4. Results
This section presents the results obtained from 55 participants (2640 tokens).
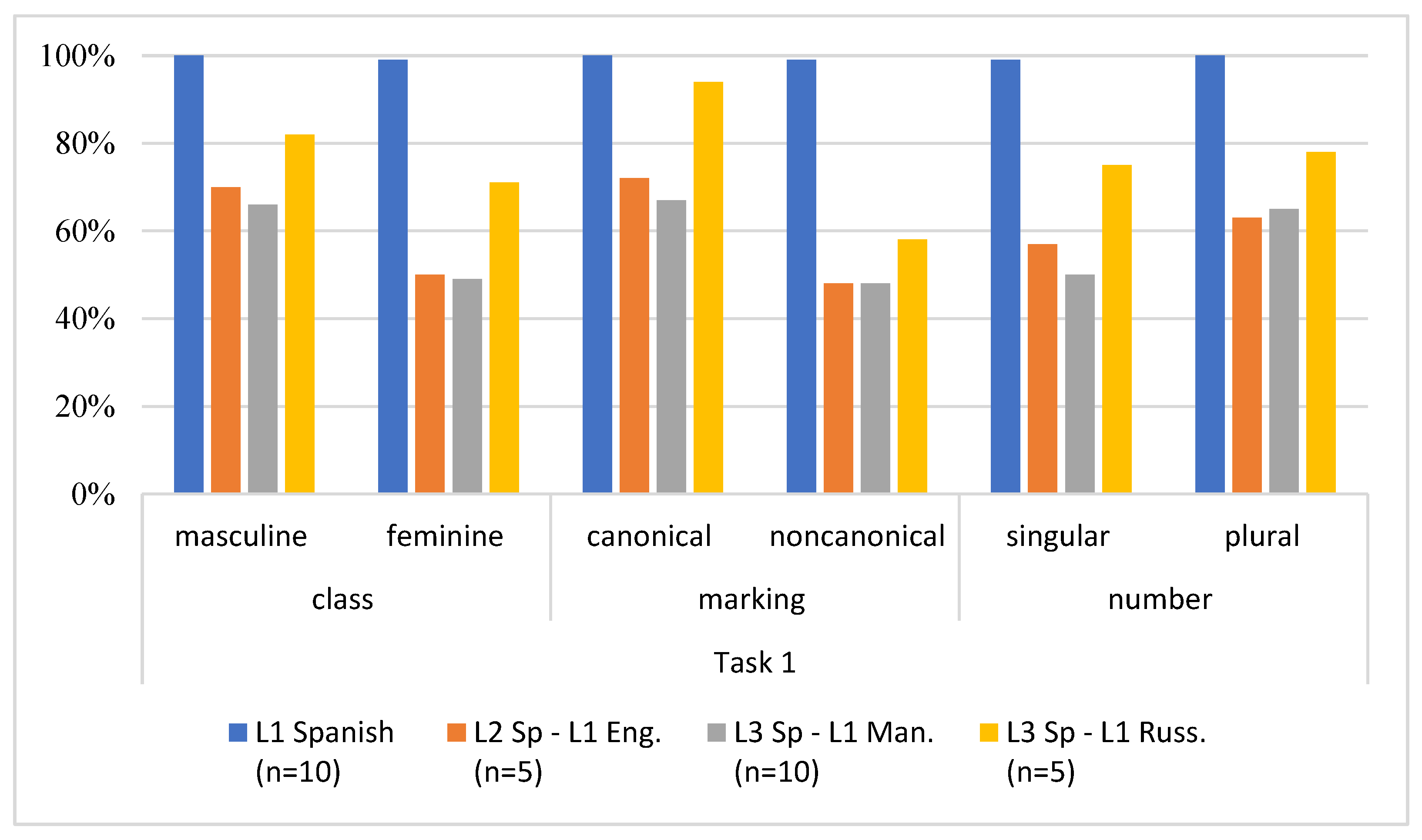
Overall, advanced learners of all three groups performed at or near ceiling, especially in Task 1, but some differences were detected, according to
Table 2.
