

Characterizing Satellite Geometry via Accelerated 3D Gaussian Splatting

Abstract
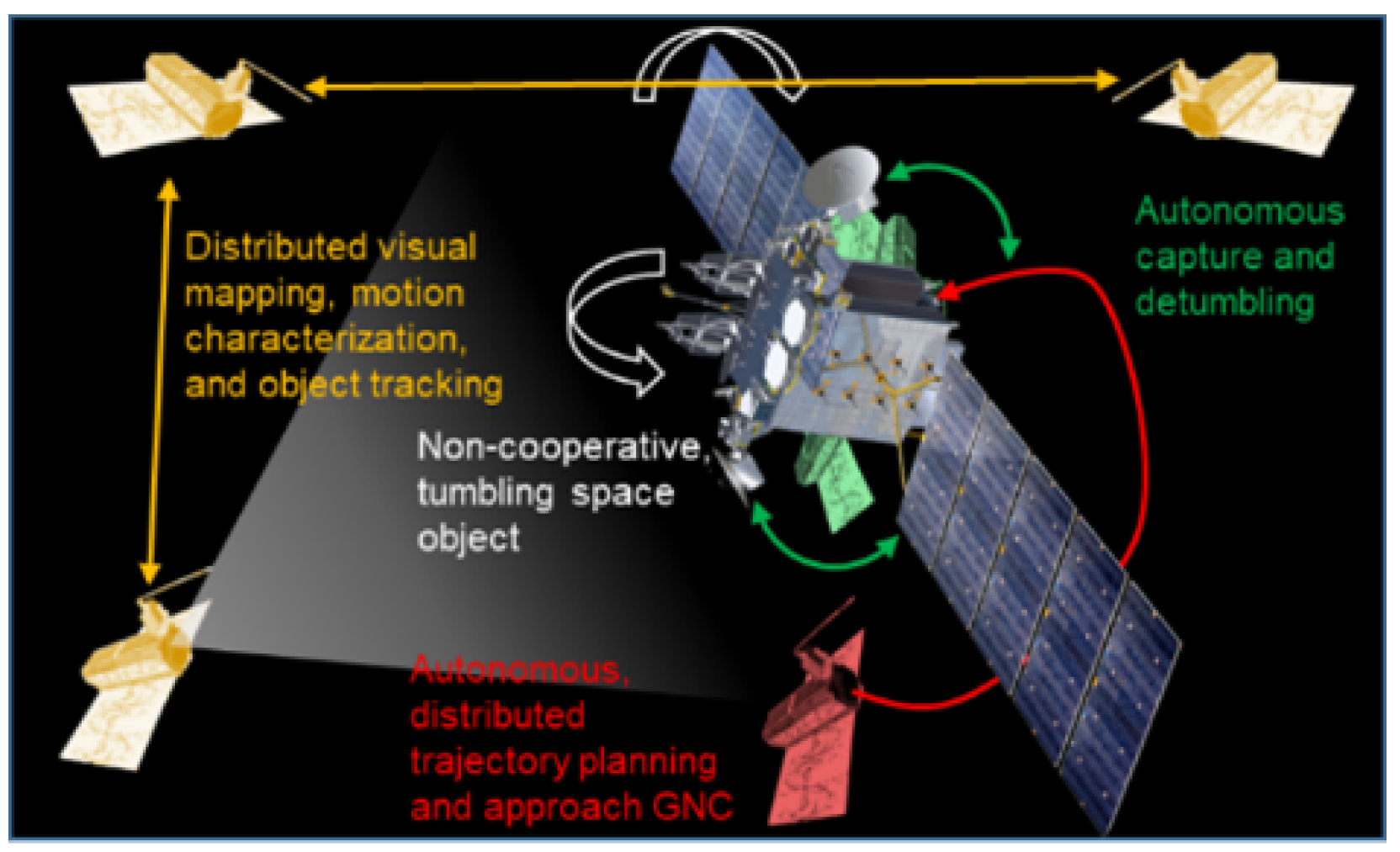
:1. Introduction
- An effective low-computational-cost 3D Gaussian splatting model optimized for the 3D reconstruction of an unknownRSO capable of deployment on spaceflight hardware;
- Hardware-in-the-loop experiments demonstrating 3D rendering performance under realistic lighting and motion conditions;
- A comparison of the NeRF, D-NeRF, Instant NeRF, 3D Gaussian splatting, and 4D Gaussian splatting algorithms in terms of 3D rendering quality, runtimes, and computational costs.
