm needed to be able to provide solutions within seconds or even milliseconds. Apparently, the hour-level algorithm cannot meet these requirements. This study, therefore, proposed a fast heuristic algorithm, which is described in the next section.
5. Numerical Analysis
5.1. Time Analysis
Based on Algorithm 2, this section analyzes the maximum production completion time of product
, thereby obtaining the correspondence between the priority and deliverability of the product. For product
, it is defined that an operation to be performed at the current time
is
. Starting from the current time
, in the worst case, it will take
k time to complete the production.
k is affected by the following factors: (1) the remaining time of the previous operation
; (2) the operation being performed on the machine at time
and the delay caused by
not being ready; (3) the product with a higher priority than
will be processed on the machine first, causing
to be delayed; and (4) the operation time of
. Starting from time
, for each operation between the first operation
and the last operation
of
, Factors (2)–(4) may exist. Thus, it will take the time described by Equation (
13) at most to complete
:
where
is the set of machines that support the operation
;
is the time of Factor (1); and
,
, and
are the time of Factors (2)–(4) of the
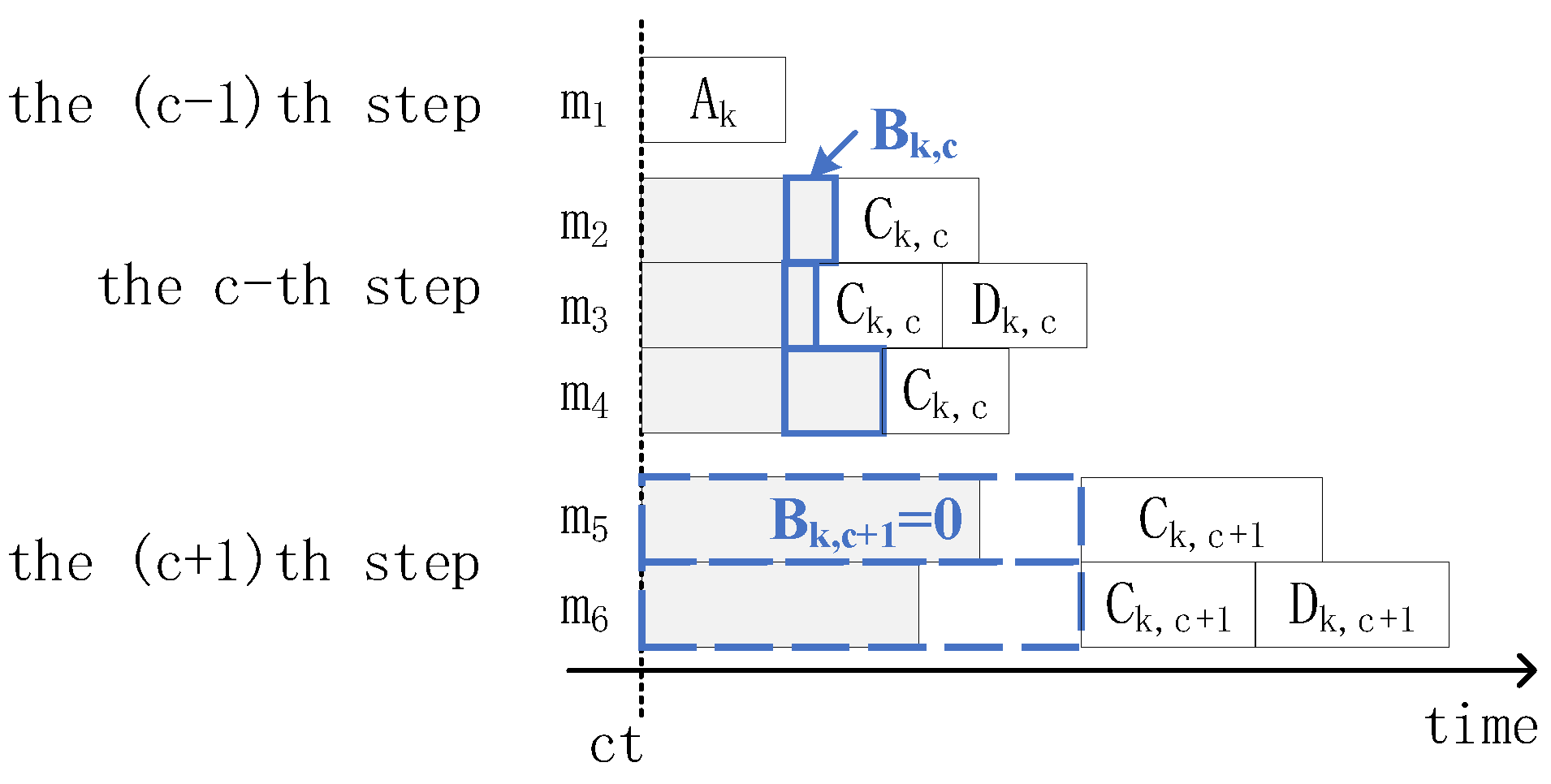
gth step. Based on
Figure 5, time
k is described as follows:
If an operation of
has started before time
, the remaining time of the operation does not exceed the overall time of the operation. Thus,
can be expressed as
From the second operation, each operation can be executed on multiple machines. The factors that might cause a production delay of
of multiple machines are expressed as
. After completing the previous operation,
will wait for the next operation on the machine that is available first. Although the earliest available time of
B and
C cannot be estimated, the time will not exceed the average running time of
B and
C on multiple machines, which is
. The time delay of Factor (2) starts from time
. To accumulate the time delay in multiple steps,
only represents the time elapsed since the end of the previous operation, such as step
c in
Figure 5. If the time delay of Factor (2) does not exceed the end time of the previous operation, then
(step
in
Figure 5). The end time of the previous operation is expressed as
The overall delay caused by factor (2) is expressed as
where
is the unfinished operation on machine
, and
is the operation that will be performed on
, which has a smaller priority than
.
is the sum of the execution time of number operations with the longest execution time in the set. Therefore,
is calculated as follows:
All higher-priority products that use the same machine may cause the production delay of
; thus,
is calculated as follows:
where
represents the operations that use the same machine as
and have a higher priority.
The current operation of corresponds to a primitive operation , and thus, . At this point, it is known that it takes at most time to complete the production of . If is smaller than the delivery deadline of the order corresponding to , the order can be successfully delivered. If exceeds the delivery deadline, the order may be delivered, since the above analysis is only the worst-case scenario, and the actual production time may be shorter than the maximum time. To ensure the number of deliverable orders, it is necessary to reasonably assign the priority of products, such that the number of products that is produced beyond the delivery deadline is as small as possible.
5.2. Priority Assignment
Based on the above analysis, the priority assignment algorithm is as shown in Algorithm 2.
is the priority to be assigned currently, and
is the highest priority (line 1). Priorities are assigned in order of low to high (lines 1, 2, and 11). For each priority, the maximum production time
for each product in
P is calculated, as well as the remaining slack time
before the order’s deadline, according to Equation (
13) (lines 3–5). The larger the value of
, the sooner the product will be assigned. However, if the maximum
is negative, it means that no product will be completed at the current priority. To minimize production cost, the product with the least cost loss will be assigned the current priority (lines 7–8). If the maximum
is not negative, then
can be produced, and the current priority
is assigned to product
(lines 9–10). Thereafter, the above steps are repeated for the next priority (line 11), until the priority assignment of all products is completed, and the function returns the assignment result (line 12). The time complexity of the algorithm is mainly in lines 2–5, with corresponding time complexities of
,
,
, and
, respectively. Since the time complexities of lines 4 and 5 are both linear, the time complexity of Algorithm 2 is
, which is smaller than that of Algorithm 1, which is
.
