

Learning on the Field: L2 Turkish Vowel Production by L1 American English-Speaking NGOs in Turkey

Abstract
:1. Introduction
1.1. L1 and L2 Phonological Acquisition
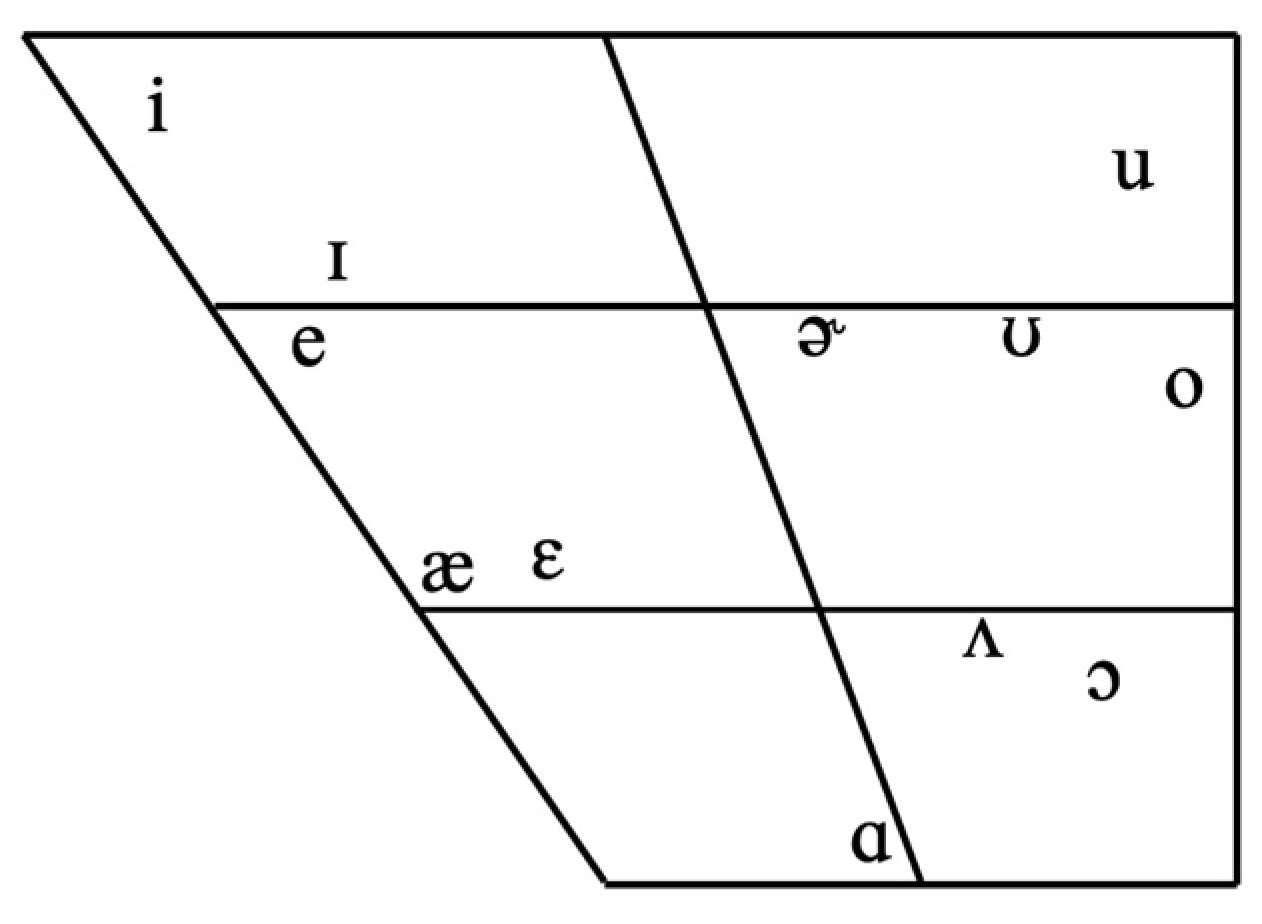
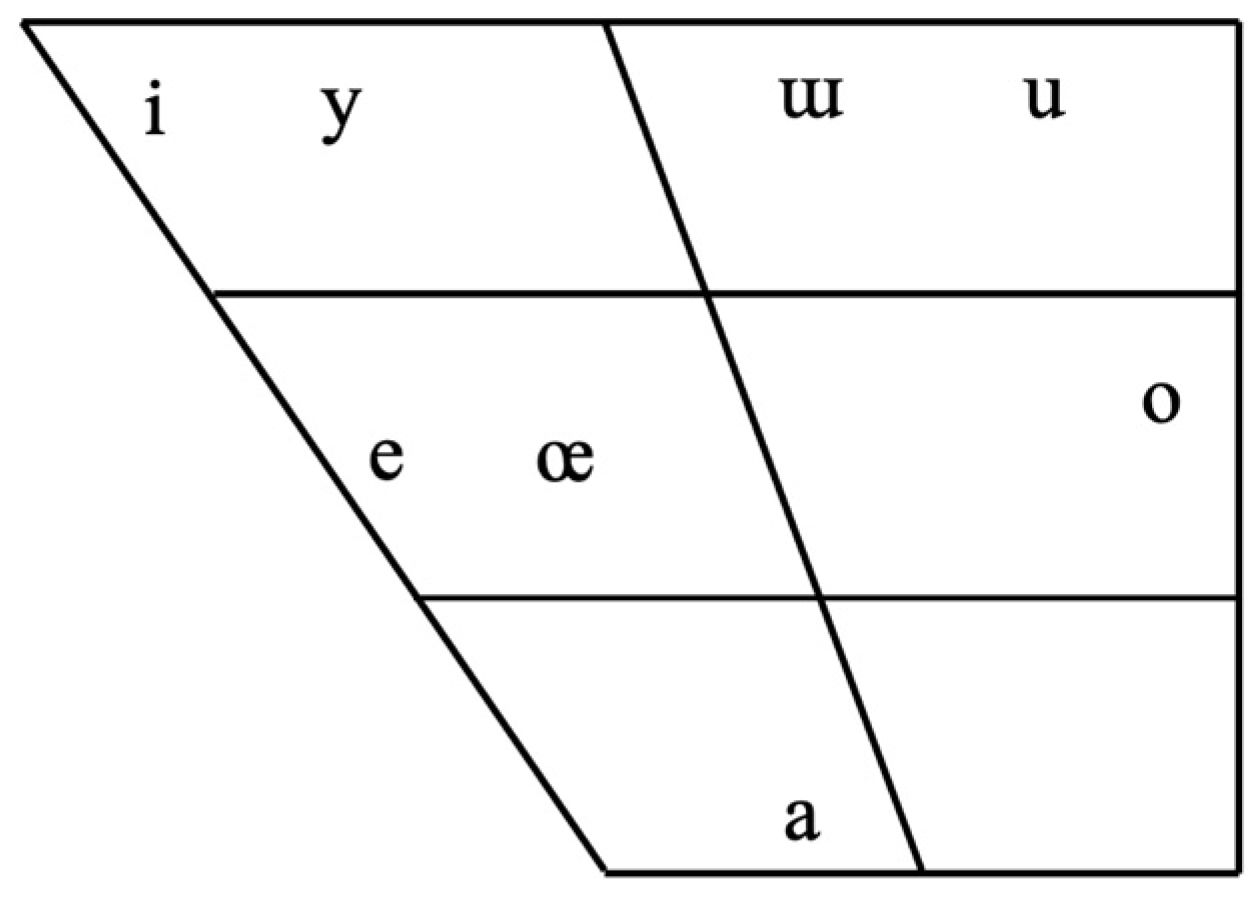
1.2. Turkish and American English Vowel Systems
1.3. Previous Research on Unrounded/Rounded Vowel Pairs
1.4. The Present Study
- What are the spectral characteristics of the L2 Turkish vowels /y/, /œ/, and /ɯ/ produced by L1 speakers of American English?
