4.1. Results for the PD
The sample taken into consideration consists of 51 companies—listed on Italian Stock Exchange, for simplicity of data retrieval—randomly chosen from sectors in consumer and services goods (see
Table A1). Data collected for the analysis refer to the year 2018. The program used for carrying out the analysis is the SPSS package. Based on the value of Net-Debt-to-Equity ratio (ND/E), a measure of company’s financial leverage calculated by dividing its net liabilities by stockholders’ equity, the dependent variable follows this rule:
In fact, according to analysts, to be a “healthy” company, this ratio should be at most equal to 1; conversely, a ratio equal to or greater than 1 would mean the company is “risky” and that in the next year it could become insolvent. According to this rule, in the sample, there are 37 healthy companies (72.5%) and 14 risky ones (27.5%) (see
Appendix A for the complete dataset). In our case, following (
Tsai 2013), the explanatory variables are six financial ratios:
- -
Current ratio (current assets to current liabilities) measures the ability of an entity to pay its near-term obligations. “Current” usually is defined as within one year. In business practice, it is believed that this ratio must be equal to 2 to have an optimal liquidity situation, or between 1.5 and 1.7 to have a satisfactory liquidity situation. A current ratio lower than 1.5 is symptomatic of a liquidity situation to be kept under control, and, if it is lower than unity, then this would mean facing liquidity crisis. It should, however, be specified that an excess of liquidity that generates a ratio higher than 2 means that the company has money in cash or safe investments that could be put to better use in the business.
- -
Debt ratio (total liabilities to total assets) is a leverage ratio and shows the degree to which a company has used debt to finance its assets. The higher is the ratio, the higher is the degree of leverage and, consequently, the higher is the risk of investing in that company. A debt ratio equal to or lower than 0.4 means that company’s assets are financed by creditors; if it is equal to or greater than 0.6, the assets are financed by owners’ (shareholders’) equity.
- -
Working capital to assets ratio (working capital to total assets) is a solvency ratio; it measures a firm’s short-term solvency. Working capital is the difference between current assets and current liabilities. A ratio greater than 0.15 represents a satisfactory solvency situation; a ratio lower than 0 means that the company’s working capital is negative, and its solvency is critical.
- -
ROI (EBIT* to total assets) is an indicator that expresses the company’s ability to produce income from only the core business for all its lenders (investors and external creditors). In fact, both financial and tax activity are excluded from EBIT (Earnings Before Interests and Taxes).
- -
Asset turnover (sales to total assets) is a key efficiency metric for any business as it measures how efficiently a business is using its assets to produce revenue.
- -
ROI (net income to cost of investment): a profitability ratio that provides how much profit a company is able to generate from its investments. The higher the number, the more efficient the company is at managing its invested capital to generate profits.
Before proceeding with the evaluation of the model results, the statistical analysis involves a detailed exploration of the characteristics of the data.
Table 1 shows frequencies of healthy and risky companies within the sample, means, medians and standard deviations of the Net-Debt-to-Equity ratio for each of the two groups:
It is easy to notice that both mean and median of the healthy group are much lower than 1 while those of the risky group are much greater than 1. The average of total observations is lower than 1, and this is evident because healthy firms make up almost three quarters of the sample. Standard deviations of the two groups also diverge by 0.5 points; this is because among risky companies there is a greater dispersion from the average of observed ratios. Looking at each explanatory variable (
Table 2), data show that: the current ratio average for the healthy group is equal to 1.6, meaning a good liquidity situation, while the same average for the risky one is equal to 1.1, signs of a liquidity situation to be kept under control. The mean of ROI is clearly different between the two groups: for the healthy one, it is 15.41%, and, for the risky one, it is equal to 0.1%. Working capital to assets ratio is negative for the risky companies, showing a critical solvency situation, where current liabilities, on average, are greater than current assets; conversely, the healthy companies’ working capital to assets is greater than 0.15, meaning a satisfactory solvency situation. As expected, debt ratio is higher for the risky group, while asset turnover and ROA are higher for healthy companies. It should be emphasized that the latter is on average negative for the risky ones, resulting from a negative net income.
