
A Text-Driven Aircraft Fault Diagnosis Model Based on a Word2vec and Priori-Knowledge Convolutional Neural Network

 , , , ,
, , , ,
Abstract
:1. Introduction
- (1)
- as a data-driven model, the proposed aircraft fault diagnosis model can automatically and quickly judge which failure type the failure described in the text belongs to once a failure-description text is entered from an objective point;
- (2)
- Word2vec as a more efficient method is used to do text feature extraction instead of the traditional Term Frequency & Inverse Document Frequency (TF-IDF) and Latent Dirichlet Allocation (LDA);
- (3)
- a novel prior-knowledge CNN is proposed by introducing the expert fault knowledge to improve the accuracy of fault diagnosis.
- Section 2 presents a literature review of text feature extraction and CNNs.
- In Section 3, the proposed text-driven aircraft fault diagnosis model is first discussed and the three core parts of the model, including text data preprocessing, Word2vec text feature extraction, and the prior-knowledge CNN, are then explained in detail.
- Section 4 describes the experiment and discusses the experimental results.
- Section 5 provides conclusions.
2. Literature Review
2.1. Text Feature Extraction
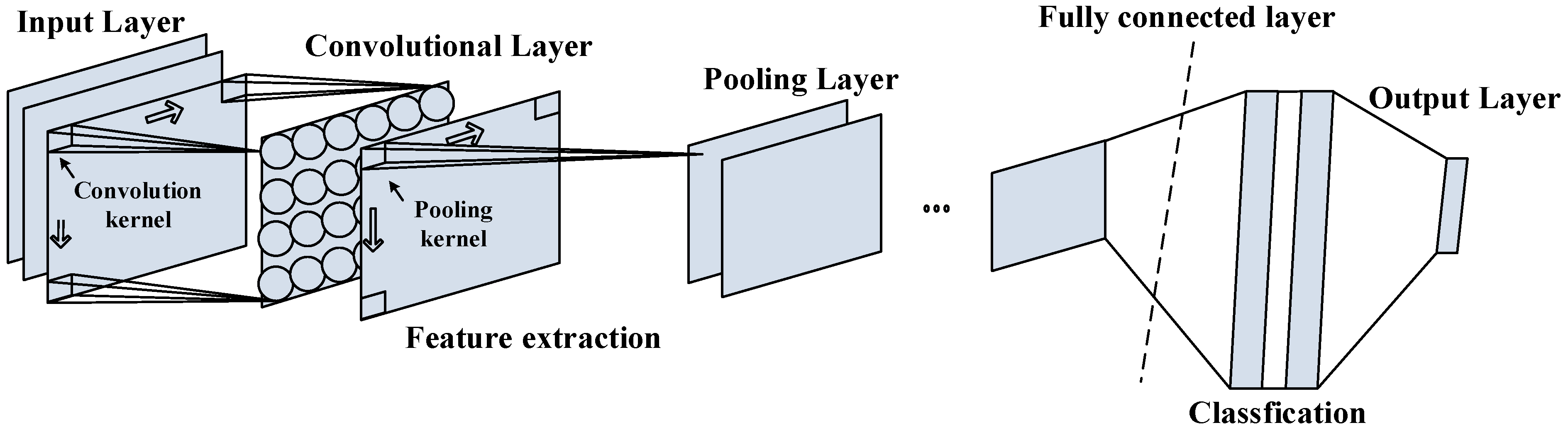
2.2. CNN
3. Methodology
3.1. Text Data Preprocessing
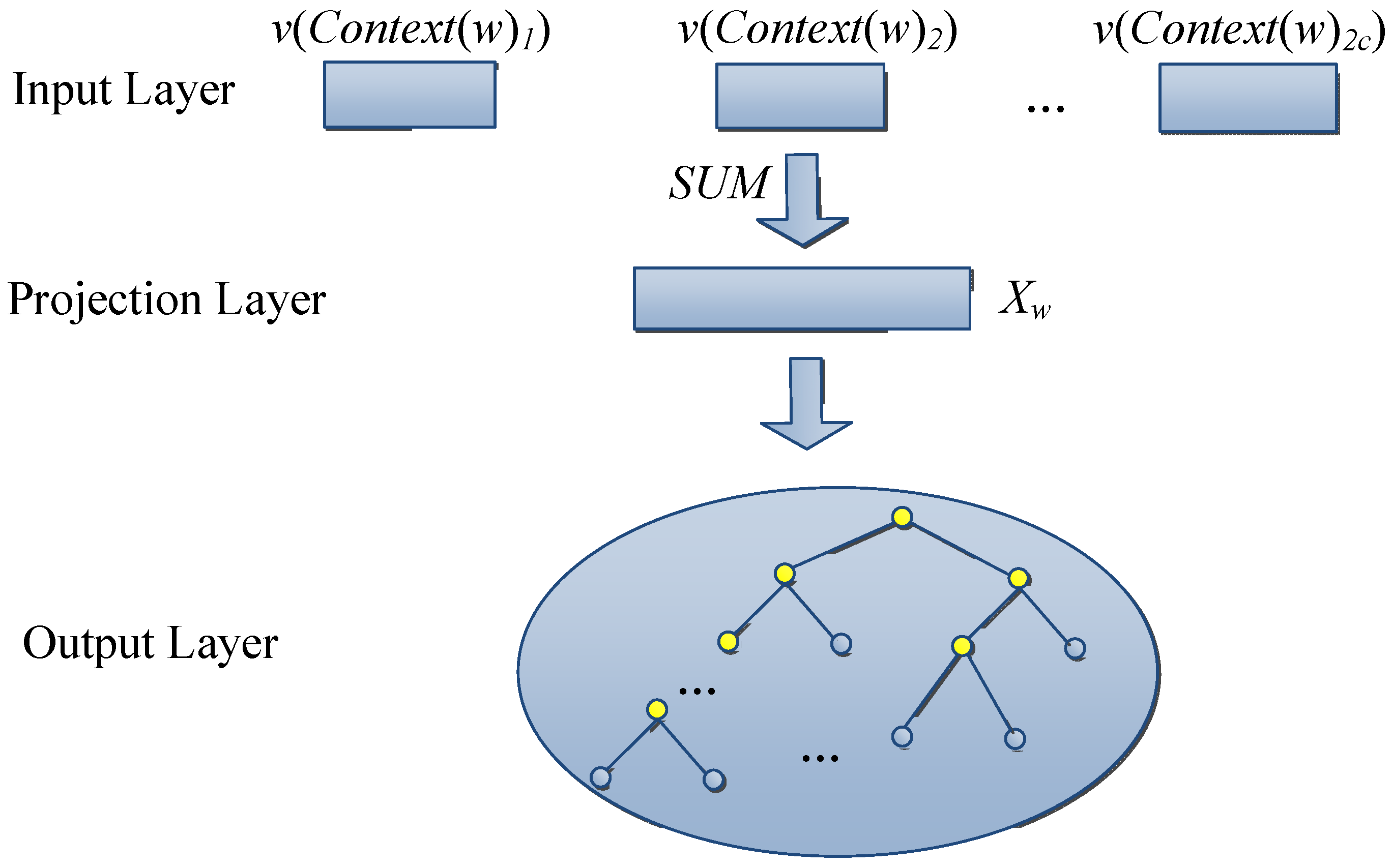
3.2. Text Feature Extraction Based on Word2vec
3.3. Prior-Knowledge CNN Based on Cloud Similarity Measurement (CSM)
3.3.1. CNN Algorithm
3.3.2. Text Similarity Measurement Based on CSM
- (1)
- Calculate the expected value of :First-order center distance:Sample variance:
