
aeroBERT-Classifier: Classification of Aerospace Requirements Using BERT
 , , , and
, , , and
Abstract
:1. Introduction
1.1. Importance of Requirements Engineering
- Necessary: capable of conveying what is necessary to achieve the required system functionalities while being compliant with regulations;
- Clear: able to convey the desired goal to the stakeholders by being simple and concise;
- Traceable: able to be traced back to higher-level specifications and vice versa;
- Verifiable: can be verified by making use of different verification processes, such as analysis, inspection, demonstration, and test;
- Complete: the requirements should result in a system that successfully achieves the client’s needs while being compliant with the regulatory standards.
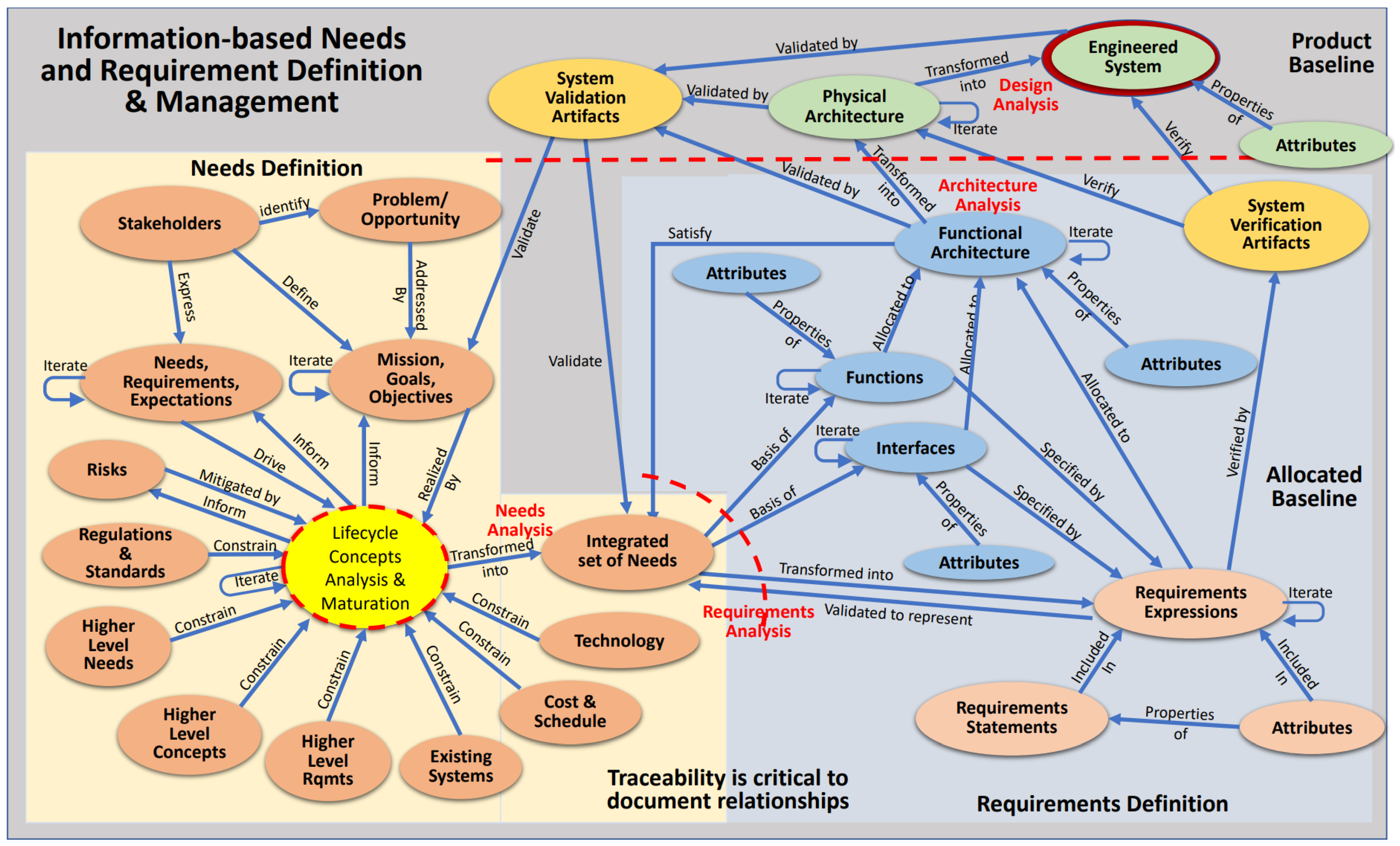
1.2. Shift towards Model-Based Systems Engineering
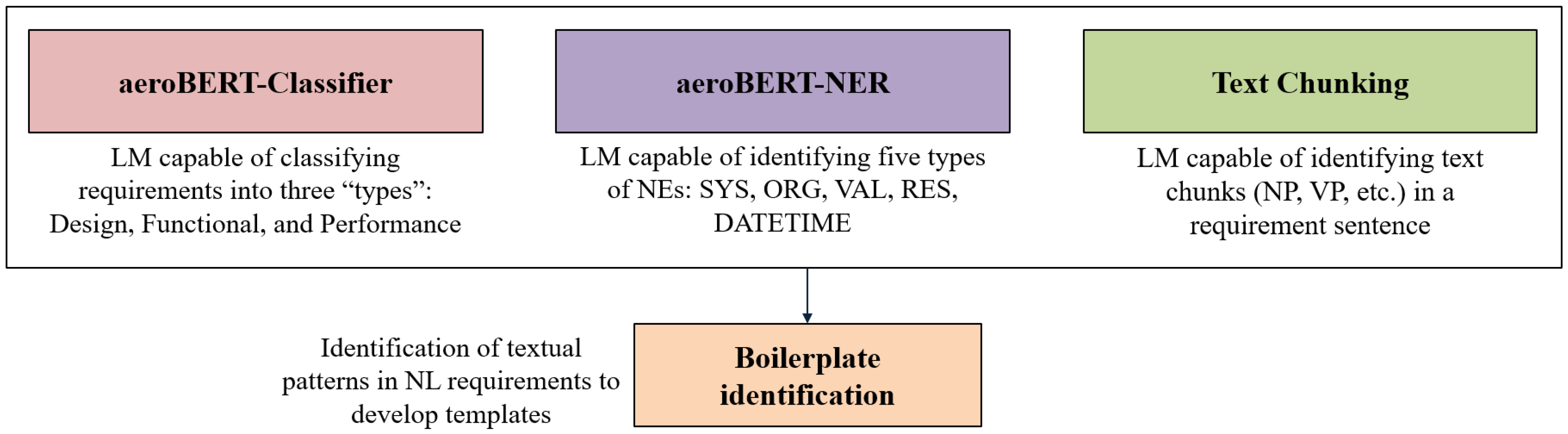
1.3. Research Focus and Expected Contributions
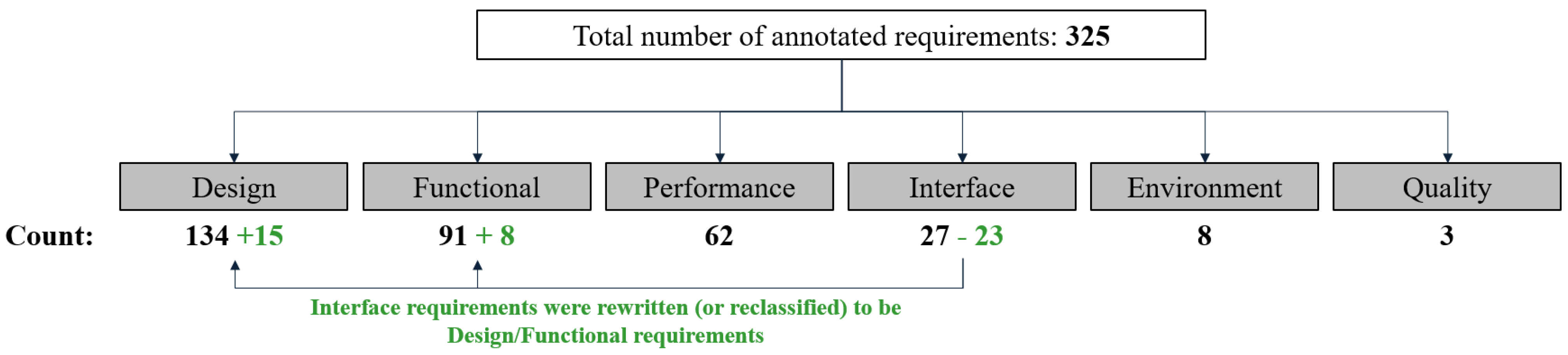
- Creation of the first open-source annotated aerospace requirements dataset. This dataset includes three types of requirements, namely, design, functional, and performance.
