
Integrating Morphosyntactic and Visual Cues in L1 and L2 Comprehension


Abstract
:1. Introduction
2. Background
2.1. The Role of Visual Cues in L1 Sentence Comprehension
2.2. Syntactic and Non-Syntactic Cues in L1 vs. L2 Sentence Comprehension
2.3. Individual Variability in L1 and L2 Sentence Comprehension
3. Aims and Research Questions
- How do (task-unrelated) visual cues influence thematic-role assignment in unambiguous sentences in L1 and L2 speakers?
- Does individual sensitivity to morphosyntactic cues predict speakers’ sensitivity to visual cues?
4. Methods
4.1. Design
4.2. Participants
4.3. Materials
4.3.1. Spoken Sentences (Experiments 1 and 2)
4.3.2. Picture Stimuli (Experiment 2)
4.3.3. Probe Questions (Experiments 1 and 2)
4.4. Procedure
4.4.1. Screening Questionnaire
4.4.2. German Proficiency Assessment
4.4.3. Comprehension Task
4.5. Data Analyses
5. Experiment 1
5.1. Predictions
5.1.1. Replication of Subject Preference and L1 Advantage
5.1.2. Individual Proxies of Sensitivity to Morphosyntax
5.2. Results
5.2.1. Descriptives
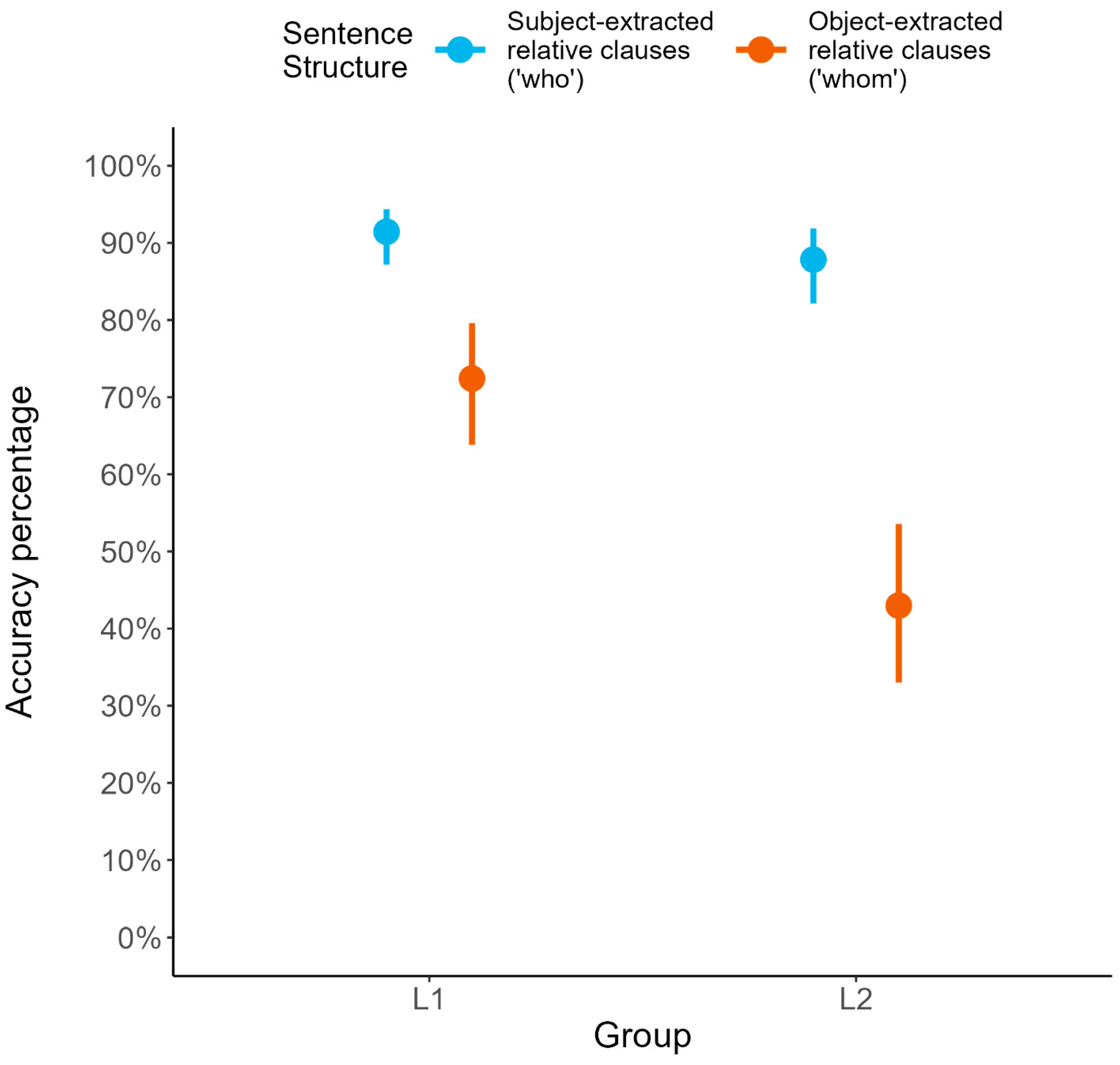
5.2.2. Replication of Group-Level Subject-Preference and L1 Advantage
5.2.3. Individual Differences in Sensitivity to Morphosyntactic Cues
6. Experiment 2
6.1. Predictions
6.1.1. Research Question 1: Visual Influences on L1 and L2 Sentence Comprehension
6.1.2. Research Question 2: The Effect of Morphosyntactic Sensitivity on Visual-Cue Weighting
6.2. Results
6.2.1. Descriptives
6.2.2. Research Question 1: Visual Influences on L1 and L2 Sentence Comprehension
6.2.3. Research Question 2: Role of Morphosyntactic Sensitivity for Visual-Cue Weighting
7. Discussion
7.1. Replication of Agent-Before-Patient Preference and L1 Advantage
7.2. Research Question 1: Influence of Visual Cues on L1 and L2 Sentence Comprehension
7.3. Research Question 2: Role of Morphosyntactic Sensitivity for Visual-Cue Weighting
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | By coding proficiency with Helmert contrasts, we compared sensitivity scores at each proficiency level (native, C1, B2 and B1+A2) to the average scores of all preceding levels (i.e., native vs. C1, native+C1 vs. B2, etc.). |
| 2 | For the follow-up analyses on the effect of sensitivity, the effect of interest was measured at the lowest and highest values of the continuous sensitivity scale. This is achieved with the argument cov.reduce = range in the emmeans function (Lenth 2022). Follow-up analyses of categorical predictors are instead performed at the mean value of the sensitivity range across the whole sample. |
References
- Allopenna, Paul D., James S. Magnuson, and Michael K. Tanenhaus. 1998. Tracking the time course of spoken word recognition using eye movements: Evidence for continuous mapping models. Journal of Memory and Language 38: 419–39. [Google Scholar] [CrossRef]
- Altmann, Gerry T. M., and Yuki Kamide. 1999. Incremental interpretation at verbs: Restricting the domain of subsequent reference. Cognition 73: 247–64. [Google Scholar] [CrossRef] [PubMed]
- Altmann, Gerry T. M., and Yuki Kamide. 2009. Discourse-mediation of the mapping between language and the visual world: Eye movements and mental representation. Cognition 111: 55–71. [Google Scholar] [CrossRef] [PubMed]
- Arnaudova, Olga, Wayles Browne, María Luisa Rivero, and Danijela Stojanovic. 2004. Relative clause attachment in Bulgarian. In Annual Workshop on Formal Approaches to Slavic Languages. Ann Arbor: Michigan Slavic Publications. [Google Scholar]
- Bader, Markus, and Jana Häussler. 2010. Word order in German: A corpus study. Lingua 120: 717–62. [Google Scholar] [CrossRef]
- Bader, Markus, and Michael Meng. 2018. The misinterpretation of noncanonical sentences revisited. Journal of Experimental Psychology: Learning Memory and Cognition 44: 1286–1311. [Google Scholar] [CrossRef]
