
Using Machine Learning Approaches to Explore Non-Cognitive Variables Influencing Reading Proficiency in English among Filipino Learners

 , ,
, , 
Abstract
:1. Introduction
1.1. The PISA 2018 Reading Assessment and Philippine Results
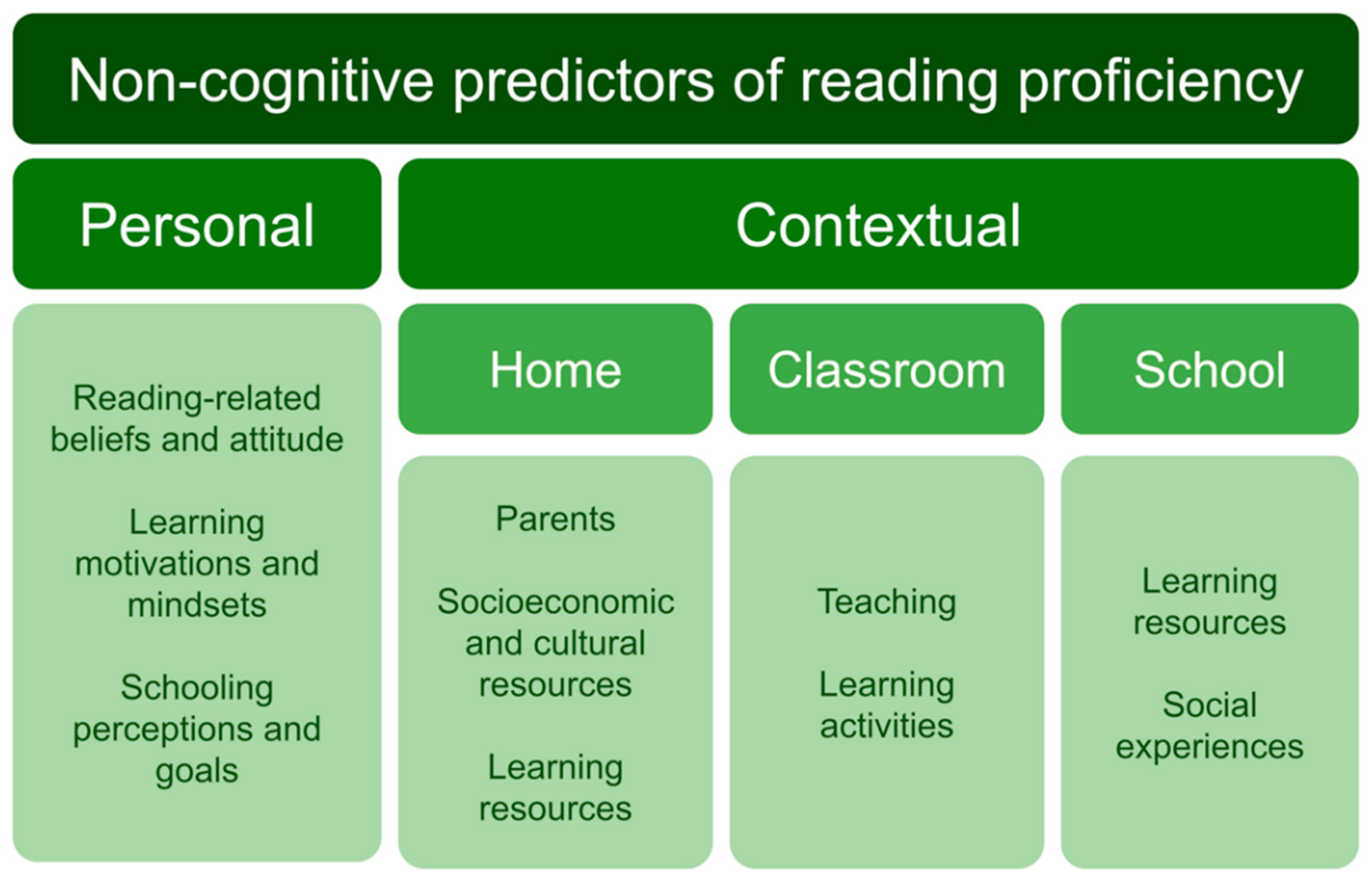
1.2. Predictors of Reading Proficiency
1.3. The Current Study
2. Materials and Analytic Methods
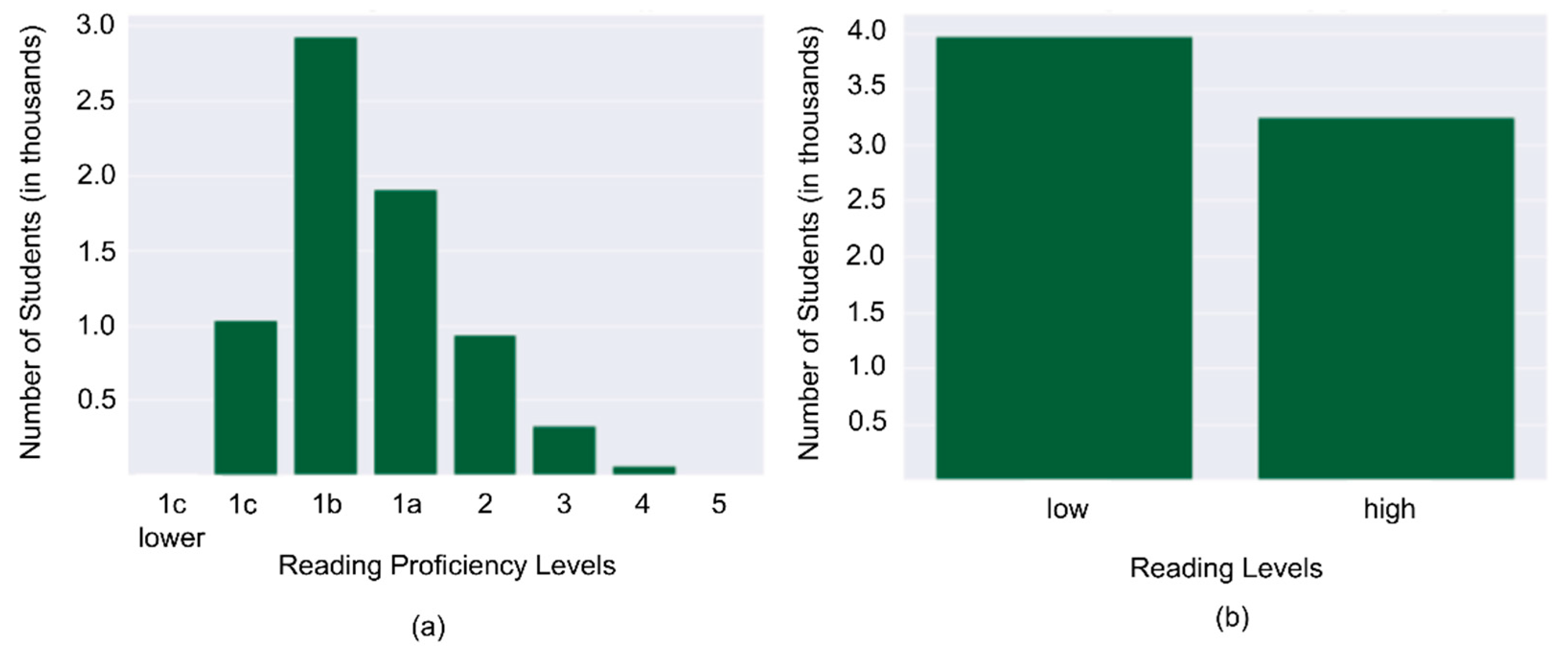
2.1. The Dataset
2.2. Machine Learning Modeling
3. Results
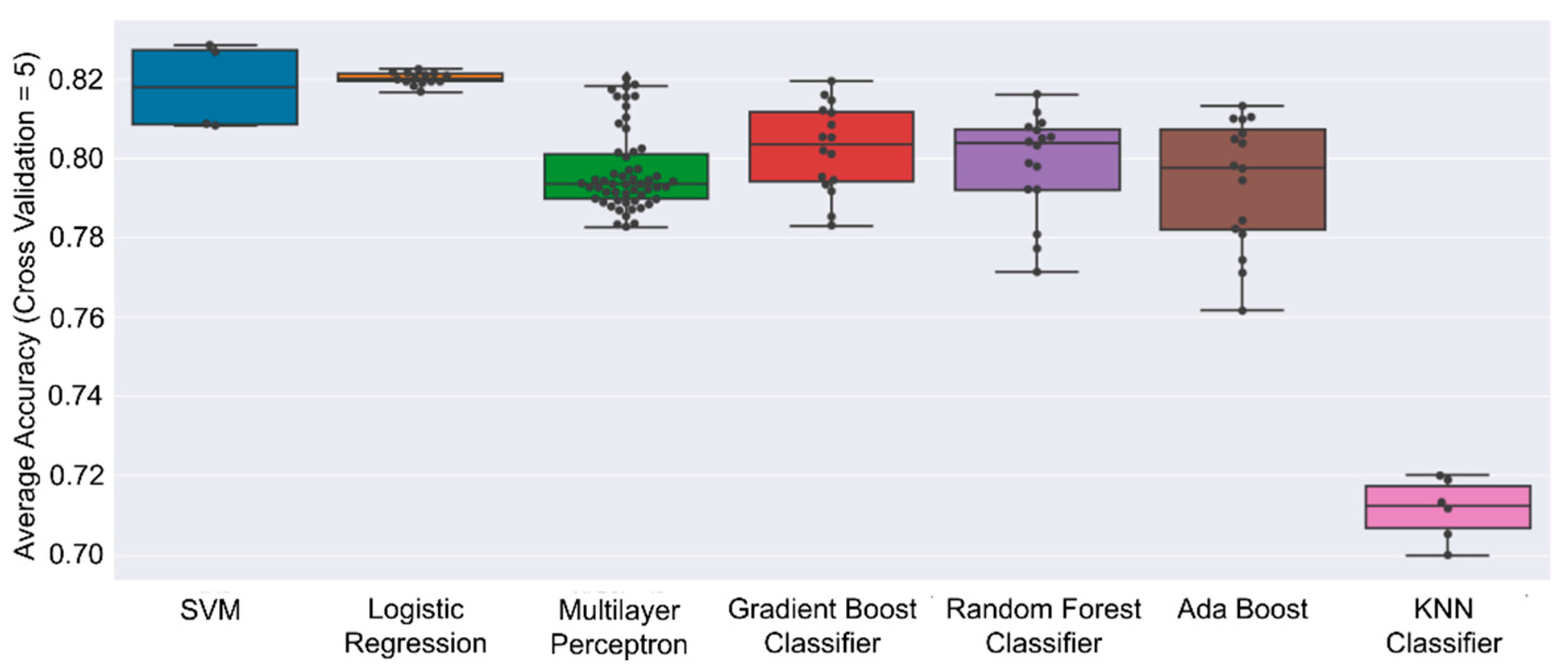
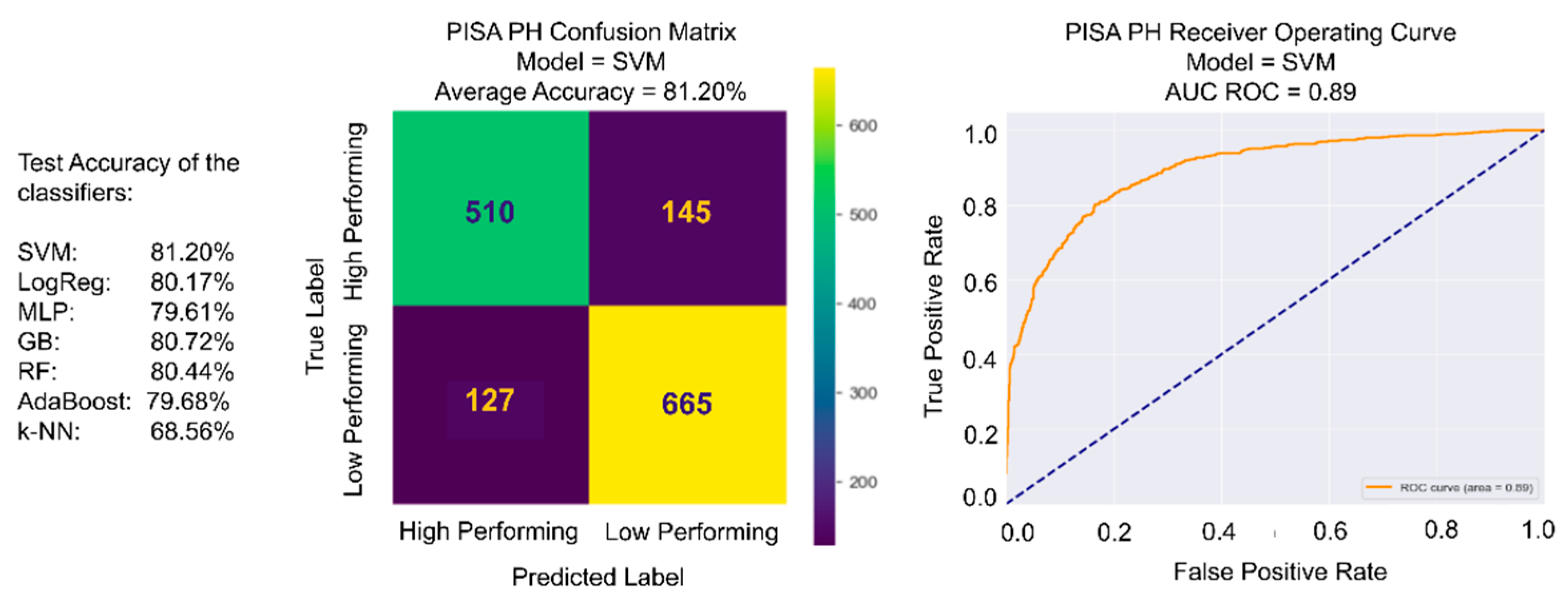