- Demonstration of a methodology describing the data collection, cleaning, and annotation of aerospace requirements from Parts 23 and 25 of Title 14 Code of Federal Regulations (CFRs) [19]. This demonstration is particularly important as it is missing from the existing literature on the use of NLP on datasets.
- Demonstration of the fine-tuning of a pre-trained large language model (BERT) to obtain an aerospace requirements classifier (aeroBERT-Classifier), which generalizes despite having been trained on a small annotated dataset.
- Demonstration of the viability of LMs in classifying high-level policy requirements such as the Federal Airworthiness Requirements (FARs), which have resisted earlier attempts to use NLP for automated processing. These requirements are particularly freeform and often complex expressions with a higher degree of classification difficulty than typical software or systems requirements (even for expert practitioners).
2. Background
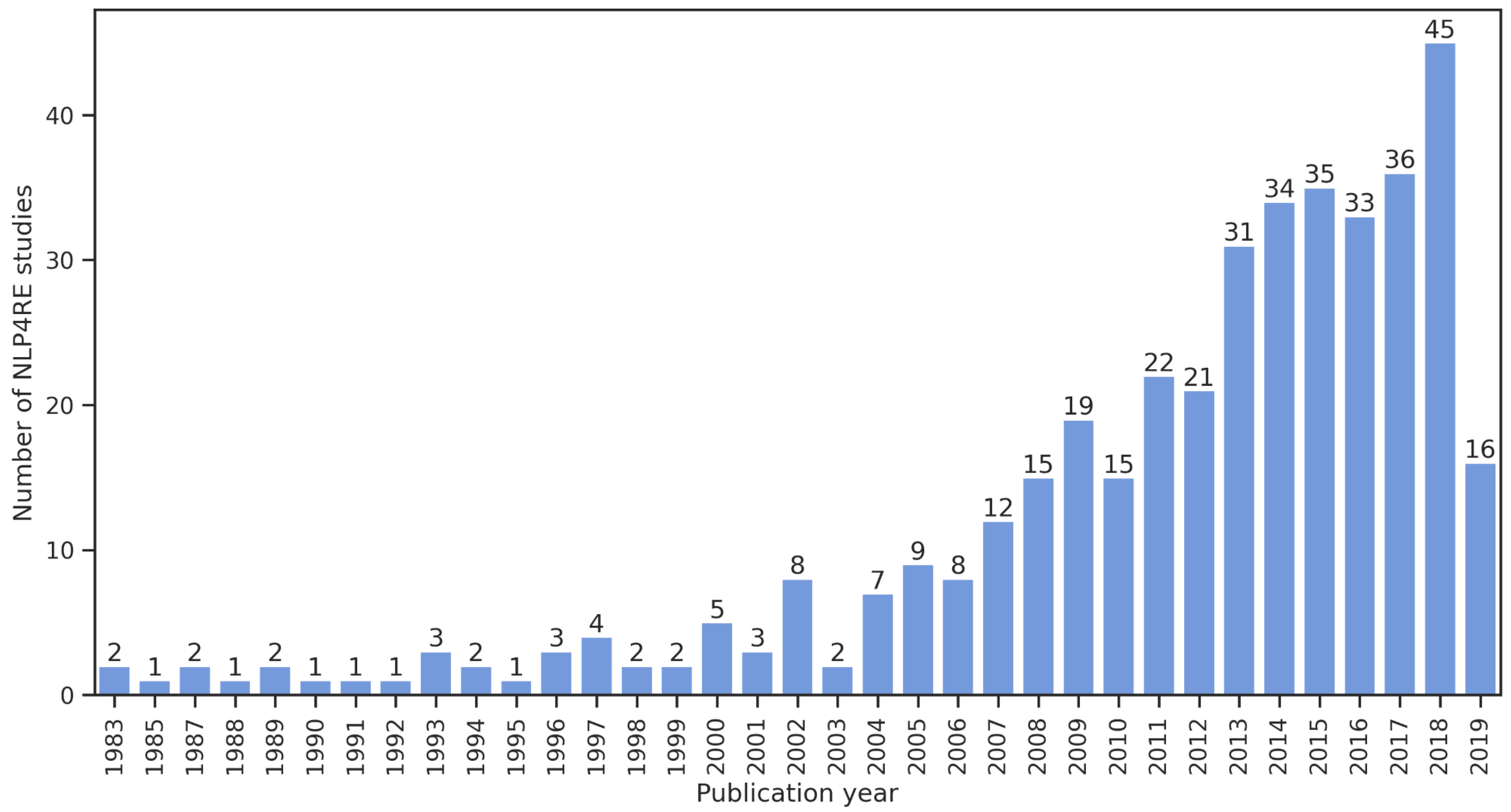
2.1. Natural Language Processing for Requirements Engineering (NLP4RE)
2.2. Natural Language Processing (NLP) and Language Models (LMs)
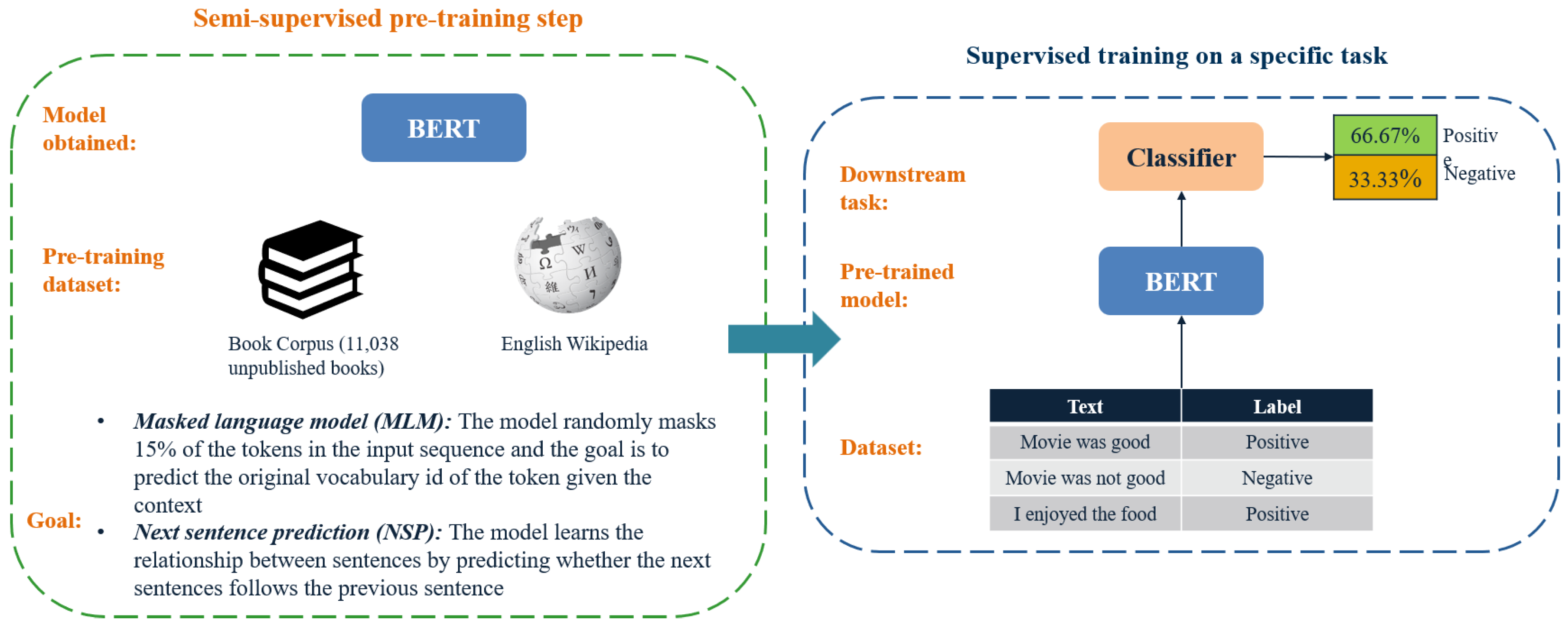
2.2.1. Bidirectional Encoder Representations from Transformers (BERT)
- BERT: contains 12 encoder blocks with a hidden size of 768 and 12 self-attention heads (total of 110 M parameters);
- BERT: contains 24 encoder blocks with a hidden size of 1024 and 16 self-attention heads (total of 340 M parameters).
