A New Text Classification Model Based on Contrastive Word Embedding for Detecting Cybersecurity Intelligence in Twitter




Abstract
:1. Introduction
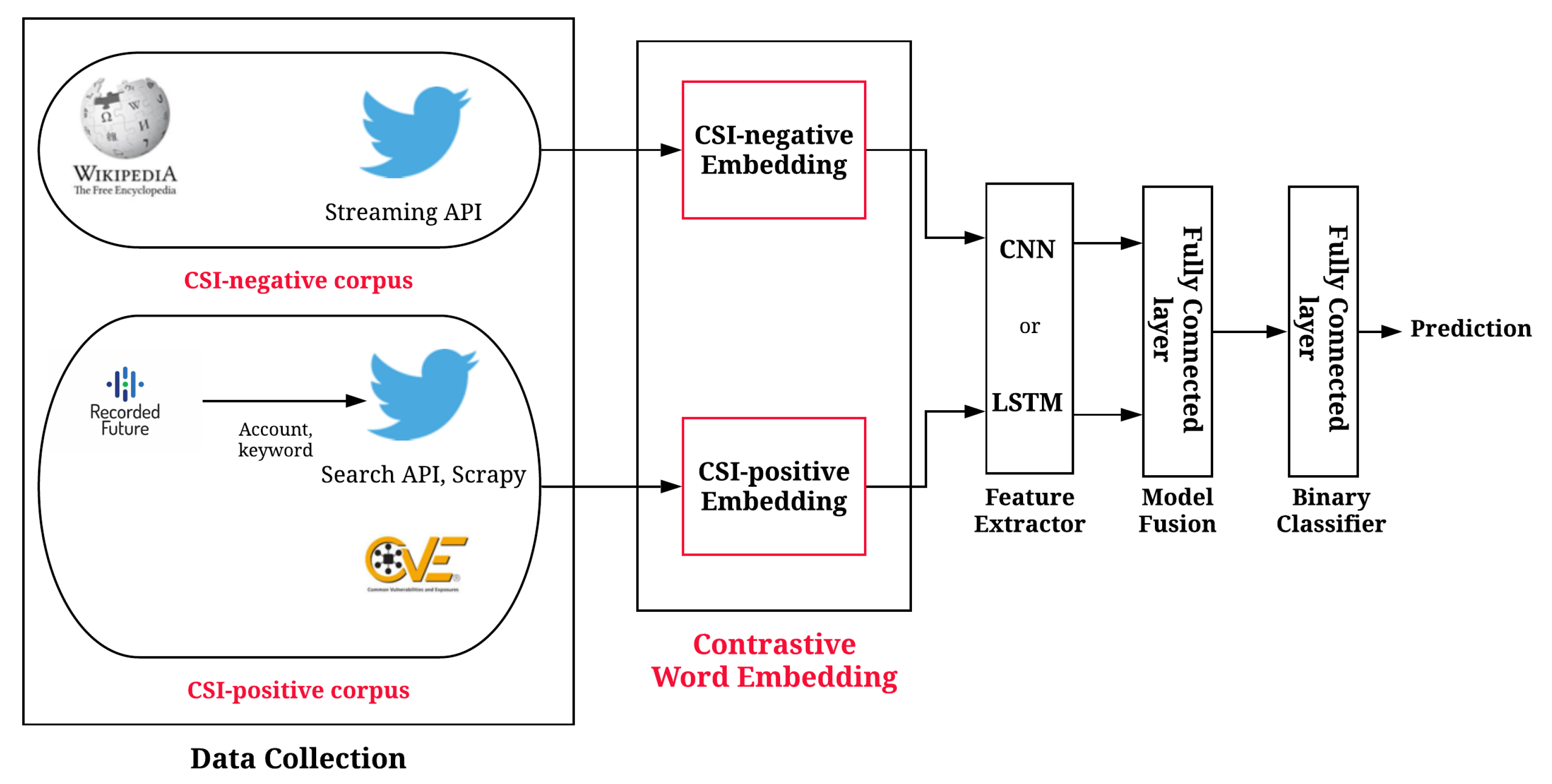
- We propose a novel word embedding model, contrastive word embedding, that enables to maximize the difference between base embedding models. We construct each embedding model using CSI-positive corpus or -negative corpus, which have completely different characteristics. Here, we utilize the background knowledge, which is well-defined public data set for a specific class, to supplement the imbalance of each tweet corpus. Hence, we use two kinds data sets for the CSI-positive corpora: (1) CSI-positive tweet data set and (2) CVE data set as the background knowledge; we use two kinds of data sets for the CSI-negative corpora: (1) CSI-negative tweet data set and (2) Wikitext data set as the background knowledge.
