Our objective was to develop a heuristic to computationally appraise ideation quality, which allows for human expertise to be incorporated. Ideation in this study was conceptualised as the act of thinking divergently/laterally and convergently/vertically, directed at innovation. This section discusses the thinking behind the development of our heuristic.
We employed a
distant reading approach to analyse our data because we were primarily interested in exploring macro-level trends and patterns. This is an approach described in digital humanities as the computational study of text [
23,
24]. Close reading “entails close and in-depth attention to the details of a smaller section of text”, whereas distant reading “involves processing (information in or about) large corpora of texts with the help of computational analysis” [
25]. Distant reading “relies on automated procedures whose design involves strategic human decisions about what to search for, count, match, analyse, and then represent as outcomes in numeric or visual form” [
26]. In
How We Think: Digital Media and Contemporary Technogenesis, Hayles [
27] referred to this as human-assisted computer reading, where humans use computer algorithms to “analyse patterns in large textual corpora where size makes human reading of the entirety impossible” (p. 70). According to Bode [
28], “data-rich analysis has the potential to explore large-scale patterns and connections in ways that non-data-rich research cannot”. Drouin [
23] stated that distant reading can reveal “concepts that might have escaped a reader’s experience, but without acknowledging the work’s historical and discursive context”. The ability to read large volumes of text objectively and quickly to explore macro-level trends and patterns was an important criterion, hence the use of distant reading.
We chose to appraise the ideation quality of university students’ essays. In our study, students had to write an academic essay on an educational leadership topic as part of their summative assessment. The assessment evaluated their ability to connect cognate concepts with the topic (a process we consider as the lateral association of concepts), and their ability to expand concepts (a process we consider as the vertical expansion of concepts). This corresponds to divergent and convergent thinking, respectively.
There was a compelling motivation behind our decision to investigate university student essays. Some courses in our university have an enrolment of more than 2000 students, making the task of marking their essays with tight deadlines challenging. We collaborated with our colleagues conducting these courses to investigate how thousands of essays could be analysed computationally. Out of the six habits we highlighted earlier, ideation quality was a metric that we deemed most suitable for exploration.
Aside from having to assess thousands of essays efficiently, another important reason was to address variability in marking standards. A course with over 2000 students and tight deadlines will require a great number of human markers with relevant expertise. Different markers will have different backgrounds and expertise, so this will inevitably translate into different interpretations of the marking rubrics, and subsequently, different marking standards. Students’ scores consequently reflect not just their performance, but also the artefacts of markers’ subjectivity. This problem is similarly present when evaluating creativity [
29]. However, with the use of computational methods, instead of personalities, the artefacts of subjectivity can be attenuated while still respecting the fact that creativity does not exist independently, but is instead part of a complex system of interacting personal, social, and cultural factors [
17,
18,
29,
30,
31].
3.1. Data
The essay assignments submitted by postgraduate students in educational leadership courses constituted part of our data. The following exemplified an actual essay assignment instruction from a doctoral-level course:
Write a scholarly paper of 10–12 pages (not including the title page and reference page(s), consistent with expectations for graduate-level writing. The topic of the paper is “Educational Leadership for Developed Countries (Advanced Economy)”. In your paper, you are expected to discuss, critique, and explore at least three major concepts from the class discussions, presentations and reading list.
Addressing the assignment would require students to think divergently in terms of the major concepts related to the theories and practices of educational leadership. They would also be required to expand upon the concepts (i.e., think convergently) by discussing, critiquing, and exploring how these concepts and practices will meet the challenges of developed countries. The challenge imposed by such an assignment is coherent with the process of ideation, as the students could not simply just discuss, critique, and explore, without also advancing a thesis.
