
Safe Motion Planning and Learning for Unmanned Aerial Systems


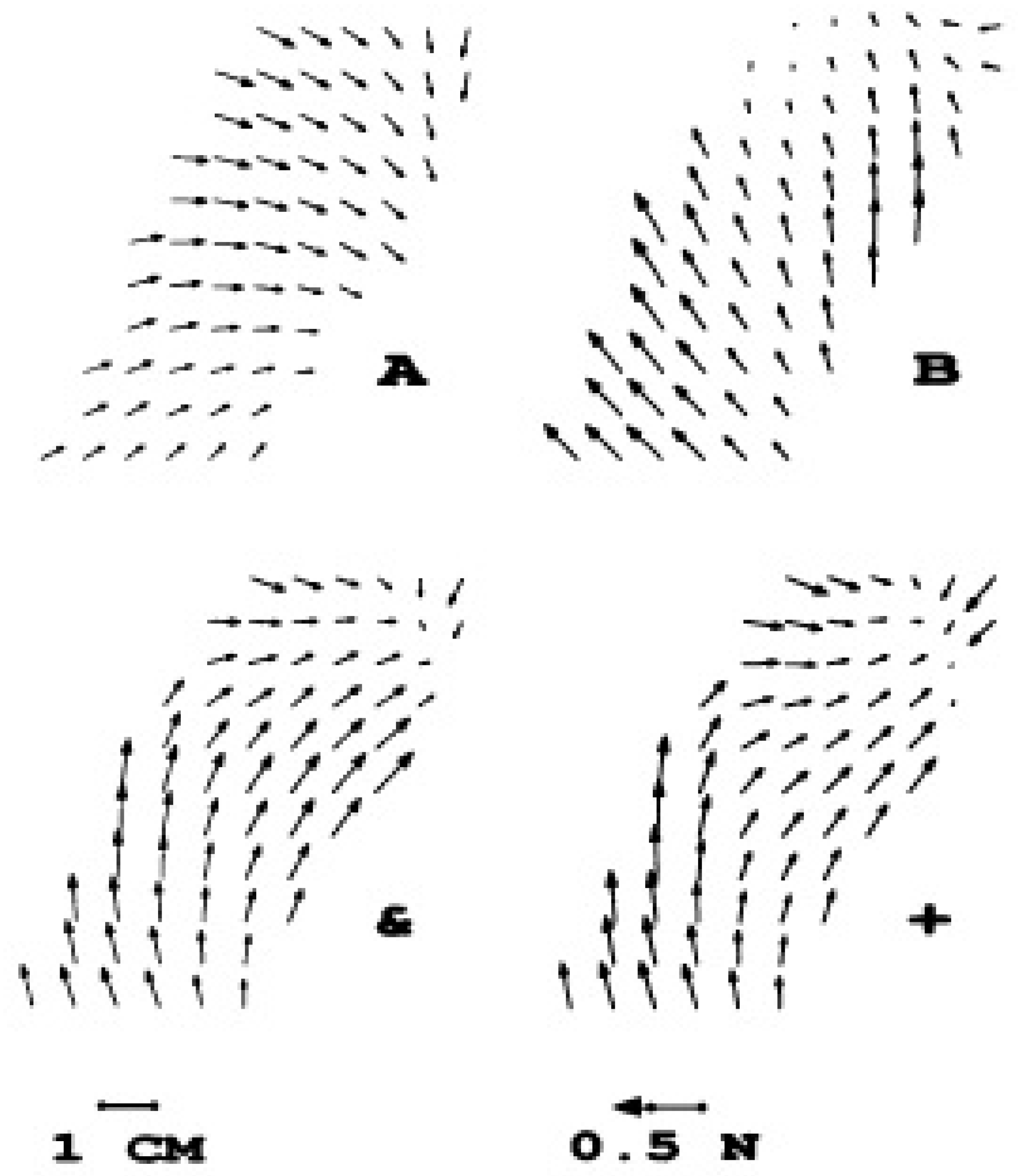{kind=link}
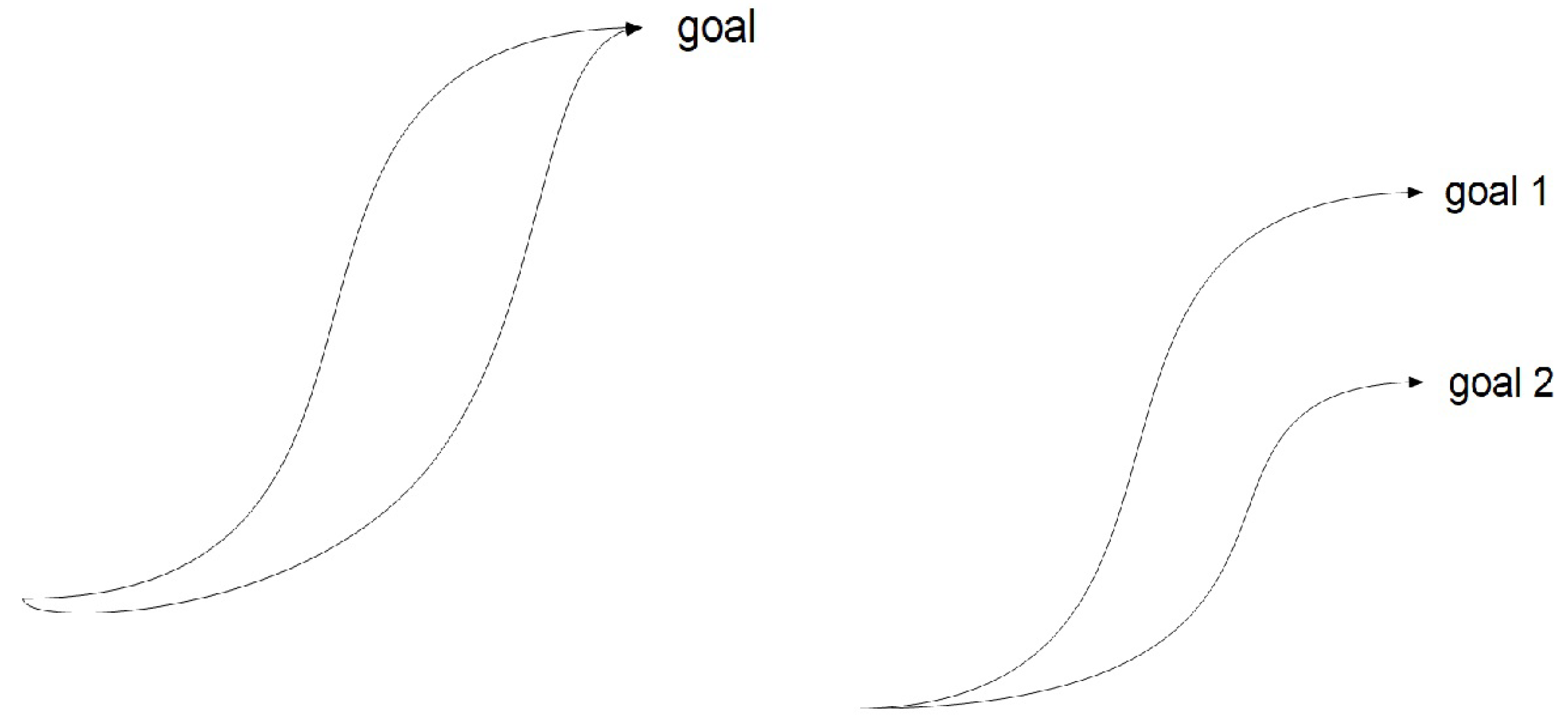