
Forecasting by Combining Chaotic PSO and Automated LSSVR

Abstract
:1. Introduction
- Initialization of the parameters: This is due to the possibility that it is unaware of the location of the global minimum at which the prior optimization problem was resolved.
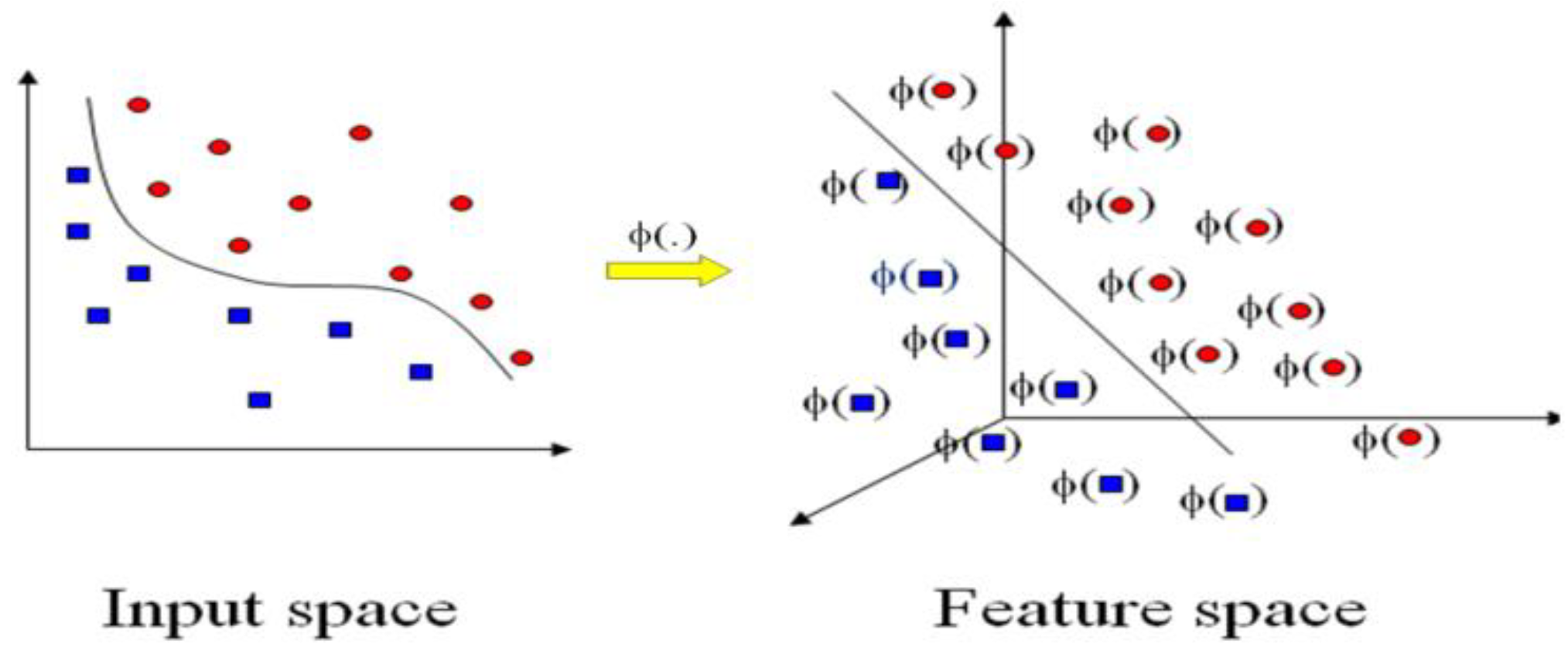
- Characteristic extract or the characteristic evolution component can typically accomplish the decrease in data dimensionality. Often, this has been accomplished using characteristic extract methods like principal component analysis (PCA). The PCA is ineffective for this study’s objectives since it also wants to produce highly precise predictive models, not just reduce the dimensionality of the data. Nevertheless, the PCA doesn’t take into account the link for variables of input and variables of reply throughout the data reduction process, making it challenging to create a model that is extremely precise. Furthermore, if the input variables’ dimensionality is really high, it might be challenging to interpret the main components that are produced by the PCA. On the other hand, for data sets with high dimensionality, the PSO has been shown to perform better than other methods [11]. A simplified LSSVR model with improved generalization can be created by selecting more information for any data set provided when employing the fewest characteristics possible throughout the characteristic evolution phase.
- Another PSO is employed in the parameter evolution component to optimize the LSSVR’s parameters. Generally, LSSVR generalization ability is governed by the type of kernel, parameters’ kernel, and parameter’s upper bound. Every form of the kernel has benefits and drawbacks, hence a mixed kernel makes sense [12,13,14]. Additionally, computational time and complexity in the training of the algorithm equals the total execution generations multiplied by the number of total solutions and multiplied by the time complexity of the update for each solution.
- The CP-LSSVR is used to initialize the parameters for the parameters initialization issue of LSSVR applications.
- A binary PSO is utilized for feature selection in the input data to improve the model’s interpretability for the issue of requiring LSSVR to preprocess the input characteristics if the dimensions of input space or input characteristics are quite vast.