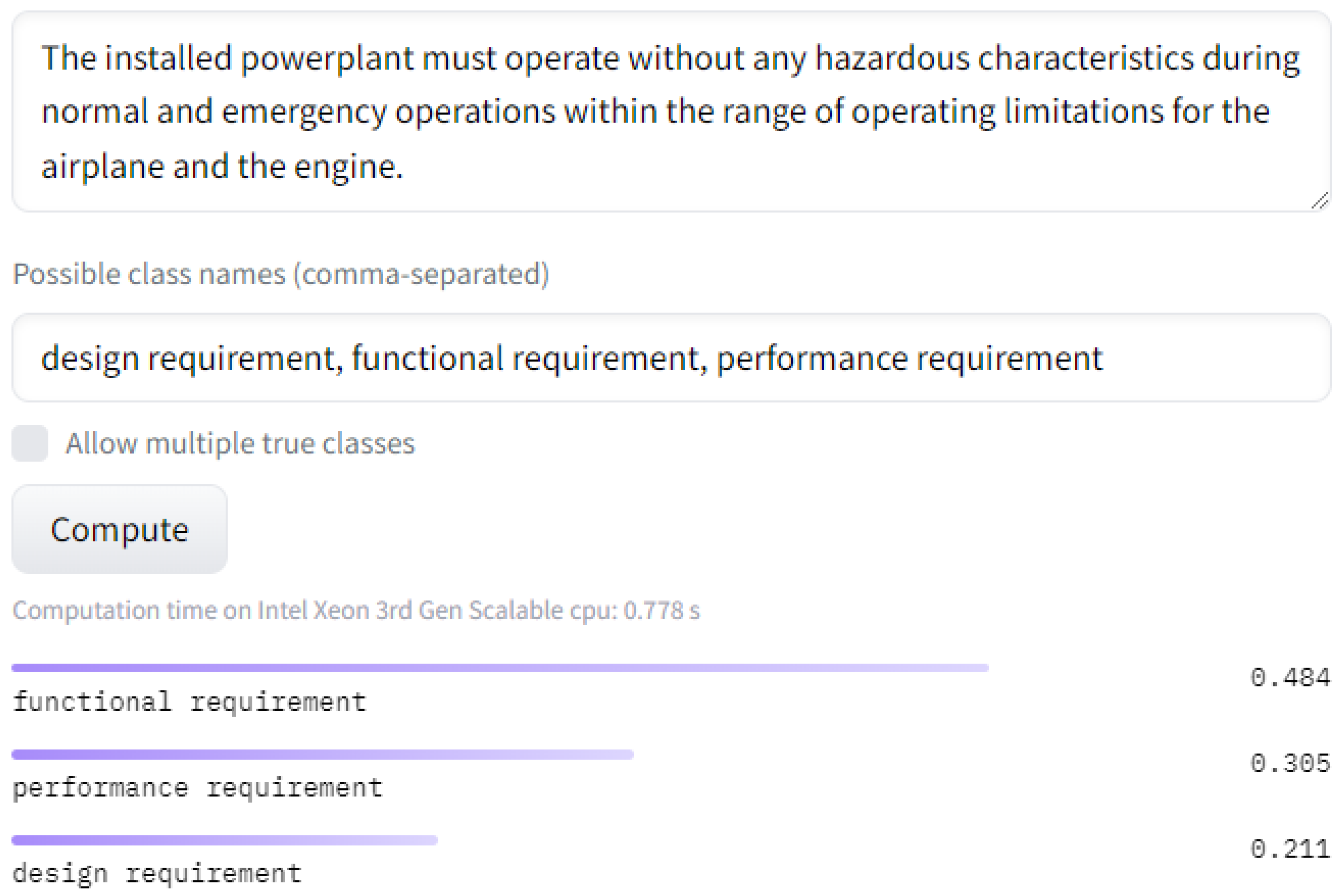
2.2.2. Zero-Shot Text Classification
3. Research Gaps and Objectives
Summary
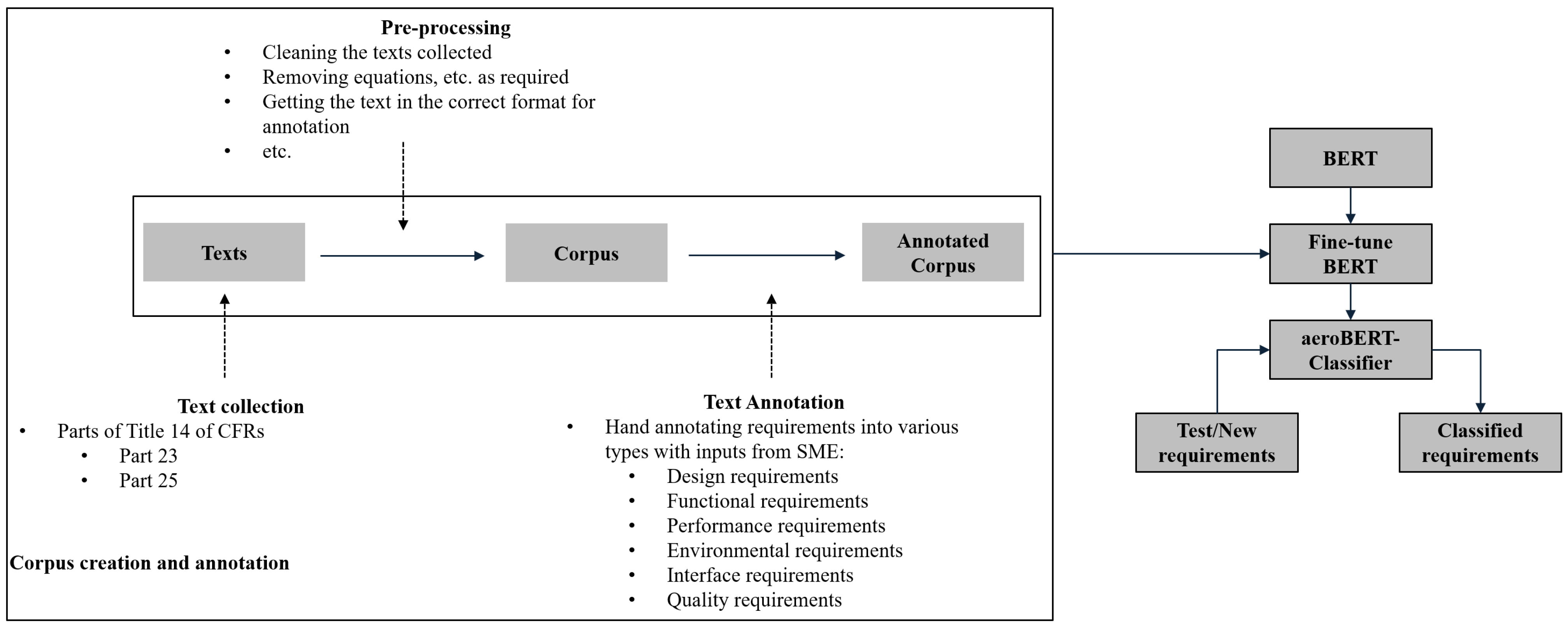
- Creation of a labeled aerospace requirements corpus: Aerospace requirements are collected from Parts 23 and 25 of Title 14 CFRs [65] and annotated. The annotation involves labeling each requirement with its type (e.g., functional, performance, interface, design, etc.).