{kind=link}
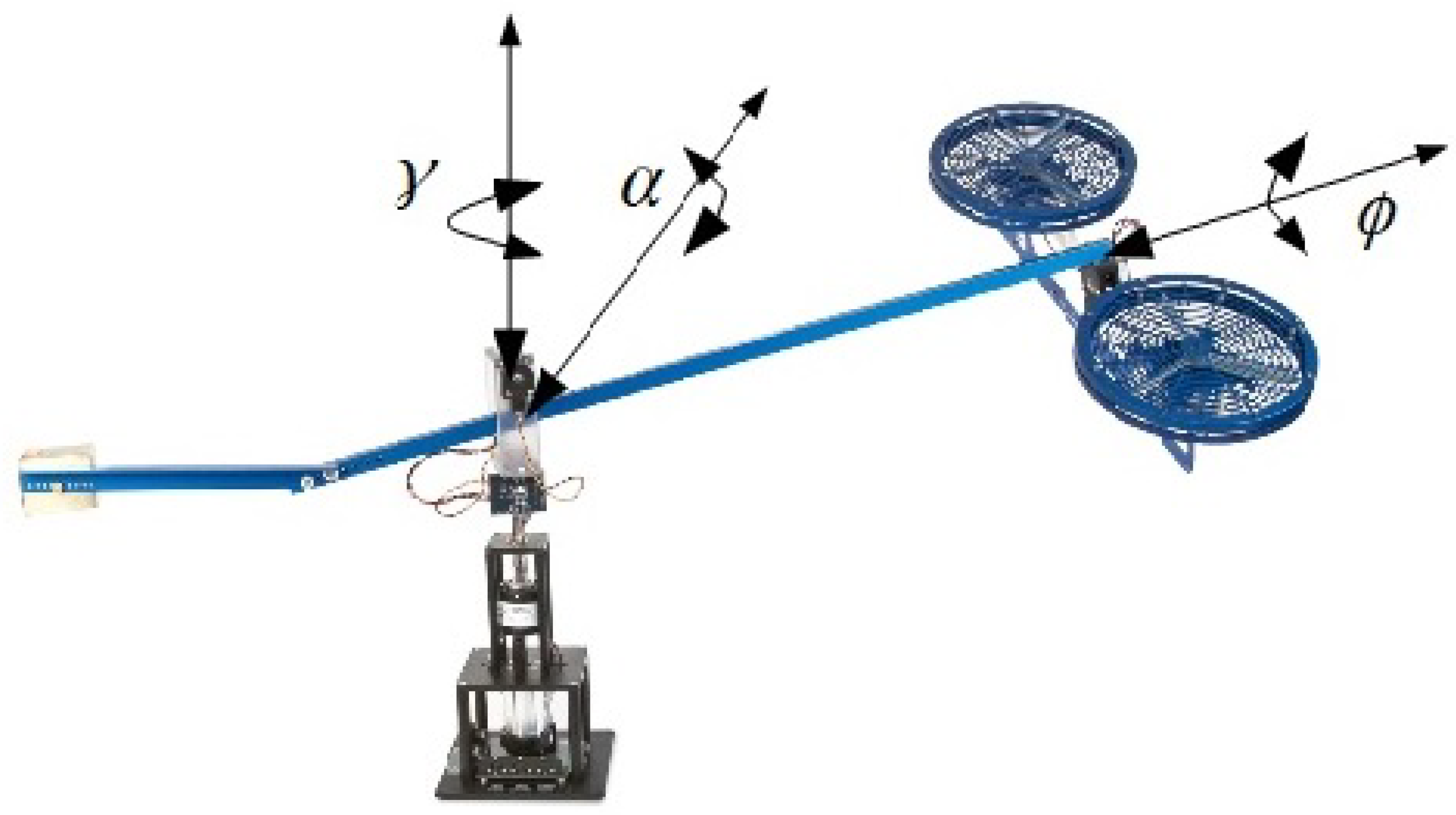{kind=link}
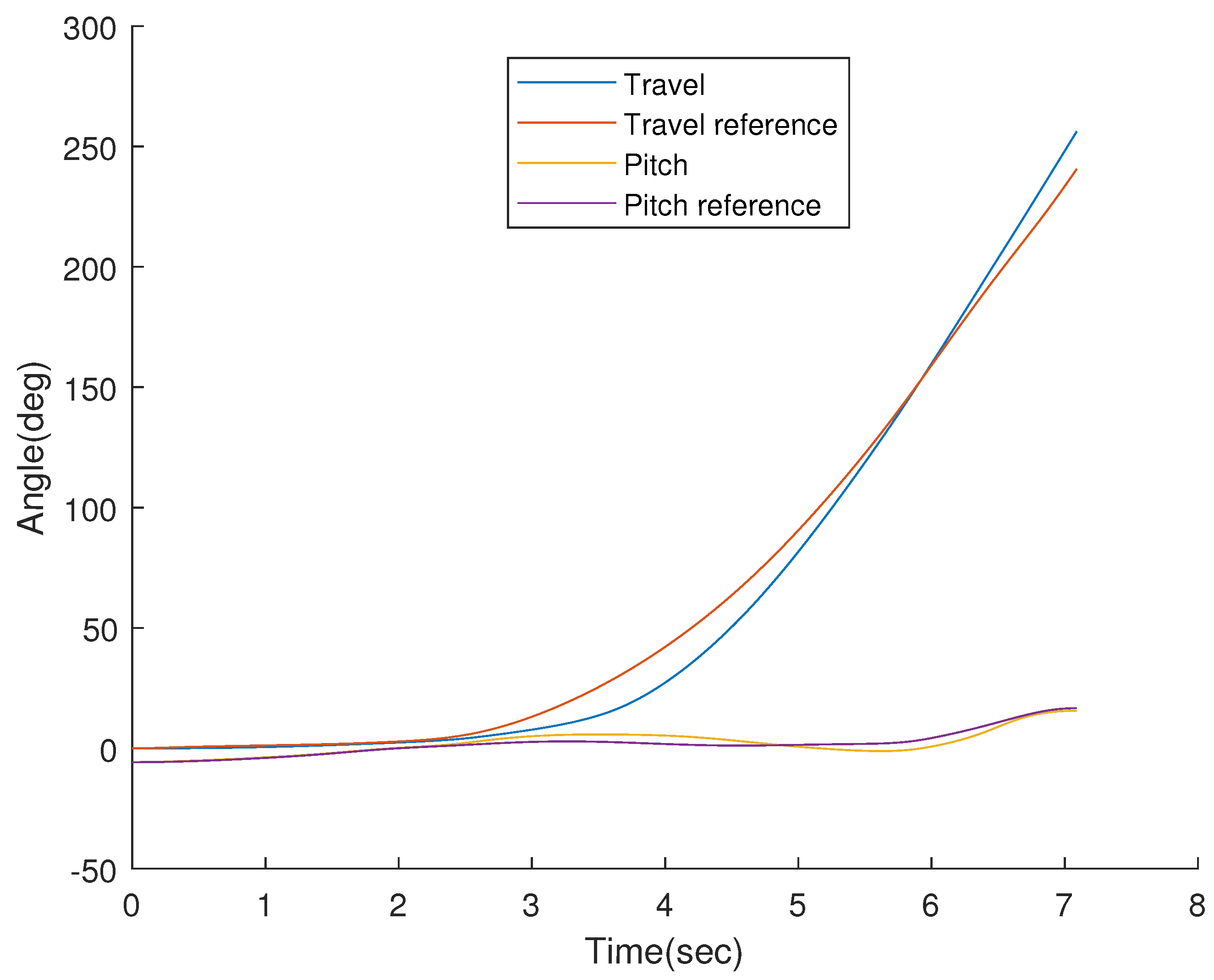{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methodology
- Contraction Theory.
- Dynamic Movement Primitives.
- Reinforcement Learning Algorithm.
