
Measuring Variable Importance in Generalized Linear Models for Modeling Size of Loss Distributions



Abstract
:1. Introduction
2. Related Work
2.1. Evaluating Importance of Risk Factors in Non-Linear Regression Models via Sensitivity Analysis
2.2. Generalized Additive Models
2.3. Other Model Specific Approaches
3. Materials and Methods
3.1. Data
3.2. Specifying a Multiple Linear Regression Model for Categorical Risk Factors
3.3. Generalized Linear Models
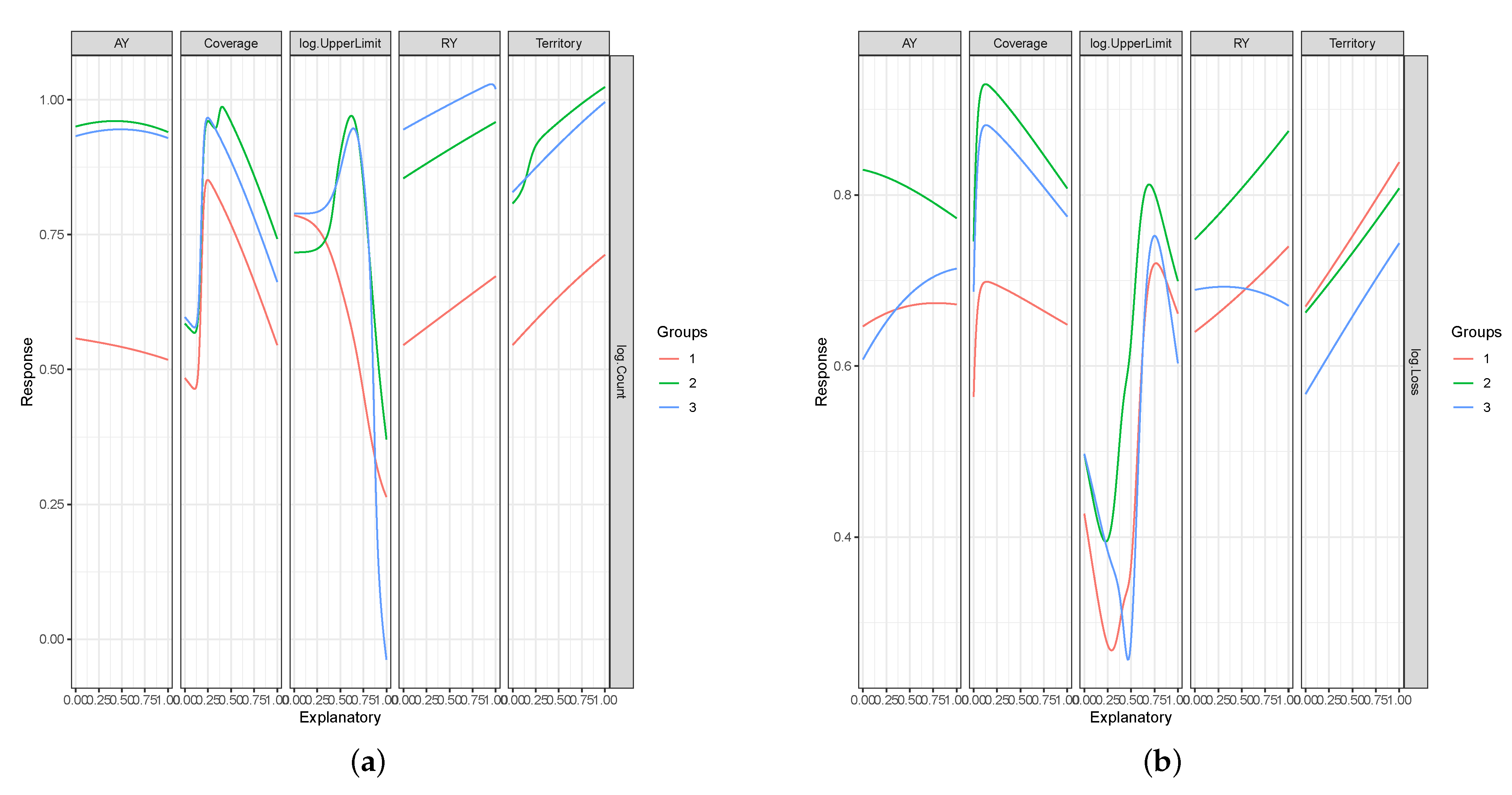
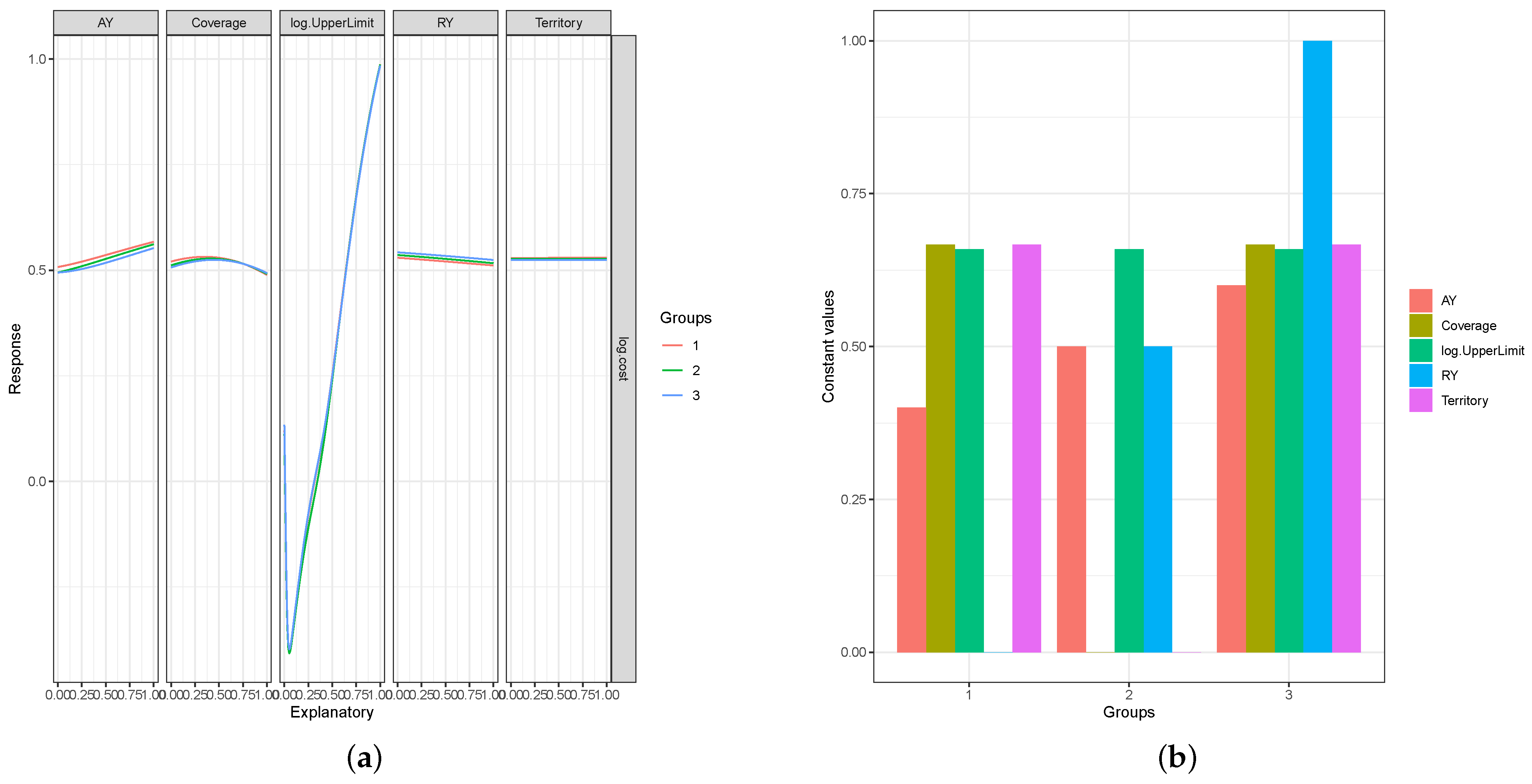
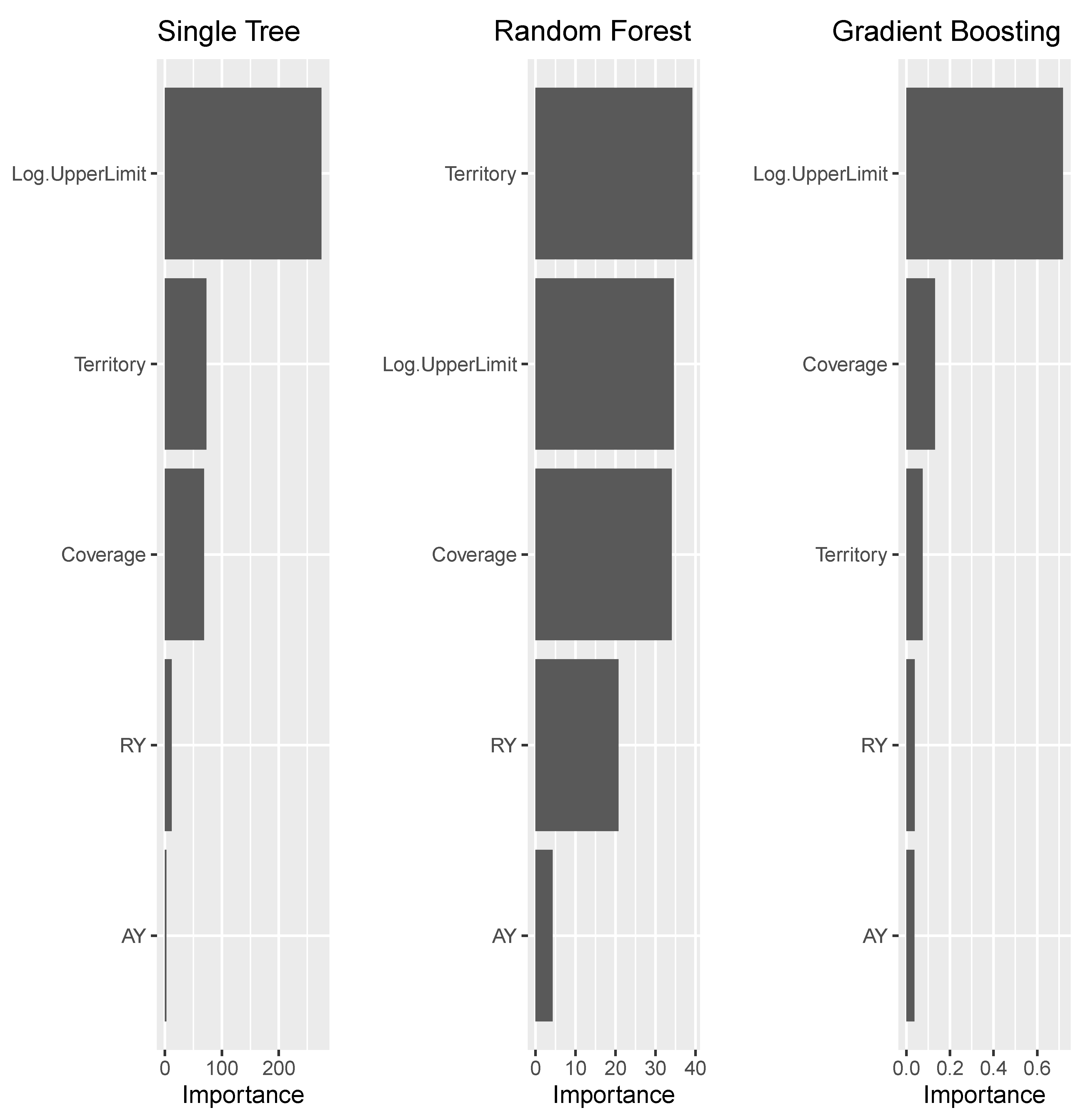
3.4. Measuring Importance of Risk Factors in GLM
4. Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- David, M. Auto insurance premium calculation using generalized linear models. Procedia Econ. Financ. 2015, 20, 147–156. [Google Scholar] [CrossRef] [Green Version]
- David, M.; Jemna, D.V. Modeling the frequency of auto insurance claims by means of poisson and negative binomial models. Analele Stiintifice ale Universitatii “Al. I. Cuza” din Iasi. Stiinte Economice/Scientific Annals of the “Al. I. Cuza” 2015, 62, 151–168. [Google Scholar] [CrossRef] [Green Version]
- Ialongo, C. Understanding the effect size and its measures. Biochem. Med. 2016, 26, 150–163. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.K. Alternatives to P value: Confidence interval and effect size. Korean J. Anesthesiol. 2016, 69, 555. [Google Scholar] [CrossRef] [Green Version]