- Bader, Markus, and Michael Meng. 2023. Processing noncanonical sentences: Effects of context on online processing and (mis)interpretation. Glossa Psycholinguistics 2: 1–45. [Google Scholar] [CrossRef]
- Barsalou, Lawrence W. 1999. Perceptual symbol systems. Behavioral and Brain Sciences 22: 577–660. [Google Scholar] [CrossRef] [PubMed]
- Barsalou, Lawrence W. 2008. Grounded cognition. Annual Review of Psychology 59: 617–45. [Google Scholar] [CrossRef]
- Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Bates, Elizabeth, and Brian MacWhinney. 1982. Functionalist approaches to grammar. In Language Acquisition: The State of the Art. Edited by Eric Wanner and Lila Gleitman. New York: Cambridge University Press. [Google Scholar]
- Bates, Elizabeth, and Brian MacWhinney. 1989. Functionalism and the Competition Model. In The Crosslinguistic Study of Sentence Processing. Edited by Elizabeth Bates and Brian MacWhinney. New York: Cambridge University Press, pp. 3–76. [Google Scholar]
- Bates, Elizabeth, Sandra McNew, Brian MacWhinney, Antonella Devescovi, and Stan Smith. 1982. Functional constraints on sentence processing: A cross-linguistic study. Cognition 11: 245–99. [Google Scholar] [CrossRef]
- Benţea, Anamaria. 2012. Does “Case” Matter in the Acquisition of Relative Clauses in Romanian? In Proceedings of the 26th Annual Boston University Conference on Child Language Development, Boston, MA, USA, November 2–4; Edited by Alia Biller, Esther Chung and Amelia Kimball. Somerville: Cascadilla Press, pp. 1–12. [Google Scholar]
- Carpenter, Patricia A., and Marcel A. Just. 1975. Sentence comprehension: A psycholinguistic processing model of verification. Psychological Review 82: 45–73. [Google Scholar] [CrossRef]
- Chambers, Craig G., Michael K. Tanenhaus, and James S. Magnuson. 2004. Actions and affordances in syntactic ambiguity resolution. Journal of Experimental Psychology: Learning Memory and Cognition 30: 687–96. [Google Scholar] [CrossRef] [PubMed]
- Christianson, Kiel, Steven G. Luke, and Fernanda Ferreira. 2010. Effects of plausibility on structural priming. Journal of Experimental Psychology: Learning Memory and Cognition 36: 538–44. [Google Scholar] [CrossRef] [PubMed]
- Christianson, Kiel. 2016. When language comprehension goes wrong for the right reasons: Good-enough, underspecified, or shallow language processing. Quarterly Journal of Experimental Psychology 69: 817–28. [Google Scholar] [CrossRef]
- Chromý, Jan. 2022. When readers fail to form a coherent representation of garden-path sentences. Quarterly Journal of Experimental Psychology 75: 169–90. [Google Scholar] [CrossRef]
- Citko, Barbara. 2016. Types of appositive relative clauses in Polish. Studies in Polish Linguistics 11: 85–110. [Google Scholar] [CrossRef]
- Clahsen, Harald, and Claudia Felser. 2006. Grammatical processing in language learners. Applied Psycholinguistics 27: 3–42. [Google Scholar] [CrossRef]
- Clahsen, Harald, and Claudia Felser. 2018. Some notes on the Shallow Structure Hypothesis. Studies in Second Language Acquisition 40: 1–14. [Google Scholar] [CrossRef]
- Clark, Herbert H., and William G. Chase. 1972. On the process of comparing sentences against pictures. Cognitive Psychology 3: 472–517. [Google Scholar] [CrossRef]
- Coltheart, Max. 1999. Modularity and cognition. Trends in Cognitive Sciences 3: 115–20. [Google Scholar] [CrossRef]
- Cooper, Roger M. 1974. Control of Eye Fixation By the Meaning of Spoken Language. Cognitive Psychology 107: 166–68. [Google Scholar] [CrossRef]
- Council of Europe. 2011. Common European Framework of References for Languages: Learning, Teaching, Assessment. Cambridge: Cambridge University Press. Available online: https://rm.coe.int/1680459f97 (accessed on 16 November 2022).