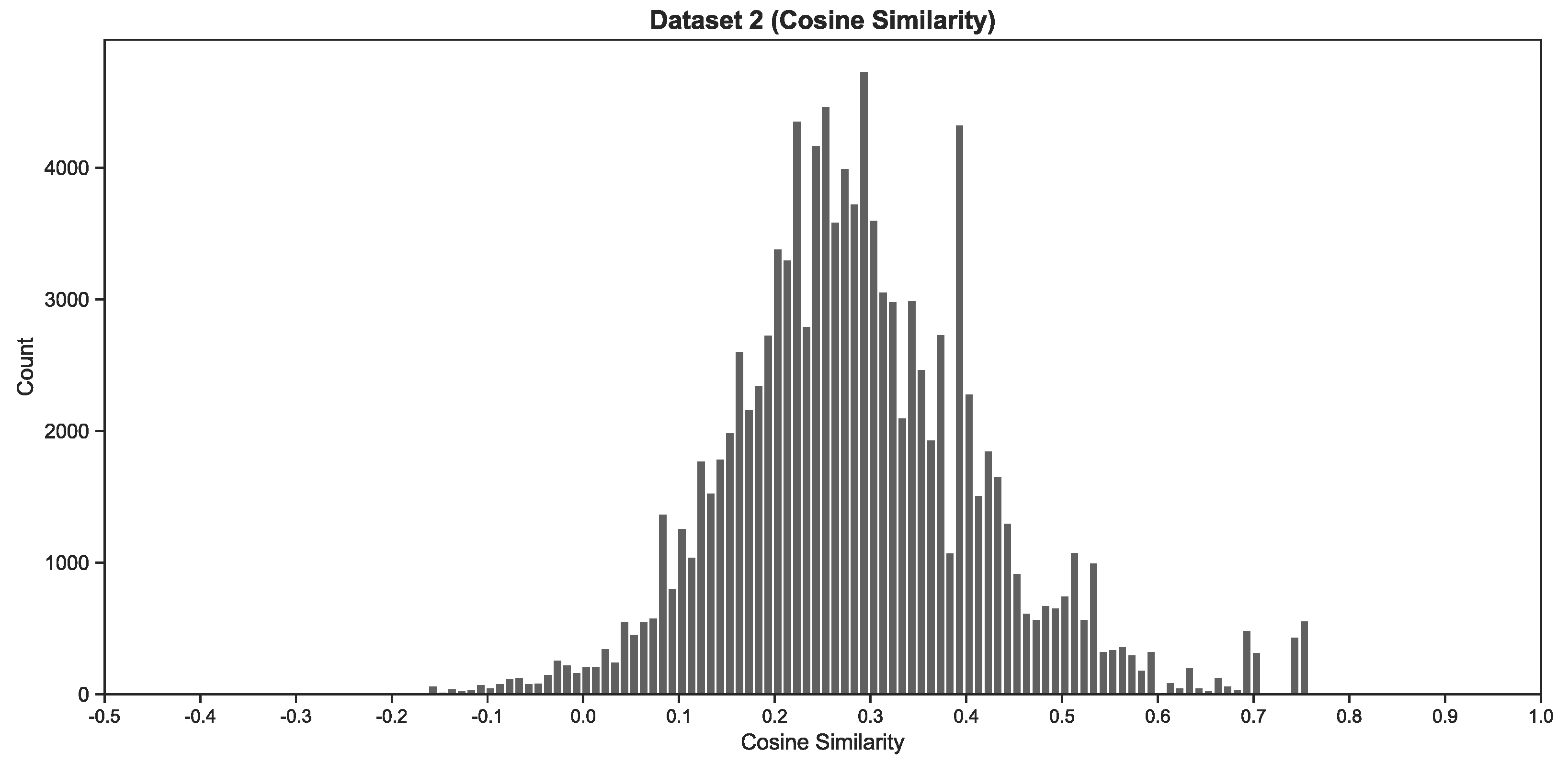
Our study investigated two essay datasets. Dataset 1 is a corpus that consists of all five essays submitted by students for a doctoral-level course on “Current and Emerging Educational Leadership Theories” in 2015. Dataset 2 is a corpus that consists of all 23 essays submitted by students for a Master’s level course on “Educational Leadership and Principalship Theories” in 2016. These two courses shared the same assignment topic and were conducted by the first author, who also graded the 28 essays.
