
The Seeds of the Noun–Verb Distinction in the Manual Modality: Improvisation and Interaction in the Emergence of Grammatical Categories

 ,
,
Abstract
:1. Introduction
1.1. Noun–Verb Distinctions in Natural Sign Languages
1.2. The Emergence of Grammatical Categories
1.3. Experimentally Modelling the Noun–Verb Distinction
2. Experiment 1
2.1. Methods
2.1.1. Participants
2.1.2. Materials
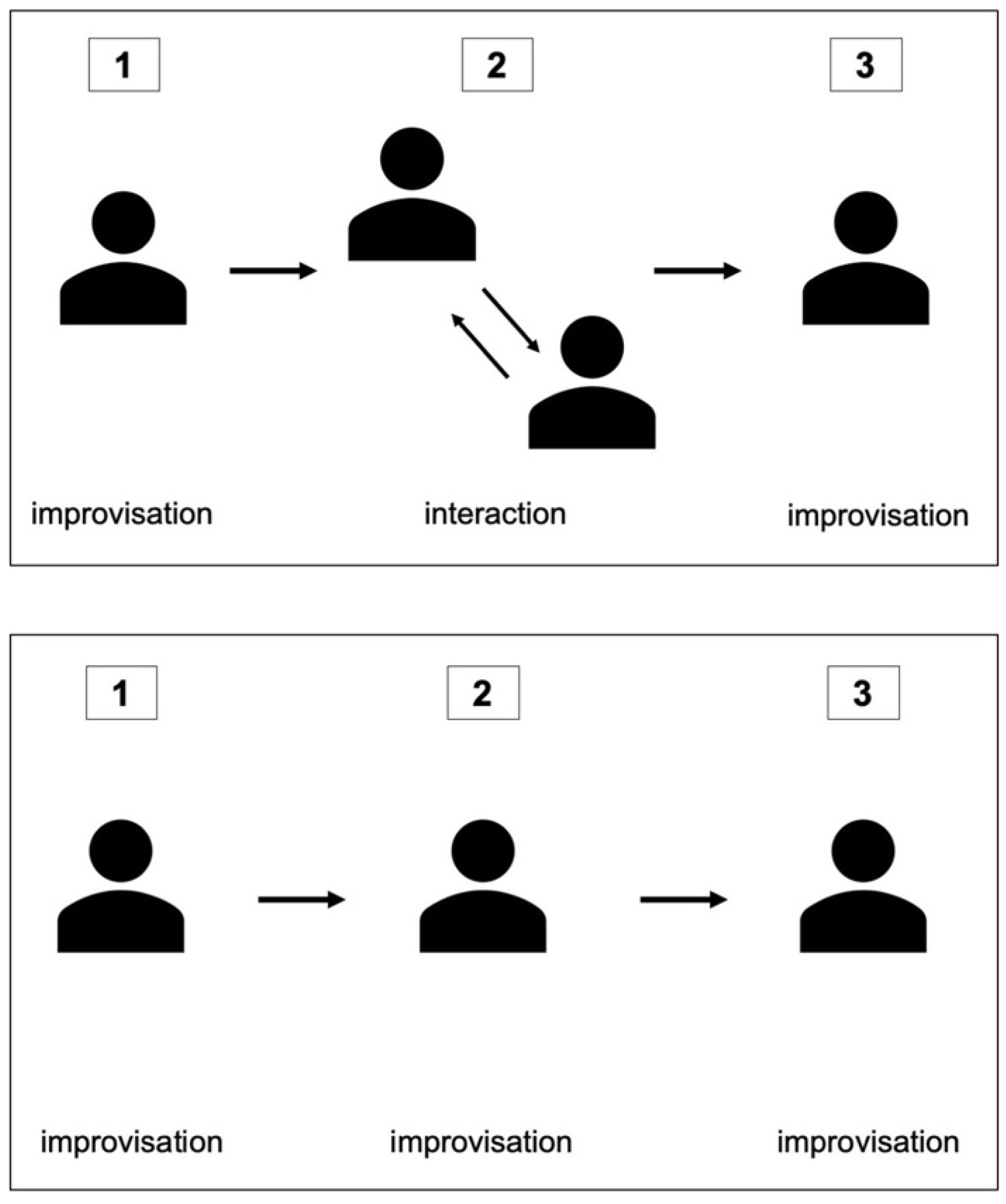
2.1.3. Procedure
- Target object–foil context: a vignette sharing the target object but showing the non-target action. For example, if the target vignette shows the typical camera context (taking a photo), then this foil would show an atypical camera context (e.g., dig with camera, shown in Figure 3, image 2).
- Foil object–target context: a vignette sharing the target context (typical or atypical) for a different object. For example, if the target vignette shows the typical camera context, this foil would show the typical context for another object (e.g., cut with scissors, shown in Figure 3, image 3).
- Foil object–foil context: a vignette that does not match the target vignette on either object or context, but does match the other foils. For example, if the target vignette shows the typical camera context, and the first foil shows the typical context for scissors, then this foil would show the atypical context for scissors (shown in Figure 3, image 1).
2.1.4. Gesture Coding
- Target action: gestures representing the action related to the object used in the stimulus; a functional action showing how the target object is used. For example, for the target object camera, the target action would be taking a photo with a camera
- Target other: gestures related to the target object, which are not the functional actions associated with that object. For example, for nail polish, a gesture showing the action of opening the nail polish bottle in order to perform the target action of painting the nails.
- Not related: gestures not related to the target object, but some other component of the scene, such as the glass of water or bin used in some of the videos.
- Verb: gestures representing the atypical verb. For example, drop, dig, cover.
