Datasets
To conduct the experiment, LandSat image data has been collected from Yerer Selassie located near the town of Bishoftu in the Oromia region of Ethiopia. Yerer is located in the East Shewa zone in the great rift valley at 38°57′40.863″ E and 8°50′55.016″ N. Yerer selassie borders on the south by Dugda Bora to the south the West Shewa Zone to the West, the town of Akaki to the Northwest, the district of Gimbichu to the northeast, and of Lome to the east. Altitudes in this district range from 1500 to over 2000 m above sea level. From this specific geo-location, three image data were collected in different time frames.
During the data pre-processing steps, we made all the required corrections such as: determining Spatial resolution using operational land imagery, Top of Atmosphere Reflectance, Radiometric correction and Topographic Correction, and Generating False color composition
. About four bands namely the red, blue, green and near-Infrared bands have been selected to extract the relevant features. Layer stacking has been performed to combine all four selected spectral bands to obtain a single stacked image data. At this level, one can utilize different false color combinations to make the visualization of the stacked image appear more natural.
Figure 3 shows the image stacking process we utilized.
The stacked multi-spectral image was used as an input dataset to train the proposed model which comprises a dimension of 372 nrow ∗ 200 ncol, 30 m spatial resolution, and a total of 65,400 features. A sample or observation of 147 spatial-polygon has been labeled as a training dataset from the raster image data. The distribution provides a parameterized mathematical function that can be used to calculate the probability for any individual observation from the sample space. From this analogy, the training datasets are almost evenly distributed.
Figure 4 illustrates the distribution of training samples on each layer stack.
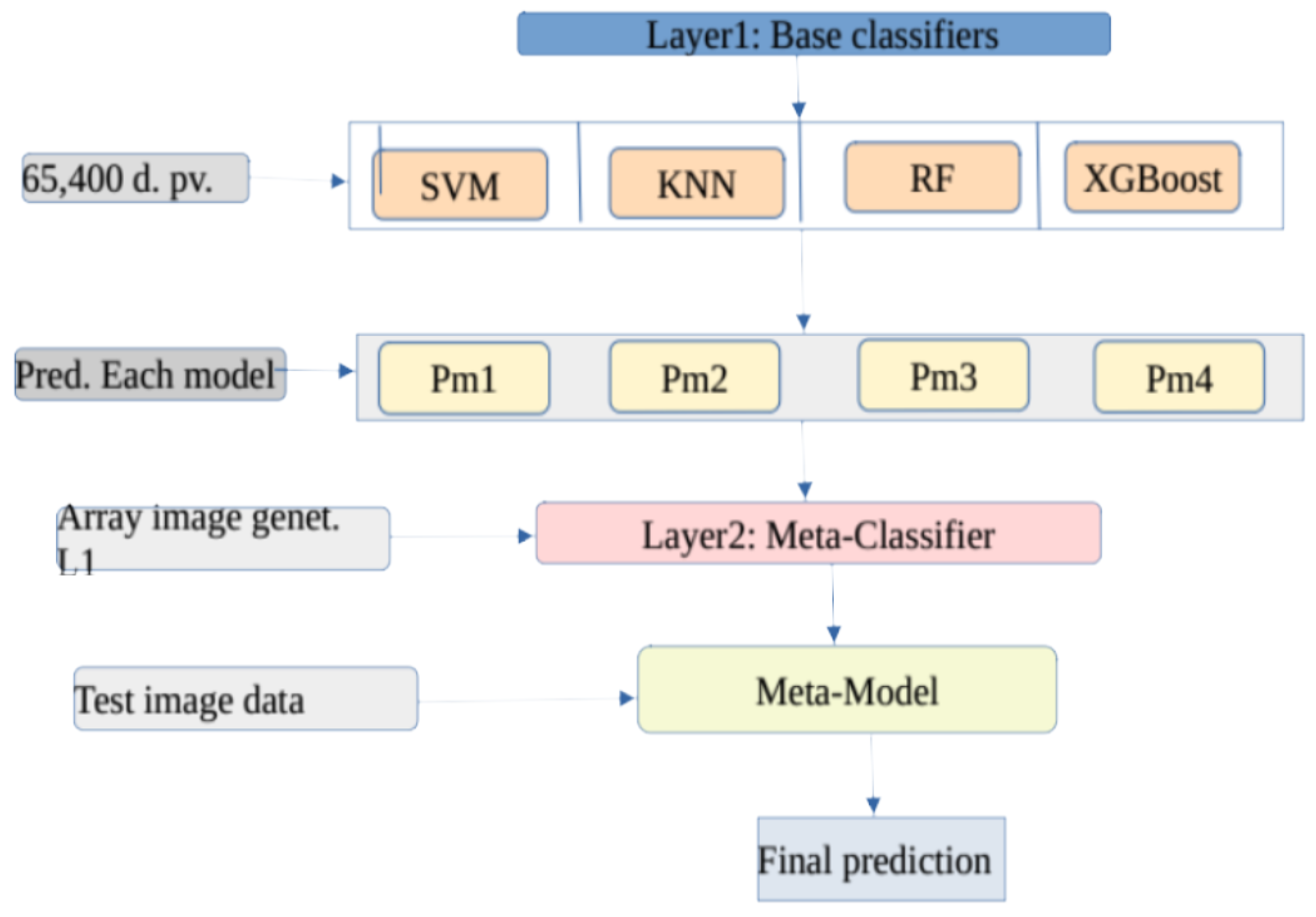
Then, the dataset split and 70% of it was used for training purposes and the remaining 30% was used for model testing purpose. The next step was applying multiple base classifiers to build our classification models. In this regard, we selected
models as base classifiers. All the base classifiers utilized
,
, nd the bootstrapped sampling technique was used to select sample dataset. The Samples were constructed by drawing observations from a large data sample one at a time and returning them to the data sample after they have been chosen. This allows a given observation to be included in a given small sample more than once. In this sub-section, we briefly discuss the nature of the individual base classifiers. First, the support vector machine is one of the strong machine learning algorithms provided non-linear issues are properly handled. We have utilized the RBF kernel function to fit the model. The radial kernel function has a form:
where
is a tuning parameter which accounts for the smoothness of the decision boundary and controls the variance of the model. If
is very large then we get quiet fluctuating and wiggly decision boundaries which accounts for high variance and over-fitting. If
