
Assessing Intervention Effects in the Presence of Missing Scores



Abstract
:1. Introduction
2. Prevalence of Missing Data in Published SCD Studies
2.1. Methodology for Investigating the Prevalence of Missing Data
2.2. Findings on the Prevalence of Missing Data
3. Problems Caused by Missing Data
3.1. Reasons for Missing Data
3.2. Problems Caused by Inappropriate Treatments of Missing Data
4. Review of Nine Methods for Treating Missing Data in Intervention Studies
4.1. Identification and Overview of the Nine Methods
4.2. Missing Data Mechanisms
4.3. The Lambert Data
4.4. The Available Data (AD) Method
4.5. The Mean Substitution (MS) Method
4.6. The Minimum-Maximum (MM) Method
4.7. The Theoretical Minimum-Maximum (TMM) Method
4.8. The LOCF (Last Observation Carried Forward) Method
4.9. The LIN (Linear Interpolation With a Noise) Method
4.10. The AMS (Adjacent Mean Substitution) Method
4.11. The Multiple Imputation (MI) Method
4.12. The Expectation-Maximization (EM) Method
5. Demonstration of AD, MS, MM, and TMM Methods and Results
5.1. Class-Level Assessment Based on g
5.2. Student-Level Assessment Based on Level Change
5.3. Student-Level Assessment Based on Immediacy of the Effect
5.4. Student-Level Assessment Based on Nonoverlap
5.5. Conclusions Based on Four Assessments
6. Discussion and Conclusions
6.1. Contingencies for Implementing Missing Data Methods
6.2. Strategies for Managing Missing Data
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A
References
- Harrison, J.R.; Soares, D.A.; Rudzinski, S.; Johnson, R. Attention Deficit Hyperactivity Disorders and Classroom-Based Interventions: Evidence-Based Status, Effectiveness, and Moderators of Effects in Single-Case Design Research. Rev. Educ. Res. 2019, 89, 569–611. [Google Scholar] [CrossRef]
- Long, A.C.J.; Miller, F.G.; Upright, J.J. Classroom management for ethnic–racial minority students: A meta-analysis of single-case design studies. Sch. Psychol. 2019, 34, 1–13. [Google Scholar] [CrossRef]
- Martinez, J.R.; Waters, C.L.; Conroy, M.A.; Reichow, B. Peer-Mediated Interventions to Address Social Competence Needs of Young Children With ASD: Systematic Review of Single-Case Research Design Studies. Top. Early Child. Spéc. Educ. 2021, 40, 217–228. [Google Scholar] [CrossRef]
- Ratanavivan, W.; Ricard, R.J. Effects of a Motivational Interviewing-Based Counseling Program on Classroom Behavior of Children in a Disciplinary Alternative Education Program. J. Couns. Dev. 2018, 96, 410–423. [Google Scholar] [CrossRef]
- Perrin, C.J.; Miller, N.; Haberlin, A.T.; Ivy, J.W.; Meindl, J.N.; Neef, N.A. MEASURING AND REDUCING COLLEGE STUDENTS’ PROCRASTINATION. J. Appl. Behav. Anal. 2011, 44, 463–474. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McDonald, S.; Quinn, F.; Vieira, R.; O’Brien, N.; White, M.; Johnston, D.W.; Sniehotta, F.F. The state of the art and future opportunities for using longitudinal n-of-1 methods in health behaviour research: A systematic literature overview. Health Psychol. Rev. 2017, 11, 307–323. [Google Scholar] [CrossRef]
- Horner, R.H.; Carr, E.G.; Halle, J.W.; McGee, G.G.; Odom, S.L.; Wolery, M. The Use of Single-Subject Research to Identify Evidence-Based Practice in Special Education. Except. Child. 2005, 71, 165–179. [Google Scholar] [CrossRef]
- Kazdin, A.E. Single-case experimental designs. Evaluating interventions in research and clinical practice. Behav. Res. Ther. 2019, 117, 3–17. [Google Scholar] [CrossRef]
- Radley, K.C.; Dart, E.H.; Fischer, A.J.; Collins, T.A. Publication trends for single-case methodology in school psychology: A systematic review. Psychol. Sch. 2020, 57, 683–698. [Google Scholar] [CrossRef]
