
Predicting Student Performance Using Clickstream Data and Machine Learning


Abstract
:1. Introduction
2. Literature Review
2.1. Learning Analytics and Educational Data Mining
2.2. Student Performance Prediction
2.3. Clickstream Data
3. Methods
3.1. Research Aim and Objectives
- RO1: Feature extraction: to extract feature sets from the original datasets, that can be effectively used for student performance prediction
- RO2: Feature selection: to investigate the impact of different features on prediction outcomes with the aim to identify the important features
- RO3: Model evaluation: to compare the performance of different models when using different feature sets, with and without a feature selection method, as well as multiple machine learning (including deep learning) algorithms, to find the most optimal model for predicting student performance.
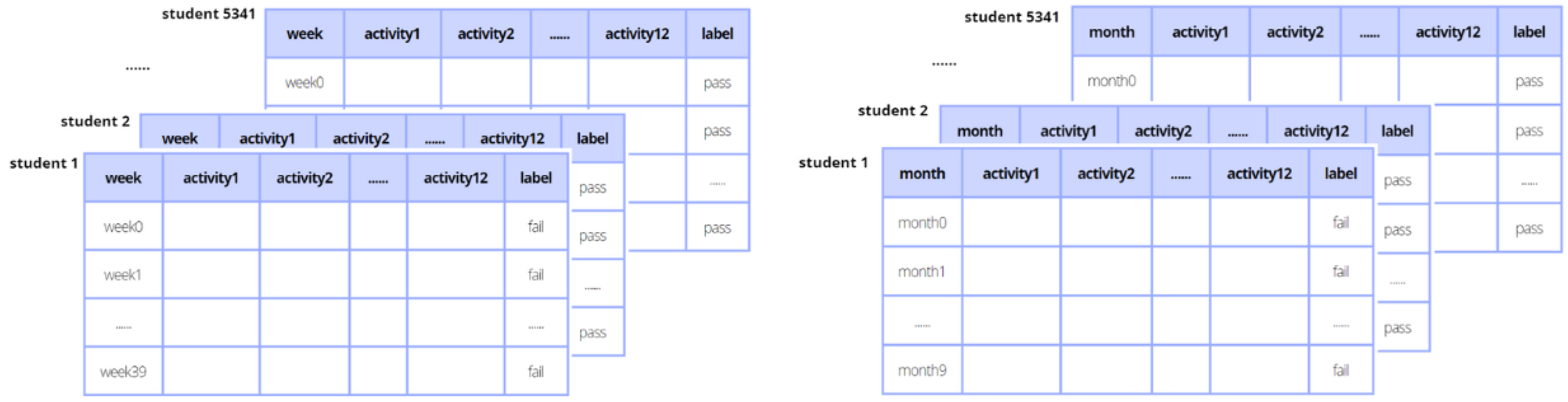
3.2. Data Sets
3.3. Experiments
4. Results
4.1. Model Training Implementation
4.2. Model Performance
4.3. Feature Importance
5. Discussion
5.1. Research Objective 1: Feature Extraction
5.2. Research Objective 2: Feature Selection
5.3. Research Objective 3: Model Evaluation
5.4. Implications for Learning and Teaching
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LA | Learning Analytics |
| EDM | Educational Data Mining |
| LMS | Learning Management System |
| OULAD | Open University Learning Analytics Dataset |
| VLEs | Virtual Learning Environments |
| LR | Logistic Regression |
| k-NN | k-Nearest Neighbors |
| RF | Random Forest |
| GBT | Gradient Boosting Trees |
| CNN | Convolutional Neural Network |
| 1D-CNN | One-dimensional Convolutional Neural Network |
| 2D-CNN | Two-dimensional Convolutional Neural Network |
| LSTM | Long Short-Term Memory |
References
- Siemens, G. Message from the LAK 2011 General &Program Chairs. In Proceedings of the LAK11: 1st International Conference on Learning Analytics and Knowledge, Banff, AB, Canada, 27 February–1 March 2011. [Google Scholar]
- Nistor, N.; Hernández-Garcíac, Á. What types of data are used in learning analytics? An overview of six cases. Comput. Hum. Behav. 2018, 89, 335–338. [Google Scholar] [CrossRef]
- Society for Learning Analytics Research (SoLAR). Available online: https://www.solaresearch.org/about/what-is-learning-analytics (accessed on 30 August 2022).
