1. Introduction
The empirical landscape related to islands and island sensitivity has been gradually shifting since the first discoveries of islands, occasioning new ideas about the general source of island sensitivity, as well as the nature of particular violations. An example of this shift, and the focus of our study, is relative clauses (henceforth RCs), long considered strong islands for extraction
1. In the first two decades following
Ross (
1967), a picture emerged in which the Mainland Scandinavian (MS) languages appeared to systematically evade some of the locality constraints proposed by Ross, including the relative clause (RC) part of the complex NP constraint; research into extraction from RC in MS has consistently shown a selective pattern of acceptable extraction, where RCs in some linguistic environments, but not all, facilitate extraction from the RC (
Erteschik-Shir 1973;
Erteschik-Shir and Lappin 1979;
Allwood 1976,
1982;
Maling and Zaenen 1982;
Taraldsen 1981,
1982). While the MS extraction patterns, and their proper analysis, is a topic of debate (
Engdahl 1997;
Kush et al. 2013,
2019;
Lindahl 2017;
Müller 2014,
2015), it remains a mystery why extraction from RCs should be so degraded in other languages (compared to MS). It is also not yet fully clear why it would be more degraded in some linguistic environments, a distribution which has sometimes suggested that the theory of locality be defined at least in part in terms of information structure, or processing limitations and constraints on working memory (
Ambridge and Goldberg 2008;
Erteschik-Shir 1973;
Hofmeister and Sag 2010;
Kluender 1992;
Kluender and Kutas 1993;
Kuno 1987). A pressing set of empirical questions therefore emerges regarding the extent of variation across both of these dimensions: across languages, and within a language, across linguistic environments. To the extent that some languages, such as the MS languages, show a selective pattern of extraction from RCs, the question we address is whether these environments vary across languages. We focus on English and present experimental evidence for acceptable extraction from English RCs. As we show, the environments in which extraction is most acceptable in English bear a significant resemblance, if not full identity, to environments identified in other languages. Based on this pattern we suggest that RCs in English are weak islands, exactly as in MS and in Hebrew (
Nyvad et al. 2017;
Lindahl 2014,
2017;
Sichel 2018), and that strong island effects arise only in a subset of environments, which we define as presuppositional DPs. Some have argued that RCs which allow sub-extraction are to be characterized in information-structural terms such as backgroundedness or presupposition (
Erteschik-Shir 1973,
1982;
Ambridge and Goldberg 2008;
Engdahl 1982;
Löwenadler 2015).
Sichel (
2018) argues that the external factors that govern extraction from an RC are no different from those that govern extraction from ordinary DPs: the DP from which extraction takes place must be non-presuppositional.
Presuppositional noun phrases are noun phrases whose denotations have already been introduced into the discourse, sometimes also referred to as given. Their referents are presupposed to exist at the point at which the sentence is presented, and the containing sentence asserts that something holds of the referent designated by the presuppositional NP. In contrast, the NP in the pivot of an existential statement, bracketed in (1a), is non-presuppositional, since the sentence is introducing the referent into the discourse, by asserting that it exists. Similarly, the predicative NP following the copula, bracketed in (1b), is also non-presuppostional, since it does not even denote an individual, let alone a presupposed one.
- (1)
There is significant consensus in the literature that extraction from simple NPs, in languages such as English, which allow it, is limited to non-presuppositional NPs (sometimes called
non-specific indefinites or
non-given NPs;
Bianchi and Chesi 2014,
Diesing 1992,
Fiengo and Higginbotham 1981). For example, it is easier to extract from a non-presuppositional NP in an existential construction than from a presuppositional NP in an ordinary clause
Moro 1997, in (2). The correlation between presuppositionality and sub-extraction is further observed within the class of direct objects, in the distinction between weak and strong quantifiers (
Milsark 1974). NPs with weak quantifiers, such as
many or
few, are allowed in the existential construction, whereas NPs with strong quantifiers, such as
each or
most, are excluded, in (3). When in direct object position, the former permit sub-extraction much more readily than the latter, in (4).
- (2)
- (3)
- (4)
Who did you see a picture of?
Who did you see many/several/few pictures of?
*Who did you see the/each picture of?
*Who did you see most pictures of?
In the languages in which it has been attested, extraction from RCs seems to follow a similar, if not identical, pattern. Beyond the known cases in MS, additional acceptable cases of overt extraction from RCs have been attested over the years, in Italian (5a, 7c), Spanish, French, and in Hebrew (5d, 6, 7d). These have been observed in particular environments: when the RC is the pivot of an existential construction, in (5), when the RC is a predicate nominal, in (6), and when the RC is the direct object of an existential-like transitive construction, dubbed
Evidential Existential by Rubovitz-Mann (
Erteschik-Shir 1973;
Rubovitz-Mann 2000,
2012), in (7).
2 And, despite history and appearances, there are reasons to doubt whether English deserves its reputation as a language whose RCs are always strong islands. Instances of extraction in English have surfaced sporadically in the literature, over the years, and they seem to track the same environments, at least impressionistically, as seen in (8a, 8b, 8c) (
Chung and McCloskey 1983;
Kuno 1976;
McCawley 1981).
- (5)
Det er der mange der kan lide.
that are there many who like
Det språket finns det många som talar.
that language exist it many that speak
‘There are many who speak that language’. (Swedish;
Engdahl 1997, p. 13)
Ida, di cui non c’è nessuno che sia mai stato innamorato …
‘Ida, whom there is nobody that was ever in love with, …’
Al lexem Saxor, yeS rak gvina axat Se-keday limraox.
on bread black be only cheese one that-worthy to.spread
‘On black bread, there is only one cheese that’s worth spreading’.
- (6)
Al ha-haxlata ha-zot, yair lapid haya ha-axaron Se-yada
about the-decision this, Yair Lapid was the-last that-knew
‘About this decision, Yair Lapid was the last to know’. (Hebrew)
- (7)
Det kender jeg mange der kan lide.
that know I many who like
[En sådan frisyr] har jag aldrig sett någon som ser snygg ut i.
that such hairstyle have I never seen anyone who looks good in
‘That kind of hairstyle, I have never seen anyone who looks good in’.
Giorgio, al quale non conosco nessune che sarebbe disposto ad affidare i propri risparmi …
‘Giorgio, whom I don’t know anybody that would be ready to entrust with their savings …’
Me-ha-sifria ha-zot, od lo macati sefer exad Se-keday le-haS’il
from-the-library this yet not found.I book one that-worth to.borrow
‘From this library, I haven’t yet found a single book that’s worth borrowing’.
- (8)
This is the child who there is nobody who is willing to accept.
This is the one that Bob Wall was the only person who hadn’t read.
That’s one trick that I’ve known a lot of people who’ve been taken in by.
The goal of this study is to confirm this impression experimentally, by systematically manipulating these three contexts: pivot of an existential, predicate nominal, and object of an existential-like construction. To the extent that we find that the pattern of extraction in English replicates the pattern in Scandinavian, Romance, and Hebrew, we will have provided new evidence for the weak island status of English RCs; and we will also have provided new evidence for the cross-linguistically uniform relationship between the presuppositional status of the containing NP and strong islandhood. In a recent study of acceptable extraction from English RCs,
Christensen and Nyvad (
2022) examine whether English speakers show some of the same selective patterns of RC extraction that speakers of Scandinavian languages do, including sensitivity to lexical frequency, improvement over trials, and a preference for topicalization over
wh-extraction. They reason that selectivity with respect to extraction suggests that RCs are weak islands, as has been argued for MS, since weak islands allow extraction, selectively. Since they do not find the same effects in English, they conclude that in English, RCs are strong islands, blocking all extraction categorically. By the same token, the finding that English sub-extraction tracks the presuppositionality of the NP as in other languages will suggest (a) that English RCs are no different, with respect to islandhood, from Scandinavian, Romance, and Hebrew, and (b) that English RCs are weak islands. Furthermore, the effect of presuppositional NPs on sub-extraction, observed with simple NPs as well, can be attributed to a strong island, however analyzed (see
Diesing 1992 and
Sichel 2018 for an implementation in terms of syntactic position). We return to discuss the theoretical implications of this generalization in the conclusions, where we spell out the consequences for recent ideas about acceptable extraction from NP islands (
Abeillé et al. 2020;
Kush et al. 2019). This paper is organized as follows:
Section 2 introduces the study of islands in experimental syntax;
Section 3 describes the experiments;
Section 4 is the discussion of our results and their potential implications; and
Section 5 concludes.