- Fine-tuning of BERT for aerospace requirements classification: The annotated aerospace requirements are used to fine-tune several variants of the BERT LM (BERT, BERT, BERT, and BERT). We call the best resulting model aeroBERT-Classifier. Metrics such as precision, recall, and F1 score are used to assess the model performance.
- The comparison of the performance of aeroBERT-Classifier against other text classification models: The performance of aeroBERT-Classifier is compared to that of GPT-2 and Bi-LSTM (with GloVe word embedding), which are also trained or fine-tuned on the developed aerospace requirements dataset. Lastly, the model performance is compared to results obtained by using bart-large-mnli, a zero-short learning classifier, to further emphasize the importance of transfer learning in low-resource domains such as aerospace requirements engineering.
4. Materials and Methods
4.1. Data Collection, Cleaning, and Annotation
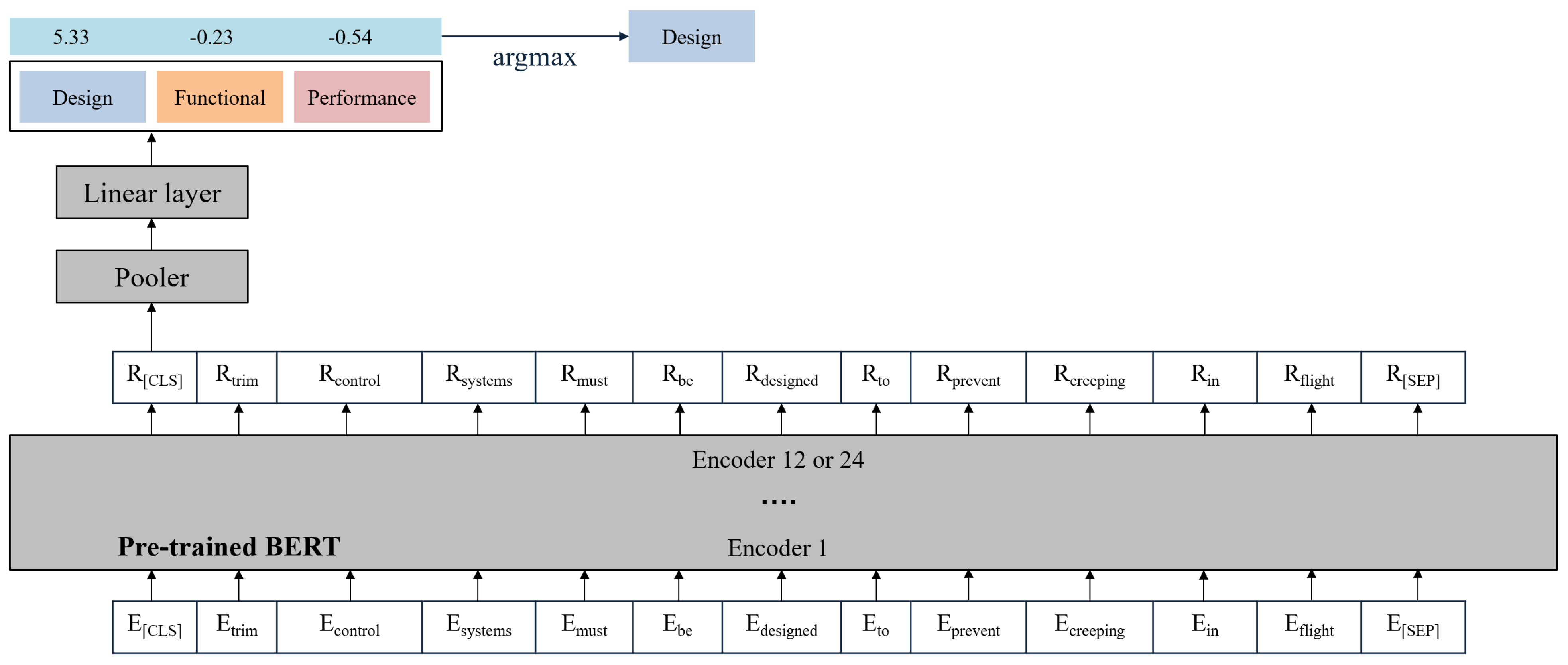
4.2. Preparing the Dataset for Fine-Tuning BERT
- [CLS]: This token is added to the beginning of every sequence of text, and its final hidden state contains the aggregate sequence representation for the entire sequence, which is then used for the sequence classification task.
- [SEP]: This token is used to separate one sequence from the next and is needed for Next-Sentence-Prediction (NSP) task. Since aerospace requirements used for this research are single sentences, this token was not used.