3.1. Machine Learning Modeling Results
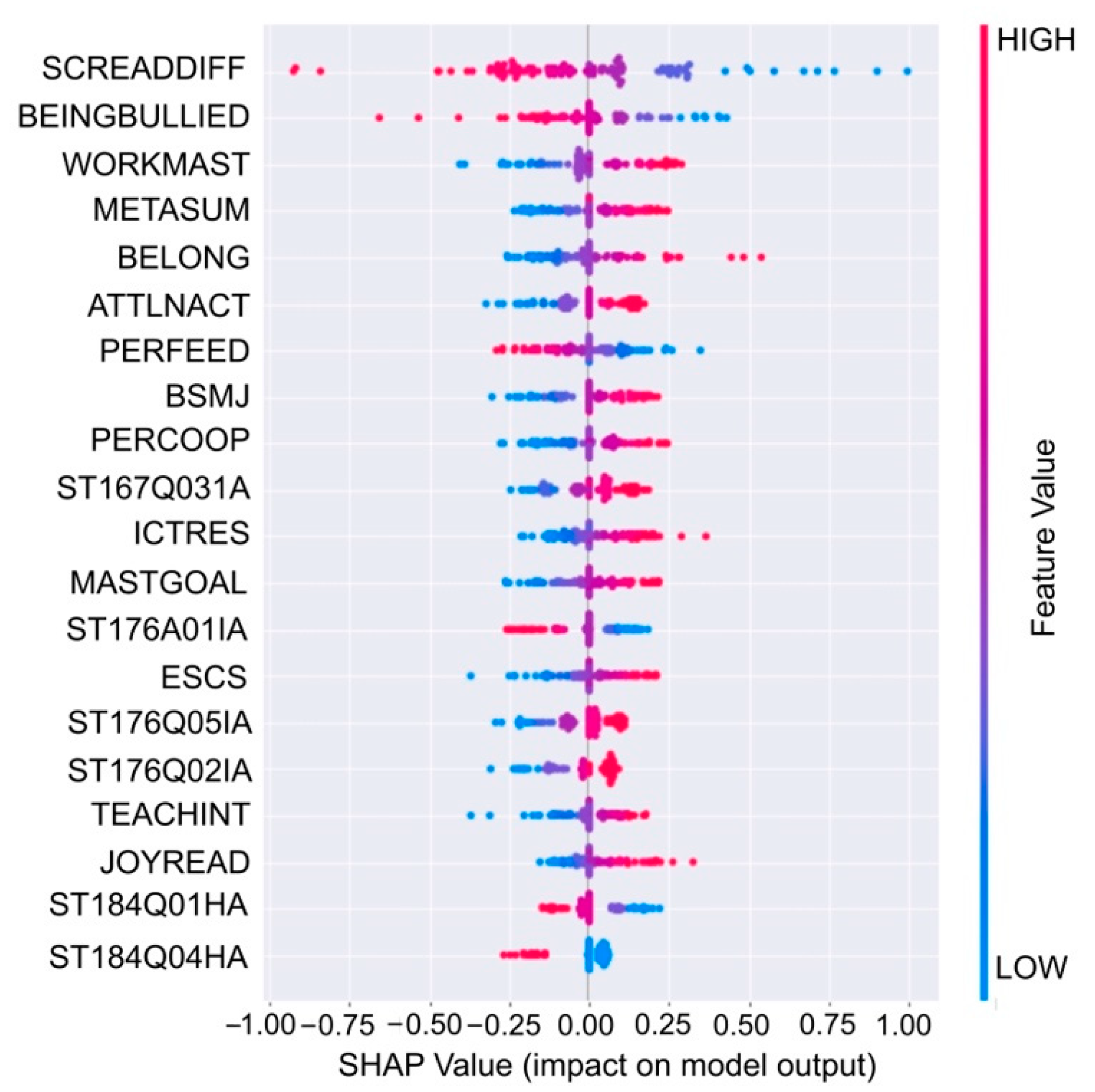
3.2. Most Important Variables
3.2.1. Reading-Related Beliefs and Enjoyment
3.2.2. Teacher-Related/Instructional Variables
3.2.3. ICT Resources and Use
3.2.4. Student Beliefs, Motivations, and Aspirations
3.2.5. Social Experiences in School
3.2.6. Economic, Social, and Cultural Status
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kern, M.L.; Friedman, H.S. Early educational milestones as predictors of lifelong academic achievement, midlife adjustment, and longevity. J. Appl. Dev. Psychol. 2009, 3, 419–430. [Google Scholar] [CrossRef] [Green Version]
- Smith, M.C.; Mikulecky, L.; Kibby, M.W.; Dreher, M.J.; Dole, J.A. What will be the demands of literacy in the workplace in the next millennium? Read. Res. Q. 2000, 35, 378–383. [Google Scholar] [CrossRef]
- Wharton-McDonald, R.; Swiger, S. Developing higher order comprehension in the middle grades. In Handbook of Research on Reading Comprehension; Israel, S.E., Duffy, G.G., Eds.; Routledge: New York, NY, USA, 2009; pp. 510–530. [Google Scholar]
- Coulombe, S.; Tremblay, J.-F.; Marchand, S. Literacy Scores, Human Capital and Growth across Fourteen OECD Countries; Statistics Canada: Ottawa, ON, Canada, 2004.
- Duke, N.K. The case for informational text. Educ. Leadersh. 2004, 61, 40–44. [Google Scholar]
- Organisation for Economic Co-Operation and Development. PISA 2018 Results (Vol I): What Students Know and Can. Do; OECD Publishing: Paris, France, 2019; Available online: https://doi.org/10.1787/5f07c754-en (accessed on 17 February 2020).