- Shadish, W.R.; Sullivan, K.J. Characteristics of single-case designs used to assess intervention effects in 2008. Behav. Res. Methods 2011, 43, 971–980. [Google Scholar] [CrossRef] [Green Version]
- Smith, J.D. Single-case experimental designs: A systematic review of published research and current standards. Psychol. Methods 2012, 17, 510–550. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Allison, D.B.; Silverstein, J.M.; Gorman, B.S. Power, sample size estimation, and early stopping rules. In Design and Analysis of Single-Case Research; Franklin, R.D., Allison, D.B., Gorman, B.S., Eds.; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 1996; pp. 335–371. [Google Scholar]
- Hall, J.A.; US Department of Health and Human Services; National Institute on Drug Abuse Skills Training for Pregnant and Parenting Adolescents. PsycEXTRA Dataset 1995, 156, 255–290. [CrossRef]
- Kellam, S.G.; Rebok, G.W.; Ialongo, N.; Mayer, L.S. The Course and Malleability of Aggressive Behavior from Early First Grade into Middle School: Results of a Developmental Epidemiologically-based Preventive Trial. J. Child Psychol. Psychiatry 1994, 35, 259–281. [Google Scholar] [CrossRef] [PubMed]
- Mason, M.J. A Review of Procedural and Statistical Methods for Handling Attrition and Missing Data in Clinical Research. Meas. Evaluation Couns. Dev. 1999, 32, 111–118. [Google Scholar] [CrossRef]
- Chen, L.-T.; Peng, C.-Y.J.; Chen, M.-E. Computing Tools for Implementing Standards for Single-Case Designs. Behav. Modif. 2015, 39, 835–869. [Google Scholar] [CrossRef]
- Chiu, M.M.; Roberts, C.A. Improved analyses of single cases: Dynamic multilevel analysis. Dev. Neurorehabilit. 2016, 21, 253–265. [Google Scholar] [CrossRef]
- Peng, C.-Y.J.; Chen, L.-T. Handling missing data in single-case studies. J. Mod. Appl. Stat. Methods 2018, 17, 5. [Google Scholar] [CrossRef] [Green Version]
- Tate, R.L.; Perdices, M.; Rosenkoetter, U.; McDonald, S.; Togher, L.; Shadish, W.; Horner, R.; Kratochwill, T.; Barlow, D.H.; Kazdin, A.; et al. The Single-Case Reporting Guideline In BEhavioural Interventions (SCRIBE) 2016: Explanation and Elaboration. Arch. Sci. Psychol. 2016, 4, 10–31. [Google Scholar] [CrossRef] [Green Version]
- Rubin, D.B. Multiple Imputation for Nonresponse in Surveys; Wiley & Sons: New York, NY, USA, 1987. [Google Scholar]
- Gadbury, G.; Schafer, J.L. Analysis of Incomplete Multivariate Data (Monographs on Statistics and Applied Probability, No. 72). J. Am. Stat. Assoc. 2000, 95, 1013. [Google Scholar] [CrossRef]
- Shadish, W.R.; Cook, T.D.; Campbell, D.T. Experimental and Quasi-Experimental Designs for Generalized Causal Inference, 2nd ed.; Houghton Mifflin: Boston, MS, USA, 2002. [Google Scholar]
- Dong, Y.; Peng, C.-Y.J. Principled missing data methods for researchers. SpringerPlus 2013, 2, 1–17. [Google Scholar] [CrossRef] [Green Version]
- What Works Clearinghouse. WWC Procedures Handbook; Version 4.0; 2017. Available online: https://ies.ed.gov/ncee/wwc/Docs/referenceresources/wwc_procedures_handbook_v4.pdf (accessed on 1 October 2020).
- What Works Clearinghouse. WWC Standards Handbook; Version 4.0; 2017. Available online: https://ies.ed.gov/ncee/wwc/Docs/referenceresources/wwc_standards_handbook_v4.pdf (accessed on 1 October 2020).
- What Works Clearinghouse. WWC Procedures Handbook; Version 4.1; 2020. Available online: https://ies.ed.gov/ncee/wwc/Docs/referenceresources/WWC-Procedures-Handbook-v4-1-508.pdf (accessed on 1 October 2020).
- What Works Clearinghouse. WWC Standards Handbook; Version 4.1; 2020. Available online: https://ies.ed.gov/ncee/wwc/Docs/referenceresources/WWC-Standards-Handbook-v4-1-508.pdf (accessed on 1 October 2020).
