
FastMimic: Model-Based Motion Imitation for Agile, Diverse and Generalizable Quadrupedal Locomotion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. Motion Imitation
2.2. Model-Based Legged Locomotion Control
2.3. Dynamic Movement Primitives (DMPs)
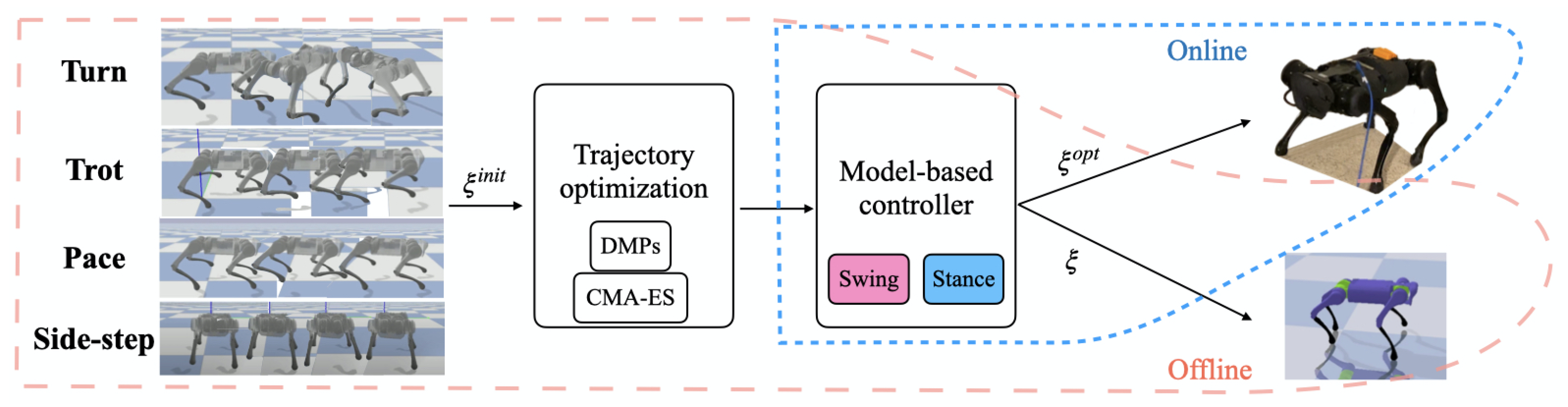
3. Model-Based Control for Motion Imitation
3.1. Motion Retargeting