- A third PSO is applied to optimize its parameters to boost the LSSVR’s capacity for normalization.
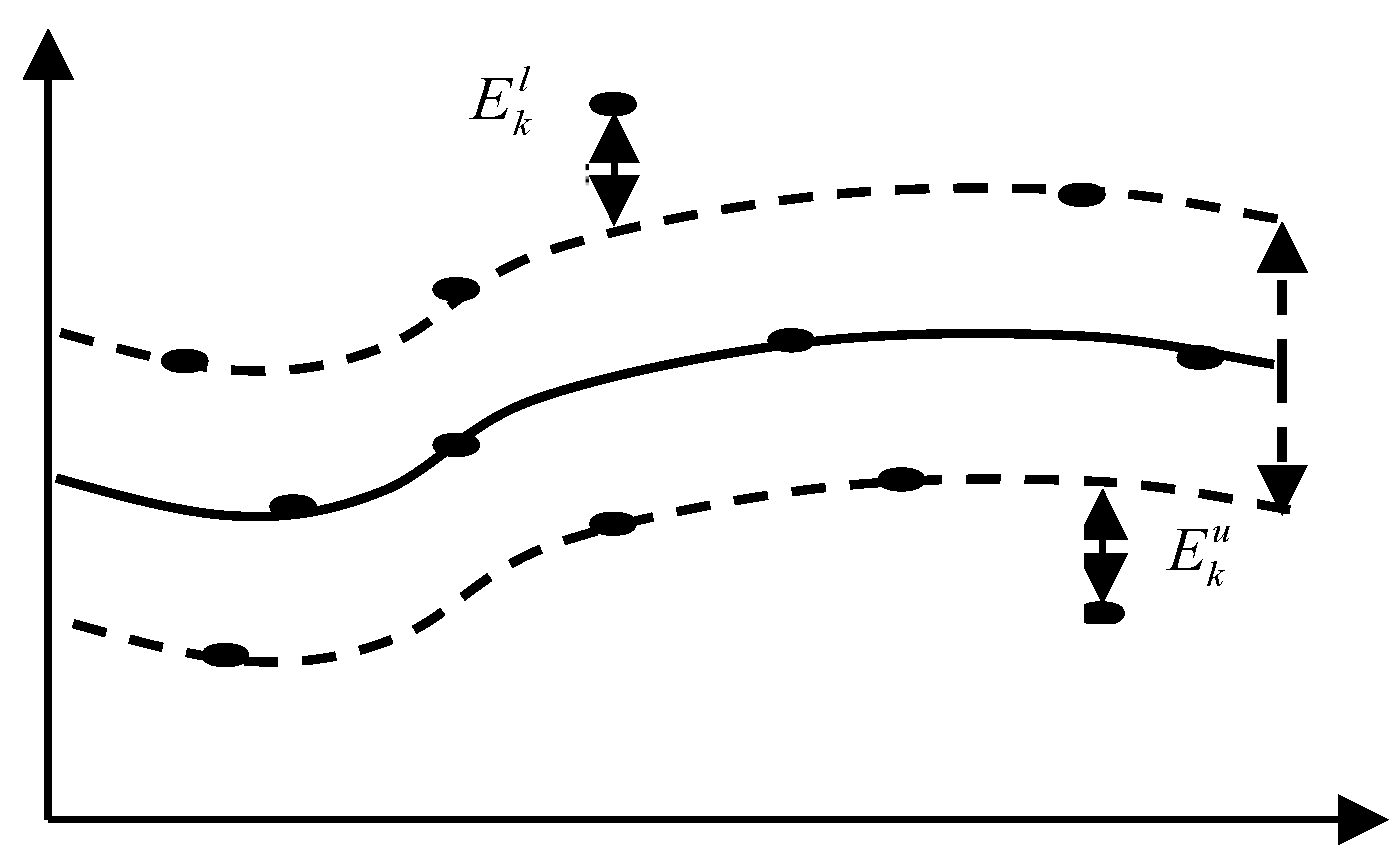
2. SVR and LSSVR
3. LSSVR Based on Chaotic Particle Swarm Optimization (CPSO) Algorithm
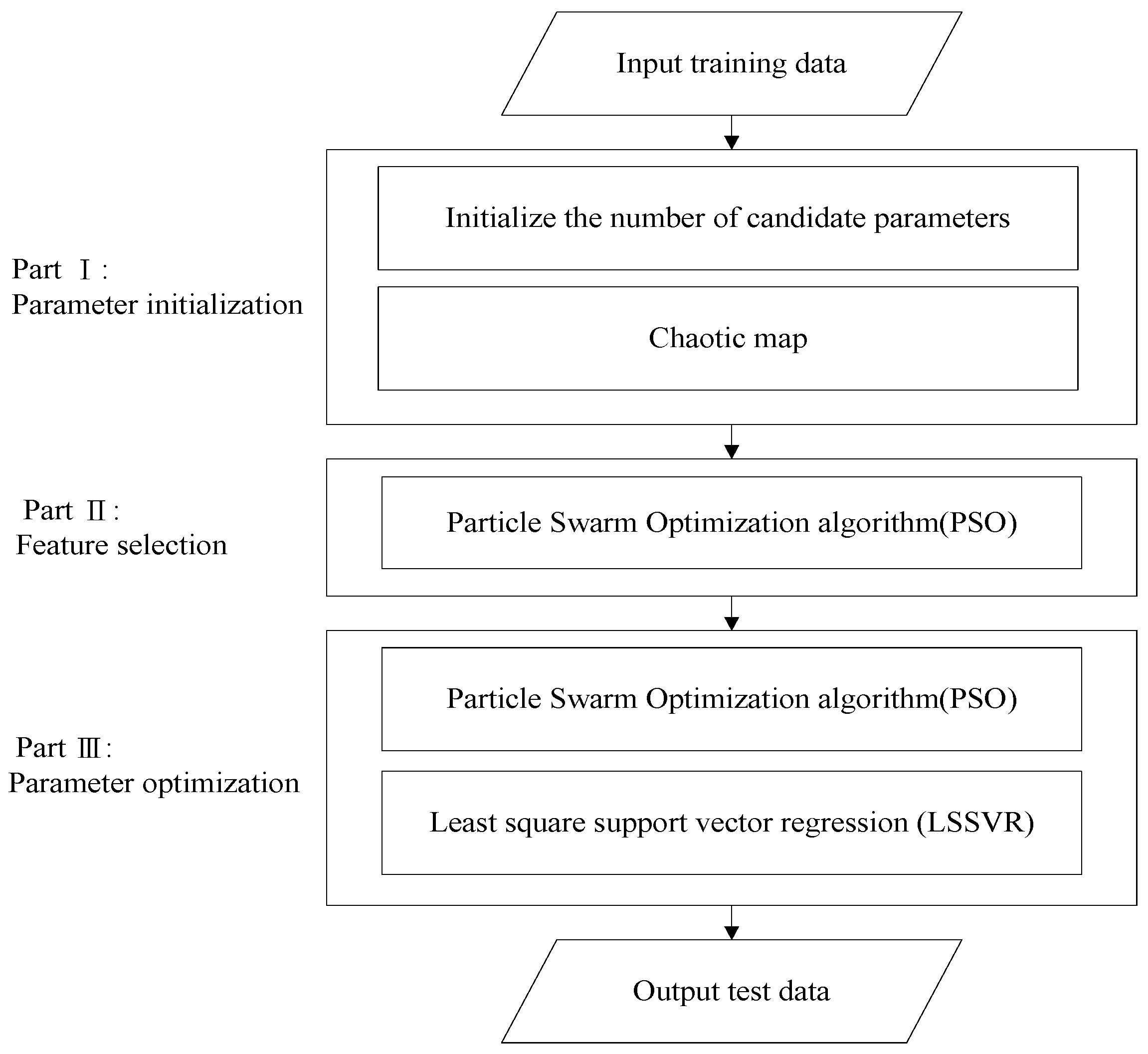
3.1. Automatic LSSVR Learning Paradigm
- Parameters initialization.
- It is required for LSSVR to preprocess the input characteristics if the dimensions of input space or input characteristics are quite vast, in order to improve the interpretability of the LSSVR-based forecasting model.
- This work adopts a mixed kernel model to get beyond the effect of kernel types because LSSVR normalization ability is frequently governed via (a) kernel type. The next two things, however, heavily rely on the researchers’ artistic ability. (b) kernel parameters: convex combination coefficients (λ1, λ2, λ3), and kernel parameters (g, σ). C is the upper bound parameter.