As our study was not a typical quantitative or qualitative research study, what constituted data must be clarified. The study involved analysing the essays submitted by 28 postgraduate participants—as part of the development of a heuristic. We were specifically interested in the artefacts produced from a treatment of their essays. Therefore, it would not be appropriate to simply describe our study as involving a population size of 5 and 23, respectively, since there were at least 50,000 and 110,000 data points, respectively. Instead, it would be more accurate to state that our unit of analysis is an essay, and our unit of observation is a word pair—a construct we elaborate later in
Section 3.2.
In addition, it must be highlighted that computers cannot understand text. To analyse text using NLP, it must first be transformed into vectors, also called word embeddings. A vector in this case would be the representation of a word. As it was not possible to collect additional data due to ethics and privacy challenges, we were limited to 28 essays. This was nowhere near enough to generate robust word embeddings. Consequently, we decided to employ the largest English language word embeddings provided by spaCy (
https://spacy.io/, accessed on 1 January 2020). This came packaged as
en_core_web_lg-3.2.0, which stood at approximately 741 MB. This comprised approximately 684,830 unique vectors, each with 300 dimensions. Doing so allowed us to better determine the semantic similarity of word pairs, in comparison to word embeddings generated from only 28 essays—with text all associated with the same assignment topic. As such, while there were only 28 essays, these were also essays interpreted through the lens of an exponentially larger collection of text.
3.2. Method
The discussion of our methods will be conducted at a more conceptual level as it is beyond the scope of this journal to go into the specificity of data operations.
To reiterate, we aimed to computationally appraise ideation quality in the context of university student essays. Consequently, we had to review the literature to unpack what constitutes an idea, and how the quality of an idea in the context of CPS can be evaluated, given there are no personalities, only algorithms.
We operationally defined a discrete idea as a word pair in the context of university student essays. A word pair is the result of taking what is basically the Cartesian product of the list of words in the title and the list of words in the content of an essay; but not the mathematical sense of Cartesian product where items in a set must be unique. For example, if we have an essay with the title words “T1 T2 T3”, and the content words “C1 C2 C2”, the Cartesian product would be as follows: T1-C1, T1-C2, T1-C2, T2-C1, T2-C2, T2-C2, T3-C1, T3-C2, T3-C2. Word pairs may not necessarily be unique since the same word can appear multiple times in an essay. As we were concerned with idea quantity and not idea variety, this was not considered problematic [
10].
Even though our method focused only on the relationship between title and content words, we are not suggesting that ideation cannot take place locally at the sentence or paragraph level. However, investigating ideation quality at the sentence or paragraph level can become unwieldy due to the ambiguity of language. NLP problems such as coreference resolution and word sense disambiguation can be challenging not just to computers, but also humans [
32]. This challenge can be further compounded given the nature of academic writing. Whether a sentence should be qualified syntactically or semantically also has to be considered, in addition to
how. Introducing different levels of analysis for individual essays will also result in different baselines. Essays with more sentences and paragraphs will translate into a higher number of word pairs. We previously explored heuristics that involved student-prescribed titles, if any, as opposed to the assignment-prescribed title. We also explored incorporating essay-specific salient words to complement the assignment prescribed title. These resulted in some essays yielding an exponentially higher number of word pairs—enough to significantly impact final outcomes. Doing so no longer presented the analogue equivalent of students, positioned on platforms characterised by the same task parameters and context, creatively solving problems and innovating. As highlighted earlier, creativity does not exist independently. To study creativity with respect, we instead sought to indirectly observe variances in the path treaded. Therefore, we chose to focus only on the relationship between title and content words after having considered the implications.