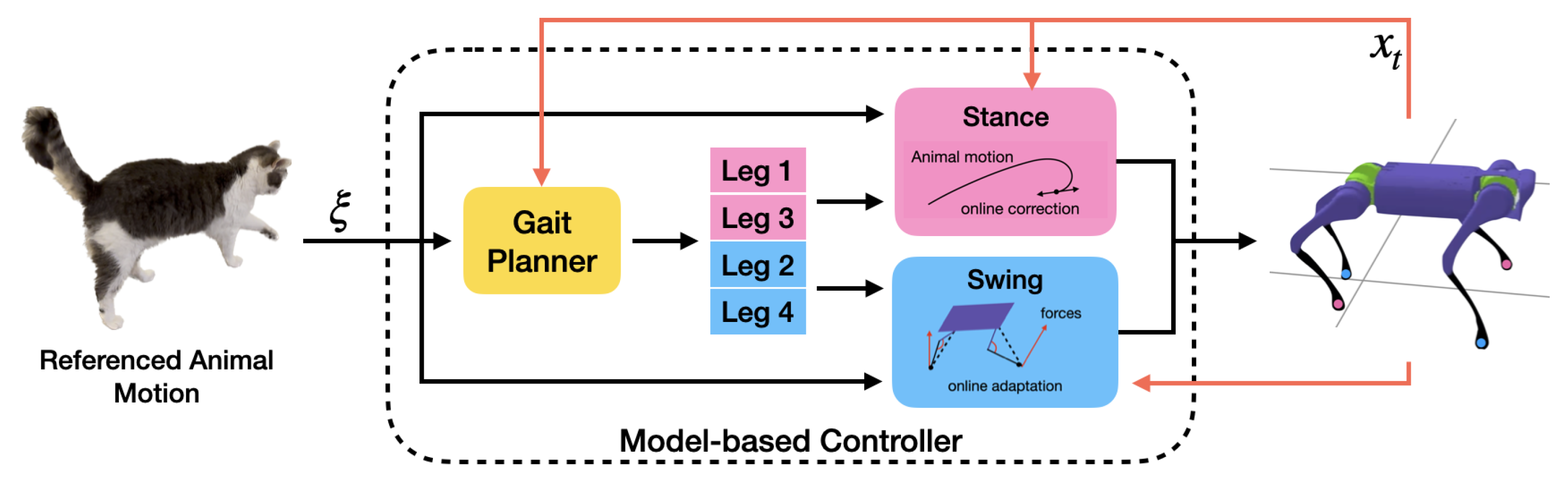
3.2. Model-Based Controller
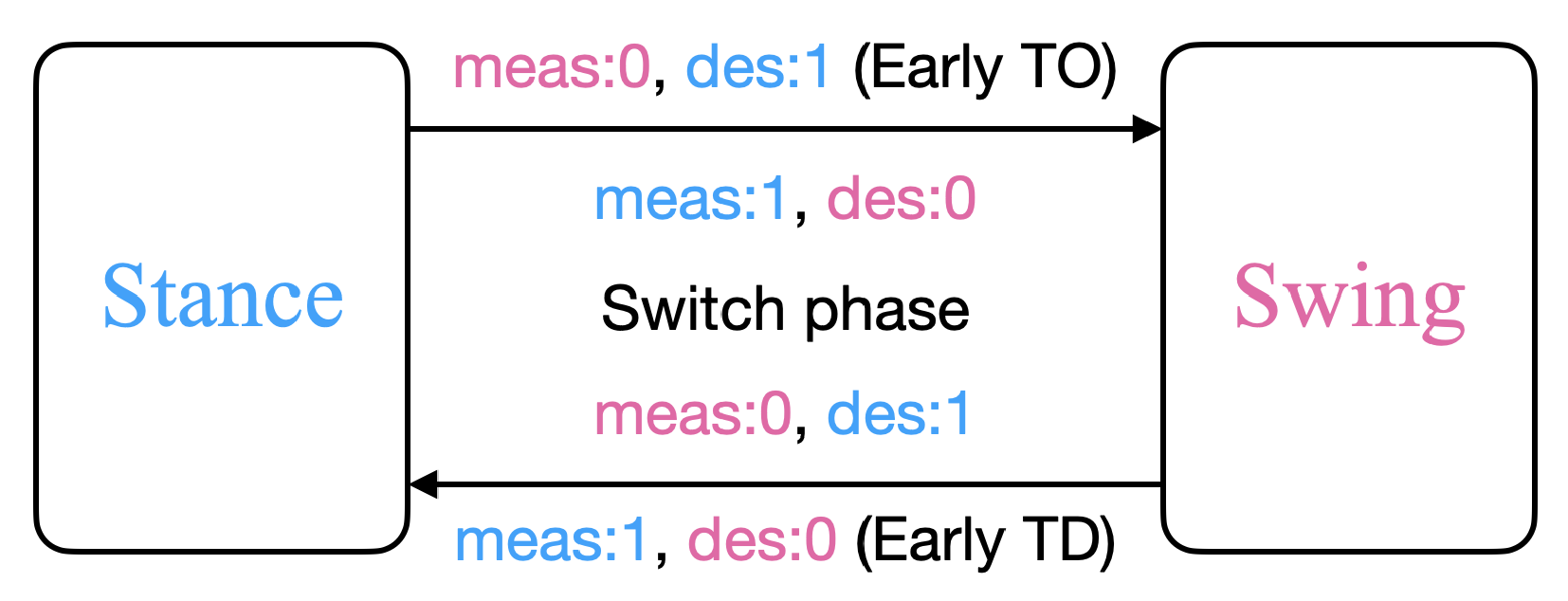
3.2.1. Gait Planner
3.2.2. Stance Controller
3.2.3. Swing Controller
3.3. Trajectory Optimization with DMPs
4. Experiment
4.1. Reward Function
- Joint pose reward ,
- Joint velocity reward ,
- End-effector reward ,
- CoM position reward ,
- CoM velocity reward .