The Russian speakers outperformed the other learner groups in two tasks and were able to converge on native speaker performance. Regarding gender form, Mandarin speakers scored higher on masculine forms than on feminine nouns. As for morphological cues, Mandarin and English learners produced more errors with non-canonical forms, which supports our hypothesis. As for the number variable, Mandarin speakers showed similar patterns to the English learners; specifically, more errors were found with the plural nouns, which again supports our initial hypothesis.
As for the beginner groups, clear distinctions were found. Therefore, for the rest of the paper, we focus on the beginner groups only. To understand better the type of errors and to determine if there is a possible task effect, we present the results for each of the two tasks separately.
Figure 1 demonstrates the effect of the linguistic variables analyzed (syntactic gender, form class, and number) on accuracy with gender agreement comparing the three learner groups and controls in Task 1.
Figure 2 presents the effect of the linguistic variables analyzed (syntactic gender, form class and number) on accuracy with gender agreement comparing the three learner groups and controls in Task 2.
As seen in
Figure 1, in the Picture Identification Task, all three groups produced more errors with the feminine form, by overgeneralizing the masculine form (e.g.,
los flores instead of
las flores ‘the flowers’).
A Kruskal–Wallis H test with all pairwise comparisons as post hoc showed that there was a significant difference of Task 1 accuracy scores, H (3) = 25.554,
p < 0.001; while the L1 Russian group performed almost native-like (
p = 0.031), L1 English group’s (
p = 0.000) and L1 Mandarin group’s (
p = 0.000) accuracy scores were significantly different from that of the L1 Spanish control group (
Table 3 and
Table 4.) The Russian group, hence, outperformed the other two learner groups, roughly by 20%, which may suggest the transfer of the grammatical gender system of their L1. As for the form class, all three groups performed better with canonical nouns than non-canonical forms, which supports our initial hypothesis, but again there were differences observed. Overall, the Russian group outperformed the other two groups, followed by Mandarin’s L3 performance. Regarding the number variable, three groups performed (slightly) better with plural numbers than singular forms, but again, the Russian group produced more correct answers than the other two groups.
As for Task 2, a Kruskal–Wallis H test with all pairwise comparisons as post hoc revealed that while all learner groups performed statistically less accurately that the L1 Spanish control group, there was no significant differences between these learner groups. Similar to
Figure 1, in
Figure 2, the three learner groups had more errors with feminine nouns than masculine ones, which was expected as per our initial hypotheses. However, group differences were also detected; unlike in Task 1, in Task 2, the grammaticality judgment task, the findings show a different pattern: the Russian group produced more errors with feminine nouns (34% error), as opposed to the Mandarin group (28%). The English group produced a similar percentage of errors with feminine and masculine nouns. Regarding the effect of class form, all groups performed better with canonical nouns (e.g., prototypical nouns that end in -o for masculine and -a for feminine), but again, the Mandarin group outperformed the other two groups when producing canonical forms. As for non-canonical endings, the Russian group performed slightly better than the Mandarin group. Regarding morphological number, the nouns with plural endings seemed to be easiest for the English bilingual participants across the two Tasks. For the Mandarin speakers, a different pattern for number is observed: in Task 1, they were more accurate with the plural nouns, whereas in Task 2, the participants performed better with singular nouns, indicative of a possible task effect. For the Russian group, the difference in Task 1 was minimal for morphological number, but in Task 2, the Russian participants clearly performed better with the singular nouns. A paired samples
t-test confirmed this task effect for beginner learners, that is, a significant difference in accuracy scores was detected between Task 1 and Task 2,
t (39) = −2.200,
p = 0.034) (
Appendix A).
As for the group differences, we predicted that Russians would outperform the other two groups, followed by English outperforming the Mandarin group in number agreement, specifically. Our findings somewhat confirm our predictions.
Based on
Table 5, the Russian group outperformed the other two groups on Task 1, followed by the other two groups who showed minimal discrepancy in their scoring. In Task 2, however, the Mandarin learners outperformed the other two groups. The difference between Mandarin and English speakers was noteworthy. Additionally, looking at individual performance of the beginner learners on Task 2, we noticed that the percentage of accuracy varied for all three language groups: for L1 English, 42–83%, for Russian L3 learners, 67–87.5%, for Mandarin L3 learners, 70.83–91.67%. There were 2 Mandarin speakers who scored 83.3% (20/24 target nouns) and 1 speaker 91.67% (22/24 target nouns) but also 6 participants whose accuracy reached only 75%. For Russian speakers, there were 4 participants who scored 81–87.5%, but also 2 other learners who were 66% accurate. Therefore, due to the individual performance differences, future analysis should focus on analyzing individual data in order to attain a deeper understanding of error type.