- Heinze, G.; Wallisch, C.; Dunkler, D. Variable selection–a review and recommendations for the practicing statistician. Biom. J. 2018, 60, 431–449. [Google Scholar] [CrossRef] [Green Version]
- Chun, H.; Keleş, S. Sparse partial least squares regression for simultaneous dimension reduction and variable selection. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2010, 72, 3–25. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, Y.; Zhu, L. A review on dimension reduction. Int. Stat. Rev. 2013, 81, 134–150. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Strobl, C.; Boulesteix, A.L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thomas, D.R.; Zhu, P.; Zumbo, B.D.; Dutta, S. On measuring the relative importance of explanatory variables in a logistic regression. J. Mod. Appl. Stat. Methods 2008, 7, 4. [Google Scholar] [CrossRef] [Green Version]
- Owen, A.B.; Prieur, C. On Shapley value for measuring importance of dependent inputs. SIAM/ASA J. Uncertain. Quantif. 2017, 5, 986–1002. [Google Scholar] [CrossRef] [Green Version]
- Kuo, K.; Lupton, D. Towards explainability of machine learning models in insurance pricing. arXiv 2020, arXiv:2003.10674. [Google Scholar]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Interpretable machine learning: Definitions, methods, and applications. arXiv 2019, arXiv:1901.04592. [Google Scholar] [CrossRef] [Green Version]