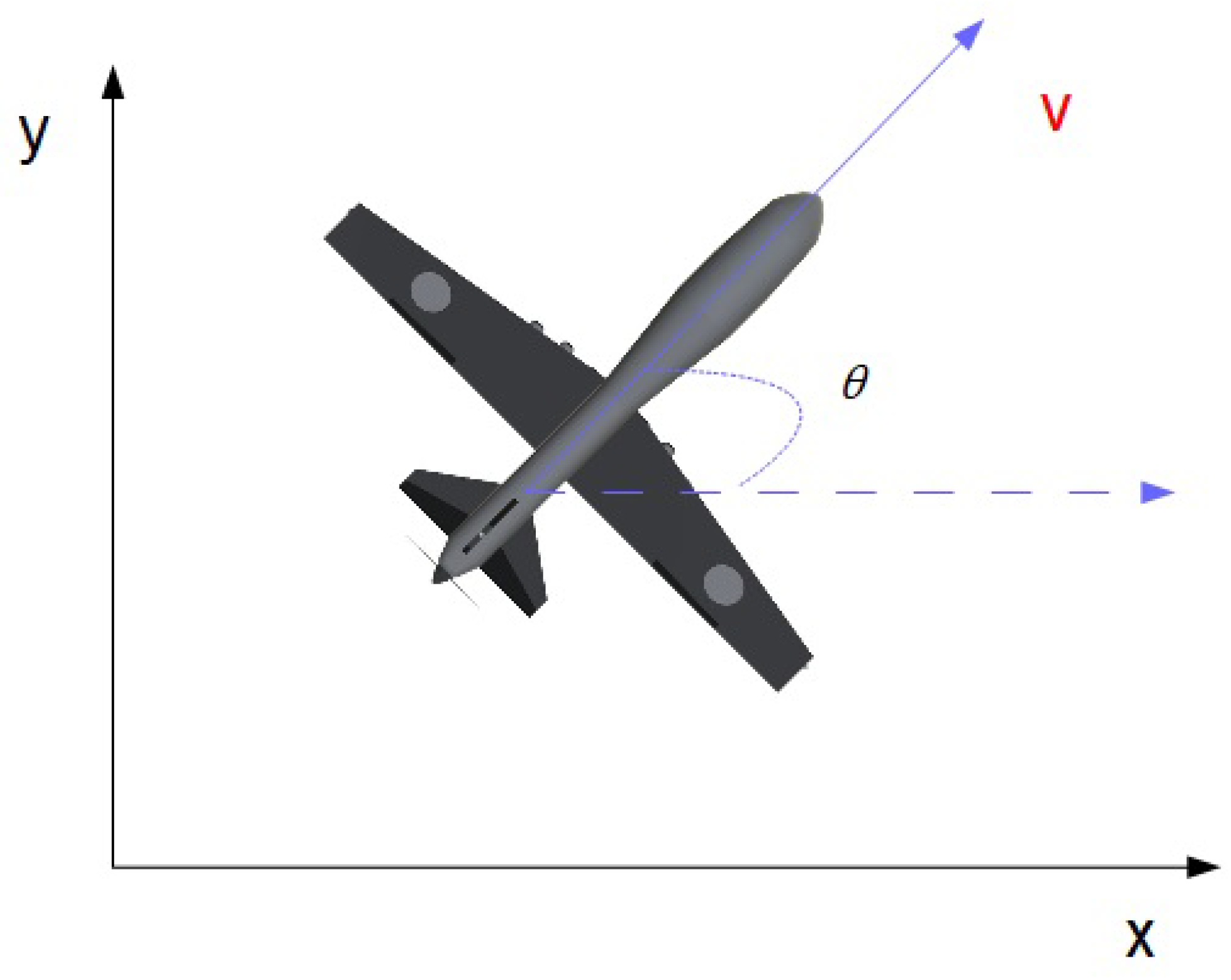
2.1. Contraction Analysis of Systems with DMPs
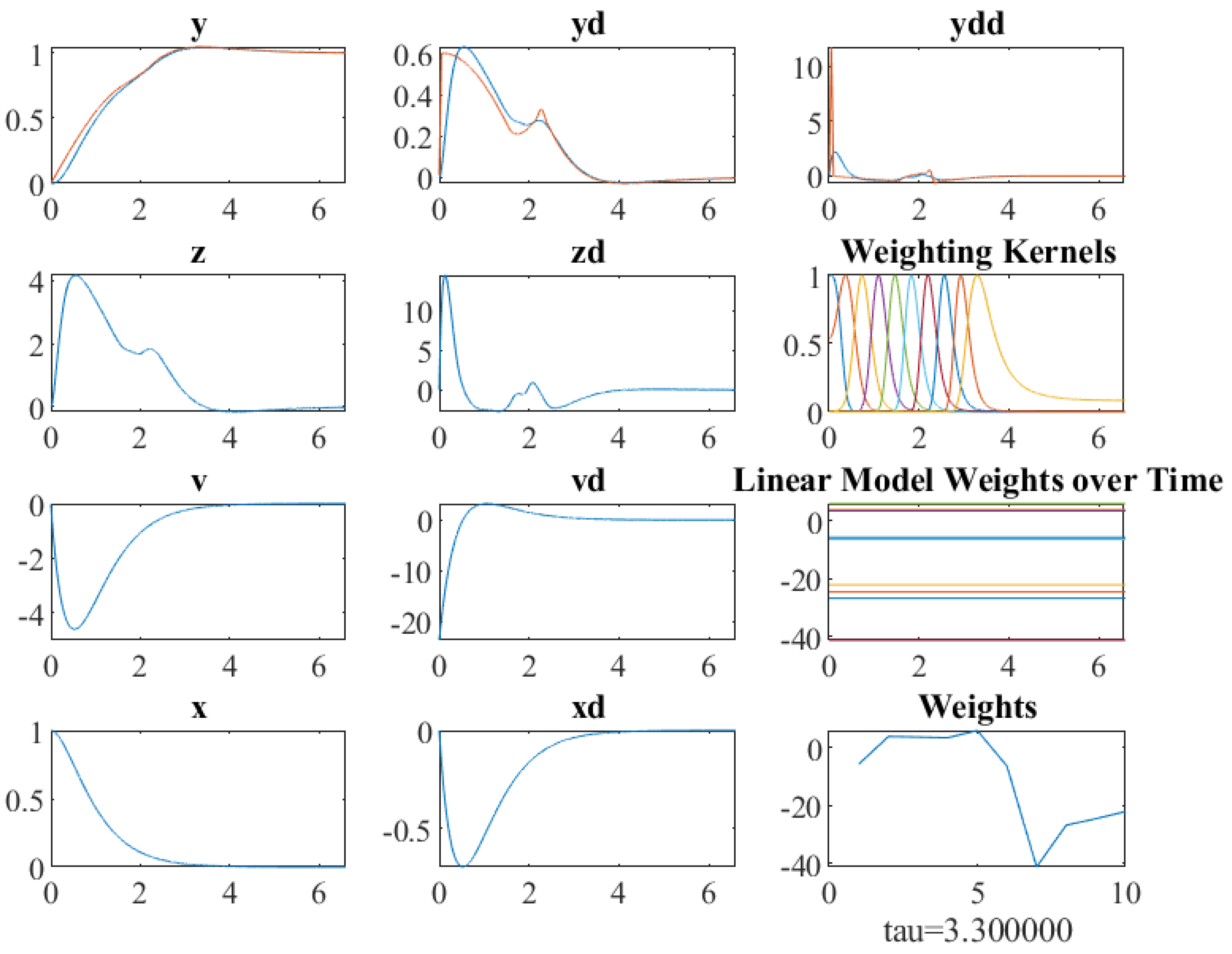
2.2. Using Reinforcement Learning with Contraction Analysis
2.3. Remarks
2.3.1. DMP as a Controller
2.3.2. Offline Learning
2.3.3. Maneuver Library
3. Application
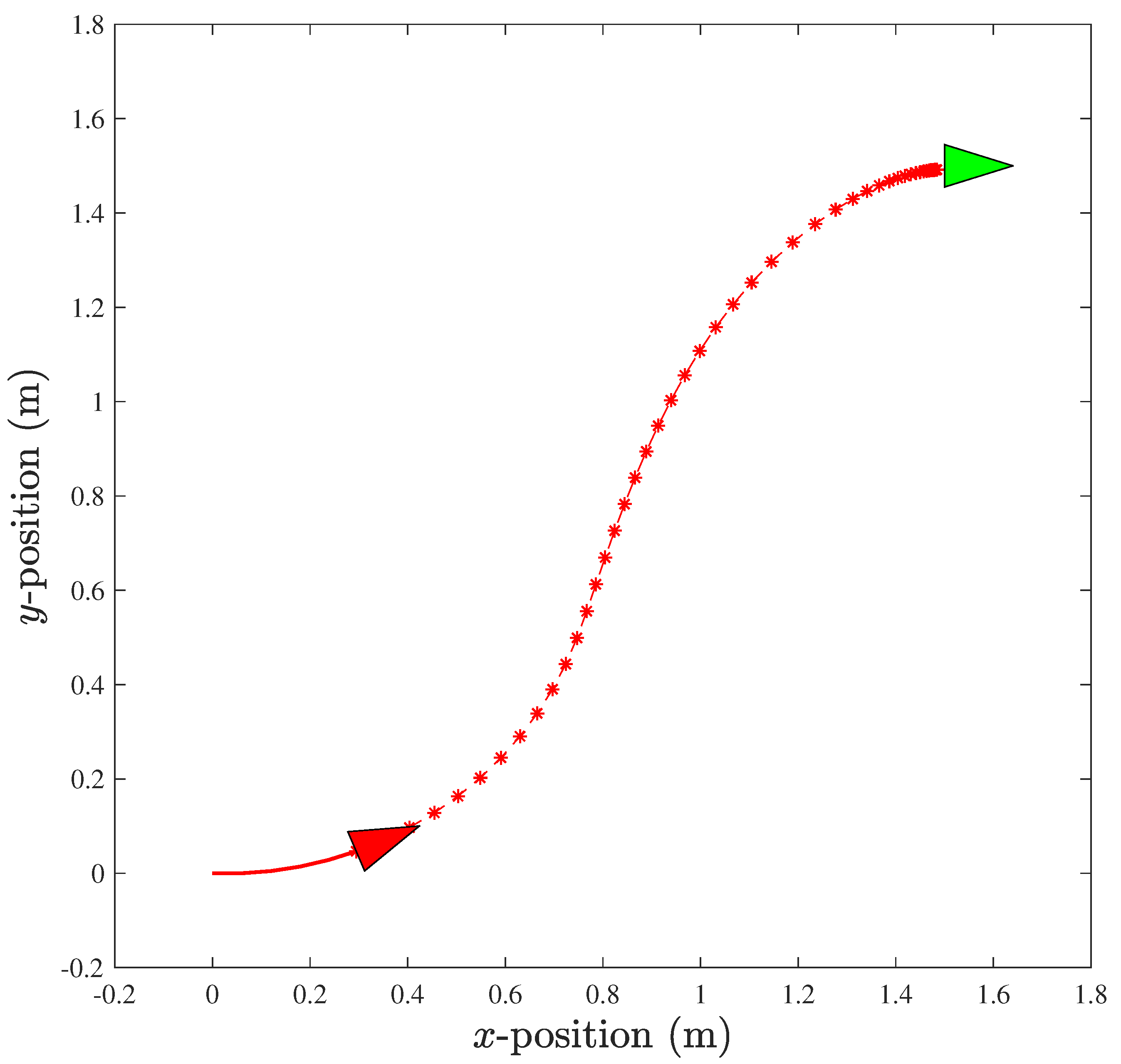
3.1. The Combination of Primitives for a 3-DOF Helicopter
3.2. MPC Application of Contraction Theory for DMPs
3.3. The Application of Contraction Theory in Reinforcement Learning ()
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B
Appendix B.1. Basic Contraction Properties and Matrix Measures
Appendix B.2. Generalized Contraction Analysis Using Metrics
Appendix B.3. Global Metrics Derived Using Linearization
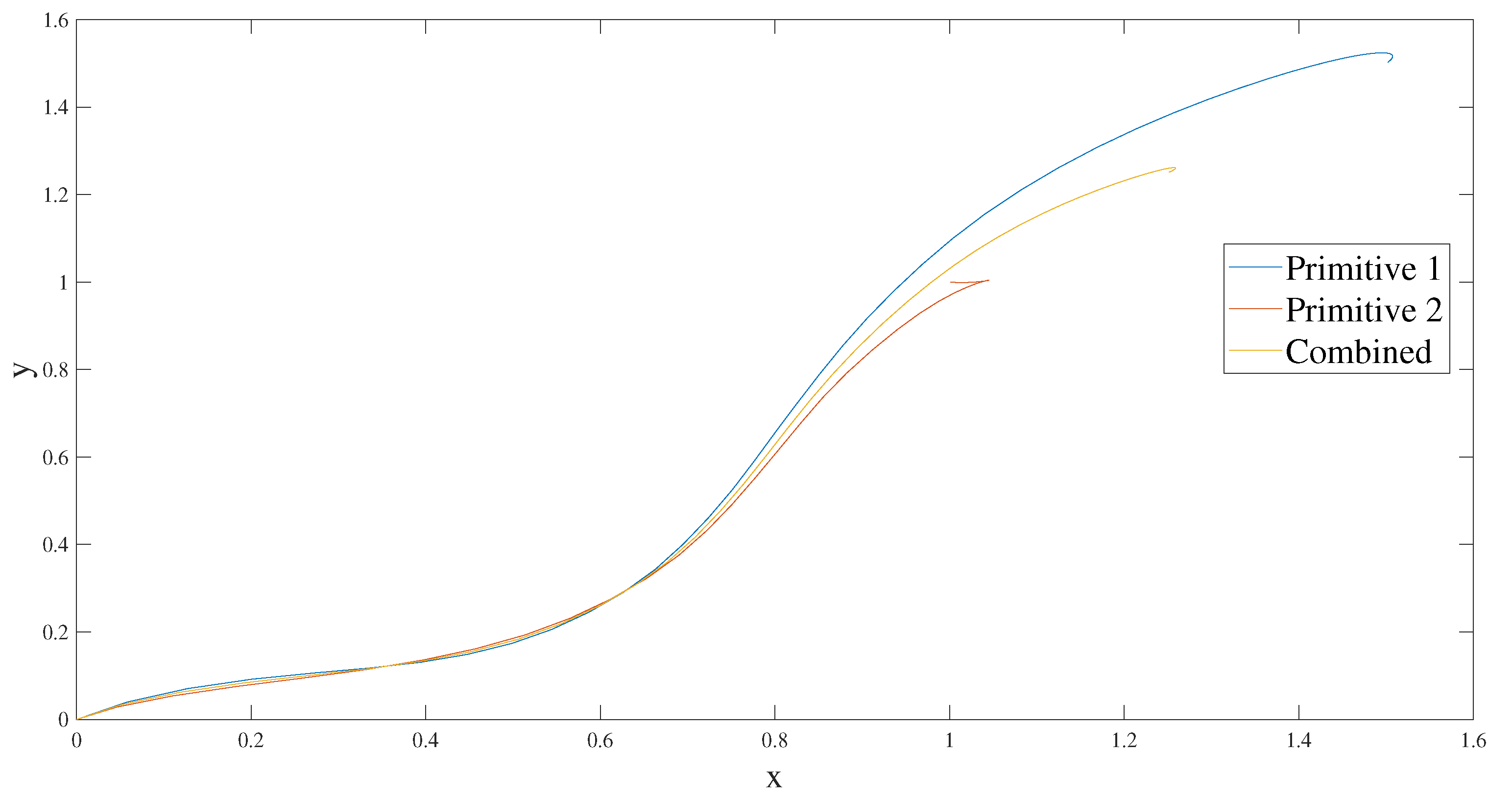
Appendix B.4. Combination of Primitives
References
- Yuksek, B.; Demirezen, U.; Inalhan, G.; Tsourdos, A. Cooperative Planning for an Unmanned Combat Aerial Vehicle Fleet Using Reinforcement Learning. J. Aerosp. Inf. Syst. 2021, 18, 739–750. [Google Scholar] [CrossRef]
- Herekoglu, O.; Hasanzade, M.; Saldiran, E.; Cetin, A.; Ozgur, I.; Kucukoglu, A.; Ustun, M.; Yuksek, B.; Yeniceri, R.; Koyuncu, E.; et al. Flight Testing of a Multiple UAV RF Emission and Vision Based Target Localization Method. In Proceedings of the AIAA Scitech 2019 Forum, San Diego, CA, USA, 7–11 January 2019. [Google Scholar] [CrossRef]
- Karali, H.; İnalhan, G.; Demirezen, M.; Yükselen, M. A new nonlinear lifting line method for aerodynamic analysis and deep learning modeling of small unmanned aerial vehicles. Int. J. Micro Air Veh. 2021, 13. [Google Scholar] [CrossRef]
- Gavrilets, V.; Frazzoli, E.; Mettler, B.; Piedmonte, M.; Feron, E. Aggressive Maneuvering of Small Autonomous Helicopters: A Human Centered Approach. Int. J. Robot. 2001, 20, 795–807. [Google Scholar] [CrossRef]
- Coates, A.; Abbeel, P.; Ng, A. Learning for Control from Multiple Demonstrations. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 144–151. [Google Scholar]