- Akçapınar, G.; Altun, A.; Aşkar, P. Using learning analytics to develop early-warning system for at-risk students. Int. J. Educ. Technol. High. Educ. 2019, 16, 40. [Google Scholar] [CrossRef]
- Chen, F.; Cui, Y. Utilizing Student Time Series Behaviour in Learning Management Systems for Early Prediction of Course Performance. J. Learn. Anal. 2020, 7, 1–17. [Google Scholar] [CrossRef]
- Imran, M.; Latif, S.; Mehmood, D.; Shah, M.S. Student Academic Performance Prediction using Supervised Learning Techniques. Int. J. Emerg. Technol. Learn. 2019, 14, 92–104. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Hooshyar, D.; Pedaste, M.; Wang, M.; Huang, Y.M.; Lim, H. Prediction of students’ procrastination behaviour through their submission behavioural pattern in online learning. J. Ambient. Intell. Humaniz. Comput. 2020, 1–18. [Google Scholar] [CrossRef]
- Brinton, C.G.; Chiang, M. MOOC performance prediction via clickstream data and social learning networks. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015; pp. 2299–2307. [Google Scholar]
- Marbouti, F.; Diefes-Dux, H.A.; Madhavan, K. Models for early prediction of at-risk students in a course using standards-based grading. Comput. Educ. 2016, 103, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez, F.; Lee, H.R.; Rutherford, T.; Fischer, C.; Potma, E.; Warschauer, M. Using clickstream data mining techniques to understand and support first-generation college students in an online chemistry course. In Proceedings of the LAK21: 11th International Conference on Learning Analytics and Knowledge, Irvine, CA, USA, 12–16 April 2021; pp. 313–322. [Google Scholar]
- Romero, C.; Ventura, S. Educational data mining and learning analytics: An updated survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1355. [Google Scholar] [CrossRef]
- Oliva-Cordova, L.M.; Garcia-Cabot, A.; Amado-Salvatierra, H.R. Learning analytics to support teaching skills: A systematic literature review. IEEE Access 2021, 9, 58351–58363. [Google Scholar] [CrossRef]
- Viberg, O.; Hatakka, M.; Bälter, O.; Mavroudi, A. The current landscape of learning analytics in higher education. Comput. Hum. Behav. 2018, 89, 98–110. [Google Scholar] [CrossRef]
- Aljohani, N.R.; Fayoumi, A.; Hassan, S.U. Predicting at-risk students using clickstream data in the virtual learning environment. Sustainability 2019, 11, 7238. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Data mining in education. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2013, 3, 12–27. [Google Scholar] [CrossRef]
- Calders, T.; Pechenizkiy, M. Introduction to the special section on educational data mining. ACM Sigkdd Explor. Newsl. 2012, 13, 3–6. [Google Scholar] [CrossRef]
- Akram, A.; Fu, C.; Li, Y.; Javed, M.Y.; Lin, R.; Jiang, Y.; Tang, Y. Predicting students’ academic procrastination in blended learning course using homework submission data. IEEE Access 2019, 7, 102487–102498. [Google Scholar] [CrossRef]
- Tomasevic, N.; Gvozdenovic, N.; Vranes, S. An overview and comparison of supervised data mining techniques for student exam performance prediction. Comput. Educ. 2020, 143, 103676. [Google Scholar] [CrossRef]
- Mangaroska, K.; Giannakos, M. Learning analytics for learning design: A systematic literature review of analytics-driven design to enhance learning. IEEE Trans. Learn. Technol. 2018, 12, 516–534. [Google Scholar] [CrossRef] [Green Version]
- Aldowah, H.; Al-Samarraie, H.; Fauzy, W.M. Educational data mining and learning analytics for 21st century higher education: A review and synthesis. Telemat. Inform. 2019, 37, 13–49. [Google Scholar] [CrossRef]
- Aleem, A.; Gore, M.M. Educational data mining methods: A survey. In Proceedings of the 2020 IEEE 9th International Conference on Communication Systems and Network Technologies (CSNT), Gwalior, India, 10–12 April 2020; pp. 182–188. [Google Scholar]