- Lorentzen, C.; Mayer, M. Peeking into the Black Box: An Actuarial Case Study for Interpretable Machine Learning. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3595944 (accessed on 1 March 2022).
- Kościelniak, H.; Puto, A. BIG DATA in decision making processes of enterprises. Procedia Comput. Sci. 2015, 65, 1052–1058. [Google Scholar] [CrossRef] [Green Version]
- Jeble, S.; Kumari, S.; Patil, Y. Role of big data in decision making. Oper. Supply Chain Manag. Int. J. 2017, 11, 36–44. [Google Scholar] [CrossRef] [Green Version]
- Janssen, M.; van der Voort, H.; Wahyudi, A. Factors influencing big data decision-making quality. J. Bus. Res. 2017, 70, 338–345. [Google Scholar] [CrossRef]
- Huang, Y.; Meng, S. Automobile insurance classification ratemaking based on telematics driving data. Decis. Support Syst. 2019, 127, 113156. [Google Scholar] [CrossRef]
- Blier-Wong, C.; Cossette, H.; Lamontagne, L.; Marceau, E. Machine learning in P&C insurance: A review for pricing and reserving. Risks 2020, 9, 4. [Google Scholar]
- Crevecoeur, J.; Antonio, K.; Desmedt, S.; Masquelein, A. Bridging the gap between pricing and reserving with an occurrence and development model for non-life insurance claims. arXiv 2022, arXiv:2203.07145. [Google Scholar]
- Ohlsson, E.; Johansson, B. Non-Life Insurance Pricing with Generalized Linear Models; Springer: Berlin, Germany, 2010; Volume 174. [Google Scholar]
