1. Introduction
Over the past decades, the prevalence of criminal activity in Africa has skyrocketed, becoming a major social problem impeding the region’s development. As economies transition from traditional to contemporary ways of living in order to experience socioeconomic and cultural changes, it is predicted that changes in criminal activities will occur. At the same time, this region is suffering from a high level of unemployment, income inequality, and low growth. This poses a question: Is a worsening labor market a breeding ground for crime? Does having a legitimate job reduce one’s willingness to offend? Does the worsening of income inequality necessarily lead to crime? These basic questions are ubiquitous throughout the developing world, and policymakers must consider first reference theory for help. As mentioned earlier, African countries suffer from a number of issues, such as high levels of unemployment and income inequality, with high crime rates.
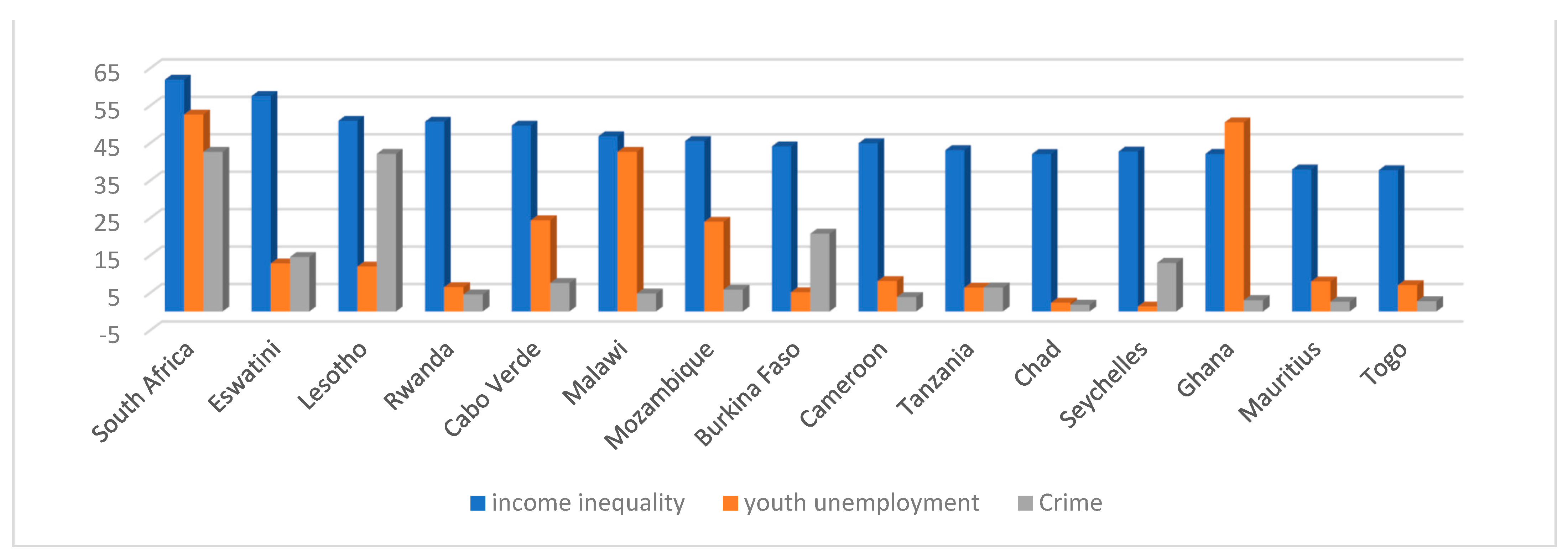
Figure 1 graphically demonstrates the mean Gini coefficient, youth unemployment, and crime covering the period (1994–2019) for 15 African countries.
The graph demonstrates and supports the argument that African countries suffer the most from these global issues, as most countries have a mean Gini coefficient of about 35 points, while the mean of youth unemployment in countries such as South Africa, Malawi, and Ghana is above 35%. In other countries, it is between 10% and 30%, while in others, it is below 10%. The crime rates, especially the murder rate, are high in countries with a high level of income inequality, while they are also high in countries with a high level of youth unemployment. This raises concerns about which socioeconomic issues (income inequality and unemployment) contribute to high crime rates. Are low growth and poor economic development in these countries the drivers of these socioeconomic issues? Finding answers to these questions will help policymakers in African economies to understand the sources of crime in these countries. These studies seek to shed light on the issue by identifying the major contributors to Africa’s crime rate using machine learning (ML).