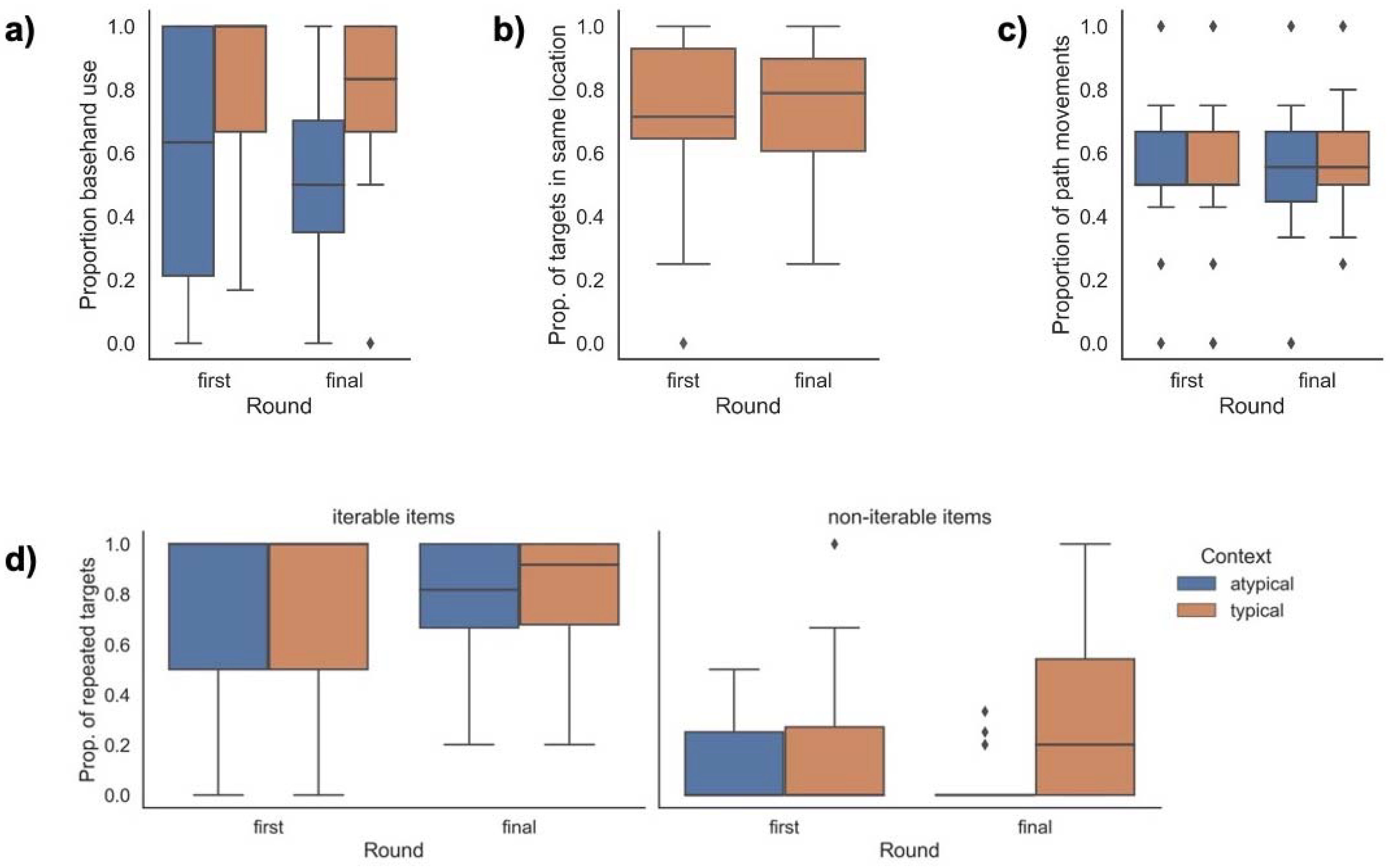
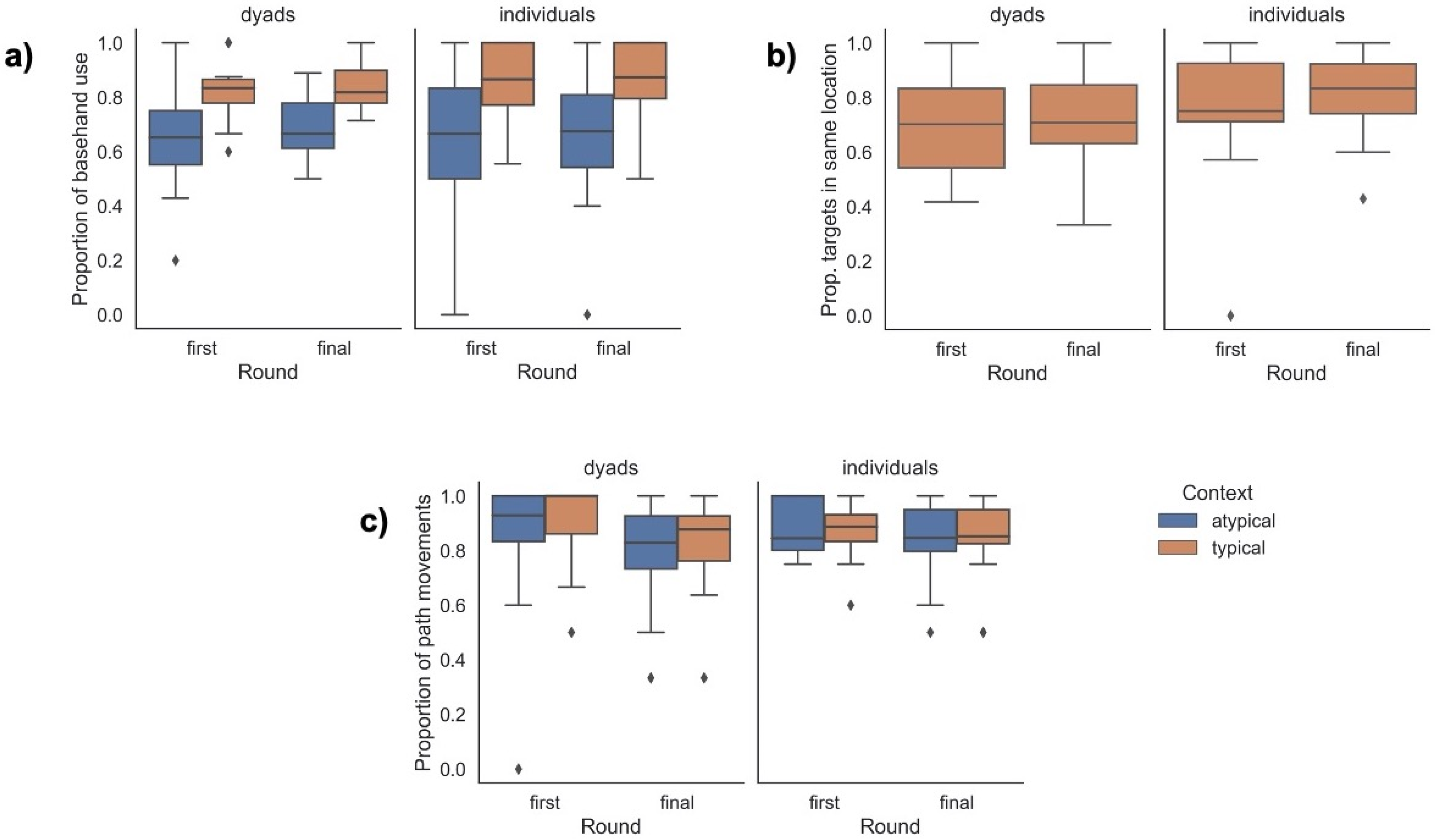
- Base hand use: the use of a non-dominant hand in a stationary gesture acting as a ground for the dominant hand (e.g., representing the wall in a hammering gesture). Only two-handed asymmetrical gestures (such as representing hammering a wall) can be coded for base hand use (i.e., symmetrical two-handed gestures cannot be articulated with a base hand).