- Branda, M. Optimization approaches to multiplicative tariff of rates estimation in non-life insurance. Asia-Pac. J. Oper. Res. 2014, 31, 1450032. [Google Scholar] [CrossRef] [Green Version]
- Magri, A.; Farrugia, A.; Valletta, F.; Grima, S. An analysis of the risk factors determining motor insurance premium in a small island state: The case of Malta. Int. J. Financ. Insur. Risk Manag. 2019, 9, 63–85. [Google Scholar]
- Gevrey, M.; Dimopoulos, I.; Lek, S. Review and comparison of methods to study the contribution of variables in artificial neural network models. Ecol. Model. 2003, 160, 249–264. [Google Scholar] [CrossRef]
- Lek, S.; Delacoste, M.; Baran, P.; Dimopoulos, I.; Lauga, J.; Aulagnier, S. Application of neural networks to modelling nonlinear relationships in ecology. Ecol. Model. 1996, 90, 39–52. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: London, UK, 2017. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin, Germany, 2009; Volume 2. [Google Scholar]
- De Jong, P.; Heller, G.Z. Generalized Linear Models for Insurance Data; Cambridge Books; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Bencze, M. About AM-HM inequality. Octogon Math. Mag. 2009, 17, 106–116. [Google Scholar]
- Xie, S. Improving explainability of major risk factors in artificial neural networks for auto insurance rate regulation. Risks 2021, 9, 126. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