3.2. Chaotic Sequences-Based Parameters Initialization
- Step 0. Generated by Logistic map chaotic sequence by Equation (15), following:
- Step 1. For the m particles in the D-dimensional space, the first generates a random initial value m:
- Step 2. Chaotic sequence to the initial value of m-Equation (15). At that point, m will be the trajectory after Z iterations.
- Step 3. Substituting the chaotic trajectory of the article from m in the selected Z iteration value into the Equation (16). One can compute
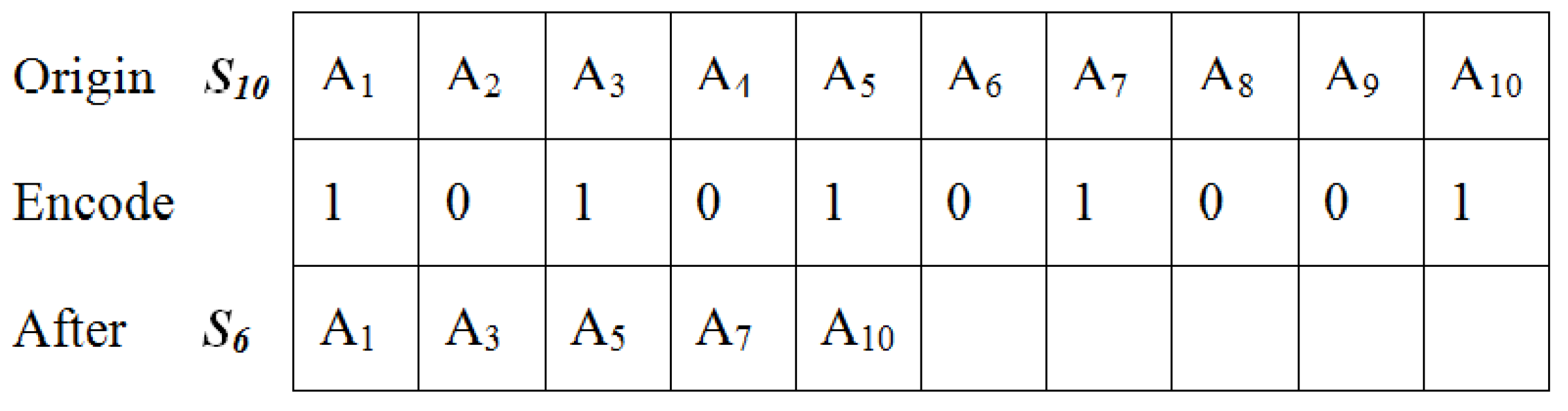
3.3. PSO-Based Input Features Evolution
- To eliminate some less-important characteristics for decreasing the input characteristics’ size and enhance forecasting capability.