- Lupashin, S.; Schöllig, A.; Sherback, M.; D’Andrea, R. A simple learning strategy for high-speed quadrocopter multi-flips. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AL, USA, 3–8 May 2010; pp. 1642–1648. [Google Scholar]
- Levin, J.; Paranjabe, A.; Nahon, M. Agile maneuvering with a small fixed-wing unmanned aerial vehicle. Robot. Auton. Syst. 2019, 116, 148–161. [Google Scholar] [CrossRef]
- Guerrero-Sánchez, M.; Hernández-González, O.; Valencia-Palomo, G.; López-Estrada, F.; Rodríguez-Mata, A.; Garrido, J. Filtered Observer-Based IDA-PBC Control for Trajectory Tracking of a Quadrotor. IEEE Access 2021, 9, 114821–114835. [Google Scholar] [CrossRef]
- Xiao, J. Trajectory planning of quadrotor using sliding mode control with extended state observer. Meas. Control 2020, 53, 1300–1308. [Google Scholar] [CrossRef]
- Almakhles, D. Robust Backstepping Sliding Mode Control for a Quadrotor Trajectory Tracking Application. IEEE Access 2020, 8, 5515–5525. [Google Scholar] [CrossRef]
- Yuksek, B.; Inalhan, G. Reinforcement learning based closed-loop reference model adaptive flight control system design. Int. J. Adapt. Control Signal Process. 2021, 35, 420–440. [Google Scholar] [CrossRef]
- Phung, M.; Ha, Q. Safety-enhanced UAV path planning with spherical vector-based particle swarm optimization. Appl. Soft Comput. 2021, 107, 107376. [Google Scholar] [CrossRef]
- Li, Y.; Liu, C. Efficient and Safe Motion Planning for Quadrotors Based on Unconstrained Quadratic Programming. Robotica 2021, 39, 317–333. [Google Scholar] [CrossRef]
- Lee, K.; Choi, D.; Kim, D. Potential Fields-Aided Motion Planning for Quadcopters in Three-Dimensional Dynamic Environments. In Proceedings of the AIAA Scitech 2021 Forum, Nashville, TN, USA, 11–15 January 2021. [Google Scholar]
- Zhang, X.; Shen, H.; Xie, G.; Lu, H.; Tian, B. Decentralized motion planning for multi quadrotor with obstacle and collision avoidance. Int. J. Intell. Robot. Appl. 2021, 5, 176–185. [Google Scholar] [CrossRef]
- Chow, Y.; Nachum, O.; Duenez-Guzman, E. A Lyapunov-based approachto safe reinforcement learning. In Proceedings of the NIPS 2018, Montréal, QC, Canada, 3–8 December 2018; pp. 8103–8112. [Google Scholar]