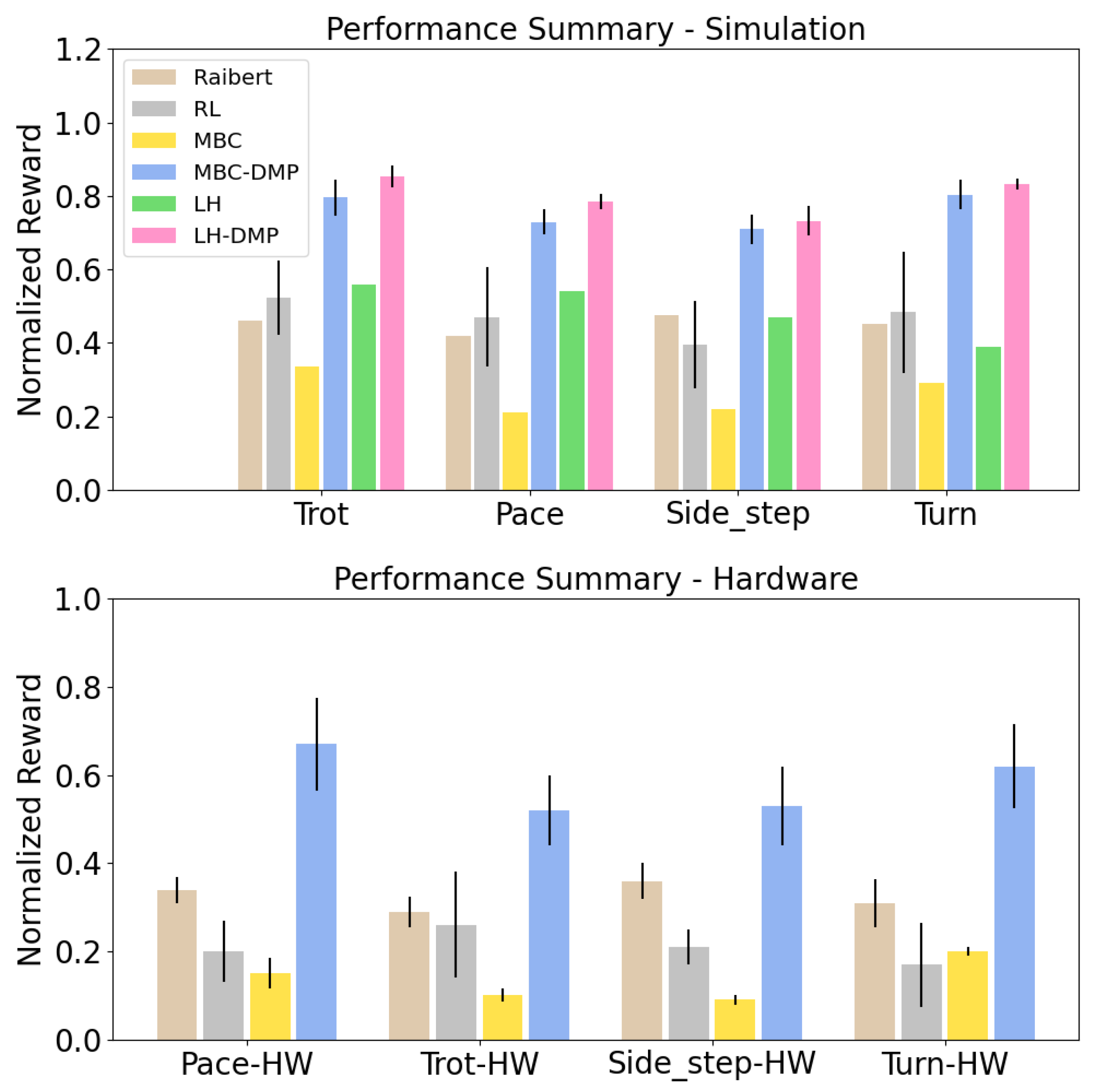
4.2. Comparison Experiments
- DeepMimic (RL): We compare our approach against DeepMimic [1], a learning-based approach that learns an RL policy per reference motion. We use the reward function described in Section 4.1 and train each policy for 100 million simulation steps using Proximal Policy Optimization [48]. We use the open-source implementation to train policies for trot, pace, turn, and side-step motions. For each target motion, we train two RL policies with different random seeds and report average performance in Figure 4. We apply policies learned in simulation to hardware with no fine-tuning to make the comparison fair to our approach.
