1. Introduction
Medical image datasets are one of the most important problems facing researchers in the field of machine learning [
1]. The limited amount of medical data comes from the difficulty of capturing it [
2]. With the problem of final ethical approval, the acquisition and labelling of medical images are time-consuming, and considerable effort needs to be spent by both researchers and specialists [
3,
4]. Several studies tried to overcome the dataset scarcity challenge through the famous task in computer vision, a method called data augmentation [
5]. Using classic data augmentation can give a simple extra feature where it involves simple modifications, such as rotation, translation, scaling, and flipping [
6]. On the other hand, some researchers employed innovative techniques for data augmentation to improve the system training process, based on synthesizing high-quality sample images using a generative model known as generative adversarial networks (GANs) [
7,
8,
9].
The GANs involved two networks; the first generates a real image from the input with the help of the noise, and the other discriminates between real and fake (generated by the first network) images. This model has been used in many studies hoping to generate realistic images, especially for medical imaging applications, such as image-to-image translation [
10], image inpainting [
11], segmentation-to-image translation [
12], medical cross-modality translations [
13], and label-to-segmentation translation [
14].
Exploiting the GAN models by researchers led to the creation of cross-modality images, such as a PET scan, which was generated from a CT scan of the abdomen to show the presence of liver lesions. The GAN model of image inpainting has served as inspiration for many studies. Costa et al. [
15] used a fully convolutional network to learn retinal vessel segmentation images. The binary vessel tree was then translated into a new retinal image. By using chest X-ray images, Dai et al. [
16] generated lung and heart image segmentation by training a GAN model. Xu et al. [
17] trained a model to translate brain MRI images into binary segmentation maps for brain tumour images. Nie et al. [
18] trained a patch-based GAN to translate between brain CT and MRI images. As a step of image refinement, they recommended using an auto-context model. Schlegl et al. [
19] trained a GAN model on normal retinal. To detect anomalies in retinal images, the model was tested on normal and abnormal data.
Based on what was mentioned above, the scarcity of data needs to be resolved so that researchers can use it more freely to analyze that data and produce results that serve the scientific process. The latter motivated the authors of this paper to use GAN models with the ability to synthesize real images, increase the existing data, and overcome the problem of lacking data. In this work, high-quality corneal images based on GAN models are synthesized for a specific task of corneal disease diagnosis to improve the clinical decision by introducing different stages and predicted shapes for images with illness. As an illustrated sample of manipulation for the imaging in the cornea, the different stages of keratoconus are, in most cases, unclear in borderlines. From a clinical perspective, overlapping features between stages of keratoconus lead to a controversial approach to treatment. To decide the severity and clinical or surgical procedure of work per patient clinically, considerable evidence is collected from different images per case to reach the final approach. The possibility of studying the effect and weight of this evidence per case is an attractive medical training to produce a final highly medical sensation and observation for the trained physician. In more detail, thinning in pachymetry images with its location, steepening in the inferior or superior position of the tangential mapping, and the isolated land or tongue shape that may appear in elevation front and back maps, with the astigmatism axis and obliqueness of the bowtie, would improve the effectiveness of the final diagnosis.
The cornea, which protects the eye from external substances and helps to control visual focus, is stiff but very sensitive to touch [
20]. There are many corneal disorders, for instance, bullous keratopathy, Cogan syndrome, corneal ulcer, herpes simplex keratitis, herpes zoster ophthalmicus, etc. [
21]. Any disorders in the cornea may cause ripping, discomfort, and dwindling vision clarity and, finally, may lead to blindness. On the other hand, any action on the cornea, such as vision correction, requires a diagnosis of the cornea’s health before treatment [
22]. Clinical decisions on the human cornea require reviewing numerous aspects, and ophthalmologists must handle this revision. Corneal topographical parameters are so extensive that it is difficult for surgeons or ophthalmologists to remember them all and make decisions [
23]. As a consequence, based on deep learning models, we also proposed to build a sophisticated medical system using the original and the generated images (using the GAN model) for diagnosing corneal cases, to aid clinicians in the interpretation of medical images and improve clinical decision-making.