- Wenqi, C.; Zhang, B. Lyapunov-regularized reinforcement learning for power system transient stability. arXiv 2021, arXiv:2103.03869. [Google Scholar]
- Perkins, T.; Barto, A. Lyapunov design for safe reinforcement learning. J. Mach. Learn. Res. 2002, 3, 803–832. [Google Scholar]
- Jadbabaie, A.; Hauser, J. On the stability of receding horizon control with a general terminal cost. IEEE Trans. Autom. Control 2005, 50, 674–678. [Google Scholar] [CrossRef] [Green Version]
- Mehrez, M.; Worthmann, K.; Mann, G.; Gosine, R.; Faulwasser, T. Predictive path following of mobile robots without terminal stabilizing constraints. In Proceedings of the 20th IFAC World Congress, Toulouse, France, 11–17 July 2017; pp. 10268–10273. [Google Scholar]
- Grüne, L.; Pannek, J.; Seehafer, M.; Worthmann, K. Analysis of unconstrained nonlinear MPC schemes with varying control horizon. SIAM J. Control Optim. 2010, 48, 4938–4962. [Google Scholar] [CrossRef] [Green Version]
- Galef, B. Imititaion in Animals: History, Definition and Interpretation of Data from the Psychological Laboratory. In Comparative Social Learning; Psychology Press: Hove, UK, 1988; pp. 3–28. [Google Scholar]
- Polit, A.; Bizzi, E. Characteristic of Motor Programs Underlying Arm Movements in Monkeys. J. Neurophsiol. 1979, 42, 183–194. [Google Scholar] [CrossRef]
- Bizzi, E.; Mussa-Ivaldi, F.; Hogan, N. Regulation of multi-joint arm posture and movement. Prog. Brain Res. 1986, 64, 345–351. [Google Scholar]
- Mussa-Ivaldi, F.; Giszter, S.F.; Bizzi, E. Motor Space Coding in the Central Nervous System. Cold Spring Harb. Symp. Quant. Biol. 1990, 55, 827–835. [Google Scholar] [CrossRef]
- Bizzi, E.; Mussa-Ivaldi, F.; Giszter, S. Computations underlying the execution of movement: A biological perpective. Science 1991, 253, 287–291. [Google Scholar] [CrossRef] [Green Version]
- Mussa-Ivaldi, F.A.; Giszter, S.F.; Bizzi, E. Linear combinations of primitives in vertebrate motor control. Proc. Natl. Acad. Sci. USA 1994, 91, 7534–7538. [Google Scholar] [CrossRef] [Green Version]
