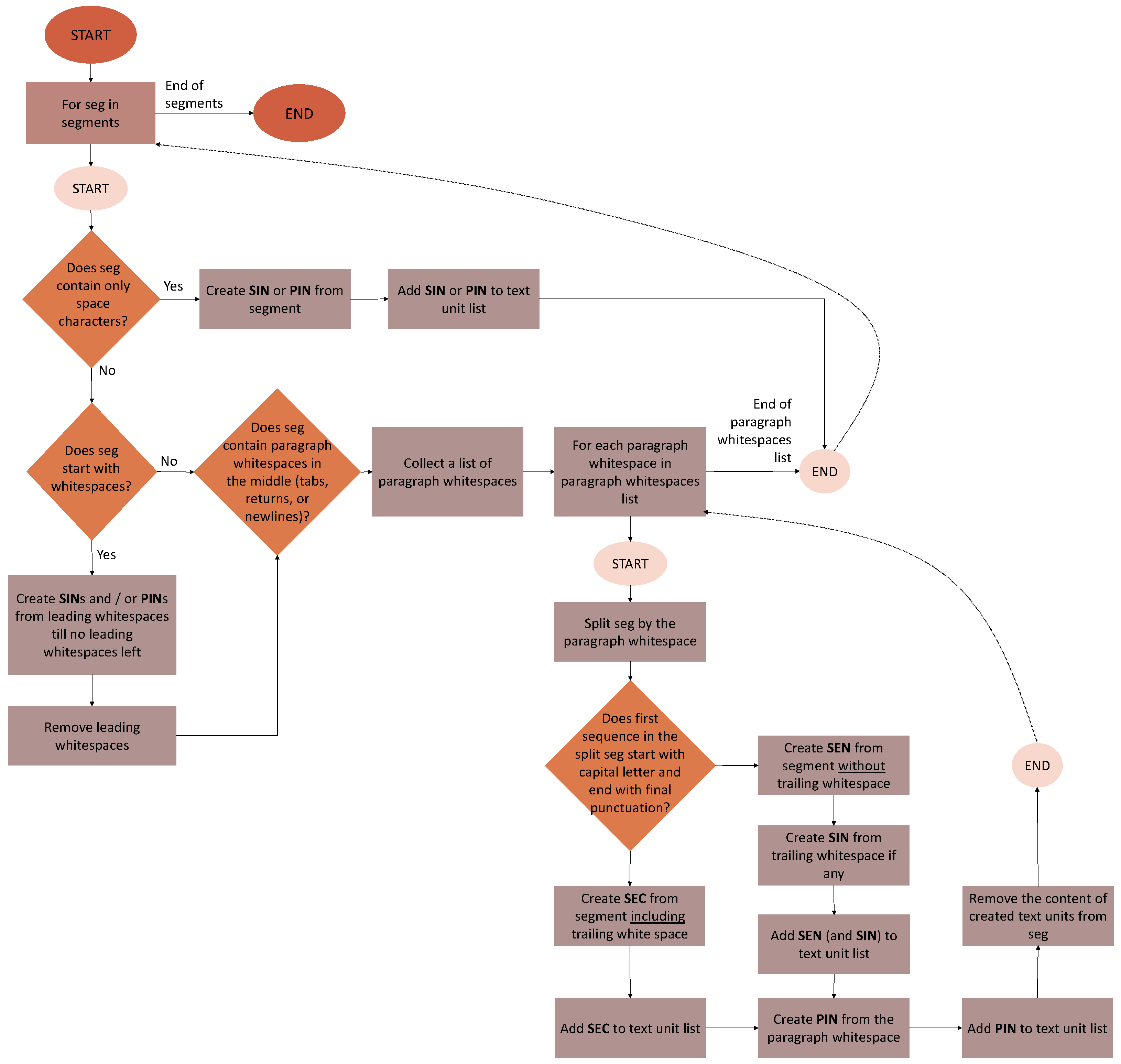
Figure 1.
A visualisation of the text segmentation into text units: SPSF, SIN, and PIN.
Figure 1.
A visualisation of the text segmentation into text units: SPSF, SIN, and PIN.