- Additionally, it is to pinpoint several crucial characteristics that influence model performance, hence bringing down model complexity.
| Algorithm 1: PSO—Based Input Features Evolution |
| Goal: Reducing (1-hit ratio) Input: training data set. Output: The PSO-LSSVR’s characteristics set. BEGIN Establish the population While (number of generations, or the halting requirement is not fulfilled) For i = 1 (particles’ number) When one’s fitness level Xk exceeds another’s p-best, next update p-bestk = Xk For υ belongs to neighborhood of Xk If fitness Xυ is higher than fitness of g-best, Next update g-best = Xυ then υ Every dimension g when rand() < then else Next g Next k Next generation till the ending criteria END |
3.4. PSO-Based Parameters Optimization
4. Experiment Findings
4.1. Benchmark Datasets and Compared Approaches
4.2. Characteristic Selection Using PSO
- Step 1: Use the initial value that the chaotic map process created in step 1 (for instance, the dataset Auto-Mpg Figure 5).
- Step 2: Assess the fitness function.
- Step 3: Before MCN.set , choose the number of input characteristics using Binary PSO.
- Step 4: Selected training data (k = 50, 60,…, 100) are used to train the LSSVR with PSO.
- Step 5: The trained LSSVR was tested for a set size.
4.3. PSO-Based Parameter Optimization for CP-LSSVR
4.4. Comparisons and Discussion
- The proposed CP-LSSVR performs best among the comparable methodologies for Servo in SSR/SST = 1.7869,
- SVR performs best among the comparable methodologies for Boston Housing Data in both SSE/SST = 0.1274 and SSR/SST = 0.9032, Servo in SSE/SST = 0.1315, Concrete Compressive Strength in SSR/SST = 0.9425, Auto Price in SSE/SST = 0.1278.
- LSSVR performs best among the comparable methodologies for Auto-Mpg in both SSE/SST = 0.1064 and SSR/SST = 0.9897, machine CPU in both SSE/SST = 0.1017 and SSR/SST = 0.9877, Concrete Compressive Strength in SSE/SST = 0.1226, Auto Price in SSR/SST = 0.9952.
- The CP-LSSVR has an SVR feature that can get beyond some of the BP-neural network’s drawbacks, like overfitting and local minima.
- The chaotic PSO parameter optimization method can help improve the normalization effect. Fourth, the character development in the CP-LSSVR can quickly identify important factors that influence model performance, improving the LSSVR’s interpretability.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vapnik, V.N. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Yeh, W.C.; Jiang, Y.; Tan, S.Y.; Yeh, C.Y. A New Support Vector Machine Based on Convolution Product. Complexity 2021, 2021, 9932292. [Google Scholar] [CrossRef]
- Ma, J.; Xia, D.; Guo, H.; Wang, Y.; Niu, X.; Liu, Z.; Jiang, S. Metaheuristic-based support vector regression for landslide displacement prediction: A comparative study. Landslides 2022, 19, 2489–2511. [Google Scholar] [CrossRef]
- Samantaray, S.; Das, S.S.; Sahoo, A.; Satapathy, D.P. Monthly runoff prediction at Baitarani river basin by support vector machine based on Salp swarm algorithm. Ain Shams Eng. J. 2022, 15, 101732. [Google Scholar] [CrossRef]
- Bansal, M.; Goyal, A.; Choudhary, A. A comparative analysis of K-Nearest Neighbour, Genetic, Support Vector Machine, Decision Tree, and Long Short Term Memory algorithms in machine learning. Decis. Anal. J. 2022, 3, 100071. [Google Scholar] [CrossRef]
- Song, X.F.; Zhang, Y.; Gong, D.W.; Gao, X.Z. A Fast Hybrid Feature Selection Based on Correlation-Guided Clustering and Particle Swarm Optimization for High-Dimensional Data. IEEE Trans. Cybern. 2021, 52, 9573–9586. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, Y.; Gao, X.; Gong, D.; Song, X.; Guo, Y.; Wang, J. A federated feature selection algorithm based on particle swarm optimization under privacy protection. Knowl. Based Syst. 2022, 260, 110122. [Google Scholar] [CrossRef]