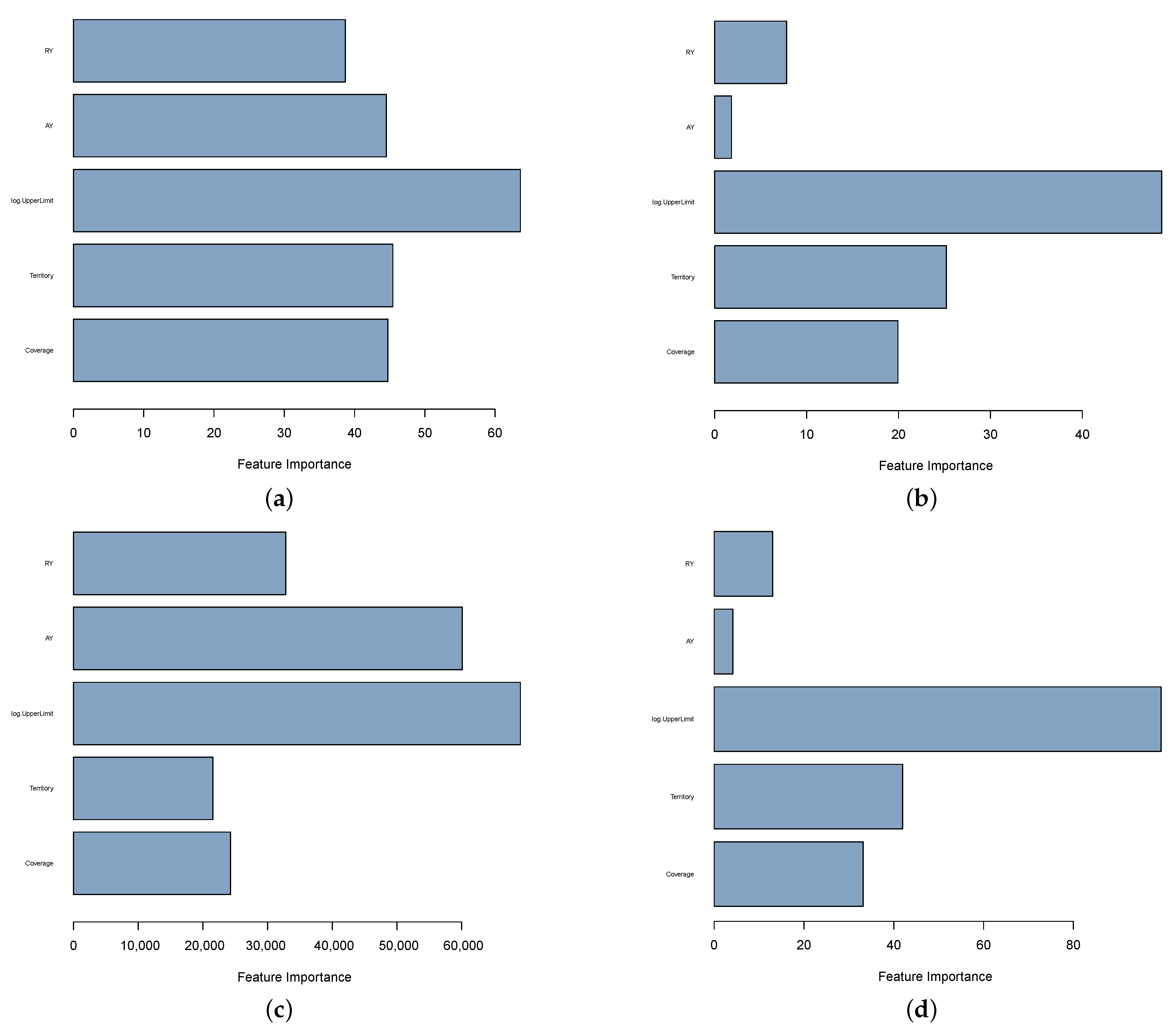{kind=link}
{kind=link}
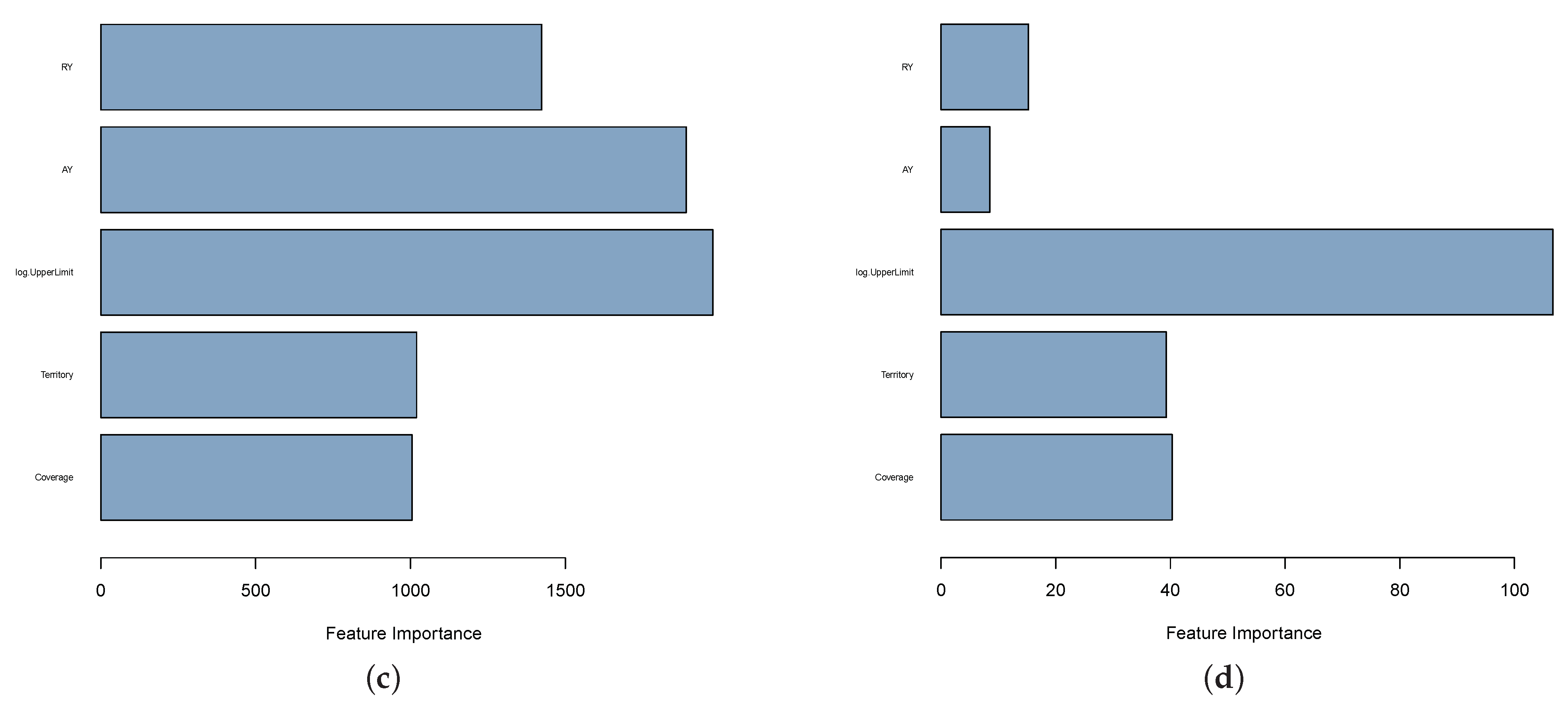{kind=link}
| Coverage: AB | ||||||
|---|---|---|---|---|---|---|
| Period | 2014 | |||||
| Trended to: | 2010.67 | 2014.75 | 1 October 2014 | |||
| Annual Trend | 7.20% | 5.10% | ||||
| Trend Factor | 1.012590732 | |||||
| LDF: | 1.738307595 | |||||
| # of Claims | Incurred losses | Incurred expenses | ||||
| Lower Limit | Upper Limit | Freq. | Total Loss | Total Exp. | Loss + Exp | Trended Ultimate |
| Losses and Exp | ||||||
| $0 | 5247 | - | $5,424,523 | $5,424,523 | $9,548,214 | |
| $1 | $1000 | 13,846 | $4,898,741 | $3,192,136 | $8,090,877 | $14,241,514 |
| $1001 | $2000 | 11,695 | $17,868,052 | $4,377,219 | $22,245,271 | $39,155,996 |
| $2001 | $3000 | 17,363 | $40,610,201 | $2,499,151 | $43,109,352 | $75,880,830 |
| $3001 | $4000 | 20,330 | $70,850,254 | $8,973,969 | $79,824,223 | $140,506,131 |
| $4001 | $5000 | 16,022 | $73,492,385 | $4,040,104 | $77,532,489 | $136,472,234 |
| $5001 | $10,000 | 31,074 | $238,908,273 | $14,664,087 | $253,572,360 | $446,336,587 |
| $10,001 | $15,000 | 13,499 | $168,725,634 | $9,305,771 | $178,031,405 | $313,369,839 |
| $15,001 | $20,000 | 8264 | $145,758,931 | $7,036,983 | $152,795,914 | $268,950,476 |
| $20,001 | $25,000 | 4354 | $97,821,028 | $5,409,368 | $103,230,396 | $181,705,540 |
| $25,001 | $30,000 | 3453 | $94,941,271 | $4,261,494 | $99,202,765 | $174,616,128 |