- Cunnings, Ian, and Hiroki Fujita. 2021. Similarity-based interference and relative clauses in second language processing. Second Language Research 39: 1–25. [Google Scholar] [CrossRef]
- Cunnings, Ian, Georgia Fotiadou, and Ianthi Tsimpli. 2017. Anaphora resolution and reanalysis during L2 sentence processing. Studies in Second Language Acquisition 39: 621–52. [Google Scholar] [CrossRef]
- Cunnings, Ian. 2017. Parsing and working memory in bilingual sentence processing. Bilingualism 20: 659–78. [Google Scholar] [CrossRef]
- den Ouden, Dirk-Bart, Michael Walsh Dickey, Catherine Anderson, and Kiel Christianson. 2016. Neural correlates of early-closure garden-path processing: Effects of prosody and plausibility. Quarterly Journal of Experimental Psychology 69: 926–49. [Google Scholar] [CrossRef] [PubMed]
- Deniz, Nazik Dinçtopal. 2022. Processing syntactic and semantic information in the L2: Evidence for differential cue-weighting in the L1 and L2. Bilingualism 25: 713–25. [Google Scholar] [CrossRef]
- Díaz, Begoña, Kepa Erdocia, Robert F. De Menezes, Jutta L. Mueller, Núria Sebastián-Gallés, and Itziar Laka. 2016. Electrophysiological correlates of second-language syntactic processes are related to native and second language distance regardless of age of acquisition. Frontiers in Psychology 7: 133. [Google Scholar] [CrossRef]
- Farmer, T. A., J. B. Misyak, and M. H. Christiansen. 2012. Individual differences in second language sentence processing. In The Cambridge Handbook of Psycholinguistics. Edited by Michael J. Spivey, Marc F. Joannisse and Ken McRae. Cambridge: Cambridge University Press, pp. 353–64. [Google Scholar] [CrossRef]
- Felser, Claudia, and Ian Cunnings. 2012. Processing reflexives in a second language: The timing of structural and discourse-level constraints. Applied Psycholinguistics 33: 571–603. [Google Scholar] [CrossRef]
- Felser, Claudia, Leah Roberts, Theodore Marinis, and Rebecca Gross. 2003. The processing of ambiguous sentences by first and second language learners of English. Applied Psycholinguistics 24: 453–89. [Google Scholar] [CrossRef]
- Ferreira, Fernanda, and Nikole D. Patson. 2007. The ‘Good Enough’ approach to language comprehension. Language and Linguistics Compass 1: 71–83. [Google Scholar] [CrossRef]
- Ferreira, Fernanda. 2003. The misinterpretation of noncanonical sentences. Cognitive Psychology 47: 164–203. [Google Scholar] [CrossRef] [PubMed]
- Fodor, Jerry A. 1983. The Modularity of Mind. Cambridge: MIT Press. [Google Scholar]
- Folk, Jocelyn R., and Robin K. Morris. 2003. Effects of syntactic category assignment on lexical ambiguity resolution in reading: An eye movement analysis. Memory and Cognition 31: 87–99. [Google Scholar] [CrossRef] [PubMed]
- Foucart, Alice, Xavier Garcia, Meritxell Ayguasanosa, Guillaume Thierry, Clara Martin, and Albert Costa. 2015. Does the speaker matter? Online processing of semantic and pragmatic information in L2 speech comprehension. Neuropsychologia 75: 291–303. [Google Scholar] [CrossRef] [PubMed]
- Frazier, Lyn, and Janet Dean Fodor. 1978. The sausage machine: A new two-stage parsing model. Cognition 6: 291–325. [Google Scholar] [CrossRef]
- Frazier, Lyn, and Keith Rayner. 1982. Making and correcting errors during sentence comprehension: Eye movements in the analysis of structurally ambiguous sentences. Cognitive Psychology 14: 178–210. [Google Scholar] [CrossRef]
- Friederici, Angela D. 2002. Towards a neural basis of auditory sentence processing. Trends in Cognitive Sciences 6: 78–84. [Google Scholar] [CrossRef]
- Gerth, Sabrina, Constanze Otto, Claudia Felser, and Yunju Nam. 2017. Strength of garden-path effects in native and non-native speakers' processing of subject-object ambiguities. International Journal of Bilingualism 21: 125–44. [Google Scholar] [CrossRef]
- Gibson, Edward. 1992. On the Adequacy of the Competition Model. Language 68: 812–30. [Google Scholar] [CrossRef]
- Grüter, Theres, Elaine Lau, and Wenyi Ling. 2020. How classifiers facilitate predictive processing in L1 and L2 Chinese: The role of semantic and grammatical cues. Language, Cognition and Neuroscience 35: 221–34. [Google Scholar] [CrossRef]