2. Experimental Syntax of Islands
Islands are typically complex syntactic environments, embedded in complex syntactic environments, or both. This makes it a challenge to interpret the acceptability of a sentence containing an extraction from a purported island, because any judgment of acceptability is affected not only by how island-specific constraints affect grammaticality but also by any general contributors to the complexity of the sentence that affect parsability. In this study, we follow the design strategy first devised by
Sprouse (
2007), and elaborated in
Sprouse et al. (
2012), which uses a factorial experimental design to decompose the acceptability of an island extraction first into any plausible contributors to degraded acceptability that are not specific to island extraction, and then into how much is “left over” for an island constraint to explain.
We illustrate this approach with a whether-island in English, as in (9). Imagine a controlled acceptability judgment experiment in which participants assigned ratings to sentences along a 1–6 Likert-type scale, where 1 is least acceptable and 6 is most acceptable. Suppose that sentences such as (9) received, on average, a rating of 2.
- (9)
What do you wonder whether John bought?
This is a low rating, which could be attributed to a grammatical constraint that is violated by extracting the what phrase across whether. However, other characteristics of (9) could lead to degraded acceptability, including the mere presence of a whether-clause complement and the fact that a long filler-gap dependency spans two clauses. Neither of these characteristics alone violates a grammatical constraint, but each independently increases the syntactic or semantic complexity of the sentence and each thus plausibly decreases its overall acceptability. If instead of measuring the acceptability of only island-containing sentences (9), we also measure the acceptability of related sentences, then we can estimate and account for these independent contributions to acceptability.
The set of sentences in (10) realizes a 2 × 2 factorial design that relates sentences along two relevant dimensions: Dependency Length (Short, Long) and Structure (Island, Non-Island). Square brackets mark the potential island domain, and an underscore marks the gap site; hypothetical average ratings are given in angle brackets in the right margin. Notice that (10d), in the Long, whether-clause condition, is just (9).
- (10)
Short, that-clause
Who thinks that John bought a car?
Long, that-clause
What do you think that John bought ?
Short, whether-clause
Who wonders [whether John bought a car]?
Long, whether-clause
What do you wonder [whether John bought ]?
Ratings from sentences that follow the design in (10) can be used to isolate effects that are specific to extraction from an island. The ratings difference (10a)–(10b) shows that there is a cost of processing a long-distance dependency on acceptability: 6 − 4 = 2. The ratings difference (10a)–(10c) gives the acceptability cost of embedding via wonder whether vs. think that: 6 − 5 = 1. Adding these two costs together, 2 + 1 = 3, lets us predict how degraded the acceptability of (10d) should be relative to (10a), if it were only due to the independent costs of Dependency Length and Structure. Under a hypothesis of independent costs, then we should expect (10d) to receive an average rating of 3, i.e., 6 – 3. But the average rating of (10d) indicates that we have an unexplained deficit: it is one point lower than predicted. This 1-pt “deficit” provides an estimate of the island effect.
Sprouse et al. (
2012) used the term ‘DD score’, as in difference of differences, to refer to how much more was needed to explain the low acceptability of an island-containing sentence. In designs such as (10) that manipulate a Length factor with some Structure factor that has
Simple and
Complex levels, such as
Non-Island and
Island in the example above, the DD score is always defined as the differences between D1 and D2, where D1 represents
Long Simple–
Long Complex, and D2 represents
Short Simple–
Short Complex. This yields a measure that is easy to interpret: if there is an island effect, DD will be positive. In the example above, DD = 1. The presence of an island effect is thus traced to a
superadditive interaction, one which can be statistically represented by a regression of the ratings measure on the experimental factors.
The DD score method has been used to test a wide range of island types and languages other than English, including Japanese (
Sprouse et al. 2011), Brazilian Portuguese (
Almeida 2014), Italian (
Sprouse et al. 2016), Hebrew (
Keshev and Meltzer-Asscher 2018), Slovenian (
Stepanov et al. 2018), Norwegian (
Kush et al. 2018,
2019), and Modern Standard Arabic (
Tucker et al. 2019).
Kush et al. (
2018) used a design comparable to (10) to investigate adjunct islands,
whether islands, subject islands, complex NP islands, and—crucially—RC islands in Norwegian. They found that all island types were characterized by a superadditive interaction, i.e., positive DD score, and that the size of the interaction was comparable across subject, adjunct, complex NP and RC islands; it was smaller for
whether islands, for which the researchers found considerable inter-speaker variation.
Given the discussion above about the often-observed permeability
3 of RCs in MS, the fact that
Kush et al. (
2018) found an island effect in Norwegian RCs is highly relevant. However, it does not necessarily contradict the observations above, because they did not systematically manipulate the embedding environment to include positions known to “unlock” the island, such as predicate nominal or existential pivot positions. Instead, the RCs appear to be in the complement position of prepositions and transitive verbs. The set of sentences in (11) below illustrates one of their RC item sets, which crosses Length (11a/11c vs. 11b/11d) and Structure (11a/11b vs. 11c/11d). Observe that the RC is in the complement position of a preposition, in
snakket med ‘speak with’ (11c/11d).
4 Their results provide evidence that RCs, in that environment, are islands for extraction in Norwegian.
- (11)
Hvem trodde at et par kritikere hadde stemt på filmen?
who thought that a few critics had voted for film.def
`Who thought that a few critics had voted for the film?’
Hva trodde regissøren at et par kritikere hadde stemt på ?
what thought director.def that a few critics had voted for
`What did the director think that a few critics had voted for?’
Hvem snakket med et par kritikere [ @ som hadde stemt på filmen]?
who spoke with a few critics that had voted for the film.def?
`Who spoke with a few critics that had voted for the film?’
Hva snakket regissøren med et par kritikere [ @ som hadde stemt på ]?
what spoke director.def with a few critics that had voted for
`What did the director speak with a few critics that had voted for?’
In a later paper,
Kush et al. (
2019) also investigated extraction from RCs, but this time, the dependency was not a
wh-question, as in (11), but topicalization. While they found generally smaller DD scores in this experiment, they nonetheless found a positive and significant island effect for topicalization out of RCs.
The key insight from this research is that we can capitalize on a factorial design to experimentally define an island effect. It is important to make a few provisos, however, about this design. Generally these experiments all cross the factors of Length and Structure, representing the island effect as their interaction. But note that these factors are merely convenient labels for a general design strategy: what they refer to depends on the experiment in question, as the position and nature of the island under consideration varies. Length sometimes, but not always, refers also to position of the gap: this is because the shortest dependency often places a gap in matrix subject position (as in 11a/11c above). Structure usually refers to the presence or absence of the island but this is then usually conflated with other lexical items. Thus, in (10), changing from a that to a whether complement necessitates changing the embedding verb (think, versus wonder). Likewise, in (11), changing from a CP to a DP complement necessitates changing the embedding verb “think” to “speak with”. Therefore, some consideration must be given to how Length and Structure are realized in any given experiment and—crucially—whether the comparison across levels fairly defines a contrast related to the island constraint in question.