So far, there has been controversy in both theoretical predictions and empirical research on the impact of unemployment and income inequality on crime. Theories such as the strain hypothesis proposed by
Merton (
1938) posit that failure to attain material success (usually characterized by a lack of jobs) can frustrate individuals ranking low in the social structure due to economic hardship, thereby breeding retaliatory crime. As a result, a failure by an individual to secure a legitimate job can breed anger, especially when the disadvantaged group finds themselves in the midst of prosperous individuals. This frustration, in turn, may serve as an incentive for economically underprivileged people to commit criminal offenses. After 30 years,
Becker (
1968), later supported by
Ehrlich (
1975) in what became known as Becker’s economic theory of crime, viewed this relationship from an economic standpoint, which was profoundly different from the strain theory. Their logic is based on the assumption that individuals tend to commit crimes when the perceived benefits outweigh the penalties.
Furthermore, and more crucially, economists emphasize that unemployment means a lack of genuine work in the labor market. A lack of a legitimate job decreases the opportunity costs of committing a crime, which drives individuals to participate in illegal activity. As a result, economists, unlike sociologists, think unemployment correlates positively with crime. A further contribution to this matter is found in the criminologists’ school of thought, which holds the view that unemployment negatively correlates with crime. They argue that unemployment implies fewer crime victims and fewer stolen products (
Felson and Cohen 1980;
Cantor and Land 1985,
2001). Precisely, when unemployment rises, the number of individuals from whom criminals may steal decreases; hence, crime is considered a negative consequence of unemployment. They also say unemployment provides additional protection since unemployed individuals spend more time safely indoors and caring for their property. However, the present literature contradicts whether unemployment and income inequality directly or indirectly affect crime. The existing literature is vast and contains numerous conflicting results, with some studies finding the strain theory and Becker’s economic theory of crime appropriate (
Fajnzylber et al. 2002;
Lobonţ et al. 2017;
Costantini et al. 2018;
Mazorodze 2020;
Kujala et al. 2019;
Ayhan and Bursa 2019;
Siwach 2018;
Anser et al. 2020;
Goh and Law 2021), while others leaned more towards the criminologists’ view (
Felson and Cohen 1980;
Cantor and Land 1985,
2001;
Anwar et al. 2017;
Zaman 2018), and yet others find inconclusive results (
Maddah 2013).
The current study contributes to the existing body of knowledge on the issue. Following the work documented by
Mazorodze (
2020), the emphasis was on southern African provinces, notably KwaZulu-Natal. He used local municipality-level data observed from 2006–2017 to support the argument that unemployment leads to crime. Our study seeks to extend
Mazorodze’s (
2020) argument by considering the impact of income inequality on the system; it has become evident from the literature that income inequality may be correlated with crime. Furthermore, we want to include educational and age-dependency variables because they are thought to be highly correlated with crime rates, just like in his study. In a nutshell, we aim to examine the crime response to shock in these variables in African countries.
The current study aims to fill a gap in the literature by incorporating and examining the impact of income inequality and unemployment on educational and age-dependence variables and their effects on crime in African emerging markets, which most previous studies have ignored, as well as by determining the measure contributor of crime between income inequality and unemployment in these countries. The goal of this study is to shed light on an ongoing debate in the literature by building a balanced panel data set of 15 African emerging markets from 1994 to 2019, using the panel vector autoregressive (PVAR) technique as well as the panel generalized method of moments (GMM), fixed-effect (FE) estimators, and machine learning (ML). The PVAR will test the following hypotheses: (1) crime does not respond to a shock of income inequality; (2) crime does not respond to a shock of unemployment in these countries. The ML will be utilized to test the following hypotheses: (3) unemployment is the main contributor to crime in these countries.