- Hagoort, Peter. 2003. Interplay between syntax and semantics during sentence comprehension: ERP effects of combining syntactic and semantic violations. Journal of Cognitive Neuroscience 15: 883–99. [Google Scholar] [CrossRef]
- Hahne, Anja, and Jörg D. Jescheniak. 2001. What’s left if the Jabberwock gets the semantics? An ERP investigation into semantic and syntactic processes during auditory sentence comprehension. Cognitive Brain Research 11: 199–212. [Google Scholar] [CrossRef] [PubMed]
- Hopp, Holger. 2015. Individual differences in the second language processing of object-subject ambiguities. Applied Psycholinguistics 36: 129–73. [Google Scholar] [CrossRef]
- Jackson, Carrie N., and Susan C. Bobb. 2009. The processing and comprehension of wh-questions among second language speakers of German. Applied Psycholinguistics 30: 603–36. [Google Scholar] [CrossRef] [PubMed]
- Jackson, Carrie. 2008. Proficiency level and the interaction of lexical and morphosyntactic information during L2 sentence processing. Language Learning 58: 875–909. [Google Scholar] [CrossRef]
- Jacob, Gunnar, and Claudia Felser. 2016. Reanalysis and semantic persistence in native and non-native garden-path recovery. Quarterly Journal of Experimental Psychology 69: 907–25. [Google Scholar] [CrossRef]
- Kamide, Yuki, Christoph Scheepers, and Gerry T. M. Altmann. 2003. Integration of Syntactic and Semantic Information in Predictive Processing: Cross-Linguistic Evidence from German and English. Journal of Psycholinguistic Research 32: 37–55. [Google Scholar] [CrossRef]
- Karimi, Hossein, and Fernanda Ferreira. 2016. Good-enough linguistic representations and online cognitive equilibrium in language processing. Quarterly Journal of Experimental Psychology 69: 1013–40. [Google Scholar] [CrossRef]
- Kempe, Vera, and Brian MacWhinney. 1998. The acquisition of case marking by adult learners of Russian and German. Studies in Second Language Acquisition 20: 543–87. [Google Scholar] [CrossRef]
- Kempe, Vera, and Brian MacWhinney. 1999. Processing of morphological and semantic cues in Russian and German. Language and Cognitive Processes 14: 129–71. [Google Scholar] [CrossRef]
- Kidd, Evan, Seamus Donnelly, and Morten H. Christiansen. 2018. Individual differences in language acquisition and processing. Trends in Cognitive Sciences 22: 154–69. [Google Scholar] [CrossRef]
- Kilborn, Kerry. 1992. On-line integration of grammatical information in a second language. Advances in Psychology 83: 337–50. [Google Scholar] [CrossRef]
- King, Jonathan, and Marcel Adam Just. 1991. Individual differences in syntactic processing: The role of working memory. Journal of Memory and Language 30: 580–602. [Google Scholar] [CrossRef]
- Knoeferle, Pia, and Helene Kreysa. 2012. Can speaker gaze modulate syntactic structuring and thematic role assignment during spoken sentence comprehension? Frontiers in Psychology 3: 1–15. [Google Scholar] [CrossRef] [PubMed]
- Knoeferle, Pia, and Matthew W. Crocker. 2005. Incremental effects of mismatch during picture-sentence integration: Evidence from eye-tracking. Paper present at 26th Annual Conference of the Cognitive Science Society, Nashville, Tennessee, August 1–4; pp. 1166–71. [Google Scholar]
- Knoeferle, Pia, and Matthew W. Crocker. 2006. The coordinated interplay of scene, utterance, and world knowledge: Evidence from eye tracking. Cognitive Science 30: 481–529. [Google Scholar] [CrossRef]
- Knoeferle, Pia, and Matthew W. Crocker. 2007. The influence of recent scene events on spoken comprehension: Evidence from eye movements. Journal of Memory and Language 57: 519–43. [Google Scholar] [CrossRef]
- Knoeferle, Pia, Matthew W. Crocker, Christoph Scheepers, and Martin J. Pickering. 2005. The influence of the immediate visual context on incremental thematic role-assignment: Evidence from eye-movements in depicted events. Cognition 95: 95–127. [Google Scholar] [CrossRef]
- Knoeferle, Pia, Thomas P. Urbach, and Marta Kutas. 2011. Comprehending how visual context influences incremental sentence processing: Insights from ERPs and picture-sentence verification. Psychophysiology 48: 495–506. [Google Scholar] [CrossRef]