- Liu, X.; Wang, G.G.; Wang, L. LSFQPSO: Quantum particle swarm optimization with optimal guided Lévy flight and straight flight for solving optimization problems. Eng. Comput. 2022, 38, 4651–4682. [Google Scholar] [CrossRef]
- Wei, C.L.; Wang, G.G. Hybrid Annealing Krill Herd and Quantum-Behaved Particle Swarm Optimization. Mathematics 2020, 8, 1403. [Google Scholar] [CrossRef]
- You, G.R.; Shiue, Y.R.; Yeh, W.C.; Chen, X.L.; Chen, C.M. A weighted ensemble learning algorithm based on diversity using a novel particle swarm optimization approach. Algorithms 2020, 13, 255. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks (IJCNN), Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Hsieh, T.J.; Hsiao, H.F.; Yeh, W.C. Mining financial distress trend data using penalty guided support vector machines based on hybrid of particle swarm optimization and artificial bee colony algorithm. Neurocomputing 2012, 82, 196–206. [Google Scholar] [CrossRef]
- Hsieh, T.J.; Yeh, W.C. Knowledge discovery employing grid scheme least squares support vector machines based on orthogonal design bee colony algorithm. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2011, 41, 1198–1212. [Google Scholar] [CrossRef] [PubMed]
- Mao, Y.; Wang, T.; Duan, M.; Men, H. Multi-objective optimization of semi-submersible platforms based on a support vector machine with grid search optimized mixed kernels surrogate model. Ocean Eng. 2022, 260, 112077. [Google Scholar] [CrossRef]
- Li, M.; Yang, S.; Zhang, M. Power supply system scheduling and clean energy application based on adaptive chaotic particle swarm optimization. Alex. Eng. J. 2022, 61, 2074–2087. [Google Scholar] [CrossRef]
- Silva-Juarez, A.; Rodriguez-Gomez, G.; Fraga, L.G.d.l.; Guillen-Fernandez, O.; Tlelo-Cuautle, E. Optimizing the Kaplan–Yorke Dimension of Chaotic Oscillators Applying DE and PSO. Technologies 2019, 7, 38. [Google Scholar] [CrossRef] [Green Version]
- Smola, A.J.; Scholkopf, B. A Tutorial on Support Vector Regression; NeuroCOLT Tech. Rep. NC-TR-98-030; Royal Holloway College, Univ.: London, UK, 1998. [Google Scholar]
- Jiao, L.; Bo, L.; Wang, L. Fast sparse approximation for least squares support vector machine. IEEE Trans. Neural Netw. 2007, 18, 685–697. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Gestel, T.V.; Brabanter, J.D.; Moor, B.D.; Vandewalle, J. Least Squares Support Vector Machines; World Scientific: Singapore, 2002. [Google Scholar]
- Schölkopf, B. Support Vector Learning. Ph.D. Thesis, Technische Universität, Berlin, Germany, 1997. [Google Scholar]
- Yu, L.; Chen, H.; Wang, S.; Lai, K.K. Evolving Least Squares Support Vector Machines for Stock Market Trend Mining. IEEE Trans. Evol. Comput. 2009, 13, 87–102. [Google Scholar]
- Yeh, W.C.; Yeh, Y.M.; Chang, P.C.; Ke, Y.C.; Chung, V. Forecasting wind power in the Mai Liao Wind Farm based on the multi-layer perceptron artificial neural network model with improved simplified swarm optimization. Int. J. Electr. Power Energy Syst. 2014, 55, 741–748. [Google Scholar] [CrossRef]
- Yeh, W.C. A squeezed artificial neural network for the symbolic network reliability functions of binary-state networks. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2822–2825. [Google Scholar] [CrossRef]
- Yeh, W.C.; Yeh, Y.M.; Chiu, C.W.; Chung, Y.Y. A wrapper-based combined recursive orthogonal array and support vector machine for classific ation and feature selection. Mod. Appl. Sci. 2014, 8, 11. [Google Scholar]
- Chapelle, O.; Vapnik, V. Model selection for support vector machines. In Proceedings of the 13th Annual Conference on Neural Information Processing Systems (NIPS), Cambridge, MA, USA, 1 January 2000; pp. 230–236. [Google Scholar]
- Tu, C.J.; Chuang, L.Y.; Chang, J.Y.; Yang, C.H. Feature Selection using PSO-SVM. IAENG Int. J. Comput. Sci. 2007, 33, IJCS_33_1_18. [Google Scholar]
- UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/index.html (accessed on 11 January 2023).