2. Related Work
2.1. Computer Vision for On-Orbit Operations
2.2. 3D Rendering
3. Methods
3.1. 3D Gaussian Splatting
3.2. Experimental Setup
3.3. Datasets
- Case 1.
- Images of the target RSO were taken at 10° increments around a circle with a radius of 5 ft (simulating an R-bar maneuver around a stationary RSO) with 10% lighting intensity. Viewing angles were at 10° increments rotating about the vertical axis.
- Case 2.
- Images of the target RSO were taken at 10° increments around a circle with a radius of 5 ft (simulating an R-bar maneuver around a stationary RSO) with 100% lighting intensity. Viewing angles were at 10° increments rotating about the vertical axis.
- Case 3.
- Videos of the RSO were captured as it yawed at 10°/s with the chaser positioned 5 ft away (simulating V-bar stationkeeping around a spinning RSO) with 10% lighting intensity. Viewing angles were at 5° increments rotating about the vertical axis.
- Case 4.
- Videos of the RSO were captured as it yawed at 10°/s with the chaser positioned 5 ft away (simulating V-bar stationkeeping around a spinning RSO) with 100% lighting intensity. Viewing angles were at 5° increments rotating about the vertical axis.
3.4. Performance Evaluation for 3D Rendering
4. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Oda, M. Summary of NASDA’s ETS-VII robot satellite mission. J. Robot. Mechatron. 2000, 12, 417–424. [Google Scholar] [CrossRef]
- Davis, T.M.; Melanson, D. XSS-10 microsatellite flight demonstration program results. In Proceedings of the Spacecraft Platforms and Infrastructure, Orlando, FL, USA, 12–16 April 2004; Volume 5419, pp. 16–25. [Google Scholar] [CrossRef]
- Air Force Research Laboratory. XSS-11 Micro Satellite; Technical Report; Air Force Research Laboratory: Adelphi, MD, USA, 2011. [Google Scholar]
- Air Force Research Laboratory. Automated Navigation and Guidance Experiment for Local Space (ANGELS); Technical Report; Air Force Research Laboratory: Adelphi, MD, USA, 2014. [Google Scholar]
- Intelsat. MEV-1: A Look Back at the Groundbreaking Journey|Intelsat. 2020. Available online: https://www.intelsat.com/resources/blog/mev-1-a-look-back-at-intelsats-groundbreaking-journey/ (accessed on 21 February 2024).
- Rainbow, J.; MEV-2 Servicer Successfully Docks to Live Intelsat Satellite. Space News 12 April 2021. Available online: https://spacenews.com/mev-2-servicer-successfully-docks-to-live-intelsat-satellite/ (accessed on 21 February 2024).