- Cano, A.; Leonard, J.D. Interpretable multiview early warning system adapted to underrepresented student populations. IEEE Trans. Learn. Technol. 2019, 12, 198–211. [Google Scholar] [CrossRef]
- Ranaldi, L.; Fallucchi, F.; Zanzotto, F.M. Dis-Cover AI Minds to Preserve Human Knowledge. Future Internet 2021, 14, 10. [Google Scholar] [CrossRef]
- Dutt, A.; Ismail, M.A.; Herawan, T. A systematic review on educational data mining. IEEE Access 2017, 5, 15991–16005. [Google Scholar] [CrossRef]
- Burgos, C.; Campanario, M.L.; de la Peña, D.; Lara, J.A.; Lizcano, D.; Martínez, M.A. Data mining for modeling students’ performance: A tutoring action plan to prevent academic dropout. Comput. Electr. Eng. 2018, 66, 541–556. [Google Scholar] [CrossRef]
- Kemper, L.; Vorhoff, G.; Wigger, B.U. Predicting student dropout: A machine learning approach. Eur. J. High. Educ. 2020, 10, 28–47. [Google Scholar] [CrossRef]
- Xu, J.; Moon, K.H.; Van Der Schaar, M. A machine learning approach for tracking and predicting student performance in degree programs. IEEE J. Sel. Top. Signal Process. 2017, 11, 742–753. [Google Scholar] [CrossRef]
- Marbouti, F.; Diefes-Dux, H.A.; Strobel, J. Building course-specific regression-based models to identify at-risk students. In Proceedings of the 2015 ASEE Annual Conference & Exposition, Seattle, WA, USA, 14–17 June 2015; pp. 26–304. [Google Scholar]
- Lemay, D.J.; Doleck, T. Predicting completion of massive open online course (MOOC) assignments from video viewing behavior. Interact. Learn. Environ. 2020, 1782–1793. [Google Scholar] [CrossRef]
- Park, Y.; Yu, J.H.; Jo, I.H. Clustering blended learning courses by online behavior data: A case study in a Korean higher education institute. Internet High. Educ. 2016, 29, 1–11. [Google Scholar] [CrossRef]
- Waheed, H.; Hassan, S.U.; Aljohani, N.R.; Hardman, J.; Alelyani, S.; Nawaz, R. Predicting academic performance of students from VLE big data using deep learning models. Comput. Hum. Behav. 2020, 104, 106189. [Google Scholar] [CrossRef] [Green Version]
- Behr, A.; Giese, M.; Theune, K. Early prediction of university dropouts—A random forest approach. Jahrbücher Für Natl. Und Stat. 2020, 240, 743–789. [Google Scholar] [CrossRef]
- Helal, S.; Li, J.; Liu, L.; Ebrahimie, E.; Dawson, S.; Murray, D.J. Identifying key factors of student academic performance by subgroup discovery. Int. J. Data Sci. Anal. 2019, 7, 227–245. [Google Scholar] [CrossRef]
- Namoun, A.; Alshanqiti, A. Predicting student performance using data mining and learning analytics techniques: A systematic literature review. Appl. Sci. 2020, 11, 237. [Google Scholar] [CrossRef]
- López Zambrano, J.; Lara Torralbo, J.A.; Romero Morales, C. Early prediction of student learning performance through data mining: A systematic review. Psicothema 2021, 33, 456–465. [Google Scholar]
- Alamri, R.; Alharbi, B. Explainable student performance prediction models: A systematic review. IEEE Access 2021, 9, 33132–33143. [Google Scholar] [CrossRef]
- Minar, M.R.; Naher, J. Recent advances in deep learning: An overview. arXiv 2018, arXiv:1807.08169. [Google Scholar]
- Mengash, H.A. Using data mining techniques to predict student performance to support decision making in university admission systems. IEEE Access 2020, 8, 55462–55470. [Google Scholar] [CrossRef]
- Nahar, K.; Shova, B.I.; Ria, T.; Rashid, H.B.; Islam, A. Mining educational data to predict students performance. Educ. Inf. Technol. 2021, 26, 6051–6067. [Google Scholar] [CrossRef]
- Zollanvari, A.; Kizilirmak, R.C.; Kho, Y.H.; Hernández-Torrano, D. Predicting students’ GPA and developing intervention strategies based on self-regulatory learning behaviors. IEEE Access 2017, 5, 23792–23802. [Google Scholar] [CrossRef]
