

GRI: General Reinforced Imitation and Its Application to Vision-Based Autonomous Driving

Abstract
:1. Introduction
- Definition of the novel GRI method to combine offline demonstrations and online exploration.
- Presentation and ablation study of GRI for the visual-based Autonomous Driving (GRIAD) algorithm.
- Further analysis of GRI-based algorithms on the Mujoco benchmark.
2. Related Work
2.1. End-to-End Autonomous Driving on CARLA
2.2. Learning from Demonstration and Exploration
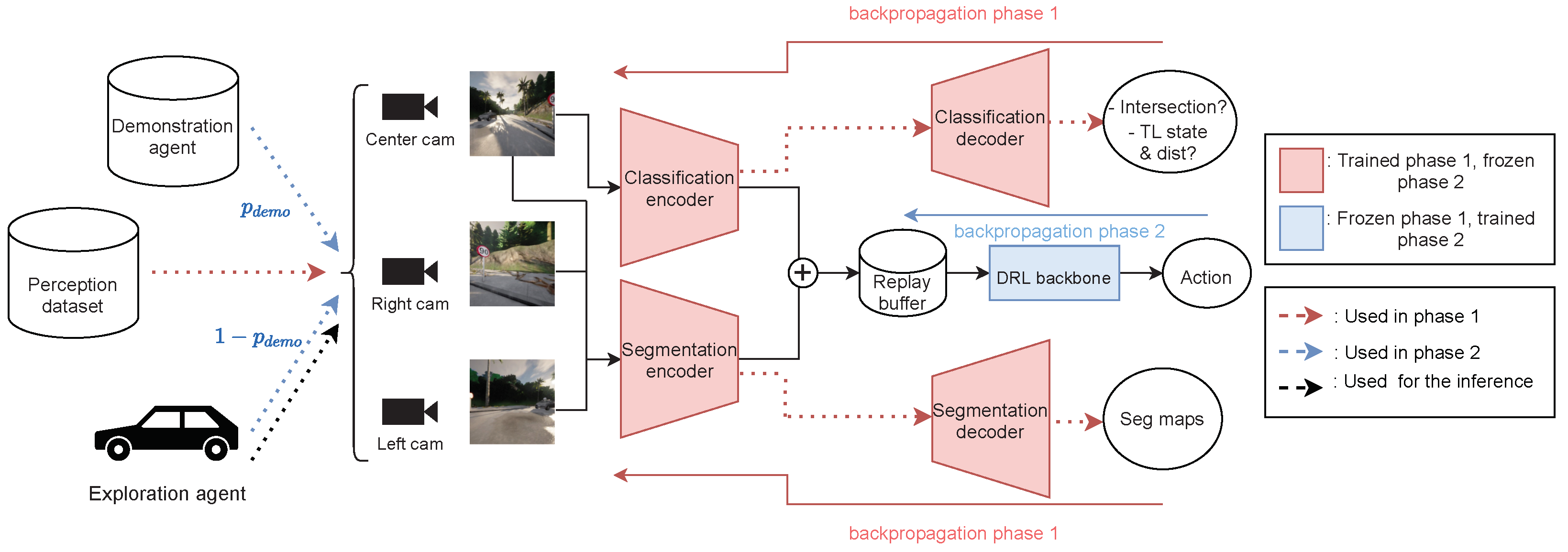