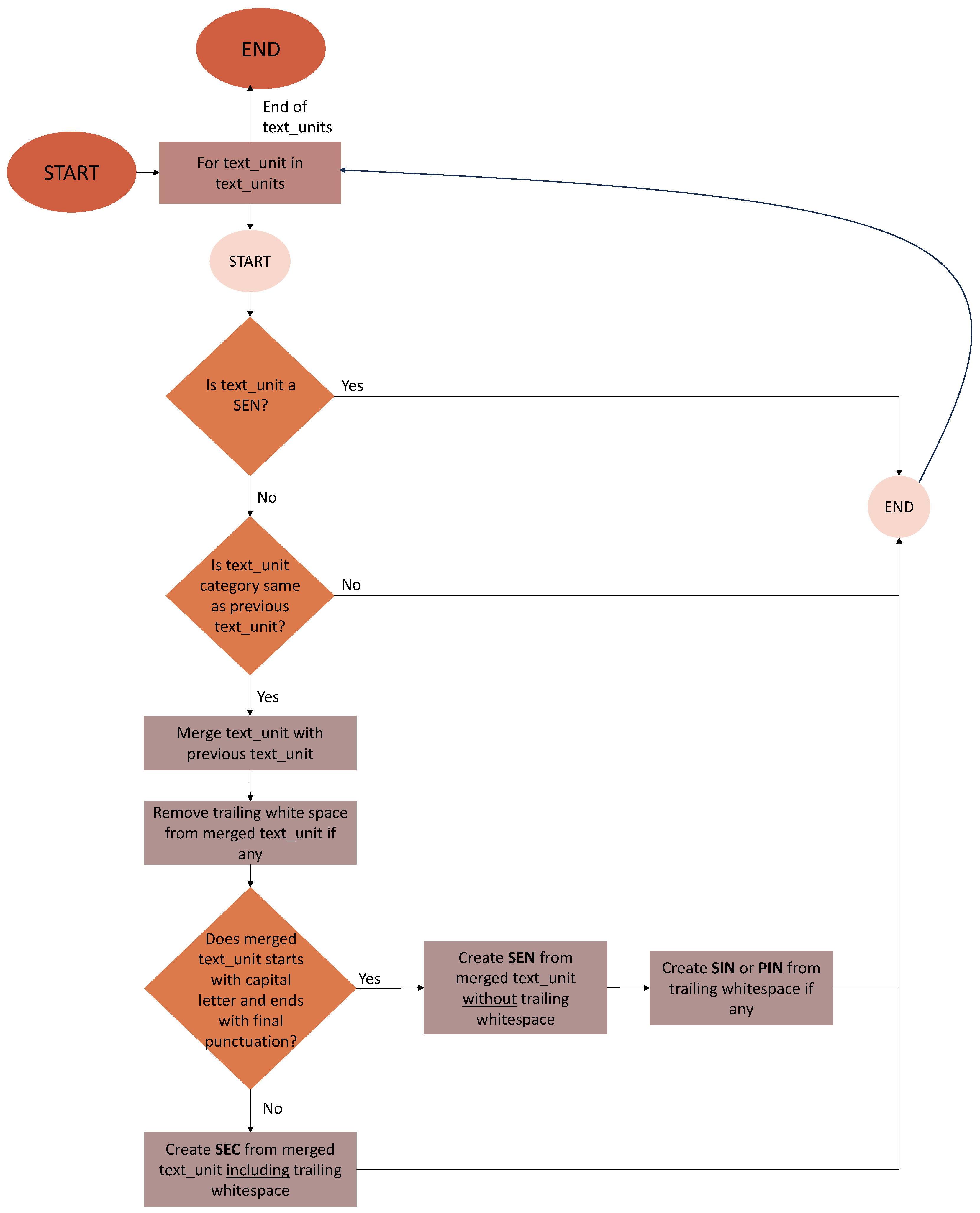
Figure 2.
Algorithm for assigning segments identified as sentences by spaCy to one of four text unit categories: SEN, SEC, SIN, or PIN.
Figure 2.
Algorithm for assigning segments identified as sentences by spaCy to one of four text unit categories: SEN, SEC, SIN, or PIN.
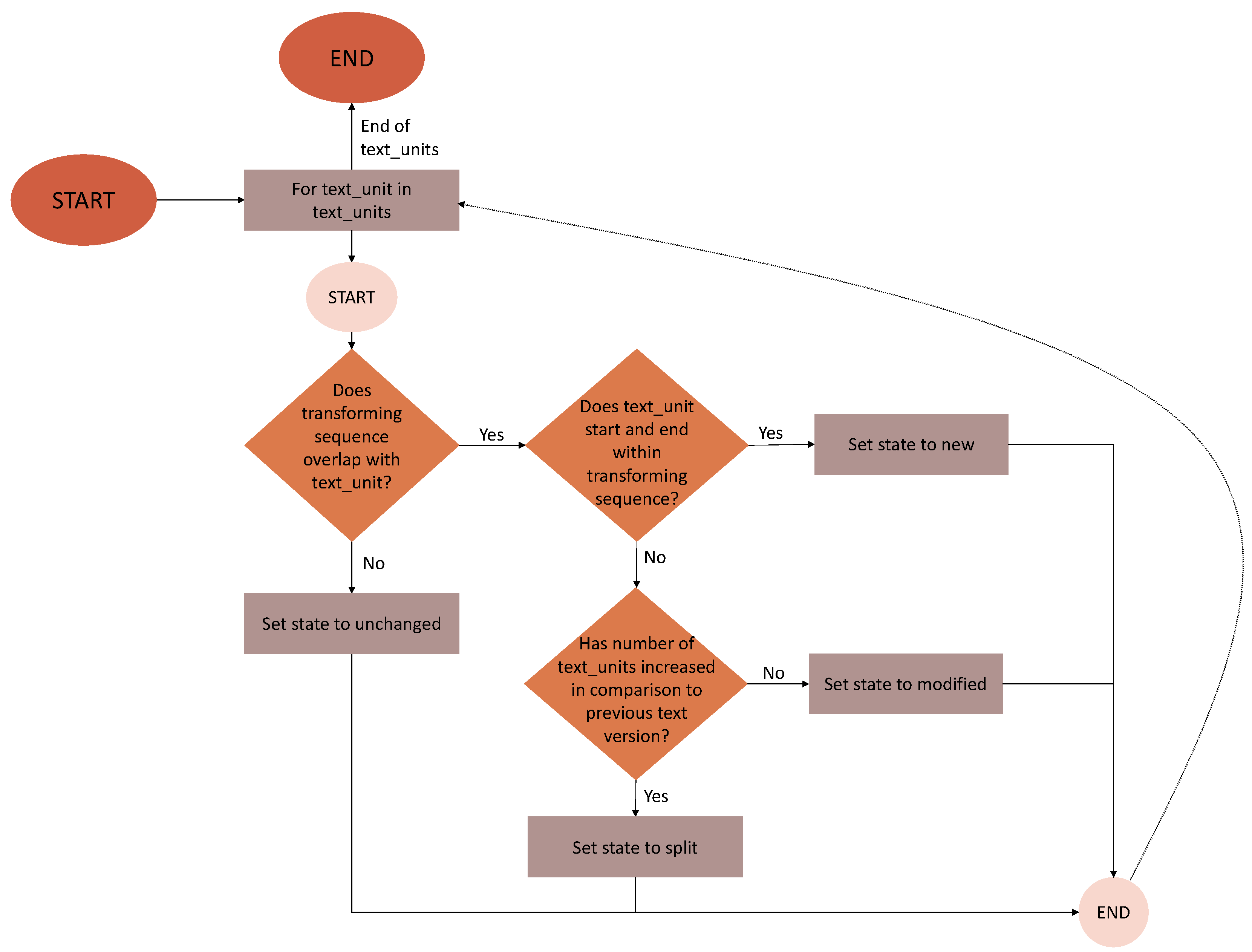
Figure 3.