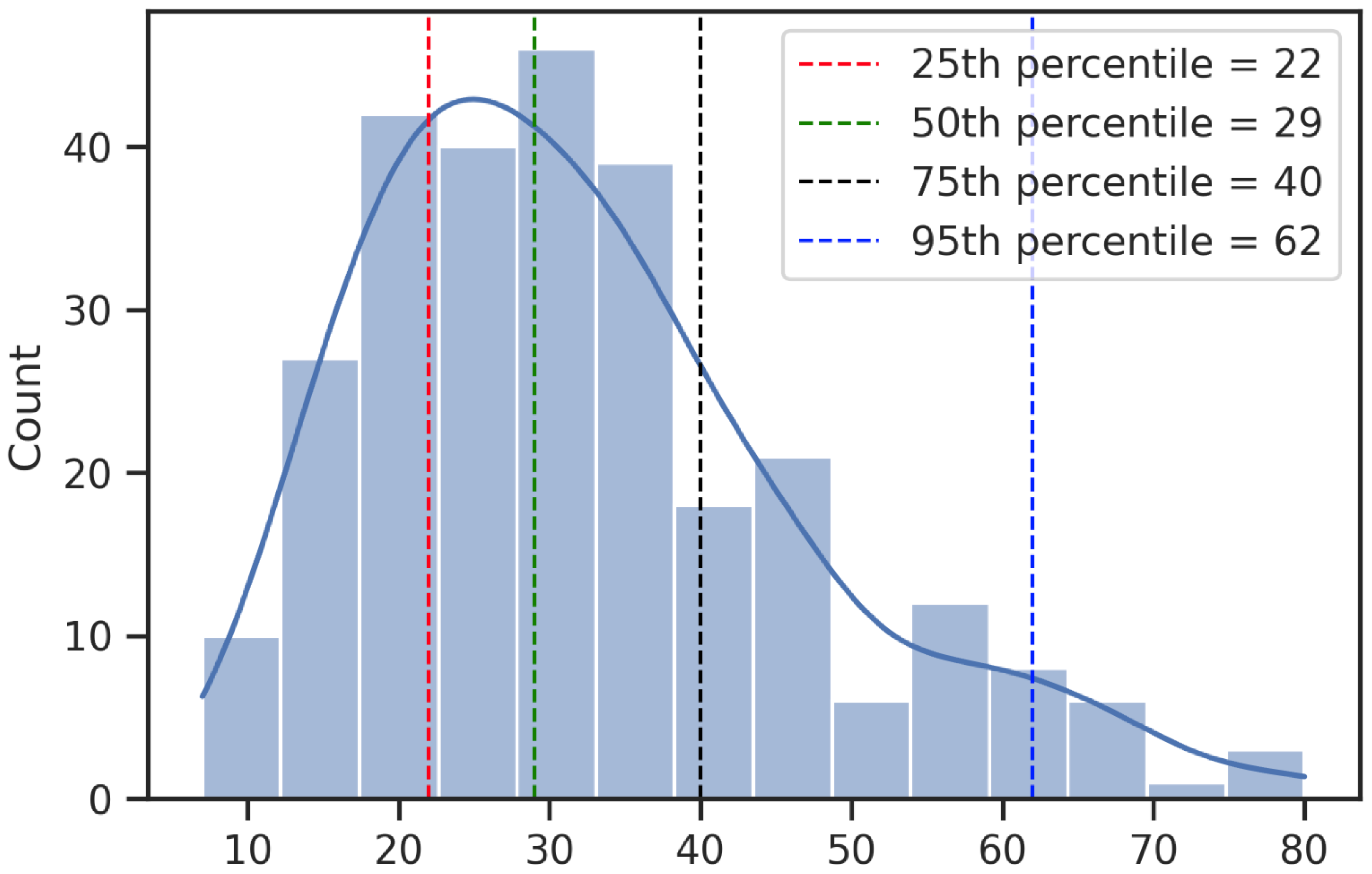
- [PAD]: This token is used to make sure that all the input sequences are of the same length. The maximum length for the input sequences was set to 100 after examining the distribution of lengths of all sequences in the training set (Figure 8). All the sequences with a length less than the set maximum length will be post-padded with [PAD] tokens till the sequence length is equal to the maximum length. The sequences that are longer than 100 will be truncated.
4.3. Fine-Tuning BERT
5. Results
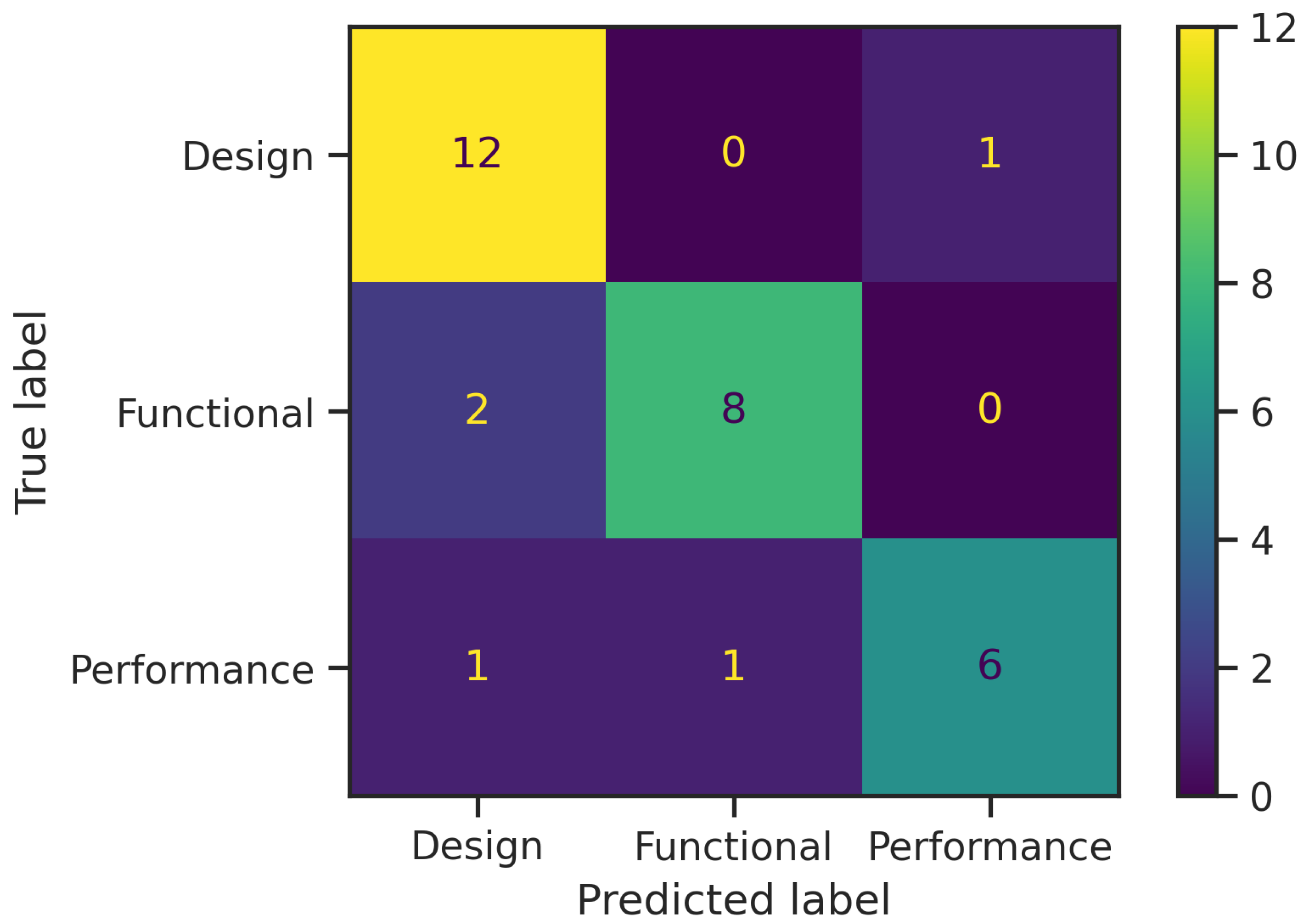
5.1. aeroBERT-Classifier Performance
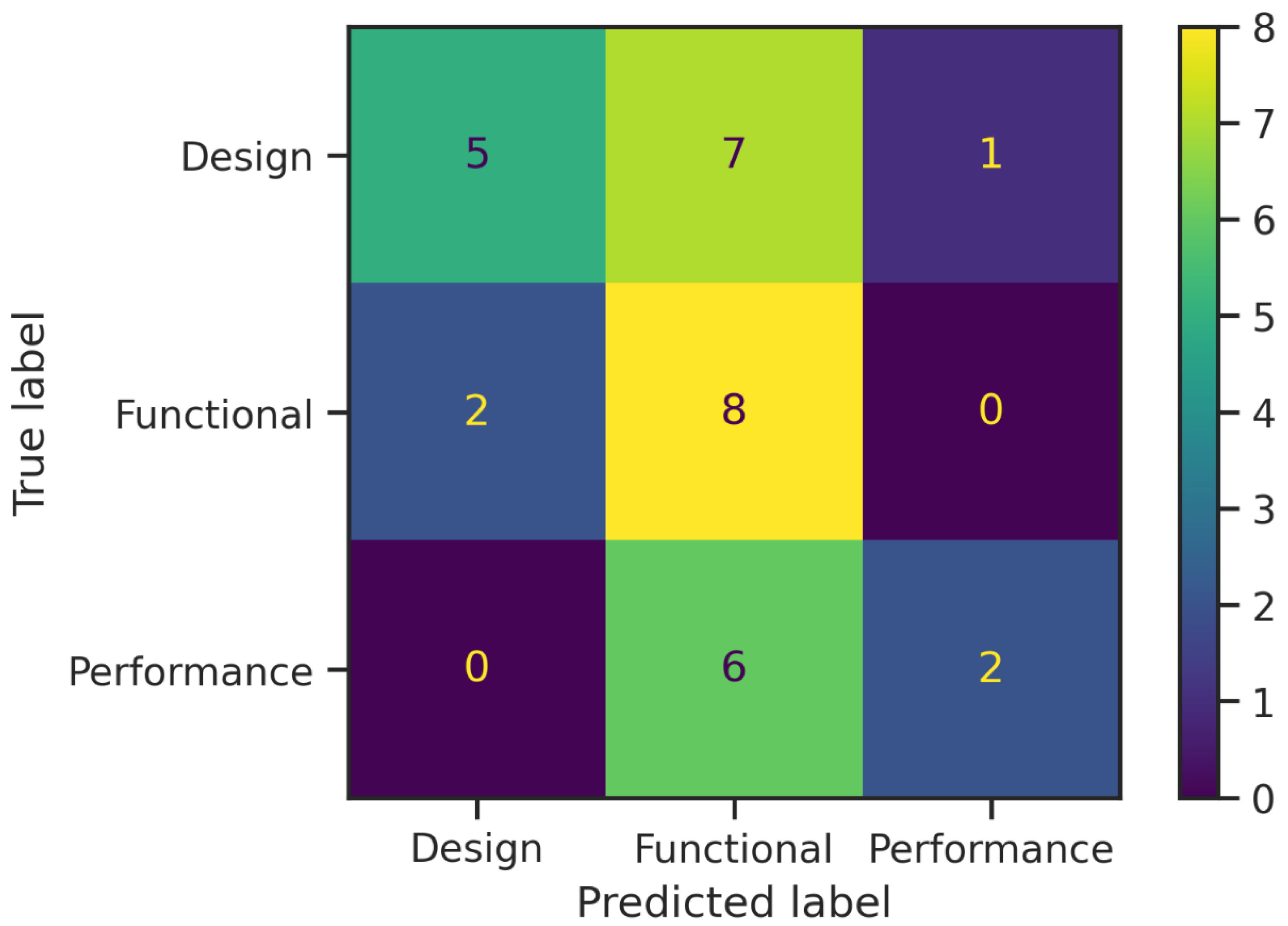
5.2. Comparison between aeroBERT-Classifier and Other Text Classification LMs
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformers |
| CFR | Code of Federal Regulations |
| FAA | Federal Aviation Administration |
| FAR | Federal Aviation Regulations |
| GPT | Generated Pre-trained Transformer |
| INCOSE | International Council on Systems Engineering |
| LM | Language Model |
| LLM | Large Language Model |
| LSTM | Long Short-Term Memory |
| MBSE | Model-Based Systems Engineering |
| MISC | Miscellaneous |
| MNLI | Multi-Genre Natural Language Inference |
| NE | Named Entity |
| NER | Named Entity Recognition |
| NL | Natural Language |
| NLI | Natural Language Inference |
| NLP | Natural Language Processing |
| NLP4RE | Natural Language Processing for Requirements Engineering |
| QFD | Quality Function Deployment |
| RE | Requirements Engineering |
| SME | Subject Matter Expert |
| SOTA | State Of The Art |
| SysML | Systems Modeling Language |
| UML | Unified Modeling Language |
| ZSL | Zero-Shot learning |
References
- BKCASE Editorial Board. Guide to the Systems Engineering Body of Knowledge; INCOSE: San Diego, CA, USA, 2020; p. 945. [Google Scholar]
- INCOSE. INCOSE Infrastructure Working Group Charter. pp. 3–5. Available online: https://www.incose.org/docs/default-source/working-groups/infrastructure-wg-documents/infrastructure_charter-ak-revision-3-feb-12-2019.pdf?sfvrsn=14c29bc6_0 (accessed on 10 January 2023).
- NASA. Appendix C: How to Write a Good Requirement. pp. 115–119. Available online: https://www.nasa.gov/seh/appendix-c-how-to-write-a-good-requirement (accessed on 5 January 2023).
- Firesmith, D. Are your requirements complete? J. Object Technol. 2005, 4, 27–44. [Google Scholar] [CrossRef]
- NASA. 2.1 The Common Technical Processes and the SE Engine. Available online: https://www.nasa.gov/seh/2-1_technical-processes (accessed on 10 January 2023).