- (2)
- Calculate the expected value of the cloud model:
- (3)
- Calculate the characteristic entropy of :
- (4)
- Calculate the super entropy of :where , , and are used to describe the overall characteristics of . The cloud vector of is then . Similarly, the cloud vector of another data set is . The cosine value of the cosine angle between two cloud vectors is expressed as the similarity of the two sequences:
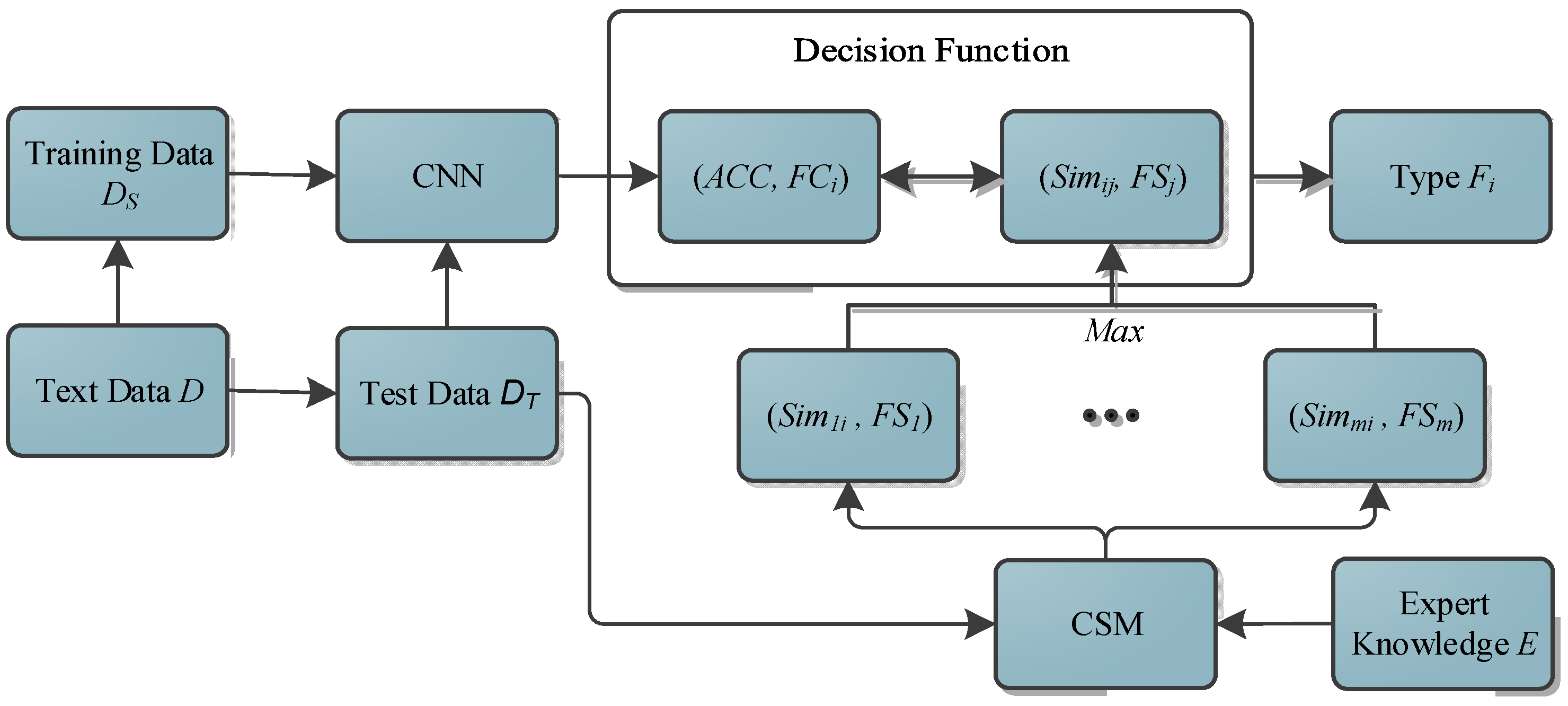
3.3.3. Construction of Prior-Knowledge CNN
- (1)
- Firstly, the text data set is divided into training set and test set according to a certain proportion.
- (2)
- Second, the training set enters the CNN to train the initial CNN classifier, and the test set enters the initial CNN classifier to test the classification accuracy of the initial CNN classifier.