A PVAR model for these economies is created based on the variety of measured flaws. Instead of focusing on a single object, this model allows us to investigate the complex interaction of numerous items simultaneously. This study, for example, examined the interactions that occurred between the 15 countries we picked due to their significant commerce. The panel VAR models that handle the dynamics of several entities considered simultaneously are critical for this sort of research. These techniques are generally more comprehensive than ordinary VAR models since they not only analyze variable relationships intuitively, as a standard VAR model but also include a cross-sub-sectional structure. Therefore, this enables us to distinguish between common and specific components, whether in terms of nations, variables, time periods, and so on, and then use this structural knowledge to improve estimation accuracy. It becomes significantly more resilient when dealing with data of varying quality and often of short duration. Static panel techniques or interaction effects do not explain these traits. Ultimately, the reason for conducting this research was not a lack of research investigating the effect of income inequality and unemployment on crime within those countries but rather the fact that this correlation may differ significantly from that published in the literature due to differences in the smoothness of industrial prosperity as well as macroeconomic policies executed.
The remainder of the paper is arranged as follows:
Section 2 briefly reviews the literature on the issue, while
Section 3 provides an outline of the model.
Section 4 analyzes the PVAR, GMM, FE, and machine learning outcomes, while
Section 5 gives concluding remarks and explores policy implications.
3. Research Methods and Data Used for the Study
To fulfill the study’s goal, we used a panel of 15 rising African markets from 1994 to 2019. His research focuses on these nations because they have high rates of violent crime, unemployment, and income inequality. Variables indicated in the literature were used in this investigation. We utilized two variables in our empirical research to quantify income inequality and unemployment. One of the most problematic elements of working on crime-related issues is the fact that crime data is usually measured with inaccuracy due to underreporting, causing the observed data to be an underestimate of the true levels of crime. Fear of victimization and distrust in the police have driven some crime victims to opt not to disclose crimes. Technically, the accuracy of crime statistics is determined by three factors: community desire to report crime cases, police efficacy, and police willingness to record all reported instances. To account for the lack of crime data, we selected murder cases (crime) as a proxy for crime because this sort of crime is not as underreported as other types of violent crime (rape, common assault, burglary at residential premises, and robbery with aggravating circumstances). To assess income inequality, we used the Gini coefficient (INE) and pre-tax national income (TOP10) (
Nilsson 2004), whereas to capture unemployment in our study, we used two types of unemployment, namely youth unemployment (YOU) and male unemployment (MUN). This is because, while unemployment may reduce legal returns from work, the proclivity to engage in criminal activities increases. Male unemployment is featured in the literature, which asserts that males are the perpetrators of violent crime on a global scale (
UNODC 2019). We adjust for educational factors such as secondary (EDS) enrollment in our model to determine the impact of education on the choice to engage in criminal activities. According to the literature, increasing the ratio of school achievement is projected to lower crime rates (
Witt et al. 1998). The age dependency ratio indicator (ADRY) is then used to adjust for the proportion of individuals of working age as well as the percentage of employed persons in relation to the overall population. The high percentage of age dependence is said to have aided crime. We use GDP per capita income (GDPp) to adjust for economic development and growth. Finally, we take into account population growth (EDT). According to the urban scaling theory, the number of crimes committed as a function of a city’s population size may follow a super-linear relationship. The variables came from many sources, including the World Development Indicators, SWIID, and the World Inequality Database. These models were estimated using the Rstudio and Stata15 software packages.
Before a detailed presentation of the PVAR, GMM, and FE, the following section will give a brief explanation of machine learning as it aims to find the variables that have a strong impact on crime between income inequality and unemployment.
3.1. Random Forest Model
Random forest (RF) was first described by
Breiman (
2001) as a collaborative method for building forecast models. The phrase “forest” means a series of decision trees that act to classify weak individuals who strongly influence the dependent variable. An important task in many econometrician fields is the perdition of a variable response based on the set of variables. In many cases, RF has been used by statisticians to find important predictor variables (
Breiman 2004;
Biau et al. 2008;
Meinshausen 2006;
Biau 2012). However, the RF not only aims to make the accurate prediction of the response, but it also aims to identify candidates in a group of variables that are most important in predicting and providing the variable importance measures; variates such as extra trees have been used as a major data-analyses tool employed with achievements in various scientific areas (
Geurts et al. 2006) and random forests (
Breiman 2001).