- What are the effects of target language experience and length of residency (LOR) on the production of the three “novel” Turkish vowels by L1 speakers of American English?
2. Materials and Methods
2.1. Participants
2.2. Measurements
2.3. Procedure
2.4. Data Analysis
3. Results
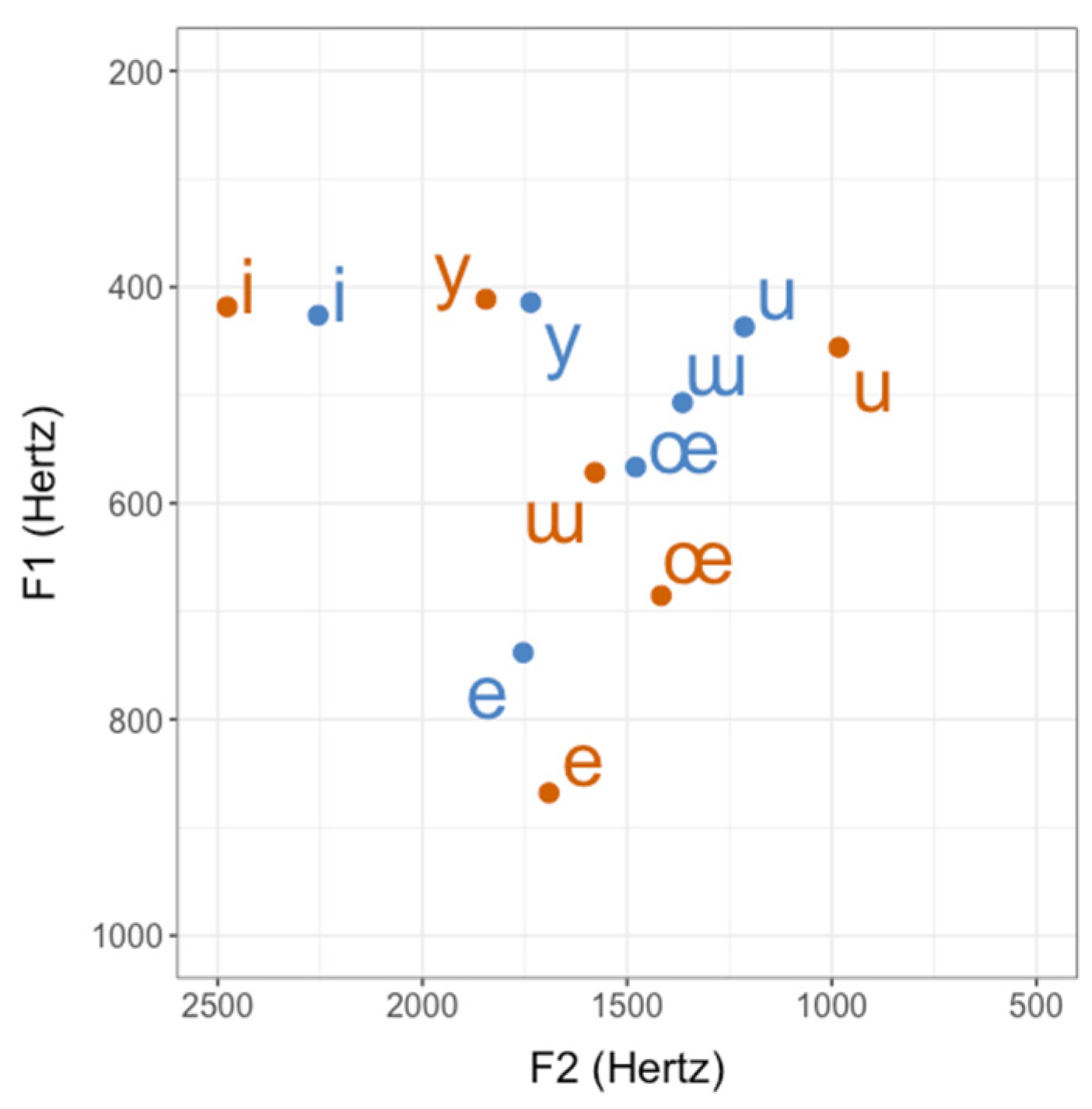
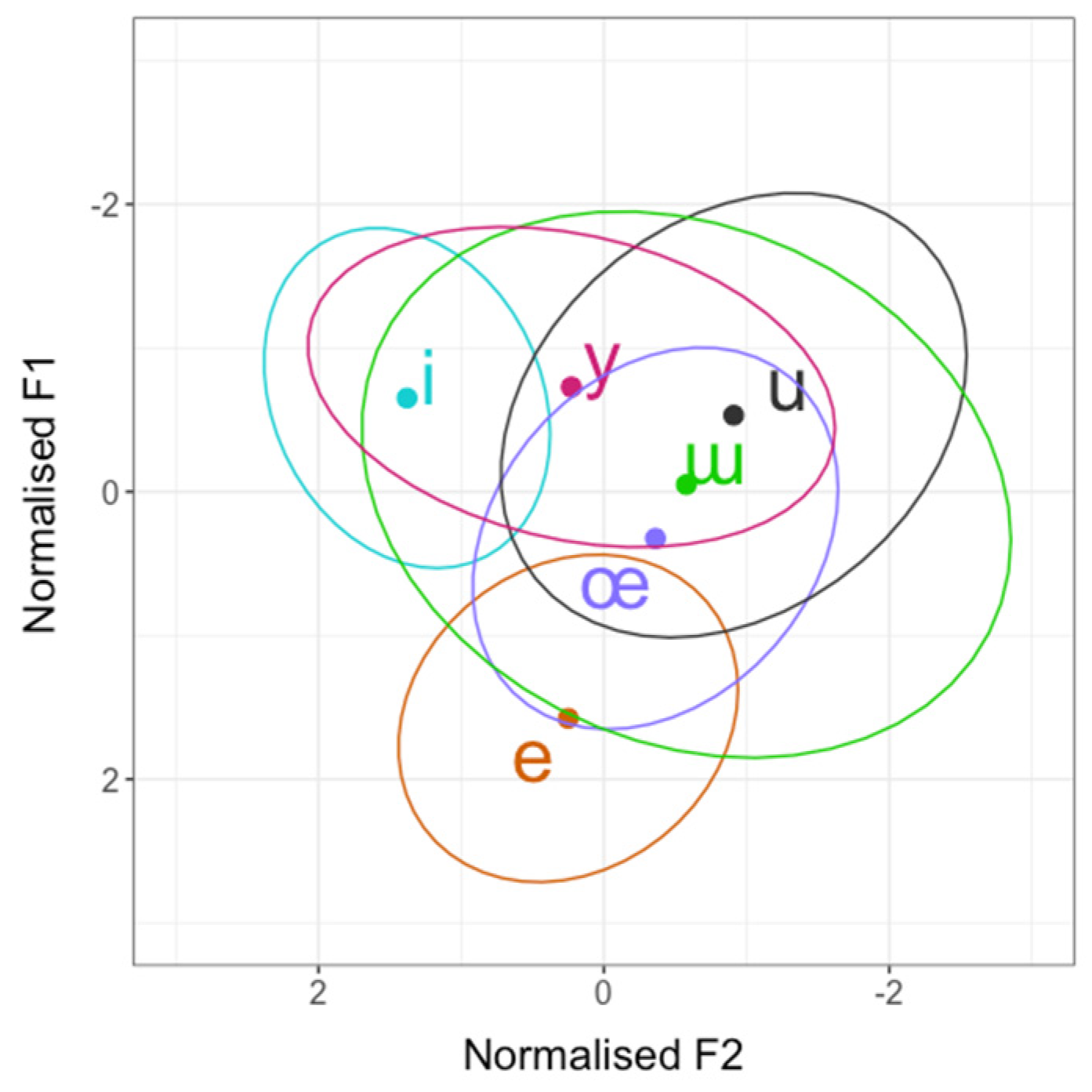
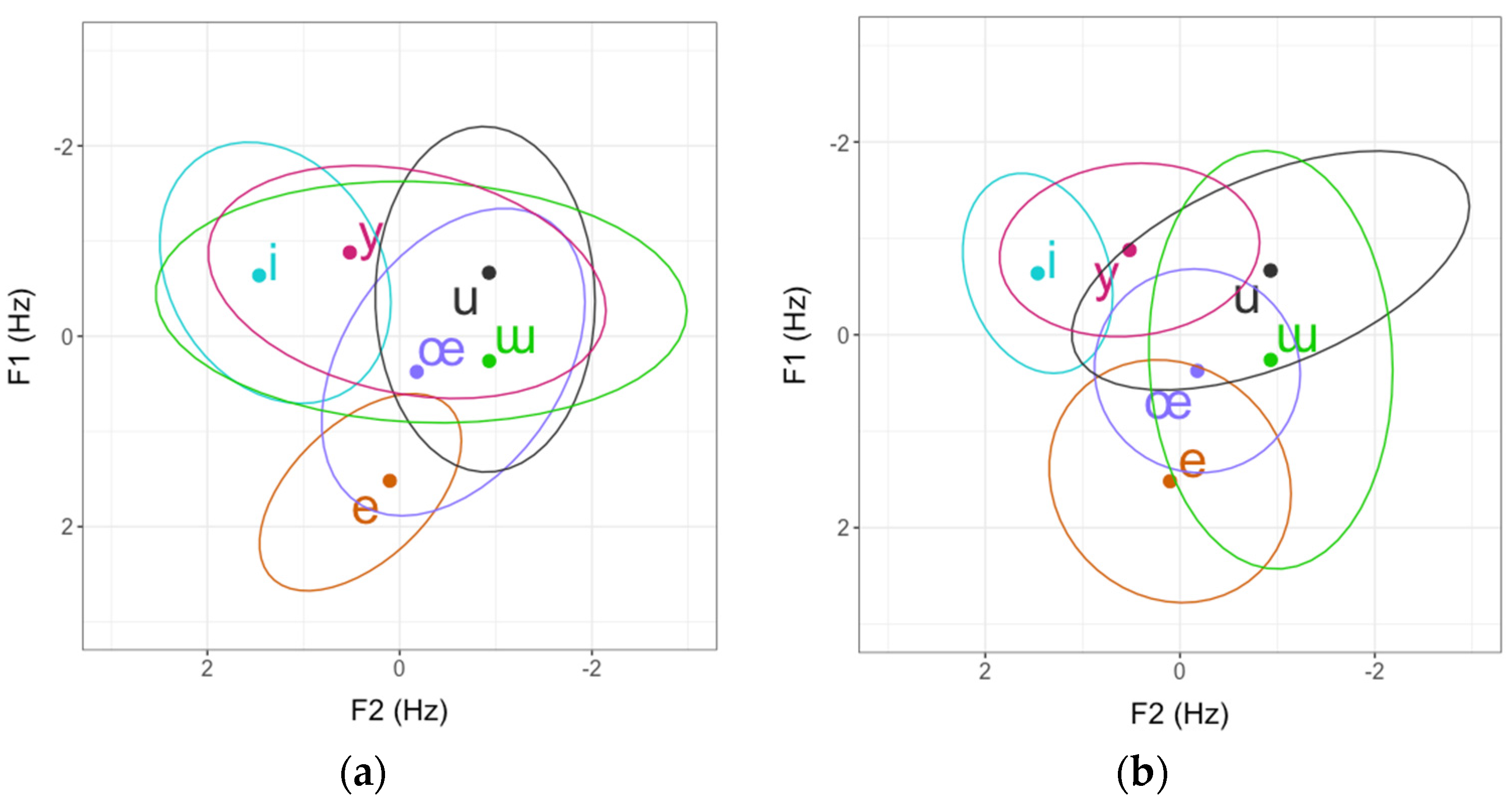