Overall, on the two tasks, results indicate accuracy scores on masculine nouns were higher for all participants, including Russian speakers, indicating that masculine as default may be a general processing strategy irrespective of L1. Secondly, canonically marked masculine nouns presented the least difficulty while noncanonical feminine nouns were most difficult, thus corroborating previous findings (e.g.,
Montrul et al. 2008). Finally, as for number, a possible task effect was observed, which will be further discussed in the next section.
5. Discussion and Conclusions
The present study focused on investigating performance with grammatical gender among speakers of typologically different languages, including Russian, Mandarin and English, who have been acquiring Spanish as an L3 in the university setting. In this project, we were interested in observing the possible effect of structural typology on the gender and number variables. We also wanted to highlight the types of errors that the different learner groups demonstrate while acquiring Spanish and examine whether these errors are similar across the three learner groups.
Our first research question investigated whether L1 structural typology plays a role in the acquisition of gender and number concord. All our advanced participants performed similarly, regardless of their L1, which might suggest that typology does not play much of a role at the advanced level of proficiency. In
Section 1.2, we also discussed two types of transfer models in L3 acquisition: wholesale models (L1 factor, L2 factor, TPM), which refer to substantial transfer of either L1 or L2 to L3 specifically at the initial stages of acquisition, and piecemeal transfer models (CEM, Scalpel, and LPM), which state that transfer occurs on a property-by-property basis throughout L3 development. Based on the results from our beginner participants, it is difficult to conclude which model best fits our findings due to a relatively small number of participants per category. At the beginner level, we see the results of the Mandarin speakers somewhat align with the English L2 group, but as mentioned in the results section, they obtained higher accuracy scores on the second task. Based on these findings, our L2 Factor prediction is not confirmed, but the results seem to align with the piecemeal transfer Scalpel Model, proposed by
Slabakova (
2017), corroborating the idea that other possible factors (e.g., structural complexity, frequency of input) may lead to transfer in L3 acquisition. As we mentioned earlier, since the Mandarin L3 group recently moved to Canada, their mode of acquisition of a non-native language is different from the English group (e.g., more explicit focus on grammar through reading, and less on oral skills) and thus might have resulted in their higher accuracy on the second task. Since
Slabakova (
2017) does not fully describe the conditions of these other factors, it is hard to fully adopt this model to our Mandarin group. Regarding our second L3 group, the Russian group overall did better on both tasks when compared to the other two learner groups, which suggests that knowledge of another gendered language plays a role in language acquisition and transfer. Based on these findings, it seems that at the initial stages, the results of the Russian L3 group could align with the TPM. Another important argument to make is that despite being typologically distant languages, Russian and Spanish are similar in the sense that they share some typological universals, in this case gender, as in both Russian and Spanish gender belongs to declination classes. Therefore, Russian learners have access to its retrieval.
Puig-Mayenco et al. (
2020) also propose a possibility of a so-called “hybrid transfer”, a term which refers to simultaneous transfer from L1 and L2. This seems to be aligned with the Competing Grammars Hypothesis, which addresses response optionality resulting from the speaker’s access to two different rules or competing grammars, i.e., English (lack of gender, masculine by
default) and Russian (masculine or feminine) (
Muñoz-Liceras and Alba de la Fuente 2015, p. 335). This, in fact, seems to align with the results of our L3 Russian group, as we find transfer features from both L1 and L2 when it comes to overgeneralization of one form as transfer from English (L2), but we also find enhanced accuracy with feminine nouns, indicative of potential transfer from Russian (L1).