- Knoeferle, Pia, Thomas P. Urbach, and Marta Kutas. 2014. Different mechanisms for role relations versus verb-action congruence effects: Evidence from ERPs in picture-sentence verification. Acta Psychologica 152: 133–48. [Google Scholar] [CrossRef]
- Knoeferle, Pia. 2007. Comparing the time course of processing initially ambiguous and unambiguous German Svo/ovs sentences in depicted events. In Eye Movements: A Window on Mind and Brain. Edited by Roger P. G. van Gompel, Martin H. Fischer, Wayne S. Murray and Robin L. Hill. Amsterdam: Elsevier, pp. 517–33. [Google Scholar] [CrossRef]
- Knoeferle, Pia. 2016. Characterising visual context effects: Active, pervasive, but resource-limited. In Visually Situated Language Comprehension. Edited by Pia Knoeferle, Pirita Pyykkönen-Klauck and Matthew W. Crocker. Amsterdam: John Benjamins Publishing Company, pp. 227–60. [Google Scholar] [CrossRef]
- Knoeferle, Pia, and Ernesto Guerra. 2016. Visually Situated Language Comprehension. Language and Linguistics Compass 10: 66–82. [Google Scholar] [CrossRef]
- Knoeferle, Pia. 2019. Predicting (variability of) context effects in language comprehension. Journal of Cultural Cognitive Science 3: 141–58. [Google Scholar] [CrossRef]
- Kreysa, Helene, Eva Nunnemann, and Pia Knoeferle. 2018. Distinct effects of different visual cues on sentence comprehension and later recall: The case of speaker gaze versus depicted actions. Acta Psychologica 188: 220–29. [Google Scholar] [CrossRef] [PubMed]
- Kuperberg, Gina R. 2007. Neural mechanisms of language comprehension: Challenges to syntax. Brain Research 1146: 23–49. [Google Scholar] [CrossRef] [PubMed]
- Lardiere, Donna. 1998. Case and tense in a ‘fossilized’ steady state. Second Language Research 14: 1–26. [Google Scholar] [CrossRef]
- Leal, Tania, Roumyana Slabakova, and Thomas A. Farmer. 2017. The fine-tuning of linguistic expectations over the course of L2 learning. Studies in Second Language Acquisition 39: 493–525. [Google Scholar] [CrossRef]
- Lee, Juyoung, and Jeffrey Witzel. 2022. Plausibility and structural reanalysis in L1 and L2 sentence comprehension. Quarterly Journal of Experimental Psychology 76: 319–37. [Google Scholar] [CrossRef]
- Lenth, Russell. 2022. emmeans: Estimated Marginal Means, aka Least-Squares Means. Available online: https://cran.r-project.org/package=emmeans (accessed on 12 December 2022).
- Levy, Roger, Evelina Fedorenko, and Edward Gibson. 2013. The syntactic complexity of Russian relative clauses. Journal of Memory and Language 69: 461–95. [Google Scholar] [CrossRef]
- Lüdecke, Daniel. 2018. sjPlot: Data Visualization for Statistics in Social Science. Available online: https://cran.r-project.org/package=sjPlot (accessed on 28 February 2021).
- MacWhinney, Brian, and Csaba Pleh. 1997. Double agreement: Role identification in Hungarian. Language and Cognitive Processes 12: 67–102. [Google Scholar] [CrossRef]
- MacWhinney, Brian, Elizabeth Bates, and Reinhold Kliegl. 1984. Cue validity and sentence interpretation in English, German, and Italian. Journal of Verbal Learning and Verbal Behavior 23: 127–50. [Google Scholar] [CrossRef]
- MacWhinney, Brian. 2002. Extending the Competition Model. In Bilingual Sentence Processing. Edited by Roberto R. Heredia and Jeanette Altarriba. Amsterdam: Elsevier Science B. V., pp. 31–57. [Google Scholar]
- MacWhinney, Brian. 2005. Second language acquisition and the Competition Model. In Tutorials in Bilingualism: Psycholinguistic Perspectives. Edited by Annette M. B. de Groot and Judith F. Kroll. Mahwah: Lawrence Erlbaum Associates, pp. 113–42. [Google Scholar]
- Marian, Viorica, Henrike K. Blumenfeld, and Margarita Kaushanskaya. 2007. The Language Experience and Proficiency Questionnaire (LEAP-Q): Assessing language profiles in bilinguals and multilinguals. Journal of Speech Language and Hearing Research 50: 940. [Google Scholar] [CrossRef]
- McRae, Ken, and Kazunaga Matsuki. 2013. Constraint-based models of sentence processing. In Sentence Processing, 1st ed. Edited by Roger P. G. van Gompel. New York: Psychology Press, pp. 51–77. [Google Scholar]
- Meng, Michael, and Markus Bader. 2021. Does comprehension (sometimes) go wrong for noncanonical sentences? Quarterly Journal of Experimental Psychology 74: 1–28. [Google Scholar] [CrossRef]