- Pyrak, M.; Anderson, J. Performance of Northrop Grumman’s Mission Extension Vehicle (MEV) RPO imagers at GEO. In Proceedings of the Autonomous Systems: Sensors, Processing and Security for Ground, Air, Sea and Space Vehicles and Infrastructure 2022, Orlando, FL, USA, 3 April–13 June 2022; Volume 12115, pp. 64–82. [Google Scholar] [CrossRef]
- Forshaw, J.; Lopez, R.; Okamoto, A.; Blackerby, C.; Okada, N. The ELSA-d End-of-life Debris Removal Mission: Mission Design, In-flight Safety, and Preparations for Launch. In Proceedings of the Advanced Maui Optical and Space Surveillance Technologies Conference, Kihei, HI, USA, 17–20 September 2019; p. 44. [Google Scholar]
- Mahendrakar, T.; White, R.; Wilde, M.; Kish, B.; Silver, I. Real-time Satellite Component Recognition with YOLO-V5. In Proceedings of the 35th Annual Small Satellite Conference, Logan, UT, USA, 7–12 August 2021. [Google Scholar]
- Mahendrakar, T.; Wilde, M.; White, R. Use of Artificial Intelligence for Feature Recognition and Flightpath Planning Around Non-Cooperative Resident Space Objects. In ASCEND 2021; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 2021. [Google Scholar] [CrossRef]
- Cutler, J.; Wilde, M.; Rivkin, A.; Kish, B.; Silver, I. Artificial Potential Field Guidance for Capture of Non-Cooperative Target Objects by Chaser Swarms. In Proceedings of the 2022 IEEE Aerospace Conference (AERO), Big Sky, MT, USA, 5–12 March 2022. [Google Scholar] [CrossRef]
- Mahendrakar, T.; Holmberg, S.; Ekblad, A.; Conti, E.; White, R.T.; Wilde, M.; Silver, I. Autonomous Rendezvous with Non-cooperative Target Objects with Swarm Chasers and Observers. In Proceedings of the 2023 AAS/AIAA Spaceflight Mechanics Meeting, Austin, TX, USA, 15–19 January 2023. [Google Scholar]
- Kerbl, B.; Kopanas, G.; Leimkuehler, T.; Drettakis, G. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Trans. Graph. 2023, 42, 139:1–139:14. [Google Scholar] [CrossRef]
- Attzs, M.; Mahendrakar, T.; Meni, M.; White, R.; Silver, I. Comparison of Tracking-By-Detection Algorithms for Real-Time Satellite Component Tracking. In Proceedings of the Small Satellite Conference, Logan, UT, USA, 5–10 August 2023. [Google Scholar]
- Viggh, H.; Loughran, S.; Rachlin, Y.; Allen, R.; Ruprecht, J. Training Deep Learning Spacecraft Component Detection Algorithms Using Synthetic Image Data. In Proceedings of the 2023 IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2023. [Google Scholar] [CrossRef]
- Dung, H.A.; Chen, B.; Chin, T.J. A Spacecraft Dataset for Detection, Segmentation and Parts Recognition. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 2012–2019. [Google Scholar] [CrossRef]
- Mahendrakar, T.; Ekblad, A.; Fischer, N.; White, R.; Wilde, M.; Kish, B.; Silver, I. Performance Study of YOLOv5 and Faster R-CNN for Autonomous Navigation around Non-Cooperative Targets. In Proceedings of the 2022 IEEE Aerospace Conference (AERO), Big Sky, MT, USA, 5–12 March 2022; pp. 1–12. [Google Scholar]
- Faraco, N.; Maestrini, M.; Di Lizia, P. Instance segmentation for feature recognition on noncooperative resident space objects. J. Spacecr. Rocket. 2022, 59, 2160–2174. [Google Scholar] [CrossRef]