5.3. Test Cases
A large number of test cases were randomly generated to evaluate the effectiveness and generalizability of the proposed algorithm. The parameter set of each test case is represented as <the maximum number of machines that can perform the same operation, the number of orders, the number of operations, the execution time interval of each operation, the deadline interval, the cost loss interval> (i.e., <>). For example, the parameter set <> means the job shop supports 10 operations, each operation can be executed by up to three machines, the time required for each operation is within [1, 10], there are currently five orders, and the deadlines of the orders are in the interval of [50, 100]. If an order cannot be delivered, its cost loss is in the interval of [1, 100].
The interval in the parameter set is used to reflect the diversity of test cases. When a test case is generated, a value in the corresponding interval is randomly selected as the order attribute, and a sudden breakdown of machines, operations, products, or orders is randomly placed to simulate dynamic events in actual production. To evaluate the generalizability of our proposed algorithm, for each parameter set, 1000 test cases are generated randomly, and then, the algorithm runs 1000 times to process them. We analyzed the effectiveness of the algorithm under different parameter configurations by sequentially changing each parameter.
5.4. Result Analysis
Z3 is the most widely used solver for OMT. However, its execution time is unacceptable for complex problems. In order for Z3 to solve the OMT formulation (Equations (1)–(12)), the parameter settings are <>. For each parameter setting, 100 test cases were randomly generated. Since these test cases are simple, Z3 can finish in 10 min, and the proposed algorithm (denoted as SchPA) finishes in 2 ms. Compared with Z3, SchPA increases the cost by about 2%. However, when the number of orders is seven, Z3 cannot solve the test case in 2 h. To evaluate the generalizability of SchPA, in the following, we ignore Z3 and only compare SchPA with heuristic algorithms.
We compared SchPA with the First Come First Serve (FCFS) rule [
35] and the shortest process time (SPT) rule [
36]. FCFS is a simple rule in which the order that is placed first is produced first. SPT gives the highest priority to the job with the smallest operation time. In [
37], the comparison between SPT and other classical methods was shown, and SPT has the most optimum outcome. This is why we chose SPT as a baseline method.
The algorithms in the present study were written in C++ and run on a Precision 5820 workstation. The solution time for all orders was less than 10 ms. The assessment index was the percentage of cost loss to the total cost of all orders. Cost loss was calculated using Equation (