- Mirman, Daniel, and James S. Magnuson. 2009. Dynamics of activation of semantically similar concepts during spoken word recognition. Memory and Cognition 37: 1026–39. [Google Scholar] [CrossRef] [PubMed]
- Mitsugi, Sanako, and Brian MacWhinney. 2016. The use of case marking for predictive processing in second language Japanese. Bilingualism 19: 19–35. [Google Scholar] [CrossRef]
- Morgan-Short, Kara, Cristina Sanz, Karsten Steinhauer, and Michael T. Ullman. 2010. Second language acquisition of gender agreement in explicit and implicit training conditions: An event-related potential study. Language Learning 60: 154–93. [Google Scholar] [CrossRef] [PubMed]
- Osterhout, Lee. 1997. On the brain response to syntactic anomalies: Manipulations of word position and word class reveal individual differences. Brain and Language 59: 494–522. [Google Scholar] [CrossRef] [PubMed]
- Pakulak, Eric, and Helen J. Neville. 2010. Proficiency differences in syntactic processing of monolingual native speakers indexed by event-related potentials. Journal of Cognitive Neuroscience 22: 2728–2744. [Google Scholar] [CrossRef]
- Pakulak, Eric, and Helen J. Neville. 2011. Maturational constraints on the recruitment of early processes for syntactic processing. Journal of Cognitive Neuroscience 23: 2752–65. [Google Scholar] [CrossRef]
- Pan, Hui-Yu, and Claudia Felser. 2011. Referential context effects in L2 ambiguity resolution: Evidence from self-paced reading. Lingua 121: 221–36. [Google Scholar] [CrossRef]
- Pan, Hui-Yu, Sarah Schimke, and Claudia Felser. 2015. Referential context effects in non-native relative clause ambiguity resolution. International Journal of Bilingualism 19: 298–313. [Google Scholar] [CrossRef]
- Papadopoulou, Despina, and Harald Clahsen. 2003. Parsing strategies in L1 and L2 sentence processing. Studies in Second Language Acquisition 25: 501–28. [Google Scholar] [CrossRef]
- Patterson, Clare, Yulia Esaulova, and Claudia Felser. 2017. The impact of focus on pronoun resolution in native and non-native sentence comprehension. Second Language Research 33: 403–29. [Google Scholar] [CrossRef]
- Pearlmutter, Neal J., and Maryellen C. MacDonald. 1995. Individual differences and probabilistic constraints in syntactic ambiguity resolution. Journal of Memory and Language 34: 521–42. [Google Scholar] [CrossRef]
- Pozzan, Lucia, and John C. Trueswell. 2016. Second language processing and revision of garden-path sentences: A visual word study. Bilingualism 19: 636–43. [Google Scholar] [CrossRef] [PubMed]
- Psychology Software Tools, Inc. 2016. E-Prime 3.0. Available online: https://pstnet.com/ (accessed on 3 April 2023).
- Psychology Software Tools, Inc. 2020. E-Prime Go. Available online: https://pstnet.com/ (accessed on 3 April 2023).
- Puebla, Cecilia, and Claudia Felser. 2022. Discourse prominence and antecedent mis-retrieval during native and non-native pronoun resolution. Discours, 29. [Google Scholar] [CrossRef]
- Rankin, Tom. 2014. Word order and case in the comprehension of L2 German by L1 English speakers. EuroSLA Yearbook, 201–24. [Google Scholar] [CrossRef]
- Roberts, Leah, and Claudia Felser. 2011. Plausibility and recovery from garden paths in second language sentence processing. Applied Psycholinguistics 32: 299–331. [Google Scholar] [CrossRef]
- Rosenblum, Lawrence D. 2005. Primacy of multimodal speech perception. In The Handbook of Speech Perception. Edited by David B. Pisoni and Robert E. Remez. Malden: Blackwell, pp. 51–78. [Google Scholar]
- Rosenblum, Lawrence D. 2008. Speech perception as a multimodal phenomenon. Current Directions in Psychological Science 17: 405–409. [Google Scholar] [CrossRef]
- Rossi, Sonja, Manfred F. Gugler, Angela D. Friederici, and Anja Hahne. 2006. The impact of proficiency on syntactic second-language processing of German and Italian: Evidence from event-related potentials. Journal of Cognitive Neuroscience 18: 2030–2048. [Google Scholar] [CrossRef]
- RStudio Team. 2021. RStudio: Integrated development environment for R. Boston: RStudio, PBC. Available online: http://www.rstudio.com/ (accessed on 1 October 2019).