- Goodwin, L.D.; Goodwin, W.L. Statistical Techniques in AERJ Articles, 1979–1983: The Preparation of Graduate Students to Read the Educational Research Literature. Educ. Res. 1985, 14, 5–11. [Google Scholar] [CrossRef]
- Dworkin, R.J. Hidden Bias in the Use of Archival Data. Evaluation Heal. Prof. 1987, 10, 173–185. [Google Scholar] [CrossRef]
- Reichow, B.; Barton, E.E.; Maggin, D.M. Development and applications of the single-case design risk of bias tool for evaluating single-case design research study reports. Res. Dev. Disabil. 2018, 79, 53–64. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-T.; Feng, Y.; Wu, P.-J.; Peng, C.-Y.J. Dealing with missing data by EM in single-case studies. Behav. Res. Methods 2020, 52, 131–150. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.-T.; Wu, P.-J.; Peng, C.-Y.J. Accounting for baseline trends in intervention studies: Methods, effect sizes, and software. Cogent Psychol. 2019, 6. [Google Scholar] [CrossRef]
- Cosbey, J.; Muldoon, D. EAT-UP™ Family-Centered Feeding Intervention to Promote Food Acceptance and Decrease Challenging Behaviors: A Single-Case Experimental Design Replicated Across Three Families of Children with Autism Spectrum Disorder. J. Autism Dev. Disord. 2017, 47, 564–578. [Google Scholar] [CrossRef] [PubMed]
- Lambert, M.C.; Cartledge, G.; Heward, W.L.; Lo, Y.-Y. Effects of Response Cards on Disruptive Behavior and Academic Responding During Math Lessons by Fourth-Grade Urban Students. J. Posit. Behav. Interv. 2006, 8, 88–99. [Google Scholar] [CrossRef]
- Stiegler, J.R.; Molde, H.; Schanche, E. Does an emotion-focused two-chair dialogue add to the therapeutic effect of the empathic attunement to affect? Clin. Psychol. Psychother. 2018, 25, e86–e95. [Google Scholar] [CrossRef]
- Matta, M.; Volpe, R.J.; Briesch, A.M.; Owens, J.S. Five direct behavior rating multi-item scales: Sensitivity to the effects of classroom interventions. J. Sch. Psychol. 2020, 81, 28–46. [Google Scholar] [CrossRef]
- Smith, J.D.; Eichler, W.C.; Norman, K.R.; Smith, S.R. The Effectiveness of Collaborative/Therapeutic Assessment for Psychotherapy Consultation: A Pragmatic Replicated Single-Case Study. J. Pers. Assess. 2014, 97, 261–270. [Google Scholar] [CrossRef]
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data, 2nd ed.; John Wiley & Sons, Inc.: New Jersey, NJ, USA, 2002. [Google Scholar]
- Borckardt, J.J.; Nash, M.R. Simulation modelling analysis for small sets of single-subject data collected over time. Neuropsychol. Rehabilitation 2014, 24, 492–506. [Google Scholar] [CrossRef]
- Busk, P.L.; Marascuilo, L.A. Autocorrelation in single-subject research: A counterargument to the myth of no autocorrelation. Behav. Assess. 1988, 10, 229–242. [Google Scholar]
- Huitema, B.E.; Mckean, J.W. Design Specification Issues in Time-Series Intervention Models. Educ. Psychol. Meas. 2000, 60, 38–58. [Google Scholar] [CrossRef]
