

Evaluating AI Courses: A Valid and Reliable Instrument for Assessing Artificial-Intelligence Learning through Comparative Self-Assessment

Abstract
:1. Introduction
1.1. AI Literacy
1.2. Assessing AI Literacy
1.3. Using an AI-Literacy-Assessment Instrument to Evaluate Learning Gains
1.4. Research Questions
- RQ1: Can the adapted “scale for the assessment of non-experts’ AI literacy” be used to reliably and validly assess the learning gains of AI courses?
- RQ2: Are AI course participants’ self-assessed AI literacy and their attitudes toward AI correlated?
- RQ3: Does AI education outside of an evaluated AI course have an impact on learning gains?
2. Materials and Methods
2.1. AI Course
2.2. Translation of the “Scale for the Assessment of Non-Experts’ AI Literacy” (SNAIL)
2.3. Evaluation Procedure
2.4. Data Analysis
3. Results
3.1. Participants
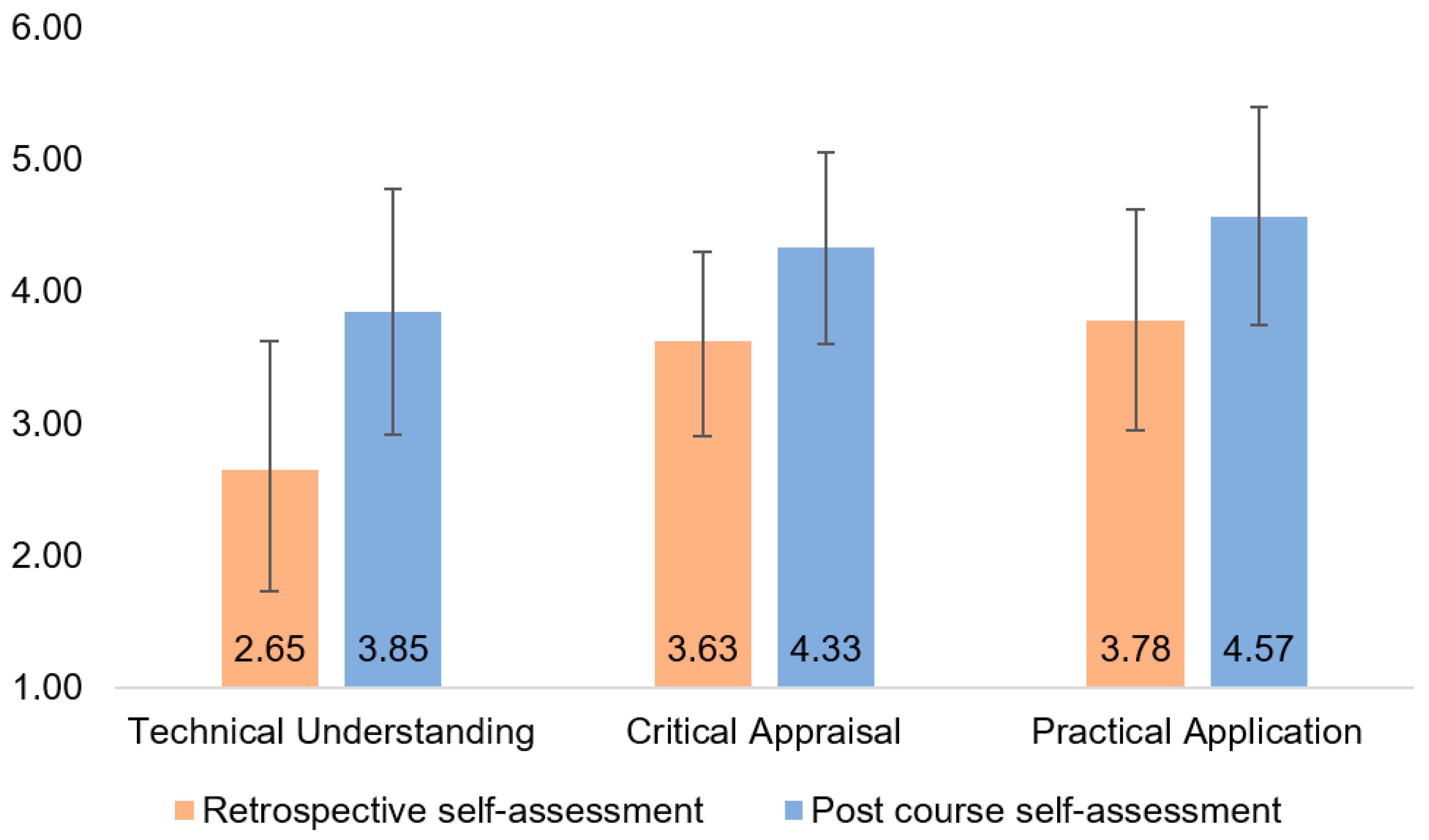
3.2. Learning Gains and Reliability
3.3. Relationship between AI Literacy and Attitudes toward AI
3.4. Relationship between AI Education Prior to the Course and Learning Gains
4. Discussion
4.1. Contextualizing of Results
4.2. Limitations
4.3. Future Research Directions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Merriam-Webster. Artificial Intelligence. Merriam-Webster: Springfield, MA, USA, 2023. Available online: https://www.merriam-webster.com/dictionary/artificial%20intelligence (accessed on 14 September 2023).