Many researchers used a variety of complex and diverse medical devices to collect data, as well as a variety of diagnostic approaches. Salih and Hussein (2018) used 732 submaps as inputs to the deep learning network; a kind of deep learning technology called the VGG-16 network was utilized to predict corneal abnormalities and normality [
24]. The detection of the keratoconus eyes dataset and recognition of the normal cornea was the focus of a group of authors who used 145 normal cornea cases and 312 keratoconus cases from a database of photographs. As a classification tool, they used support vector machine (SVM) and multilayer perceptron methods. The features were extracted from the input images, then passed to the classifiers [
25]. A group of researchers used a compilation of data from both Placido and Scheimpug as a feature vector. The prototype was tested with and without a posterior corneal surface, and it performed well in both situations. The thickness and posterior characteristics were found to be critical tools for predicting corneal keratoconus and avoiding corneal ectasia surgery in patients with early corneal ectasia disease [
26]. Researchers employed machine learning techniques, such as ANN, SVM, regression analysis, and decision tree algorithms, to identify the disease. The information was gathered from a group of patients; in total, 23 cases of ectasia after LASIK were discovered, as well as 266 stable post-LASIK cases with over a year of follow-up. They concluded that this study method still needed to be validated [
27]. Samer et al. presented a method known as SWFT for diagnosing the corneal image by extracting features from the corneal image using a Wavelet and diagnosing it using an SVM classifier [
28]. In 2021, Samer and his participants designed an LIP algorithm to extract corneal image features, and they evaluated their method using many classifiers. Thus, they could train a system capable of automatically classifying corneal diseases [
22]. We used deep learning techniques in the current study to diagnose corneal diseases. GAN networks were used as a tool to generate realistic corneal images. On the other hand, pre-trained convolutional neural networks (CNN) [
29,
30,
31] are employed in diagnosing corneal diseases, which have recently been used in many medical imaging studies and have been reported to improve performance for a broad range of medical tasks.
This paper has made the following contributions:
(1) Using the GAN model for creating high-quality corneal images from topographical images to solve the scarcity of the cornea dataset.
(2) Examining various transfer learning methods as a based solution for the corneal diagnosis task.
(3) Augmentation of the dataset to be used in training the networks, using the generated synthetic data for improved clinical decisions.
(4) Solving the issue of time consumption that is suffered by deep learning networks.
3. Results
The goal of this research, in which all of the steps have been outlined in detail in Algorithm 1, is to find out to what extent generated data affect the diagnosis of corneal diseases, and how well classifiers can classify them. Therefore, the CGAN model has been trained to deal with data disparities; in other words, each corneal disease’s image generated is separated with high-quality topographical images by using fine-tuning parameters to disband the scarcity of cornea dataset. For clinical decision transfer, learning methods have been exploited, where the augmented dataset is used in training the networks.
| Algorithm 1. Algorithm of the Proposed Method. |
| | Inputs: D:Dataset, img: a cornea’s image which is selected from the D; |
| 1 | GI= Build a model M which generate images from noise and targeting D |
| 2 | For I = 1: CNN classifieres // (MobilenetV2, Resnet50, Xception, ViT, CoaT, and Swin-T) |
| 3 | [accuracy, precision, recall, f1-score] = Calculate metrics [Accuracy, Precision, Recall, F1-score] from GI |
| 4 | End for |
| 5 | [SSIM, MSE, PSNR, FID] = Calculate [SSIM, MSE, PSNR, FID] between an image from GI and D |
| 6 | End |
The results of diagnosing corneal diseases are reported using different types of transfer learning models, such as MobileNetv2, Resnet50, and Xception.
To detect the importance of data generation, as well as its effect on classification tasks, we used the original dataset to train and test each classifier with and without corneal-generated images.
On the other hand, to assess the strength of the synthesis model and its ability to synthesize convergent data in a particular category and divergent from other categories, each classifier was trained on the synthesized data without using the original data. We employed eight-fold cross-validation with case separation at the patient level in all of our experiments and evaluations. The used examples contained the corneal cases (normal or abnormal for each corneal map).
For each batch of data images, we trained the network and assessed the outcomes individually. The CGAN architecture is used to train each corneal-case class separately, utilizing the same eight-fold cross-validation method and data split. Following training, the generator is capable of creating realistic corneal case images separately using a vector of noise formed by uniform distributions (see
Figure 3). Accordingly, the model synthesized eight different cases of corneal images: normal and abnormal cases for sagittal, corneal thickness, elevation front, and elevation back images.
We employed two main kinds of metrics in our research. First, we used observational error metrics such as accuracy, precision, recall, and F1-score metrics to evaluate classification accuracy (Equations (2), (3), (4), and (5), respectively). Second, we used Equations (6) and (7) to evaluate the synthesized image’s quality with the original images via the structural similarity index method (SSIM) [
48] and the peak signal-to-noise ratio (PSNR) [
49].
where
TP = true positives,
TN = true negatives,
FP = false positives, and
FN = false negatives.
Structural similarity (SSIM) [
48] is an image quality measurement based on Equation (6) between the approximated image
and the ground truth image
.