1), and total cost was obtained after the orders were generated. Each point in the following figure represents the average cost loss for 1000 random orders. For the purpose of comparison, the y-axis scale was kept constant at
.
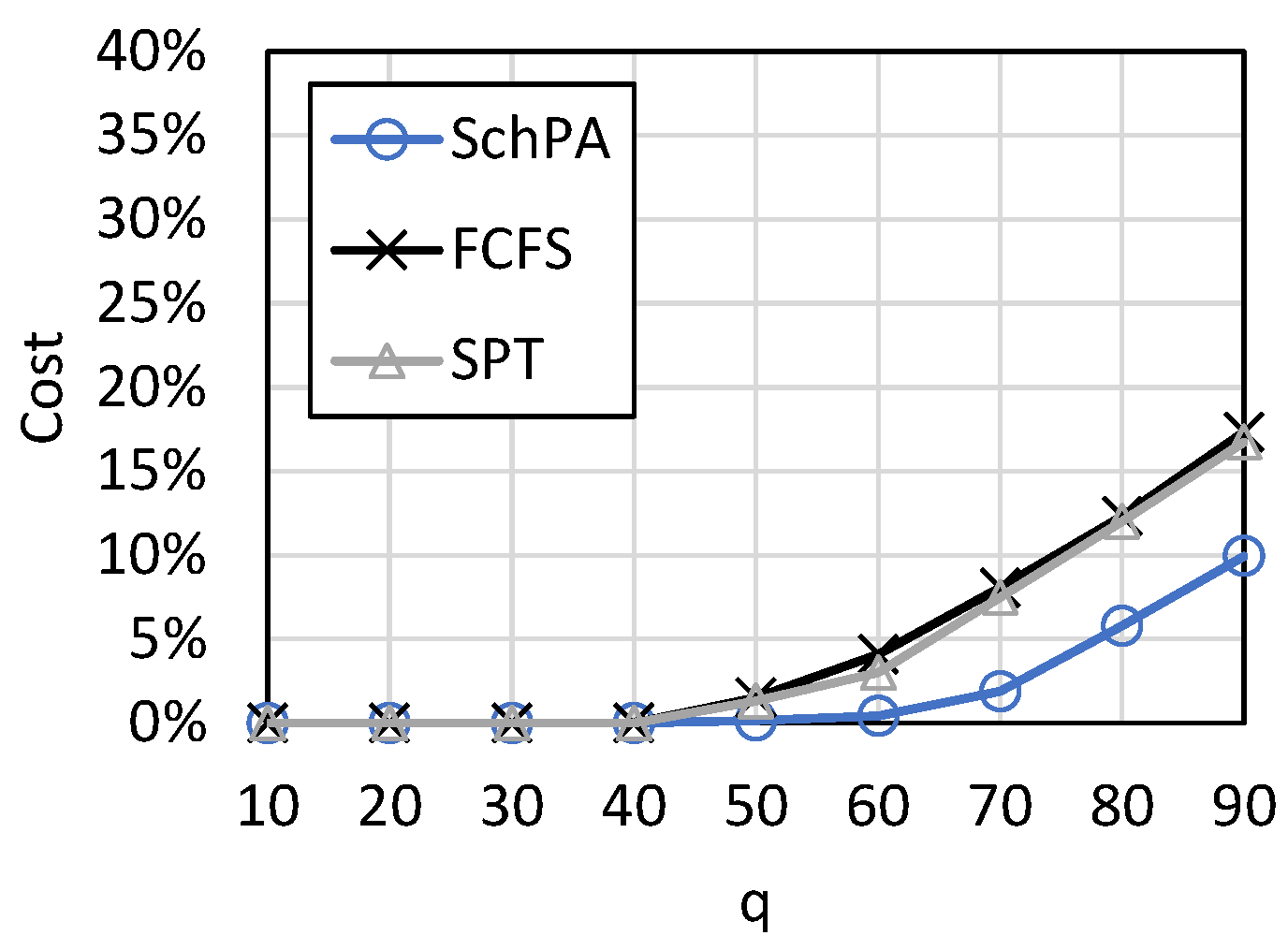
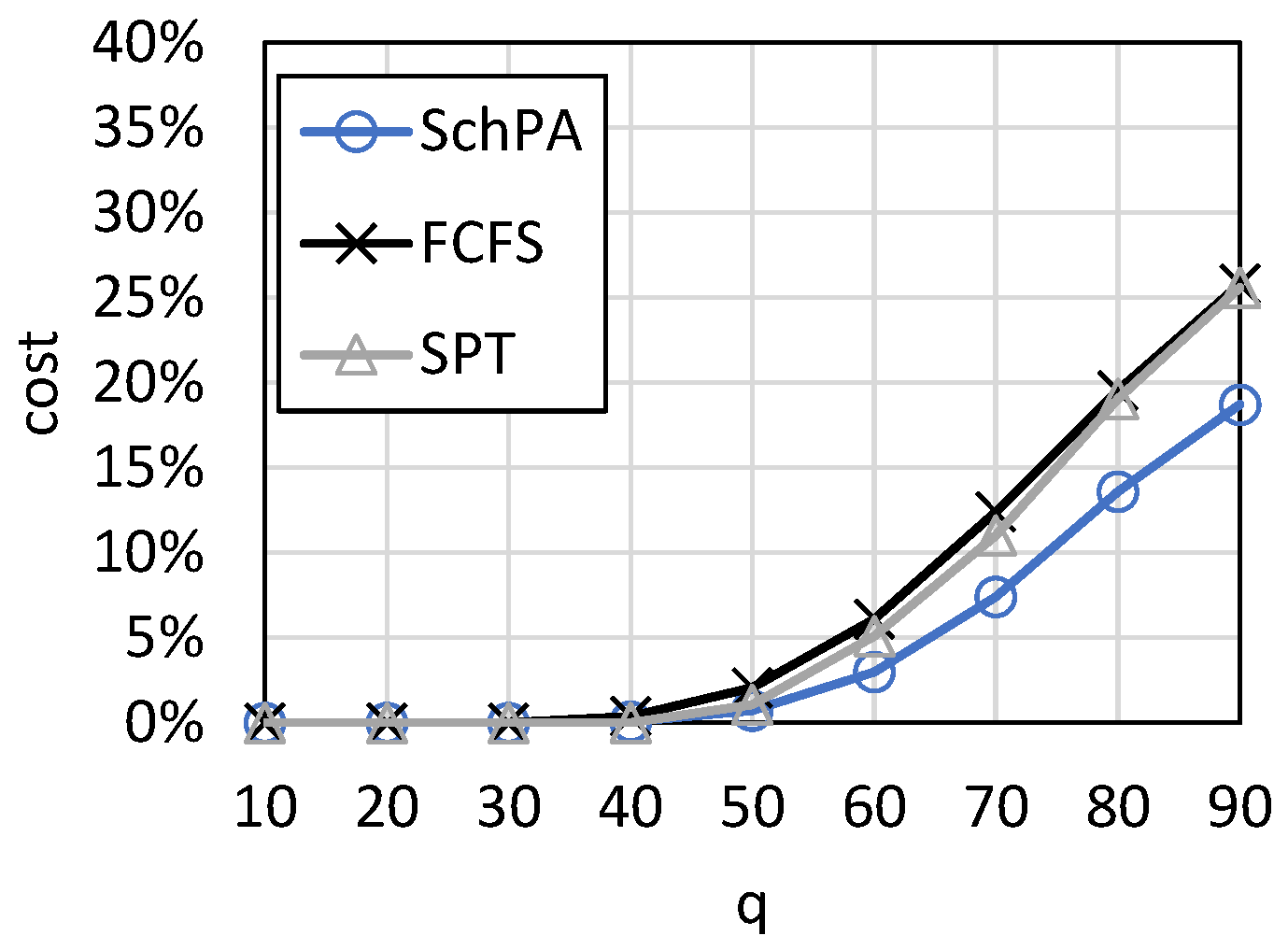
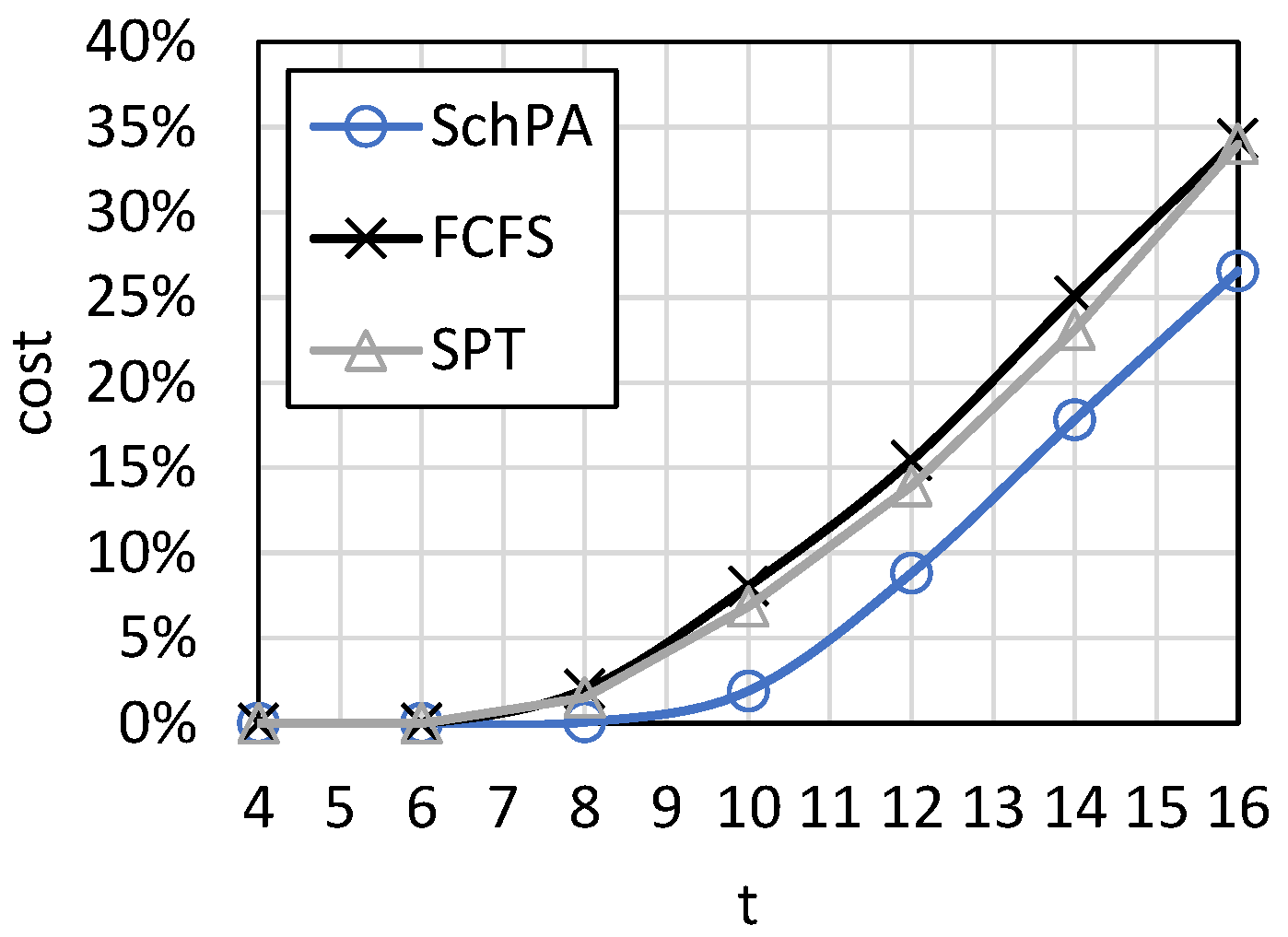
Figure 6 shows the cost loss curve with the number of orders. The parameter set is <10, 3, [1, 10], [10, 90], [50, 100], [1, 100]>. It can be seen that the cost loss increases with the number of orders. This is because the more orders there are, the more difficult it is for a limited number of machines to complete them. Since deadline and cost are optimized in our algorithm, it outperforms FCFS and SPT. SPT has less cost loss than FCFS because it can schedule production more efficiently. However, when an order fails, it needs to reproduce, so the cost loss is still large. When the number of orders is large, the proposed algorithm can reduce cost loss by about
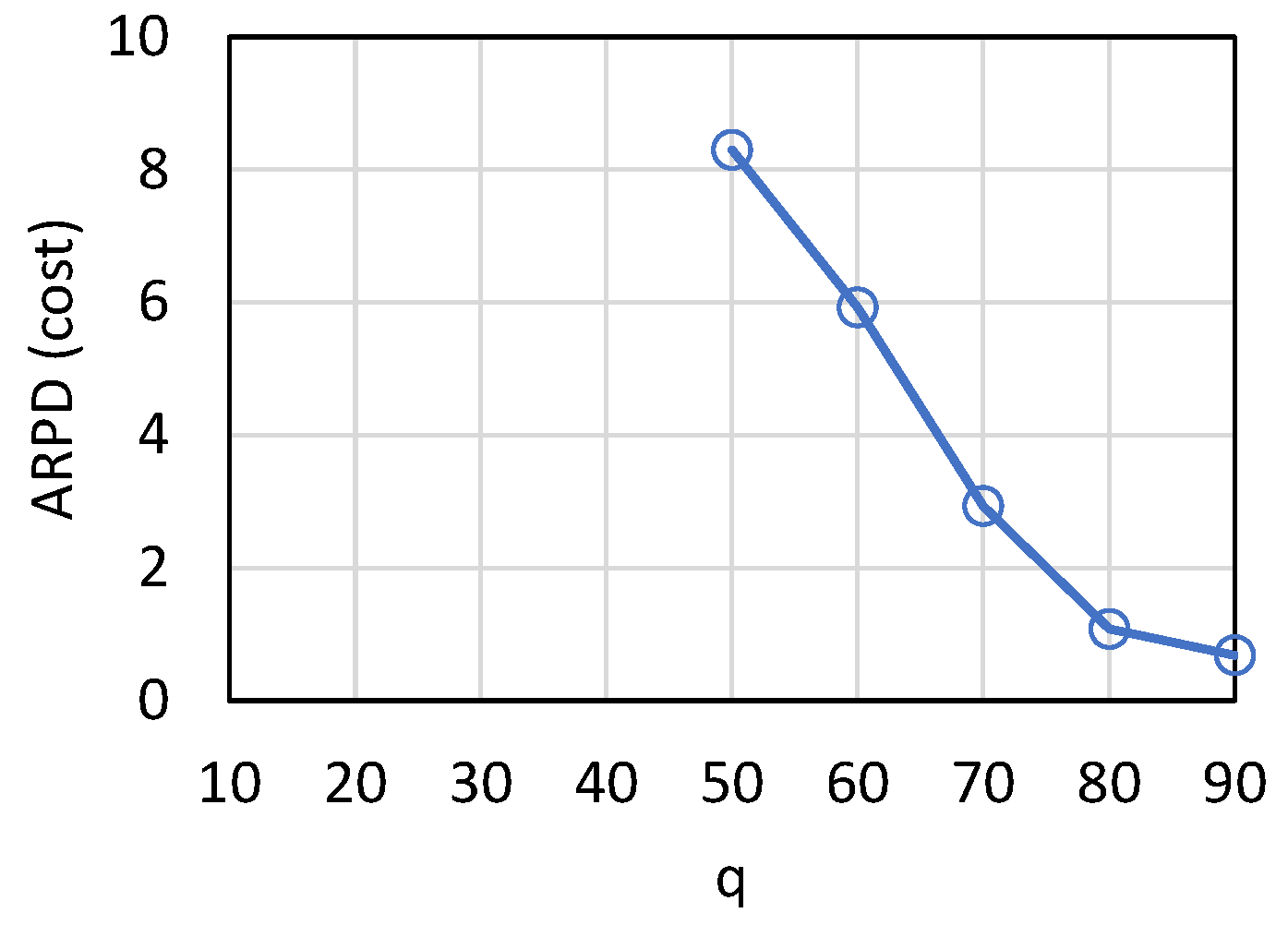
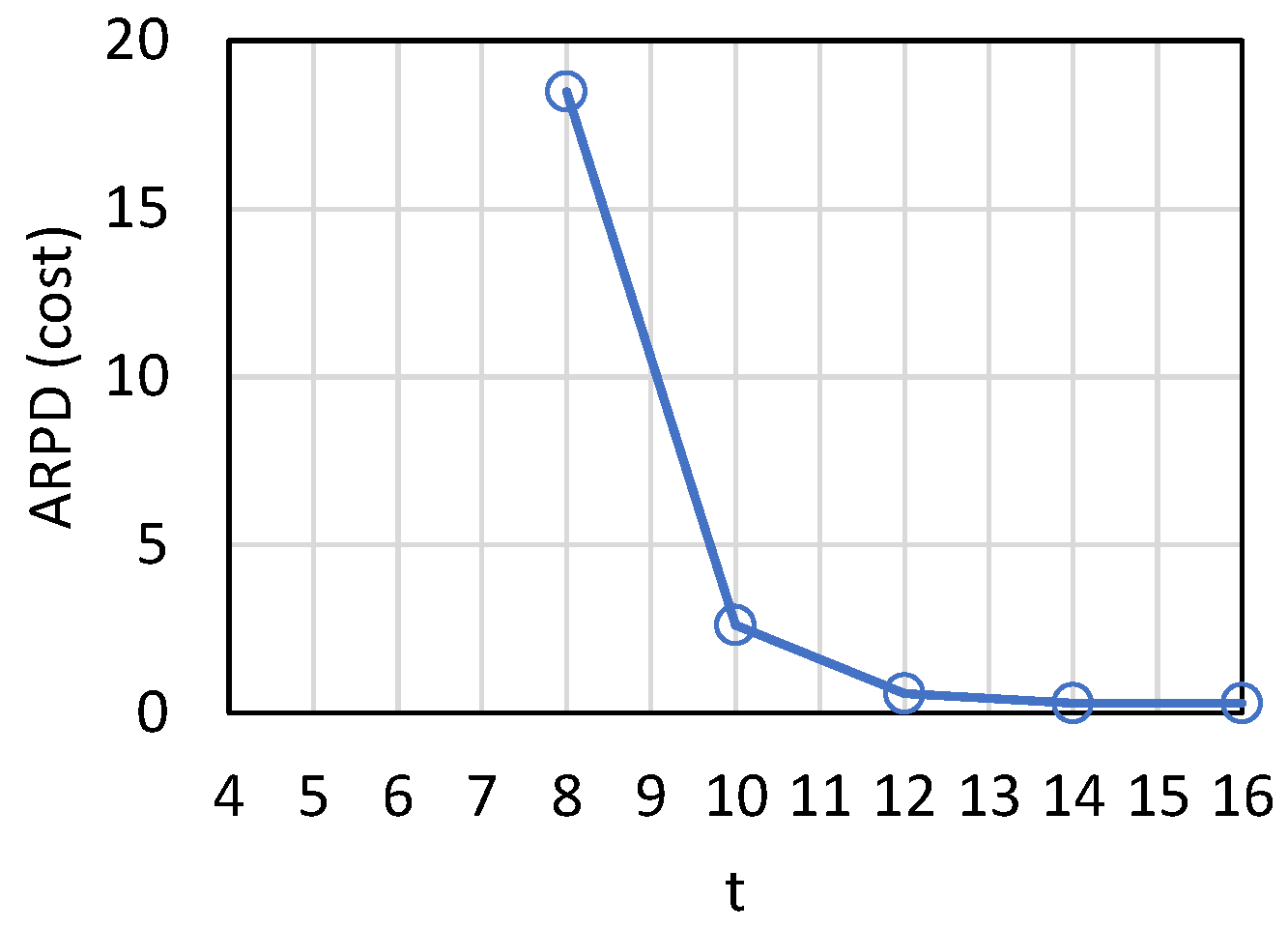
. To show the comparison result more clearly, the average relative percentage deviation (ARPD) of cost loss is shown in
Figure 7. Since SPT had less cost loss than FCFS, we used SPT and SchPA to calculate the relative percentage deviation (RPD), i.e., RPD = (SPT − SchPA)/SchPA. ARPD was the average of RPD of the 1000 test cases. In the best case, the cost loss of SchPA is about one-ninth of SPT.