- Filvà, D.A.; Forment, M.A.; García-Peñalvo, F.J.; Escudero, D.F.; Casañ, M.J. Clickstream for learning analytics to assess students’ behavior with Scratch. Future Gener. Comput. Syst. 2019, 93, 673–686. [Google Scholar] [CrossRef]
- Li, Q.; Baker, R.; Warschauer, M. Using clickstream data to measure, understand, and support self-regulated learning in online courses. Internet High. Educ. 2020, 45, 100727. [Google Scholar] [CrossRef]
- Broadbent, J.; Poon, W.L. Self-regulated learning strategies & academic achievement in online higher education learning environments: A systematic review. Internet High. Educ. 2015, 27, 1–13. [Google Scholar]
- Jiang, T.; Chi, Y.; Gao, H. A clickstream data analysis of Chinese academic library OPAC users’ information behavior. Libr. Inf. Sci. Res. 2017, 39, 213–223. [Google Scholar] [CrossRef]
- Gasevic, D.; Jovanovic, J.; Pardo, A.; Dawson, S. Detecting learning strategies with analytics: Links with self-reported measures and academic performance. J. Learn. Anal. 2017, 4, 113–128. [Google Scholar] [CrossRef] [Green Version]
- Seo, K.; Dodson, S.; Harandi, N.M.; Roberson, N.; Fels, S.; Roll, I. Active learning with online video: The impact of learning context on engagement. Comput. Educ. 2021, 165, 104132. [Google Scholar] [CrossRef]
- Kuzilek, J.; Hlosta, M.; Zdrahal, Z. Open university learning analytics dataset. Sci. Data 2017, 4, 170171. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zou, X.; Hu, Y.; Tian, Z.; Shen, K. Logistic regression model optimization and case analysis. In Proceedings of the 2019 IEEE 7th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 19–20 October 2019; pp. 135–139. [Google Scholar]
- Zhou, Q.; Quan, W.; Zhong, Y.; Xiao, W.; Mou, C.; Wang, Y. Predicting high-risk students using Internet access logs. Knowl. Inf. Syst. 2018, 55, 393–413. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Bader-El-Den, M.; Teitei, E.; Perry, T. Biased Random Forest For Dealing With the Class Imbalance Problem. IEEE Trans. Neural Networks Learn. Syst. 2019, 30, 2163–2172. [Google Scholar] [CrossRef] [Green Version]
- Gupta, A.; Gusain, K.; Popli, B. Verifying the value and veracity of extreme gradient boosted decision trees on a variety of datasets. In Proceedings of the 2016 11th International Conference on Industrial and Information Systems (ICIIS), Roorkee, India, 3–4 December 2016; pp. 457–462. [Google Scholar]
- Zhu, G.; Wu, Z.; Wang, Y.; Cao, S.; Cao, J. Online purchase decisions for tourism e-commerce. Electron. Commer. Res. Appl. 2019, 38, 100887. [Google Scholar] [CrossRef]
- Vo, C.; Nguyen, H.P. An enhanced CNN model on temporal educational data for program-level student classification. In Asian Conference on Intelligent Information and Database Systems; Springer: Cham, Switzerland, 2020; pp. 442–454. [Google Scholar]
- Sarkar, M.; De Bruyn, A. LSTM response models for direct marketing analytics: Replacing feature engineering with deep learning. J. Interact. Mark. 2021, 53, 80–95. [Google Scholar] [CrossRef]
- Hung, J.L.; Rice, K.; Kepka, J.; Yang, J. Improving predictive power through deep learning analysis of K-12 online student behaviors and discussion board content. Inf. Discov. Deliv. 2020, 48, 199–212. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]


{kind=link}
| # | Columns | Description | Data Type |
|---|---|---|---|
| 1 | code_module | the module identification code | nominal |
| 2 | code_presentation | the presentation identification code | nominal |
| 3 | id_site | the VLE material identification number | numerical |
| 4 | id_student | the unique student identification number | numerical |
| 5 | date | the day of student’s interaction with the material | numerical |