The RF is a machine learning algorithm; therefore, the RF is a collection of tree predictors developed firstly by growing the tree by splitting the training data sets at each node according to the value of one from a randomly selected subset of variables using classification and regression tree, which is known as growing phase (seven). Next, randomly select the subset of the learning data sets, which is a training set for growing the tree known as the bootstrap phase. Each tree is expanding to the largest extent possible. The growing phases and the bootstrap require the input of random quantities. These quantities are assumed to be independent among trees and are identically distributed. Hence, each tree can be seen as a sample independent of the collaboration of all tree predictors for a given learning set. For hypothesizing, the occurrence runs through each tree in a forest down to the terminal node, which assigns its class with a maximum amount of votes for presenting the RF with the probabilistic interpretation of the forest assumption.
3.1.1. Feature Importance
In an RF, feature importance is used as a way of describing how much impact a feature has on the model-making decision. In this study for feature importance, the author will rely on the Gini impurity, which measures the chance that a new variable will be correct when randomly classified. This feature is bound by zero and one where one denotes that it is guaranteed that it will be wrong, while zero simply denotes that it is impossible to be wrong.
The Gini impurity of the node is estimated using this equation:
In this case, is the probability of the record being assigned to class and is a predicted category of the random class.
3.1.2. Gini Importance
The Gini importance, in this case, is a total reduction of the Gini impurity that comes from a feature, where it is calculated as a weighted sum of the indifference in Gini impurity among the node and its antecedents. Therefore, it takes this form:
3.2. Panel Vector Auto Regression (PVAR) Approach
Prior to actually estimating the PVAR model, we will use the cross-sectional dependency (CD) test,
Friedman’s (
1937) statistic,
Frees’ (
1995) test statistic, and the Pedroni cointegration test to rule out the potential of cross-sectional dependence. Panel stationarity is as important in panel data analysis as it is in time series analysis. As a consequence, the Im–Peseran–Shin (
Im et al. 2003) test will be employed, and the Harris–Tzavalis (
Harris and Tzavalis 1999) test will be used for robustness. In African emerging economies, we employed a balance panel VAR approach to capture the dynamic effect of income disparity and unemployment on crime. We followed
Maddah’s (
2013) lead and used structural VAR in Iran from 1979 to 2007. Our panel VAR model is a system of equations comprised of two models, each with seven endogenous variables, as stated in
Section 3. The general model is as follows:
where
is a (7 × 1) vector of endogenous variables for year
and country
, which include the murder cases to measure crime (Crime), income inequality (INE), youth unemployment (YOU), the secondary (EDS) enrolment ratio to capture education, the age dependency ratio indicator (ADR), population growth (EDT), and real per capita gross domestic product (GDPp),
is a (7 × 1) vector of a constant,
is a (7 × 7) matrix of coefficient estimates, and
is a (7 × 1) vector of system innovations, while
is a cross-sectional identifier, and
is selected though observing the value of the Schwarz Bayesian Criterion (SBC) and Akaike information criterion (AIC), which is the optimal lag length of each variable. PVAR analysis selecting the appropriate lag order is among the first stages which need to be undertaken, both in a moment condition and panel-VAR specification. Therefore, PVAR analysis is reliant upon appropriate lag selection.