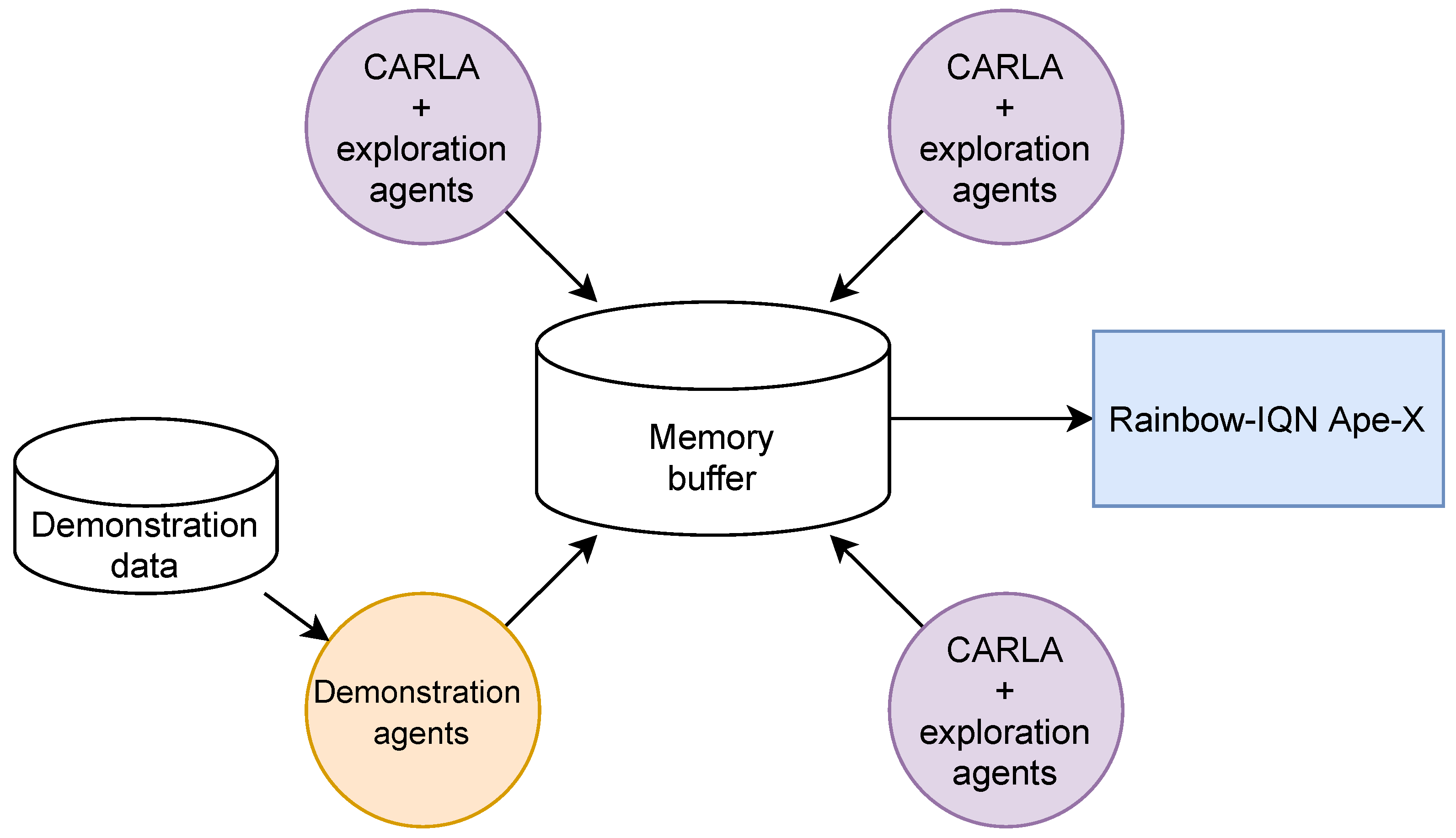
3. General Reinforced Imitation
3.1. Method
| Algorithm 1: GRI: General Reinforced Imitation. |
 |
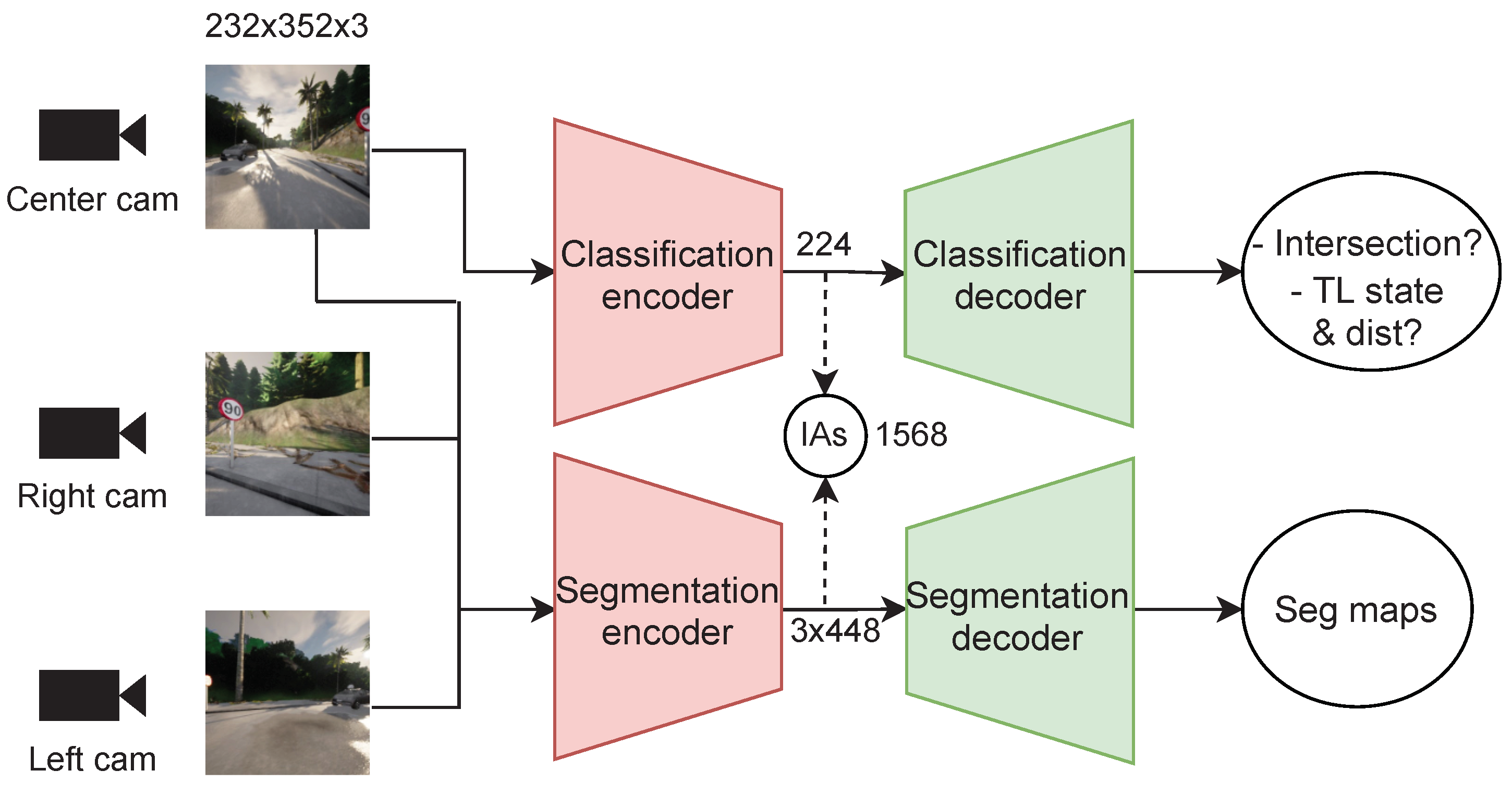
3.2. GRI for Autonomous Driving
4. Experimental Results
4.1. GRIAD on CARLA
4.2. GRI on the Mujoco Benchmark
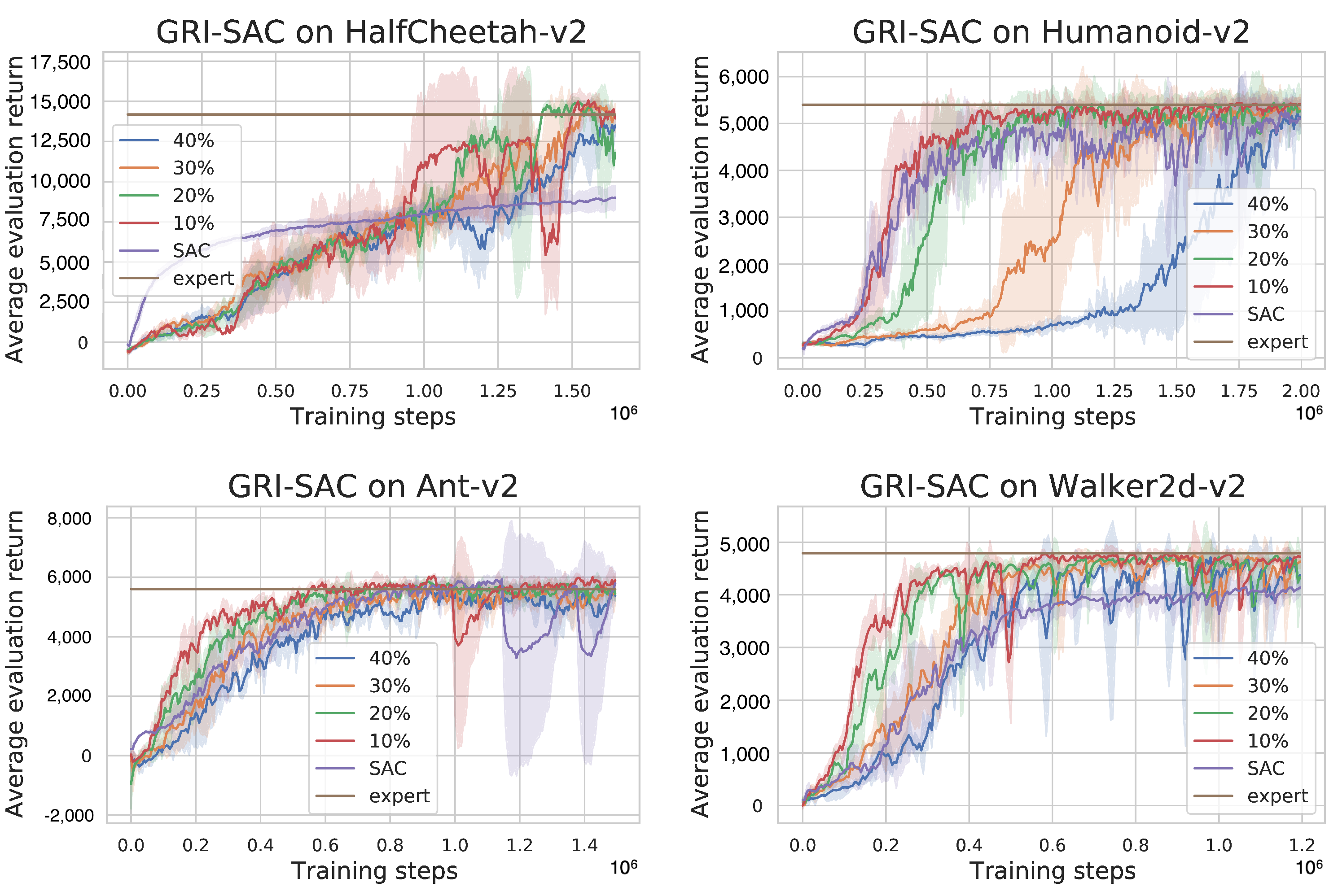
- For HalfCheetah-v2, a difficult task on which the expert is significantly stronger than the trained SAC, we observe that the beginning of the training is slower using GRI-SAC; we call this a warm up phase, which we will explain further in Section 4.3. However, the rewards turns out to become significantly higher after some time. Here, GRI-SAC is better than SAC with every proportion of demonstration agents. The best scores were reached with 10% and 20% of demonstration agents.
- For Humanoid-v2, a difficult task on which the expert is just a little stronger than the trained SAC, we observe that the higher the number of demonstration agents is, the longer the warm up phase is. Nonetheless, GRI-SAC models end up having higher rewards after their warm up phase. The best scores are reached with 10% and 20% of demonstration agents.
- Ant-v2 and Walker2d-v2 are the easiest tasks of the four evaluated. On Ant-v2, the SAC agent reaches the expert level, converging similarly as GRI-SAC regardless of the number of demonstration agents used. Nevertheless, GRI-SAC converges faster with 10% and 20% demonstration agents. On Walker2d-v2, the final reward of GRI-SAC is significantly higher and reaches the expert level, while SAC remains below.