- Mussa-Ivaldi, F.A.; Bizzi, E. Motor learning through the Combination of Primitives. Philos. Trans. R. Soc. B Biol. Sci. 2000, 355, 1755–1769. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schaal, S.; Mohajerian, P.; Ijspeert, A. Dynamics systems vs. optimal control—A unifying view. Prog. Brain Res. 2007, 165, 425–445. [Google Scholar] [PubMed]
- Lohmiller, J.S.W. On Contraction Analysis for Nonlinear Systems. Automatica 1998, 34, 683–686. [Google Scholar] [CrossRef] [Green Version]
- Bazzi, S.; Ebert, J.; Hogan, N.; Sternad, D. Stability and predictability in human control of complex objects. Chaos Interdiscip. J. Nonlinear Sci. 2018, 28, 103103. [Google Scholar] [CrossRef]
- Theodorou, E.; Buchli, J.; Schaal, S. A generalized path integral controlapproach to reinforcement learning. J. Mach. Learn. Res. 2010, 11, 3137–3181. [Google Scholar]
- Perk, B.E.; Slotine, J.J.E. Motion primitives for robotic flight control. arXiv 2006, arXiv:cs/0609140v2. [Google Scholar]
- Ijspeert, A.; Nakanishi, J.; Schaal, S. Learning attractor landscapes for learning motor primitives. In Advances in Neural Information Processing Systems 15; MIT Press: Cambridge, MA, USA, 2003; pp. 1547–1554. [Google Scholar]
- Slotine, J.; Li, W. Applied Nonlinear Control; Prentice-Hall: Hoboken, NJ, USA, 1991. [Google Scholar]
- Suttojn, R.; Barto, A. Reinforcement Learning; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Stengel, R. Optimal Control and Estimation; Dover Books on Advanced Mathematics; Dover Publications: New York, NY, USA, 1994. [Google Scholar]
- Fleming, W.; Soner, H. Controlled Markov Processes and Viscosity Solutions. In Applications of Mathematics, 2nd ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Available online: https://www.quanser.com (accessed on 20 January 2022).
- Ishutkina, M. Design and Implimentation of a Supervisory Safety Controller for a 3DOF Helicopter. Master’s Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2004. [Google Scholar]
- Perk, B.E. Control Primitives for Fast Helicopter Maneuvers. Master’s Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2006. [Google Scholar]