- Model-based Controller with Raibert Swing (Raibert): Next, we compare our method against a model-based method from Kang et al. [15] which uses animal reference for CoM motion, but uses linear swing trajectories of fixed time length that reach a footstep calculated using the Raibert heuristic: . Compared to Equation (3), we note that this method does not take the animal motion into account, while our approach augments the animal motion with a stabilizing feedback mechanism. Because each gait has unique swing foot motion style, using pre-defined swing trajectories could cause difficulties when reproducing natural and diverse motion styles.
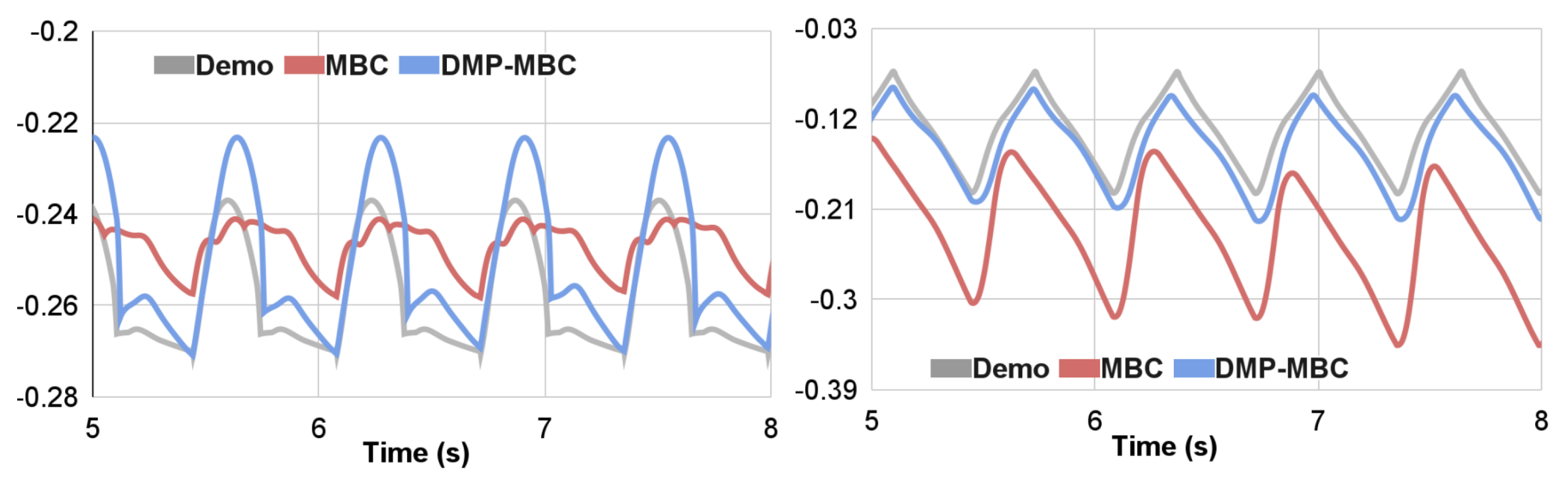
- Model-based Controller (MBC): In this baseline, we send the animal motion trajectories to our model-based controller without any trajectory optimization. This experiment highlights the importance of whole-body trajectory optimization in simulation.
- Model-based Controller with DMP Optimization (MBC-DMP, ours): Our approach, which uses offline trajectory optimization to adapt the reference motion sent to the model-based controller.
- Long horizon Model-predictive control (LH): Whole-body control of quadrupedal robots can be improved by using a receding-horizon model predictive control approach that plans over multiple time steps, instead of instantaneous forces, as in Equation (1). We utilize the approach from Di et al. [5] to solve a higher-order QP to plan actions over a horizon of 10 steps, instead of a single step. During stance, this long-horizon convex MPC controller uses the linearized centroidal model to predict future states, and plans a sequence of contact forces that lead to a desired CoM trajectory. For swing control, we use the same setup as ours. This experiment aims to test if online MPC can replace offline trajectory optimization.