- (3)
- Thirdly, for any fault text vector in the test set , it is put into the initial CNN classifier to obtain the initial predictions fault type . and make up the tuple .
- (4)
- Fourthly, the similarity between the fault text vector in the expert fault knowledge base and fault text vector to be classified is calculated to obtain the similarity set . The maximum value of set is taken to obtain . and make up the tuple .
- (5)
- Fifthly, the operation shown in Equation (12) is performed on and to obtain the final fault type corresponding to the fault text vector .
4. Experiments and Result Analysis
5. Conclusions
- (1)
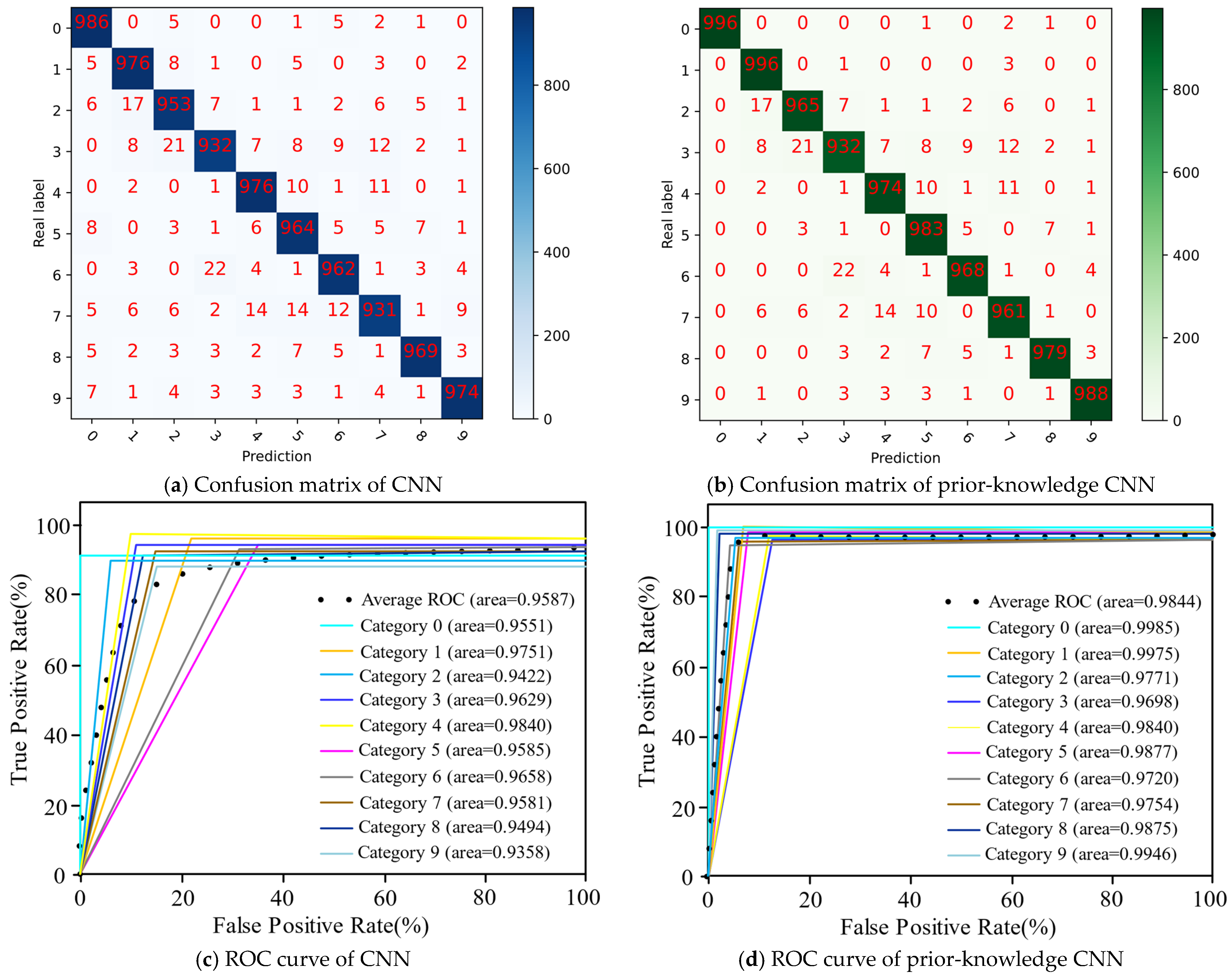
- The proposed aircraft fault diagnosis model based on Word2vec and the prior-knowledge CNN reached 0.9742, 0.9740, and 0.9844 in , , and , respectively. The accuracy is more than 97%, so the fault type can be accurately judged according to the fault description text by this model.
