4.3. Experimental Results
Victoria Park Dataset is a stereo camera recorded dataset using the UniSA MAV. This dataset has been recorded from different geo-positions and altitudes, as shown in
Figure 5. The recorded sequence consists of many loops from different altitudes and orientations, making the dataset more realistic for evaluating a vision-based robotic system in 3D space. The dataset consists of stereo camera sequence, GPS, Baro, IMU, Compass, and other sensor data. This dataset has different challenges, such that patterns are mostly repetitive with grass, trees, and distant house-like objects. Moreover, the MAV pose changes rapidly, causing the different angles of view for the same scene, which puts the place recognition system into a challenge. The data was recorded just before sunset, so various light conditions combine sunny and shaded areas in the image sequence. As it is a MAV recorded dataset, half of each frame is mainly covered by the sky. The rest of the frame is covered by primarily repetitive patterns as there are many loops in the dataset from different directions that a visual place recognition system can utilise.
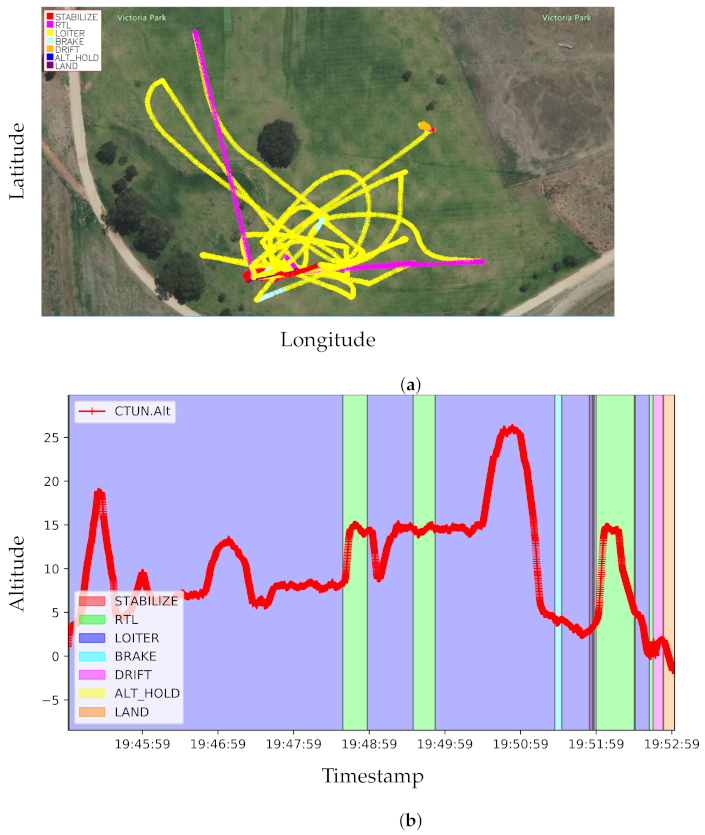
Figure 6 shows the recorded dataset’s latitude, longitude, and altitude. The background colour of each plot shows different flight modes, as shown in the legends. A few flight modes have been used for the dataset recording, Stabilize, RTL, Loiter, Brake, Drift, Alt Hold (altitude hold), and Land. The Stabilize mode attempts to self-level the roll and pitch axis of the MAV during the flight. The RTL mode (Return To Launch mode) navigates the MAV from its current position to the home position. The Loiter mode automatically attempts to maintain the current Global Positioning System (GPS) location, heading and altitude. The Brake mode stops the MAV as soon as possible once it is triggered. The dataset is mostly recorded with Loiter flight mode. It is shown in
Figure 5a how the geo-position changed when the dataset was recorded. The varied geo-positions and altitude affect the performance of the visual place recognition systems which has been discussed in the later part of the experimental results.