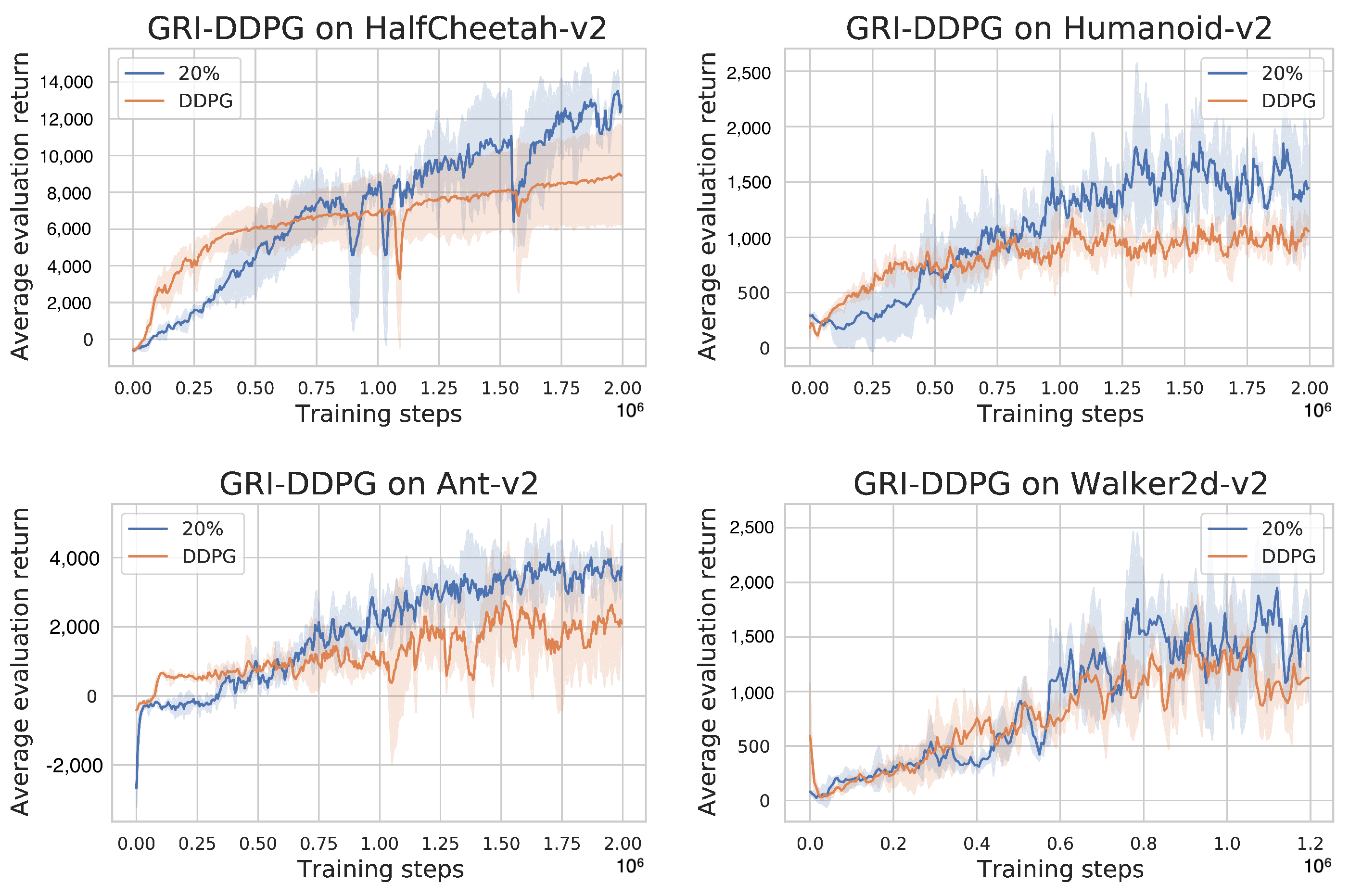
GRI with DDPG as the DRL Backbone
4.3. Limitations and Quantitative Insights
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bojarski, M.; Testa, D.D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to End Learning for Self-Driving Cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Osa, T.; Pajarinen, J.; Neumann, G.; Bagnell, J.A.; Abbeel, P.; Peters, J. An algorithmic perspective on imitation learning. Found. Trends® Robot. 2018, 7, 1–179. [Google Scholar] [CrossRef]
- Prakash, A.; Chitta, K.; Geiger, A. Multi-Modal Fusion Transformer for End-to-End Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Toromanoff, M.; Wirbel, E.; Wilhelm, F.; Vejarano, C.; Perrotton, X.; Moutarde, F. End to End Vehicle Lateral Control Using a Single Fisheye Camera. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3613–3619. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 1587–1596. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the The 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; Volume 48, pp. 1928–1937. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Chen, D.; Koltun, V.; Krähenbühl, P. Learning to drive from a world on rails. In Proceedings of the ICCV, Virtual, 11–17 October 2021. [Google Scholar]
- Codevilla, F.; Santana, E.; Lopez, A.; Gaidon, A. Exploring the Limitations of Behavior Cloning for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9328–9337. [Google Scholar] [CrossRef]
- Todorov, E.; Erez, T.; Tassa, Y. MuJoCo: A physics engine for model-based control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 5026–5033. [Google Scholar] [CrossRef]
- Chen, D.; Zhou, B.; Koltun, V.; Krähenbühl, P. Learning by Cheating. In Proceedings of the Conference on Robot Learning (CoRL), London, UK, 8–11 November 2019. [Google Scholar]
- Gordon, D.; Kadian, A.; Parikh, D.; Hoffman, J.; Batra, D. SplitNet: Sim2Sim and Task2Task Transfer for Embodied Visual Navigation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1022–1031. [Google Scholar] [CrossRef]
- Toromanoff, M.; Wirbel, E.; Moutarde, F. End-to-End Model-Free Reinforcement Learning for Urban Driving Using Implicit Affordances. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, Z.; Liniger, A.; Dai, D.; Yu, F.; Van Gool, L. End-to-End Urban Driving by Imitating a Reinforcement Learning Coach. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021. [Google Scholar]