- Cambridge Dictionary. Artificial Intelligence. Cambridge University Press: Cambridge, UK, 2023. Available online: https://dictionary.cambridge.org/dictionary/english/artificial-intelligence (accessed on 14 September 2023).
- Bennett, J.; Lanning, S. The Netflix Prize. In Proceedings of the KDD Cup and Workshop, San Jose, CA, USA, 12 August 2007; Volume 2007, p. 35. [Google Scholar]
- Skinner, G.; Walmsley, T. Artificial intelligence and deep learning in video games—A brief review. In Proceedings of the 2019 IEEE 4th International Conference on Computer and Communication Systems (ICCCS), Singapore, 23–25 February 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 404–408. [Google Scholar] [CrossRef]
- Yu, K.H.; Beam, A.L.; Kohane, I.S. Artificial intelligence in healthcare. Nat. Biomed. Eng. 2018, 2, 719–731. [Google Scholar] [CrossRef]
- Li, B.H.; Hou, B.C.; Yu, W.T.; Lu, X.B.; Yang, C.W. Applications of artificial intelligence in intelligent manufacturing: A review. Front. Inf. Technol. Electron. Eng. 2017, 18, 86–96. [Google Scholar] [CrossRef]
- Schleiss, J.; Bieber, M.; Manukjan, A.; Kellner, L.; Stober, S. An interdisciplinary competence profile for AI in engineering. In Towards a New Future in Engineering Education, New Scenarios That European Alliances of Tech Universities Open Up; Universitat Politècnica de Catalunya: Barcelona, Spain, 2022; pp. 1601–1609. [Google Scholar] [CrossRef]
- Long, D.; Magerko, B. What is AI literacy? Competencies and design considerations. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–16. [Google Scholar] [CrossRef]
- Kandlhofer, M.; Steinbauer, G.; Hirschmugl-Gaisch, S.; Huber, P. Artificial intelligence and computer science in education: From kindergarten to university. In Proceedings of the 2016 IEEE Frontiers in Education Conference (FIE), Erie, PA, USA, 12–15 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Su, J.; Yang, W. Artificial intelligence in early childhood education: A scoping review. Comput. Educ. Artif. Intell. 2022, 3, 100049. [Google Scholar] [CrossRef]
- Eguchi, A.; Okada, H.; Muto, Y. Contextualizing AI education for K-12 students to enhance their learning of AI literacy through culturally responsive approaches. KI Künstl. Intell. 2021, 35, 153–161. [Google Scholar] [CrossRef] [PubMed]
- Casal-Otero, L.; Catala, A.; Fernández-Morante, C.; Taboada, M.; Cebreiro, B.; Barro, S. AI literacy in K-12: A systematic literature review. Int. J. STEM Educ. 2023, 10, 29. [Google Scholar] [CrossRef]
- Ng, D.T.K.; Leung, J.K.L.; Su, M.J.; Yim, I.H.Y.; Qiao, M.S.; Chu, S.K.W. AI Literacy in K-16 Classrooms; Springer International Publishing: Berlin/Heidelberg, Germany, 2023. [Google Scholar] [CrossRef]
- Southworth, J.; Migliaccio, K.; Glover, J.; Reed, D.; McCarty, C.; Brendemuhl, J.; Thomas, A. Developing a model for AI Across the curriculum: Transforming the higher education landscape via innovation in AI literacy. Comput. Educ. Artif. Intell. 2023, 4, 100127. [Google Scholar] [CrossRef]
- Laupichler, M.C.; Aster, A.; Schirch, J.; Raupach, T. Artificial intelligence literacy in higher and adult education: A scoping literature review. Comput. Educ. Artif. Intell. 2022, 3, 100101. [Google Scholar] [CrossRef]
- Kirkpatrick, D.; Kirkpatrick, J. Evaluating Training Programs: The Four Levels; Berrett-Koehler Publishers: Oakland, CA, USA, 2006. [Google Scholar]