- Mahendrakar, T.; Attzs, M.N.; Tisaranni, A.L.; Duarte, J.M.; White, R.T.; Wilde, M. Impact of Intra-class Variance on YOLOv5 Model Performance for Autonomous Navigation around Non-Cooperative Targets. In Proceedings of the AIAA SCITECH 2023 Forum, National Harbor, MD, USA, 23–27 January 2023; p. 2374. [Google Scholar]
- Kisantal, M.; Sharma, S.; Park, T.H.; Izzo, D.; Martens, M.; D’Amico, S. Satellite Pose Estimation Challenge: Dataset, Competition Design, and Results. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 4083–4098. [Google Scholar] [CrossRef]
- Park, T.H.; Märtens, M.; Lecuyer, G.; Izzo, D.; D’Amico, S. SPEED+: Next-Generation Dataset for Spacecraft Pose Estimation across Domain Gap. In Proceedings of the 2022 IEEE Aerospace Conference (AERO), Big Sky, MT, USA, 5–12 March 2022. [Google Scholar] [CrossRef]
- Park, T.H.; Sharma, S.; D’Amico, S. Towards Robust Learning-Based Pose Estimation of Noncooperative Spacecraft. arXiv 2019, arXiv:1909.00392. [Google Scholar] [CrossRef]
- Sharma, S.; D’Amico, S. Neural Network-Based Pose Estimation for Noncooperative Spacecraft Rendezvous. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 4638–4658. [Google Scholar] [CrossRef]
- Lotti, A.; Modenini, D.; Tortora, P.; Saponara, M.; Perino, M.A. Deep Learning for Real-Time Satellite Pose Estimation on Tensor Processing Units. J. Spacecr. Rocket. 2023, 60, 1034–1038. [Google Scholar] [CrossRef]
- Piazza, M.; Maestrini, M.; Di Lizia, P. Monocular Relative Pose Estimation Pipeline for Uncooperative Resident Space Objects. J. Aerosp. Inf. Syst. 2022, 19, 613–632. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Schwarz, K.; Liao, Y.; Niemeyer, M.; Geiger, A. Graf: Generative radiance fields for 3d-aware image synthesis. Adv. Neural Inf. Process. Syst. 2020, 33, 20154–20166. [Google Scholar]
- Mergy, A.; Lecuyer, G.; Derksen, D.; Izzo, D. Vision-based Neural Scene Representations for Spacecraft. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 2002–2011. [Google Scholar]
- Caruso, B.; Mahendrakar, T.; Nguyen, V.M.; White, R.T.; Steffen, T. 3D Reconstruction of Non-cooperative Resident Space Objects using Instant NGP-accelerated NeRF and D-NeRF. arXiv 2023, arXiv:2301.09060. [Google Scholar] [CrossRef]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. ACM Trans. Graph. 2022, 41, 102:1–102:15. [Google Scholar] [CrossRef]
- Pumarola, A.; Corona, E.; Pons-Moll, G.; Moreno-Noguer, F. D-NeRF: Neural Radiance Fields for Dynamic Scenes. arXiv 2020, arXiv:2011.13961. [Google Scholar] [CrossRef]
- Kulu, E. DODONA @ Nanosats Database. Available online: https://www.nanosats.eu/sat/dodona (accessed on 21 February 2024).
- Park, T.H.; D’Amico, S. Rapid Abstraction of Spacecraft 3D Structure from Single 2D Image. In Proceedings of the AIAA SCITECH Forum 2024, Orlando, FL, USA, 8–12 January 2024. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-From-Motion Revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Wu, G.; Yi, T.; Fang, J.; Xie, L.; Zhang, X.; Wei, W.; Liu, W.; Tian, Q.; Wang, X. 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering. arXiv 2023, arXiv:2310.08528. [Google Scholar] [CrossRef]