- Gesture location: We note the location of the gesture as either placed on the body (specified as eyes, mouth, ear, shoulder, torso) or in neutral space (specified in different zones related to height and laterality of the gesture).
- Gesture size: We code gestures as comprising local movement only (articulated using the wrist, thumb or finger joints) or path movement (the elbow, shoulder and trunk are involved in the movement; note that this code subsumes local movements).
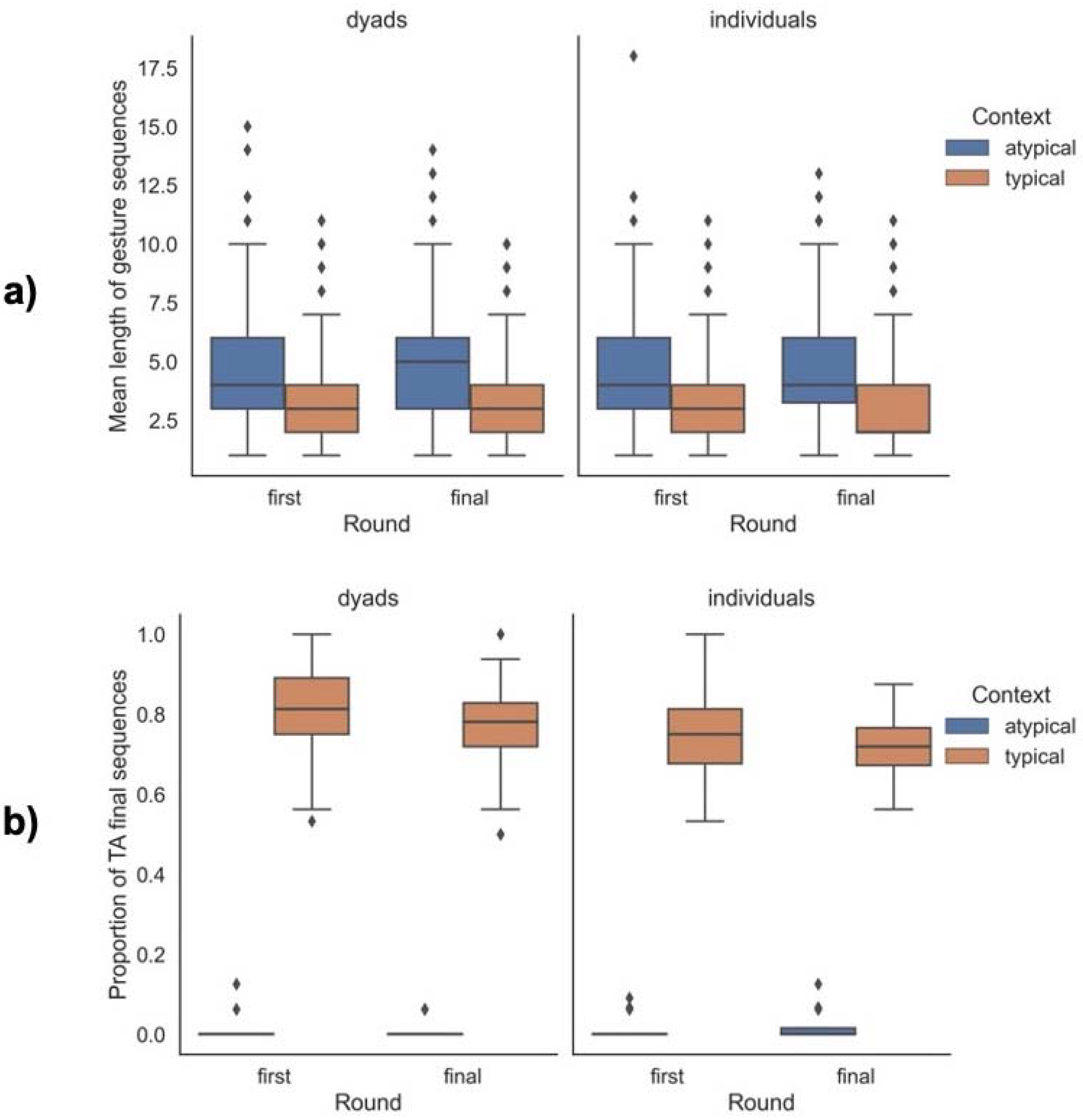
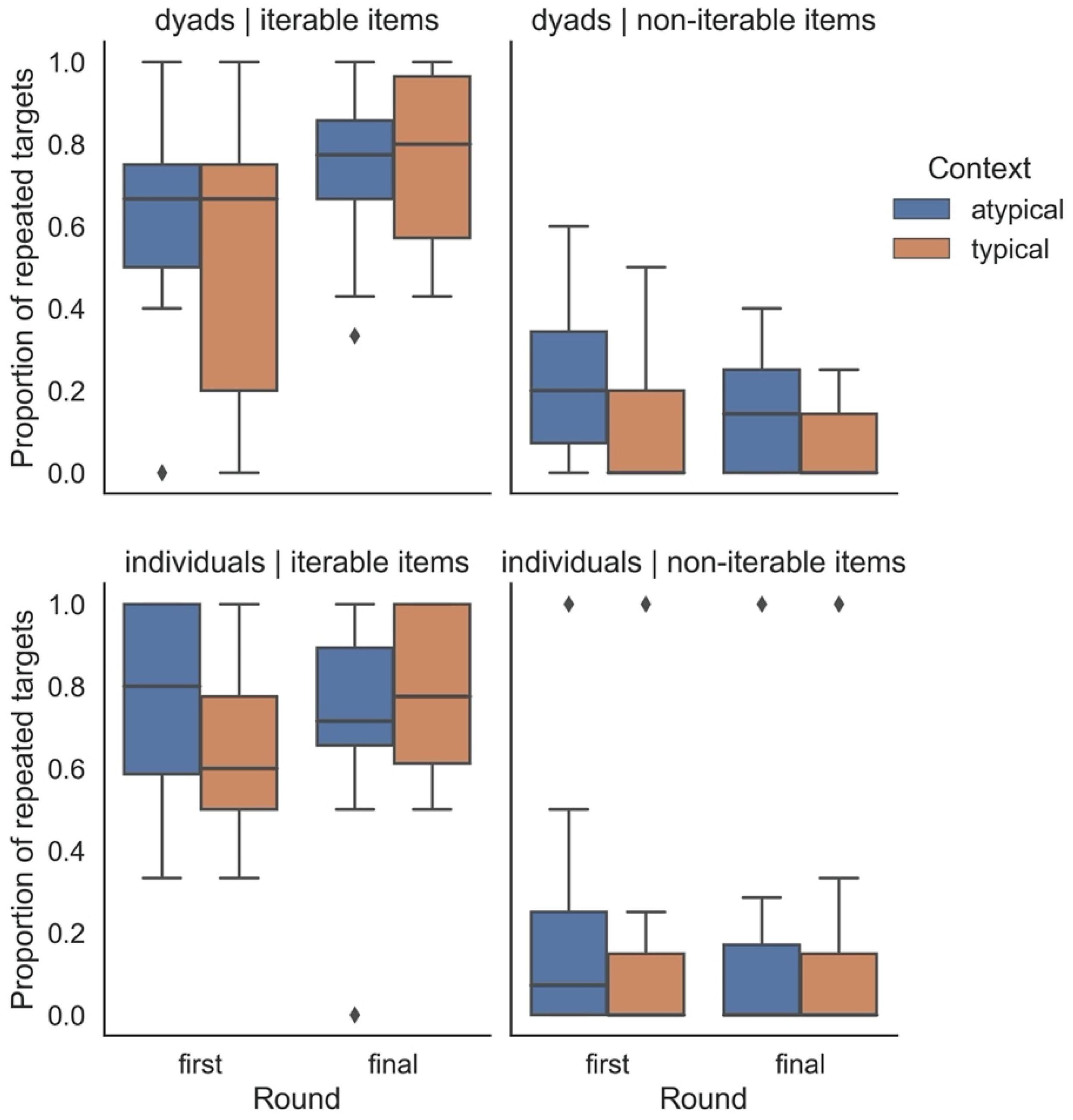
- Repetitions: We note whether or not there is a repetition within a single gesture unit (target action).
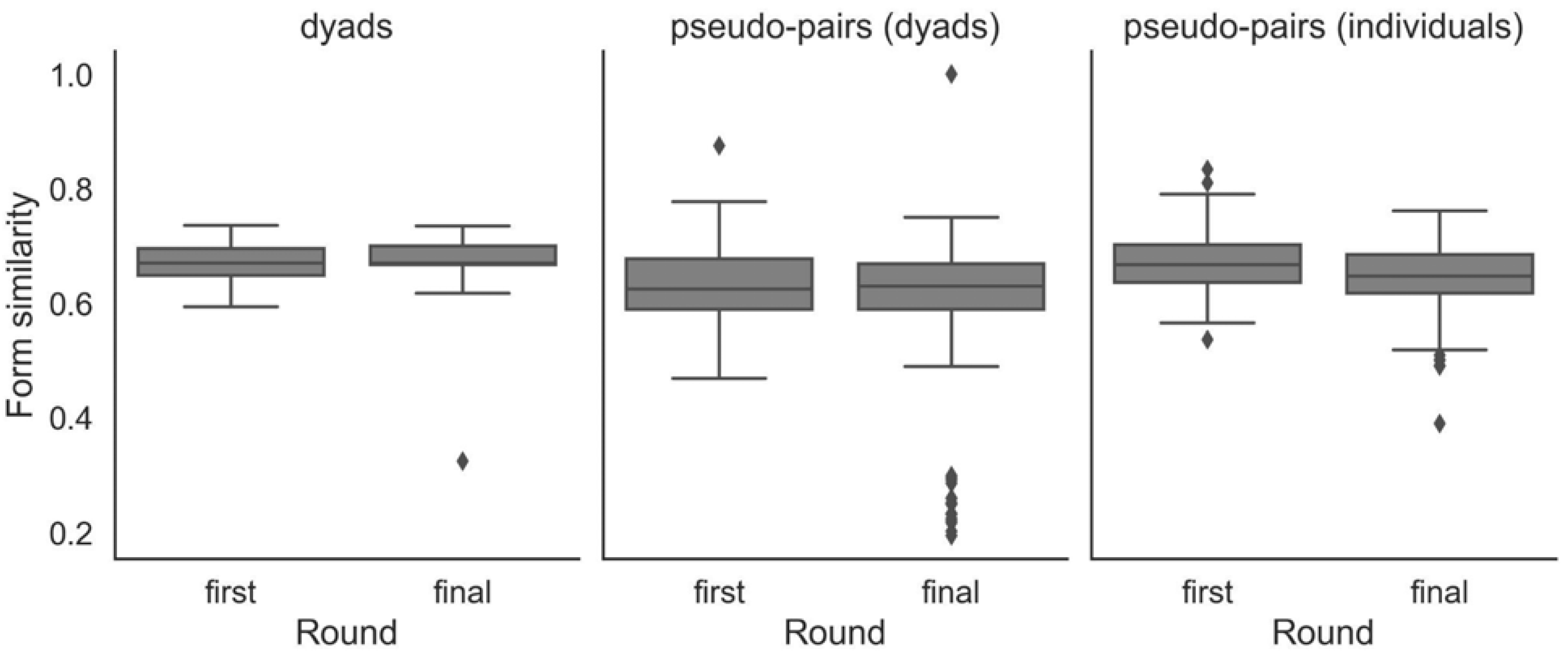
2.2. Results
2.3. Experiment 1 Summary
3. Experiment 2
3.1. Methods
3.1.1. Participants
3.1.2. Materials
3.1.3. Procedure
3.1.4. Coding
3.2. Results
3.3. Experiment 2 Summary
4. General Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | While accounts exist suggesting that some languages do not have clear noun-verb categories (Kaufman 2009; Kinkade 1983), these accounts have proved controversial with others providing analysis that shows while categories may not be overtly marked, nominals and predicates are distinguished at some level (Baker 2003; Koch and Matthewson 2009). |
| 2 | The full list of items included can be found at OSF page. https://osf.io/qzgjt (accessed on 21 March 2022). |
| 3 | A list of target actions can be found at https://osf.io/qzgjt (accessed on 21 March 2022). |
| 4 | Plots throughout the manuscript were generated using the Python libraries Matplotlib and Seaborn (Hunter 2007; Waskom 2021). |