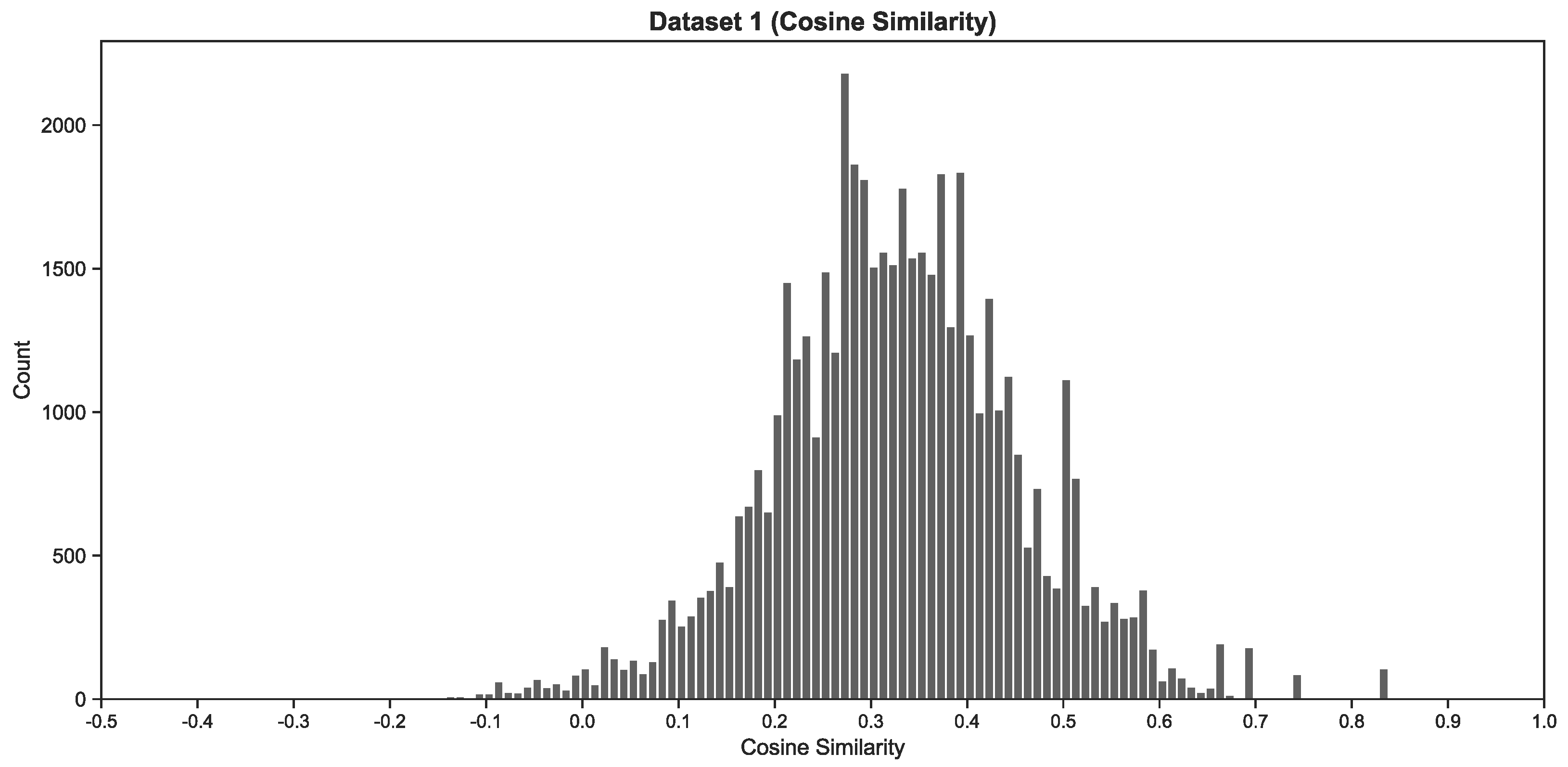
To appraise the ideation quality of a single word pair, we first quantified the semantic similarity between its title word and its content word. This involved computing the cosine similarity between the vector representation of each word—the cosine of the angle between two vectors. The result would be a value between −1.0 and 1.0, but most values were positive with the word embeddings we employed. Without taking into consideration the artefacts of the word embeddings employed, the cosine similarity of a word pair can be interpreted as follows:
Real-world data require interpretation to take relevant factors and contexts into consideration.