Algorithm for merging adjacent SECs, SINs, and PINs and transforming them into new SECs, SINs, PINs and SENs.
Figure 3.
Algorithm for merging adjacent SECs, SINs, and PINs and transforming them into new SECs, SINs, PINs and SENs.
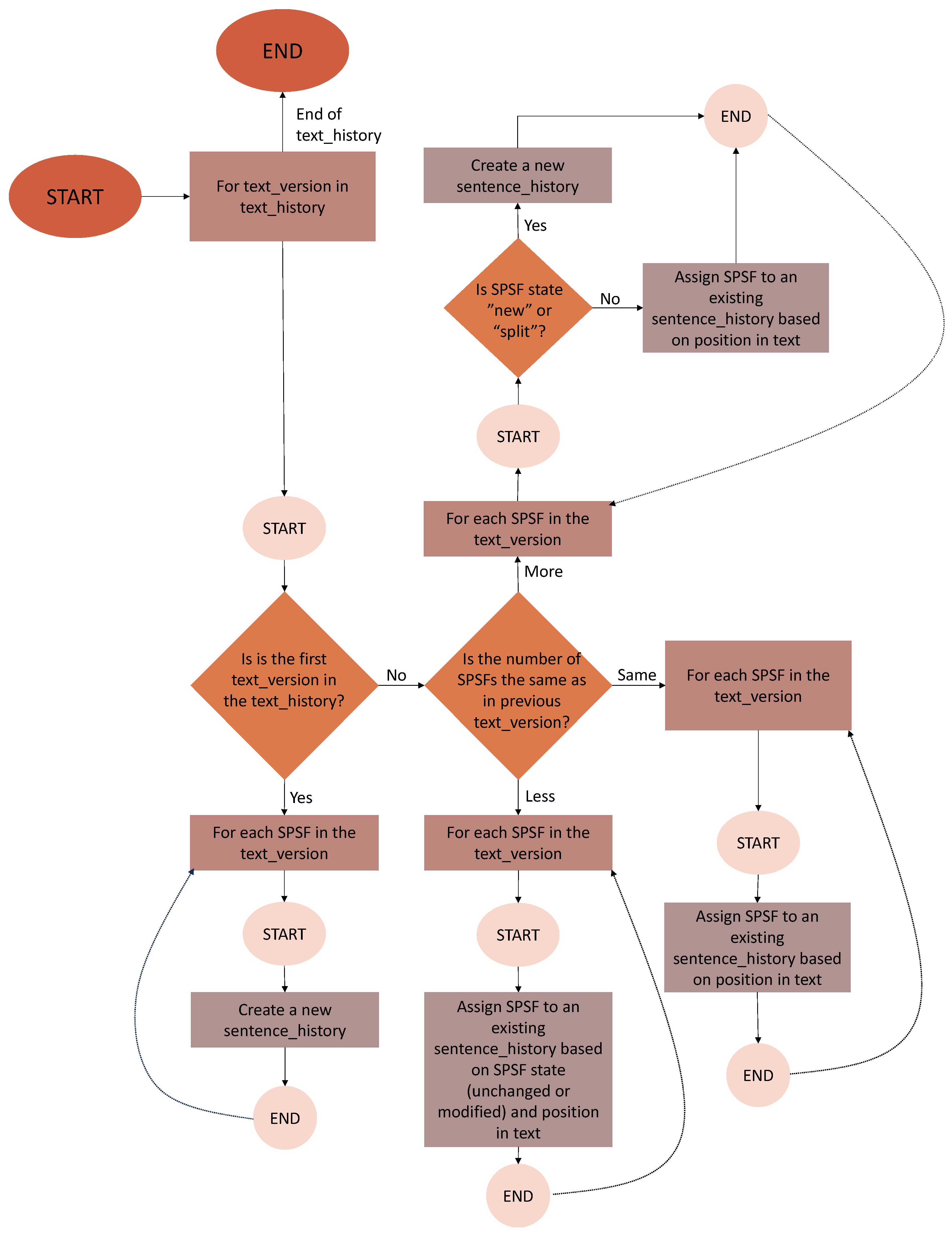
Figure 4.
Algorithm for detecting TPSFs’ states.
Figure 4.
Algorithm for detecting TPSFs’ states.
Figure 5.
Algorithm for generating sentence histories.
Figure 5.
Algorithm for generating sentence histories.
Table 1.
Adapted excerpt from a keystroke log from the evaluation corpus (
Section 5.1).
Start_time and
end_time: millisecond from the beginning of the writing session at which the beginning and the end of the event occurred;
position: position in text at which the event occurred;
␣: space character; ←: deletion.
Table 1.
Adapted excerpt from a keystroke log from the evaluation corpus (
Section 5.1).