In contrast, peak signal-to-noise ratio (PSNR) [
49] is an objective assessment based on comparisons using particular numerical criteria [
50,
51]; a higher PSNR value indicates better image quality. Images generated by Equation (7) have significant numerical differences at the low end of the PSNR scale [
52,
53].
MATLAB2020b is used for the implementation of corneal diagnosing. All training processes were performed using an NVIDIA GeForce GTX 1660 GPU.
Using the above-mentioned metrics for different classifiers, few results were recorded when no synthesized data were used; this might be due to overfitting over the smaller number of training images. Conversely, using the CGAN model, the results improved as the number of training instances grew (see
Table 2).
Since our data images are unbalanced, we suggested revealing how the corneal diagnosis would be affected if a balanced dataset was available. Therefore, we used the traditional data balancing methods, where we conducted data resampling using both approaches to make a balanced dataset out of an imbalanced one. The first approach was undersampling (keeping all samples in the rare class and randomly selecting an equal number of samples in the abundant class); the second approach was oversampling (increasing the size of rare samples using repetition). These two approaches were applied to the data before and after generating images.
Results reported that, generally, when applying data resampling on the original data (before using the CGAN model), the classifiers achieved a moral performance, while the data were balanced. Moreover, training by oversampling synthesized data for all classifiers outperforms training by underdamped synthesized data. On the other hand, applying oversampled data on the generated image (after implementing the CGAN model) will not affect the classifier results since the data are vast enough to train the models correctly. In contrast, undersampling negatively affected the achievement of classifiers due to the data being decreased again (see
Table 3).
This issue of whether the set of images generated was sufficiently distinct to allow classification between the corneal case categories was investigated with the help of an expert ophthalmologist. We provided him with 500 randomly generated images with various categories to classify and diagnose.
Table 4 summarizes the findings, and
Table 5 shows the average of SSIM and PSNR for a random selection of 100 images.
The SSIM and PSNR have been calculated before and after training the CGAN model on a random sample of 100 images.
Table 5 shows that the model can generate synthetic images very close to the original. Therefore, we can consider those images to be legitimate for training CNNs models, and ophthalmologists can use them in clinical research.
The CNN classifiers are repeatedly tested in this work to determine the testing process. The suggested model can be applied in real-time, where testing images only takes a few moments, according to
Table 6. While the CoaT model requires the longest ATT, the ATT for ViT beats the other classifiers.
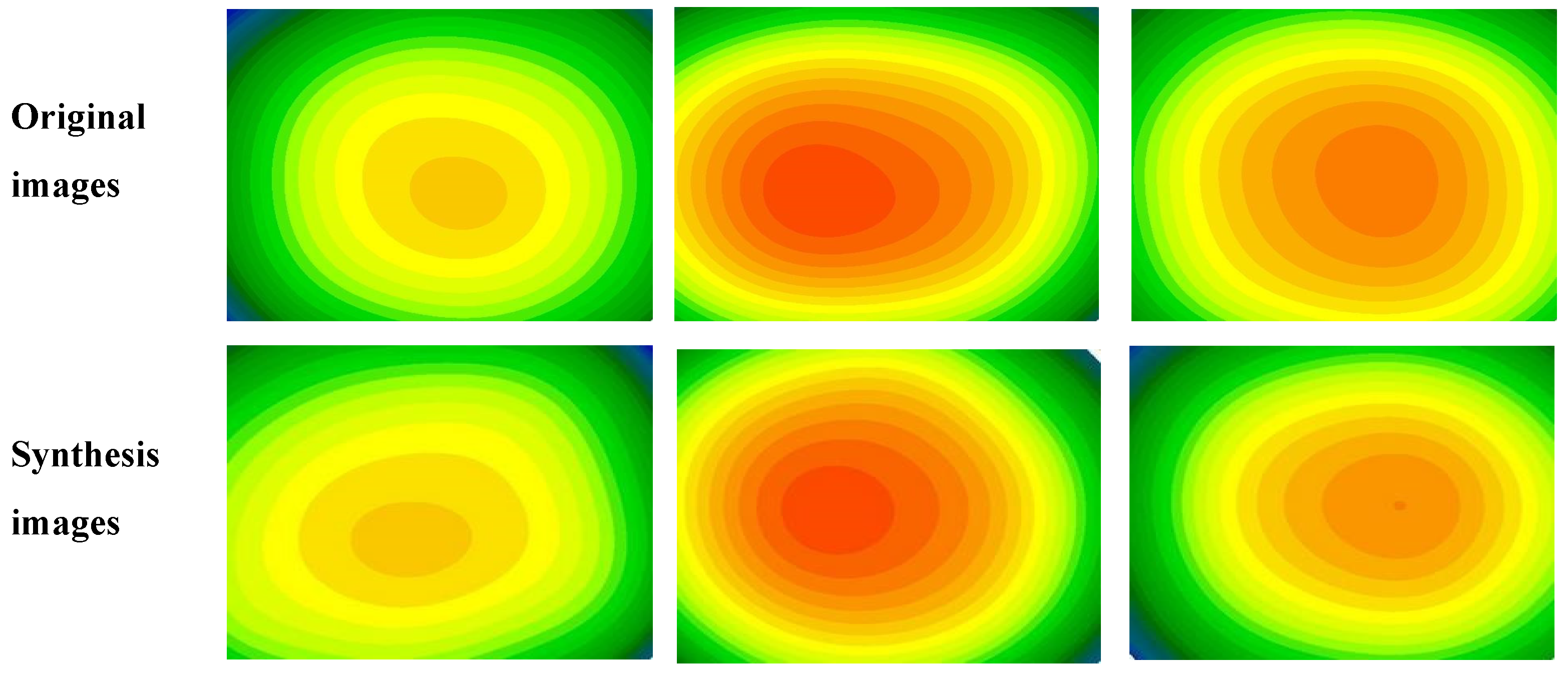
The high quality of the images can be seen in the images synthesized from the test images using the CGAN model, which are displayed in
Figure 4. It is also possible to notice the stability of the structures and morphologies of the images.
4. Discussion