- (2)
- For this study, Word2vec is a more effective text feature extraction method compared with TF-IDF and LDA and it can improve the performance of the classifier.
- (3)
- The CNN classifier is better than the MLP classifier and the SVM classifier for the performance indicators of , , and . Introducing expert fault knowledge to the CNN by CSM can further improve the accuracy of fault diagnosis.
- (4)
- A high-quality expert fault knowledge base is the key to further improving the performance of the prior-knowledge CNN classifier.
- (1)
- A new text-driven aircraft fault diagnosis framework based on Word2vec and the prior-knowledge CNN is proposed in this paper, and it has a higher fault diagnosis accuracy compared with the previous text-driven aircraft fault frameworks.
- (2)
- To further improve the accuracy of fault diagnosis, a more efficient Word2vec method, instead of the traditional TF-IDF and LDA methods, is used to extract text features.
- (3)
- A novel prior-knowledge CNN is proposed in this paper by fusing a CNN and CSM, which improves the performance of the CNN classifier and is much better than the traditional MLP and SVM classifiers.
- (4)
- The text-driven aircraft fault diagnosis model developed in this paper can process not only English text but also Chinese text.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dhillon, B.S.; Liu, Y. Human error in maintenance: A review. J. Qual. Maint. Eng. 2006, 12, 21–36. [Google Scholar] [CrossRef]
- Qin, S.J. Survey on data-driven industrial process monitoring and diagnosis. Annu. Rev. Control 2012, 36, 220–234. [Google Scholar] [CrossRef]
- Salfner, F.; Lenk, M.; Malek, M. A survey of online failure prediction methods. ACM Comput. Surv. (CSUR) 2010, 42, 1–42. [Google Scholar] [CrossRef]
- Nguyen, N.P.; Huynh, T.T.; Do, X.P.; Mung, N.X.; Hong, S.K. Robust Fault Estimation Using the Intermediate Observer: Application to the Quadcopter. Sensors 2020, 20, 4917. [Google Scholar] [CrossRef]
- Nguyen, N.P.; Mung, N.X.; Thanh Ha, L.N.N.; Huynh, T.T.; Hong, S.K. Finite-Time Attitude Fault Tolerant Control of Quadcopter System via Neural Networks. Mathematics 2020, 8, 1541. [Google Scholar] [CrossRef]
- Gao, Z.; Ma, C.; Song, D.; Liu, Y. Deep quantum inspired neural network with application to aircraft fuel system fault diagnosis. Neurocomputing 2017, 238, 13–23. [Google Scholar] [CrossRef]
- Shen, Y.; Khorasani, K. Hybrid multi-mode machine learning-based fault diagnosis strategies with application to aircraft gas turbine engines. Neural Netw. 2020, 130, 126–142. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.M.; Cheung, C.F.; Lee, W.B.; Kwok, S.K. Mining knowledge from natural language texts using fuzzy associated concept mapping. Inform. Process. Manag. 2008, 44, 1707–1719. [Google Scholar] [CrossRef]
- Liang, H.; Sun, X.; Sun, Y.; Gao, Y. Text feature extraction based on deep learning: A review. Eurasip. J. Wirel. Comm. 2017, 2017, 211. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Xu, X.; Liu, Y.; Chang, R.; Xiao, Y. Text Similarity Measurement of Semantic Cognition Based on Word Vector Distance Decentralization with Clustering Analysis. IEEE Access 2019, 7, 107247–107258. [Google Scholar] [CrossRef]