A second proviso concerns statistical interactions. In acceptability judgment experiments, participants are usually making their responses on a rating scale where each number on the scale is essentially meaningless other than it defines an order of “goodness” (or “badness”). On a typical 1–6 Likert-type scale, a participant who judges a sentence ‘2’ is judging it to be more acceptable than a sentence to which they have assigned a ‘1’. Likewise, a participant who judges a sentence a ‘4’ is judging it to be more acceptable than a ‘3’. But there is no guarantee that a ‘4’ is as much of an improvement on ‘3’ as a ‘2’ is on ‘1’: in other words, these numbers do not define an interval scale. In some participants and experiments, the judgment ‘2’ might correspond to a much wider range of underlying acceptability than ‘1’, say, but less than ‘3’. It is possible for a spurious statistical interaction to arise if, for example, lower ratings define a much narrower range of acceptability than higher ratings or vice versa (
Dillon and Wagers 2021). This is a familiar problem with statistical interactions, when the measurement scale has an unknown relationship to the underlying cognitive constructs (
Loftus 1978;
Rotello et al. 2015). Two solutions have been proposed to this problem: one,
magnitude estimation, has been largely discarded because its assumptions are not met by acceptability judgments (
Sprouse 2011). Another,
z-score transformation by participants, is widely employed to dampen scale bias effects; but it can still give rise to spurious interactions. However, most researchers are at least implicitly aware of this problem and take care to guard against “ceiling” and “floor” effects, which can give rise to some of the pernicious scale compression problems mentioned above.
Dillon and Wagers (
2021) advocate for using tools from signal detection theory, such as the receiver-operating characteristic function, which directly takes into account how the scale is used, but in the research we report below, we use cumulative ordinal regression modeling to directly estimate the “width” of each ratings category and thus guard against spurious interactions. In figures and data tables, we report average ratings as if they were numbers, for convenience and comparability to previous research, but the underlying data analysis is ordinal.
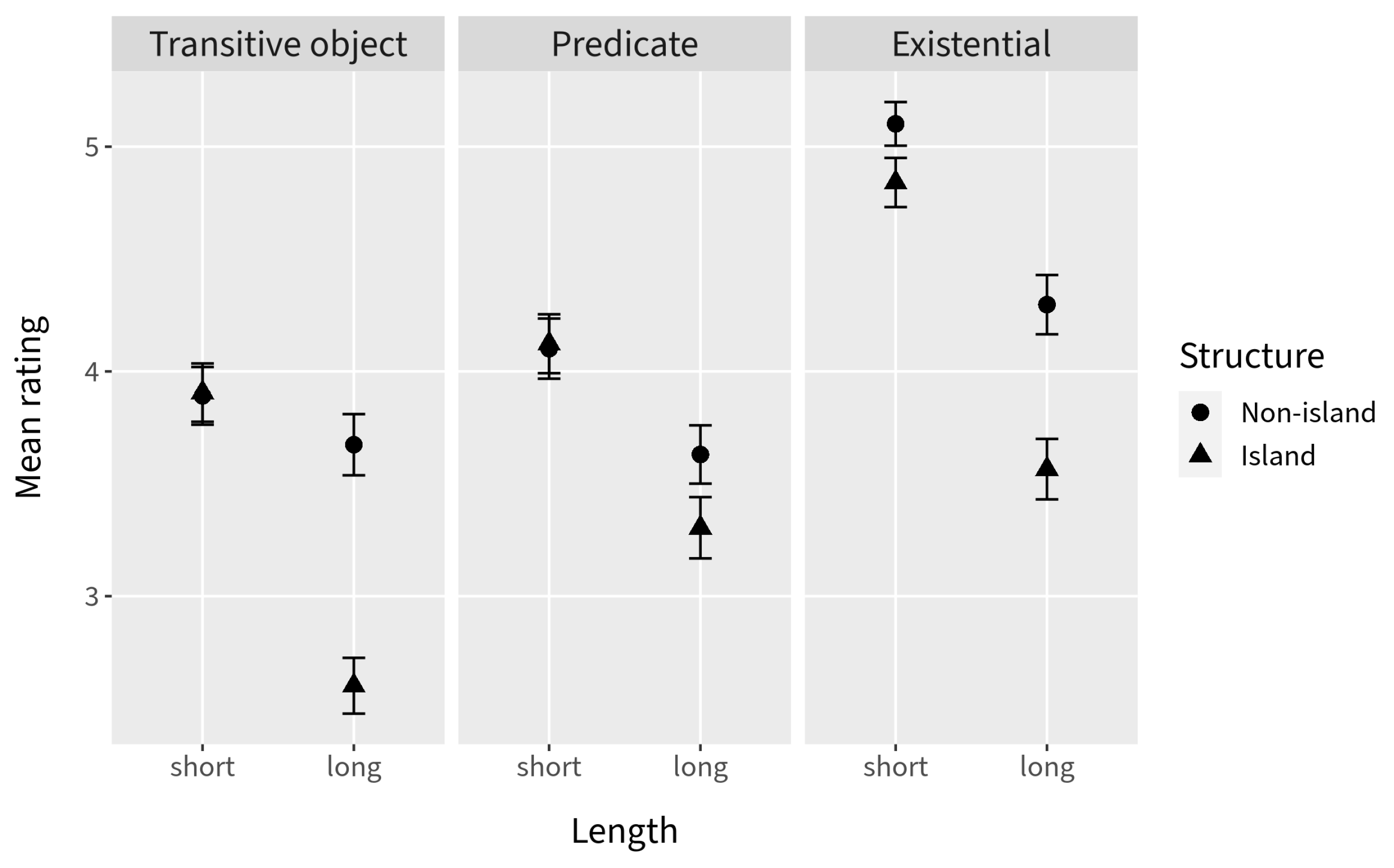
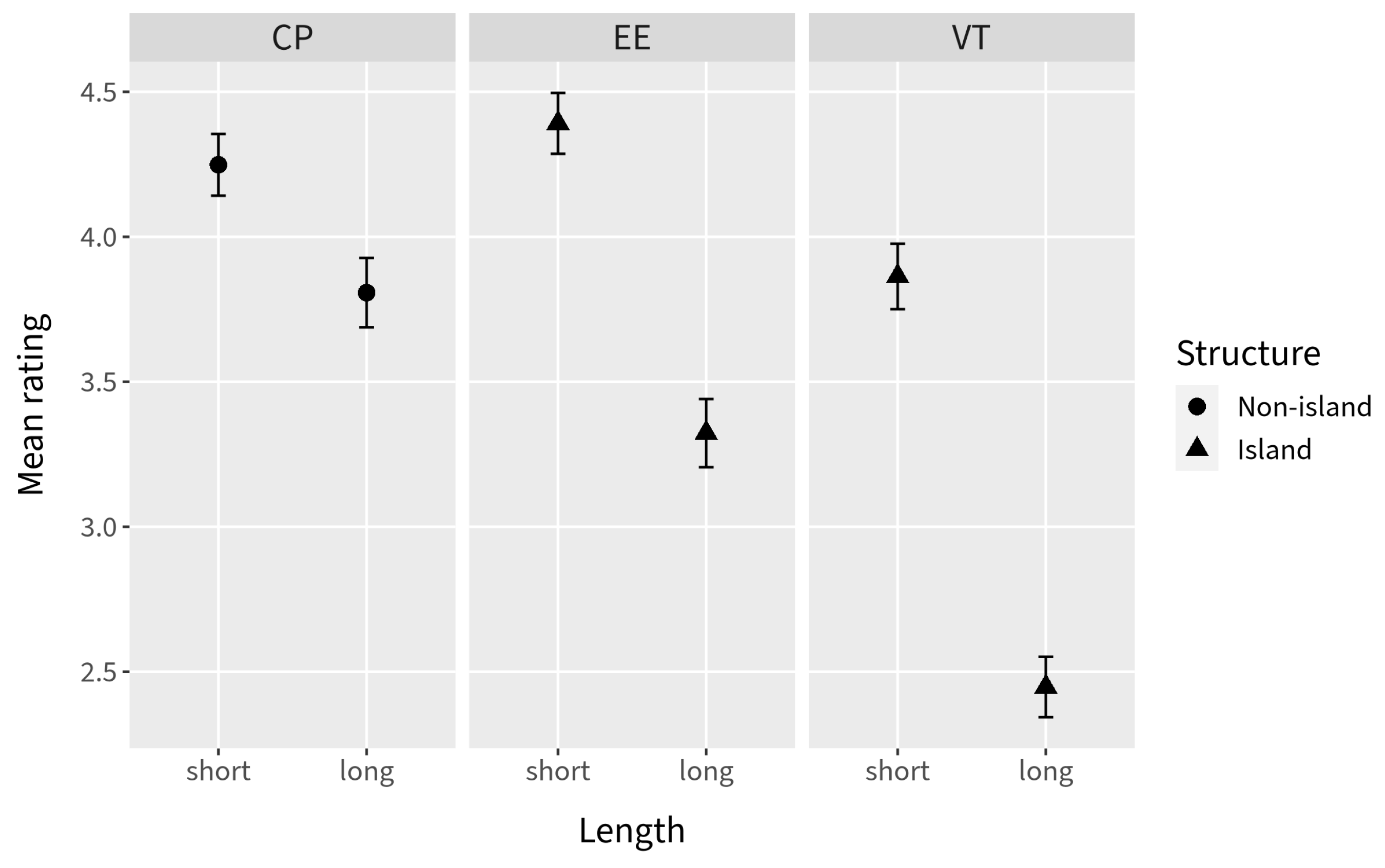
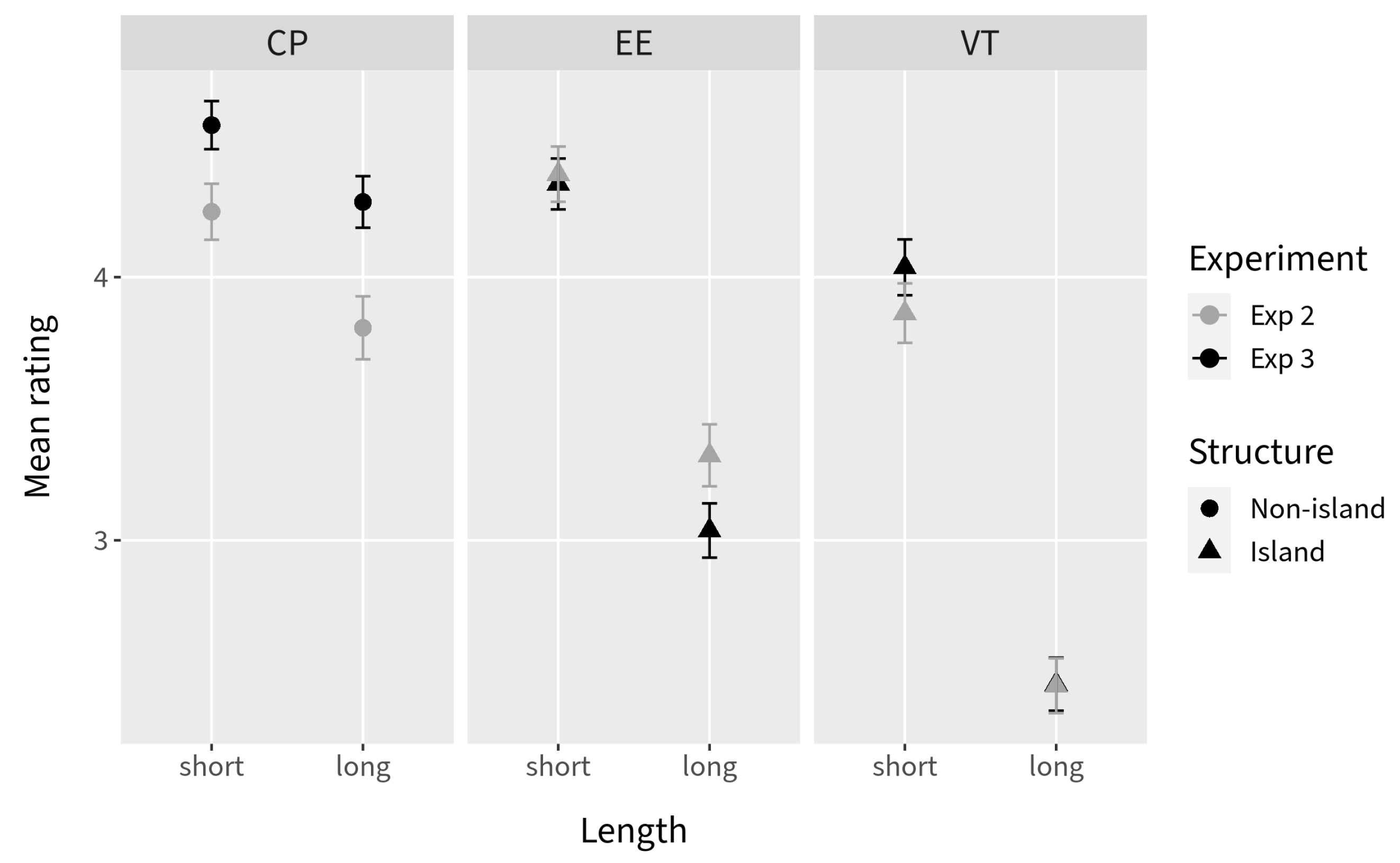
4. General Discussion
The inferential statistics for Experiments 2 and 3 indicate a persistent interaction between Length and Environment, regardless of Verb type. Taking these results seriously, we cannot conclude that there was a complete absence of island effects in either experiment. This conclusion is confirmed by the ordinal regression model estimated for the combination of the data from the two experiments: the lack of a significant interaction between Length, Environment, and Experiment (for either verb type) indicates that we cannot confidently conclude that there was a significant difference in island effect across Experiment 2 and Experiment 3 within each Verb type.