- Romero, A.D.; Papango, M.C. PISA reading literacy vis-à-vis K to12 English curriculum. In Challenges of PISA: The PNU Report; Balagtas, M.U., Montealegre, M.C., Eds.; Philippine Normal University and Rex Institute for Student Excellence, Inc.: Manila, Philippines, 2020; pp. 33–56. [Google Scholar]
- Trinidad, J.E. Material resources, school climate, and achievement variations in the Philippines: Insights from PISA 2018. Int. J. Educ. Dev. 2020, 75, 102174. [Google Scholar] [CrossRef]
- Bernardo, A.B.I. Socioeconomic status moderates the relationship between growth mindset and learning in mathematics and science: Evidence from PISA 2018 Philippine data. Int. J. Sch. Educ. Psychol. 2020, 9, 208–222. [Google Scholar] [CrossRef]
- Organization for Economic Co-Operation and Development. PISA 2018. Assessment and Analytic Framework; OECD Publishing: Paris, France, 2019. [Google Scholar] [CrossRef]
- Tse, S.; Xiao, X. Differential infuences of affective factors and contextual factors on high-proficiency readers and low-proficiency readers: A multilevel analysis of PIRLS data from Hong Kong. Large Scale Assess. Educ. 2014, 2, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Cheung, W.; Tse, S.; Lam, J.; Loh, K. Progress in International Reading Literacy Study 2006 (PIRLS): Pedagogical correlates of fourth-grade Students in Hong Kong. J. Res. Read. 2009, 32, 293–308. [Google Scholar] [CrossRef]
- Okkinga, M.; van Steensel, R.; van Gelderen, A.J.S.; van Schooten, E.; Sleegers, P.J.C.; Arends, L.R. Effectiveness of reading-strategy interventions in whole classrooms: A meta-analysis. Educ. Psychol. Rev. 2018, 30, 1215–1239. [Google Scholar] [CrossRef]
- Burns, M.K.; Davidson, K.; Zaslofsky, A.F.; Parker, D.C.; Maki, K.E. The relationship between acquisition rate for words and working memory, short-term memory, and reading skills: Aptitude-by-treatment or skill-by-treatment interaction? Assess. Eff. Interv. 2018, 43, 182–192. [Google Scholar] [CrossRef]
- Ghabanchi, Z.; Rastegar, R.E. The correlation of IQ and Emotional Intelligence with reading comprehension. Reading 2014, 14, 135–144. [Google Scholar]
- Beglar, D.; Hunt, A.; Kite, Y. The Effect of pleasure reading on Japanese university EFL learners’ reading rates. Lang. Learn. J. 2011, 62, 665–703. [Google Scholar] [CrossRef]
- Wilhelm, J.D.; Smith, M.W. The power of pleasure reading: What we can learn from the secret reading lives of teens. Engl. J. 2016, 105, 25–30. [Google Scholar]
- Hebbecker, K.; Förster, N.; Souvignier, E. Reciprocal effects between reading achievement and intrinsic and extrinsic reading motivation. Sci. Stud. Read. 2019, 23, 419–436. [Google Scholar] [CrossRef]
- Ma, L.; Luo, H.; Xiao, L. Perceived teacher support, self-concept, enjoyment and achievement in reading: A multilevel mediation model based on PISA 2018. Learn. Indiv. Diff. 2021, 85, 101947. [Google Scholar] [CrossRef]
- Friesen, D.; Haigh, C. How and why strategy instruction can improve second language reading comprehension: A review. Read. Matrix. 2018, 18, 1–18. [Google Scholar]
- Zhang, L.; Goh, C.C.M.; Kunnan, A.J. Analysis of test takers’ metacognitive and cognitive strategy use and EFL reading test performance: A multi-sample SEM approach. Lang. Assess. Q. 2014, 11, 76–102. [Google Scholar] [CrossRef]
- Vidal-Abarca, E.; Mañá, A.; Gil, L. Individual differences for self-regulating task-oriented reading activities. J. Educ. Psychol. 2010, 102, 817–826. [Google Scholar] [CrossRef]
- Toste, J.R.; Didion, L.; Peng, P.; Filderman, M.J.; McClelland, A.M. A meta-analytic review of the relations between motivation and reading achievement for K–12 students. Rev. Educ. Res. 2020, 90, 420–456. [Google Scholar] [CrossRef]
- Whitney, S.D.; Bergin, D.A. Students’ motivation and engagement predict reading achievement differently by ethnic group. J. Genet. Psychol. 2018, 179, 357–370. [Google Scholar] [CrossRef]
- Cho, E.; Toste, J.R.; Lee, M.; Ju, U. Motivational predictors of struggling readers’ reading comprehension: The effects of mindset, achievement goals, and engagement. Read. Writ. 2019, 32, 1219–1242. [Google Scholar] [CrossRef]