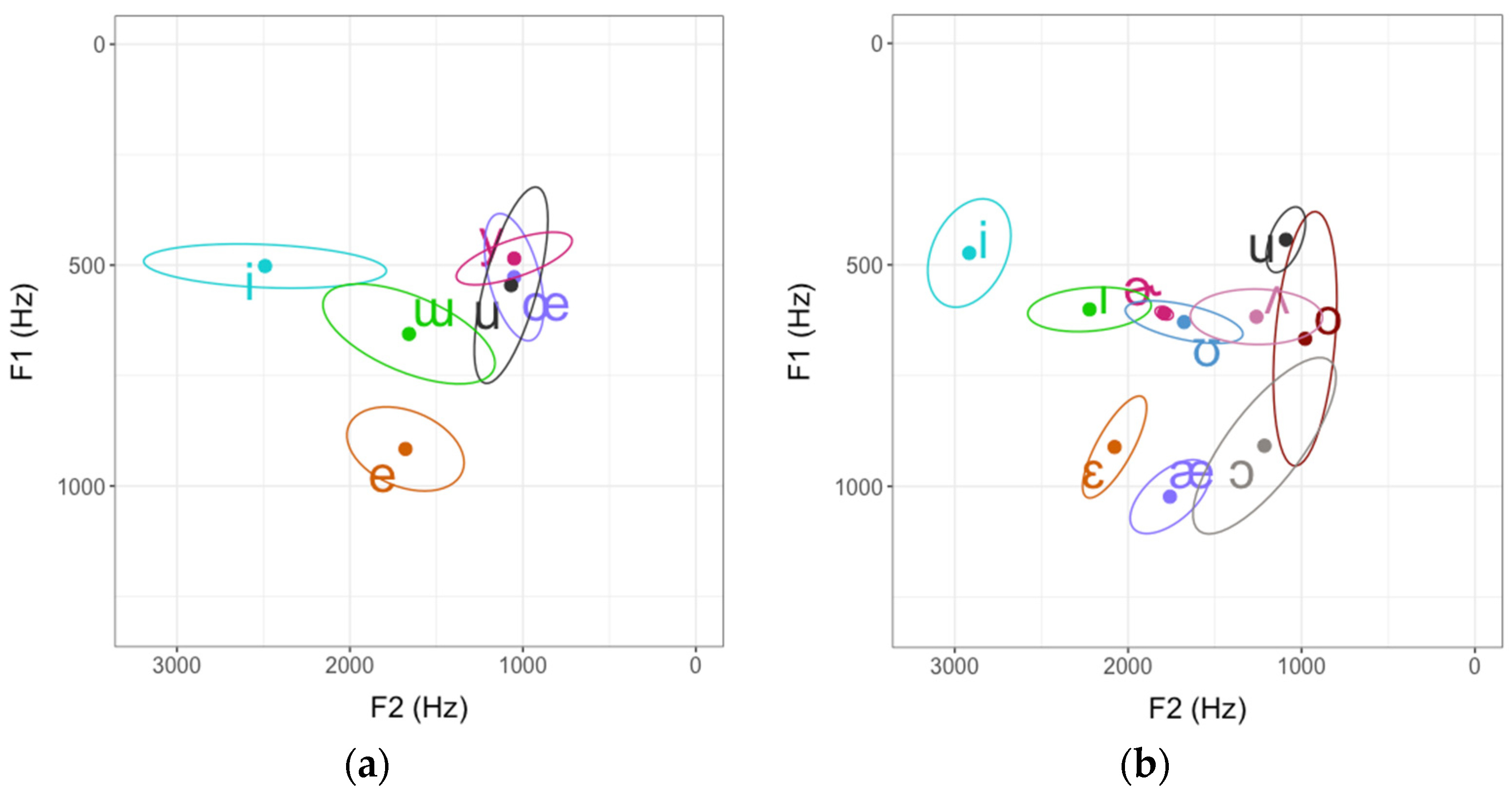
3.1. Overview of L2 Turkish Vowels
3.2. Target Language Experience, LOR, and Vowel Production
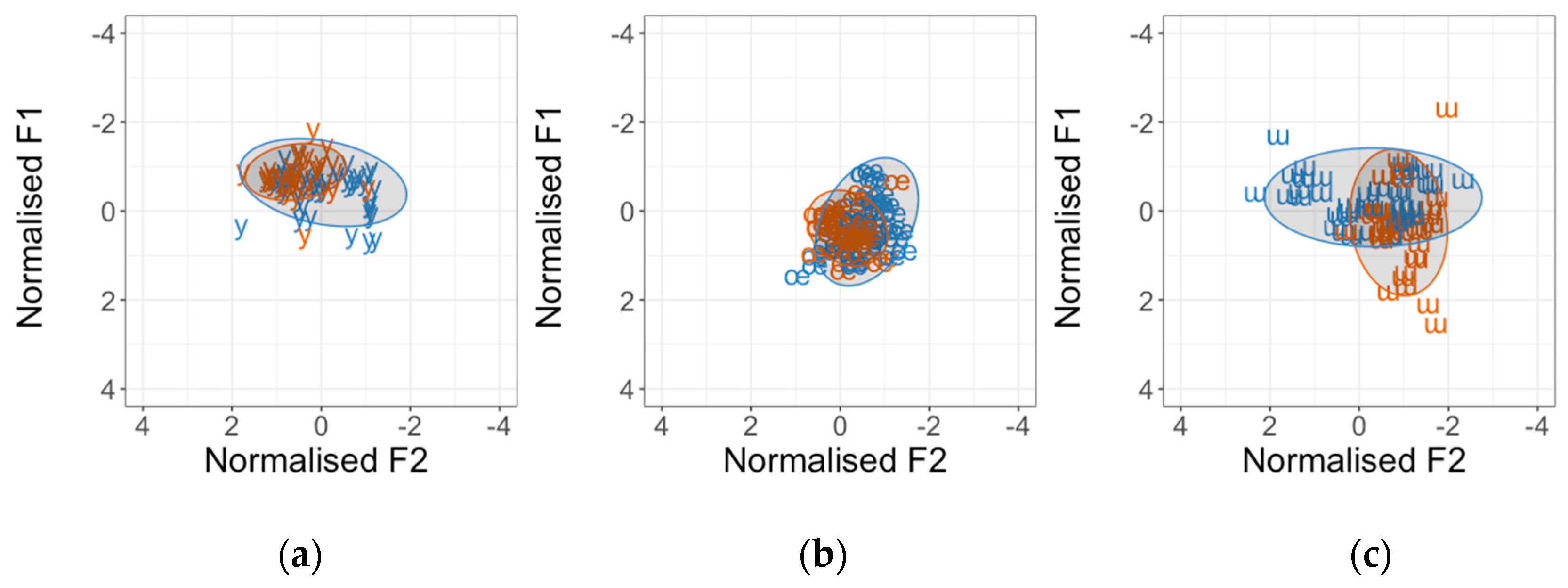
3.3. L1 Influence and Interspeaker Variation
4. Discussion
4.1. Novel Vowel Characteristics and L1-L2 Interaction
4.2. Target Language Experience and LOR
4.3. Limitation and Future Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | Symbols for this vowel vary in the literature on Turkish, with the phoneme represented as /ɛ/ and /e/ (see Sabev 2019). |
References
- Albrecht, Katharina. 2017. The Identification of Typical and Atypical Phonological Acquisition in Turkish-German Bilingual Children. Doctoral dissertation, The University of Sheffield, Sheffield, UK. Available online: https://etheses.whiterose.ac.uk/18545/ (accessed on 1 May 2021).