is small, the decision line or boundary is smoother and has low variance. Then the support of SVM becomes:
The second base classifier is the random forest (RF) classifier which is an ensemble learner by its very nature. It a classifier comprising a number of decision trees on various subsets of the given observation and takes the average to improve the predictive accuracy of that dataset. The output chosen by the majority of the decision trees becomes the final output of the rain forest system. The third base classifier was the KNN algorithm that stores all the available data and classifies a new data point based on similarity. That is, when new data appears, then it can be easily classified into a category by using the KNN algorithm. KNN is a non-parametric algorithm, which means it does not make any assumptions about the underlying data. There is no particular way to determine the best value for “K”, so we need to try some values to find the best performing one. The most preferred value for K is 5.
where,
x and
y are the two vector points on sample space. Optimal classification performance obtained at
.
Table 1 above summarizes experiment results and the classification performance of each base classifier on the training data-sets. Generally, each classifiers performs very well on the training data. In the case of KNN, the new training samples were classified into their respective categories by a majority vote of its neighbors, with the case being assigned to the class most common amongst its
K nearest neighbors measured by a distance function. There is no standard to define the numbers of
K values. It needs several trial and errors to get the optimal values. On the other hand, we have evaluate different distance metrics that fit the problem domain. Similarly, SVM needs to address the non-linearity issue by finding the best fitting kernel function. The idea behind generating non-linear decision boundaries is that we need to do some nonlinear transformations on the features
, which transforms them into a higher dimensional space. In our case, the non-linear decision boundary and the values of the tuning parameters were
and a number of support vectors. Results of the experiment show that the number of predictors affects the classification performance of each base classifier. In this regard, as the number of predictors increases or decreases, the performance of the model also varies. The last but not least base classifier was the XGBoost method [
37,
38,
39]. Assume that our image dataset is D = (
,
):
i = 1 …
n,
ɛ
,
ɛ
, then we get n observations with m dimensions each and with a target class y. Let ŷ
i be defined as a result given by the ensemble represented by the generalized model as follows [
43]:
where
is a regression tree, and
represents the score given by the
k-th tree to the
i-th observation in the data. In order to define function
, the following regularized objective function should be minimized:
L is the loss function. In order to prevent the model from getting too large and complex, the penalty term
is included as follows:
where
Y and
are parameters controlling penalty for the number of leaves
T and the magnitude of leaf weights
w, respectively. The purpose of
is to prevent over-fitting while simplifying models produced by this algorithm.