Start_time and
end_time: millisecond from the beginning of the writing session at which the beginning and the end of the event occurred;
position: position in text at which the event occurred;
␣: space character; ←: deletion.
| ID | Start_Time | End_Time | Event | Position |
|---|
| 1 | 870,085 | 870,176 | m | 445 |
| 2 | 870,245 | 870,329 | i | 446 |
| 3 | 870,466 | 870,546 | e | 447 |
| 4 | 870,608 | 870,684 | u | 448 |
| 5 | 870,724 | 870,819 | x | 449 |
| 6 | 870,822 | 870,888 | ␣ | 450 |
| 7 | 871,221 | 871,317 | c | 451 |
| 8 | 871,363 | 871,453 | o | 452 |
| 9 | 871,508 | 871,595 | n | 453 |
| 10 | 871,649 | 871,744 | n | 454 |
| 11 | 871,776 | 871,869 | u | 455 |
| 12 | 871,896 | 871,984 | e | 456 |
| 13 | 872,009 | 872,100 | ␣ | 457 |
| 14 | 872,574 | 872,644 | s | 458 |
| 15 | 872,662 | 872,791 | o | 459 |
| 16 | 872,740 | 872,844 | u | 460 |
| 17 | 872,851 | 872,938 | s | 461 |
| 18 | 872,946 | 873,051 | ␣ | 462 |
| 19 | 873,087 | 873,171 | l | 463 |
| 20 | 873,185 | 873,272 | e | 464 |
| 21 | 873,338 | 873,427 | ␣ | 465 |
| 22 | 873,708 | 873,798 | n | 466 |
| 23 | 873,842 | 873,964 | o | 467 |
| 24 | 873,952 | 874,038 | m | 468 |
| 25 | 874,531 | 874,614 | ␣ | 469 |
| 26 | 879,551 | 879,628 | ← | 449 |
| 27 | 879,686 | 879,769 | ← | 448 |
| 28 | 879,834 | 879,913 | ← | 447 |
| 29 | 879,973 | 880,060 | ← | 446 |
| 30 | 880,150 | 880,220 | ← | 445 |
| 31 | 880,955 | 881,045 | a | 445 |
| 32 | 881,096 | 881,194 | u | 446 |
| 33 | 881,227 | 881,307 | s | 447 |
| 34 | 881,368 | 881,448 | s | 448 |
| 35 | 881,470 | 881,548 | i | 449 |
| 36 | 883,293 | 883,387 | d | 470 |
| 37 | 883,449 | 883,533 | e | 471 |
| 38 | 883,547 | 883,631 | ␣ | 472 |
Table 2.
SPSFs with incomplete grammatical structures but building grammatically correct sentence versions according to our grammatical correctness definition. GCOR = grammatically correct.
Table 2.
SPSFs with incomplete grammatical structures but building grammatically correct sentence versions according to our grammatical correctness definition. GCOR = grammatically correct.
| SPSF | Gloss | GCOR |
|---|
| Alle diese Erfahrungen haben mich schlussendlich
| All these experiences have finally | Yes |
| Immerhin verbringt man doch die meiste Zeit seines Lebens mit | After all, one spends most of one’s life with | Yes |
| Und auch wir | And also we | Yes |
Table 3.
Excerpt from a sentence history showing how an SPSF evolves from SEC to SEN and back and how it can be modified while still preserving the status of SEN.
Table 3.
Excerpt from a sentence history showing how an SPSF evolves from SEC to SEN and back and how it can be modified while still preserving the status of SEN.
| SPSF | Gloss | SEN or SEC? |
|---|
| Meiner Meinung nach, bringen die Migrant:innen sehr viel Ressourcen mit, die man einsetzen und förder | In my opinion, migrants bring a lot resources with them that should be used and promot | SEC |
| Meiner Meinung nach, bringen die Migrant:innen sehr viel Ressourcen mit, die man einsetzen und fördern sollt. | In my opinion, migrants bring a lot resources with them that should be used and promote. | SEN |
| Meiner Meinung nach, bringen die Migrant:innen sehr viel Ressourcen mit, die man einsetzen und fördern sollt | In my opinion, migrants bring a lot resources with them that should be used and promote | SEC |
| Meiner Meinung nach, bringen die Migrant:innen sehr viel Ressourcen mit, die man einsetzen und fördern sollte. | In my opinion, migrants bring a lot resources with them that should be used and promoted. | SEN |
| Meiner Meinung nachbringen die Migrant:innen sehr viel Ressourcen mit, die man einsetzen und fördern sollte. | In my opinionmigrants bring a lot resources with them that should be used and promoted. | SEN |
| Meiner Meinung nach bringen die Migrant:innen sehr viel Ressourcen mit, die man einsetzen und fördern sollte. | In my opinion migrants bring a lot resources with them that should be used and promoted. | SEN |
| Meiner Meinung nach bringen die Migrant:innen sehr vielRessourcen mit, die man einsetzen und fördern sollte. | In my opinion migrants bring a lotresources with them that should be used and promoted. | SEN |
| Meiner Meinung nach bringen die Migrant:innen sehr viele Ressourcen mit, die man einsetzen und fördern sollte. | In my opinion, migrants bring a lot of resources with them that should be used and promoted. | SEN |
Table 4.
Possible positions of sentence candidates. B = beginning of TPSF, E = edge of TPSF. Bold highlights the sentence candidate considered. Last column indicates the total number of SPSFs in the example.
Table 4.
Possible positions of sentence candidates. B = beginning of TPSF, E = edge of TPSF. Bold highlights the sentence candidate considered. Last column indicates the total number of SPSFs in the example.
| SEC Position | Example | SPSFs |
|---|
| B-SEC-E | This is a story of a tortoise | 1 |
| B-PIN-SEC-E | <tab> This is a story of a tortoise | 1 |
| B-SEN-SIN-SEC-E | This is a story of a tortoise. The tortoise carries his home on his back | 2 |
| B-SEC-SEN-E | This is a story of a tortoise The tortoise carries his home on his back. | 2 |
| B-SEC-PIN-E | This is a story of a tortoise
<newline> | 1 |
| B-SEN-SIN-SEC-SEN-E | This is a story of a tortoise. The tortoise carries his home on his back No matter how hard he tries he cannot leave home. | 3 |
| B-SEN-PIN-SEC-SEN-E | This is a story of a tortoise.