- Allen, Heather Willis, and Beatrice Dupuy. 2013. Study abroad, foreign language use, and the communities standard. Foreign Language Annals 45: 468–93. [Google Scholar] [CrossRef]
- Archibald, John. 2022. Segmental and prosodic evidence for property-by-property transfer in L3 English in Northern Africa. Languages 7: 28. [Google Scholar] [CrossRef]
- Baró, Àngels Llanes, and Raquel Serrano. 2011. Length of stay and study abroad: Language gains in two versus three months abroad. Revista Espanola De Linguistica Aplicada 24: 95–110. [Google Scholar]
- Benson, Erica J., Michael J. Fox, and Jared Balkman. 2011. The bag that Scott bought: The low vowels in northwest Wisconsin. American Speech 86: 271–311. [Google Scholar] [CrossRef]
- Best, Catherine T. 1994. The emergence of native-language phonological influences in infants: A perceptual assimilation model. In The Development of Speech Perception: The Transition from Speech Sounds to Spoken Words. Edited by Judith C. Goodman and Howard C. Nusbaum. Cambridge: MIT Press, pp. 167–224. [Google Scholar]
- Best, Catherine T. 1995. A direct realist view of cross-language speech perception. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winifred Strange. Baltimore: York Press, pp. 171–204. [Google Scholar]
- Best, Catherine T., and Michael D. Tyler. 2007. Nonnative and second-language speech perception: Commonalities and complementarities. In Language Experience in Second Language Speech Learning: In Honor of James Flege. Edited by Murray J. Munro and Ocke-Schwen Bohn. Amsterdam: John Benjamins, pp. 13–34. [Google Scholar]
- Boersma, Paul, and David Weenink. 2015. Praat: Doing Phonetics by Computer (6.1.16). September 2020. Available online: www.praat.org (accessed on 1 May 2021).
- Börtlü, Göktuğ. 2020. The second formants of the laterals in Turkish. Journal of Language and Linguistic Studies 16: 510–20. [Google Scholar] [CrossRef]
- Cadd, Marc. 2012. Encouraging students to engage with native speakers during study abroad. Foreign Language Annals 45: 229–46. [Google Scholar] [CrossRef]
- Council of Europe. 2001. Common European Framework of Reference for Languages: Learning, Teaching, Assessment. Cambridge: Press Syndicate of the University of Cambridge. [Google Scholar]
- Cox, Felicity. 2006. The acoustic characteristics of/hVd/vowels in the speech of some Australian teenagers. Australian Journal of Linguistics 26: 147–79. [Google Scholar] [CrossRef]
- Darcy, Isabelle, and Franziska Krüger. 2012. Vowel perception and production in Turkish children acquiring L2 German. Journal of Phonetics 40: 568–81. [Google Scholar] [CrossRef]
- Dewey, Dan. 2007. Language learning during study abroad: What we know and what we have yet to learn. Japanese Language and Literature 41: 245–69. [Google Scholar] [CrossRef]
- D’Onofrio, Annette, Penelope Eckert, Robert J. Podesva, Teresa Pratt, and Janneke Van Hofwegen. 2016. The low vowels in California’s Central Valley. In Speech in the Western States. Edited by Valerie Fridland, Betsy Evans, Tyler Kendall and Alicia Wassink. Durham: Duke University Press, vol. 1, pp. 11–32. [Google Scholar]
- Ergenç, Iclal. 1989. Türkiye Türkçesinin Görevsel Sesbilimi. Ankara: Engin. [Google Scholar]
- Escudero, Paola, and Paul Boersma. 2004. Bridging the gap between L2 speech perception research and phonological theory. Studies in Second Language Acquisition 26: 551–85. [Google Scholar] [CrossRef]
- Flege, James Emil, and Ocke-Schwen Bohn. 2021. The revised Speech Learning Model. In Second Language Speech Learning: Theoretical and Empirical Progress. Edited by Ratree Wayland. Cambridge: Cambridge University Press, pp. 3–83. [Google Scholar]
- Flege, James Emil, David Birdsong, Ellen Bialystok, Molly Mack, Hyekyung Sung, and Kimiko Tsukada. 2006. Degree of foreign accent in English sentences produced by Korean children and adults. Journal of Phonetics 34: 153–75. [Google Scholar] [CrossRef]
- Flege, James Emil, Murray J. Munro, and Laurie Skelton. 1992. The production of word-final English/t/-/d/contrast by native speakers of English, Mandarin, and Spanish. Journal of the Acoustical Society of America 92: 128–43. [Google Scholar] [CrossRef] [PubMed]
- Flege, James Emil, Ocke-Schwen Bohn, and Sunyoung Jang. 1997. The effect of experience on non-native subjects’ production and perception of English vowels. Journal of Phonetics 25: 437–70. [Google Scholar] [CrossRef]
- Flege, James Emil. 1987. The production of “new” and “similar” phones in a foreign language: Evidence for the effect of equivalence classification. Journal of Phonetics 15: 47–65. [Google Scholar] [CrossRef]
- Flege, James Emil. 1995. Second-language speech learning: Theory, findings, and problems. In Speech Perception and Linguistic Experience: Issues in Cross Language Research. Edited by Winifred Strange. Baltimore: York Press, pp. 229–73. [Google Scholar]
- Flege, James Emil. 1998. The role of subject and phonetic variables in L2 speech acquisition. Paper presented at 34th annual meeting of the Chicago Linguistic Society, Chicago, IL, USA, April 17–19. [Google Scholar]
- Flege, James Emil. 1999. Age of learning and second-language speech. In New Perspectives on the Critical Period Hypothesis for Second Language Acquisition. Edited by E. Birdsong. New York: Lawrence Erlbaum, pp. 101–32. [Google Scholar]
- Flege, James Emil. 2007. Language contact in bilingualism: Phonetic system interactions. In Laboratory Phonology. Edited by José Ignacio and Jennifer Cole. Berlin: Mouton de Gruyter, pp. 353–81. [Google Scholar]
- Freed, Barbara F., Dan P. Dewey, Norman Segalowitz, and Randall Halter. 2004. The language contact profile. Studies in Second Language Acquisition 26: 349–56. [Google Scholar] [CrossRef]
- Gottfried, Terry L. 1984. Effects of consonant context on the perception of French vowels. Journal of Phonetics 12: 91–114. [Google Scholar] [CrossRef]
- Guion, Susan G., James E. Flege, Serena H. Liu, and Grace H. Yeni-Komshian. 2000. Age of learning effects on the duration of sentences produced in a second language. Applied Psycholinguistics 21: 205–28. [Google Scholar] [CrossRef]
- Hall-Lew, Lauren. 2010. Improved representation of variance in measures of vowel merger. The Journal of the Acoustical Society of America 127: 2020. [Google Scholar] [CrossRef]
- Hay, Jennifer, Paul Warren, and Katie Drager. 2006. Factors influencing speech perception in the context of a merger-in-progress. Journal of Phonetics 34: 458–84. [Google Scholar] [CrossRef]
- Hernández, Todd. 2010. The Relationship Among Motivation, Interaction, and the Development of Second Language Oral Proficiency in a Study-Abroad Context. The Modern Language Journal 94: 600–17. [Google Scholar] [CrossRef]
- Hillenbrand, James, Laura A. Getty, Michael J. Clark, and Kimberlee Wheeler. 1995. Acoustic characteristics of American English vowels. The Journal of the Acoustical Society of America 97: 3099–111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hillenbrand, James. 2003. American English: Southern Michigan. Journal of the International Phonetic Association 33: 121–26. [Google Scholar] [CrossRef]
- Kiliç, Mehmet Akif, and Fatih Öğüt. 2004. A high unrounded vowel in Turkish: Is it a central or back vowel? Speech Communication 43: 143–54. [Google Scholar] [CrossRef]
- Kiliç, Mehmet Akif, Ilhami Yildirim, Erdoğan Okur, Fatih Öğüt, and Bülent Şerbetçioğlu. 2006. The effect of stimulus duration on perception of Turkish vowels in normal-hearing and hearing-impaired children. International Journal of Audiology 45: 675–80. [Google Scholar] [CrossRef] [PubMed]
- Kisler, Thomas, Uwe Reichel, and Florian Schiel. 2017. Multilingual processing of speech via web services. Computer Speech & Language 45: 326–47. [Google Scholar] [CrossRef]
- Kohler, Klaus J. 1981. Contrastive phonology and the acquisition of phonetic skills. Phonetica 38: 213–26. [Google Scholar] [CrossRef]
- Kopkalli-Yavuz, Handan. 1993. A Phonetic and Phonological Analysis of Final Devoicing in Turkish. Doctoral dissertation, University of Michigan, Ann Arbor, MI, USA. Available online: https://www.researchgate.net/publication/36172850_A_phonetic_and_phonological_analysis_of_final_devoicing_in_Turkish (accessed on 1 May 2021).