- Sato, Mikako, and Claudia Felser. 2010. Sensitivity to morphosyntactic violations in English as a second language. Second Language 9: 101–18. [Google Scholar] [CrossRef]
- Schlenter, Judith, and Claudia Felser. 2021. L2 prediction ability across different linguistic domains: Evidence from German. In Prediction in Second Language Processing and Learning. Edited by Edith Kaan and Theres Grüter. Amsterdam: John Benjamins, pp. 48–68. [Google Scholar] [CrossRef]
- Schriefers, Herbert, Angela D. Friederici, and Katja Kuhn. 1995. The processing of locally ambiguous relative clauses in German. Journal of Memory and Language. [Google Scholar] [CrossRef]
- Sedivy, Julie C., Michael K. Tanenhaus, Craig G. Chambers, and Gregory N. Carlson. 1999. Achieving incremental semantic interpretation through contextual representation. Cognition 71: 109–47. [Google Scholar] [CrossRef]
- Service, Elisabet, Päivi Helenius, Sini Maury, and Riitta Salmelin. 2007. Localization of syntactic and semantic brain responses using magnetoencephalography. Journal of Cognitive Neuroscience 19: 1193–1205. [Google Scholar] [CrossRef] [PubMed]
- Sevcenco, Anca, Larisa Avram, and Ioana Stoicescu. 2013. Subject and direct object relative clause production in child Romanian. In Topics in Language Acquisition and Language Learning in a Romanian Context. Edited by Larisa Avram and Anca Sevcenco. Bucharest: Editura Universităţii din Bucureşti, pp. 51–85. [Google Scholar]
- Swets, Benjamin, Timothy Desmet, Charles Clifton, and Fernanda Ferreira. 2008. Underspecification of syntactic ambiguities: Evidence from self-paced reading. Memory and Cognition 36: 201–16. [Google Scholar] [CrossRef] [PubMed]
- Tanenhaus, Michael K., Michael J. Spivey-Knowlton, Kathleen M. Eberhard, and Julie C. Sedivy. 1995. Integration of visual and linguistic information in spoken language comprehension. Science 268: 1632–34. [Google Scholar] [CrossRef]
- Tanner, Darren, Judith McLaughlin, Julia Herschensohn, and Lee Osterhout. 2013. Individual differences reveal stages of L2 grammatical acquisition: ERP evidence. Bilingualism 16: 367–82. [Google Scholar] [CrossRef]
- Tanner, Darren, Kayo Inoue, and Lee Osterhout. 2014. Brain-based individual differences in online L2 grammatical comprehension. Bilingualism 17: 277–93. [Google Scholar] [CrossRef]
- The GIMP Development Team. 2019. GIMP. Available online: https://www.gimp.org (accessed on 26 January 2017).
- Traxler, Matthew J. 2011. Parsing. Wiley Interdisciplinary Reviews: Cognitive Science 2: 353–64. [Google Scholar] [CrossRef]
- Trueswell, John C., Michael K. Tanenhaus, and Susan M. Garnsey. 1994. Semantic influences on parsing: Use of thematic role information in syntactic ambiguity resolution. Journal of Memory and Language 33: 285–318. [Google Scholar] [CrossRef]
- Underwood, Geoffrey, Lorraine Jebbett, and Katharine Roberts. 2004. Inspecting pictures for information to verify a sentence: Eye movements in general encoding and in focused search. Quarterly Journal of Experimental Psychology Section A: Human Experimental Psychology 57: 165–82. [Google Scholar] [CrossRef]
- Van Gompel, Roger P. G., and Martin J. Pickering. 2006. Syntactic parsing. In The Oxford Handbook of Psycholinguistics, 2nd ed. Edited by Matthew Traxler and Morton A. Gernsbacher. Cambridge: Academic Press, pp. 455–503. [Google Scholar] [CrossRef]
- Veríssimo, João, Vera Heyer, Gunnar Jacob, and Harald Clahsen. 2018. Selective effects of age of acquisition on morphological priming: Evidence for a sensitive period. Language Acquisition 25: 315–26. [Google Scholar] [CrossRef]
- Wannemacher, Jill T. 1974. Processing strategies in picture-sentence verification tasks. Memory & Cognition 2: 554–60. [Google Scholar] [CrossRef]
- Wickham, H. 2016. Elegant Graphics for Data Analysis Second Edition (vol. 35, pp. 10–1007). Available online: http://www.springer.com/series/6991 (accessed on 12 October 2019).
- Yadav, Himanshu, Dario Paape, Garrett Smith, Brian W. Dillon, and Shravan Vasishth. 2022. Individual differences in cue weighting in sentence comprehension: An evaluation using approximate Bayesian computation. Open Mind 6: 1–24. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Demographic Information | |||||||
|---|---|---|---|---|---|---|---|
| Group | Female | Male | Total | Mean Age in Years (SD) | Mean Years of Education (SD) | ||
| L1 | 36 | 9 | 45 | 24 (4) | 15 (2) | ||
| L2 | 35 | 4 | 39 | 32 (9) | 16 (5) | ||
| Total | 71 | 13 | 84 | 28 (8) | 16 (4) | ||
| L2 Group | |||||||
| Age of Acquisition of German | N | Proficiency in German | N | German Learning Context | N | Daily Use of German | N |