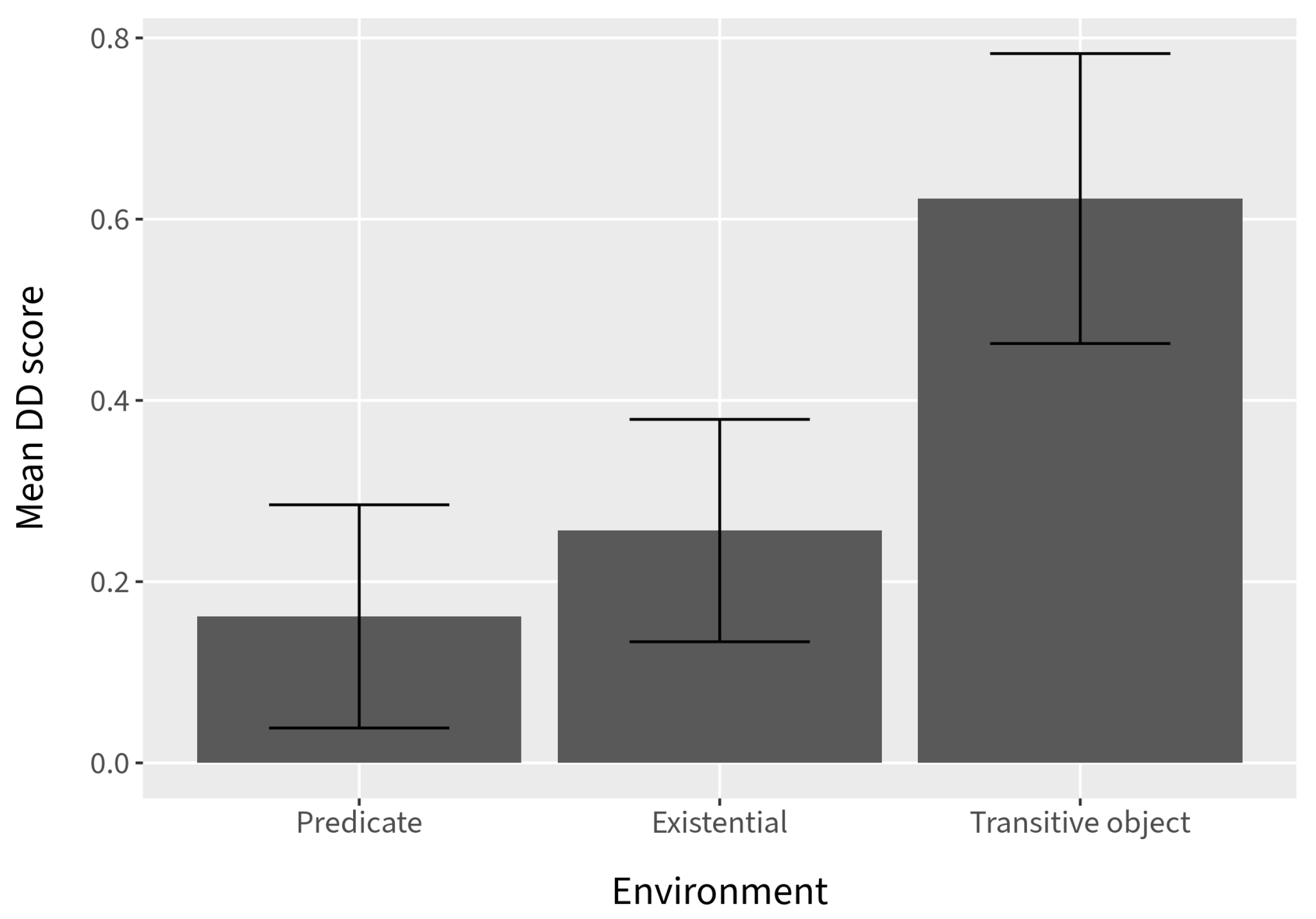
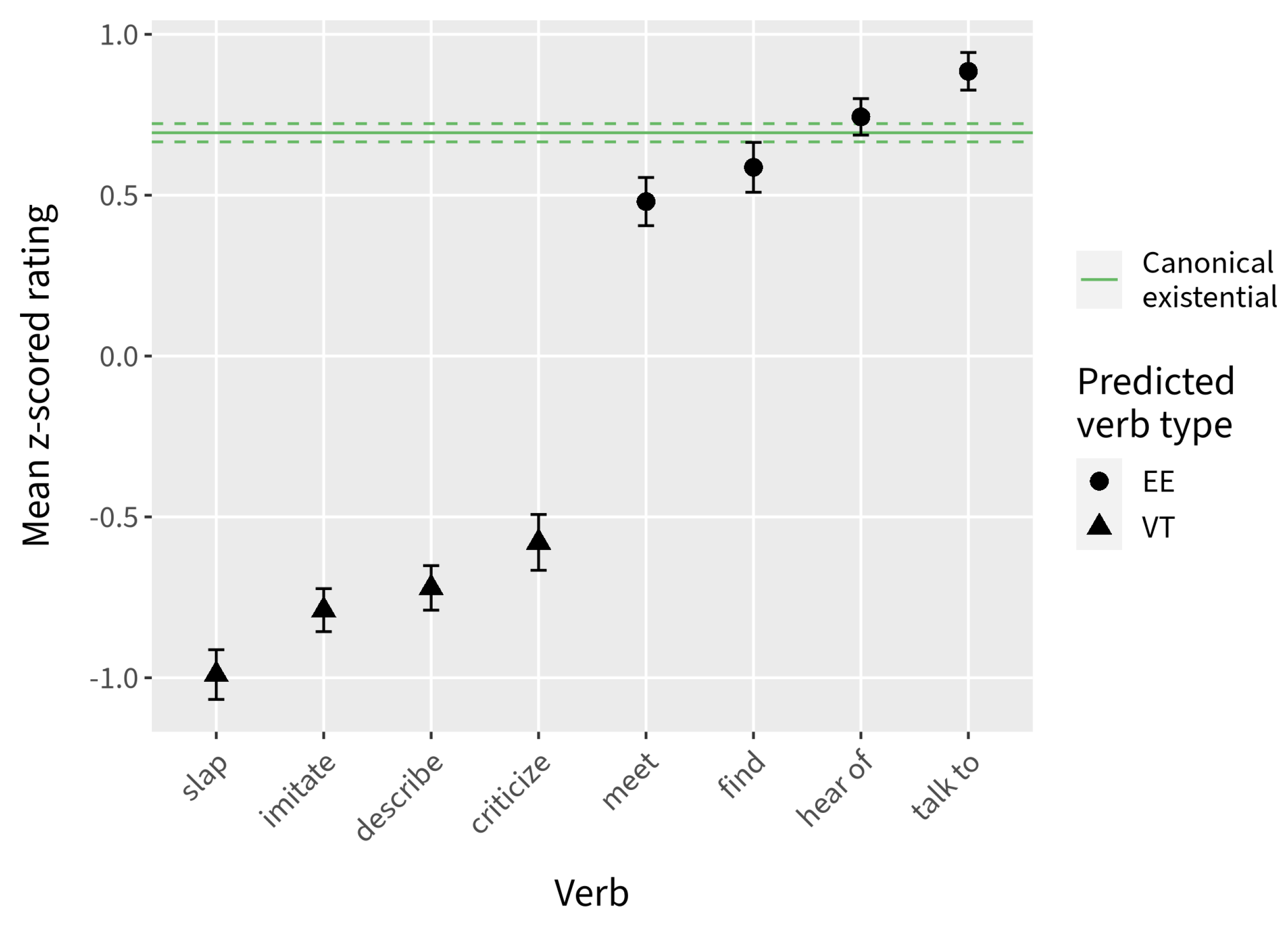
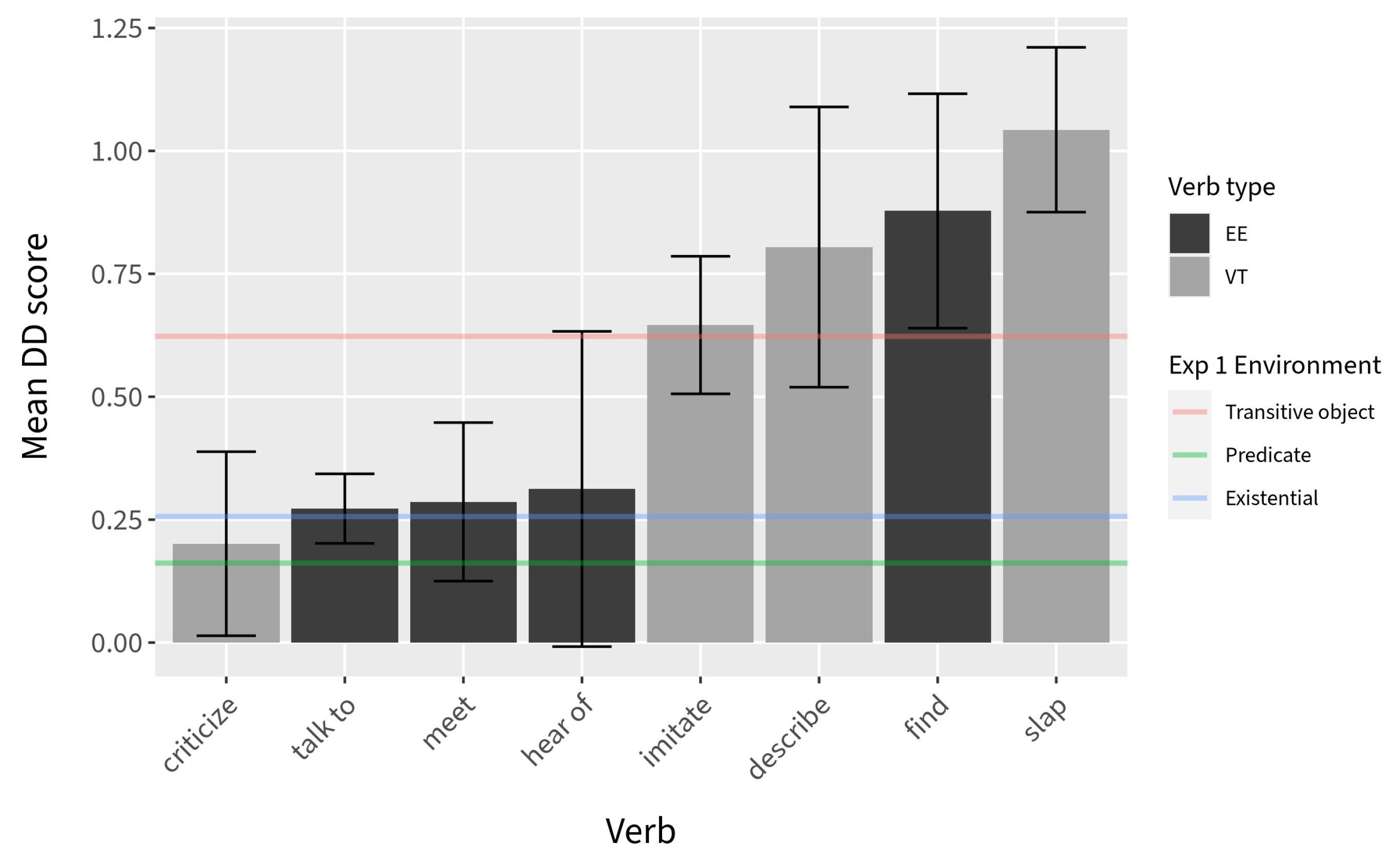
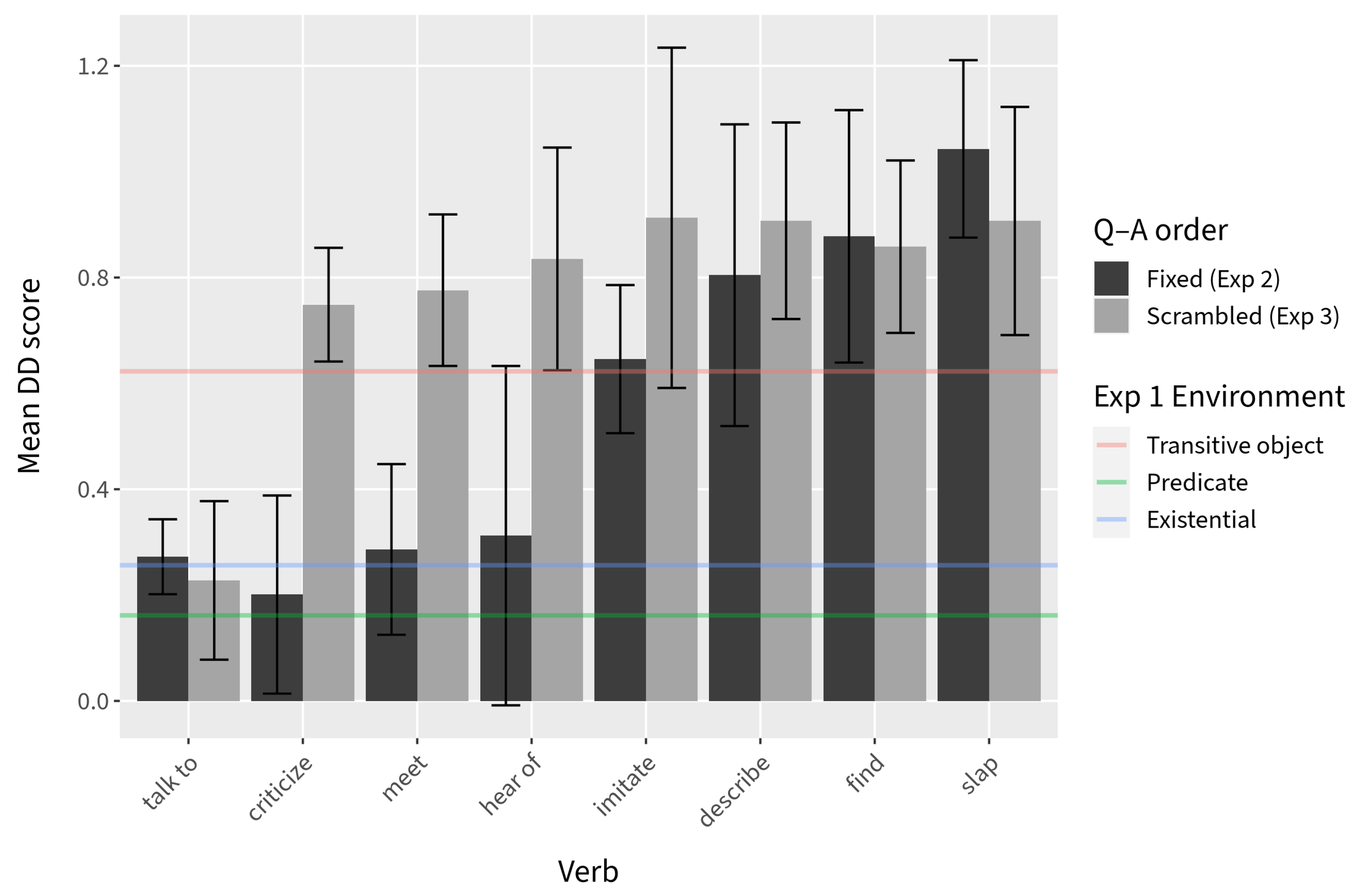
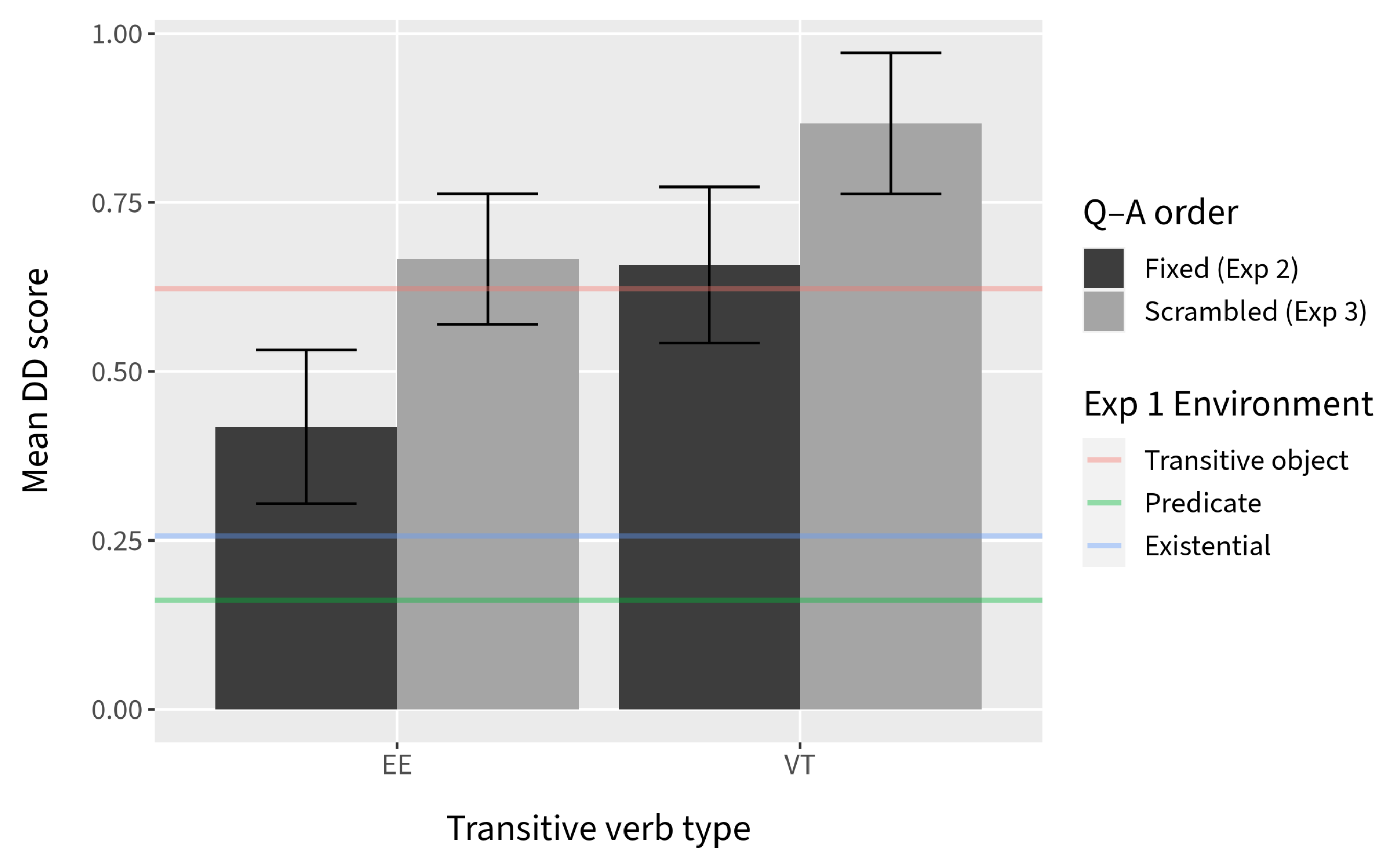
However, examination of the DD scores suggests that the combined effects of Verb type and context are not inconsequential. Although we observed a general increase in the DD scores for both verb types in Experiment 3, the DD scores for the
EE verb type pull apart slightly more across the two experiments when compared to the
VT verb type (
Figure 10). Further, when the mean DD scores visualized in
Figure 10 are broken down according to verb (
Figure 9), there are notable trends within each verb type. The only verb in the
EE group that maintained consistently low DD scores across the two experiments was
talk to. This is unlikely to be due to chance; the results from the evidential existentiality norming study indicate that out of fourteen transitive verbs tested,
talk to is the most natural transitive verb with which to make an “evidential existential” claim (for additional discussion, see