- Labov, William, Sharon Ash, and Charles Boberg. 2006. The Atlas of North American English: Phonetics, Phonology, and Sound Change. Berlin: Mouton de Gruyter. [Google Scholar] [CrossRef]
- Ladefoged, P. 1999. American English. In Handbook of the International Phonetic Association. Cambridge: Cambridge University Press, pp. 41–44. [Google Scholar]
- Lee, Soyoung, and Gregory K. Iverson. 2009. Vowel development in English and Korean: Similarities and differences in linguistic and non-linguistic factors. Speech Communication 51: 684–94. [Google Scholar] [CrossRef]
- Leonard, Karen. 2015. Speaking Fluency and Study Abroad: What Factors are Related to Fluency Development? Doctoral dissertation, University of Iowa, Iowa City, IA, USA. [Google Scholar] [CrossRef]
- Levy, Erika S. 2009a. Language experience and consonantal context effects on perceptual assimilation of French vowels by American-English learners of French. Journal of the Acoustical Society of America 125: 1138–52. [Google Scholar] [CrossRef]
- Levy, Erika S. 2009b. On the assimilation-discrimination relationship in American English adults’ French vowel learning. Journal of the Acoustical Society of America 126: 2670–82. [Google Scholar] [CrossRef] [Green Version]
- Levy, Erika S., and Winifred Strange. 2008. Perception of French vowels by American English adults with and without French language experience. Journal of Phonetics 36: 141–57. [Google Scholar] [CrossRef]
- Lobanov, Boris. 1971. Classification of Russian vowels spoken by different speakers. Journal of the Acoustical Society of America 49: 606–8. [Google Scholar] [CrossRef]
- Lu, Genghan. 2015. Length of residence and Chinese ESL Students’ English speaking comprehensibility and intelligibility. Journal of Language Teaching and Research 6: 943–55. [Google Scholar] [CrossRef]
- Maddieson, Ian. 1984. Patterns of Sounds. Cambridge: Cambridge University Press. [Google Scholar]
- Mairano, Paolo, Caroline Bouzon, Marc Capliez, and Valentina De Iacovo. 2019. Acoustic distances, Pillai scores and LDA classification scores as metrics of L2 comprehensibility and nativelikeness. Paper presented at 19th International Congress of Phonetic Sciences, Melbourne, Australia, August 5–9; Edited by Sasha Calhoun, Paola Escudero, Marija Tabain and Paul Warren. pp. 1104–8. [Google Scholar]
- McCloy, Daniel R. 2014. Phonetic effects of morphological structure in Indonesian vowel reduction. Proceedings of Meetings on Acoustics 12: 1–14. [Google Scholar]
- Moyer, Alene. 1999. Ultimate attainment in L2 phonology: The critical factors of age, motivation, and instruction. Studies in Second Language Acquisition 21: 81–108. [Google Scholar] [CrossRef]
- Moyer, Alene. 2005. Formal and informal experiential realms in German as a foreign language: A preliminary investigation. Foreign Language Annals 38: 337–87. [Google Scholar] [CrossRef]
- Moyer, Alene. 2009. Input as a critical means to an end: Quantity and quality of experience in L2 phonological attainment. In Input matters in SLA. Edited by Thorsten Piske and Martha Young-Scholten. Bristol: De Gruyter, pp. 159–74. [Google Scholar]
- Nycz, Jennifer, and Lauren Hall-Lew. 2013. Best practices in measuring vowel merger. Proceedings of Meetings on Acoustics 20: 060008. [Google Scholar] [CrossRef]
- Peterson, Gordon E., and Ilse Lehiste. 1960. Duration of syllable nuclei in English. Journal of the Acoustical Society of America 32: 693–703. [Google Scholar] [CrossRef]
- Piske, Thorsten, Ian R. A. MacKay, and James E. Flege. 2001. Factors affecting degree on foreign accent: A review. Journal of Phonetics 29: 191–215. [Google Scholar] [CrossRef]
- Polgardi, Krisztina. 1999. Vowel harmony and disharmony in Turkish. The Linguistic Review 16: 187–204. [Google Scholar] [CrossRef]
- Polka, Linda. 1995. Linguistic influences in adult perception of non-native vowel contrasts. Journal of the Acoustical Society of America 97: 1286–96. [Google Scholar] [CrossRef]
- Purnell, Thomas C. 2008. Prevelar raising and phonetic conditioning: Role of labial and anterior tongue gestures. America Speech 83: 373–402. [Google Scholar] [CrossRef]
- R Core Team. 2013. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. [Google Scholar]
- Radisic, Milica. 2008. The Adaptation of the Turkish Labial Vowels [y œ] and the Turkish Non Labial Vowel [ɯ] in Serbian. Master’s thesis, University of Toronto, Toronto, ON, Canada. [Google Scholar]
- Radisic, Milica. 2014. An Ultrasound and Acoustic Study of Turkish Rounded/Unrounded Vowel Pairs. Doctoral dissertation, The University of Toronto, Toronto, ON, Canada. [Google Scholar]
- Republic of Turkey, Ministry of Higher Education. 2021. Üniversite izleme ve değerlendirme raporları [University Monitoring and Evaulation Reports]; Ankara: Yükseköğretim kurulu. Available online: https://www.yok.gov.tr/universiteler/izleme-ve-degerlendirme-raporlari (accessed on 1 May 2021).