<newline> The tortoise carries his home on his back No matter how hard he tries he cannot leave home. | 3 |
| B-PIN-SEC-PIN-E | <tab> This is a story of a tortoise
<newline> | 1 |
| B-SEN-SEC-SEN-E | This is a story of a tortoise. The tortoise carries his home on his back No matter how hard he tries he cannot leave home. | 3 |
Table 5.
Sentencehood criteria in relation to the type of SPSF: sentence or sentence candidate. MCOM = mechanical completeness, SCOM = syntactical completeness, CCOM = conceptual completeness, MCOR = mechanical correctness, GCOR = grammatical correctness.
Table 5.
Sentencehood criteria in relation to the type of SPSF: sentence or sentence candidate. MCOM = mechanical completeness, SCOM = syntactical completeness, CCOM = conceptual completeness, MCOR = mechanical correctness, GCOR = grammatical correctness.
| SPSF | MCOM | SCOM | CCOM | MCOR | GCOR |
|---|
| SEN | + | +/− | +/− | +/− | +/− |
| SEC | − | +/− | − | − | +/− |
Table 6.
Sentence history containing 4 SPSFs (3 SECs and 1 SEN) meeting a different set of sentencehood criteria. MCOM = mechanical completeness, SCOM = syntactical completeness, CCOM = conceptual completeness, MCOR = mechanical correctness, GCOR = grammatical correctness.
Table 6.
Sentence history containing 4 SPSFs (3 SECs and 1 SEN) meeting a different set of sentencehood criteria. MCOM = mechanical completeness, SCOM = syntactical completeness, CCOM = conceptual completeness, MCOR = mechanical correctness, GCOR = grammatical correctness.
| | SPSF | MCOM | SCOM | CCOM | MCOR | GCOR |
|---|
| Ich s (‘I s’) | SEC | − | − | − | − | − |
| Ich stehe also in direkter Re (‘So I stand in direct re’) | SEC | − | + | − | − | − |
| Ich stehe also in direkter Relation zu zwei Sprachen (‘So I stand in direct relation to two languages’) | SEC | − | + | − | − | + |
| Ich stehe also in direkter Relation zu zwei Sprachen, zwei Ländern, zwei Kulturen und zwei Gesellschaften. (‘So I stand in direct relation to two languages, two countries, two cultures, and two societies’.) | SEN | + | + | + | + | + |
Table 7.
Sentence history containing 4 SPSFs (1 SEC and 3 SENs) meeting a different set of sentencehood criteria. MCOM = mechanical completeness, SCOM = syntactical completeness, CCOM = conceptual completeness, MCOR = mechanical correctness, GCOR = grammatical correctness.
Table 7.
Sentence history containing 4 SPSFs (1 SEC and 3 SENs) meeting a different set of sentencehood criteria. MCOM = mechanical completeness, SCOM = syntactical completeness, CCOM = conceptual completeness, MCOR = mechanical correctness, GCOR = grammatical correctness.
| | SPSF | MCOM | SCOM | CCOM | MCOR | GCOR |
|---|
| Genauso wichtig ist es, wenn m (‘It is just as important when y’) | SEC | − | + | − | − | − |
| Genauso wichtig ist es, wenn man versucht zu verstehen, wie jemand anderes etwas versteht. (‘It is just as important when you try to understand how someone else understands something’.) | SEN | + | + | + | + | + |
| Genauso wichtig ist es, wenn man versuchzu verstehen, wie jemand anderes etwas versteht. (‘It is just as important when youtry to understand how someone else understands something’.) | SEN | + | + | + | − | − |
| Genauso wichtig ist es, wenn man versuchen zu verstehen, wie jemand anderes etwas versteht. (‘It is just as important when you to try to understand how someone else understands something’.) | SEN | + | + | + | + | − |
| Genauso wichtig ist es, versuchen zu verstehen, wie jemand anderes etwas versteht. (‘It is just as important to try to understand how someone else understands something’.) | SEN | + | + | + | + | + |
Table 8.
Possible sentencehood degrees.
Table 8.
Possible sentencehood degrees.
| Sentencehood Degree | Definition | Completeness Criteria | Correctness Criteria |
|---|
| Full | Complete and correct | 3/3 | 2/2 |
| Partial | | | |
| | Complete and incorrect | 3/3 | 0/2 |
| | Partially complete and incorrect | 1/3 or 2/3 | 0/2 |
| | Partially complete and partially correct | 1/3 or 2/3 | 1/2 |
| | Incomplete and correct | n/a | n/a |
| Missing | Incomplete and incorrect | 0/3 | 0/2 |
Table 9.
Example of an incorrect automated detection of sentence boundaries by spaCy.
Table 9.
Example of an incorrect automated detection of sentence boundaries by spaCy.
| Unsegmented text: | | Diese Texte wurden auf Inception annotiert, indem die Fehler in den entsprechenden Fehlerkategorien markiert wur (‘These texts have been annotated on Inception by mar the errors in the appropriate error categories’) |
| Segmented text: | (1) | Diese Texte wurden auf Inception annotiert, (‘These texts have been annotated on Inception’) |
| | (2) | indem die Fehler in den entsprechenden Fehlerkategorien markiert wur (‘by mar the errors in the appropriate error categories’) |
Table 10.
Evaluation corpus.
Table 10.