| $30,001 | $40,000 | 4068 | $141,599,160 | $6,328,065 | $147,927,225 | $260,380,638 |
| $40,001 | $50,000 | 2144 | $96,215,854 | $4,933,842 | $101,149,696 | $178,043,104 |
| $50,001 | $75,000 | 2308 | $139,797,760 | $6,917,330 | $146,715,090 | $258,247,045 |
| $75,001 | $100,000 | 1029 | $88,618,550 | $3,963,795 | $92,582,345 | $162,962,903 |
| $100,001 | $150,000 | 684 | $81,987,834 | $3,478,170 | $85,466,004 | $150,436,761 |
| $150,001 | $200,000 | 173 | $29,586,463 | $1,019,194 | $30,605,657 | $53,871,899 |
| $200,001 | $300,000 | 149 | $36,506,839 | $830,420 | $37,337,259 | $65,720,825 |
| $300,001 | $400,000 | 84 | $29,606,699 | $430,171 | $30,036,870 | $52,870,723 |
| $400,001 | $500,000 | 69 | $31,530,518 | $759,586 | $32,290,104 | $56,836,852 |
| $500,001 | $750,000 | 63 | $38,287,083 | $413,871 | $38,700,954 | $68,121,193 |
| $750,001 | $1,000,000 | 34 | $31,215,367 | $467,750 | $31,683,117 | $55,768,438 |
| $1,000,001 | $2,000,000 | 54 | $75,090,254 | $862,952 | $75,953,206 | $133,692,390 |
| $2,000,000 | $9,999,999 | 14 | $35,584,904 | $559,828 | $36,144,732 | $63,621,746 |
| Error Distribution | Link Function | Mean Function | Variance Approximation |
|---|---|---|---|
| Normal | |||
| Poisson | |||
| Inverse Gaussian | |||
| Gamma | |||
| Binomial |
| Dependent Variable | ||
|---|---|---|
| log.Loss | log.Counts | |
| CoverageBI | 0.008 *** (0.0005) | 0.082 *** (0.003) |