The first estimated model includes all the six independent variables introduced above, under the assumption of absence of multicollinearity. However, looking at the parameter estimates (
Table 3), it is clear that for the discussed sample only two of these six regressors are significant for the PD model.
Proceeding to the sequential elimination of covariates through Wald test, the variables discarded in increasing order of significance are: ROA (
p-value = 0.360), asset turnover (0.207), current ratio (0.242) and debt ratio (0.091). The only two remaining significant variables are ROI and Working-capital-to-Asset ratio. The second estimated model contains precisely these two variables for both ML estimation (
Table 4) and Firth penalized logistic regression (
Table 5).
As expected, both coefficients are negative: this means that both variables have a positive effect on company health. The log-likelihood ratio test provides a chi-square with six degrees of freedom equal to 26.974, whose
p-value is 0.000. Therefore, the null hypothesis that at least one of the parameters of the model is equal to zero is rejected. The measures of goodness-of-fit are also acceptable either with the classical ML estimation (
Table 6) or with the Firth penalized logistic regression (
Table 7). Likelihood ratio represents what of the dependent variable is not explained after considering covariates: the bigger it is, the worse it is. Cox–Snell R Square provides how much the independent variables explain the outcome; it is between 0 and 1, where the bigger the better. The Nagelkerke R Square is similar to the previous but reaches 1.
A pseudo R-square equal to 40% is good if it is considered that PD is certainly not determined exclusively by these two variables. The Hosmer–Lemeshow test provides a high enough
p-value to accept the hypothesis that the model is correctly specified (0.914). The contingency table of the test is available in
Table 8.