- Long horizon MPC with DMP Optimization (LH-DMP): Lastly, we augment the long horizon model-predictive control (LH) with our DMP-based trajectory optimization (LH-DMP). We expect that this method outperforms our method because it reasons over a longer horizon of the reference motion. However, both long-horizon predictive control methods, LH and LH-DMP, cannot easily be deployed to hardware due to their expensive computational costs. Therefore, we only conduct simulation experiments for analysis.

4.3. Motion Stitching
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Peng, X.B.; Abbeel, P.; Levine, S.; van de Panne, M. Deepmimic: Example-guided deep reinforcement learning of physics-based character skills. ACM Trans. Graph. (TOG) 2018, 37, 143. [Google Scholar] [CrossRef] [Green Version]
- Peng, X.B.; Coumans, E.; Zhang, T.; Lee, T.W.; Tan, J.; Levine, S. Learning agile robotic locomotion skills by imitating animals. arXiv 2020, arXiv:2004.00784. [Google Scholar]
- Park, H.W.; Wensing, P.M.; Kim, S. High-speed bounding with the MIT Cheetah 2: Control design and experiments. Int. J. Robot. Res. 2017, 36, 167–192. [Google Scholar] [CrossRef] [Green Version]
- Bledt, G.; Powell, M.J.; Katz, B.; Di Carlo, J.; Wensing, P.M.; Kim, S. MIT Cheetah 3: Design and control of a robust, dynamic quadruped robot. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2245–2252. [Google Scholar]
- Di Carlo, J.; Wensing, P.M.; Katz, B.; Bledt, G.; Kim, S. Dynamic locomotion in the mit cheetah 3 through convex model-predictive control. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar]
- Park, S.; Ryu, H.; Lee, S.; Lee, S.; Lee, J. Learning Predict-and-simulate Policies from Unorganized Human Motion Data. ACM Trans. Graph. (TOG) 2019, 38, 205. [Google Scholar] [CrossRef] [Green Version]
- Bergamin, K.; Clavet, S.; Holden, D.; Forbes, J.R. DReCon: Data-driven Responsive Control of Physics-based Characters. ACM Trans. Graph. (TOG) 2019, 38, 206. [Google Scholar] [CrossRef] [Green Version]
- Won, J.; Gopinath, D.; Hodgins, J. A scalable approach to control diverse behaviors for physically simulated characters. ACM Trans. Graph. (TOG) 2020, 39, 33. [Google Scholar] [CrossRef]
- Fussell, L.; Bergamin, K.; Holden, D. SuperTrack: Motion tracking for physically simulated characters using supervised learning. ACM Trans. Graph. (TOG) 2021, 40, 197. [Google Scholar] [CrossRef]
- Holden, D.; Komura, T.; Saito, J. Phase-functioned neural networks for character control. ACM Trans. Graph. (TOG) 2017, 36, 42. [Google Scholar] [CrossRef] [Green Version]
- Ijspeert, A.J.; Nakanishi, J.; Hoffmann, H.; Pastor, P.; Schaal, S. Dynamical movement primitives: Learning attractor models for motor behaviors. Neural Comput. 2013, 25, 328–373. [Google Scholar] [CrossRef] [Green Version]
- Hansen, N. The CMA evolution strategy: A comparing review. Towards a New Evolutionary Computation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006; pp. 75–102. [Google Scholar]
- Raibert, M.H. Legged Robots That Balance; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Unitree Robotics. Available online: http://www.unitree.cc/ (accessed on 3 March 2023).