- Nuseibeh, B.; Easterbrook, S. Requirements Engineering: A Roadmap. In Proceedings of the Conference on the Future of Software Engineering, Limerick, Ireland, 4–11 June 2000; Association for Computing Machinery: New York, NY, USA, 2000; pp. 35–46. [Google Scholar] [CrossRef] [Green Version]
- Firesmith, D. Common Requirements Problems, Their Negative Consequences, and the Industry Best Practices to Help Solve Them. J. Object Technol. 2007, 6, 17–33. [Google Scholar] [CrossRef] [Green Version]
- Haskins, B.; Stecklein, J.; Dick, B.; Moroney, G.; Lovell, R.; Dabney, J. 8.4. 2 error cost escalation through the project life cycle. In INCOSE International Symposium; Wiley Online Library: Hoboken, NJ, USA, 2004; Volume 14, pp. 1723–1737. [Google Scholar]
- Bell, T.E.; Thayer, T.A. Software requirements: Are they really a problem? In Proceedings of the 2nd International Conference on Software Engineering, San Francisco, CA, USA, 13–15 October 1976; pp. 61–68. [Google Scholar]
- Dalpiaz, F.; Ferrari, A.; Franch, X.; Palomares, C. Natural language processing for requirements engineering: The best is yet to come. IEEE Softw. 2018, 35, 115–119. [Google Scholar] [CrossRef]
- Ramos, A.L.; Ferreira, J.V.; Barceló, J. Model-based systems engineering: An emerging approach for modern systems. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2011, 42, 101–111. [Google Scholar] [CrossRef]
- Estefan, J.A. Survey of model-based systems engineering (MBSE) methodologies. Incose MBSE Focus Group 2007, 25, 1–12. [Google Scholar]
- Jacobson, L.; Booch, J.R.G. The Unified Modeling Language Reference Manual; Addison-Wesley: Boston, MA, USA, 2021. [Google Scholar]
- Ballard, M.; Peak, R.; Cimtalay, S.; Mavris, D.N. Bidirectional Text-to-Model Element Requirement Transformation. In Proceedings of the 2020 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2020; pp. 1–14. [Google Scholar]
- Lemazurier, L.; Chapurlat, V.; Grossetête, A. An MBSE approach to pass from requirements to functional architecture. IFAC-PapersOnLine 2017, 50, 7260–7265. [Google Scholar] [CrossRef]
- BKCASE Editorial Board. Needs, Requirements, Verification, Validation Lifecycle Manual; INCOSE: San Diego, CA, USA, 2022; p. 457. [Google Scholar]
- Wheatcraft, L.; Ryan, M.; Llorens, J.; Dick, J. The Need for an Information-based Approach for Requirement Development and Management. In Proceedings of the INCOSE International Symposium, Biarrtiz, France, 11–13 September 2019; Wiley Online Library: Hoboken, NJ, USA; Volume 29, pp. 1140–1157. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- FAA. Title 14 Code of Federal Regulations; FAA: Washington, DC, USA, 2023.