| 5 | A full description of vignettes can be found at https://osf.io/qzgjt (accessed on 21 March 2022). |
References
- Abner, Natasha. 2017. What You See Is What You Get.Get: Surface Transparency and Ambiguity of Nominalizing Reduplication in American Sign Language. Syntax 20: 317–52. [Google Scholar] [CrossRef]
- Abner, Natasha. 2021. Determiner phrases—Theoretical perspectives. In Routledge Handbook of Theoretical and Experimental Sign Language Research. Edited by Josep Quer, Roland Pfau and Annika Herrman. London: Routledge, pp. 213–31. [Google Scholar] [CrossRef]
- Abner, Natasha, Molly Flaherty, Katelyn Stangl, Marie Coppola, Diane Brentari, and Susan Goldin-Meadow. 2019. The noun-verb distinction in established and emergent sign systems. Language 95: 230–67. [Google Scholar] [CrossRef]
- Aronoff, Mark, Irit Meir, and Wendy Sandler. 2005. The Paradox of Sign Language Morphology. Language 81: 301–44. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baker, Mark C. 2003. Lexical Categories: Verbs, Nouns and Adjectives. Cambridge: Cambridge University Press. [Google Scholar] [CrossRef]
- Bates, Douglas, Ben Bolker, Martin Machler, and Steven C. Walker. 2015. Fitting Linear Mixed-Effects Models Using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Beckner, Clay, Janet B. Pierrehumbert, and Jennifer Hay. 2017. The emergence of linguistic structure in an online iterated learning task. Journal of Language Evolution 2: 160–76. [Google Scholar] [CrossRef] [Green Version]