- Shadish, W.R.; Hedges, L.V.; Pustejovsky, J.E. Analysis and meta-analysis of single-case designs with a standardized mean difference statistic: A primer and applications. J. Sch. Psychol. 2014, 52, 123–147. [Google Scholar] [CrossRef] [PubMed]
- Rafii, M.S.; Baumann, T.L.; Bakay, R.A.E.; Ostrove, J.M.; Siffert, J.; Fleisher, A.S.; Herzog, C.D.; Barba, D.; Pay, M.; Salmon, D.P.; et al. A phase1 study of stereotactic gene delivery of AAV2-NGF for Alzheimer’s disease. Alzheimer’s Dement. 2014, 10, 571–581. [Google Scholar] [CrossRef]
- Daza, E.J. Causal Analysis of Self-tracked Time Series Data Using a Counterfactual Framework for N-of-1 Trials. Methods Inf. Med. 2018, 57, e10–e21. [Google Scholar] [CrossRef] [Green Version]
- Pole, N.; Ablon, J.S.; O’Connor, L.E. Using psychodynamic, cognitive behavioral, and control mastery prototypes to predict change: A new look at an old paradigm for long-term single-case research. J. Couns. Psychol. 2008, 55, 221–232. [Google Scholar] [CrossRef] [Green Version]
- McDonald, S.; Vieira, R.; Johnston, D.W. Analysing N-of-1 observational data in health psychology and behavioural medicine: A 10-step SPSS tutorial for beginners. Heal. Psychol. Behav. Med. 2020, 8, 32–54. [Google Scholar] [CrossRef] [Green Version]
- Schafer, J.L. Multiple imputation: A primer. Stat. Methods Med. Res. 1999, 8, 3–15. [Google Scholar] [CrossRef] [PubMed]
- Peng, C.-Y.J.; Harwell, M.R.; Liou, S.-M.; Ehman, L.H. Advances in missing data methods and implications for educational research. In Real Data Analysis; Sawilowsky, S.S., Ed.; Information Age Pub: New York, NY, USA, 2006; pp. 31–78. [Google Scholar]
- Hobbs, N.; Dixon, D.; Johnston, M.; Howie, K. Can the theory of planned behaviour predict the physical activity behaviour of individuals? Psychol. Heal. 2013, 28, 234–249. [Google Scholar] [CrossRef] [PubMed]
- Nyman, S.R.; Goodwin, K.; Kwasnicka, D.; Callaway, A. Increasing walking among older people: A test of behaviour change techniques using factorial randomised N-of-1 trials. Psychol. Health 2016, 31, 313–330. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Quinn, F.; Johnston, M.; Johnston, D.W. Testing an integrated behavioural and biomedical model of disability in N-of-1 studies with chronic pain. Psychol. Health 2013, 28, 1391–1406. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data Via the EM Algorithm. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 1977, 39, 1–22. [Google Scholar] [CrossRef]
- Rubin, D.B. Inference and missing data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Graham, J.W. Adding Missing-Data-Relevant Variables to FIML-Based Structural Equation Models. Struct. Equ. Model. A Multidiscip. J. 2003, 10, 80–100. [Google Scholar] [CrossRef]
- Smith, J.D.; Borckardt, J.J.; Nash, M.R. Inferential Precision in Single-Case Time-Series Data Streams: How Well Does the EM Procedure Perform When Missing Observations Occur in Autocorrelated Data? Behav. Ther. 2012, 43, 679–685. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buu, A. Analysis of Longitudinal Data with Missing Values: A Methodological Comparison. Ph.D. Thesis, Indiana University, Bloomington, IN, USA, 1999. [Google Scholar]