- Goetz, T.; Frenzel, A.C.; Pekrun, R.; Hall, N.C.; Lüdtke, O. Between-and within-domain relations of students’ academic emotions. J. Educ. Psychol. 2007, 99, 715–733. [Google Scholar] [CrossRef] [Green Version]
- Bernardo, A.B.I.; Cai, Y.; King, R.B. Society-level social axiom moderates the association between growth mindset and achievement across cultures. Br. J. Educ. Psychol. 2021, e12411. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, Y.; Wei, Y.; Hu, J. Discrimination of the contextual features of top performers in scientific literacy using a machine learning approach. Res. Sci. Educ. 2019, 47, 27–33. [Google Scholar] [CrossRef]
- Cabrera, A.F.; la Nasa, S.M. Three critical tasks America’s disadvantaged face on their path to college. New Dir. Inst. Res. 2000, 107, 23–29. [Google Scholar] [CrossRef]
- Ngorosho, D. Reading and writing ability in relation to home environment: A study in primary education in rural Tanzania. Child. Indic. Res. 2010, 4, 369–388. [Google Scholar] [CrossRef]
- Xiao, Y.; Hu, J. The moderation examination of ICT use on the association between Chinese Mainland students’ socioeconomic status and reading achievement. Int. J. Emerg. Technol. Learn. 2019, 14, 107–120. [Google Scholar] [CrossRef] [Green Version]
- Hu, X.; Gong, Y.; Lai, C.; Leung, F.K. The relationship between ICT and student literacy in mathematics, reading, and science across 44 countries: A multilevel analysis. Comput. Educ. 2018, 125, 1–13. [Google Scholar] [CrossRef]
- Shin, S.; Slater, C.L.; Ortiz, S. Leader perceptions and student achievement. Int. J. Educ. Manag. 2017, 31, 1103–1118. [Google Scholar] [CrossRef]
- Alivernini, F.; Manganelli, S. Country, school and students factors associated with extreme levels of science literacy across 25 countries. Int. J. Sci. Educ. 2015, 37, 1992–2012. [Google Scholar] [CrossRef]
- Poon, C.L.; Lam, K.W.; Chan, M.; Chng, M.; Kwek, D.; Tan, S. Preparing students for the twenty-first century: A Snapshot of Singapore’s approach. In Educating for the 21st Century; Springer: Berlin/Heidelberg, Germany, 2016; pp. 225–241. [Google Scholar] [CrossRef]
- Broh, B.A. Linking extracurricular programming to academic achievement: Who benefits and why? Sociol. Educ. 2002, 5, 69–95. [Google Scholar] [CrossRef]
- Gerra, G.; Benedetti, E.; Resce, G.; Potente, R.; Cutilli, A.; Molinaro, S. Socioeconomic status, parental education, school connectedness and individual socio-cultural resources in vulnerability for drug use among students. Int. J. Environ. Res. Public Health 2020, 17, 1306. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Turunen, T.; Kiuru, N.; Poskiparta, E.; Niemi, P.; Nurmi, J.E. Word reading skills and externalizing and internalizing problems from Grade 1 to Grade 2—Developmental trajectories and bullying involvement in Grade 3. Sci. Stud. Read. 2019, 23, 161–177. [Google Scholar] [CrossRef] [Green Version]
- Bronfenbrenner, U. The Ecology of Human Development: Experiments by Nature and Design; Harvard University Press: Cambridge, UK, 2009. [Google Scholar]
- Bernardo, A.B.I.; Liem, G.A.D. Mapping the spaces of cross-cultural educational psychology. In Advancing Cross-Cultural Perspectives on Educational Psychology; Liem, G.A.D., Bernardo, A.B.I., Eds.; Information Age Publications: Charlotte, NC, USA, 2013; pp. 345–357. [Google Scholar]
- Calica, M.P.C. The effect of parental characteristics and home resources on reading performance of 15-year old students in the Philippines. New Educ. Rev. 2020, 62, 1–176. [Google Scholar] [CrossRef]
- Torres, L.R.; Ordóñez, G.; Calvo, K. Teacher and student practices associated with performance in the PISA reading literacy evaluation. Front. Educ. 2021, 6, 167. [Google Scholar] [CrossRef]
- Gubbels, J.; Swart, N.M.; Groen, M.A. Everything in moderation: ICT and reading performance of Dutch 15-year-olds. Large Scale Assess. Educ. 2020, 8, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Besa, F. Philippines Country Note. Programme for International Student Assessment (PISA). Results from PISA 2018; OECD Publishing: Paris, France, 2019; Available online: http://www.oecd.org/pisa/publications/PISA2018_CN_PHL.pdf (accessed on 25 January 2020).