The objectives of this work were to apply the CGAN model to generate synthetic medical images for data augmentation to expand limited datasets and improve clinical decision-making for corneal diseases. Thus, we investigated the extent to which synthetic corneal images help another system perform better behind the scenes. The study used a small dataset comprising the sagittal, corneal thickness, elevation front, and elevation back of corneal images. Each class has its distinct characteristics, although there is considerable intra-class variation. Our diagnosis was based on the four maps, each of which was examined to determine whether it was normal or diseased. To identify corneal disorders, a variety of transfer learning architectures were employed. We discovered that by utilizing the CGAN model to synthesize extra realistic images, we could increase the size of the training data groups, thus boosting the clinical decision. The diagnostic outcomes for mobilenetV2, Resnet50, Xception, ViT, CoaT, and Swin-T classifiers improved from 75.2 % to 88.6 %, 77.13% to 90.5%, 78.9% to 90.7 %, 71.2% to 88.7%, 65.6% to 69.3%, and 58.4% to 63.4%, respectively. Results from
Table 2 show that the synthetic data samples generated can increase the variability of the input dataset, resulting in more accurate clinical decisions.
The scores demonstrate that the synthesized images have useful visuals and, more crucially, useful characteristics that may be used in computer-aided diagnosis. The other aspect of this research is to test the effect of data balance on diagnostic results, where we used the resampling method to make the dataset balanced. The results showed that training the model before generating a new set of data on a balanced dataset is very important, especially in circumstances where data are scarce. On the contrary, we did not notice a significant impact on the performance of the classifiers when using the data resampling on the generated data because the data was sufficient and suitable for training the models without the need to balance them using data balancing methods. This is clear evidence of the importance of the model proposed in this paper. In a final experiment, we compared the performance of the classifiers-based systems employed in this study for clinical decision-making (
Table 3). The highest performance was derived from synthesized data in the Xception classifier, whereas the best performance came from using balance data in Resnet50 when using the oversampling approach, but the ViT model while using the undersampling approach.
This work has several limitations. For example, the training complexity was enhanced by training distinct GANs for each corneal case class. It might be useful to look into GAN designs that produce multi-class samples at the same time. Another type of GAN learning process might increase the quality of the corneal image. It is also possible to do more research to improve the training loss function by adding regularization terms.
Because the human factor is critical in evaluating the proposed model’s outputs, an expert opinion was obtained after providing him with a set of generated corneal images containing a randomly selected set of normal and abnormal corneal images. The following was the expert’s opinion: “Creating a new template for the corneal topographical of four refractive maps is considered an interesting subject as it enriched the overall expected shapes that could be seen during the daily clinic. These new images which created based on real cases collected previously and diagnosed that the new images are still inside the reality borderlines. Gain good experience with the new shapes and specify the further required steps of a diagnosis other than the topographical maps that could be specified advanced for predicted out-of-skim cases. In such a way, offline training for the new ophthalmologists and improving the skill of diagnosis with the preparation for new unseen cases could be done.” In the future, we look to develop our research to exploit other GANs that might benefit from corneal image synthesis for better achievement.

 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}