Computers cannot understand text as we highlighted earlier. This is why text must first be transformed into vectors. The validity of this transformation is premised on the linguistic principle of distributional hypothesis put forward by Harris [
33]. The underlying idea is that the distribution of words in a language is not random, and that the meaning of a word can be inferred through its co-occurrence with other words (p. 146). The reason we can use the cosine similarity between two vectors to determine semantic similarity is because the direction of a word’s vector representation is indicative of its meaning [
34].
Given that creativity and CPS fundamentally involve divergent and convergent thinking, we decided to similarly discriminate between divergent and convergent ideas. To do so, we further weighed the cosine similarity of each word pair so as to yield a more coherent unit of analysis.
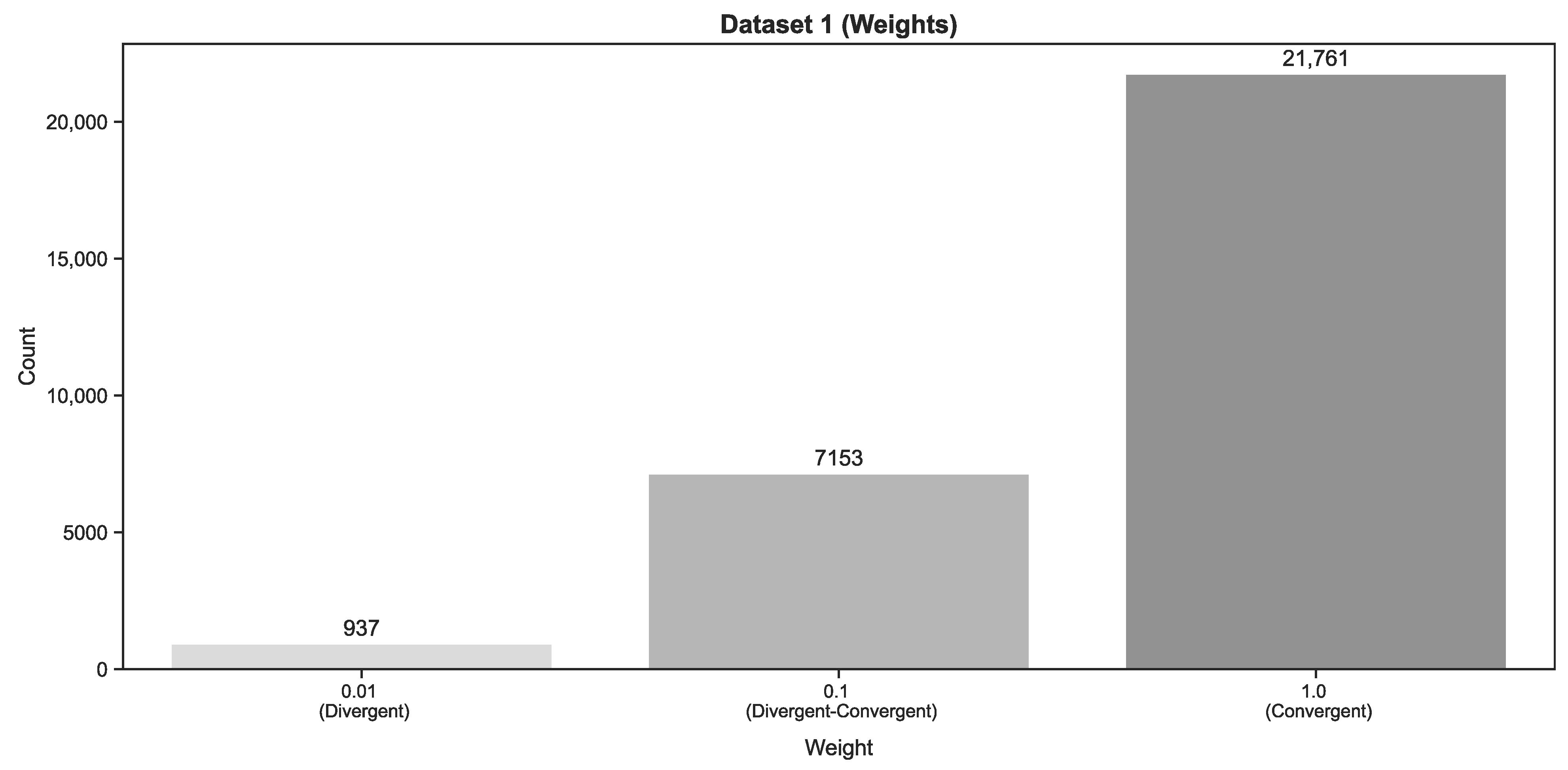
Table 2 below demonstrates how word pairs were grouped and ascribed a weight.