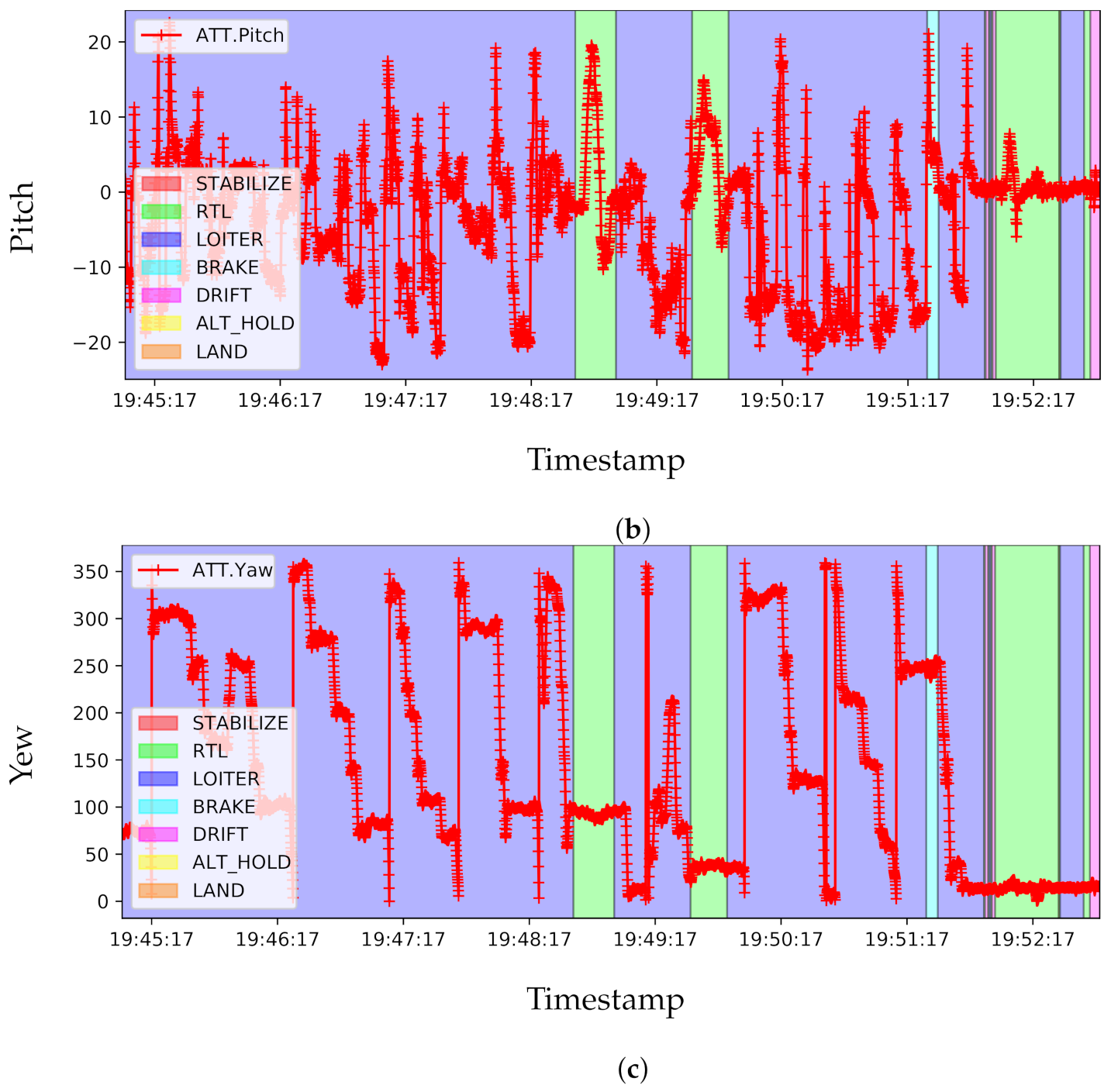
An excellent visual place recognition system should recognise a place from a different angle of view for the same scene. A different angle of view can be correlated with camera position and orientation as any 3D world points can be viewed by the appropriate translation and orientation of the camera facing to that point. Hence, our MAV-recorded Victoria Park dataset has been recorded with varied orientations and positions of a scene to challenge any VPR systems. Alongside the stereo camera sequence, Inertial Measurement Unit (IMU) data from three multiple sensors have also been captured in the Victoria Park dataset. Later Extended Kalman Filter (EKF) is used to fuse all the data from different parallel sensors to get a better pose estimation. In
Figure 7, the pose data have been presented in Euler angles (Roll, Pitch, and Yaw), where the Euler angle (in degree) is plotted in the
y-axis for the timestamp in the
x-axis. It is shown later that the visual place recognition systems produce poor results when the pose of the MAV significantly changes for the same scene. All the sensory data of the Victoria Park dataset are synced with a timestamp.