Evaluation corpus.
| Text ID | Lang. | Genre | Writer’s Age | Education Level | Number of Keystrokes |
|---|
| Children_1 | FR (L1) | essay | 11–12 | secondary school | 551 |
| Children_2 | FR (L1) | narrative | 8–9 | primary school | 334 |
| Children_3 | FR (L1) | narrative | 8–9 | primary school | 552 |
| Children_4 | FR (L1) | narrative | 10–11 | primary school | 583 |
| Translation_1 | FR (L1) | translation | young adult | university | 3769 |
| Composition_1 | FR (L1) | essay | young adult | university | 5012 |
| Composition_2 | FR (L1) | essay | young adult | university | 2417 |
| Composition_3 | FR (L1) | essay | young adult | university | 3326 |
| Composition_4 | DE (L1) | blog post | young adult | university | 2710 |
| Composition_5 | EN (L2) | blog post | young adult | university | 2653 |
Table 11.
Excerpt from manual annotation of text units.
Table 11.
Excerpt from manual annotation of text units.
| TPSF ID | Text Units | Total Text Units |
|---|
| 0 | SEN-SIN-SEN-SIN-SEN-SIN-SEN-SIN | 8 |
| 1 | SEN-SIN-SEN-SIN-SEN-SIN-SEN-SIN-SEC | 9 |
Table 12.
TU segmentation accuracy. # TPSF: number of TPSFs in text history. SEG acc.: TU segmentation accuracy (%). OER: % of over-segmented TPSFs. UER: % of under-segmented TPSFs.
Table 12.
TU segmentation accuracy. # TPSF: number of TPSFs in text history. SEG acc.: TU segmentation accuracy (%). OER: % of over-segmented TPSFs. UER: % of under-segmented TPSFs.
| Text ID | Genre | Age | # TPSF | SEG acc. | OER | UER |
|---|
| Children_1 | essay | 11–12 | 46 | 100.00 | 0.00 | 0.00 |
| Children_2 | essay | 8–9 | 21 | 100.00 | 0.00 | 0.00 |
| Children_3 | narrative | 8–9 | 21 | 95.24 | 0.00 | 4.76 |
| Children_4 | narrative | 10–11 | 32 | 12.50 | 6.25 | 81.25 |
| Composition_1 | essay | young adult | 235 | 98.30 | 1.70 | 0.00 |
| Composition_2 | essay | young adult | 69 | 92.75 | 0.00 | 7.25 |
| Composition_3 | essay | young adult | 254 | 98.82 | 0.79 | 0.39 |
| Composition_4 | blog post | young adult | 100 | 100.00 | 0.00 | 0.00 |
| Composition_5 | blog post | young adult | 217 | 99.54 | 0.00 | 0.46 |
| Translation_1 | translation | young adult | 130 | 99.23 | 0.00 | 0.77 |
| | | Average | 101 | 85.26 | 1.25 | 13.49 |
Table 13.
TU identification accuracy. # corr. TPSF: number of correctly segmented TPSF used to calculate classification accuracy. # TU: total number of extracted TUs per text. CLASS acc.: classification accuracy (%).
Table 13.
TU identification accuracy. # corr. TPSF: number of correctly segmented TPSF used to calculate classification accuracy. # TU: total number of extracted TUs per text. CLASS acc.: classification accuracy (%).
| Text ID | Genre | Age | # corr. TPSF | # TU | CLASS acc. |
|---|
| Children_1 | essay | 11-12 | 46 | 54 | 100.00 |
| Children_2 | essay | 8-9 | 21 | 22 | 100.00 |
| Children_3 | narrative | 8-9 | 21 | 23 | 100.00 |
| Children_4 | narrative | 10-11 | 4 | 4 | 100.00 |
| Composition_1 | essay | young adult | 231 | 4646 | 100.00 |
| Composition_2 | essay | young adult | 64 | 823 | 100.00 |
| Composition_3 | essay | young adult | 251 | 4868 | 100.00 |
| Composition_4 | blog post | young adult | 100 | 2419 | 100.00 |
| Composition_5 | blog post | young adult | 216 | 4744 | 100.00 |
| Translation_1 | translation | young adult | 129 | 1886 | 100.00 |
| | | Average | 103 | 1753.14 | 100.00 |
Table 14.
SPSF detection accuracy of spaCy and THEtool on the example of 4 texts. SPSF DET acc.: SPSF detection accuracy (%).
Table 14.
SPSF detection accuracy of spaCy and THEtool on the example of 4 texts. SPSF DET acc.: SPSF detection accuracy (%).
| Text ID | Genre | Age | SPSF DET acc. | SPSF DET acc. |
|---|
| | | | of SpaCy | of THEtool |
| Children_1 | essay | 11–12 | 85.10 | 100.00 |
| Children_2 | essay | 8–9 | 80.95 | 100.00 |
| Children_4 | narrative | 10–11 | 56.41 | 79.49 |
| Composition_4 | blog post | young adult | 100.00 | 100.00 |
| | | Average | 80.62 | 94.87 |
Table 15.
Example segmentation errors found in spaCy and THEtool output.
Table 15.