- Rochet, Bernar L. 1995. Perception and production of second-language speech sounds by adults. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winifred Strange. Baltimore: York Press, pp. 379–410. [Google Scholar]
- Sabev, Mitko. 2019. Spectral and Durational Unstressed Vowel Reduction: An Acoustic Study of Monolingual and Bilingual Speakers of Bulgarian and Turkish. Doctoral dissertation, The University of Oxford, Oxford, UK. [Google Scholar]
- Saito, Kazuya, and Luke Plonsky. 2019. Effects of second language pronunciation teaching revisited: A proposed measurement framework and meta-analysis. Language Learning 69: 652–708. [Google Scholar] [CrossRef]
- Selen, Nevin. 1979. Söyleyiş sesbilimi, akustik sesbilim ve Türkiye Türkçesi [Phonology of Pronunciation, Acoustic Phonology and Turkish in Turkey]. Ankara: Türk Dil Kurumu. [Google Scholar]
- Sewell, Andrew. 2021. Functional Load and the Teaching-Learning Relationship in L2 Pronunciation. Frontiers in Communication 6: 627378. [Google Scholar] [CrossRef]
- Shport, Irina A. 2019. Perception of Vietnamese back vowels contrasting in rounding by English listeners. Journal of Phonetics 73: 8–23. [Google Scholar] [CrossRef]
- Stevens, Kenneth N. 1998. Acoustic Phonetics. Cambridge: MIT Press. [Google Scholar]
- Stevens, Kenneth N., Alvin M. Libermann, Michael Studdert-Kennedy, and S. E. G. Öhman. 1969. Cross language study of vowel perception. Language and Speech 12: 1–23. [Google Scholar] [CrossRef] [PubMed]
- Strange, Winifred. 2007. Cross-language phonetic similarity of vowels: Theoretical and methodological issues. In Language Experience in Second Language Speech Learning: In Honor of James Emil Flege. Edited by Murray J. Munro and Ocke-Schwen Bohn. Amsterdam: John Benjamins, pp. 35–55. [Google Scholar]
- Thomson, Ron I., and Tracey M. Derwing. 2015. The effectiveness of L2 pronunciation instruction: A narrative review. Applied Linguistics 36: 326–44. [Google Scholar] [CrossRef]
- UNHCR. 2021. Operational Data Portal: Refugee Situations—Syria Regional Refugee Response, Turkey. In Response to the Syrian Crisis: Regional Refugee and Resiliance Plan. Available online: https://data2.unhcr.org/en/situations/syria/location/113 (accessed on 1 May 2021).
- Villareal, Dan. 2018. The construction of social meaning: A matched-guise investigation of the California Vowel Shift. Journal of English Linguistics 46: 52–78. [Google Scholar] [CrossRef]
- Vonwiller, Julie, Inge Rogers, Chris Cleirigh, and Wendy Lewis. 1995. Speaker and material selection for the Australian National Databases of Spoken Language. Journal of Quantitative Linguistics 2: 177–211. [Google Scholar] [CrossRef]
- Wayland, Ratree P., and James E. Flege. 2000. Perception and production of English vowels by Spanish adult L2 learners: Effects of experience and proficiency. Journal of the Acoustical Society of America 107: 2802. [Google Scholar] [CrossRef]
- Westergaard, Marit, Natalia Mitrofanova, Roksolana Mykhaylyk, and Yulia Rodina. 2017. Crosslinguistic influence in the acquisition of a third language: The Linguistic Proximity Model. International Journal of Bilingualism 21: 666–82. [Google Scholar] [CrossRef] [Green Version]
- Wickham, Hadley. 2016. ggplot2: Elegant Graphics for Data Analysis. New York: Springer. [Google Scholar]
- Yang, Jing, and Robert A. Fox. 2014. Perception of English vowels by bilingual Chinese–English and corresponding monolingual listeners. Language and Speech 57: 215–37. [Google Scholar] [CrossRef] [PubMed]
- Yang, Jing, and Robert A. Fox. 2017. L1–L2 interactions of vowel systems in young bilingual Mandarin-English children. Journal of Phonetics 65: 60–76. [Google Scholar] [CrossRef]
- Yavaş, Mehmet. 2016. Applied English Phonology. Hoboken: John Wiley & Sons, Ltd. [Google Scholar]
- Zimmer, Karl, and Orhan Orgun. 1992. Turkish. Journal of the International Phonetic Association 22: 43–45. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Front | Back | |||
|---|---|---|---|---|
| Unrounded | Rounded | Unrounded | Rounded | |
| Close (high) | i | y | ɯ | u |
| Open (non-high) | e1 | œ | a | o |
| Word (Orthography) | Word (IPA) | Vowel (IPA) |
|---|---|---|
| kil | /kil/ | /i/ |
| kül | /kyl/ | /y/ |
| kel | /kel/ | /e/ |
| göl | /ɡœl/ | /œ/ |
| kal | /kaɫ/ | /a/ |
| kıl | /kɯɫ/ | /ɯ/ |
| kul | /kuɫ/ | /u/ |
| kol | /koɫ/ | /o/ |
| Word | Vowel (IPA) |
|---|---|
| heed | /i/ |
| hid | /ɪ/ |
| head | /ɛ/ |
| had | /æ/ |
| hod | /ɔ/ |
| hawed | /o/ |
| hood | /ʊ/ |
| who’d | /u/ |
| hud | /ʌ/ |
| heard | /ɚ/ |