Observations are divided into deciles based on observed frequencies. The table shows that expected frequencies are very close to the observed ones for each decile except for the ninth, where the deviation of the two values is more marked. The percentage correctly predicted is equal to 82.4%: 42 are the cases rightly estimated; of the nine classified incorrectly, six (42.9%) are among the risky companies and three (8.1%) are among the healthy ones (
Table 9).
The model ranks health companies better, but this is mainly due to the fact that the majority of the sample is made up of Type 0 companies. The effects of the individual regressors are graphically described (
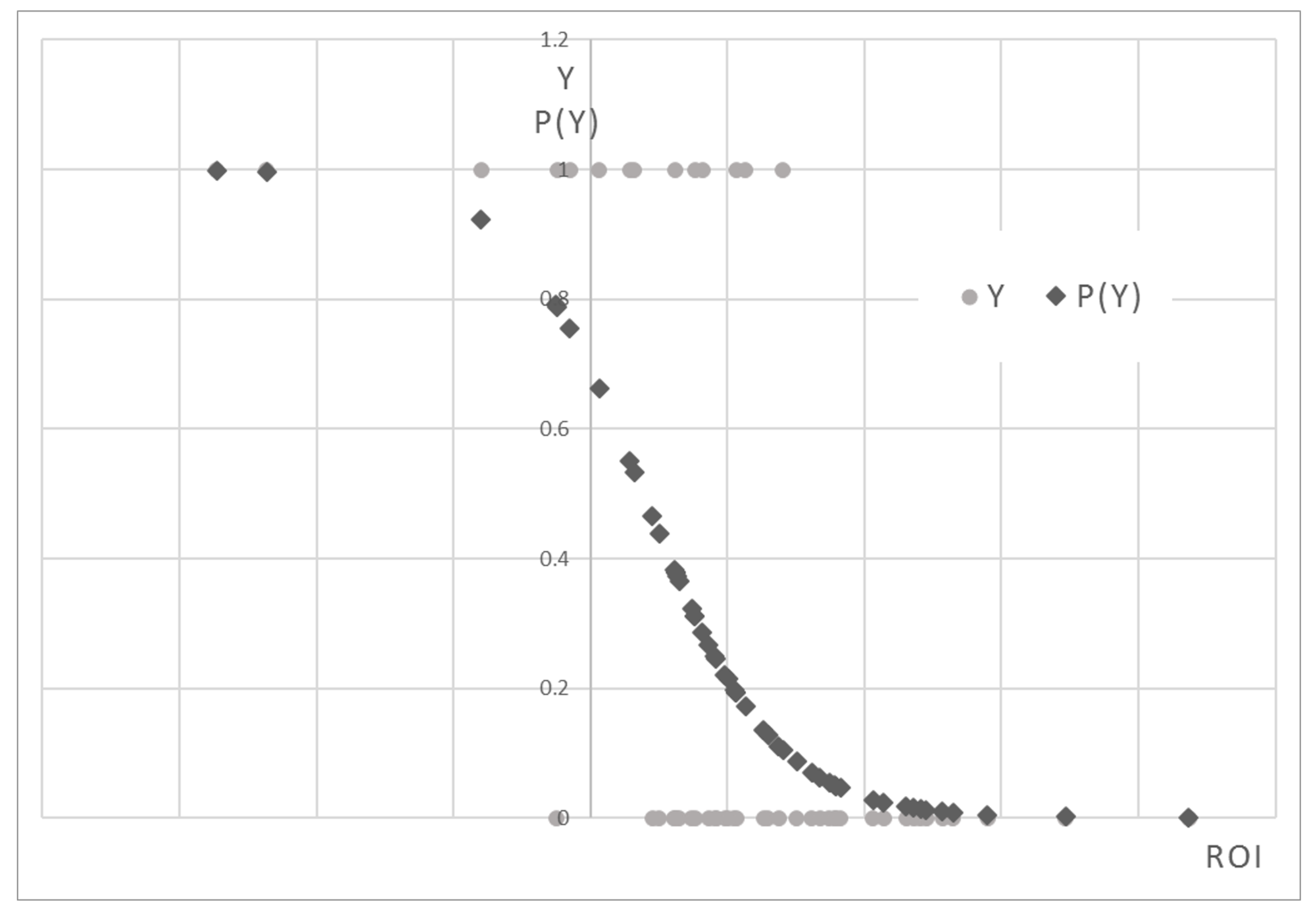
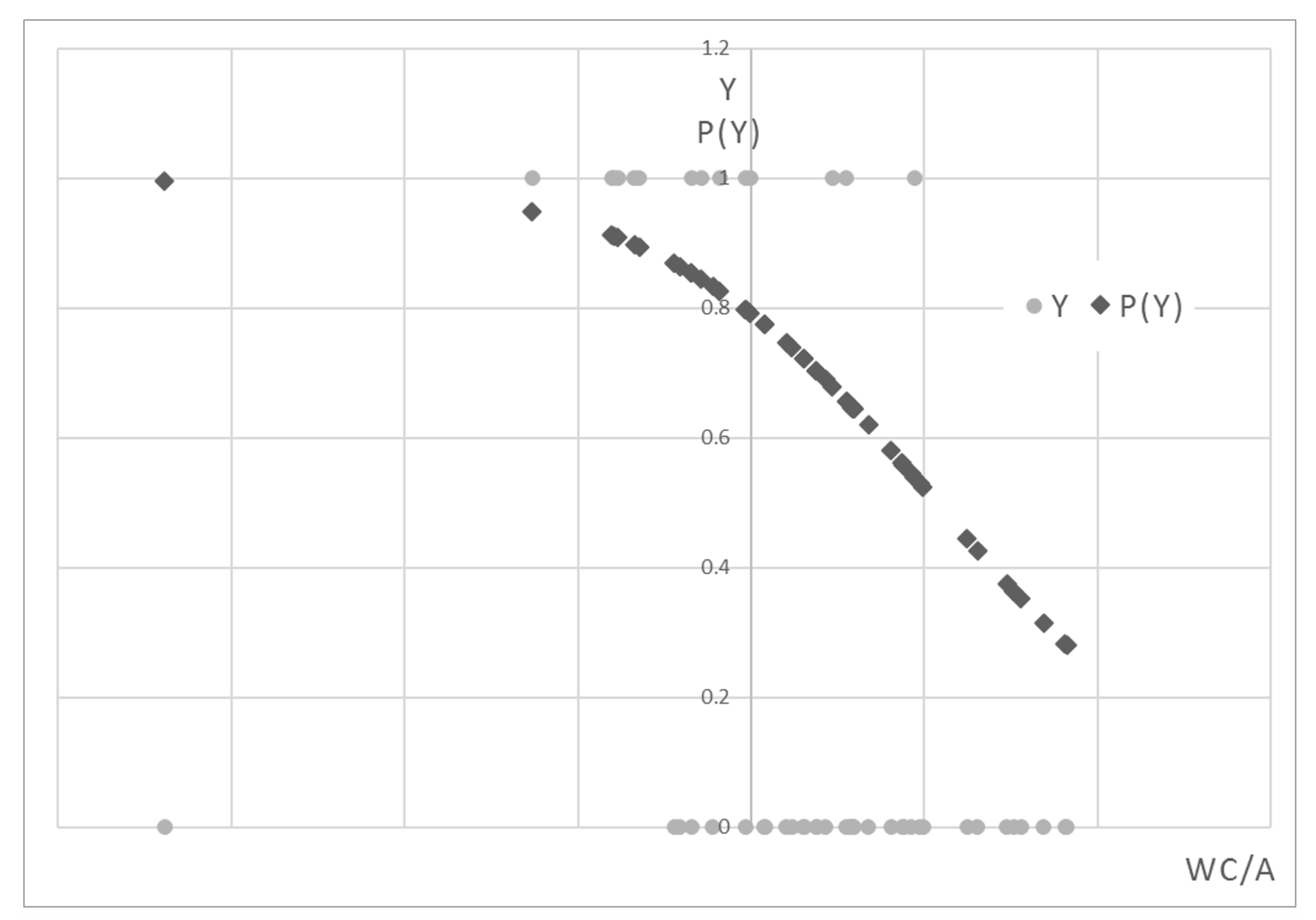
Figure 1 and
Figure 2). Both the coefficients are negative showing that PD decreases with increasing covariates. As the Return on Investment (ROI) increases, the riskiness of the company decreases (
Figure 1); as the Working Capital to Asset ratio increases (and, therefore, as the difference between current assets and current liabilities increases), the company becomes safer (
Figure 2).
The points of the P(Y) constitute an inverse sigmoid: as the ROI increases, P(Y) decreases. They are concentrated mainly in the lower part of the graph, where P(Y) is less than 0.4. This is because in the sample there are more Type 0 firms than Type 1 ones. A probability function of this type is better suited to the observations, remaining within the constraints of 0 and 1.
This second inverse sigmoid has the same trend as the previous one. However, it is truncated, as no observation of the sample presents a probability as a function of the WC to asset ratio lower than 0.3.
4.2. Results for the LGD
Our dataset contains 55 defaulted loans, of which are known historical accounting movements, year of default, EAD, recovery time and presence of collateral (see
Table A2). According to the definition, LGD is calculated as the complement to the one of the Recovery Rate (RR), the proportion of money financial institutions successfully collected minus the administration fees during the collection period, given the borrower has already defaulted
Ye and Bellotti (
2019):
where
is the exposure at default of each loan,