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Ferrari, A.; Dell’Orletta, F.; Esuli, A.; Gervasi, V.; Gnesi, S. Natural Language Requirements Processing: A 4D Vision. IEEE Softw. 2017, 34, 28–35. [Google Scholar] [CrossRef]
- Abbott, R.J.; Moorhead, D. Software requirements and specifications: A survey of needs and languages. J. Syst. Softw. 1981, 2, 297–316. [Google Scholar] [CrossRef]
- Luisa, M.; Mariangela, F.; Pierluigi, N.I. Market research for requirements analysis using linguistic tools. Requir. Eng. 2004, 9, 40–56. [Google Scholar] [CrossRef] [Green Version]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; Association for Computational Linguistics: Baltimore, MD, USA, 2014; pp. 55–60. [Google Scholar] [CrossRef] [Green Version]
- Natural Language Toolkit. Available online: https://www.nltk.org/ (accessed on 1 October 2022).
- spaCy. Available online: https://spacy.io/ (accessed on 1 October 2022).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar] [CrossRef]
- Zhao, L.; Alhoshan, W.; Ferrari, A.; Letsholo, K.J.; Ajagbe, M.A.; Chioasca, E.V.; Batista-Navarro, R.T. Natural language processing for requirements engineering: A systematic mapping study. ACM Comput. Surv. (CSUR) 2021, 54, 1–41. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. In Proceedings of the NeurIPS EMC2 Workshop, Vancouver, BC, Canada, 13 December 2019. [Google Scholar]
- Goldberg, Y. Neural network methods for natural language processing. Synth. Lect. Hum. Lang. Technol. 2017, 10, 1–309. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing (Draft). 2021. Available online: https://web.stanford.edu/~jurafsky/slp3/ed3book.pdf (accessed on 1 February 2023).
- Niesler, T.R.; Woodland, P.C. A variable-length category-based n-gram language model. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings, Atlanta, GA, USA, 9 May 1996; IEEE: New York, NY, USA, 1996; Volume 1, pp. 164–167. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P. A Neural Probabilistic Language Model. In Advances in Neural Information Processing Systems; Leen, T., Dietterich, T., Tresp, V., Eds.; MIT Press: Cambridge, MA, USA, 2000; Volume 13. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Graves, A. Generating Sequences With Recurrent Neural Networks. arXiv 2013, arXiv:1308.0850. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the EMNLP, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? In Proceedings of the China National Conference on Chinese Computational Linguistics, Kunming, China, 18–20 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 194–206. [Google Scholar]
- Alammar, J. The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning). Available online: https://jalammar.github.io/illustrated-bert/ (accessed on 1 February 2023).
- Hey, T.; Keim, J.; Koziolek, A.; Tichy, W.F. NoRBERT: Transfer learning for requirements classification. In Proceedings of the 2020 IEEE 28th International Requirements Engineering Conference (RE), Zurich, Switzerland, 31 August–4 September 2020; IEEE: New York, NY, USA, 2020; pp. 169–179. [Google Scholar]
- Dima, A.; Lukens, S.; Hodkiewicz, M.; Sexton, T.; Brundage, M.P. Adapting natural language processing for technical text. Appl. AI Lett. 2021, 2, e33. [Google Scholar] [CrossRef]
- Sharir, O.; Peleg, B.; Shoham, Y. The cost of training nlp models: A concise overview. arXiv 2020, arXiv:2004.08900. [Google Scholar]
- Dai, A.M.; Le, Q.V. Semi-supervised sequence learning. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Peters, M.E.; Ammar, W.; Bhagavatula, C.; Power, R. Semi-supervised sequence tagging with bidirectional language models. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 1756–1765. [Google Scholar] [CrossRef] [Green Version]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding with Unsupervised Learning. 2018. Available online: https://openai.com/research/language-unsupervised (accessed on 1 February 2023).
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 328–339. [Google Scholar] [CrossRef] [Green Version]
- Hugging Face. Available online: https://huggingface.co/ (accessed on 1 October 2022).
- Alammar, J. The Illustrated Transformer. Available online: https://jalammar.github.io/illustrated-transformer/ (accessed on 1 October 2022).
- Cleland-Huang, J.; Mazrouee, S.; Liguo, H.; Port, D. Nfr. Available online: https://doi.org/10.5281/zenodo.268542 (accessed on 1 October 2022).
- Zero-Shot Learning in Modern NLP. Available online: https://joeddav.github.io/blog/2020/05/29/ZSL.html (accessed on 1 October 2022).
- Yin, W.; Hay, J.; Roth, D. Benchmarking Zero-shot Text Classification: Datasets, Evaluation and Entailment Approach. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3914–3923. [Google Scholar] [CrossRef] [Green Version]
- Williams, A.; Nangia, N.; Bowman, S. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers); Association for Computational Linguistics: New Orleans, LA, USA, 2018; p. 1112. [Google Scholar]
- Alhoshan, W.; Zhao, L.; Ferrari, A.; Letsholo, K.J. A Zero-Shot Learning Approach to Classifying Requirements: A Preliminary Study. In Requirements Engineering: Foundation for Software Quality; Gervasi, V., Vogelsang, A., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 52–59. [Google Scholar]
- Tikayat Ray, A.; Pinon-Fischer, O.J.; Mavris, D.N.; White, R.T.; Cole, B.F. aeroBERT-NER: Named-Entity Recognition for Aerospace Requirements Engineering using BERT. In AIAA SCITECH 2023 Forum; American Institute of Aeronautics and Astronautics, Inc.: Reston, VA, USA, 2023. [Google Scholar] [CrossRef]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A pretrained language model for scientific text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 3615–3620. [Google Scholar] [CrossRef]
- Araci, D. Finbert: Financial sentiment analysis with pre-trained language models. arXiv 2019, arXiv:1908.10063. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [Green Version]
- Alsentzer, E.; Murphy, J.R.; Boag, W.; Weng, W.H.; Jin, D.; Naumann, T.; McDermott, M. Publicly available clinical BERT embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 72–78. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.S.; Hsiang, J. Patentbert: Patent classification with fine-tuning a pre-trained bert model. World Pat. Inf. 2020, 61, 101965. [Google Scholar] [CrossRef]
- FAA. Overview—Title 14 of the Code of Federal Regulations (14 CFR); FAA: Washington, DC, USA, 2013.
- Fundamentals of Systems Engineering: Requirements Definition. Available online: https://ocw.mit.edu/courses/16-842-fundamentals-of-systems-engineering-fall-2015/7f2bc41156a04ecb94a6c04546f122af_MIT16_842F15_Ses2_Req.pdf (accessed on 1 October 2022).