Note: The final values used for the model were , , , , , .
After evaluating the performance of individual base classifier, we employed the remaining 30% of our test data-set to evaluate the overall prediction performance of each base classifier.
Table 2 summarizes the prediction performance of the base classifiers using the test dataset.
From
Table 2, one can deduce that all the models performed well in classifying the test dataset with high accuracy. However, when we compared the prediction performance of KNN and SVM on test and training data-sets, we encountered an issue an issue over-fitting. One of the possible solutions is increasing the sizes of both the training and testing data set. Another challenge is, the sensitive of base classifiers, where small variances significantly affected their prediction performance. The main objective of this study was to implement stack-based ensemble learning method. In ensemble learning method, before proceeding to combine different base classifier, evaluating the correlation among individual base classifiers are very import. If there is no difference among base classifier, then no need of applying Ensembling learning approach. The rules of ensemble-based learning are mainly based on difference among base classifiers. From our experimental results, the correlation among the base classifiers are briefly summarized in
Table 3.
In
Table 3, the pairwise correlations between individual models are low and fulfill the requirement of an ensemble learning rule. From experiment results, two models are highly correlated in predicting the training data-sets. Building the ensemble learning demand the analogy of less difference among the base classifiers. Due to the bootstrap re-sampling, the size of selected samples in each target classes are differ at different executions. The base classifier sensitivity was also observed in the correlation among the models.
Once the assessment has been completed, the next step was implementing the stack-based ensemble learning approach to determine the final categories using meta-data. The stacking approach utilizes meta-data generated from each base classifier as input for training the meta-model. Bagging namely bootstrap aggregating [
44,
45] is one of the most intuitive and simple frameworks in ensemble learning that uses the bootstrapped sampling method. In this method, many original training samples may be repeated in the resulting training data, whereas others may be left out. Samples are selected randomly from the training set, instructive iteration is applied to create different bags, and the weak learner is trained in each bag. Each base learner predicts the label of the unknown sample, respectively.
In the case of Stacked XGBoosting method, a multi-nominal distribution sampling technique has been used to select observations randomly from the sample space. First, the parameters
are sorted in descending order. Then, for each trial, variable
X is drawn from a uniform
distribution. The resulting outcome is the component.
= 1;
= 0 for
is one observation from the multi-nomial distribution with
and
. A sum of independent repetitions of this experiment is an observation from a multi-nominal distribution with n equal to the number of such repetitions. Our overall results from the experiment, in terms of the classification accuracy of the base and ensemble models are summarized in
Table 4.
It is apparent from
Table 4 that the majority of the individual base classifiers have classified both the training and testing datasets with satisfactory accuracies. When the base classifiers were combined using the stacking ensemble approach, the performance improved. The proposed model classified the multi-spectral image data with 99.96% classification accuracy. This is promising and the model is worth applying for various application areas. We plan to extend our work to further test the proposed model using larger image datasets. In this study, handling the challenges of bias and variance is our concern. To resolve this pitfall, we integrate the XGBoosting method into the ensemble learning approach. The XGBoost model belongs to a family of boosting algorithms that turn weak learners into strong learners. Boosting is a sequential process; i.e., trees are grown using the information from a previous grown tree one after the other. This process slowly learns from previously use of data and tries to improve its prediction in subsequent iterations. Boosting reduces
Both variance and bias. It reduces variance because it uses multiple models through a bagging process. It also reduces bias through training successive models by passing information on errors made by previous models. These are some of the reasons why we integrated the XGBoosting method into the stacking learning approach to address the challenges of bias-variance trade-off. In addition, Samat and colleague [
25] also proposed the Meta-XGBoosting framework to improve the limitations of the XGBoost model. Finally, the XGBoost model enabled us to achieve optimal classification accuracy from the proposed model.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}