Our second research question investigated the effect of gender (masculine vs. feminine), inflectional forms (canonical and non-canonical endings), and morphological number (singular vs. plural) on performance with Spanish gender and number agreement. Regarding masculine and feminine score differences, our results indicate that feminine noun forms were prone to be more difficult for all beginner learner groups, which corroborates previous research (
Montrul et al. 2008;
McCarthy 2008). Based on
McCarthy’s (
2008) MUH hypothesis, the learners seem to overgeneralize and, by default, prefer the masculine form, because it is easier to process (
Boloh and Ibernon 2010). This is what we have observed in our results. Despite the gender feature being available to Russian speakers, they still exhibit more errors with the feminine form, by overgeneralizing the masculine form. This difference in performance across masculine and feminine nouns could also be attributable to mismatching gender between Spanish and Russian; in other words, in Russian, the noun might be masculine, so they transfer the masculine assignment to the equivalent noun in Spanish. Our future research will investigate matching versus mismatching forms (i.e., noun gender congruence across languages) in Russian and Spanish in order to determine to what extent gender assignment in Russian may be transferred to the acquisition of grammatical gender in Spanish.
Regarding the gender forms, the learners of all three groups were more accurate with canonical nouns than non-canonical forms, which confirms our hypothesis and corroborates previous research (e.g.,
Foote 2009;
Gamboa Rengifo 2012;
Montrul et al. 2008). Again, similar to previous findings, Russian speakers demonstrated greater accuracy, which might indicate that learners of gendered languages which share typological or formal universals (e.g., access to gender) have an advantage when acquiring another gendered language. It is important to note, however, that the results of the Mandarin L3 learners show very interesting patterns. Specifically, in the grammatically judgement task, the Mandarin group slightly outperformed the Russian group with accuracy scores on canonical items, which may be indicative of a task effect. Given the fact that L1 Mandarin participants performed better on Task 2 in which they could see the questions and answers written on the slides and performed less accurately on the picture identification task that focused more on the relationship between the text and a corresponding image, may signal an affinity towards
reading tasks for this particular group of learners. This affinity for a reading task could be attributable to the language learning background of the Mandarin participants. These participants recently moved to Canada from China and therefore are habituated to a more traditional type of language teaching methodology (e.g., grammar translation method (
Álvarez et al. 2008) that focuses on written and reading proficiency. Another trend noticed with the Mandarin speakers is that they also performed much slower and took more time with their responses compared to the other groups, which could explain their enhanced accuracy scores. Future research should examine task completion times as an explanatory variable to determine how much of the variation in accuracy scores between learner groups may be explained by how much time learners take to complete a task, that is, whether slower times lead to greater response accuracy.
Apart from differences in participant performance potentially related to an affinity towards picture versus more textual tasks, we further consider other possible task effects. We assert that both Task 1 (Picture Identification) and Task 2 (Grammaticality Judgment) assess knowledge of grammatical gender assignment and agreement through the use of stimuli featuring both articles and adjectives. Therefore, the fundamental difference between these two tasks does not lie in the grammatical domain assessed, but rather in the nature of the task itself, that is, the procedural experience for the participants and how they are asked to respond. For Task 1, participants were asked to select the correct image with its corresponding bare noun in response to a written prompt containing the determiner phrase but no adjective. In Task 2, by contrast, the participants were provided with four written variations of a complete sentence containing the target noun and possible determiners and adjectives (only one of which was grammatically correct). Therefore, in this sense, Task 2 could be interpreted as having two possible cues indicating the grammaticality of the prompt: the determiner and the adjective, whereas Task 1 provided participants with only one cue—the determiner—by which to select the noun that fits. Therefore, a possible task effect may have arisen from a difference in the number of cues present in the written linguistic signal of each task, as our data demonstrate enhanced performance on Task 2 among the beginner learner groups even though native speakers did not appear affected by task differences.
Regarding the number variable, overall, the Russian group outperformed the other two learner groups. As recalled from the Introduction, Russian marks number on adjectives and nouns, so we expected this group to be the most accurate. As recalled from the background on languages, Russian and Spanish are similar in gender referring to declination classes, yet this similarity is only detectable in singular forms. In plural forms, the Russian language still exhibits declination classes, while Spanish alternates between two allophones “-s” and “-es”. If we analyze the results, though non-significant in the present sample, we still notice slightly higher accuracy on singular forms than plural forms, which suggests structural typology may play a role in number, as well. Despite our predictions, Mandarin speakers outperformed the English group and showed variation in their responses. Although in the first task they performed slightly better with the plural form, in Task 2, they produced more errors with plurals. Interestingly, the English group performed better with plural forms than singular forms on both tasks, which contradicts our initial hypothesis as we predicted the singular form would be treated as a default.