Example segmentation errors found in spaCy and THEtool output.
| Text ID | SPSFs by SpaCy | SPSFs by THEtool | Correct SPSFs |
|---|
| Children_1 | (SPSF 1) Ce que je pense de la violence (SPSF 2) c’est que al | (SPSF 1) Ce que je pense de la violence c’est que al | (SPSF 1) Ce que je pense de la violence c’est que al |
| | (SPSF 1) ‘What I think of violence’ (SPSF 2) ‘is that ats’ | (SPSF 1) ‘What I think of violence is that ats’ | (SPSF 1) ‘What I think of violence is that ats’ |
| Children_2 | (SPSF 1) Je pance que la violance a l’ecole est un peut i peut tros danjereut il y a de la bagare de l’insuletans et (SPSF 2) de | (SPSF 1) Je pance que la violance a l’ecole est un peut i peut tros danjereut il y a de la bagare de l’insuletans et de | (SPSF 1) Je pance que la violance a l’ecole est un peut i peut tros danjereut il y a de la bagare de l’insuletans et de |
| | (SPSF 1) ‘I think that violance at school is a litle bitt too danjerous there are fites insultings and ’ (SPSF 2) ‘de’ | (SPSF 1) ‘I think that violance at school is a litle bitt too danjerous there are fites insultings and de’ | (SPSF 1) ‘I think that violance at school is a litle bitt too danjerous there are fites insultings and de’ |
| Children_4 | (SPSF 1) Elle vat giffler (SPSF 2) shazya puie ainsi de suite. | (SPSF 1) Elle vat giffler shazya puie ainsi de suite. | (SPSF 1) Elle vat giffler shazya puie ainsi de suite. |
| | (SPSF 1) ‘She gos an slaps’ (SPSF 2) ‘shazya an so on’. | (SPSF 1) Elle vat giffler shazya puie ainsi de suite. | (SPSF 1) Elle vat giffler shazya puie ainsi de suite. |
| Children_4 | (SPSF 1) Il était une fois ,à l’ école des enfants avec leurs amis qui joue au loup .Tout d, | (SPSF 1) Il était une fois ,à l’ école des enfants avec leurs amis qui joue au loup .Tout d, | (SPSF 1) Il était une fois ,à l’ école des enfants avec leurs amis qui joue au loup . (SPSF 2) Tout d, |
| | (SPSF 1) ‘Once upon a time ,at school children with their friends were playing tag .Sudd’ | (SPSF 1) ‘Once upon a time ,at school children with their friends were playing tag .Sudd’ | (SPSF 1) ‘Once upon a time ,at school children with their friends were playing tag .’ (SPSF 2) ‘Sudd’ |
Table 16.
Excerpt from manual annotation of sentence histories.
Table 16.
Excerpt from manual annotation of sentence histories.
| Sentence History ID | TPSF ID | Position in Text | SPSF Text |
|---|
| 101877 | 0 | 1 | il etait une foi |
| 101882 | 2 | 1 | i |
| 101886 | 4 | 1 | Il etait ue |
| 101886 | 5 | 1 | Il etait u |
| 101886 | 6 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copinee |
| 101886 | 7 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copine |
| 101886 | 8 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copine et touta |
| 101886 | 9 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copine et tout |
| 101886 | 10 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copine et tout aje |
| 101886 | 11 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copine et tout a |
| 101886 | 12 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copine et tout a je mm |
| 101886 | 13 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copine et tout a je m |
| 101886 | 14 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copine et tout a je me suis retour |
| 101886 | 15 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copine et tout a |
| 101886 | 16 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copine et tout a cout je me suis retour nait et il y a un eleve qui ma tape la et qui ma pousse par terre. |
| 101886 | 17 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copine et tout a cout je me suis retour nait et il y a un eleve qui ma tape la et qui ma pousse par t |
| 101886 | 18 | 1 | Il etait une fois cans on sortait de la classe j’ai jouer avec mait copine et tout a cout je me suis retour nait et il y a un eleve qui ma tape la et qui ma pousse par terre. |
Table 17.
Sentence history aggregation results. # senhis: number of sentence histories in reference corpus. P: precision. R: recall. F1: F1 score. Metrics are macro-averaged.
Table 17.
Sentence history aggregation results. # senhis: number of sentence histories in reference corpus. P: precision. R: recall. F1: F1 score. Metrics are macro-averaged.
| Text ID | Genre | Age | # senhis | P | R | F1 |
|---|
| Children_1 | essay | 11–12 | 2 | 1.00 | 1.00 | 1.00 |
| Children_2 | essay | 8–9 | 1 | 1.00 | 1.00 | 1.00 |
| Children_3 | narrative | 8–9 | 7 | 0.71 | 0.70 | 0.71 |
| Children_4 | narrative | 10–11 | 11 | 0.82 | 0.80 | 0.81 |
| Composition_1 | essay | young adult | 28 | 1.00 | 1.00 | 1.00 |
| Composition_2 | essay | young adult | 12 | 1.00 | 1.00 | 1.00 |
| Composition_3 | essay | young adult | 18 | 1.00 | 1.00 | 1.00 |
| Composition_4 | blog post | young adult | 30 | 0.94 | 0.94 | 0.94 |
| Composition_5 | blog post | young adult | 24 | 0.92 | 0.92 | 0.92 |
| Translation_1 | translation | young adult | 15 | 1.00 | 1.00 | 1.00 |
| | | Average | 14.80 | 0.94 | 0.94 | 0.94 |
Table 18.
Excerpt from manual annotation of sentencehood. MCOM = mechanical completeness, SCOM = syntactic completeness, CCOM = conceptual completeness, MCOR = mechanical correctness, GCOR = grammatical correctness.
Table 18.