- We devise a new text classification model based on the proposed word embedding model. We adopt deep learning models such as CNN or LSTM to extract adequate feature vectors from the embedding model and integrate the feature vectors into one classifier. To the best of our knowledge, none of the previous methods have considered both CSI-positive and -negative embedding models in one integrated classifier.
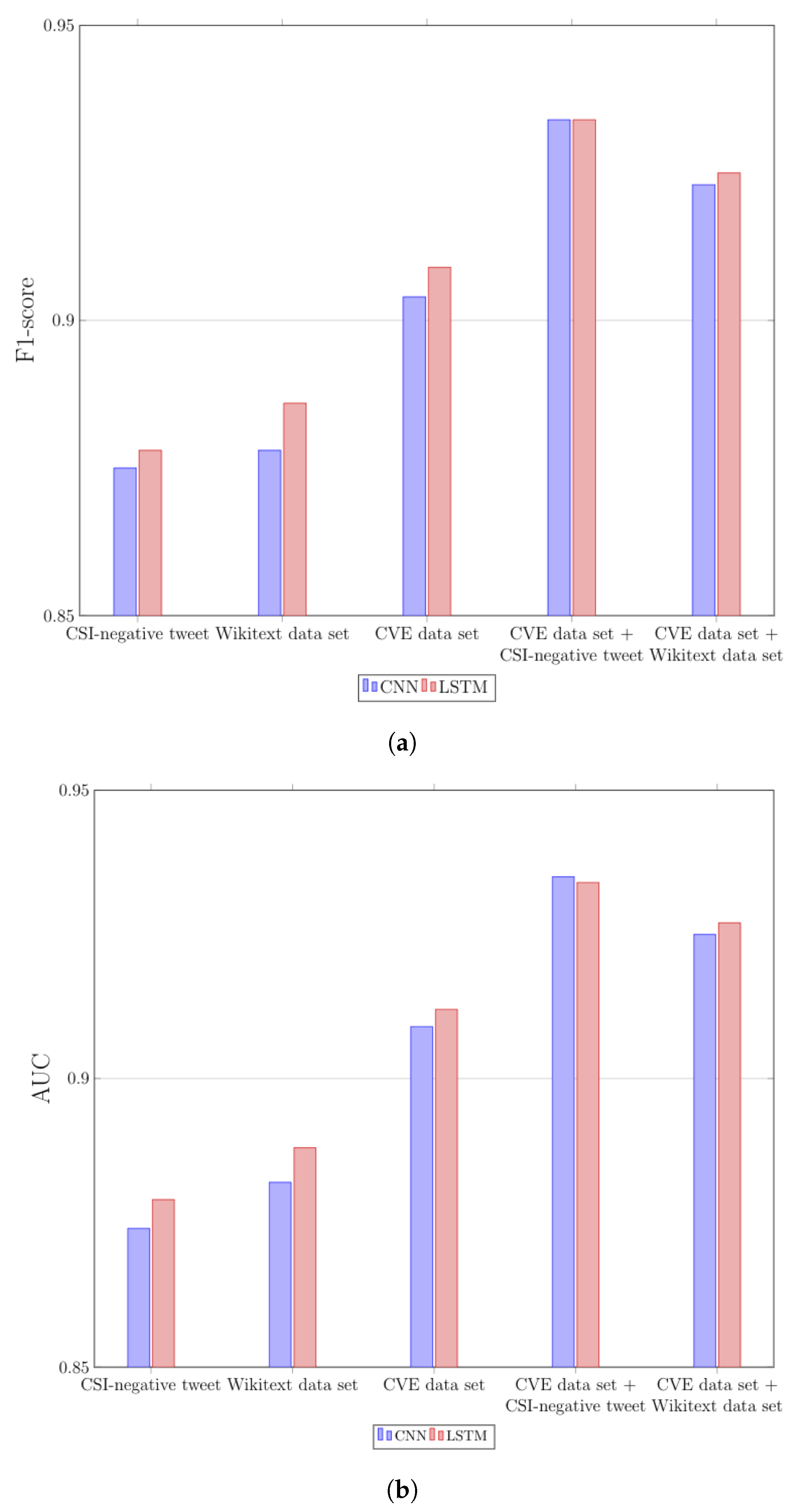
- To validate the effectiveness of the proposed classification model, we compare it with two baseline models: (1) a model based on a single embedding model constructed with CSI-positive corpus only and (2) another model with CSI-negative corpus only. In the experiment, we use 70,000 tweets for CSI-positive and CSI-negative corpora as training data set, respectively, and 30,000 tweets for each corpus as testing data set, respectively. As a result, we