- Sparck, J.K. A Statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn Res. 2003, 3, 993–1022. [Google Scholar]
- Rodrigues, R.S.; Balestrassi, P.P.; Paiva, A.P.; Garcia-Diaz, A.; Pontes, F.J. Aircraft interior failure pattern recognition utilizing text mining and neural networks. J. Intell. Inf. Syst. 2012, 38, 741–766. [Google Scholar] [CrossRef]
- Wang, F.; Xu, T.; Tang, T.; Zhou, M.; Wang, H. Bilevel Feature Extraction-Based Text Mining for Fault Diagnosis of Railway Systems. IEEE T Intell. Transp. 2017, 18, 49–58. [Google Scholar] [CrossRef]
- Zhou, S.; Chen, B.; Zhang, Y.; Liu, H.; Xiao, Y.; Pan, X. A Feature Extraction Method Based on Feature Fusion and its Application in the Text-Driven Failure Diagnosis Field. Int. J. Interact. Multimed. Artif. Intell. 2020, 6, 121–130. [Google Scholar]
- Kim, D.; Seo, D.; Cho, S.; Kang, P. Multi-co-training for document classification using various document representations: TF–IDF, LDA, and Doc2Vec. Inform. Sci. 2019, 477, 15–29. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Jatnika, D.; Bijaksana, M.A.; Suryani, A.A. Word2Vec Model Analysis for Semantic Similarities in English Words. Procedia Comput. Sci. 2019, 157, 160–167. [Google Scholar] [CrossRef]
- Chang, W.; Xu, Z.; You, M.; Zhou, S.; Xiao, Y.; Cheng, Y. A Bayesian Failure Prediction Network Based on Text Sequence Mining and Clustering. Entropy 2018, 12, 923. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bai, Z.; Sun, G.; Zang, H.; Zhang, M.; Shen, P.; Liu, Y.; Wei, Z. Identification Technology of Grid Monitoring Alarm Event Based on Natural Language Processing and Deep Learning in China. Energies 2019, 17, 3258. [Google Scholar] [CrossRef] [Green Version]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recogn. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Boser, B.E.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Denver, CO, USA, 26–29 November 1990; pp. 396–404. [Google Scholar]
- Shang, R.; He, J.; Wang, J.; Xu, K.; Jiao, L.; Stolkin, R. Dense connection and depthwise separable convolution based CNN for polarimetric SAR image classification. Knowl. Based Syst. 2020, 194, 105542. [Google Scholar] [CrossRef]
- Wu, M.; Yue, H.; Wang, J.; Huang, Y.; Liu, M.; Jiang, Y.; Ke, C.; Zeng, C. Object detection based on RGC mask R-CNN. IET Image Process. 2020, 14, 1502–1508. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Pintelas, P. A CNN–LSTM model for gold price time-series forecasting. Neural Comput. Appl. 2020, 32, 17351–17360. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Pr. 2020, 138, 106587. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Eren, L.; Ince, T.; Kiranyaz, S. A Generic Intelligent Bearing Fault Diagnosis System Using Compact Adaptive 1D CNN Classifier. J. Signal Process. Syst. 2019, 91, 179–189. [Google Scholar] [CrossRef]
- Zhong, S.; Fu, S.; Lin, L. A novel gas turbine fault diagnosis method based on transfer learning with CNN. Measurement 2019, 137, 435–453. [Google Scholar] [CrossRef]