- Bickerton, Derek. 1990. Language and Species. Chicago: University of Chicago Press. [Google Scholar]
- Carrigan, Emily M., and Marie Coppola. 2017. Successful communication does not drive language development: Evidence from adult homesign. Cognition 158: 10–27. [Google Scholar] [CrossRef] [Green Version]
- Christensen, Peer, Riccardo Fusaroli, and Kristian Tylén. 2016. Environmental constraints shaping constituent order in emerging communication systems: Structural iconicity, interactive alignment and conventionalization. Cognition 146: 67–80. [Google Scholar] [CrossRef] [Green Version]
- Cohen, Jacob. 1960. A Coefficient of Agreement for Nominal Scales. Educational and Psychological Measurement 20: 37–46. [Google Scholar] [CrossRef]
- Coppola, Marie, and Elissa L. Newport. 2005. Grammatical subjects in homesign: Abstract linguistic structure in adult primary gesture systems without linguistic input. Proceedings of the National Academy of Sciences 102: 19259–53. [Google Scholar] [CrossRef] [Green Version]
- Dingemanse, Mark, Sean G. Roberts, Julia Baranova, Joe Blythe, Paul Drew, Simeon Floyd, Rosa S. Gisladottir, Kobin H. Kendrick, Stephen C. Levinson, Elizabeth Manrique, and et al. 2015. Universal Principles in the Repair of Communication Problems. PLoS ONE 10: e0136100. [Google Scholar] [CrossRef]
- Emmorey, Karen, and Jennie Pyers. 2017. Cognitive biases in construing iconic mappings. Paper presented at the 11th International Symposium on Iconicity in Language and Literature, Brighton, UK, April 7; Available online: https://osf.io/awyg2 (accessed on 21 March 2022).