Vincent 2021). Two of the other four
EE verbs used in Experiments 2 and 3,
meet and
hear of, have a noticeably higher DD score in Experiment 3, when context did not favor an existential use. Similarly, three out of four verbs that were categorized under
VT (
imitate,
describe, and
slap) maintained consistently high DD scores across the two experiments. This also seems unlikely to be due to chance, as these three verbs were found to be the least natural transitive verbs to use to make an existential claim in a supporting context.
What this suggests to us is that there is a gradient effect on relative clause permeability that is affected by the likelihood of the transitive verb being used existentially. Certain verbs such as talk to are so natural in non-canonical existential assertions that a reading in which their complement is non-presupposed is easily accommodated. Verbs such as imitate, describe, and slap, on the other hand, are so unnatural in existential assertions that a non-presupposed reading of their complement is difficult to accommodate—even when context provides the right conditions for an existential assertion. It is also possible that there is variation across speakers regarding the possibility for a non-canonical existential reading for particular verbs, contributing to the overall less clear picture.
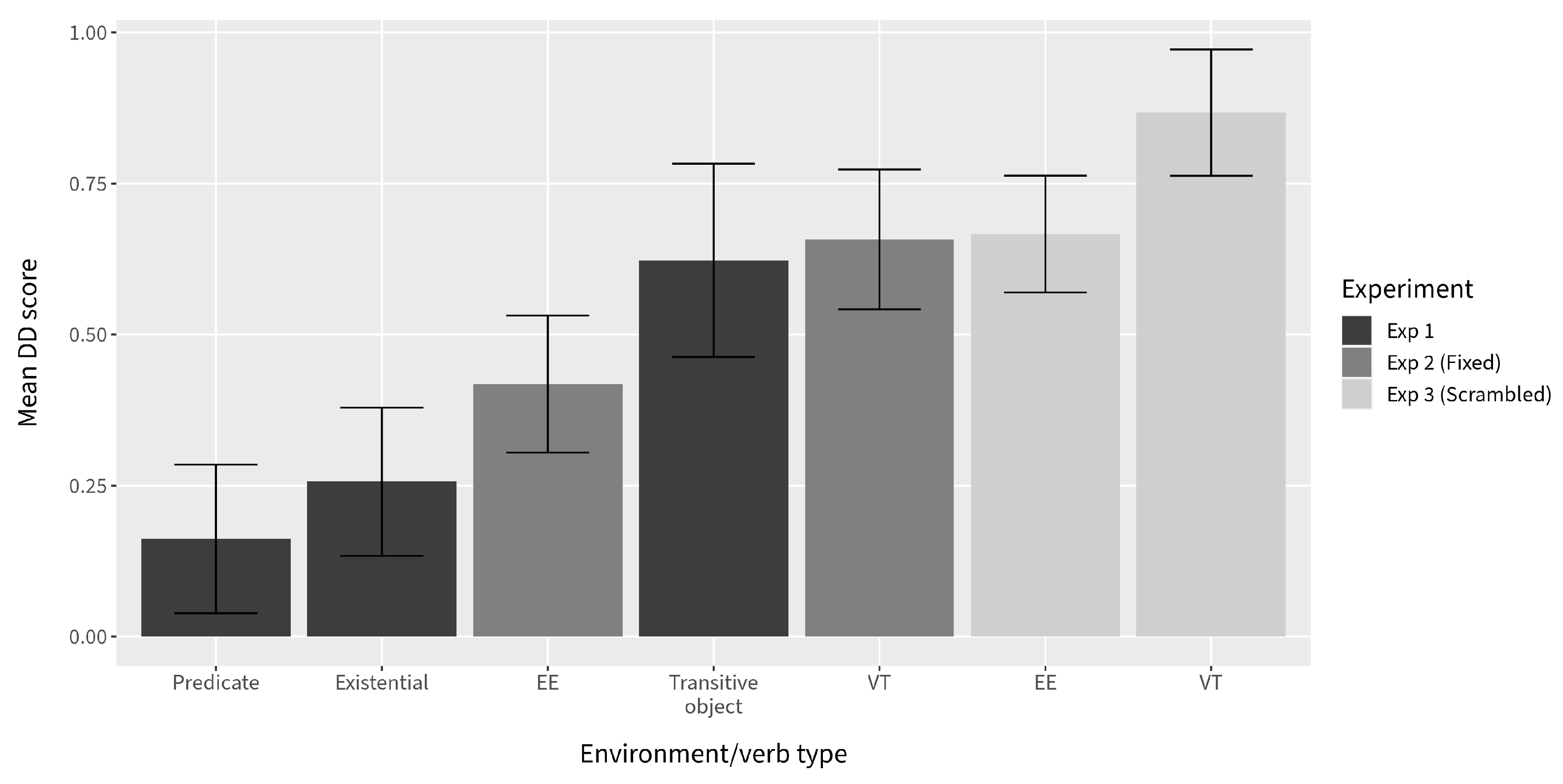
In conjunction with the results from Experiment 1, in which canonical existential and predicate nominal environments result in a substantial decrease in island effects, the picture that emerges is that the same factors appear to modulate RC permeability in English as in the Mainland Scandinavian languages: extraction is facilitated when the RC is within a predicate nominal, an existential pivot, or a direct object of a verb with which it is natural to make an existential assertion (refer to the combined DD score plot in
Figure 11). This finding is noteworthy from an empirical standpoint because it contrasts with the general consensus that English islands (apart from
whether-complements) invariably give rise to severe degradation under extraction.