3.3. Generalized Method of Moments and Fixed-Effect Models
To investigate the relationship between income inequality, unemployment, and crime, we apply the difference generalized method of moments (Difference GMM) (
Arellano and Bond 1991;
Blundell and Bond 1998) and fixed-effect models (FE). We chose the Difference-GMM because we wanted to address the issue of individual effects. The dependent variable will also be included as a lagged explanatory variable in the GMM estimator. Because this research may suffer from the endogeneity problem, this estimating technique is used. Furthermore, the possibility of multiple causations cannot be ruled out for several of our control variables. Finally, there are two sorts of instruments in the GMM estimator: external and internal. In the literature, it has been suggested that internal instruments are preferable to external instrumentation for the GMM system. This is due to the fact that choosing an external instrument for the GMM is the most difficult task of the estimation. Therefore, internal instruments, such as lag values of regressors, will be the instruments for the data that the researcher is working with. For the current investigation, we use our capabilities to construct instruments domestically. As a result, endogenous variables are instrumented by their lagged values. In a nutshell, this means that the tool for this analysis must originate within the following:
where
indicates the time dimensions and cross-section and the time dimensions of the panel, correspondingly. Whereas
and
take for the time and fixed individual effects, respectively, correspondingly,
is the vector of control variables, and the errors term is denoted by
. Equation (15) investigates the influence of income inequality on crime, whereas Equation (16) investigates the impact of unemployment on crime. Under the entire set of random-effects assumptions, the Hausman test will be utilized to choose between FE and random-effects (RE) estimates. The test findings indicate that the RE assumption is rejected; hence, the FE estimations are employed. To prevent biased estimates due to the lack of other significant explanatory factors, we converted Equations (15) and (16) into a dynamic model by including a lagged term of crime based on the static model, as shown in Equations (17) and (18). In this study, the dynamic panel models are estimated using differential GMM:
5. Conclusions
The extant empirical literature is filled with disputes over the impact of income inequality and unemployment on crime in both developed and developing countries. The current study provides a substantial positive relationship between income inequality, unemployment, and crime in African economies. The results reveal that an unanticipated 1% increase in income inequality and youth unemployment has a favorable effect on crime. For robustness and sensitivity, we used multiple measurements of income inequality (pre-tax national income top 10% from the world inequality database), unemployment (male unemployment rate), and even a different approach (S-GMM and FE). Even by these measures, we yield the same results, as we found that when income inequality increases by 1%, crime increases by 5.80%. While on the other hand, a 1% increase in male unemployment results in a 2.98% increase in crime. These findings were further supported by the FE. The findings are theoretically conceivable and in line with previous research on income inequality and crime, such as
Maddah (
2013) for Iran,
Lobonţ et al. (
2017) for Romania,
Costantini et al. (
2018) for the United States,
Ngozi and Abdul (
2020) for a panel of 38 Africans, and
Goh and Law (
2021) for Brazil. Moreover, with unemployment-crime, our findings support the findings reported by
Costantini et al. (
2018) using panel data from the US,
Mazorodze (
2020) focusing on the southern African provinces, particularly KwaZulu-Natal,
Kujala et al. (
2019) for some countries in Europe,
Ayhan and Bursa (
2019) for a panel of 28 European Union countries and
Siwach (
2018) for New York State.
We then use machine learning to answer the question: which socioeconomic issues between income inequality and unemployment contribute to high crime rates, specifically in African economies? The results pointed to income inequality as the major contributor to high crime in African countries, as we found that it contributes about 61.04% to crime, while unemployment contributes about 44.26% to crime.
We expanded the argument by including educational variables, such as school enrolment at secondary levels in the system. The results show that crime responds negatively to an unexpected 1% shock on school entertainment through enrolment at the secondary y level. This was further supported by the results generated by the S-GMM and FE.
The use of real GDP per capita to measure the quality of life or economic development was included in the conclusion that low growth and poor economic development in these nations are the root causes of these social concerns. The results show that crime responds negatively to an unexpected 1% rise in per capita income (economic development), supporting the importance of raising living standards in these countries, as it has been demonstrated to reduce crime. The findings are theoretically sound and consistent with recent research, such as the Hong Kong study by
Chen and Zhong (
2020). Population growth was found to increase crime levels in all models. The study extends the argument in this area by controlling for age dependence. In all models, crime responds negatively to an unexpected 1% shock in age dependency. This was further supported by the results generated from the S-GMM and FE models. Similar findings were documented by
Galbraith (
1998).
From a policy standpoint, the current study informs the government that some measures are more suited to resolving concerns about income inequality and unemployment (income policy or fiscal policy). As a result, additional measures aimed at income distribution are required, as this may reduce economic disparity while also lowering crime rates. We suggest that future research should focus on a comparative study where this region is compared to Europe or other countries with similar characteristics. Furthermore, a study that aims to find the possibility of nonlinearity in the subject will have a significant contribution. Finally, the study that will seek to determine the reliance on policy regulation on this subject is significant. This is due to the fact that
Figure 1: “Graphic analysis of the mean Gini-index, youth employment, and crimes, 1994–2019.” From this figure, it is obvious that for individual countries, the dependencies between the studied indicators can have very significant differences.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