- Ng, D.T.K.; Leung, J.K.L.; Chu, K.W.S.; Qiao, M.S. AI literacy: Definition, teaching, evaluation and ethical issues. Proc. Assoc. Inf. Sci. Technol. 2021, 58, 504–509. [Google Scholar] [CrossRef]
- Weber, P. Unrealistic Optimism Regarding Artificial Intelligence Opportunities in Human Resource Management. Int. J. Knowl. Manag. 2023, 19, 1–19. [Google Scholar] [CrossRef]
- Schepman, A.; Rodway, P. Initial validation of the general attitudes towards Artificial Intelligence Scale. Comput. Hum. Behav. Rep. 2020, 1, 100014. [Google Scholar] [CrossRef] [PubMed]
- Schepman, A.; Rodway, P. The General Attitudes towards Artificial Intelligence Scale (GAAIS): Confirmatory validation and associations with personality, corporate distrust, and general trust. Int. J. Hum. Comput. Interact. 2022, 39, 2724–2741. [Google Scholar] [CrossRef]
- Sindermann, C.; Sha, P.; Zhou, M.; Wernicke, J.; Schmitt, H.S.; Li, M.; Sariyska, R.; Stavrou, M.; Becker, B.; Montag, C. Assessing the attitude towards artificial intelligence: Introduction of a short measure in German, Chinese, and English language. KI Künstl. Intell. 2021, 35, 109–118. [Google Scholar] [CrossRef]
- Wang, B.; Rau PL, P.; Yuan, T. Measuring user competence in using artificial intelligence: Validity and reliability of artificial intelligence literacy scale. Behav. Inf. Technol. 2022, 42, 1324–1337. [Google Scholar] [CrossRef]
- Pinski, M.; Benlian, A. AI Literacy-Towards Measuring Human Competency in Artificial Intelligence. In Proceedings of the 56th Hawaii International Conference on System Sciences, Maui, HI, USA, 3–6 January 2023. [Google Scholar]
- Carolus, A.; Koch, M.; Straka, S.; Latoschik, M.E.; Wienrich, C. MAILS—Meta AI Literacy Scale: Development and Testing of an AI Literacy Questionnaire Based on Well-Founded Competency Models and Psychological Change-and Meta-Competencies. arXiv 2023, arXiv:2302.09319. [Google Scholar] [CrossRef]
- Ng, D.T.K.; Leung, J.K.L.; Chu, S.K.W.; Qiao, M.S. Conceptualizing AI literacy: An exploratory review. Comput. Educ. Artif. Intell. 2021, 2, 100041. [Google Scholar] [CrossRef]
- Laupichler, M.C.; Aster, A.; Raupach, T. Delphi study for the development and preliminary validation of an item set for the assessment of non-experts’ AI literacy. Comput. Educ. Artif. Intell. 2023, 4, 100126. [Google Scholar] [CrossRef]
- Laupichler, M.C.; Aster, A.; Raupach, T. Development of the “Scale for the Assessment of Non-Experts’ AI Literacy”—An Exploratory Factor Analysis; Institute of Medical Education, University Hospital Bonn: Bonn, Germany, 2023. [Google Scholar]
- Raupach, T.; Münscher, C.; Beißbarth, T.; Burckhardt, G.; Pukrop, T. Towards outcome-based programme evaluation: Using student comparative self-assessments to determine teaching effectiveness. Med. Teach. 2011, 33, e446–e453. [Google Scholar] [CrossRef]
- Howard, G.S. Response-shift bias: A problem in evaluating interventions with pre/post self-reports. Eval. Rev. 1980, 4, 93–106. [Google Scholar] [CrossRef]
- Sibthorp, J.; Paisley, K.; Gookin, J.; Ward, P. Addressing response-shift bias: Retrospective pretests in recreation research and evaluation. J. Leis. Res. 2007, 39, 295–315. [Google Scholar] [CrossRef]
- Tsang, S.; Royse, C.F.; Terkawi, A.S. Guidelines for developing, translating, and validating a questionnaire in perioperative and pain medicine. Saudi J. Anaesth. 2017, 11, 80–89. [Google Scholar] [CrossRef] [PubMed]