Figure 8 shows the comparison of feature matching from different viewpoints, meaning having different geo-position and orientations with respect to previous frames. The changes in orientation and position of the presented frames are shown in
Figure 6 and
Figure 7. The matching lines are presented in diverging colourmaps, where the green matching lines represent the more confidence level of the corresponding points and blue represents the lower confidence level. In
Figure 8, the left column shows the correspondences using the method by Sarlin [
48], where it can be seen the miss matches of corresponding points in the Victoria Park dataset for its highly repetitive patterns and illumination changes. Conversely, the proposed method produces more accurate and stable matches with significant viewpoint and illumination changes. Most importantly, it avoids less meaningful features like grasses and tree shadows. For this challenging dataset, the proposed method finds a good number of correspondences with high confidence to ensure a correct place recognition.
Figure 9 shows the similarity matrix for different methods on the New College dataset [
46]. The similarity data have been presented in heatmaps, and each subfigure shows the heatmap of the 4024 images. Each pixel of the subfigure shows the similarity score of that candidate compared with the entries in the database. The lighter the image’s pixel intensity, the more similar the image in the database.
Figure 9a shows the ground truth for the New College dataset. It can be seen that the background colour is very plain as the intensity of the comparison is zero. Therefore, the whole plain background has the same similarity score. The dark pixel shows the overlapping high similarity score with the entries. Light background with a highly dark foreground represents a desirable higher singular score. When the background and foreground colours are blended, the place recognition system disregards the place recognition. If
Figure 9b,c are compared considering the above measures, it can be seen that the proposed method produces the best similarity matrix, which is quite close to the ground truth similarity matrix.
Figure 10a illustrates the relationship between precision and recall for a generic system. The recall is presented on the
X-axis and precision on the
Y-axis with a 0.1 step size on both axes. The dot point in the curve represents the precision and recall rate for a certain detection threshold. Less precision means more false-positive predictions by the system. In other words, the system is prone to false predictions if the curve moves downward. Recall, on the other hand, reduces if the false-negative prediction increases. Therefore, if the curve tends to the
Y-axis, the system is prone to more false predictions that are correct in the ground truth.
Figure 10b shows the precision–recall curve in the New College [
46] dataset. The curves have been obtained for different detection thresholds, while other methods achieve a reasonably good result, the proposed method secures as high recall as 75% at 100% precision. As the proposed method utilises 3D geometrical information of the environment, achieving a minimal and sensitive loop-closure detection threshold is possible, which is impossible using other existing techniques.
Comparative results are summarised in
Table 4, where the proposed method has been compared with other state-of-the-art methods on the same datasets. The compared baseline methods are HF-Net [
49], DBoW2 [
13], and FAB-MAP [
5]. The performance of each of the baseline methods has been obtained from experimenting with their open-source implementations. HF-Net by Sarlin [
49] works relatively well in dynamic lighting conditions and achieves better precision and recall accuracy than DBoW2 [
13] and FAB-MAP [
5]. However, the network needs intensive GPU computation costs, and it could reach up to 8 FPS with NVIDIA RTX 3060 GPU. Therefore, the method is not suitable for low-powered robotic applications. On the other hand, the proposed method produces better precision and recall accuracy in most of the datasets except the Malaga [
47] dataset, where Sarlin [
49] achieves a slightly better result than the proposed method. Most importantly, the proposed method obtains significantly better precision and recall accuracy while using less computational resources. The proposed method obtained 65% recall at 100% precision in the City Centre [
5], which is considered one of the most complex datasets in this domain.
The execution time, another important evolution matrix, has been presented in
Table 5. Mean, standard deviation, minimum and maximum time taken by the proposed method have been summarised based on different tasks in the program pipelines. The attention network took 2.85 ms of time for each frame computation and, at most, 5.65 ms for a complex operation. The Jetson AGX Xavier has a 7.2 compute-capable GPU, specifically designed for machine learning, deep learning, and mobile robotics. Therefore, the inference mean-time for each frame reduces significantly as efficiency as approximately 2.8 ms. The sum of the whole program execution time is relatively small, around 23.63 ms; therefore, the system can be run on a real-time system with approximately FPS 48.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}