- Hao, B.; Zhang, X.; Li, H.; Yang, Z. Intelligent fault diagnosis of rolling bearings based on normalized CNN considering data imbalance and variable working conditions. Knowl. Based Syst. 2020, 199, 105971. [Google Scholar]
- Ma, C.; Chen, L.; Yong, J. AU R-CNN: Encoding expert prior knowledge into R-CNN for action unit detection. Neurocomputing 2019, 355, 35–47. [Google Scholar] [CrossRef] [Green Version]
- Hou, W.; Tao, X.; De, X. Combining Prior Knowledge with CNN for Weak Scratch Inspection of Optical Components. IEEE T Instrum. Meas. 2021, 70, 1–11. [Google Scholar]
- Zhao, H.; Cai, D.; Huang, C.; Kit, C. Chinese word segmentation: Another decade review (2007–2017). arXiv 2019, arXiv:1901.06079. [Google Scholar]
- Krishnaraj, N.; Elhoseny, M.; Lydia, E.L.; Shankar, K.; ALDabbas, O. An efficient radix trie-based semantic visual indexing model for large-scale image retrieval in cloud environment. Softw. Pract. Exp. 2021, 51, 489–502. [Google Scholar] [CrossRef]
- Manogaran, G.; Vijayakumar, V.; Varatharajan, R.; Malarvizhi Kumar, P.; Sundarasekar, R.; Hsu, C. Machine Learning Based Big Data Processing Framework for Cancer Diagnosis Using Hidden Markov Model and GM Clustering. Wirel. Pers. Commun. 2018, 102, 2099–2116. [Google Scholar] [CrossRef]
- Shlezinger, N.; Farsad, N.; Eldar, Y.C.; Goldsmith, A.J. ViterbiNet: A Deep Learning Based Viterbi Algorithm for Symbol Detection. Ieee T Wirel. Commun. 2020, 19, 3319–3331. [Google Scholar] [CrossRef] [Green Version]
- Liu, K.; Ergu, D.; Cai, Y.; Gong, B.; Sheng, J. A New Approach to Process the Unknown Words in Financial Public Opinion. Procedia Comput. Sci. 2019, 162, 523–531. [Google Scholar] [CrossRef]
- Qingshuang, Y.U.; Jie, Z.H.O.U.; Wenjuan, G.O.N.G. A Lightweight Sentiment Analysis Method. ZTE Commun. 2019, 17, 2. [Google Scholar]
- Zhang, D.; Xu, H.; Su, Z.; Xu, Y. Chinese comments sentiment classification based on word2vec and SVMperf. Expert Syst. Appl. 2015, 42, 1857–1863. [Google Scholar] [CrossRef]
- Han, L.; Li, C.; Shen, L.; Becerra Villanueva, J.A. Application in Feature Extraction of AE Signal for Rolling Bearing in EEMD and Cloud Similarity Measurement. Shock Vib. 2015, 2015, 752078. [Google Scholar] [CrossRef] [Green Version]
- Zhou, S.; Qian, S.; Chang, W.; Xiao, Y.; Cheng, Y. A Novel Bearing Multi-Fault Diagnosis Approach Based on Weighted Permutation Entropy and an Improved SVM Ensemble Classifier. Sensors 2018, 18, 1934. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jin, K.H.; McCann, M.T.; Froustey, E.; Unser, M. Deep Convolutional Neural Network for Inverse Problems in Imaging. IEEE T Image Process. 2017, 26, 4509–4522. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adeli, H. Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals. Comput. Biol. Med. 2018, 100, 270–278. [Google Scholar] [CrossRef] [PubMed]
- Poria, S.; Cambria, E.; Gelbukh, A. Aspect extraction for opinion mining with a deep convolutional neural network. Knowl. Based Syst. 2016, 108, 42–49. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Text Number | Content | Fault Type |
|---|---|---|
| 1 | Compressor bladed was broken and the rotor was stuck. | Mechanical fault (4) |