- Dong, X.; Hu, J. An exploration of impact factors influencing students’ reading literacy in Singapore with machine learning approaches. Int. J. Engl. Linguist. 2019, 9, 52–65. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S. A unified approach to interpreting model predictions. In Proceedings of the 31st Conference on Neural Information Processing System (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Mohseni, F.; Seifoori, Z.; Ahangari, S.; Khajavi, Y. The impact of metacognitive strategy training and critical thinking awareness-raising on reading comprehension. Cogent Educ. 2020, 7, 1720946. [Google Scholar] [CrossRef]
- Sheikh, I.; Soomro, K.; Kamal, A.; Hussain, N. Metacognitive awareness of reading strategies, reading practices and academic attainments of university students. J. Educ. Educ. Dev. 2019, 6, 126–137. [Google Scholar] [CrossRef]
- Dewaele, J.M.; Li, C. Teacher enthusiasm and students’ social-behavioral learning engagement: The mediating role of student enjoyment and boredom in Chinese EFL classes. Lang. Teach. Res. 2021, 25, 1–26. [Google Scholar] [CrossRef]
- Gumus, S.; Atalmis, E. Exploring the relationship between purpose of computer usage and reading skills of Turkish students: Evidence from PISA 2006. Turk. Online J. Educ. Technol. 2011, 10, 129–140. [Google Scholar]
- Moran, J.; Ferdig, R.E.; Pearson, P.D.; Wardrop, J.; Blomeyer, R.L. Technology and reading performance in the middle-school grades: A Meta-analysis with recommendations for policy and practice. J. Lit. Res. 2008, 40, 6–58. [Google Scholar] [CrossRef]
- Gomez, R.; Suarez, A.M. Do Inquiry-based teaching and school climate influence science achievement and critical thinking? Evidence from PISA 2015. Int. J. STEM Educ. 2020, 7, 43. [Google Scholar] [CrossRef]
- Leventhal, T.; Brooks-Gunn, J. The neighborhoods they live in: The effects of neighborhood residence on child and adolescent outcomes. Psychol. Bull. 2000, 126, 309–337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mok, S.Y.; Bakaç, C.; Froehlich, L. ‘My family’s goals are also my goals’: The relationship between collectivism, distal utility value, and learning and career goals of international university students in Germany. Int. J. Educ. Vocat. Guid. 2021, 21, 355–378. [Google Scholar] [CrossRef]
- Engelhardt, L.E.; Church, J.A.; Paige Harden, K.; Tucker-Drob, E.M. Accounting for the shared environment in cognitive abilities and academic achievement with measured socioecological contexts. Dev. Sci. 2019, 22, e12699. [Google Scholar] [CrossRef]
- Bernardo, A.B.I.; Ganotice, F.A.; King, R.B. Motivation gap and achievement gap between public and private high schools in the Philippines. Asia Pacific Edu. Res. 2015, 24, 657–667. [Google Scholar] [CrossRef]
- Sirin, S.R. Socioeconomic status and academic achievement: A meta-analytic review of research. Rev. Educ. Res. 2005, 75, 417–453. [Google Scholar] [CrossRef] [Green Version]
- Chmielewski, A.K. The global increase in the socioeconomic achievement gap, 1964 to 2015. Am. Sociol. Rev. 2019, 84, 517–544. [Google Scholar] [CrossRef]
- Yu, S.; Zhao, X. The negative impact of bullying victimization on academic literacy and social integration: Evidence from 51 countries in PISA. Soc. Sci. Humanit. Open. 2021, 4, 100151. [Google Scholar] [CrossRef]
- Arslan, G. School belonging in adolescents: Exploring the associations with school achievement and internalizing and externalizing problems. Educ. Child. Psychol. 2019, 36, 22–33. [Google Scholar] [CrossRef]
- Bond, L.; Butler, H.; Thomas, L.; Carlin, J.; Glover, S.; Bowes, G.; Patton, G. Social and school connectedness in early secondary school as predictors of late teenage substance use, mental health, and academic outcomes. J. Adolesc. Health 2007, 40. [Google Scholar] [CrossRef]
- Sampasa-Kanyinga, H.; Hamilton, H.A. Does socioeconomic status moderate the relationships between school connectedness with psychological distress, suicidal ideation and attempts in adolescents? Prev. Med. 2016, 87, 11–17. [Google Scholar] [CrossRef]
- Korpershoek, H.; Canrinus, E.T.; Fokkens-Bruinsma, M.; de Boer, H. The relationships between school belonging and students’ motivational, social-emotional, behavioural, and academic outcomes in secondary education: A meta-analytic review. Res. Pap. Educ. 2020, 35, 641–680. [Google Scholar] [CrossRef] [Green Version]
- Hulleman, C.S.; Barron, K.E. Motivation interventions in education: Bridging theory, research, and practice. In Handbook of Educational Psychology; Corno, L., Anderman, E., Eds.; Routledge: New York, NY, USA, 2016; pp. 160–171. [Google Scholar]