- Luca, A.; Oriola, G.; Vendittelli, M. Control of wheeled mobile robots: An experimental overview. In Ramsete; Nicosia, S., Sicil, B., Bicchi, A., Valigi, P., Eds.; Springer: Berlin, Germany, 2001; Volume 270, pp. 181–226. [Google Scholar]
- Mehrez, M. Github. MPC and MHE Implementation in MATLAB Using Casadi. Available online: https://github.com/MMehrez (accessed on 20 January 2022).
- Andersson, J.; Gillis, J.; Horn, G.; Rawlings, J.; Dieh, M. CasADi: A Software Framework for Nonlinear Optimization and Optimal Control. Math. Program. Comput. 2019, 11, 1–36. [Google Scholar] [CrossRef]
- Theodorou, E.; Buchli, J.; Schaal, S. Path Integral Reinforcement (PI2) Learning Software. Available online: http://www-clmc.usc.edu/Resources/Software (accessed on 20 January 2022).
- Maidens, J.; Arcak, M. Reachability analysis of nonlinear systems using matrix measures. IEEE Trans. Automat. Control 2015, 60, 265–270. [Google Scholar] [CrossRef]
- Desoer, C.; Vidyasagar, M. Feedback Systems: Input-Output Properties; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2009. [Google Scholar]
- Meyer, P.; Davenport, A.; Arcak, M. TIRA: Toolbox for interval reachability analysis. arXiv 2019, arXiv:1902.05204. [Google Scholar]
- Aylward, E.; Parrilo, P.; Slotine, J. Stability and robustness analysis of nonlinear systems via contraction metrics and SOS programming. Automatica 2008, 48, 2163–2170. [Google Scholar] [CrossRef] [Green Version]
- Manchester, I.; Tang, J.; Slotine, J. Unifying robot trajectory tracking with control contraction metrics. In Robotics Research; Springer: Cham, Switzerland, 2018; pp. 403–418. [Google Scholar]












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perk, B.E.; Inalhan, G. Safe Motion Planning and Learning for Unmanned Aerial Systems. Aerospace 2022, 9, 56. https://doi.org/10.3390/aerospace9020056
Perk BE, Inalhan G. Safe Motion Planning and Learning for Unmanned Aerial Systems. Aerospace. 2022; 9(2):56. https://doi.org/10.3390/aerospace9020056
Chicago/Turabian StylePerk, Baris Eren, and Gokhan Inalhan. 2022. "Safe Motion Planning and Learning for Unmanned Aerial Systems" Aerospace 9, no. 2: 56. https://doi.org/10.3390/aerospace9020056