| 6 | sum_click | the number of times the student interacted with the material | numerical |
| Feature Name | Activity Category | Weight Scores in WEEK | Weight Scores in MONTH |
|---|---|---|---|
| Act1 | forum | 0.60 | 0.63 |
| Act2 | content | 0.28 | 0.34 |
| Act3 | subpage | 0.28 | 0.54 |
| Act4 | homepage | 1.00 | 1.00 |
| Act5 | quiz | 0.12 | 0.32 |
| Act6 | resource | 0.22 | 0.43 |
| Act7 | url | 0.13 | 0.19 |
| Act8 | collaborate | 0.04 | 0.09 |
| Act9 | questionnaire | 0.03 | 0.06 |
| Act10 | onlineclass | 0.00 | 0.01 |
| Act11 | glossary | 0.03 | 0.06 |
| Act12 | sharedsubpage | 0.00 | 0.00 |
| Algorithms | M1 Using Feature Set WEEK | M2 Using Feature Set WEEK | M1 Using Feature Set MONTH | M2 Using Feature Set MONTH |
|---|---|---|---|---|
| LR | 70.24% (±0.02%) | 70.25% (±0.00%) 1 | 70.24% (±0.03%) | 70.25% (±0.00%) 2 |
| k-NN | 66.29% (±0.30%) | 66.10% (±0.32%) 3 | 76.46% (±0.48%) | 76.46% (±0.49%) 4 |
| RF | 70.25% (±0.00%) | 70.25% (±0.00%) 5 | 73.82% (±3.83%) | 76.39% (±0.47%) 6 |
| GBT | 70.25% (±0.00%) | 69.02% (±1.99%) 7 | 76.47% (±0.49%) | 76.47% (±0.49%) 8 |
| 1D-CNN | 70.25% (±0.27%) | n/a | 77.55% (±0.88%) | n/a |
| LSTM | 89.25% (±0.97%) * | n/a | 88.67% (±1.27%) ** | n/a |
| Algorithms | M1 Using Feature Set WEEK | M2 Using Feature Set WEEK | M1 Using Feature Set MONTH | M2 Using Feature Set MONTH |
|---|---|---|---|---|
| LR | 82.51% (±0.01%) | 82.53% (±0.00%) 1 | 82.51% (±0.02%) | 82.53% (±0.00%) 2 |
| k-NN | 72.94% (±0.25%) | 72.67% (±0.27%) 3 | 84.06% (±0.37%) | 84.06% (±0.38%) 4 |
| RF | 82.52% (±0.00%) | 82.52% (±0.00%) 5 | 83.88% (±1.65%) | 83.96% (±0.37%) 6 |
| GBT | 82.52% (±0.00%) | 79.58% (±4.75%) 7 | 84.04% (±0.38%) | 84.04% (±0.38%) 8 |
| 1D-CNN | 82.52% (±0.18%) | n/a | 85.24% (±0.82%) | n/a |
| LSTM | 92.71% (±0.62%) * | n/a | 92.37% (±0.81%) ** | n/a |
| Algorithms | M1 Using Feature Set WEEK | M2 Using Feature Set WEEK | M1 Using Feature Set MONTH | M2 Using Feature Set MONTH |
|---|---|---|---|---|
| LR | 0.597 (±0.007) | 0.607 (±0.006) 1 | 0.482 (±0.008) | 0.500 (±0.000) 2 |
| k-NN | 0.670 (±0.006) | 0.666 (±0.007) 3 | 0.671 (±0.008) | 0.670 (±0.010) 4 |
| RF | 0.690 (±0.004) | 0.674 (±0.004) 5 | 0.751 (±0.008) | 0.734 (±0.009) 6 |
| GBT | 0.698 (±0.004) | 0.690 (±0.004) 7 | 0.763 (±0.007) | 0.763 (±0.007) 8 |
| 1D-CNN | 0.720 (±0.005) | n/a | 0.786 (±0.006) | n/a |
| LSTM | 0.913 (±0.014) * | n/a | 0.906 (±0.013) ** | n/a |
| Removed Feature | Activity Category | Model’s Accuracy | Dropped Accuracy |
|---|---|---|---|
| Act1 | forum | 89.22% (±0.79%) | 0.03% |
| Act2 * | content | 89.03% (±0.68%) | 0.22% |
| Act3 * | subpage | 88.90% (±0.78%) | 0.35% |
| Act4 * | homepage | 88.90% (±1.27%) | 0.35% |
| Act5 * | quiz | 89.07% (±0.93%) | 0.18% |
| Act6 | resource | 89.18% (±0.87%) | 0.07% |
| Act7 | url | 89.12% (±0.89%) | 0.13% |
| Act8 | collaborate | 89.16% (±0.97%) | 0.09% |
| Act9 | questionnaire | 89.23% (±0.89%) | 0.02% |
| Act10 | onlineclass | 89.16% (±0.83%) | 0.09% |
| Act11 | glossary | 89.22% (±0.77%) | 0.03% |
| Act12 | sharedsubpage | 89.22% (±0.69%) | 0.03% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Fan, S.; Xu, S.; Sajjanhar, A.; Yeom, S.; Wei, Y. Predicting Student Performance Using Clickstream Data and Machine Learning. Educ. Sci. 2023, 13, 17. https://doi.org/10.3390/educsci13010017
Liu Y, Fan S, Xu S, Sajjanhar A, Yeom S, Wei Y. Predicting Student Performance Using Clickstream Data and Machine Learning. Education Sciences. 2023; 13(1):17. https://doi.org/10.3390/educsci13010017
Chicago/Turabian StyleLiu, Yutong, Si Fan, Shuxiang Xu, Atul Sajjanhar, Soonja Yeom, and Yuchen Wei. 2023. "Predicting Student Performance Using Clickstream Data and Machine Learning" Education Sciences 13, no. 1: 17. https://doi.org/10.3390/educsci13010017