- Law, Y.K. The effects of cooperative learning on enhancing Hong Kong fifth graders’ achievement goals, autonomous motivation and reading proficiency. J. Res. Read. 2011, 34, 402–425. [Google Scholar] [CrossRef]
- O’Mara, A.J.; Marsh, H.W.; Craven, R.G.; Debus, R.L. Do self-concept interventions make a difference? A synergistic blend of construct validation and meta-analysis. Educ. Psychol. 2006, 41, 181–206. [Google Scholar] [CrossRef]
- Yeager, D.S.; Hanselman, P.; Walton, G.M.; Murray, J.S.; Crosnoe, R.; Muller, C.; Tipton, E.; Schneider, B.; Hulleman, C.S.; Hinojosa, C.P.; et al. A national experiment reveals where a growth mindset improves achievement. Nature 2019, 573, 364–369. [Google Scholar] [CrossRef] [Green Version]
- Destin, M.; Hanselman, P.; Buontempo, J.; Tipton, E.; Yeager, D.S. Do student mindsets differ by socioeconomic status and explain disparities in academic achievement in the United States? AERA Open 2019, 5, 2332858419857706. [Google Scholar] [CrossRef] [PubMed]
- Castleman, B.; Goodman, J. Intensive college counseling and the enrollment and persistence of low-income students. Educ. Financ. Policy 2018, 13, 19–41. [Google Scholar] [CrossRef]
- Chiapa, C.J.; Garrido, S.P. The effect of social programs and exposure to professionals on the educational aspirations of the poor. Econ. Educ. Rev. 2012, 31, 778–798. [Google Scholar] [CrossRef] [Green Version]
- Merisuo-Storm, T.; Soininen, M. Interesting reading materials and exercises encourage also reluctant boys to read. Procedia Soc. Behav. Sci. 2014, 116, 2583–2588. [Google Scholar] [CrossRef] [Green Version]
- Ramírez-Leyva, E.M. Encouraging reading for pleasure and the comprehensive training for readers. Investig. Bibliotecol. 2015, 30, 93–116. [Google Scholar] [CrossRef]
- Gaffney, H.; Farrington, D.P.; Ttofi, M.M. Examining the effectiveness of school-bullying intervention programs globally: A meta-analysis. Int. J. Bullying Prev. 2019, 1, 14–31. [Google Scholar] [CrossRef] [Green Version]
- Wachs, S.; Bilz, L.; Niproschke, S.; Schubarth, W. Bullying intervention in schools: A multilevel analysis of teachers’ success in handling bullying from the students’ perspective. J. Early Adolesc. 2019, 39, 642–668. [Google Scholar] [CrossRef]
- Darling-Hammond, L.; Cook-Harvey, C.M. Educating the Whole Child: Improving School Climate to Support. Student Success; Learning Policy Institute: Palto Alto, CA, USA, 2018. [Google Scholar]
- Noble-Carr, D.; Barker, J.; McArthur, M.; Woodman, E. Improving practice: The importance of connections in establishing positive identity and meaning in the lives of vulnerable young people. Child. Youth Serv. Rev. 2014, 47, 389–396. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine Learning Models | Tweaked Hyperparameters | Optimized Value for the Hyperparameters |
|---|---|---|
| SVM | Kernel = polynomial, radial basis function, c = 0.1, 1, 10 | Kernel = radial basis function, c = 1.0 |
| Logistic Regression | c = 0.001, 0.01, 0.1, 10, 100, 1000 | c = 0.01 |
| Multilayer Perceptron | Hidden layers = (32, 32), (32, 32, 16), (32, 32, 32) Activation function = sigmoid, tanh, relu Learning rate = 0.01, 0.001, 0.0001 | Hidden layers = (32, 32, 32) Activation function = sigmoid Learning rate = 0.0001 |
| Gradient Boosting Classifier | n_estimators = 6, 8, 10, 12, 14, 16, 18, 20 | n_estimators = 20 |
| Random Forest | n_estimators = 6, 8, 10, 12, 14, 16, 18, 20 | n_estimators = 20 |
| Ada Boost | n_estimators = 6, 8, 10, 12, 14, 16, 18, 20 | n_estimators = 20 |
| kNN | k = 3, 5, 6 | k = 7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bernardo, A.B.I.; Cordel, M.O., II; Lucas, R.I.G.; Teves, J.M.M.; Yap, S.A.; Chua, U.C. Using Machine Learning Approaches to Explore Non-Cognitive Variables Influencing Reading Proficiency in English among Filipino Learners. Educ. Sci. 2021, 11, 628. https://doi.org/10.3390/educsci11100628
Bernardo ABI, Cordel MO II, Lucas RIG, Teves JMM, Yap SA, Chua UC. Using Machine Learning Approaches to Explore Non-Cognitive Variables Influencing Reading Proficiency in English among Filipino Learners. Education Sciences. 2021; 11(10):628. https://doi.org/10.3390/educsci11100628
Chicago/Turabian StyleBernardo, Allan B. I., Macario O. Cordel, II, Rochelle Irene G. Lucas, Jude Michael M. Teves, Sashmir A. Yap, and Unisse C. Chua. 2021. "Using Machine Learning Approaches to Explore Non-Cognitive Variables Influencing Reading Proficiency in English among Filipino Learners" Education Sciences 11, no. 10: 628. https://doi.org/10.3390/educsci11100628