- Harkness, J.; Pennell, B.E.; Schoua-Glusberg, A. Survey questionnaire translation and assessment. In Methods for Testing and Evaluating Survey Questionnaires; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2004; pp. 453–473. [Google Scholar] [CrossRef]
- Chang, A.M.; Chau, J.P.; Holroyd, E. Translation of questionnaires and issues of equivalence. J. Adv. Nurs. 2001, 29, 316–322. [Google Scholar] [CrossRef] [PubMed]
- Schiekirka, S.; Reinhardt, D.; Beibarth, T.; Anders, S.; Pukrop, T.; Raupach, T. Estimating learning outcomes from pre-and posttest student self-assessments: A longitudinal study. Acad. Med. 2013, 88, 369–375. [Google Scholar] [CrossRef] [PubMed]
- Schleiss, J.; Laupichler, M.C.; Raupach, T.; Stober, S. AI Course Design Planning Framework: Developing Domain-Specific AI Education Courses. Educ. Sci. 2023, 13, 954. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Variable | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1. CSA TU | — | ||||||||||
| 2. CSA CA | 0.382 | — | |||||||||
| 0.059 | |||||||||||
| 3. CSA PA | 0.556 ** | 0.573 ** | — | ||||||||
| 0.004 | 0.003 | ||||||||||
| 4. TU—retrospective | −0.106 | 0.004 | −0.107 | — | |||||||
| 0.614 | 0.985 | 0.611 | |||||||||
| 5. TU—post | 0.416 * | 0.385 | 0.321 | 0.678 ** | — | ||||||
| 0.039 | 0.058 | 0.118 | <0.001 | ||||||||
| 6. CA—retrospective | −0.254 | −0.234 | −0.169 | 0.357 | 0.271 | — | |||||
| 0.220 | 0.260 | 0.419 | 0.080 | 0.191 | |||||||
| 7. CA—post | 0.233 | 0.471 * | 0.415 * | 0.146 | 0.505 * | 0.588 ** | — | ||||
| 0.263 | 0.018 | 0.039 | 0.486 | 0.010 | 0.002 | ||||||
| 8. PA—retrospective | −0.347 | −0.023 | −0.096 | 0.239 | 0.159 | 0.523 ** | 0.266 | — | |||
| 0.089 | 0.914 | 0.648 | 0.250 | 0.448 | 0.007 | 0.198 | |||||
| 9. PA—post | 0.206 | 0.519 ** | 0.593 ** | 0.073 | 0.447 * | 0.302 | 0.729 ** | 0.589 ** | — | ||
| 0.323 | 0.008 | 0.002 | 0.730 | 0.025 | 0.142 | <0.001 | 0.002 | ||||
| 10. Other courses | −0.111 | −0.348 | −0.244 | 0.556 ** | 0.402 * | 0.364 | 0.066 | 0.043 | −0.147 | — | |
| 0.597 | 0.088 | 0.239 | 0.004 | 0.046 | 0.074 | 0.755 | 0.838 | 0.482 | |||
| 11. Other AI education | 0.376 | 0.309 | 0.292 | 0.557 ** | 0.684 ** | 0.271 | 0.492 * | 0.332 | 0.524 ** | 0.171 | — |
| 0.064 | 0.133 | 0.157 | 0.004 | <0.001 | 0.190 | 0.013 | 0.105 | 0.007 | 0.413 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Laupichler, M.C.; Aster, A.; Perschewski, J.-O.; Schleiss, J. Evaluating AI Courses: A Valid and Reliable Instrument for Assessing Artificial-Intelligence Learning through Comparative Self-Assessment. Educ. Sci. 2023, 13, 978. https://doi.org/10.3390/educsci13100978
Laupichler MC, Aster A, Perschewski J-O, Schleiss J. Evaluating AI Courses: A Valid and Reliable Instrument for Assessing Artificial-Intelligence Learning through Comparative Self-Assessment. Education Sciences. 2023; 13(10):978. https://doi.org/10.3390/educsci13100978
Chicago/Turabian StyleLaupichler, Matthias Carl, Alexandra Aster, Jan-Ole Perschewski, and Johannes Schleiss. 2023. "Evaluating AI Courses: A Valid and Reliable Instrument for Assessing Artificial-Intelligence Learning through Comparative Self-Assessment" Education Sciences 13, no. 10: 978. https://doi.org/10.3390/educsci13100978