- Kang, D.; Zimmermann, S.; Coros, S. Animal Gaits on Quadrupedal Robots Using Motion Matching and Model Based Control. In Proceedings of the IROS, Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]
- Won, J.; Lee, J. Learning Body Shape Variation in Physics-based Characters. ACM Trans. Graph. (TOG) 2019, 38. [Google Scholar] [CrossRef] [Green Version]
- Merel, J.; Tassa, Y.; TB, D.; Srinivasan, S.; Lemmon, J.; Wang, Z.; Wayne, G.; Heess, N. Learning human behaviors from motion capture by adversarial imitation. arXiv 2017, arXiv:1707.02201. [Google Scholar]
- Merel, J.; Hasenclever, L.; Galashov, A.; Ahuja, A.; Pham, V.; Wayne, G.; Teh, Y.W.; Heess, N. Neural Probabilistic Motor Primitives for Humanoid Control. In Proceedings of the ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Xie, Z.; Berseth, G.; Clary, P.; Hurst, J.; van de Panne, M. Feedback Control for Cassie with Deep Reinforcement Learning. In Proceedings of the IROS, Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Luo, Y.S.; Soeseno, J.H.; Chen, T.P.C.; Chen, W.C. CARL: Controllable Agent with Reinforcement Learning for Quadruped Locomotion. ACM Trans. Graph. (TOG) 2020, 39, 38. [Google Scholar] [CrossRef]
- Exarchos, I.; Jiang, Y.; Yu, W.; Liu, C.K. Policy Transfer via Kinematic Domain Randomization and Adaptation. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Schwind, W.J. Spring Loaded Inverted Pendulum Running: A Plant Model; University of Michigan: Ann Arbor, MI, USA, 1998. [Google Scholar]
- Green, K.; Godse, Y.; Dao, J.; Hatton, R.L.; Fern, A.; Hurst, J. Learning Spring Mass Locomotion: Guiding Policies with a Reduced-Order Model. IEEE RAL 2021, 6, 3926–3932. [Google Scholar] [CrossRef]
- Gong, Y.; Grizzle, J. Angular momentum about the contact point for control of bipedal locomotion: Validation in a lip-based controller. arXiv 2020, arXiv:2008.10763. [Google Scholar]
- Li, T.; Geyer, H.; Atkeson, C.G.; Rai, A. Using deep reinforcement learning to learn high-level policies on the atrias biped. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA 2019), Montreal, QC, Canada, 20–24 May 2019; pp. 263–269. [Google Scholar]
- Kim, D.; Di Carlo, J.; Katz, B.; Bledt, G.; Kim, S. Highly dynamic quadruped locomotion via whole-body impulse control and model predictive control. arXiv 2019, arXiv:1909.06586. [Google Scholar]
- Xie, Z.; Da, X.; Babich, B.; Garg, A.; van de Panne, M. GLiDE: Generalizable Quadrupedal Locomotion in Diverse Environments with a Centroidal Model. arXiv 2021, arXiv:2104.09771. [Google Scholar]
- Da, X.; Xie, Z.; Hoeller, D.; Boots, B.; Anandkumar, A.; Zhu, Y.; Babich, B.; Garg, A. Learning a contact-adaptive controller for robust, efficient legged locomotion. arXiv 2020, arXiv:2009.10019. [Google Scholar]
- Li, T.; Calandra, R.; Pathak, D.; Tian, Y.; Meier, F.; Rai, A. Planning in Learned Latent Action Spaces for Generalizable Legged Locomotion. IEEE Robot. Autom. Lett. 2021, 6, 2682–2689. [Google Scholar] [CrossRef]
- Kormushev, P.; Calinon, S.; Caldwell, D.G. Robot motor skill coordination with EM-based reinforcement learning. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 3232–3237. [Google Scholar]
- Mülling, K.; Kober, J.; Kroemer, O.; Peters, J. Learning to select and generalize striking movements in robot table tennis. Int. J. Robot. Res. 2013, 32, 263–279. [Google Scholar] [CrossRef] [Green Version]
- Ude, A.; Gams, A.; Asfour, T.; Morimoto, J. Task-specific generalization of discrete and periodic dynamic movement primitives. IEEE Trans. Robot. 2010, 26, 800–815. [Google Scholar] [CrossRef] [Green Version]