stands for the administration costs incurred, discounted at the time of default, and
is the present value of the recovered amount. Recovery time is standardized through the equation
. The discount rate used is 10%. All data are shown in
Appendix A. As in
Hartmann-Wendels et al. (
2014);
Jones and Hensher (
2004);
Tsai (
2013), and to avoid data separation that could be introduced by a finer partition of the dataset, we split the sample into three buckets so that the ‘
’ column is categorized as (0, 1, 2) of each loan in relation to the
level. Therefore, the following rule applies:
In the ‘COLLATERAL*’ column, the presence or absence of collateral is, respectively, indicated by 1 and 0.
At this point, the goal is to demonstrate in this sample how the presence of collateral and the length of the recovery time affects
. Loans with the lowest loss level are 15% of the sample; Category 1, where loss was between 30% and 70% of exposure, constituting 49% of total; loans with
greater than 0.7 are 36%. It is easy to understand that the average and the median of latent
are lower than 0.1 for the first category of loans, close to 0.5—and to the total average of the sample—for the second category, and almost 1 for the third. Moreover, only 17 credits of 55 were guaranteed by collateral (31%), 7 out of 8 in the first category, 6 out of 27 in the second one and 4 out of 20 in the third groups. Both mean and median of latent response variable are higher for loans without collateral than for the ones with collateral, confirming that collateral has positive effect on credit recovery. Both mean and median of recovery time grow as the
increases: as more time passes, it becomes more difficult to recover a loan. The first model shows the relationship between
trend and the presence of collateral. Estimating the model, it can be immediately noticed that this model does not fit very well to the data: Pearson’s chi-square corresponds to a small
p-value that does not allow us to reject the null hypothesis according to which the model is good. Pseudo r-square is also very low and therefore unconvincing. The results are shown below (
Table 10 and
Table 11).