- Fay, Nicolas, Michael Arbib, and Simon Garrod. 2013. How to bootstrap a human communication system. Cognitive Science 37: 1356–67. [Google Scholar] [CrossRef] [PubMed]
- Fay, Nicolas, Simon Garrod, Leo Roberts, and Nik Swoboda. 2010. The interactive evolution of human communication systems. Cognitive Science 34: 351–86. [Google Scholar] [CrossRef] [PubMed]
- Flaherty, Molly, Asha Sato, and Simon Kirby. 2020. An Emergent Language Becomes Smaller as It Evolves: New Evidence From Motion Tracking in Nicaraguan Sign Language. In The Evolution of Language: Proceedings of the 13th International Conference (EvoLang13). Edited by Andrea C. Ravignani, Chiara Barbieri, Mauricio Martins, Molly Flaherty, Ella Lattenkamp, Hannah Little, Katie Mudd and Tessa Verhoef. Nijmegen: The Evolution of Language Conferences. [Google Scholar] [CrossRef]
- Garrod, Simon, and Martin J. Pickering. 2009. Joint Action, Interactive Alignment, and Dialog. Topics in Cognitive Science 1: 292–304. [Google Scholar] [CrossRef] [PubMed]
- Garrod, Simon, Nicolas Fay, John Lee, Jon Oberlander, and Tracy MacLeod. 2007. Foundations of representation: Where might graphical symbol systems come from? Cognitive Science 31: 961–87. [Google Scholar] [CrossRef]
- Gershkoff-Stowe, Lisa, and Susan Goldin-Meadow. 2002. Is there a natural order for expressing semantic relations? Cognitive Psychology 45: 375–412. [Google Scholar] [CrossRef]
- Gibson, Edward, Steven T. Piantadosi, Kimberly Brink, Leon Bergen, Eunice Lim, and Rebecca Saxe. 2013. A Noisy-Channel Account of Crosslinguistic Word-Order Variation. Psychological Science 24: 1079–88. [Google Scholar] [CrossRef] [Green Version]
- Goldin-Meadow, Susan, Wing Chee So, Asli Ozyürek, and Carolyn Mylander. 2008. The natural order of events: How speakers of different languages represent events nonverbally. Proceedings of the National Academy of Sciences of the United States of America 105: 9163–68. [Google Scholar] [CrossRef] [Green Version]
- Goldin-Meadow, Susan. 2003. The Resilience of Language. London: Taylor and Francis. [Google Scholar]
- Goldin-Meadow, Susan, and Heidi Feldman. 1977. The development of language-like communication without a language model. Science 197: 401–3. [Google Scholar] [CrossRef]
- Goldin-Meadow, Susan, Cynthia Butcher, Carolyn Mylander, and Mark Dodge. 1994. Nouns and Verbs in a Self-Styled Gesture System: What’s in a name? Cognitive Psychology 27: 259–319. [Google Scholar] [CrossRef]
- Goldin-Meadow, Susan, Diane Brentari, Marie Coppola, Laura Horton, and Ann Senghas. 2014. Watching language grow in the manual modality: Nominals, predicates, and handshapes. Cognition 136: 381–95. [Google Scholar] [CrossRef] [Green Version]
- Hall, Matthew L., Rachel I. Mayberry, and Victor S. Ferreira. 2013. Cognitive constraints on constituent order: Evidence from elicited pantomime. Cognition 129: 1–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Healey, Patrick G. T., Nik Swoboda, Ichiro Umata, and James King. 2007. Graphical language games: Interactional constraints on representational form. Cognitive Science 31: 285–309. [Google Scholar] [CrossRef] [PubMed]
- Heine, Bernd, and Tania Kuteva. 2007. The Genesis of Grammar: A Reconstruction. Oxford: Oxford University Press. [Google Scholar]
- Hockett, Charles F. 1977. The View from Language: Selected Essays, 1948–1974. Athens: The University of Georgia Press. [Google Scholar]
- Hopper, Paul J., and Sandra Thompson. 1985. The iconicity of the universal categories ‘noun’ and ‘verb’. In Iconicity in Syntax. Edited by John Haiman. Amsterdam: John Benjamins. [Google Scholar]
- Hunger, Barbara. 2006. Noun/Verb Pairs in Austrian Sign Language (ÖGS). Available online: https://doi.org/info:doi/10.1075/sll.9.1.06hun (accessed on 21 March 2022).
- Hunter, John D. 2007. Matplotlib: A 2D Graphics Environment. Computing in Science & Engineering 9: 90–95. [Google Scholar]
- Hurford, James R. 2007. The Origins of Meaning: Language in the Light of Evolution. Oxford: Oxford University Press. [Google Scholar]
- Hwang, So-One, Nozomi Tomita, Hope Morgan, Rabia Ergin, Deniz Ilkbasaran, Sharon Seegers, Ryan Lepic, and Carol Padden. 2016. Of the body and the hands: Patterned iconicity for semantic categories. Language and Cognition 9: 573–602. [Google Scholar] [CrossRef] [Green Version]
- Jackendoff, Ray. 2002. Foundations of Language. Oxford: Oxford University Press. [Google Scholar]
- Johnston, Trevor. 2001. Nouns and verbs in Australian Sign Language: An open and shut case? Journal of Deaf Studies and Deaf Education 6: 235–57. [Google Scholar] [CrossRef]
- Kaufman, Daniel. 2009. Austronesian Nominalism and Its Consequences: A Tagalog Case Study. Theoretical Linguistics 35: 1–49. [Google Scholar] [CrossRef]
- Kimmelman, Vadim. 2009. Parts of speech in Russian Sign Language: The role of iconicity and economy. Sign Language and Linguistics 12: 161–86. [Google Scholar] [CrossRef]
- Kinkade, M. Dale. 1983. Salish evidence against the universality of ‘noun’ and ‘verb’. Lingua 60: 25–39. [Google Scholar] [CrossRef]
- Kirby, Simon. 2016. VideoBox: Video Recording, Streaming and Mirroring for Experiments. Available online: http://edin.ac/2haREUz (accessed on 21 March 2022).