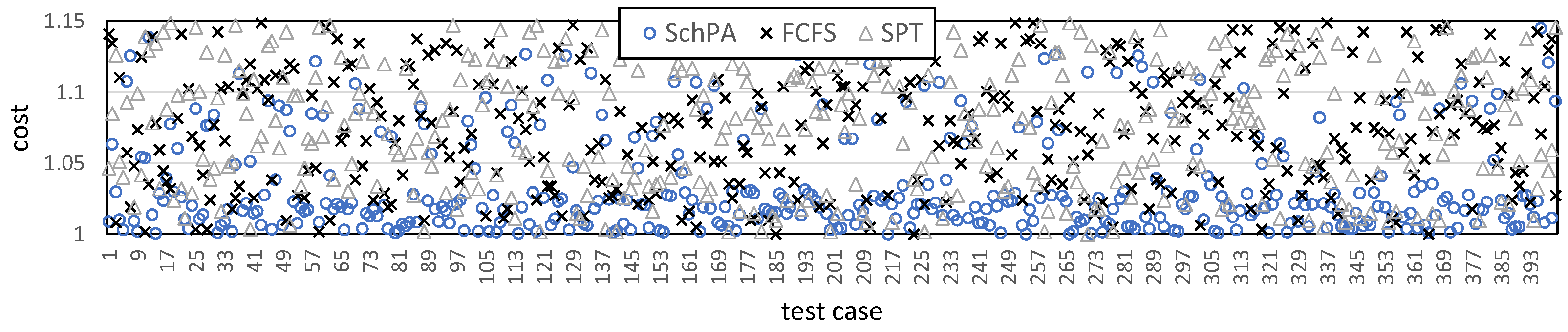
Figure 8 shows the cost loss distribution when
q = 70. Owing to the large number of orders, only partial results are shown. Regarding cost distribution, we can see that the proposed algorithm was below 1.04 for most of the orders.
Figure 9 and
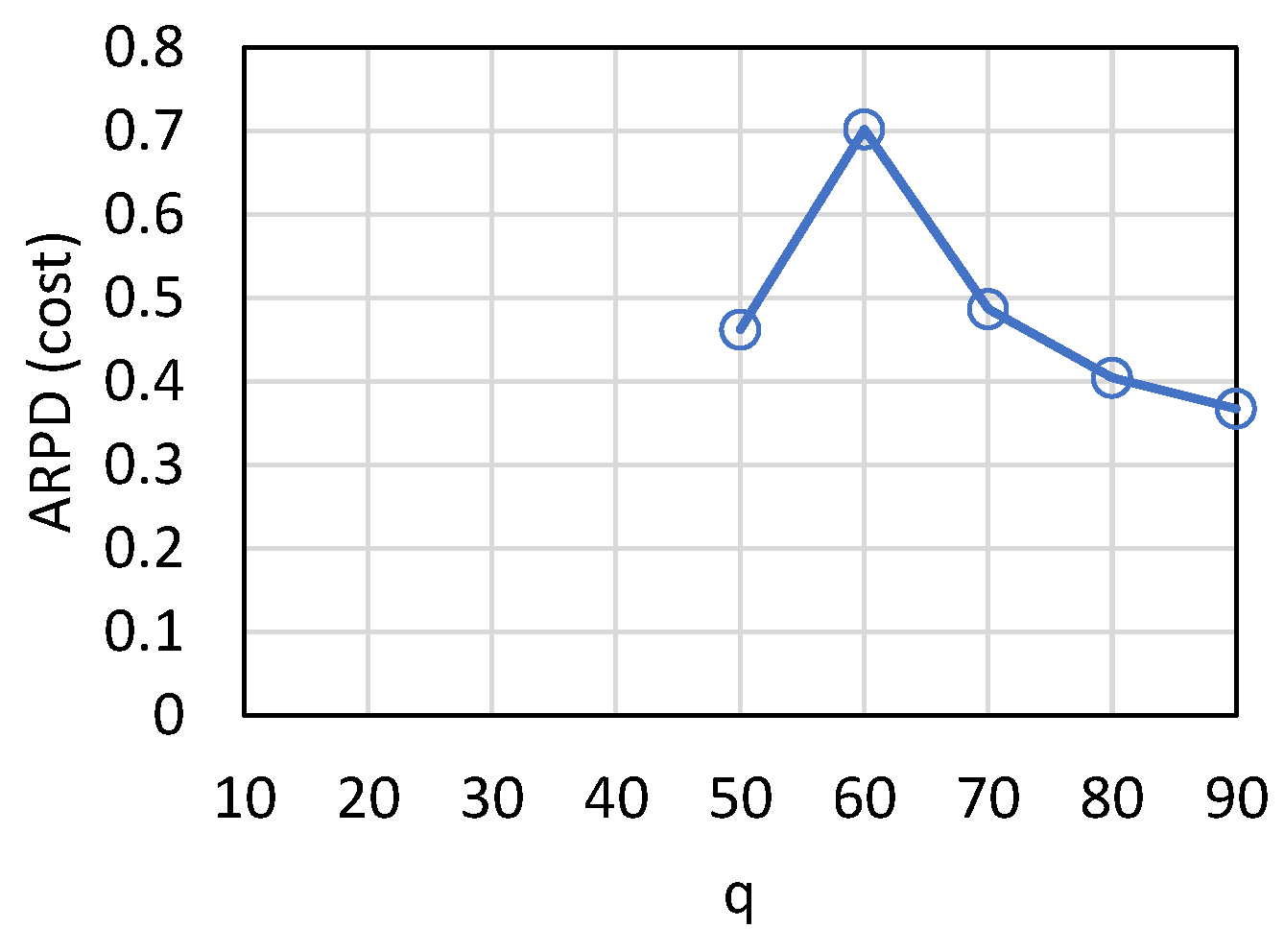
Figure 10 show the cost loss and ARPD when the deadline is shortened from [50, 100] to [50, 80]. Comparing
Figure 6 and
Figure 9, we know that after the deadline is shortened, more orders cannot be completed in time. When there are 90 orders at the same time, the cost loss increases by about
. Therefore, if the deadline can be negotiated with the customer, the later the deadline, the better. If the deadline cannot be negotiated, loss can only be reduced by increasing the number of machines (
Figure 11) or improving their efficiency (discussed later).