indicate that the proposed model shows high accuracy, i.e., 0.934 of F1-score and 0.935 of AUC, which improves the baseline models by 1.76∼6.74% of F1-score and by 1.64∼6.98% of AUC.
2. Background
2.1. Word Representation
2.1.1. Word Embedding
2.1.2. Multiple Word Embedding
2.1.3. Background Knowledge for Embedding
2.2. Text Classification with Deep Learning
2.2.1. CNN
2.2.2. RNN and LSTM
3. Related Work
3.1. Tweet Classification
3.2. Classification Using Background Knowledge
3.3. Classification by the Cybersecurity Intelligence
4. Data Sets and Corpus
4.1. Curated Data
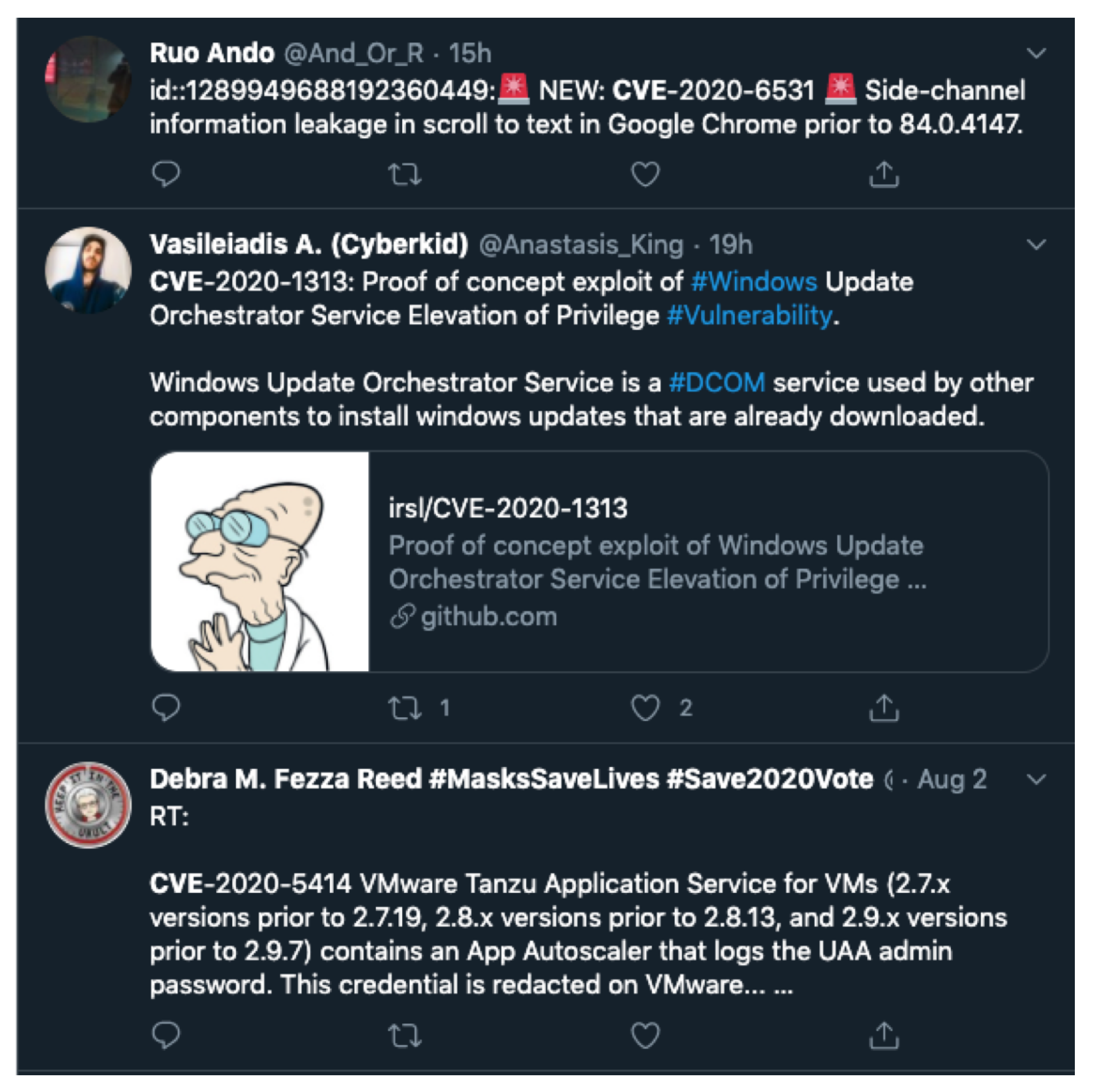
4.2. CSI-Positive Tweet Data Set
4.3. CSI-Negative Tweet Data Set
4.4. CVE Data Set
4.5. Wikitext Data Set
5. The Proposed Classification Model for Detecting Cybersecurity Intelligence in Twitter
5.1. Basic Idea
5.2. Pre-Processing of Data Sets
5.3. Annotation
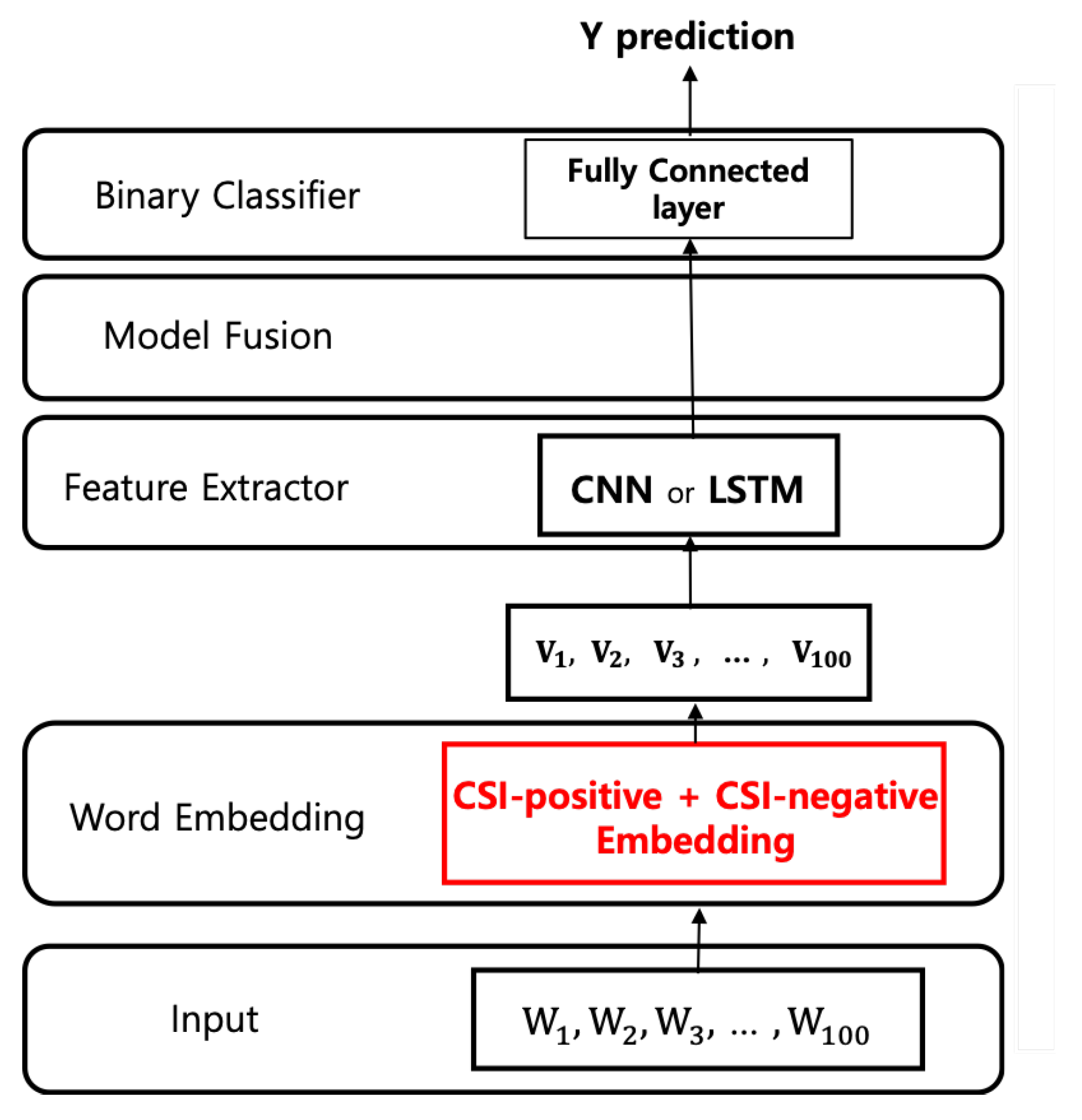