- Wilde, M.; Kaplinger, B.; Go, T.; Gutierrez, H.; Kirk, D. ORION: A simulation environment for spacecraft formation flight, capture, and orbital robotics. In Proceedings of the 2016 IEEE Aerospace Conference, Big Sky, MT, USA, 5–12 March 2016; pp. 1–14. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Case 1 | Case 2 | Case 3 | Case 4 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSIM↑ | PSNR↑ | LPIPS↓ | SSIM↑ | PSNR↑ | LPIPS↓ | SSIM↑ | PSNR↑ | LPIPS↓ | SSIM↑ | PSNR↑ | LPIPS↓ | |
| NeRF | 0.3891 | 16.81 | 0.5503 | 0.4520 | 16.52 | 0.5008 | 0.9332 | 28.24 | 0.0763 | 0.6438 | 19.54 | 0.3207 |
| D-NeRF | 0.3783 | 16.76 | 0.5418 | 0.0337 | 9.22 | 0.5877 | 0.8156 | 16.66 | 0.1853 | 0.6184 | 19.61 | 0.3282 |
| Instant NeRF | 0.5149 | 16.47 | 0.4374 | 0.4729 | 14.71 | 0.4440 | 0.8571 | 17.55 | 0.1277 | 0.8569 | 19.99 | 0.1056 |
| 3DGS | 0.9223 | 25.70 | 0.0814 | 0.6803 | 16.78 | 0.2949 | 0.8756 | 26.53 | 0.1040 | 0.9213 | 25.52 | 0.0796 |
| 4DGS | 0.5192 | 16.78 | 0.4310 | 0.4877 | 13.17 | 0.5193 | 0.4358 | 15.07 | 0.1454 | 0.7619 | 17.16 | 0.1890 |
| Method | Case 1 | Case 2 | Case 3 | Case 4 | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| VRAM (MB)↓ | Training Time↓ | VRAM (MB)↓ | Training Time↓ | VRAM (MB)↓ | Training Time↓ | VRAM (MB)↓ | Training Time↓ | VRAM (MB)↓ | Training Time↓ | C/T↑ | |
| NeRF | 3833 | 54 m 24 s | 3845 | 55 m 47 s | 4195 | 1 h 18 m 21 s | 3952 | 1 h 15 m 24 s | 3956.25 | 1 h 5 m 59 s | 2.58 |
| D-NeRF | 4586 | 1 h 37 m 17 s | 4598 | 1 h 39 m 32 s | 4948 | 2 h 14 m 56 s | 4634 | 2 h 05 m 24 s | 4691.5 | 1 h 54 m 17 s | 1.49 |
| Instant NeRF | 1664 | 5 m 18 s | 1684 | 5 m 7 s | 1934 | 6 m 11 s | 1702 | 6 m 15 s | 1746 | 5 m 43 s | 29.85 |
| 3DGS | 1485 | 5 m 42 s | 1668 | 7 m 4 s | 1875 | 6 m 59 s | 1792 | 6 m 32 s | 1705 | 6 m 34 s | 25.99 |
| 4DGS | 2224 | 57 m 32 s | 4089 | 1 h 5 m 51 s | 5385 | 44 m 34 s | 5022 | 1 h 56 m 00 s | 4180 | 1 h 10 m 59 s | 2.40 |
| Method | Case 1 | Case 2 | Case 3 | Case 4 | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| VRAM (MB)↓ | FPS↑ | VRAM (MB)↓ | FPS↑ | VRAM (MB)↓ | FPS↑ | VRAM (MB)↓ | FPS↑ | VRAM (MB)↓ | FPS↑ | FPS/CUDA Core↑ | |
| NeRF | 9143 | 0.27 | 11307 | 0.31 | 11323 | 0.14 | 11323 | 0.07 | 10774 | 0.20 | 1.95 |
| D-NeRF | 9171 | 0.19 | 11331 | 0.20 | 11347 | 0.08 | 11349 | 0.05 | 10799.5 | 0.13 | 1.27 |
| Instant NeRF | 1375 | 0.67 | 1407 | 0.85 | 1829 | 0.59 | 1827 | 0.23 | 1609.5 | 0.59 | 5.76 |
| 3DGS | 1615 | 45.84 | 1129 | 215.12 | 2807 | 108.78 | 1955 | 42.04 | 1876.5 | 102.95 | 1.01 |
| 4DGS | 1351 | 23.23 | 1389 | 28.93 | 1681 | 121.85 | 2687 | 8.23 | 1777 | 45.56 | 4.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, V.M.; Sandidge, E.; Mahendrakar, T.; White, R.T. Characterizing Satellite Geometry via Accelerated 3D Gaussian Splatting. Aerospace 2024, 11, 183. https://doi.org/10.3390/aerospace11030183
Nguyen VM, Sandidge E, Mahendrakar T, White RT. Characterizing Satellite Geometry via Accelerated 3D Gaussian Splatting. Aerospace. 2024; 11(3):183. https://doi.org/10.3390/aerospace11030183
Chicago/Turabian StyleNguyen, Van Minh, Emma Sandidge, Trupti Mahendrakar, and Ryan T. White. 2024. "Characterizing Satellite Geometry via Accelerated 3D Gaussian Splatting" Aerospace 11, no. 3: 183. https://doi.org/10.3390/aerospace11030183