- Staudte, R.G.; Sheather, S.J. Robust Estimation and Testing: Wiley Series in Probability and Mathematical Statistics; Wiley: New York, NY, USA, 1990. [Google Scholar]
- Bates, D.M.; Watts, D.G. Nonlinear Regression Analysis and its Applications; Wiley: New York, NY, USA, 1988. [Google Scholar]
- Zhou, J.; Zheng, W.; Wang, D.; Coit, D.W. A resilient network recovery framework against cascading failures with deep graph learning. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2022. [Google Scholar] [CrossRef]
- Yousefi, N.; Tsianikas, S.; Coit, D.W. Dynamic maintenance model for a repairable multi-component system using deep reinforcement learning. Qual. Eng. 2022, 34, 16–35. [Google Scholar] [CrossRef]
- Yeh, W.C. Novel Recursive Inclusion-Exclusion Technology Based on BAT and MPs for Heterogeneous-Arc Binary-State Networ k Reliability Problems. Reliab. Eng. Syst. Saf. 2023, 231, 108994. [Google Scholar] [CrossRef]
- Liu, T.; Ramirez-Marquez, J.E.; Jagupilla, S.C.; Prigiobbe, V. Combining a statistical model with machine learning to predict groundwater flooding (or infiltration) into sewer networks. J. Hydrol. 2021, 603, 126916. [Google Scholar] [CrossRef]
- Borrelli, D.; Iandoli, L.; Ramirez-Marquez, J.E.; Lipizzi, C. A Quantitative and Content-Based Approach for Evaluating the Impact of Counter Narratives on Affective Polarization in Online Discussions. IEEE Trans. Comput. Soc. Syst. 2021, 9, 914–925. [Google Scholar] [CrossRef]
- Su, P.C.; Tan, S.Y.; Liu, Z.Y.; Yeh, W.C. A Mixed-Heuristic Quantum-Inspired Simplified Swarm Optimization Algorithm for scheduling of real-time tasks in the multiprocessor system. Appl. Soft Comput. 2022, 1131, 109807. [Google Scholar] [CrossRef]
- Yeh, W.C.; Liu, Z.; Yang, Y.C.; Tan, S.Y. Solving Dual-Channel Supply Chain Pricing Strategy Problem with Multi-Level Programming Based on Improved Simplified Swarm Optimization. Technologies 2022, 10, 10030073. [Google Scholar] [CrossRef]
- Yeh, W.C.; Tan, S.Y. Simplified Swarm Optimization for the Heterogeneous Fleet Vehicle Routing Problem with Time-Varying Continuous Speed Function. Electronics 2021, 10, 10151775. [Google Scholar] [CrossRef]
- Bajaj, N.S.; Patange, A.D.; Jegadeeshwaran, R.; Pardeshi, S.S.; Kulkarni, K.A.; Ghatpande, R.S. Application of metaheuristic optimization based support vector machine for milling cutter health monitoring. Intell. Syst. Appl. 2023, 18, 200196. [Google Scholar] [CrossRef]
- Patange, A.D.; Pardeshi, S.S.; Jegadeeshwaran, R.; Zarkar, A.; Verma, K. Augmentation of Decision Tree Model Through Hyper-Parameters Tuning for Monitoring of Cutting Tool Faults Based on Vibration Signatures. J. Vib. Eng. Technol. 2022. [Google Scholar] [CrossRef]
- Yeh, W.C. A new branch-and-bound approach for the n/2/flowshop/αF+ βCmax flowshop scheduling problem. Comput. Oper. Res. 1999, 26, 1293–1310. [Google Scholar] [CrossRef]
- Yeh, W.C. Search for MC in modified networks. Comput. Oper. Res. 2001, 28, 177–184. [Google Scholar] [CrossRef]
- Yeh, W.C.; Wei, S.C. Economic-based resource allocation for reliable Grid-computing service based on Grid Bank. Future Gener. Comput. Syst. 2012, 28, 989–1002. [Google Scholar] [CrossRef]
- Hao, Z.; Yeh, W.C.; Wang, J.; Wang, G.G.; Sun, B. A quick inclusion-exclusion technique. Inf. Sci. 2019, 486, 20–30. [Google Scholar] [CrossRef]
- Yeh, W.C. Novel binary-addition tree algorithm (BAT) for binary-state network reliability problem. Reliab. Eng. Syst. Saf. 2021, 208, 107448. [Google Scholar] [CrossRef]
- Corley, H.W.; Rosenberger, J.; Yeh, W.C.; Sung, T.K. The cosine simplex algorithm. Int. J. Adv. Manuf. Technol. 2006, 27, 1047–1050. [Google Scholar] [CrossRef]