- Hester, T.; Vecerík, M.; Pietquin, O.; Lanctot, M.; Schaul, T.; Piot, B.; Sendonaris, A.; Dulac-Arnold, G.; Osband, I.; Agapiou, J.P.; et al. Learning from Demonstrations for Real World Reinforcement Learning. arXiv 2017, arXiv:1704.03732. [Google Scholar]
- Reddy, S.; Dragan, A.D.; Levine, S. SQIL: Imitation Learning via Regularized Behavioral Cloning. arXiv 2019, arXiv:1905.11108. [Google Scholar]
- Rajeswaran, A.; Kumar, V.; Gupta, A.; Schulman, J.; Todorov, E.; Levine, S. Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations. arXiv 2017, arXiv:1709.10087. [Google Scholar]
- Martin, J.B.; Chekroun, R.; Moutarde, F. Learning from demonstrations with SACR2: Soft Actor-Critic with Reward Relabeling. arXiv 2021, arXiv:2110.14464. [Google Scholar]
- Xu, D.; Nair, S.; Zhu, Y.; Gao, J.; Garg, A.; Fei-Fei, L.; Savarese, S. Neural Task Programming: Learning to Generalize Across Hierarchical Tasks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3795–3802. [Google Scholar] [CrossRef]
- Gao, Y.; Xu, H.; Lin, J.; Yu, F.; Levine, S.; Darrell, T. Reinforcement Learning from Imperfect Demonstrations. arXiv 2018, arXiv:1802.05313. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Hessel, M.; Modayil, J.; van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.G.; Silver, D. Rainbow: Combining Improvements in Deep Reinforcement Learning. arXiv 2017, arXiv:1710.02298. [Google Scholar] [CrossRef]
- Dabney, W.; Ostrovski, G.; Silver, D.; Munos, R. Implicit Quantile Networks for Distributional Reinforcement Learning. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 1096–1105. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Toromanoff, M.; Wirbel, E.; Moutarde, F. Is Deep Reinforcement Learning Really Superhuman on Atari? In Proceedings of the Deep Reinforcement Learning Workshop of 39th Conference on Neural Information Processing Systems (Neurips’2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Hu, H.; Liu, Z.; Chitlangia, S.; Agnihotri, A.; Zhao, D. Investigating the impact of multi-lidar placement on object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 2550–2559. [Google Scholar]
- Wu, P.; Jia, X.; Chen, L.; Yan, J.; Li, H.; Qiao, Y. Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline. Adv. Neural Inf. Process. Syst. 2022, 35, 6119–6132. [Google Scholar]
- Shao, H.; Wang, L.; Chen, R.; Waslander, S.L.; Li, H.; Liu, Y. ReasonNet: End-to-End Driving with Temporal and Global Reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 13723–13733. [Google Scholar]
- Chen, D.; Krähenbühl, P. Learning from all vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 17222–17231. [Google Scholar]