| TerritoryU | −0.010 *** (0.0005) | −0.079 *** (0.003) |
| as.factor(Log.UpperLimit)1000 | 0.009 *** (0.002) | 0.026 *** (0.009) |
| as.factor(Log.UpperLimit)2000 | 0.004 ** (0.002) | 0.057 *** (0.010) |
| as.factor(Log.UpperLimit)3000 | 0.005 *** (0.002) | 0.076 *** (0.010) |
| as.factor(Log.UpperLimit)4000 | 0.006 *** (0.002) | 0.093 *** (0.010) |
| as.factor(Log.UpperLimit)5000 | 0.0004 (0.002) | 0.078 *** (0.010) |
| as.factor(Log.UpperLimit)10,000 | −0.012 *** (0.002) | 0.032 *** (0.009) |
| as.factor(Log.UpperLimit)15,000 | −0.012 *** (0.002) | 0.049 *** (0.009) |
| as.factor(Log.UpperLimit)20,000 | −0.013 *** (0.002) | 0.060 *** (0.010) |
| as.factor(Log.UpperLimit)25,000 | −0.013 *** (0.002) | 0.071 *** (0.010) |
| as.factor(Log.UpperLimit)30,000 | −0.015 *** (0.002) | 0.068 *** (0.010) |
| as.factor(Log.UpperLimit)40,000 | −0.020 *** (0.002) | 0.045 *** (0.009) |
| as.factor(Log.UpperLimit)50,000 | −0.019 *** (0.002) | 0.063 *** (0.010) |
| as.factor(Log.UpperLimit)75,000 | −0.024 *** (0.002) | 0.043 *** (0.009) |
| as.factor(Log.UpperLimit)1 × 10 | −0.022 *** (0.002) | 0.076 *** (0.010) |
| as.factor(Log.UpperLimit)150,000 | −0.024 *** (0.002) | 0.081 *** (0.010) |
| as.factor(Log.UpperLimit)2 × 10 | −0.020 *** (0.002) | 0.134 *** (0.011) |
| as.factor(Log.UpperLimit)3 × 10 | −0.021 *** (0.002) | 0.149 *** (0.011) |
| as.factor(Log.UpperLimit)4 × 10 | −0.019 *** (0.002) | 0.218 *** (0.013) |