- Horner, R.H.; Swaminathan, H.; Sugai, G.; Smolkowski, K. Considerations for the Systematic Analysis and Use of Single-Case Research. Educ. Treat. Child. 2012, 35, 269–290. [Google Scholar] [CrossRef]
- Marson, D.; Shadish, W.R. User guide for DHPS, D_Power, and GPHDPwr SPSS macros, Version 1.0. 2014.
- Tarlow, K.R. Baseline Corrected Tau Calculator. Available online: http://www.ktarlow.com/stats/tau (accessed on 1 October 2020).
- Hedges, L.V.; Pustejovsky, J.E.; Shadish, W.R. A standardized mean difference effect size for single case designs. Res. Synth. Methods 2012, 3, 224–239. [Google Scholar] [CrossRef] [PubMed]
- Tarlow, K.R. An Improved Rank Correlation Effect Size Statistic for Single-Case Designs: Baseline Corrected Tau. Behav. Modif. 2016, 41, 427–467. [Google Scholar] [CrossRef] [PubMed]
- Kendall, M. Rank Correlation Methods, 3rd ed.; Hafner Publishing Company: New York, NY, USA, 1962. [Google Scholar]
- Bennett, D.A. How can I deal with missing data in my study? Aust. N. Z. J. Public Heal. 2001, 25, 464–469. [Google Scholar] [CrossRef]
- Tabachnick, B.G.; Fidell, L.S. Using Multivariate Statistics, 6th ed.; Allyn & Bacon: Boston, MS, USA, 2012. [Google Scholar]
- Little, R.J.A.; Schenker, N. Missing data. In Handbook of Statistical Modeling for the Social and Behavioral Sciences; Arminger, G., Clogg, C.C., Sobel, M.E., Eds.; Plenum Press: New York, NY, USA, 1995; pp. 39–75. [Google Scholar]
- Carpenter, J.R.; Goldstein, H. Multiple imputation in MLwiN. Multilevel Model. Newsl. 2004, 16, 9–18. [Google Scholar]
- Horton, N.J.; Kleinman, K.P. Much Ado About Nothing. Am. Stat. 2007, 61, 79–90. [Google Scholar] [CrossRef] [PubMed]
- White, I.R.; Royston, P.; Wood, A.M. Multiple imputation using chained equations: Issues and guidance for practice. Stat. Med. 2010, 30, 377–399. [Google Scholar] [CrossRef] [PubMed]
- Allison, P.D. Missing Data; Sage Publications: Thousand Oaks, CL, USA, 2001. [Google Scholar]
- Collins, L.M.; Schafer, J.L.; Kam, C.-M. A comparison of inclusive and restrictive strategies in modern missing data procedures. Psychol. Methods 2001, 6, 330–351. [Google Scholar] [CrossRef]
- Rubin, D.B. Multiple Imputation after 18+ Years. J. Am. Stat. Assoc. 1996, 91, 473–489. [Google Scholar] [CrossRef]
- Schomaker, M.; Heumann, C. Bootstrap inference when using multiple imputation. Stat. Med. 2018, 37, 2252–2266. [Google Scholar] [CrossRef]
- Edgington, E.; Onghena, P. Randomization Tests; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Bulté, I.; Onghena, P. An R package for single-case randomization tests. Behav. Res. Methods 2008, 40, 467–478. [Google Scholar] [CrossRef] [Green Version]
- De, T.K.; Michiels, B.; Tanious, R.; Onghena, P. Handling missing data in randomization tests for single-case experiments: A simulation study. Behav. Res. Methods 2020, 52, 1355–1370. [Google Scholar] [CrossRef]