| 2 | The booster switch cannot be closed, resulting in a broken motor shaft. | Switch fault (9) |
| 3 | Low output voltage due to resistance fault. | Resistance fault (3) |
| 4 | The vibration meter amplifier of Engine 4 did not indicate, the light did not work, and there was an internal fault. | Indicator fault (7) |
| 5 | Oil pipe aging led to oil leakage of Engine 3’s hydraulic oil inlet pipe. | Equipment aging (5) |
| … | … | … |
| Text Number | Text Preprocessing Result |
|---|---|
| 1 | Compressor/bladed/broken/rotor/stuck |
| 2 | booster switch/cannot/closed/resulting in/motor shaft/broken |
| 3 | Low output voltage/due to/resistance fault |
| 4 | vibration meter/amplifier/Engine 4/did not/indicate, light/did not work/there was/internal fault |
| 5 | Oil pipe/aging/led to/oil/leakage/Engine 3/hydraulic/oil inlet pipe |
| … | … |
| Number | Dimension | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | … | 98 | 99 | 100 | |
| 1 | 0.0224 | 0.1750 | 0.1249 | 0.1361 | … | 0.0854 | 0.0536 | 0.0307 |
| 2 | 0.0123 | 0.1364 | 0.0933 | 0.1007 | … | 0.0560 | 0.0345 | 0.0208 |
| 3 | 0.0166 | 0.1335 | 0.0940 | 0.0993 | … | 0.0601 | 0.0372 | 0.0183 |
| 4 | 0.0090 | 0.1133 | 0.0750 | 0.0776 | 0.0497 | 0.0262 | 0.0221 | |
| 5 | 0.0080 | 0.1236 | 0.0874 | 0.0948 | … | 0.0505 | 0.0313 | 0.0263 |
| … | … | … | … | … | … | … | … | … |
| Number | Fault Type | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 0.9523 | 0.8645 | 0.8748 | 0.9845 | 0.8412 | 0.6312 | 0.7412 | 0.8936 | 0.8512 | 0.9621 |
| 2 | 0.8154 | 0.6126 | 0.2278 | 0.7386 | 0.6260 | 0.8790 | 0.9900 | 0.4981 | 0.5860 | 0.6609 |
| 3 | 0.9889 | 0.5277 | 0.9009 | 0.7298 | 0.0005 | 0.4795 | 0.5747 | 0.6664 | 0.8908 | 0.8654 |
| 4 | 0.8013 | 0.8452 | 0.0835 | 0.9823 | 0.9283 | 0.8449 | 0.6352 | 0.2819 | 0.2055 | 0.0170 |
| … | … | … | … | … | … | … | … | … | … | … |
| Group ID | Method | |||
|---|---|---|---|---|
| A | TF-IDF + MLP | 0.8325 | 0.8169 | 0.8187 |
| B | LDA + SVM | 0.8946 | 0.8721 | 0.8825 |
| C | TF-IDF + CNN | 0.8735 | 0.8224 | 0.8465 |
| D | LDA + CNN | 0.9364 | 0.9105 | 0.9476 |
| E | Word2vec + CNN | 0.9623 | 0.9647 | 0.9587 |
| F | Word2vec + MLP | 0.8568 | 0.8678 | 0.8628 |
| G | Word2vec + SVM | 0.9251 | 0.9168 | 0.9176 |
| H | Word2vec + Priori-knowledge CNN | 0.9742 | 0.9740 | 0.9844 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Chen, B.; Zhou, S.; Chang, W.; Ji, X.; Wei, C.; Hou, W. A Text-Driven Aircraft Fault Diagnosis Model Based on a Word2vec and Priori-Knowledge Convolutional Neural Network. Aerospace 2021, 8, 112. https://doi.org/10.3390/aerospace8040112
Xu Z, Chen B, Zhou S, Chang W, Ji X, Wei C, Hou W. A Text-Driven Aircraft Fault Diagnosis Model Based on a Word2vec and Priori-Knowledge Convolutional Neural Network. Aerospace. 2021; 8(4):112. https://doi.org/10.3390/aerospace8040112
Chicago/Turabian StyleXu, Zhenzhong, Bang Chen, Shenghan Zhou, Wenbing Chang, Xinpeng Ji, Chaofan Wei, and Wenkui Hou. 2021. "A Text-Driven Aircraft Fault Diagnosis Model Based on a Word2vec and Priori-Knowledge Convolutional Neural Network" Aerospace 8, no. 4: 112. https://doi.org/10.3390/aerospace8040112