The cosine similarity ranges indicated above are ranges that we felt best reflect the data, following discussion with the first author as domain expert. This was based on a rule of thumb approach. As we were primarily interested in the macro-level trends and patterns that would emerge, precision was not a concern and also not as relevant. This aspect of our heuristic is where we acknowledge that creativity does not exist independently, and where we incorporate human expertise.
To facilitate the calibration of these ranges by a domain expert, we constructed a “semantic ruler”—essentially a simple NLP application to determine the cosine similarity between select word pairs. See
Figure 2 below for an example.
In this particular example, the first author as domain expert selected the title word “leadership” and a set of 11 content words. The content words included words the first author considers to be prominent to the essay topic, as well as words known not to be associated with leadership. This helped to establish points of reference. Explicitly knowing the cosine similarity of potential word pairs allowed the first author to better determine the cosine similarity ranges to qualify convergent, divergent-convergent, and divergent ideas.
We discarded word pairs with values below 0.30 because we considered such word pairs to be artefacts of linguistic expression rather than ideation per se. Again, this followed discussion with the first author as domain expert. As indicated earlier, we are not suggesting that ideation cannot take place locally at the sentence or paragraph level. Words that are part of a compound subject, verb, or object of the sentence may be directed at elaborating the local subject, verb, or object. Congruently, not all words in a sentence will serve to expand directly upon the title. Examples include closed-class words such as “it” and “neither”, and proper nouns such as “John” and “Brown”. We decided that 0.30 should be the threshold where word pairs would no longer be considered sensible in the context of our data and should be treated as noise.
Table 3 below illustrates how we conceived of divergent and convergent ideas given the title word “leadership” as an example.
Divergent thinking is a critical component of creativity and CPS. It can also be thought of as the ability to think laterally. Conversely, convergent thinking can be thought of as the ability to think vertically. But divergent thinking in itself is only a means to an end. As highlighted in the literature review, creative ideas on their own are simply unusual combinations or statistical surprises. They are merely probabilities and inconsequential. In the same vein, simply presenting an assortment of ideas from the literature does not constitute an academic essay. We expect postgraduate students to additionally engage in a coherent treatment of the literature they reviewed, to engage in higher level discourse, and to ultimately advance a thesis in relation to the assignment topic. As such, we weighed convergent ideas more as these play a role that is commensurate.
To appraise the ideation quality of an essay, we subsequently added the weights ascribed to all word pairs.
Table 4 below illustrates how an essay with three different word pairs would be computationally appraised for ideation quality.