We also examined whether proficiency plays a role in the acquisition of gender agreement. Though we had a relatively small pool of participants, our results indicate that as proficiency level increases, accuracy increases as well. A Kruskal–Wallis H test indicated that Test 1 accuracy scores were significantly different between beginner Spanish learners, advanced Spanish learners, and native Spanish speakers (H (2) = 40.554,
p < 0.001). A pairwise comparisons revealed that the beginner learners’ accuracy scores were significantly lower than the native Spanish controls (
p < 0.01) and the advanced learners (
p < 0.01), and that there was no significant difference between the advanced learners and the native controls (
p = 1.000). This is also true for Task 2 accuracy scores; the Test 2 accuracy scores are significantly different between beginner Spanish learners, advanced Spanish learners, and native Spanish speakers (H(2) = 34.137,
p < 0.001). Pairwise comparisons revealed the beginner learners’ accuracy scores are significantly lower than the native Spanish controls (
p < 0.01) and the advanced learners (
p < 0.01), and that there was no statistically significant difference between the advanced learners and the native controls (
p = 1.000) (
Appendix B). Therefore, in our study, our advanced participants performed at or near ceiling, which is similar to the results of the native speaker control group, closely aligning with previous research (e.g.,
Montrul et al. 2008;
McCarthy 2008). All Russian learners aligned closely with the control group, whereas the other two groups produced some errors with more difficult forms, as initially predicted. Mandarin advanced learners showed more errors than the other two groups, with feminine, non-canonical, plural forms, similar to McCarthy’s conclusions that even advanced speakers encounter problems with some forms and by default overgeneralize one form, such as masculine. Nonetheless, L1 Mandarin and L1 English groups exhibited accuracy scores above chance-level, indicating that their acquisition of the grammatical gender feature in L3 Spanish is underway.
Since this project is ongoing, future work will be needed. First, it will be crucial to include a larger pool of participants for inferential analysis in order to determine to what extent the patterns uncovered here may be generalizable to the broader L3 learner population. We also believe it is important to include mirror-image groups, such as L1English-L2Mandarin/L2Russian-L3 Spanish in order to tease apart order of acquisition from other factors (e.g., typology, type of acquisition, etc.) (see
Rothman 2011;
Puig-Mayenco et al. 2020) In his study on L3 Brazilian Portuguese (BP) word order and relative clause attachment acquisition, Rothman studied and compared mirror-image groups, namely Spanish (L1)–English (L2) learners of BP (L3) and L1 English (L1)–L2 Spanish (L2)–(L3) learners, of BP (L3), and found that
L1 and
L2 transfer macro-variables were not counted as positive, since Spanish was transferred in both groups, which suggested that L1 or L2 transfer is not an absolute default and, in the case of L3 BP learners, the results suggest the effect of typological primacy rather than the order of acquisition.
Furthermore, an analysis of the effect of noun frequency in the input learners receive would likely yield interesting results as learners may be more likely to acquire–and to a greater degree of accuracy–the grammatical gender assignment of nouns frequently encountered in the linguistic environment. Although for the present study only target nouns found in the studied chapters of the beginner course textbook were included, there is likely to be some differences in their relative frequencies in both the textbook and course lectures and tutorial materials. Finally, it will also be crucial to analyze other individual variables, including language history, use, proficiency (both self-report and through testing), and attitudes, which could potentially influence performance with grammatical gender as well as the degree of transfer from other languages known. These factors constitute important avenues of future research that this ongoing project has uncovered and endeavors to explore further.
In conclusion, this study provides new insights into the L3 acquisition of grammatical gender. To our knowledge, the Mandarin-Russian-English-Spanish language pairing has not been previously studied, and this particular choice of languages both with (Russian, Spanish) and without (Mandarin, English) an explicit grammatical gender system has yielded some interesting results which merit further research. On the one hand, the Russian group performed better than the other two groups, which suggests that participants whose L1 has the gender feature available in their linguistic repertoire will be more accurate as they can transfer to some extent this feature. On the other hand, language environment and L1 and L2 use can also affect performance, which means that it will be important to assess participants’ daily language use to better understand and further explain the results.





{kind=link}
{kind=link}