Certainly, a large part of this low fit score is attributable to the sample size, which is extremely small. However, the estimates of the model parameters are shown below (
Table 12), which are still significant.
The second estimated model is the one that includes recovery time as regressor. Estimating the model, data fit measures are obtained first. The “Final” model has a better fit than the first one (
Table 13).
LR Chi-Square test allows verifying if the predictor’s regression coefficient is not equal to zero. Test statistic is obtained from the difference between LR of Model 0 and LR of the final model.
P-value (equal to 0.000—it represents the probability of obtaining this chi-square statistic (31.56) if in reality there is no effect of the predictive variables) compared with a specified alpha level—i.e., our willingness to accept a Type I error, which is generally set equal to 0.05—leads us to conclude that the regression coefficient of the model is not equal to 0. Pearson’s chi-square statistics and deviance-based chi-square statistics give us information on how suitable the model is for empirical observations. Null hypothesis is that the model is good; therefore, if
p-value is large, then the null hypothesis is accepted, and the model is considered good. In this case, it is possible to say that the model is acceptable, as its results are satisfactory: it has a Pearson’s chi-square equal to 22.0, df = 19,
p-value = 0.283; Deviance’s chi-square is equal to 23.5, df = 19,
p-value = 0.218; the pseudo R-square measurements are also acceptable (
Table 14), considering that the
is determined by many factors and recovery time is not the only feature.
In
Table 15, it is possible to notice that recovery time is significant as well as directly proportional to
: the positive coefficient tells us that, as recovery time increases,
also increases, as expected. In fact, it is known from the literature that the best way to manage a bad credit is to act promptly and that, over time, the chances to recover a loan worsen.
The ‘threshold’ section contains estimates, in terms of logit, of cutoff points between categories of response variable. The value for
is the estimate of cutoff between the first and second class of
; the value corresponding at
is the estimate of cutoff between the second and the third
classes. Basically, they represent points, in terms of logit, from which loans should be predicted in the upper class of
. For the purposes of this analysis, their interpretation is not particularly significant, nor is it useful to interpret these values individually. The only estimate of logit ordered regression coefficient that appears in the parameter estimates table is the one relating to the regressor. Conceptually, interpretation of this value is that when explanatory variable increases by one unit the level of the response variable is expected to change, according to its ordered log-odd regression coefficient. In our case, a unit time increment generates a variation of the ordered log-odd of being in a higher
category of 6.624. A corresponding
p-value (0.000) that remains below the acceptance threshold of the null hypothesis ensures the significance of recovery time determining
.