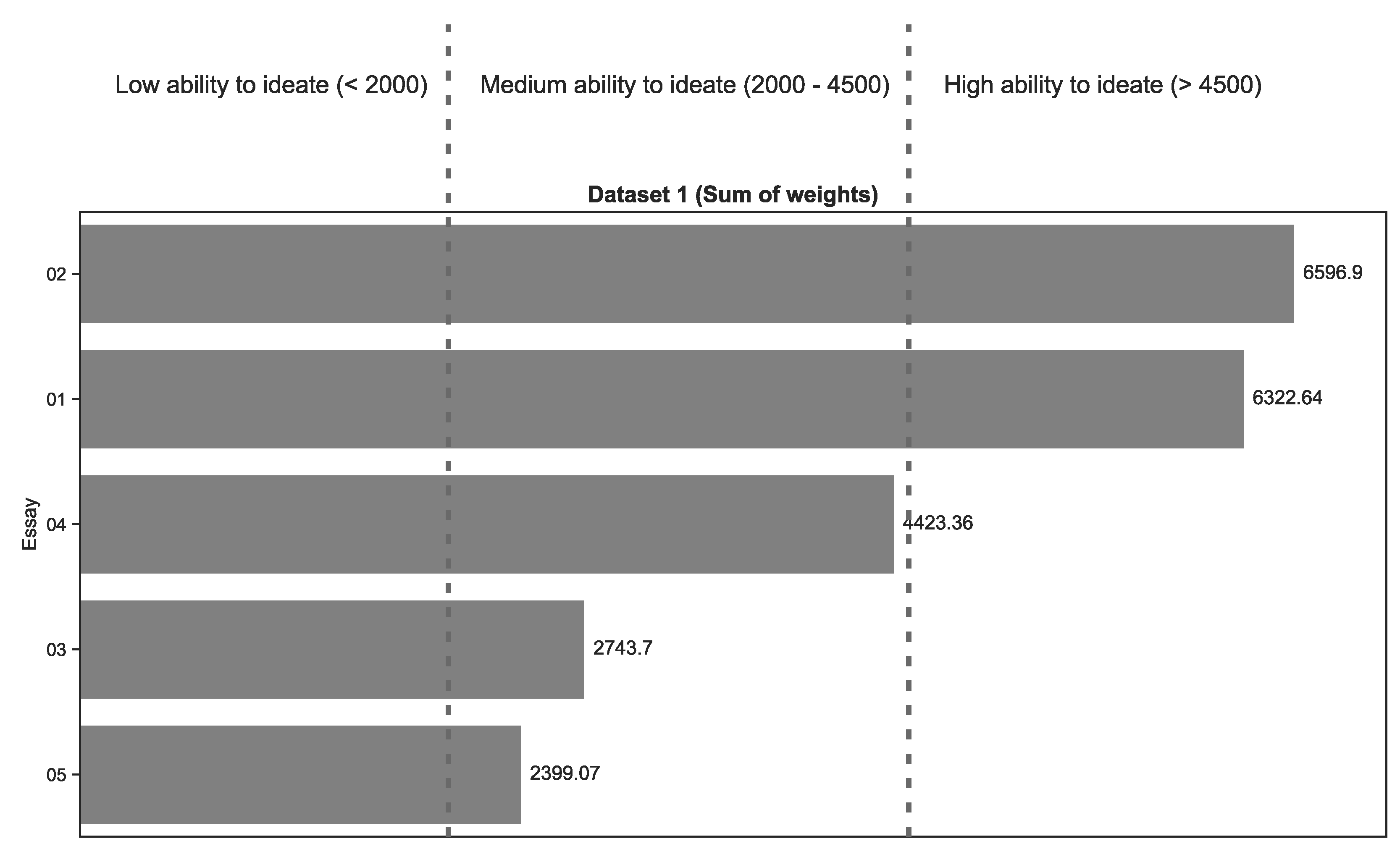
Since it can be difficult to gauge the distance in ideation quality between essays, we additionally normalised the sum of weights within a dataset so as to scale the values between 0 and 1. We refer to this final outcome as the ideation score.
Table 5 below illustrates how the sum of weights for a sample dataset with only three essays would be normalised.
As highlighted earlier, personalities were not directly involved in the appraisal process, only algorithms. In addition, we cannot independently observe creativity. There are no objective benchmarks, or upper and lower bounds in which we can take reference. However, we do know that the essays within a dataset share the exact same task parameters and context. This effectively means that the students in a course were engaged in the same innovative process and dealing with very similar constraints. This can be exploited to indirectly observe variances in the path treaded as there will be inherent differences in the students’ ideation ability. So, instead of arbitrarily establishing upper and lower bounds, we let them emerge organically. A numerical score can be too granular, so it may be more meaningful to represent this categorically. For example, 0.00 to 0.33 as “Low”, 0.34 to 0.66 as “Medium”, and 0.67 to 1.0 as “High”.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}