From a theoretical standpoint, our findings provide some clues as to which analyses of extraction from RC may turn out to be fruitful and which may turn out to be unfruitful. What initially appeared to be a phenomenon specific to the Mainland Scandinavian languages may be a more general pattern than initially thought. If the phenomenon’s first discovery in these languages is what initially led to suggestions that island constraints be parameterized to handle cross-linguistic variation, then finding that this phenomenon is observable even in English should take us at least one step away from parameterization. It appears likely that the picture is both more cross-linguistically uniform and also more nuanced, language-internally, than a parameterization approach could satisfactorily handle.
Besides the language-particular effects found in English, another conclusion which emerges from our experiments is that the environments which facilitate extraction seem to be cross-linguistically uniform: extraction is permitted (or more acceptable) from a non-presupposed RC (
Erteschik-Shir 1973,
1982;
Engdahl 1997;
Rubovitz-Mann 2000;
Sichel 2018;
Vincent 2021). Regardless of the ultimate “island” status of some of these environments, the existence of such a consistent cross-linguistic landscape suggests that there is something to understand about these environments and why they facilitate extraction to the extent that they do. The significance of these particular environments is further highlighted by the fact that sub-extraction from simple, non-relative DPs in English follows the same pattern: possible when DP is a non-presupposed indefinite. Here, too, the English pattern is similar to what is known about other languages (
Davies and Dubinsky 2003;
Diesing 1992;
Fiengo and Higginbotham 1981;
Mahajan 1992, among others). This suggests that presuppositional DPs are strong islands, and that English RCs, when non-presuppositional, are weak islands, as in other languages in which sub-extraction is attested. Another empirical benefit of our study is that it provides a clear blueprint for future studies in other languages: measurement of sub-extraction facilitation effects depends on knowing where to look for them. Rather than comparing, for example, extraction from RC in subject position vs. extraction from RC in object position, or extraction from indefinite RCs vs. definite RCs, it seems to us that, to the extent that it is at all possible in a language, sub-extraction from an RC is most likely to be found in the sort of non-presuppositional contexts we have focused on.
11 Further investigation of these environments in other languages is needed for a clearer understanding of the cross-linguistic landscape of RC island-hood and its relationship to general DP island-hood.
On the theoretical side, a more nuanced conception of the environments which facilitate sub-extraction is key for the analysis of these cases and for our understanding of the nature of island violations more generally. First, the claim in
Sichel (
2018) that the external environments which facilitate RC sub-extraction are no different from those which support sub-extraction from simple DPs is further supported by the English pattern. If this is so, and to the extent that sub-extraction from simple DPs can ultimately be analyzed in terms of the syntactic position (derived, non-derived) of presupposed and non-presupposed DPs (
Bianchi and Chesi 2014;
Diesing 1992), there is no a priori reason to suspect that sub-extraction from RCs is any different: an RC from which extraction is acceptable is in a non-derived position, consistent with contemporary theories of DP-islandhood, which allow sub-extraction from a simple DP when that DP is in a non-derived position (
Rizzi 2004;
Stepanov 2001;
Takahashi 1994;
Uriagereka 1999;
Gallego and Uriagereka 2006,
2007;
Chomsky 2008; among others).
Second, the empirical cut which emerges from English, along with other languages which permit RC sub-extraction to some degree, can be used to further test predictions raised by other theories of acceptable extraction from islands. In a recent paper on extraction from subject islands,
Abeillé et al. (
2020) focus on the nature of the extracted constituent and argue for an information-structure based constraint on sub-extraction from subjects, according to which extraction is subject to a focus-background conflict constraint (FBC), a gradient constraint disallowing a focused element to be part of a backgrounded constituent. They compared A-bar extraction for
wh-questioning with A-bar extraction for relativization, across subjects and objects. They found that extraction from a subject is degraded compared to extraction from an object when extraction is part of question formation—but not when it is part of relativization. The effect is attributed to a clash between the focus potential of the
wh-phrase and the givenness of subjects, generally. While we basically agree with the characterization of the extraction domain which hinders sub-extraction in terms of information structure, and with the specific characterization in terms of pre-suppositionality (or
givenness, in the terms of
Abeillé et al. 2020), we believe that our more nuanced approach to the distribution of these environments is helpful for further testing of their predictions. While
Abeillé et al. (
2020) have characterized the overall difference between subjects and objects in terms of givenness, we follow contemporary findings in syntax and semantics which acknowledge that presuppositionality has an effect on sub-extraction both
within the domain of subjects, as well as
within the domain of objects: presupposed subjects, as well as presupposed objects, block sub-extraction, whereas non-presupposed objects, as well as non-presupposed subjects, are more porous for sub-extraction. We also think that it is premature to attribute this sensitivity to a clash between the information-structural properties of the extraction domain and the information-structural properties of the extracted constituent. If the source of the problem were indeed such a clash, the expectation is that the characterization of the extraction domain should vary across extraction types—and should reverse when the extracted constituent is information-structurally characterized as
given, or presupposed. In particular, the types of A-bar movement which apply to given, presuppositional constituents, such as scrambling and topicalization, should actually be more acceptable when the extraction domain is a presupposed (or given) DP than when it is non-presupposed. Our own study used both
wh-movement in question formation (Experiment 1) and relativization (Experiments 2 and 3) and made no attempt to manipulate them systematically.
Kush et al. (
2019) found a lower penalty for topicalization out of RCs than for
wh-questioning out of RCs but made no attempt to systematically manipulate environments which ‘unlock’ islands.
Sichel (
2018) found that topicalization from an RC follows the same presuppositional pattern as in the present study, an indication that the extraction domain does not vary with the information-structure characterization of the extracted constituent. That study, however, is not experimental and did not include the careful quantitative controls that experimental studies, such as the former studies, do. We hope that future work will test these comparative predictions by combining careful quantitative controls and nuanced manipulation of the blocking and facilitating environments.
Although less central to the main focus of this paper, we hope to impress two main methodological points upon our readers. First, we believe that our experiments can be viewed as a trial of the Length by Structure experiment design and an example of how it can be extended to measure not only the permeability of individual island domains but the influence of additional factors (such as environment and context) on the permeability of island domains. Second, we believe that our effort to suggest a context (in Experiment 2) without changing the nature of the acceptability judgment task was successful, considering the distinctions we observed in the results for experiments that were identical except for the relevance of Q–A pairs. Future research in this and other areas may find this technique useful when context is relevant or is part of an experiment manipulation but when it is undesirable to directly ask participants to consider an item with respect to a context.
5. Conclusions
Our results indicate that English should be counted among the languages that allow extraction from RCs in at least some environments. The results from Experiment 1 suggest a negligible island effect for RCs in predicate nominal environments and a substantially reduced island effect for those in canonical existential environments. The interactions between the Environment comparisons and Length were significant in both Experiments 2 and 3, indicating that the data collapsed across verbs still bear the signature of a significant island effect. However, the DD scores calculated by verb reveal a somewhat more complex story: the scores for three out of four of the verbs we categorized as EE verbs (talk to, meet, and hear of) are on a par with the DD score for canonical existentials in Experiment 1 when participants are “primed” by an adjacent context-setting question.
In addition to the above findings, an important takeaway is that cross-linguistically, the factors that enhance a relative clause’s permeability appear to be stable, even if the size of their effects on acceptability ratings vary somewhat. It is a clear pattern that environments and contexts that support existential, non-presupposed interpretations of the DP containing the RC ‘unlock’ the RC to some extent, whether the environment is a direct assertion (or denial) of existence, a nominal predication, or an indirect assertion (or denial) of existence using an evidential existential verb in a supporting context.
Lastly, we highlighted the methodological innovations that we believe may be useful for further investigation into this and other topics. These include expansion of the Length by Structure design to compare extraction environments as closely as possible as well as the use of trial adjacency to suggest interpretation and evaluation of a condition in the context of another condition without disturbing the overall task.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