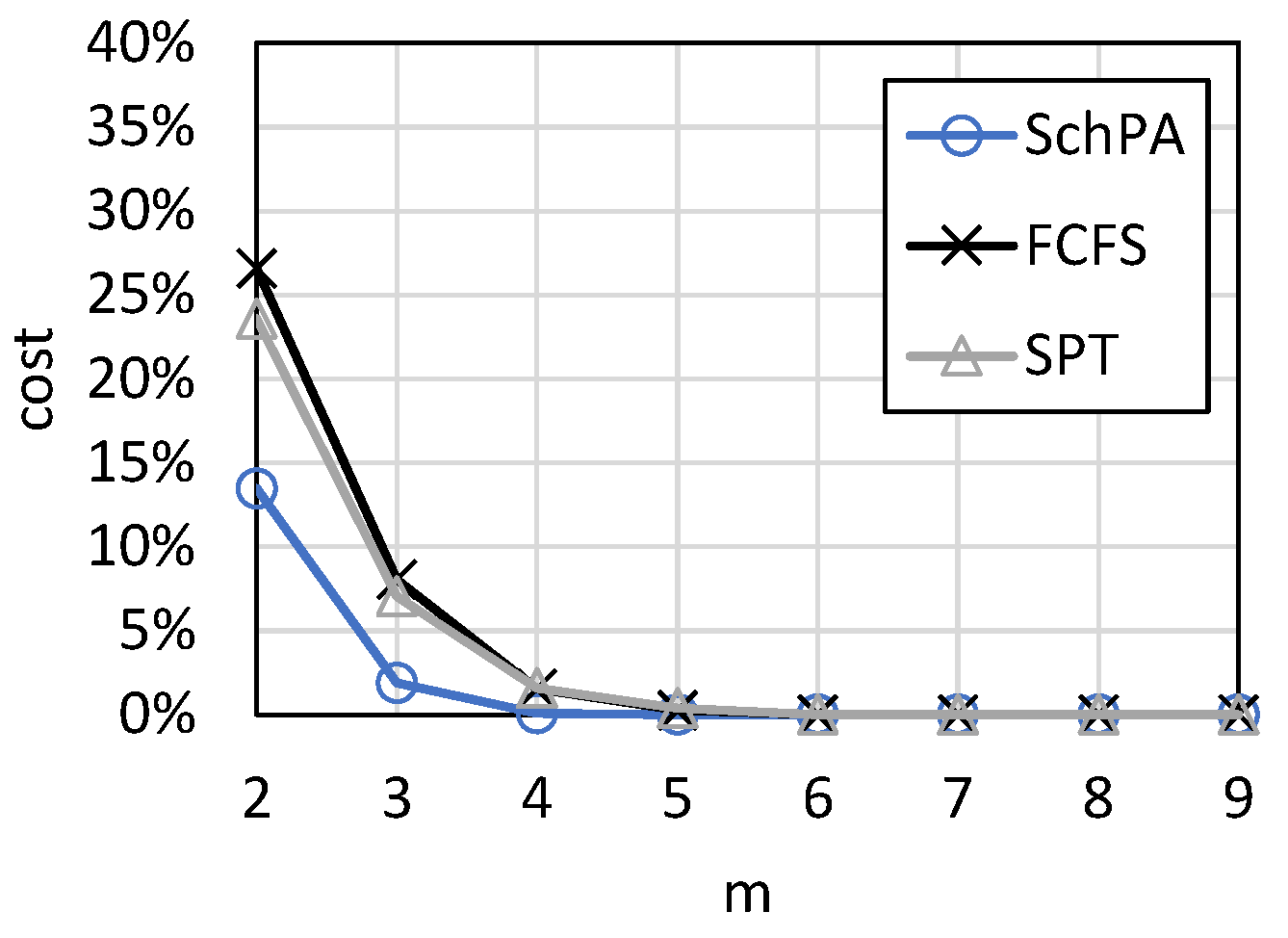
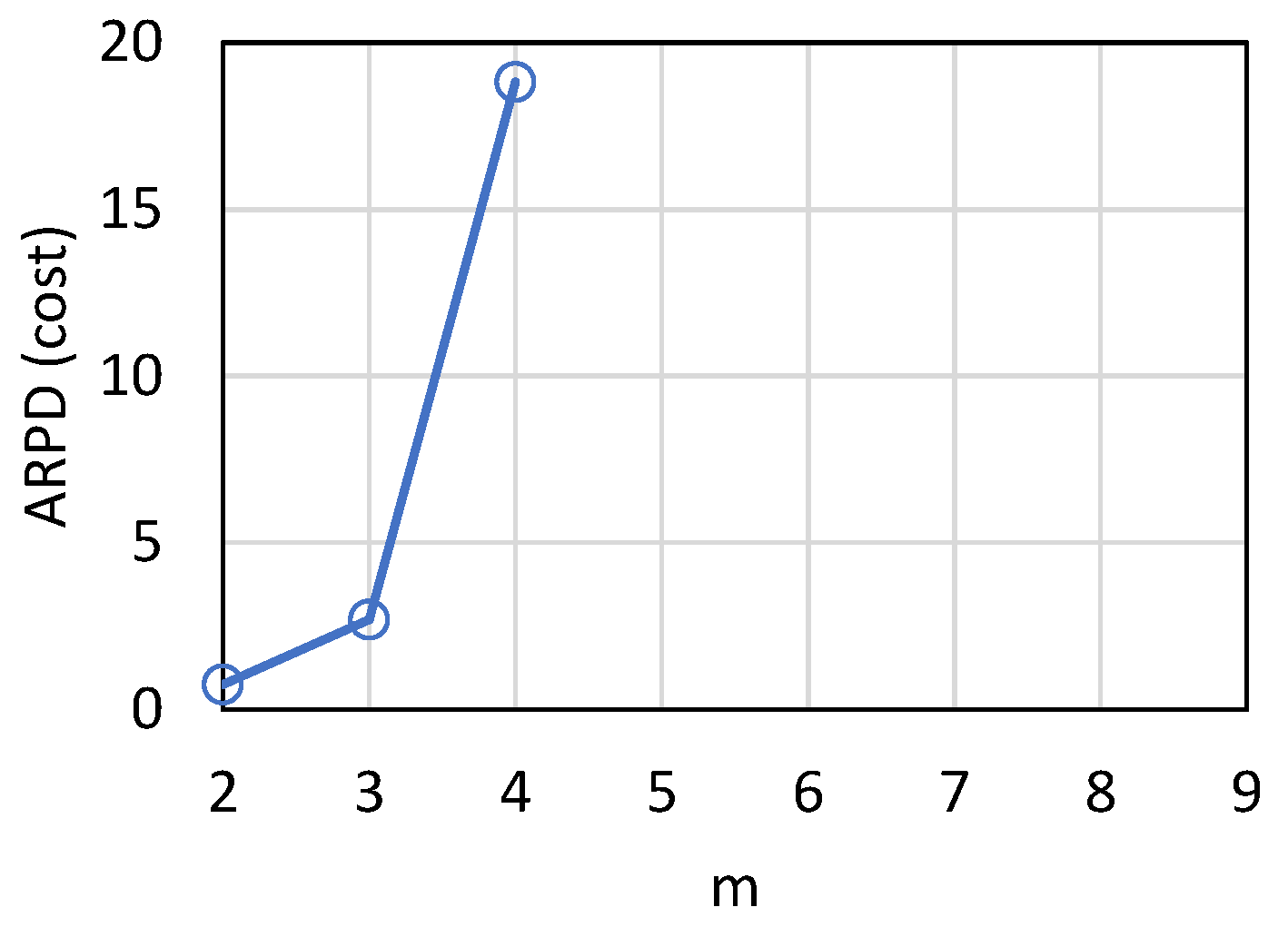
Figure 11 shows the variations in cost loss according to the number of machines, and
Figure 12 shows ARPD for the test cases of
Figure 12. The parameter set is <10, [2, 9], [1, 10], 70, [50, 100], [1, 100]>. It can be seen that when the number of machines increases to four, the cost loss decreases to zero. When the number of machines is small, the proposed algorithm is greatly superior to FCFS and SPT, suggesting that the proposed algorithm can precisely capture the competitive relationship between products and machines. When the number of machines is limited, the proposed algorithm should be used to reduce production losses.
In
Figure 13 and
Figure 14, the execution time of each operation is modified. We can see that the shorter the execution time, the higher the machine efficiency. As can be seen, cost loss increases with a decrease in machine efficiency. If improving machine efficiency will increase the cost of other parts, it will be necessary to balance the costs of various parts, such that the system achieves optimal or near-optimal performance.