- Conkey, A.; Hermans, T. Active learning of probabilistic movement primitives. In Proceedings of the Humanoids, Toronto, ON, Canada, 15–17 October 2019; pp. 1–8. [Google Scholar]
- Kober, J.; Peters, J. Learning motor primitives for robotics. In Proceedings of the ICRA, Paris, France, 7–10 December 2009; pp. 2112–2118. [Google Scholar]
- Pastor, P.; Kalakrishnan, M.; Chitta, S.; Theodorou, E.; Schaal, S. Skill learning and task outcome prediction for manipulation. In Proceedings of the Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 3828–3834. [Google Scholar]
- Rai, A.; Sutanto, G.; Schaal, S.; Meier, F. Learning feedback terms for reactive planning and control. In Proceedings of the Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2184–2191. [Google Scholar]
- Stulp, F.; Sigaud, O. Path integral policy improvement with covariance matrix adaptation. arXiv 2012, arXiv:1206.4621. [Google Scholar]
- Bahl, S.; Mukadam, M.; Gupta, A.; Pathak, D. Neural dynamic policies for end-to-end sensorimotor learning. arXiv 2020, arXiv:2012.02788. [Google Scholar]
- Jalics, L.; Hemami, H.; Zheng, Y.F. Pattern generation using coupled oscillators for robotic and biorobotic adaptive periodic movement. In Proceedings of the Robotics and Automation (ICRA), Albuquerque, NW, USA, 20–25 April 1997. [Google Scholar]
- Kajita, S.; Kanehiro, F.; Kaneko, K.; Fujiwara, K.; Yokoi, K.; Hirukawa, H. A realtime pattern generator for biped walking. In Proceedings of the Robotics and Automation (ICRA), Washington, DC, USA, 11–15 May 2002; Volume 1, pp. 31–37. [Google Scholar]
- Yang, J.F.; Lam, T.; Pang, M.Y.; Lamont, E.; Musselman, K.; Seinen, E. Infant stepping: A window to the behaviour of the human pattern generator for walking. Can. J. Physiol. Pharmacol. 2004, 82, 662–674. [Google Scholar] [CrossRef]
- Ijspeert, A.J. Central pattern generators for locomotion control in animals and robots: A review. Neural Netw. 2008, 21, 642–653. [Google Scholar] [CrossRef]
- Rosado, J.; Silva, F.; Santos, V. Adaptation of Robot Locomotion Patterns with Dynamic Movement Primitives. In Proceedings of the 2015 IEEE International Conference on Autonomous Robot Systems and Competitions, Vila Real, Portugal, 8–10 April 2015; pp. 23–28. [Google Scholar] [CrossRef]
- Schaller, N.U.; Herkner, B.; Villa, R.; Aerts, P. The intertarsal joint of the ostrich (Struthio camelus): Anatomical examination and function of passive structures in locomotion. J. Anat. 2009, 214, 830–847. [Google Scholar] [CrossRef] [PubMed]
- Wu, A.; Geyer, H. The 3-D spring–mass model reveals a time-based deadbeat control for highly robust running and steering in uncertain environments. IEEE TRO 2013, 29, 1114–1124. [Google Scholar] [CrossRef]
- Zhang, H.; Starke, S.; Komura, T.; Saito, J. Mode-adaptive neural networks for quadruped motion control. ACM Trans. Graph. (TOG) 2018, 37, 145. [Google Scholar] [CrossRef] [Green Version]
- Coumans, E.; Bai, Y. PyBullet. 2016–2019. Available online: http://pybullet.org (accessed on 3 March 2023).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Won, J.; Cho, J.; Ha, S.; Rai, A. FastMimic: Model-Based Motion Imitation for Agile, Diverse and Generalizable Quadrupedal Locomotion. Robotics 2023, 12, 90. https://doi.org/10.3390/robotics12030090
Li T, Won J, Cho J, Ha S, Rai A. FastMimic: Model-Based Motion Imitation for Agile, Diverse and Generalizable Quadrupedal Locomotion. Robotics. 2023; 12(3):90. https://doi.org/10.3390/robotics12030090
Chicago/Turabian StyleLi, Tianyu, Jungdam Won, Jeongwoo Cho, Sehoon Ha, and Akshara Rai. 2023. "FastMimic: Model-Based Motion Imitation for Agile, Diverse and Generalizable Quadrupedal Locomotion" Robotics 12, no. 3: 90. https://doi.org/10.3390/robotics12030090