| 3 to 5 yrs | 6 | C1 | 7 | School | 35 | 100% | 7 |
| 6 to 10 yrs | 10 | B2 | 18 | Home | 3 | 90% | 5 |
| 11 to 15 yrs | 10 | B1 | 13 | Informal | 1 | 80% | 10 |
| 16 to 20 yrs | 8 | A2 | 1 | 70% | 4 | ||
| 21 to 25 yrs | 5 | 60% | 5 | ||||
| 26 to 30 yrs | 1 | 50% | 3 | ||||
| 31 to 35 yrs | 0 | 40% | 0 | ||||
| 36 to 38 yrs | 1 | 30% | 1 | ||||
| 20% | 3 | ||||||
| 10% | 1 | ||||||
| Additional Language Information | |||||||
| L1 | N | Spoken Languages | L1 Group | L2 Group | Additional Languages (N) | Mean AoA in Years (SD) | |
| Bulgarian | 4 | L1 | 2 | 0 | English (74) | 7 (4) | |
| Czech | 4 | L1 + 1 | 14 | 8 | French (20) | 7 (6) | |
| German | 45 | L1 + 2 | 21 | 18 | Spanish (9) | 10 (4) | |
| Latvian | 1 | L1 + 3 | 7 | 4 | Russian (7) | 6 (5) | |
| Polish | 5 | L1 + 4 | 1 | 7 | Italian (3) | 9 (4) | |
| Romanian | 8 | L1 + 5 | 0 | 2 | |||
| Russian | 15 | ||||||
| Slovakian | 1 | ||||||
| Ukrainian | 1 | ||||||
| First Slide | Second Slide | |||
|---|---|---|---|---|
| Sentence Structure | Visual Cue | Written Probe Question | ||
| Level | Example | Level | Example | |
| Subject relative (SR) | Das ist der Koch, der die Braut verfolgt. this is theNOM cook, whoNOM theACC bride follows ‘This is the cook who is following the bride.’ | Match |  | Wird die Braut/der Koch verfolgt? is theNOM bride/theNOM cook followed ‘Is the bride/the cook being followed?’ |
| Mismatch |  | |||
| Object relative (OR) | Das ist der Koch, den die Braut verfolgt. this is theNOM cook, whoACC theNOM bride follows ‘This is the cook whom the bride is following.’ | Match |  | |
| Mismatch |  | |||
| Group | Sentence Structure | Accuracy | SD Accuracy | Reaction Times | SD Reaction Times |
|---|---|---|---|---|---|
| L1 | SR | 0.88 | 0.32 | 1112 | 410 |
| L1 | OR | 0.68 | 0.47 | 1219 | 471 |
| L2 | SR | 0.85 | 0.36 | 1318 | 491 |
| L2 | OR | 0.45 | 0.50 | 1369 | 541 |
| Reaction Times | ||||
| Predictor | Estimate | Std. Error | t Value | p Value |
| (Intercept) | 7.07 | 0.03 | 219.59 | <0.001 |
| Sentence Structure | 0.07 | 0.02 | 3.71 | <0.001 |
| Group | 0.15 | 0.06 | 2.55 | 0.011 |
| Sentence Structure × Group | −0.03 | 0.04 | −0.75 | 0.455 |
| Accuracy | ||||
| Predictor | Estimate | Std. Error | t Value | p Value |
| (Intercept) | 1.26 | 0.12 | 10.40 | <0.001 |
| Sentence Structure | −1.83 | 0.22 | −8.36 | <0.001 |
| Group | −0.82 | 0.21 | −3.85 | <0.001 |
| Sentence Structure × Group | −0.86 | 0.41 | −2.08 | 0.038 |
| Group | Visual Cue | Sentence Structure | Accuracy | SD—Accuracy | Reaction Times | SD—Reaction Times |
|---|---|---|---|---|---|---|
| L1 | Match | SR | 0.93 | 0.25 | 1096 | 377 |
| L1 | Match | OR | 0.74 | 0.44 | 1121 | 396 |
| L1 | Mismatch | SR | 0.75 | 0.43 | 1263 | 531 |
| L1 | Mismatch | OR | 0.50 | 0.50 | 1307 | 470 |
| L2 | Match | SR | 0.89 | 0.31 | 1250 | 454 |
| L2 | Match | OR | 0.59 | 0.49 | 1411 | 508 |
| L2 | Mismatch | SR | 0.77 | 0.42 | 1370 | 498 |
| L2 | Mismatch | OR | 0.30 | 0.46 | 1234 | 521 |
| Predictor | Estimate | Std. Error | z Value | p Value |
|---|---|---|---|---|
| (Intercept) | 1.16 | 0.14 | 8.57 | <0.001 |
| Sentence Structure | −2.08 | 0.25 | −8.47 | <0.001 |
| Visual Cue | −1.41 | 0.23 | −6.11 | <0.001 |
| Group | −0.65 | 0.25 | −2.59 | 0.009 |
| Sentence Structure × Visual Cue | −0.37 | 0.31 | −1.18 | 0.238 |
| Sentence Structure × Group | −0.82 | 0.14 | −1.78 | 0.074 |
| Visual Cue × Group | 0.04 | 0.42 | 0.11 | 0.914 |
| Sentence Structure × Visual Cue × Group | −0.93 | 0.58 | −1.61 | 0.106 |
| Predictor | Estimate | Std. Error | z Value | p Value |
|---|---|---|---|---|
| (Intercept) | 1.20 | 0.11 | 10.52 | <0.001 |
| Sentence Structure | −2.06 | 0.25 | −8.32 | <0.001 |
| Visual Cue | −1.44 | 0.23 | −6.23 | <0.001 |
| Sensitivity score | 4.65 | 0.64 | 7.21 | <0.001 |
| Sentence Structure × Visual Cue | −0.24 | 0.32 | −0.76 | 0.449 |
| Sentence Structure × Sensitivity Score | 2.94 | 1.45 | 2.03 | 0.042 |
| Visual Cue × Sensitivity Score | 1.41 | 1.34 | 1.05 | 0.294 |
| Sentence Structure × Visual Cue × Sensitivity Score | 3.74 | 1.85 | 2.02 | 0.043 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zona, C.I.; Felser, C. Integrating Morphosyntactic and Visual Cues in L1 and L2 Comprehension. Languages 2023, 8, 111. https://doi.org/10.3390/languages8020111
Zona CI, Felser C. Integrating Morphosyntactic and Visual Cues in L1 and L2 Comprehension. Languages. 2023; 8(2):111. https://doi.org/10.3390/languages8020111
Chicago/Turabian StyleZona, Carlotta Isabella, and Claudia Felser. 2023. "Integrating Morphosyntactic and Visual Cues in L1 and L2 Comprehension" Languages 8, no. 2: 111. https://doi.org/10.3390/languages8020111