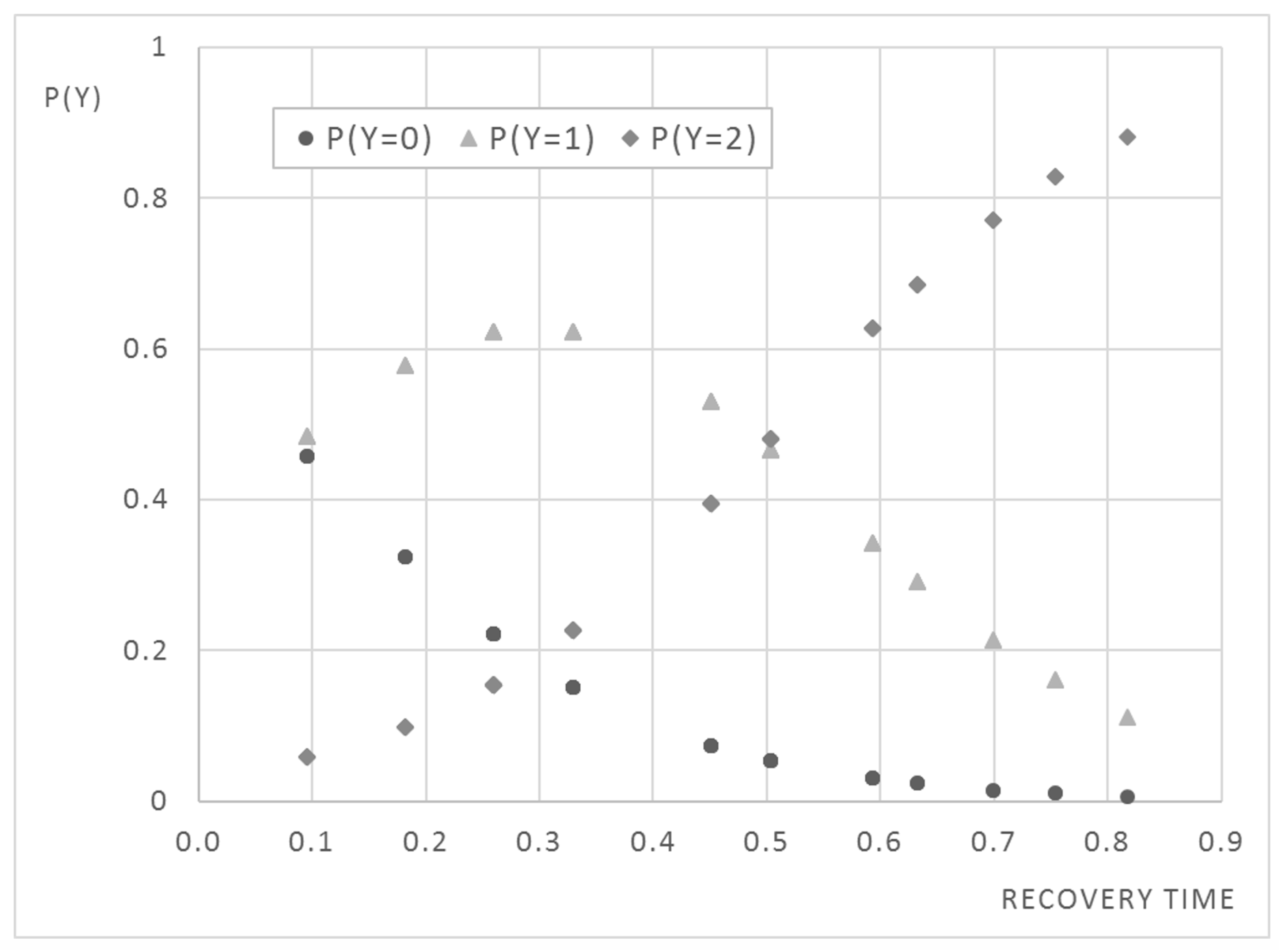
Figure 3 shows the probability curves of occurrence of each category related to recovery time.
Circles belong to probability curve that Y is equal to 0—the category with the lowest loss rate. Over time, this probability decreases until it is almost zero for loans, among the observed, with longest recovery times. Diamonds, instead, define the curve of probability that Y is equal to 2: here, loans have very high expected , almost equal to one. This probability increases considerably over time. Finally, triangles outline the probability curve that Y is equal to 1, the class in which the expected is between 0.30 and 0.70. It is increasing in the first part; starting from the moment in which the probabilities of the other two classes are equal and the respective curves intersect it starts to decrease till the end of time axis.
Poisson Estimation and Suitability Analysis
As mentioned, we divided the dataset into three groups as in
Jones and Hensher (
2004);
Tsai (
2013);
Hartmann-Wendels et al. (
2014). We found the ranges in Equation (
8) to suit well our analysis but, in other contexts, it could be that these ranges are different. The logistic regression answers the question how many cases belong to a certain category. To assess the suitability of the classification, we ran a generalized linear model (GLM) Poisson regression.
Table 16 and
Table 17 provide the estimates for the models with (Model 1) or without the intercept (Model 2), respectively. The dispersion of the results is shown in
Table 18. As illustrated, Model 2 (i.e., the model without intercept) performs better than Model 1 with little loss in terms of dispersion of residuals. Moreover, this analysis confirms that the most important factor is time.




{kind=link}
{kind=link}
{kind=link}