{kind=link}
| Characteristics | AD | MS | MM | TMM | LOCF | LIN | AMS | MI | EM |
|---|---|---|---|---|---|---|---|---|---|
| Implementations | |||||||||
| A default in most SCD specialized computing tools | √ | ||||||||
| Missing score is replaced | √ | √ | √ | √ | √ | √ | √ | ||
| Statistical inferences are valid if scores are missing completely at random (MCAR) | √ | ||||||||
| Statistical inferences are valid if scores are missing at random (MAR) | √ | √ | √ | √ | √ | √ | √ | √ | |
| Imputed scores are based on information contained in observed scores | √ | √ | √ | √ | √ | √ | √ | ||
| Statistical inferences are derived from observed scores | √ | √ | √ | √ | √ | √ | √ | √ | √ |
| Statistical model for the observed and missing scores is required | √ | √ | |||||||
| Multivariate normal distribution is assumed for population | √ | √ | |||||||
| Minimizes bias in parameter estimates derived from the AD method | √ | √ | √ | √ | √ | √ | √ | √ | |
| Provides a more conservative assessment of level change than the AD method | √ | √ | |||||||
| Can be used in conjunction with visual analysis of data | √ | √ | √ | √ | √ | √ | √ | ||
| Inappropriate if the purpose of intervention is to slow the rate of decline, or flatten the rate of increase | √ | ||||||||
| Decreases precision in assessing the intervention effect | √ | ||||||||
| Decreases statistical power of a statistical test | √ | √ | |||||||
| Inflates correlations among scores | √ | ||||||||
| Reduces variability among scores; hence, increases the probability of Type I error | √ | √ | √ | ||||||
| Strengths | |||||||||
| Maintains the study design | √ | √ | √ | √ | √ | √ | √ | ||
| Maintains the sample size | √ | √ | √ | √ | √ | √ | √ | ||
| Always applicable | √ | √ | √ | √ | |||||
| Individual-level assessments can be integrated into group assessments | √ | √ | √ | √ | √ | √ | √ | √ | |
| Suitable when missing data rate is ≤5% | √ | √ | √ | √ | √ | √ | √ | √ | √ |
| Suitable when missing data rate is between 5% and 30% and MAR holds | √ | √ | √ | √ | √ | √ | √ | √ | |
| Imputed scores are always on the same scale as data | √ | √ | √ | ||||||
| Can account for uncertainty surrounding the imputed scores 1 | √ | √ | √ |
| SSR1 1 | RC1 1 | |||||||||||||||
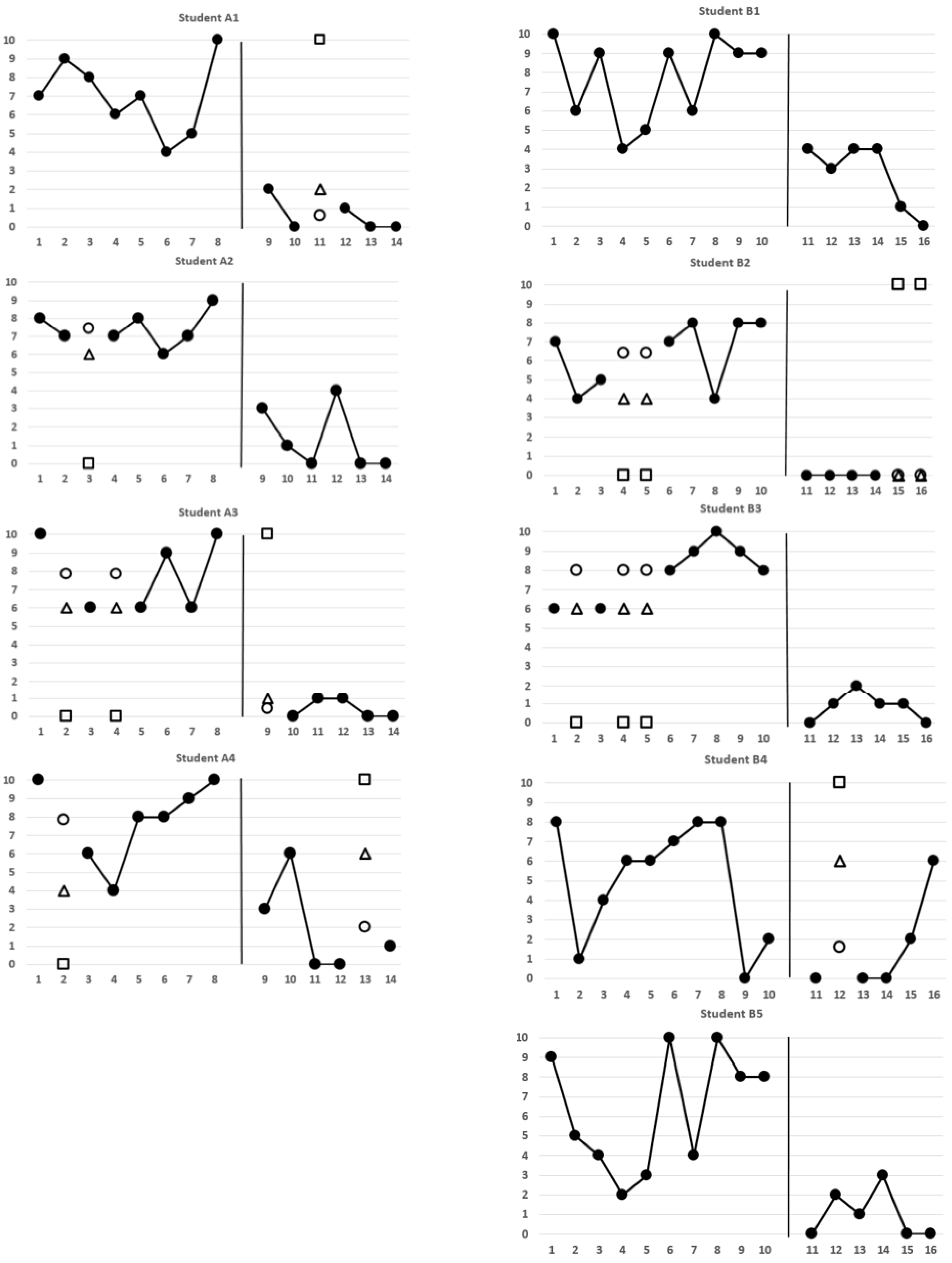
| Student | 1 2 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 3 | 10 | 11 | 12 | 13 | 14 | ||
| A1 | 7 | 9 | 8 | 6 | 7 | 4 | 5 | 10 | 2 | 0 | (0.60/2/10) | 1 | 0 | 0 | ||
| A2 | 8 | 7 | (7.43/6/0) | 7 | 8 | 6 | 7 | 9 | 3 | 1 | 0 | 4 | 0 | 0 | ||
| A3 | 10 | (7.83/6/0) | 6 | (7.83/6/0) | 6 | 9 | 6 | 10 | (0.40/1/10) | 0 | 1 | 1 | 0 | 0 | ||
| A4 | 10 | (7.86/4/0) | 6 | 4 | 8 | 8 | 9 | 10 | 3 | 6 | 0 | 0 | (2.00/6/10) | 1 | ||
| SSR1 1 | RC1 1 | |||||||||||||||
| Student | 1 2 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 4 | 12 | 13 | 14 | 15 | 16 |