- Shao, H.; Wang, L.; Chen, R.; Li, H.; Liu, Y. Safety-enhanced autonomous driving using interpretable sensor fusion transformer. In Proceedings of the Conference on Robot Learning, Atlanta, GA, USA, 6–9 November 2023; pp. 726–737. [Google Scholar]
- Fujita, Y.; Nagarajan, P.; Kataoka, T.; Ishikawa, T. ChainerRL: A Deep Reinforcement Learning Library. J. Mach. Learn. Res. 2021, 22, 3557–3570. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Cam. | LiDAR | IMU | DS | RC | IS |
|---|---|---|---|---|---|---|
| GRIAD (ours) | 3 | ✗ | ✗ | 36.79 | 61.85 | 0.60 |
| Rails [10] | 4 | ✗ | ✗ | 31.37 | 57.65 | 0.56 |
| IAs [15] | 1 | ✗ | ✗ | 24.98 | 46.97 | 0.52 |
| TCP [30] | 1 | ✗ | ✓ | 75.13 | 85.53 | 0.87 |
| Latent Transfuser [3] | 3 | ✗ | ✓ | 45.2 | 66.31 | 0.72 |
| LBC [13] | 3 | ✗ | ✓ | 10.9 | 21.3 | 0.55 |
| ReasonNet [31] | 4 | ✓ | ✓ | 79.95 | 89.89 | 0.89 |
| LAV [32] | 4 | ✓ | ✓ | 61.8 | 94.5 | 0.64 |
| InterFuser [33] | 3 | ✓ | ✓ | 76.18 | 88.23 | 0.84 |
| Transfuser+ [3] | 4 | ✓ | ✗ | 50.5 | 73.8 | 0.68 |
| Task | Town, Weather | GRIAD | ||
|---|---|---|---|---|
| Explo. 12 M | Explo. 12 M + Demo. 4 M | Explo. 16 M | ||
| Empty | 96.3 ± 1.5 | 98.0 ± 1.7 | 98.0 ± 1.0 | |
| Regular | train, train | 95.0 ± 2.4 | 98.3 ± 1.7 | 98.6 ± 1.2 |
| Dense | 91.7 ± 2.0 | 93.7 ± 1.7 | 95.0 ± 1.6 | |
| Empty | 83.3 ± 3.7 | 94.0 ± 1.6 | 96.3 ± 1.7 | |
| Regular | test, train | 82.6 ± 3.7 | 93.0 ± 0.8 | 96.3 ± 2.5 |
| Dense | 61.6 ± 2.0 | 77.7 ± 4.5 | 78.0 ± 2.8 | |
| Empty | 67.3 ± 1.9 | 83.3 ± 2.5 | 73.3 ± 2.5 | |
| Regular | train, test | 76.7 ± 2.5 | 86.7 ± 2.5 | 81.3 ± 2.5 |
| Dense | 67.3 ± 2.5 | 82.6 ± 0.9 | 80.0 ± 1.6 | |
| Empty | 60.6 ± 2.5 | 68.7 ± 0.9 | 62.0 ± 1.6 | |
| Regular | test, test | 59.3 ± 2.5 | 63.3 ± 2.5 | 56.7 ± 3.4 |
| Dense | 40.0 ± 1.6 | 52.0 ± 4.3 | 46.0 ± 3.3 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chekroun, R.; Toromanoff, M.; Hornauer, S.; Moutarde, F. GRI: General Reinforced Imitation and Its Application to Vision-Based Autonomous Driving. Robotics 2023, 12, 127. https://doi.org/10.3390/robotics12050127
Chekroun R, Toromanoff M, Hornauer S, Moutarde F. GRI: General Reinforced Imitation and Its Application to Vision-Based Autonomous Driving. Robotics. 2023; 12(5):127. https://doi.org/10.3390/robotics12050127
Chicago/Turabian StyleChekroun, Raphael, Marin Toromanoff, Sascha Hornauer, and Fabien Moutarde. 2023. "GRI: General Reinforced Imitation and Its Application to Vision-Based Autonomous Driving" Robotics 12, no. 5: 127. https://doi.org/10.3390/robotics12050127