Excerpt from manual annotation of sentencehood. MCOM = mechanical completeness, SCOM = syntactic completeness, CCOM = conceptual completeness, MCOR = mechanical correctness, GCOR = grammatical correctness.
| Sentence History ID | Sentence Text | MCOM | CCOM | SCOM | MCOR | GCOR |
|---|
| 146291 | Wenn ich meine bisherige berufliche Laufbahn ber (‘When I lok at my professional career so far’) | | | | MCOR | GCOR |
| 146291 | Wenn ich meine bisherige berufliche Laufbahn be (‘When I lo at my professional career so far’) | | | | MCOR | GCOR |
| 146291 | Wenn ich meine bisherige berufliche Laufbahn betrachte (‘When I look back at my professional career so far’) | | | | MCOR | GCOR |
| 146291 | Wenn ich meine bisherige berufliche Laufbahn betrachte muss ich feststellen, dass ich sehr vielseitige Br (‘When I look back at my professional career so far, I have to say that I very varied po’) | | | SCOM | MCOR | GCOR |
| 146291 | Wenn ich meine bisherige berufliche Laufbahn betrachte muss ich feststellen, dass ich sehr vielseitige B (‘When I look back at my professional career so far, I have to say that I very varied p’) | | | SCOM | MCOR | GCOR |
| 146291 | Wenn ich meine bisherige berufliche Laufbahn betrachte muss ich feststellen, dass ich sehr vielseitige Berufserfahrungen machen durfte. (‘When I look at my professional career so far, I have to say that I have been able to gain very varied professional experience’.) | MCOM | CCOM | SCOM | MCOR | GCOR |
Table 19.
Sentencehood detection results. # occurrences: number of SPSFs which were assigned to the particular category. P: precision. R: recall. F1: F1 score. Metrics are macro-averaged.
Table 19.
Sentencehood detection results. # occurrences: number of SPSFs which were assigned to the particular category. P: precision. R: recall. F1: F1 score. Metrics are macro-averaged.
| Sentencehood Category | # occurrences | P | R | F1 |
|---|
| Mechanical completeness | 92 | 1.00 | 1.00 | 1.00 |
| Syntactic completeness | 378 | 0.98 | 0.99 | 0.98 |
| Conceptual completeness | 65 | 1.00 | 1.00 | 1.00 |
| Mechanical correctness | 59 | 0.86 | 0.81 | 0.83 |
| Grammatical correctness | 465 | 0.97 | 0.99 | 0.98 |
| Average | 211.8 | 0.96 | 0.96 | 0.96 |
Table 20.
Examples of errors in the syntactic completeness detection.
Table 20.
Examples of errors in the syntactic completeness detection.
| Sentence History ID | Sentence Text | SCOM (Manual) | SCOM (THEtool) |
|---|
| 146291 | Wenn ich meine bisherige berufliche Laufbahn betrachte (‘When I look at my professional career so far’) | No | Yes |
| 221283 | Wenn Menschen in das Land migrieren (‘When people migrate to the country’) | No | Yes |
| 352745 | Jahre später, als ich mich schon in Verzweiflung wiegte, weil ich absolut nciht (‘Years later, when I was already in despair because I absolutely could nto’) | No | No |
| 300739 | Eigentlich ist e (‘Actually i is’) | No | Yes |
| 185864 | Natürlich waren die meixsten (‘Of course mst were’) | No | Yes |
| 352745 | Alle diese Erfahrungen hab (‘All these experiences ha’) | No | Yes |
| 300741 | Und auch wir wärn (‘And we woud also’) | No | Yes |
Table 21.
Examples of differences in the detection of grammatical correctness between a human annotator and THEtool.
Table 21.
Examples of differences in the detection of grammatical correctness between a human annotator and THEtool.
| Sentence History ID | Sentence Text | GCOR (Manual) | GCOR (THEtool) |
|---|
| 300739 | So habe ich nach anderen Möglichkeitn gäbe und bin auf den Studiengang ’Sprachliche Integration’ gestossen. (‘So I looked for other optios would be and came across the degree programme ‘Linguistic Integration’.’) | No | Yes |
| 185273 | Integration sowie die gesellschaftliche Partizipation geschieht zu einem seh (‘Integration and social participation happen at a ver’) | Yes | No |
Table 22.
Examples of differences in the automated detection of grammatical correctness between SPSFs containing incomplete or incorrect words and SPSFs where all words are complete.
Table 22.
Examples of differences in the automated detection of grammatical correctness between SPSFs containing incomplete or incorrect words and SPSFs where all words are complete.
| Sentence History ID | Sentence Text | GCOR (Manual) | GCOR (THEtool) |
|---|
| 300741 | Und auch wir wärn (‘And we woud also’) | No | Yes |
| 300741 | Und auch wir wär (‘And we wou also’) | No | No |
| 185273 | Integration sowie die gesellschaftliche Partizipation geschieht zu einem seh (‘Integration and social participation happen at a ver’) | Yes | No |
| 185273 | Integration sowie die gesellschaftliche Partizipation geschieht zu einem (‘Integration and social participation happen at a’) | Yes | Yes |
Table 23.
Examples of errors in the automated detection of mechanical correctness.
Table 23.
Examples of errors in the automated detection of mechanical correctness.
| Sentence History ID | Sentence Text | GCOR (Manual) | GCOR (THEtool) |
|---|
| 185272 | Diese Ausgrenzung der Minderheitsgesellschaften kann zu einem grossen Teil verhindert werden, wenn sich ausländische Personen schnell integrieren. (‘This exclusion of minority communities can be prevented to a large extent if foreigners integrate quickly’.) | Yes | No |
| 300740 | Ich kenne viele Menschen, die eine Arbeit haben die sie nicht erfüllt. (‘I know many people who have a job that does not fulfil them’.) | No | Yes |
Table 24.
Sentence versions with minor differences.
Table 24.
Sentence versions with minor differences.
| Sentence Version | SPSF | Gloss |
|---|
| 0 | il etait une foi | ‘once upon a time’ |
| 1 | | |
| 2 | i | |
| 3 | | |
| 4 | Il etait ue | ‘once upon an’ |
Table 25.
Sentence versions with shared surface content and syntactic/semantic differences.
Table 25.
Sentence versions with shared surface content and syntactic/semantic differences.
| Sentence Version | SPSF | Gloss |
|---|
| 0 | il etait une foi | ‘once upon a time’ |
| 1 | il | ‘he/it’ |
| 2 | il a décidé de | ‘he decided that’ |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}