Figure 15 shows the variations in cost loss according to the number of operations, and
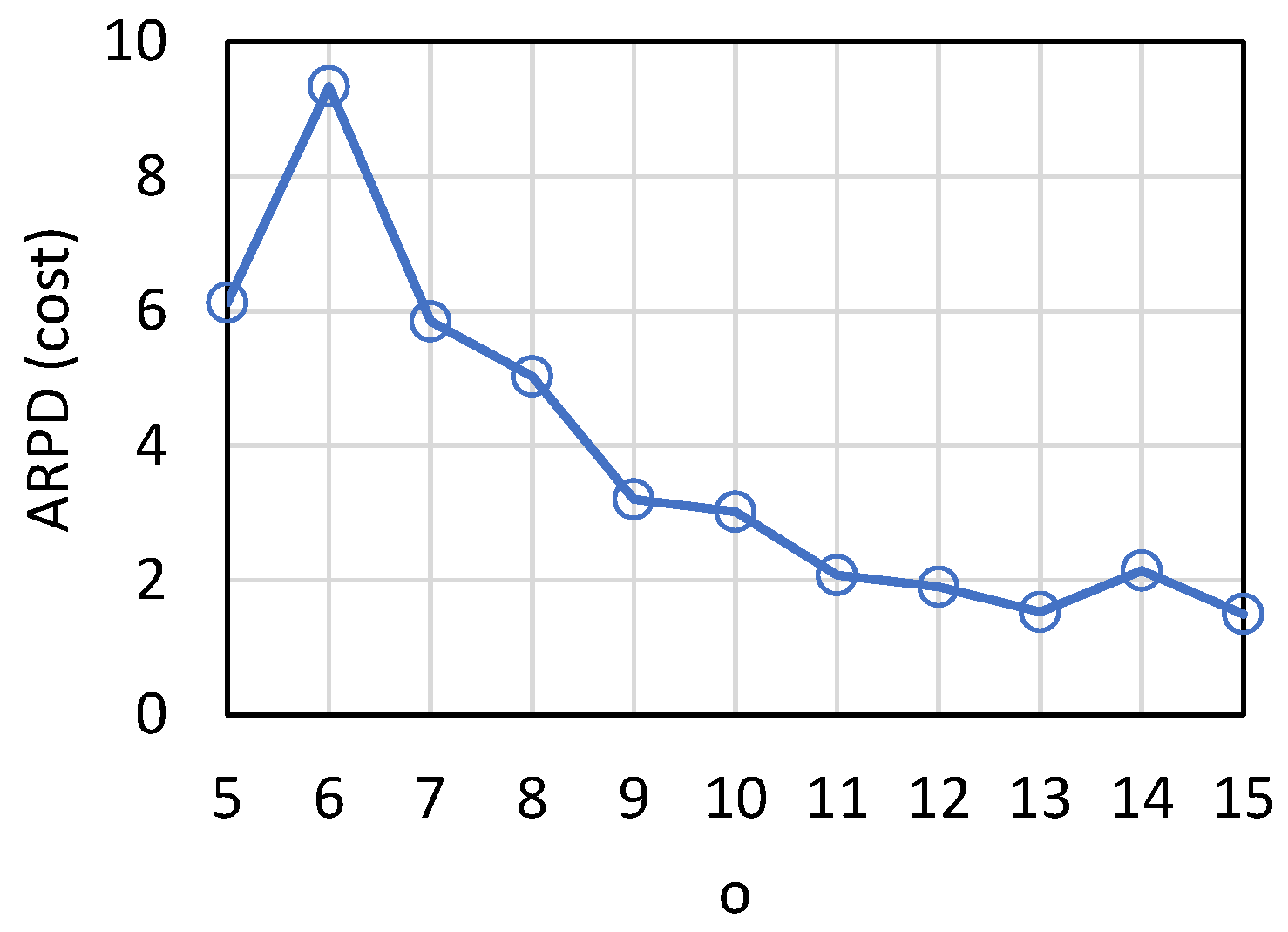
Figure 16 is ARPD for the test cases of
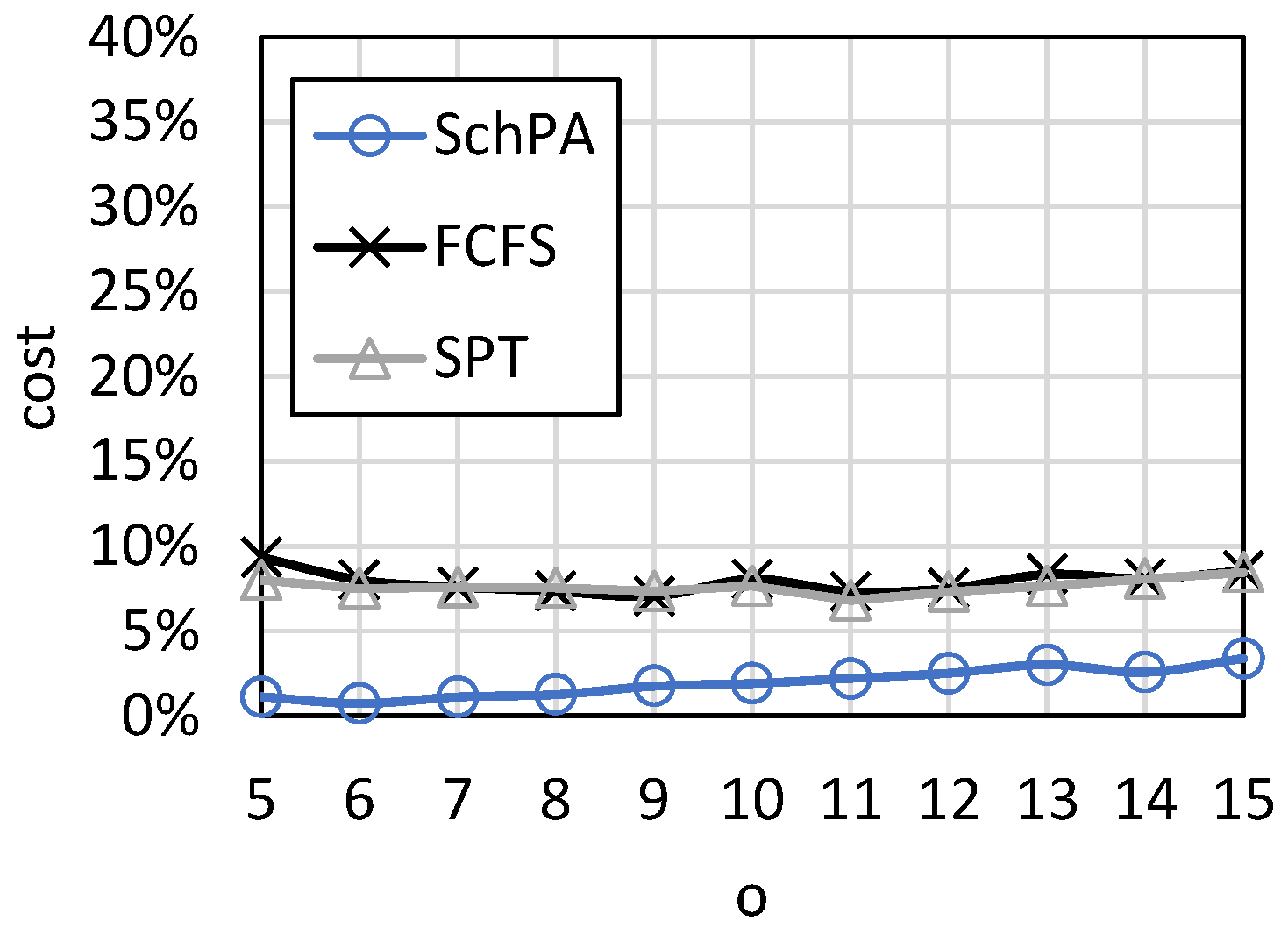
Figure 15. The parameter set is <[5, 15], 3, [1, 10], 70, [50, 100], [1, 100]>. As can be seen, the number of operations has little effect on cost loss.