- Wheatcraft, L.S. Everything You Wanted to Know About Interfaces, but Were Afraid to Ask. Available online: https://reqexperts.com/wp-content/uploads/2016/04/Wheatcraft-Interfaces-061511.pdf (accessed on 1 February 2023).
- Spacey, J. 11 Examples of Quality Requirements. Available online: https://simplicable.com/new/quality-requirements (accessed on 1 February 2023).
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial No. | Requirements |
|---|---|
| 1 | The product shall be available for use 24 h per day 365 days per year. |
| 2 | The product shall synchronize with the office system every hour. |
| 3 | The system shall let existing customers log into the website with their email address and password in under 5 s. |
| 4 | The product should be able to be used by 90% of novice users on the internet. |
| 5 | The ratings shall be on a scale of 1–10. |
| Serial No. | Name of Resource (Title 14 CFR) |
|---|---|
| 1 | Part 23: Airworthiness Standards: Normal, Utility, Acrobatic and Commuter Airplanes |
| 2 | Part 25: Airworthiness Standards: Transport Category Airplanes |
| 14 CFR §23.2145(a) | Requirements Created |
|---|---|
| Airplanes not certified for aerobatics must: | |
| (1) Have static longitudinal, lateral, and directional stability in normal operations; | Requirement 1: Airplanes not certified for aerobatics must have static longitudinal, lateral, and directional stability in normal operations. |
| (2) Have short dynamic period and Dutch roll stability in normal operations; and | Requirement 2: Airplanes not certified for aerobatics must have short dynamic period and dutch roll stability in normal operations. |
| (3) Provide stable control force feedback throughout the operating envelope. | Requirement 3: Airplanes not certified for aerobatics must provide stable control force feedback throughout the operating envelope. |
| Original Symbol | Modified Text/Symbol | Example |
|---|---|---|
| § | Section | §25.531 → Section 25.531 |
| §§ | Sections | §§25.619 through 25.625 → Sections 25.619 through 25.625 |
| Dot (‘.’) used in section numbers | Dash (‘-’) | Section 25.531 → Section 25–531 |
| Requirement Type | Definition |
|---|---|
| Design | Dictates “how” a system should be designed given certain technical standards and specifications; |
| Example: Trim control systems must be designed to prevent creeping in flight. | |
| Functional | Defines the functions that need to be performed by a system in order to accomplish the desired system functionality; |
| Example: Each cockpit voice recorder shall record voice communications of flight crew members on the flight deck. | |
| Performance | Defines “how well” a system needs to perform a certain function; |
| Example: The airplane must be free from flutter, control reversal, and divergence for any configuration and condition of operation. | |
| Interface | Defines the interaction between systems [67]; |
| Example: Each flight recorder shall be supplied with airspeed data. | |
| Environmental | Defines the environment in which the system must function; |
| Example: The exhaust system, including exhaust heat exchangers for each powerplant or auxiliary power unit, must be designed to prevent likely hazards from heat, corrosion, or blockage. | |
| Quality | Describes the quality, reliability, consistency, availability, usability, maintainability, and materials and ingredients of a system [68]; |
| Example: Internal panes must be made of nonsplintering material. |
| Original Interface Requirement | Modified Requirement Type/Category |
|---|---|
| Each flight recorder shall be supplied with airspeed data. | The airplane shall supply the flight recorder with airspeed data. (Functional Requirement) |
| Each flight recorder shall be supplied with directional data. | The airplane shall supply the flight recorder with directional data. (Functional Requirement) |
| The state estimates supplied to the flight recorder shall meet the aircraft-level system requirements and the functionality specified in Section 23–2500. | The state estimates supplied to the flight recorder shall meet the aircraft level system requirements and the functionality specified in Section 23–2500. (Design Requirement) |
| Requirements | Label |
|---|---|
| Each cockpit voice recorder shall record voice communications transmitted from or received in the airplane by radio. | 1 |
| Each recorder container must be either bright orange or bright yellow. | 0 |
| Single-engine airplanes, not certified for aerobatics, must not have a tendency to inadvertently depart controlled flight. | 2 |
| Each part of the airplane must have adequate provisions for ventilation and drainage. | 0 |
| Each baggage and cargo compartment must have a means to prevent the contents of the compartment from becoming a hazard by impacting occupants or shifting. | 1 |
| Requirement Type | Training Set Count | Test Set Count |
|---|---|---|
| Design (0) | 136 | 13 |
| Functional (1) | 89 | 10 |
| Performance (2) | 54 | 8 |
| Total | 279 | 31 |
| Models | Design | Functional | Performance | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | F1 | |
| aeroBERT-Classifier | 0.91 | 0.77 | 0.83 | 0.83 | 1.0 | 0.91 | 0.75 | 0.75 | 0.75 | 0.83 |
| aeroBERT-Classifier | 0.86 | 0.92 | 0.89 | 0.82 | 0.90 | 0.86 | 0.83 | 0.63 | 0.71 | 0.82 |
| aeroBERT-Classifier | 0.80 | 0.92 | 0.86 | 0.89 | 0.80 | 0.84 | 0.86 | 0.75 | 0.80 | 0.83 |
| aeroBERT-Classifier | 0.79 | 0.85 | 0.81 | 0.80 | 0.80 | 0.80 | 0.86 | 0.75 | 0.80 | 0.80 |
| GPT-2 | 0.67 | 0.60 | 0.63 | 0.67 | 0.67 | 0.67 | 0.70 | 0.78 | 0.74 | 0.68 |
| Bi-LSTM (GloVe) | 0.75 | 0.75 | 0.75 | 0.75 | 0.60 | 0.67 | 0.43 | 0.75 | 0.55 | 0.68 |
| bart-large-mnli | 0.43 | 0.25 | 0.32 | 0.38 | 0.53 | 0.44 | 0.0 | 0.0 | 0.0 | 0.34 |
| Requirements | Actual | Predicted |
|---|---|---|
| The installed powerplant must operate without any hazardous characteristics during normal and emergency operation within the range of operating limitations for the airplane and the engine. | 2 | 1 |
| Each flight recorder must be installed so that it remains powered for as long as possible without jeopardizing the emergency operation of the airplane. | 0 | 2 |
| The microphone must be located and, if necessary, the preamplifiers and filters of the recorder must be adjusted or supplemented so that the intelligibility of the recorded communications is as high as practicable when recorded under flight cockpit noise conditions and played back. | 2 | 0 |
| A means to extinguish a fire within a fire zone, except a combustion heater fire zone, must be provided for any fire zone embedded within the fuselage, which must also include a redundant means to extinguish a fire. | 1 | 0 |
| Thermal/acoustic materials in the fuselage must not be a flame propagation hazard. | 1 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tikayat Ray, A.; Cole, B.F.; Pinon Fischer, O.J.; White, R.T.; Mavris, D.N. aeroBERT-Classifier: Classification of Aerospace Requirements Using BERT. Aerospace 2023, 10, 279. https://doi.org/10.3390/aerospace10030279
Tikayat Ray A, Cole BF, Pinon Fischer OJ, White RT, Mavris DN. aeroBERT-Classifier: Classification of Aerospace Requirements Using BERT. Aerospace. 2023; 10(3):279. https://doi.org/10.3390/aerospace10030279
Chicago/Turabian StyleTikayat Ray, Archana, Bjorn F. Cole, Olivia J. Pinon Fischer, Ryan T. White, and Dimitri N. Mavris. 2023. "aeroBERT-Classifier: Classification of Aerospace Requirements Using BERT" Aerospace 10, no. 3: 279. https://doi.org/10.3390/aerospace10030279