- Kirby, Simon, Monica Tamariz, Hannah Cornish, and Kenny Smith. 2015. Compression and Communication in the Cultural Evolution of Linguistic Structure linguistic structure. Cognition 141: 87–102. [Google Scholar] [CrossRef] [Green Version]
- Kirby, Simon, Thomas L. Griffiths, and Kenny Smith. 2014. Iterated learning and the evolution of language. Current Opinion in Neurobiology 28: 108–14. [Google Scholar] [CrossRef] [Green Version]
- Kocab, Annemarie, Hannah Lam, and Jesse Snedeker. 2018. When Cars Hit Trucks and Girls Hug Boys: The Effect of Animacy on Word Order in Gestural Language Creation. Cognitive Science 42: 918–38. [Google Scholar] [CrossRef] [Green Version]
- Koch, Karsten, and Lisa Matthewson. 2009. The Lexical Category Debate in Salish and Its Relevance for Tagalog. Theoretical Linguistics 35: 125–37. [Google Scholar] [CrossRef]
- Kubus, Okan. 2008. An analysis of Turkish Sign Language (TİD) Phonology and Morphology. Master’s thesis, Middle East Technical University, Ankara, Turkey. [Google Scholar]
- McCaskill, Carolyn, Ceil Lucas, Robert Bayley, and Joseph Hill. 2011. The Hidden Treasure of Black ASL: Its History and Structure. Washington, DC: Gallaudet University Press. [Google Scholar]
- Meir, Irit, Mark Aronoff, Carl Börstell, So-One Hwang, Deniz Ilkbasaran, Itamar Kastner, Adi Lifshitz, Ben Basat, Carol Padden, and Wendy Sandler. 2014. The effect of being human and the basis of grammatical word order: Insights from novel communication systems and young sign languages. Cognition 158: 1–40. [Google Scholar] [CrossRef]
- Mesoudi, Alex, and Alex Thornton. 2018. What Is Cumulative Cultural Evolution? Proceedings of the Royal Society B: Biological Sciences 13: 285. [Google Scholar] [CrossRef] [Green Version]
- Mirus, Gene, Christian Rathmann, and Richard P. Meier. 2001. Proximalization and distalization of sign movement in adult learners. In Signed Languages: Discoveries from International Research. Edited by Valerie M. Dively, Melanie Metzger, Anne Marie Baer and Sarah Taub. Washington, DC: Gallaudet University Press, pp. 103–19. [Google Scholar]
- Morford, Jill P., and Susan Goldin-Meadow. 1997. From here and now to there and then: The development of displaced reference in homesign and English. Child Development 68: 420–35. [Google Scholar] [CrossRef]
- Motamedi, Yasamin, Kenny Smith, Marieke Schouwstra, Jennifer Culbertson, and Simon Kirby. 2021. The emergence of systematic argument distinctions in artificial sign languages. Journal of Language Evolution 6: 77–98. [Google Scholar] [CrossRef]
- Motamedi, Yasamin, Marieke Schouwstra, Kenny Smith, Jennifer Culbertson, and Simon Kirby. 2019. Evolving artificial sign languages in the lab: From improvised gesture to systematic sign. Cognition 192: 103964. [Google Scholar] [CrossRef] [Green Version]
- Namboodiripad, Savithry, Daniel Lenzen, Ryan Lepic, and Tessa Verhoef. 2016. Measuring Conventionalization in the Manual Modality. Journal of Language Evolution 1: 109–18. [Google Scholar] [CrossRef] [Green Version]
- Napoli, Donna Jo, and Rachel Sutton-Spence. 2014. Order of the major constituents in sign languages: Implications for all language. Frontiers in Psychology 5: 376. [Google Scholar] [CrossRef] [Green Version]
- Nölle, Jonas, Marlene Staib, Riccardo Fusaroli, and Kristian Tylén. 2018. The emergence of systematicity: How environmental and communicative factors shape a novel communication system. Cognition 181: 93–104. [Google Scholar] [CrossRef] [Green Version]
- Özçalışkan, Şeyda, Ché Lucero, and Susan Goldin-Meadow. 2016. Does language shape silent gesture? Cognition 148: 10–18. [Google Scholar] [CrossRef] [Green Version]
- Özyürek, Asli, Reyhan Furman, and Susan Goldin-Meadow. 2015. On the way to language: Event segmentation in homesign and gesture. Journal of Child Language 42: 64–94. [Google Scholar] [CrossRef] [Green Version]
- Peirce, Jonathan W. 2007. PsychoPy–Psychophysics software in Python. Journal of Neuroscience Methods 162: 8–13. [Google Scholar] [CrossRef] [Green Version]
- Perlman, Marcus, Rick Dale, and Gary Lupyan. 2015. Iconicity can ground the creation of vocal symbols. Royal Society Open Science 2: 150152. [Google Scholar] [CrossRef] [Green Version]
- Pizzuto, Elena, and Serena Corazza. 1996. Noun morphology in Italian Sign Language (LIS). Lingua 98: 169–96. [Google Scholar] [CrossRef]
- R Core Team. 2013. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing, Available online: http://www.R-project.org/ (accessed on 21 March 2022).
- Raviv, Limor, Antje Meyer, and Shiri Lev-Ari. 2019. Compositional structure can emerge without generational transmission. Cognition 182: 151–64. [Google Scholar] [CrossRef] [Green Version]
- Roberts, Sean G., and Stephen C. Levinson. 2017. Conversation, cognition and cultural evolution: A model of the cultural evolution of word order through pressures imposed from turn taking in conversation. Interaction Studies 18: 402–42. [Google Scholar] [CrossRef] [Green Version]
- Sandler, Wendy, Irit Meir, Carol Padden, and Mark Aronoff. 2005. The emergence of grammar: Systematic structure in a new language. Proceedings of the National Academy of Sciences of the United States of America 102: 2661–65. [Google Scholar] [CrossRef] [Green Version]
- Schouwstra, Marieke, and Henrietta de Swart. 2014. The semantic origins of word order. Cognition 131: 431–36. [Google Scholar] [CrossRef]
- Schouwstra, Marieke, Kenny Smith, and Simon Kirby. 2016. From natural order to convention in silent gesture. The Evolution of Language: Proceedings of the 11th International Conference (EVOLANG11). Available online: http://evolang.org/neworleans/papers/67.html (accessed on 21 March 2022).