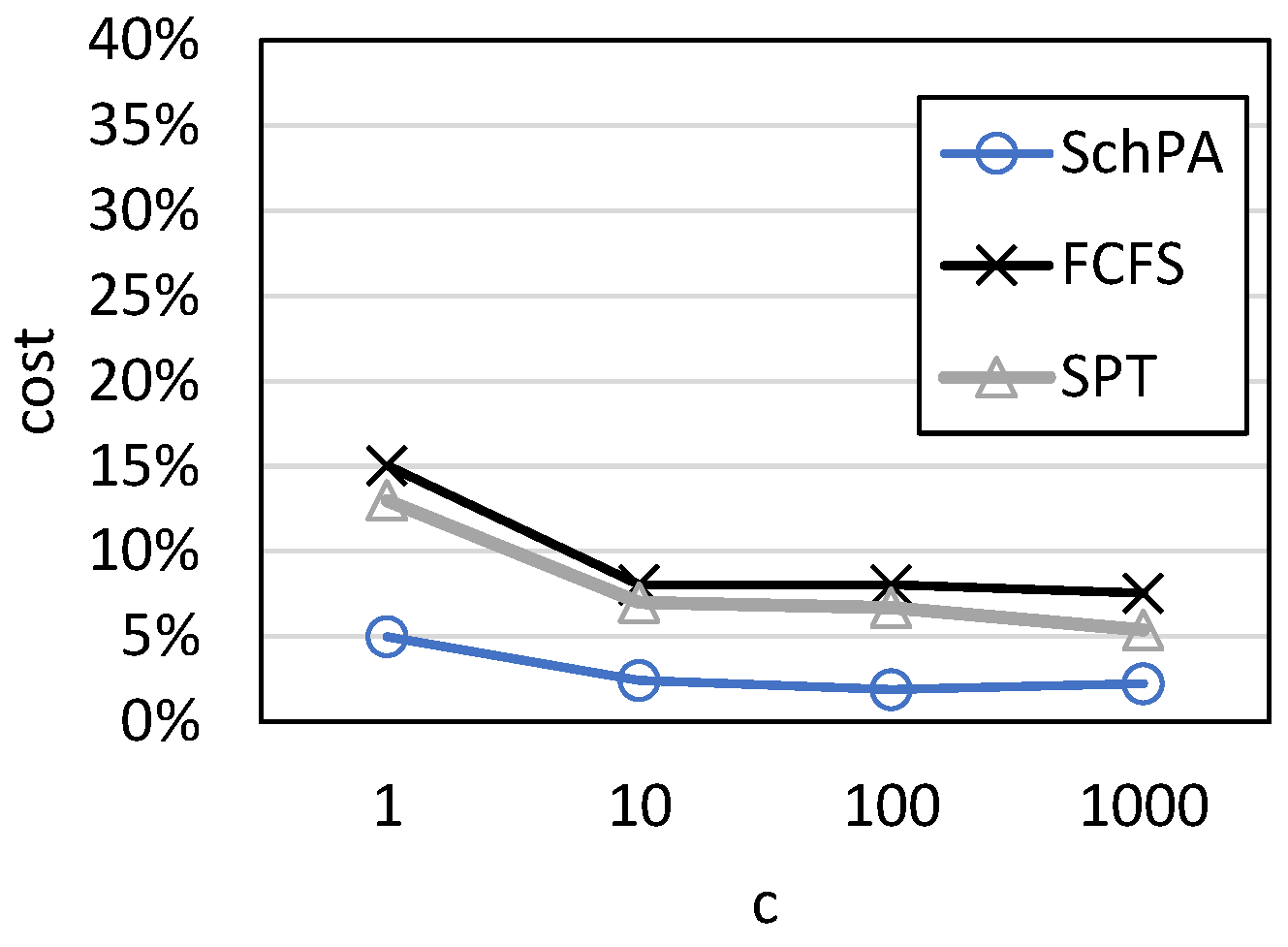
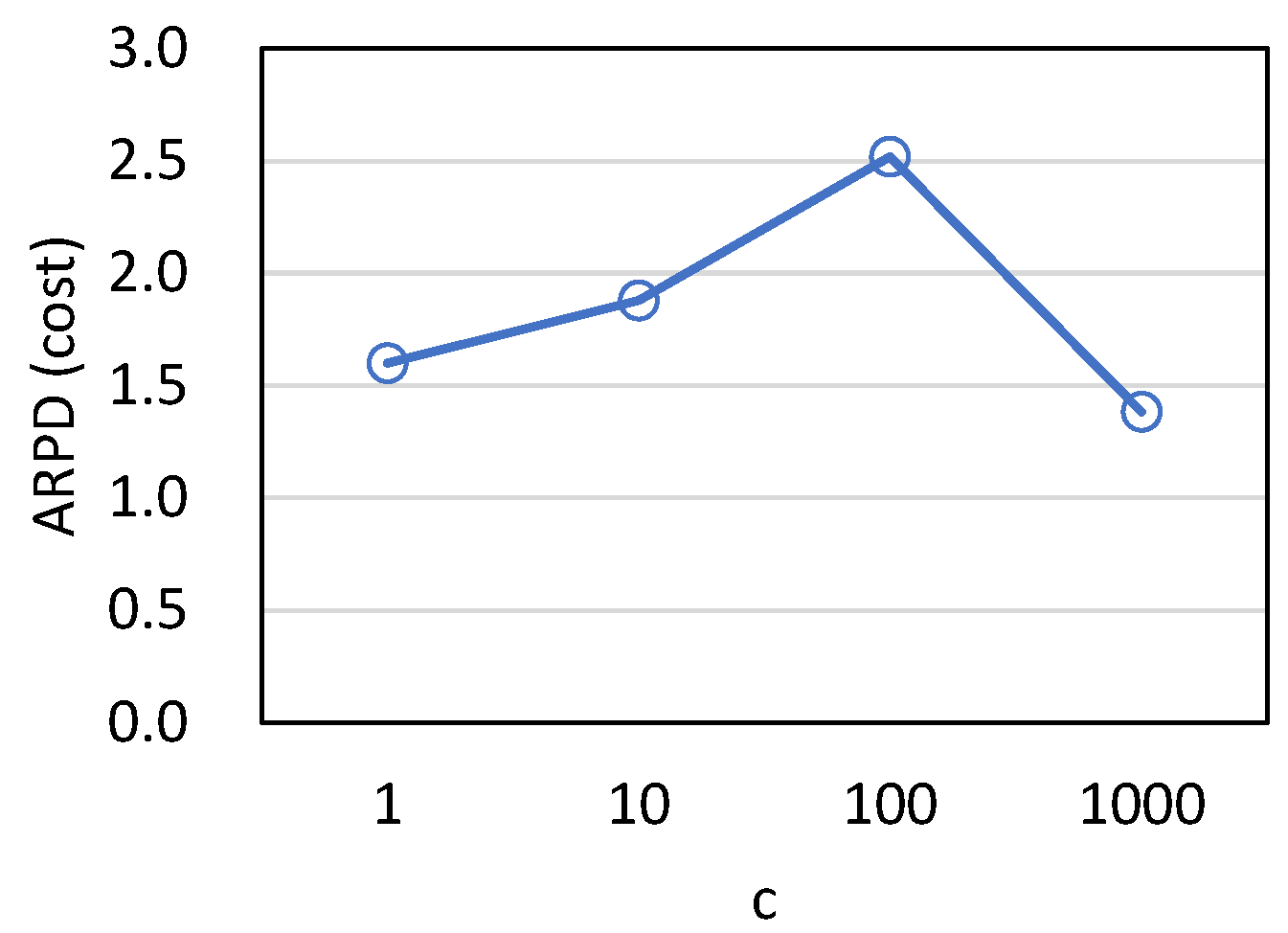
Figure 17 and
Figure 18 show the results when the cost range is modified. We can see that the cost range has almost no effect on the percentage of loss, and loss is relatively high only when all products have the same cost. When the cost is randomly selected in the interval, it is not always the maximum value. Yet, when all products have the same cost, each product has the largest loss, resulting in a large loss. As long as the cost losses of different products are different, the percentage loss remains basically the same, regardless of the range of difference.
We also calculated the p-value results of a paired-sample t-test to distinguish SchPA and SPT. Among all these parameter sets, the largest p-value is , which is smaller than 0.5. Therefore, SchPA significantly outperforms SPT.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