| B1 | 10 | 6 | 9 | 4 | 5 | 9 | 6 | 10 | 9 | 9 | 4 | 3 | 4 | 4 | 1 | 0 |
| B2 | 7 | 4 | 5 | (6.38/4/0) | (6.38/4/0) | 7 | 8 | 4 | 8 | 8 | 0 | 0 | 0 | 0 | (0/0/10) | (0/0/10) |
| B3 | 6 | (8.00/6/0) | 6 | (8.00/6/0) | (8.00/6/0) | 8 | 9 | 10 | 9 | 8 | 0 | 1 | 2 | 1 | 1 | 0 |
| B4 | 8 | 1 | 4 | 6 | 6 | 7 | 8 | 8 | 0 | 2 | 0 | (1.60/6/10) | 0 | 0 | 2 | 6 |
| B5 | 9 | 5 | 4 | 2 | 3 | 10 | 4 | 10 | 8 | 8 | 0 | 2 | 1 | 3 | 0 | 0 |
| AD | MS | MM | TMM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | g | p | 95% CI | g | p | 95% CI | g | p | 95% CI | g | p | 95% CI |
| A | 3.78 | <0.001 | [2.82, ∞] | 4.33 | <0.001 | [3.39, ∞] | 3.42 | <0.001 | [2.64, ∞] | 1.41 | <0.001 | [0.91, ∞] |
| B | 2.62 | <0.001 | [1.93, ∞] | 2.47 | <0.001 | [1.89, ∞] | 2.35 | <0.001 | [1.78, ∞] | 1.33 | <0.001 | [0.80, ∞] |
| A + B | 3.02 | <0.001 | [2.48, ∞] | 3.29 | <0.001 | [2.80, ∞] | 2.97 | <0.001 | [2.51, ∞] | 1.40 | <0.001 | [1.04, ∞] |
| Method | AD | ||||||
|---|---|---|---|---|---|---|---|
| Student | MSSR12 | MRC12 | SDSSR1 | SDRC1 | t | df | P3 |
| A1 | 7.00 | 0.60 | 2.00 | 0.89 | 6.67 | 11 | <0.001 |
| A2 | 7.43 | 1.33 | 0.98 | 1.75 | 7.92 | 11 | <0.001 |
| A3 | 7.83 | 0.40 | 2.04 | 0.55 | 7.85 | 9 | <0.001 |
| A4 | 7.86 | 2.00 | 2.19 | 2.55 | 4.27 | 10 | 0.001 |
| B1 1 | 7.70 | 2.67 | 2.21 | 1.75 | 4.73 | 14 | <0.001 |
| B2 | 6.38 | 0.00 | 1.77 | 0.00 | 7.04 | 10 | <0.001 |
| B3 | 8.00 | 0.83 | 1.53 | 0.75 | 10.41 | 11 | <0.001 |
| B4 | 5.00 | 1.60 | 3.06 | 2.61 | 2.12 | 13 | 0.027 |
| B5 1 | 6.30 | 1.00 | 3.02 | 1.26 | 4.05 | 14 | 0.001 |
| MS | |||||||
| A1 | 7.00 | 0.60 | 2.00 | 0.80 | 7.35 | 12 | <0.001 |
| A2 | 7.43 | 1.33 | 0.90 | 1.75 | 8.52 | 12 | <0.001 |
| A3 | 7.83 | 0.40 | 1.73 | 0.49 | 10.15 | 12 | <0.001 |
| A4 | 7.86 | 2.00 | 2.03 | 2.28 | 5.08 | 12 | <0.001 |
| B2 | 6.38 | 0.00 | 1.56 | 0.00 | 9.88 | 14 | <0.001 |
| B3 | 8.00 | 0.83 | 1.25 | 0.75 | 12.66 | 14 | <0.001 |
| B4 | 5.00 | 1.60 | 3.06 | 2.33 | 2.34 | 14 | 0.017 |
| MM | |||||||
| A1 | 7.00 | 0.83 | 2.00 | 0.98 | 6.90 | 12 | <0.001 |
| A2 | 7.25 | 1.33 | 1.04 | 1.75 | 7.94 | 12 | <0.001 |
| A3 | 7.38 | 0.50 | 1.92 | 0.55 | 8.43 | 12 | <0.001 |
| A4 | 7.38 | 2.67 | 2.45 | 2.80 | 3.35 | 12 | 0.003 |
| B2 | 5.90 | 0.00 | 1.85 | 0.00 | 7.69 | 14 | <0.001 |
| B3 | 7.40 | 0.83 | 1.58 | 0.75 | 9.47 | 14 | <0.001 |
| B4 | 5.00 | 2.33 | 3.06 | 2.94 | 1.71 | 14 | 0.055 |
| TMM | |||||||
| A1 | 7.00 | 2.17 | 2.00 | 3.92 | 3.03 | 12 | 0.005 |
| A2 | 6.50 | 1.33 | 2.78 | 1.75 | 3.98 | 12 | 0.001 |
| A3 | 5.88 | 2.00 | 4.02 | 3.95 | 1.80 | 12 | 0.049 |
| A4 | 6.88 | 3.33 | 3.44 | 3.98 | 1.78 | 12 | <0.050 |
| B2 | 5.10 | 3.33 | 3.11 | 5.16 | 0.86 | 14 | 0.202 |
| B3 | 5.60 | 0.83 | 4.06 | 0.75 | 2.81 | 14 | 0.007 |
| B4 | 5.00 | 3.00 | 3.06 | 4.15 | 1.11 | 14 | 0.143 |
| Three Scores 2 | AD | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Student | SSR1 | RC1 | MSSR13 | MRC13 | SDSSR1 | SDRC1 | t | df | P4 |
| A1 | 4, 5, 10 | 2, 0, ? | 6.33 | 1.00 | 3.21 | 1.41 | 2.13 | 3 | 0.062 |