- Schreurs, Linda. 2006. The Distinction between Formally and Semantically Related Noun-Verb Pairs in Sign Language of the Netherlands (NGT). Master’s thesis, University of Amsterdam, Amsterdam, The Netherlands. [Google Scholar]
- Silvey, Catriona, Simon Kirby, and Kenny Smith. 2019. Communication increases category structure and alignment only when combined with cultural transmission. Journal of Memory and Language 109: 104051. [Google Scholar] [CrossRef]
- Singleton, Jenny L., Susan Goldin-Meadow, and David McNeill. 1995. The Cataclysmic Break Between Gesticulation and Sign: Evidence Against a Unified Continuum of Gestural Communication. In Language, Gesture and Space. Edited by Karen Emmorey and Judy S. Reilly. Mahwah: Lawrence Erlbaum Associates Publishers, pp. 287–311. [Google Scholar]
- Sloetjes, Han, and Peter Wittenburg. 2008. Annotation by category—ELAN and ISO DCR. Paper presented at the 6th International Conference on Language Resources and Evaluation, Marrakech, Morocco, May 28–30. [Google Scholar]
- Stivers, Tania, Nick J. Enfield, Penelope Brown, Christina Englert, Makoto Hayashi, Trine Heinemann, Gertie Hoymann, Federico Rossano, Jan Pieter de Ruiter, Kyung-Eun Yoon, and et al. 2009. Universals and cultural variation in turn-taking in conversation. Proceedings of the National Academy of Sciences of the United States of America 106: 10587–92. [Google Scholar] [CrossRef] [Green Version]
- Sulik, Justin. 2018. Cognitive mechanisms for inferring the meaning of novel signals during symbolisation. PLoS ONE 13: e0189540. [Google Scholar] [CrossRef] [Green Version]
- Supalla, Ted, and Elissa L. Newport. 1978. How many seats in a chair? The derivation of nouns and verbs in American Sign Language. In Understanding Language through Sign Language Research. Edited by Patricia Siple. New York: Academic Press, pp. 91–131. [Google Scholar]
- Tamariz, Monica, and Simon Kirby. 2016. The cultural evolution of language. Current Opinion in Psychology 8: 37–43. [Google Scholar] [CrossRef] [Green Version]
- Theisen, Carrie A., Jon Oberlander, and Simon Kirby. 2010. Systematicity and arbitrariness in novel communication systems. Interaction Studies 11: 14–32. [Google Scholar] [CrossRef] [Green Version]
- Tkachman, Oksana, and Wendy Sandler. 2013. The noun–verb distinction in two young sign languages. Gesture 13: 253–86. [Google Scholar] [CrossRef]
- Verhoef, Tessa, Simon Kirby, and Bart de Boer. 2014. Emergence of combinatorial structure and economy through iterated learning with continuous acoustic signals. Journal of Phonetics 43: 57–68. [Google Scholar] [CrossRef]
- Waskom, Michael L. 2021. Seaborn: Statistical data visualization. Journal of Open Source Software 6: 3021. [Google Scholar] [CrossRef]
- Wilbur, Ronnie B. 2003. Representations of telicity in ASL. In Proceedings from the Annual Meeting of the Chicago Linguistic Society. Chicago: Chicago Linguistic Society, vol. 39. [Google Scholar]
- Wilbur, Ronnie B. 2008. Complex predicates involving events, time and aspect: Is this why sign languages look so similar? In Signs of the Time: Selected Papers from TISLR 2004. Edited by Josep Quer. Seedorf: Signum Press. [Google Scholar]
- Wilcox, Sherman. 2004. Cognitive iconicity: Conceptual spaces, meaning, and gesture in signed language. Cognitive Linguistics 15: 119–47. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Silent Gesture | Abner et al. (2019), Natural Languages | ||||
|---|---|---|---|---|---|
| Experiment 1 | Experiment 2 | ASL | NSL | Nicaraguan Homesigners | |
| Utterance final position | Higher proportion of utterance-final targets for typical scenes | Higher proportion of utterance-final targets for typical scenes | Higher proportion of utterance-final verb targets | Higher proportion of utterance-final verb targets | Higher proportion of utterance-final verb targets |
| Base hand | Higher proportion of base hand use with targets for typical scenes | Higher proportion of base hand use with targets for typical scenes | Higher proportion of base hand use with verb targets | Higher proportion of base hand use with verb targets for more recent cohort signers | No reliable trends found. |
| Location | Same location used for both typical and atypical targets | Same location used for both typical and atypical targets | Not studied | Not studied | Not studied |
| Size of movement | No reliable trends found | No reliable trends found | Higher proportion of proximal movement with verb targets | Higher proportion of proximal movement with verb targets | Higher proportion of proximal movement with verb targets |
| Repetitions | Higher proportion of repetitions for iterable targets and for targets in typical scenes | Higher proportion of repetitions for iterable targets. | Higher proportion of repetitions with noun targets for iterable and non-iterable targets | Higher proportion of repetitions for iterable targets; higher proportion of repetitions for noun targets for later cohorts | Higher proportion of repetitions for iterable targets. Tendency to produce more repetitions for noun targets. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Motamedi, Y.; Montemurro, K.; Abner, N.; Flaherty, M.; Kirby, S.; Goldin-Meadow, S. The Seeds of the Noun–Verb Distinction in the Manual Modality: Improvisation and Interaction in the Emergence of Grammatical Categories. Languages 2022, 7, 95. https://doi.org/10.3390/languages7020095
Motamedi Y, Montemurro K, Abner N, Flaherty M, Kirby S, Goldin-Meadow S. The Seeds of the Noun–Verb Distinction in the Manual Modality: Improvisation and Interaction in the Emergence of Grammatical Categories. Languages. 2022; 7(2):95. https://doi.org/10.3390/languages7020095
Chicago/Turabian StyleMotamedi, Yasamin, Kathryn Montemurro, Natasha Abner, Molly Flaherty, Simon Kirby, and Susan Goldin-Meadow. 2022. "The Seeds of the Noun–Verb Distinction in the Manual Modality: Improvisation and Interaction in the Emergence of Grammatical Categories" Languages 7, no. 2: 95. https://doi.org/10.3390/languages7020095