| Vowel | All Participants | Regional Residence | Urban Residence | |||
|---|---|---|---|---|---|---|
| F1 Mean (SD) | F2 Mean (SD) | F1 Mean (SD) | F2 Mean (SD) | F1 Mean (SD) | F2 Mean (SD) | |
| /e/ | 738.21 (15.10) | 1753.66 (25.51) | 745.15 (23.42) | 1720.46 (34.17) | 730.79 (18.91) | 1789.23 (37.75) |
| /i/ | 426.16 (13.93) | 2254.78 (33.54) | 425.18 (18.53) | 2322.20 (39.65) | 427.18 (21.14) | 2184.15 (53.02) |
| /œ/ | 566.50 (12.34) | 1478.90 (37.20) | 570.10 (16.39) | 1582.47 (39.90) | 562.65 (18.75) | 1367.93 (60.03) |
| /u/ | 436.77 (12.92) | 1213.63 (38.94) | 418.33 (17.10) | 1231.21 (60.82) | 456.53 (19.25) | 1194.80 (48.15) |
| /ɯ/ | 506.91 (10.95) | 1364.44 (34.65) | 540.40 (14.91) | 1241.14 (28.30) | 473.41 (14.54) | 1487.73 (58.00) |
| /y/ | 414.24 (11.17) | 1738.52 (45.79) | 394.58 (12.75) | 1877.40 (42.68) | 434.84 (18.18) | 1586.88 (76.46) |
| ID | RS | i–y | i–ɯ | i–œ | y–œ | y–u | y–ɯ | ɯ–u | e–œ | œ–u | e–u | œ–ɯ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F07 | Urban | 0.97 | 0.39 | 0.40 | 0.97 | 0.57 | ||||||
| F32 | Urban | 0.88 | 0.47 | 0.87 | 0.89 | 0.37 | 0.79 | |||||
| F46 | Urban | 0.92 | 0.89 | 0.74 | 0.50 | 0.90 | 0.60 | 0.79 | 0.35 | 0.68 | 0.28 | |
| M02 | Urban | 0.65 | 0.42 | 0.82 | ||||||||
| M45 | Urban | 0.90 | 0.64 | 0.65 | 0.51 | 0.08 | 0.89 | 0.86 | 0.37 | 0.12 | 0.90 | 0.80 |
| F06 | Urban | 0.90 | 0.26 | 0.94 | 0.61 | |||||||
| F48 | Urban | 0.89 | 0.72 | 0.88 | 0.90 | 0.79 | 0.67 | 0.84 | 0.65 | |||
| M16 | Urban | 0.90 | 0.85 | 0.42 | ||||||||
| M47 | Urban | 0.85 | 0.78 | 0.67 | 0.77 | |||||||
| M04 | Reg | 0.82 | 0.89 | 0.60 | 0.51 | 0.65 | 0.56 | 0.72 | 0.40 | |||
| F34 | Reg | 0.86 | 0.62 | 0.89 | 0.87 | 0.83 | ||||||
| F56 | Reg | 0.92 | 0.47 | 0.39 | 0.92 | |||||||
| M38 | Reg | 0.87 | 0.52 | 0.68 | 0.32 | 0.39 | ||||||
| F14 | Reg | 0.75 | 0.75 | |||||||||
| F39 | Reg | 0.85 | 0.93 | |||||||||
| F52 | Reg | 0.78 | ||||||||||
| M54 | Reg | 0.73 | 0.90 | 0.91 | ||||||||
| M55 | Reg | 0.75 | 0.82 | 0.88 | 0.37 |
| ID | RS | T-L2/i/ | T-L2/y/ | T-L2/ɯ/ | T-L2/u/ | T-L2/e/ | T-L2/œ/ |
|---|---|---|---|---|---|---|---|
| F07 | Urban | /i/-/i/0.77 | /y/-/u/0.76 | /ɯ/-/ɚ/0.59 /ɯ/-/ɪ/0.88 /ɯ/-/u/0.98 | /u/-/u/0.78 | /œ/-/u/0.71 /œ/-/o/0.71 | |
| F32 | Urban | /i/-/i/0.86 | /y/-/ʊ/0.98 | /ɯ/-/u/0.93 | /e/-/æ/0.72 | /œ/-/ɚ/0.40 /œ/-/o/0.88 | |
| F46 | Urban | /i/-/i/0.44 /i/-/ɪ/0.61 | /ɯ/-/ɚ/0.90 /ɯ/-/ʊ/0.65 | /e/-/ɛ/0.39 | /œ/-/ɚ/0.94 /œ/-/o/0.95 | ||
| M02 | Urban | /i/-/i/0.91 | /y/-/u/0.45 /y/-/ʊ/0.97 | /ɯ/-/ɪ/0.70 | /u/-/ʊ/0.89 | /e/-/æ/0.63 | /œ/-/æ/0.98 |
| M45 | Urban | /i/-/i/0.95 /i/-/ɪ/0.71 | /y/-/u/0.69 | /ɯ/-/i/0.52 | /u/-/u/0.57 | /e/-/æ/0.79 | /œ/-/ɚ/0.02 /œ/-/o/0.48 |
| F06 | Urban | /i/-/i/0.92 | /ɯ/-/u/0.95 | /u/-/u/0.82 | /e/-/ɛ/0.61 /e/-/æ/0.84 | /œ/-/ɛ/0.92 /œ/-/ɚ/0.85 /œ/-/o/0.96 | |
| F48 | Urban | /i/-/i/0.89 /i/-/ɪ/0.75 | /ɯ/-/u/0.75 /ɯ/-/ɚ/0.79 | /u/-/u/0.91 | /e/-/ɛ/0.72 | /œ/-/u/0.88 | |
| M16 | Urban | /i/-/i/0.66 | /ɯ/-/ɚ/0.97 | /u/-/u/0.73 | /e/-/ɛ/0.90 | /œ/-/ɚ/0.92 | |
| M47 | Urban | /i/-/i/0.60 | /y/-/u/0.86 | /ɯ/-/ɚ/0.35 | /u/-/u/0.21 | /e/-/ɛ/0.58 | /œ/-/ɚ/0.91 /œ/-/ɛ/0.84 |
| M04 | Reg | /y/-/u/0.86 /y/-/ʊ/0.95 | /ɯ/-/ɚ/0.69 | /e/-/ɛ/0.44 | /œ/-/ɛ/0.69 | ||
| F34 | Reg | /i/-/i/0.91 | /y/-/u/0.96 | /u/-/u/0.25 | /e/-/ɛ/0.29 | /œ/-/ɚ/0.28 | |
| F56 | Reg | /i/-/i/0.86 | /ɯ/-/ɚ/0.84 | /u/-/u/0.96 | /e/-/ɛ/0.23 | /œ/-/o/0.88 | |
| M38 | Reg | /i/-/i/0.99 | /y/-/u/0.82 | /ɯ/-/ɚ/0.99 | /u/-/u/0.94 | /œ/-/o/0.98 | |
| F14 | Reg | /i/-/i/0.61 | /y/-/u/0.98 | /ɯ/-/u/0.84 | /œ/-/ɛ/0.58 /œ/-/ɚ/0.87 | ||
| F39 | Reg | /i/-/i/0.81 | /y/-/i/0.96 | /ɯ/-/ɚ/0.98 /ɯ/-/ʊ/0.97 | /u/-/u/0.91 | /œ/-/ɛ/0.87 | |
| F52 | Reg | /i/-/i/0.76 | /ɯ/-/ɚ/0.96 | /u/-/u/0.95 | /e/-/ɛ/0.67 | ||
| M54 | Reg | /i/-/i/0.44 | /y/-/ɪ/0.81 | /u/-/u/0.13 /u/-/ʊ/0.78 | /e/-/ɛ/0.55 | ||
| M55 | Reg | /i/-/i/0.01 | /y/-/u/0.91 | /ɯ/-/ɚ/0.99 | /u/-/u/0.92 | /e/-/ɛ/0.90 | /œ/-/ɚ/0.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Jonge, K.; Maxwell, O.; Zhao, H. Learning on the Field: L2 Turkish Vowel Production by L1 American English-Speaking NGOs in Turkey. Languages 2022, 7, 252. https://doi.org/10.3390/languages7040252
de Jonge K, Maxwell O, Zhao H. Learning on the Field: L2 Turkish Vowel Production by L1 American English-Speaking NGOs in Turkey. Languages. 2022; 7(4):252. https://doi.org/10.3390/languages7040252
Chicago/Turabian Stylede Jonge, Keryn, Olga Maxwell, and Helen Zhao. 2022. "Learning on the Field: L2 Turkish Vowel Production by L1 American English-Speaking NGOs in Turkey" Languages 7, no. 4: 252. https://doi.org/10.3390/languages7040252