| A2 1 | 6, 7, 9 | 3, 1, 0 | 7.33 | 1.33 | 1.53 | 1.53 | 4.81 | 4 | 0.004 |
| A3 | 9, 6, 10 | ?, 0, 1 | 8.33 | 0.50 | 2.08 | 0.71 | 4.91 | 3 | 0.008 |
| A4 1 | 8, 9, 10 | 3, 6, 0 | 9.00 | 3.00 | 1.00 | 3.00 | 3.29 | 4 | 0.015 |
| B1 1 | 10, 9, 9 | 4, 3, 4 | 9.33 | 3.67 | 0.58 | 0.58 | 12.02 | 4 | <0.001 |
| B2 1 | 4, 8, 8 | 0, 0, 0 | 6.67 | 0.00 | 2.31 | 0.00 | 5.00 | 4 | 0.004 |
| B3 1 | 10, 9, 8 | 0, 1, 2 | 9.00 | 1.00 | 1.00 | 1.00 | 9.80 | 4 | <0.001 |
| B4 | 8, 0, 2 | 0, ?, 0 | 3.33 | 0.00 | 4.16 | 0.00 | 1.07 | 3 | 0.181 |
| B5 1 | 10, 8, 8 | 0, 2, 1 | 8.67 | 1.00 | 1.15 | 1.00 | 8.69 | 4 | <0.001 |
| MS | |||||||||
| A1 | 4, 5, 10 | 2, 0, 0.6 | 6.33 | 0.87 | 3.21 | 1.03 | 2.81 | 4 | 0.024 |
| A3 | 9, 6, 10 | 0.4, 0, 1 | 8.33 | 0.47 | 2.08 | 0.50 | 6.36 | 4 | 0.002 |
| B4 | 8, 0, 2 | 0, 1.6, 0 | 3.33 | 0.53 | 4.16 | 0.92 | 1.14 | 4 | 0.160 |
| MM | |||||||||
| A1 | 4, 5, 10 | 2, 0, 2 | 6.33 | 1.33 | 3.21 | 1.15 | 2.54 | 4 | 0.032 |
| A3 | 9, 6, 10 | 1, 0, 1 | 8.33 | 0.67 | 2.08 | 0.58 | 6.15 | 4 | 0.002 |
| B4 | 8, 0, 2 | 0, 6, 0 | 3.33 | 2.00 | 4.16 | 3.46 | 0.43 | 4 | 0.350 |
| TMM | |||||||||
| A1 | 4, 5, 10 | 2, 0, 10 | 6.33 | 4.00 | 3.21 | 5.29 | 0.65 | 4 | 0.275 |
| A3 | 9, 6, 10 | 10, 0, 1 | 8.33 | 3.67 | 2.08 | 5.51 | 1.37 | 4 | 0.121 |
| B4 | 8, 0, 2 | 0, 10, 0 | 3.33 | 3.33 | 4.16 | 5.77 | 0.00 | 4 | 0.500 |
| AD | MS | MM | TMM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Student | Tau | SE | p | Tau | SE | p | Tau | SE | p | Tau | SE | P4 |
| A1 | −0.735 | 0.266 | 0.002 | −0.743 | 0.253 | 0.001 | −0.747 | 0.251 | 0.001 | −0.514 | 0.324 | 0.019 |
| A2 | −0.769 | 0.251 | 0.002 | −0.756 | 0.247 | 0.001 | −0.760 | 0.245 | 0.001 | −0.625 | 0.295 | 0.007 |
| A3 | −0.799 | 0.256 | 0.004 | −0.765 | 0.243 | 0.001 | −0.805 | 0.224 | 0.001 | −0.336 | 0.356 | 0.103 |
| A4 | −0.687 | 0.297 | 0.006 | −0.696 | 0.271 | 0.002 | −0.598 | 0.303 | 0.008 | −0.364 | 0.352 | 0.076 |
| B1 1 | −0.715 | 0.247 | 0.001 | (same as AD results) | ||||||||
| B2 | −0.763 | 0.264 | 0.004 | −0.778 | 0.222 | <0.001 | −0.795 | 0.215 | <0.001 | −0.156 | 0.349 | 0.269 |
| B3 2 | −0.769 | 0.251 | 0.002 | −0.710 2 | 0.249 | <0.001 3 | −0.713 2 | 0.248 | <0.001 3 | −0.380 | 0.327 | 0.055 |
| B4 | −0.472 | 0.322 | 0.027 | −0.474 | 0.311 | 0.021 | −0.405 | 0.323 | 0.044 | −0.275 | 0.340 | 0.124 |
| B5 1 | −0.683 | 0.258 | 0.002 | (same as AD results) | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, C.-Y.J.; Chen, L.-T. Assessing Intervention Effects in the Presence of Missing Scores. Educ. Sci. 2021, 11, 76. https://doi.org/10.3390/educsci11020076
Peng C-YJ, Chen L-T. Assessing Intervention Effects in the Presence of Missing Scores. Education Sciences. 2021; 11(2):76. https://doi.org/10.3390/educsci11020076
Chicago/Turabian StylePeng, Chao-Ying Joanne, and Li-Ting Chen. 2021. "Assessing Intervention Effects in the Presence of Missing Scores" Education Sciences 11, no. 2: 76. https://doi.org/10.3390/educsci11020076