- Yeh, W.C. A new algorithm for generating minimal cut sets in k-out-of-n networks. Reliab. Eng. Syst. Saf. 2006, 91, 36–43. [Google Scholar] [CrossRef]
- Yeh, W.C.; He, M.F.; Huang, C.L.; Tan, S.Y.; Zhang, X.; Huang, Y.; Li, L. New genetic algorithm for economic dispatch of stand-alone three-modular microgrid in DongAo Island. Appl. Energy 2020, 263, 114508. [Google Scholar] [CrossRef]
- Yeh, W.C.; Chuang, M.C.; Lee, W.C. Uniform parallel machine scheduling with resource consumption constraint. Appl. Math. Model. 2015, 39, 2131–2138. [Google Scholar] [CrossRef]
- Lee, W.C.; Yeh, W.C.; Chung, Y.H. Total tardiness minimization in permutation flowshop with deterioration consideration. Appl. Math. Model. 2014, 38, 3081–3092. [Google Scholar] [CrossRef]
- Lee, W.C.; Chuang, M.C.; Yeh, W.C. Uniform parallel-machine scheduling to minimize makespan with position-based learning curves. Comput. Ind. Eng. 2014, 63, 813–818. [Google Scholar] [CrossRef]
- Bae, C.; Yeh, W.C.; Wahid, N.; Chung, Y.Y.; Liu, Y. A New Simplified Swarm Optimization (SSO) using Exchange Local Search Scheme. Int. J. Innov. Comput. Inf. Control 2012, 8, 4391–4406. [Google Scholar]
- Bajaj, N.S.; Patange, A.D.; Jegadeeshwaran, R.; Kulkarni, K.A.; Ghatpande, R.S.; Kapadnis, A.M. A Bayesian Optimized Discriminant Analysis Model for Condition Monitoring of Face Milling Cutter Using Vibration Datasets. J. Nondestruct. Eval. 2022, 5, 021002. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Data Sets | Observations | Training (100%) | Testing | Attributions |
|---|---|---|---|---|---|
| 1 | Boston Housing Data | 506 | 304 | 202 | 13 |
| 2 | Auto-Mpg | 398 | 239 | 159 | 8 |
| 3 | machine CPU | 209 | 125 | 84 | 6 |
| 4 | Servo | 167 | 100 | 67 | 4 |
| 5 | Concrete Compressive Strength | 1030 | 618 | 412 | 8 |
| 6 | Auto Price | 159 | 95 | 64 | 14 |
| Attribution | Boston Housing Data | Auto-Mpg | Machine CPU | Servo | Concrete Compressive Strength | Auto Price |
|---|---|---|---|---|---|---|
| 1 | CRIM | cylinders | MYCT | motor | Cement | normalized-losses |
| 2 | ZN | displacement | MMIN | screw | Blast Furnace Slag | wheel-base |
| 3 | INDUS | horsepower | MMAX | pgain | Fly Ash | length |
| 4 | CHAS | weight | CACH | vgain | Water | width |
| 5 | NOX | acceleration | CHMIN | Superplasticizer | height | |
| 6 | RM | model year | CHMAX | Coarse Aggregate | curb-weight | |
| 7 | AGE | origin | Fine Aggregate | engine-size | ||
| 8 | DIS | car name | Age | bore | ||
| 9 | RAD | stroke | ||||
| 10 | TAX | compression-ratio | ||||
| 11 | PTRATIO | horsepower | ||||
| 12 | B | peak-rpm | ||||
| 13 | LSTAT | city-mpg | ||||
| 14 | highway-mpg | |||||
| 15 | price |
| No. | Data Sets | Number of Particles | Iteration | c1 | c2 | w0 | u |
|---|---|---|---|---|---|---|---|
| 1 | BostonHousing Data | 50 | 200 | 2 | 2 | 0.9 | 4 |
| 2 | Auto-Mpg | 50 | 200 | 2 | 2 | 0.9 | 4 |
| 3 | machine CPU | 50 | 200 | 2 | 2 | 0.9 | 4 |
| 4 | Servo | 50 | 200 | 2 | 2 | 0.9 | 4 |
| 5 | Concrete Compressive Strength | 50 | 200 | 2 | 2 | 0.9 | 4 |
| 6 | Auto Price | 50 | 200 | 2 | 2 | 0.9 | 4 |
| Training (%) | Selected Feature ID | #Features |
|---|---|---|
| 50 | 1, 2, 4, 5, 8, 9, 11, 12 | 8 |
| 60 | 1, 2, 4, 6, 8, 13 | 6 |
| 70 | 1, 2, 3, 9, 11 | 5 |
| 80 | 1, 2, 4, 8, 9 | 5 |
| 90 | 1, 2, 4, 6, 9, 11 | 6 |
| 100 | 1, 2, 4, 8, 9, 11 | 6 |
| Average | 6.0000 |
| Training (%) | Selected Feature ID | #Features |
|---|---|---|
| 50 | 1, 2, 3, 4, 5, 8 | 6 |
| 60 | 1, 3, 4, 6, 8 | 5 |
| 70 | 1, 4, 7, 8 | 4 |
| 80 | 2, 3, 4, 6 | 4 |
| 90 | 1, 2, 4, 5, 7 | 5 |
| 100 | 1, 4, 6, 8 | 4 |
| Average | 4.6667 |