| as.factor(Log.UpperLimit)5 × 10 | −0.017 *** (0.002) | 0.284 *** (0.014) |
| as.factor(Log.UpperLimit)750,000 | −0.020 *** (0.002) | 0.264 *** (0.014) |
| as.factor(Log.UpperLimit)1 × 10 | −0.018 *** (0.002) | 0.365 *** (0.016) |
| as.factor(Log.UpperLimit)2 × 10 | −0.024 *** (0.002) | 0.293 *** (0.014) |
| AY2010 | −0.0005 (0.001) | −0.002 (0.007) |
| AY2011 | 0.001 (0.001) | 0.011 (0.007) |
| AY2012 | 0.001 (0.001) | 0.014 ** (0.007) |
| AY2013 | 0.0001 (0.001) | 0.013 * (0.007) |
| AY2014 | −0.0002 (0.001) | 0.019 ** (0.009) |
| RY2014 | −0.004 *** (0.001) | −0.034 *** (0.004) |
| Constant | 0.151 *** (0.001) | 0.304 *** (0.008) |
| Observations | 960 | 920 |
| Log Likelihood | −437.949 | −346.747 |
| Akaike Inf. Crit. | 939.898 | 755.495 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, S.; Luo, R. Measuring Variable Importance in Generalized Linear Models for Modeling Size of Loss Distributions. Mathematics 2022, 10, 1630. https://doi.org/10.3390/math10101630
Xie S, Luo R. Measuring Variable Importance in Generalized Linear Models for Modeling Size of Loss Distributions. Mathematics. 2022; 10(10):1630. https://doi.org/10.3390/math10101630
Chicago/Turabian StyleXie, Shengkun, and Rebecca Luo. 2022. "Measuring Variable Importance in Generalized Linear Models for Modeling Size of Loss Distributions" Mathematics 10, no. 10: 1630. https://doi.org/10.3390/math10101630