| Training (%) | Selected Feature ID | #Features |
|---|---|---|
| 50 | 1, 2, 3, 5, 6 | 5 |
| 60 | 1, 2, 4, 6 | 4 |
| 70 | 2, 3, 4, 6 | 4 |
| 80 | 1, 2, 4 | 3 |
| 90 | 1, 3, 4, 6 | 4 |
| 100 | 1, 2, 3, 4 | 4 |
| Average | 4.0000 |
| Training (%) | Selected Feature ID | #Features |
|---|---|---|
| 50 | 1, 2, 3, 4 | 4 |
| 60 | 1, 2, 3 | 3 |
| 70 | 1, 2, 3, 4 | 4 |
| 80 | 1, 2, 3, 4 | 4 |
| 90 | 1, 2, 3, 4 | 4 |
| 100 | 1, 2, 3, 4 | 4 |
| Average | 3.8333 |
| Training (%) | Selected Feature ID | #Features |
|---|---|---|
| 50 | 2, 3, 4, 5, 6, 8 | 6 |
| 60 | 1, 2, 3, 6, 7, 8 | 6 |
| 70 | 1, 2, 3, 7 | 4 |
| 80 | 1, 2, 4, 7 | 4 |
| 90 | 1, 2, 4, 6, 7 | 5 |
| 100 | 1, 2, 4, 7 | 4 |
| Average | 4.8333 |
| Training (%) | Selected Feature ID | #Features |
|---|---|---|
| 50 | 1, 2, 3, 4, 5, 7, 9, 10, 12, 13, 14 | 11 |
| 60 | 2, 3, 4, 6, 7, 9, 10, 12, 13 | 9 |
| 70 | 1, 3, 4, 510, 12, 13 | 7 |
| 80 | 1, 2, 4, 5, 7, 10, 12, 13 | 8 |
| 90 | 1, 2, 4, 5, 7, 10, 12, 13 | 8 |
| 100 | 1, 2, 4, 5, 10, 12, 13 | 7 |
| Average | 8.3333 |
| Training (100%) | Weights of Mixed Kernel | Kernel Parameters | Upper Bound | |||
|---|---|---|---|---|---|---|
| lada_1 | lada_2 | lada_3 | d | sigma | C | |
| Boston Housing Data | 0.2140 | 0.3711 | 0.4148 | 2.8264 | 0.4331 | 3.0288 |
| Auto-Mpg | 0.2970 | 0.3417 | 0.3613 | 2.8863 | 0.3420 | 2.2992 |
| machine CPU | 0.1661 | 0.2654 | 0.5684 | 2.5853 | 0.4018 | 3.4588 |
| Servo | 0.3223 | 0.2743 | 0.4034 | 2.6001 | 0.5901 | 2.4512 |
| Concrete Compressive Strength | 0.2827 | 0.3197 | 0.3976 | 2.7553 | 0.6408 | 3.2270 |
| Auto Price | 0.3466 | 0.3828 | 0.2705 | 2.3582 | 0.3772 | 2.4982 |
| Data Sets | Regressor | SSE/SST | SSR/SST |
|---|---|---|---|
| Boston Housing Data | SVR | 0.1274 | 0.9032 |
| LSSVR | 0.1293 | 0.8964 | |
| PSO-LSSVR | 0.9091 | 0.1720 | |
| CP-LSSVR | 0.9900 | 0.1484 | |
| CP-LSSVR | 1.0000 | 0.1276 | |
| CP-LSSVR | 1.0030 | 0.1302 | |
| CP-LSSVR | 1.0437 | 0.1563 | |
| Auto-Mpg | SVR | 0.1134 | 0.9873 |
| LSSVR | 0.1064 | 0.9897 | |
| PSO-LSSVR | 0.9941 | 0.4608 | |
| CP-LSSVR | 0.9560 | 0.5095 | |
| CP-LSSVR | 1.0409 | 0.4609 | |
| CP-LSSVR | 1.0071 | 0.4688 | |
| CP-LSSVR | 1.0010 | 0.4884 | |
| machine CPU | SVR | 0.1048 | 0.9813 |
| LSSVR | 0.1017 | 0.9877 | |
| PSO-LSSVR | 0.9585 | 0.0064 | |
| CP-LSSVR | 0.9652 | 0.0103 | |
| CP-LSSVR | 0.9552 | 0.0104 | |
| CP-LSSVR | 0.9700 | 0.0055 | |
| CP-LSSVR | 0.9547 | 0.0058 | |
| Servo | SVR | 0.1315 | 0.9774 |
| LSSVR | 0.1331 | 0.9756 | |
| PSO-LSSVR | 0.9713 | 1.7185 | |
| CP-LSSVR | 1.0034 | 1.7251 | |
| CP-LSSVR | 1.0044 | 1.7869 | |
| CP-LSSVR | 1.0043 | 1.6734 | |
| CP-LSSVR | 1.0234 | 1.7577 | |
| Concrete Compressive Strength | SVR | 0.1237 | 0.9425 |
| LSSVR | 0.1226 | 0.9338 | |
| PSO-LSSVR | 0.9395 | 0.2030 | |
| CP-LSSVR | 0.9604 | 0.1944 | |
| CP-LSSVR | 0.9802 | 0.1836 | |
| CP-LSSVR | 0.9700 | 0.1942 | |
| CP-LSSVR | 0.9692 | 0.1936 | |
| Auto Price | SVR | 0.1278 | 0.9821 |
| LSSVR | 0.1288 | 0.9952 | |
| PSO-LSSVR | 0.9913 | 0.1858 | |
| CP-LSSVR | 0.9843 | 0.1803 | |
| CP-LSSVR | 0.9950 | 0.1982 | |
| CP-LSSVR | 1.0515 | 0.1639 | |
| CP-LSSVR | 1.0562 | 0.1862 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeh, W.-C.; Zhu, W. Forecasting by Combining Chaotic PSO and Automated LSSVR. Technologies 2023, 11, 50. https://doi.org/10.3390/technologies11020050
Yeh W-C, Zhu W. Forecasting by Combining Chaotic PSO and Automated LSSVR. Technologies. 2023; 11(2):50. https://doi.org/10.3390/technologies11020050
Chicago/Turabian StyleYeh, Wei-Chang, and Wenbo Zhu. 2023. "Forecasting by Combining Chaotic PSO and Automated LSSVR" Technologies 11, no. 2: 50. https://doi.org/10.3390/technologies11020050