5.4. The Baseline Model
- Input layer: We conduct one-hot encoding of the input tweet text. We fix the length of the encoded bits as 100. That is, if the encoded bit length is larger than 100, we use the front 100 bits; otherwise, we pad 0.
- Word embedding: For the baseline model, we use a single embedding layer, i.e., CSI-positive or -negative embedding on which we construct CNN or LSTM layers. We use four types of corpora (i.e., CSI-positive tweet data set and CVE data set for CSI-positive corpora; CSI-negative tweet data set and Wikitext data set for CSI-negative corpora). To construct all the embedding models, we randomly initialize output vectors of the model with the size of 100 dimensions.
- Feature extractor: In the proposed model, we employ the feature fusion strategy for integrating feature vectors extracted from multiple learning models into a classifier (See Section 5.5). For this, we need to separate the feature extractor and the classifier because the concatenation of the features occurred between the feature extractor and the classifier. We also design each baseline model with the same strategy for comparison. That is, we use the deep learning model (i.e., CNN and LSTM) for the feature extractor. Then, we apply the classifier to the feature vectors extracted from the feature extractor. For constructing a CNN model, we use a Conv1D layer with 128 filters and a global max-pooling layer; For a LSTM model, we use 128 nodes in a hidden layer and tanh activation.
- Binary classifier: We design a binary classifier based on a fully connected layer with sigmoid activation. We train the model so as to minimize the binary cross entropy.
5.5. Contrastive Word Embedding and Model Fusion
6. Performance Evaluation
6.1. Experimental Methods and Evaluation Metrics
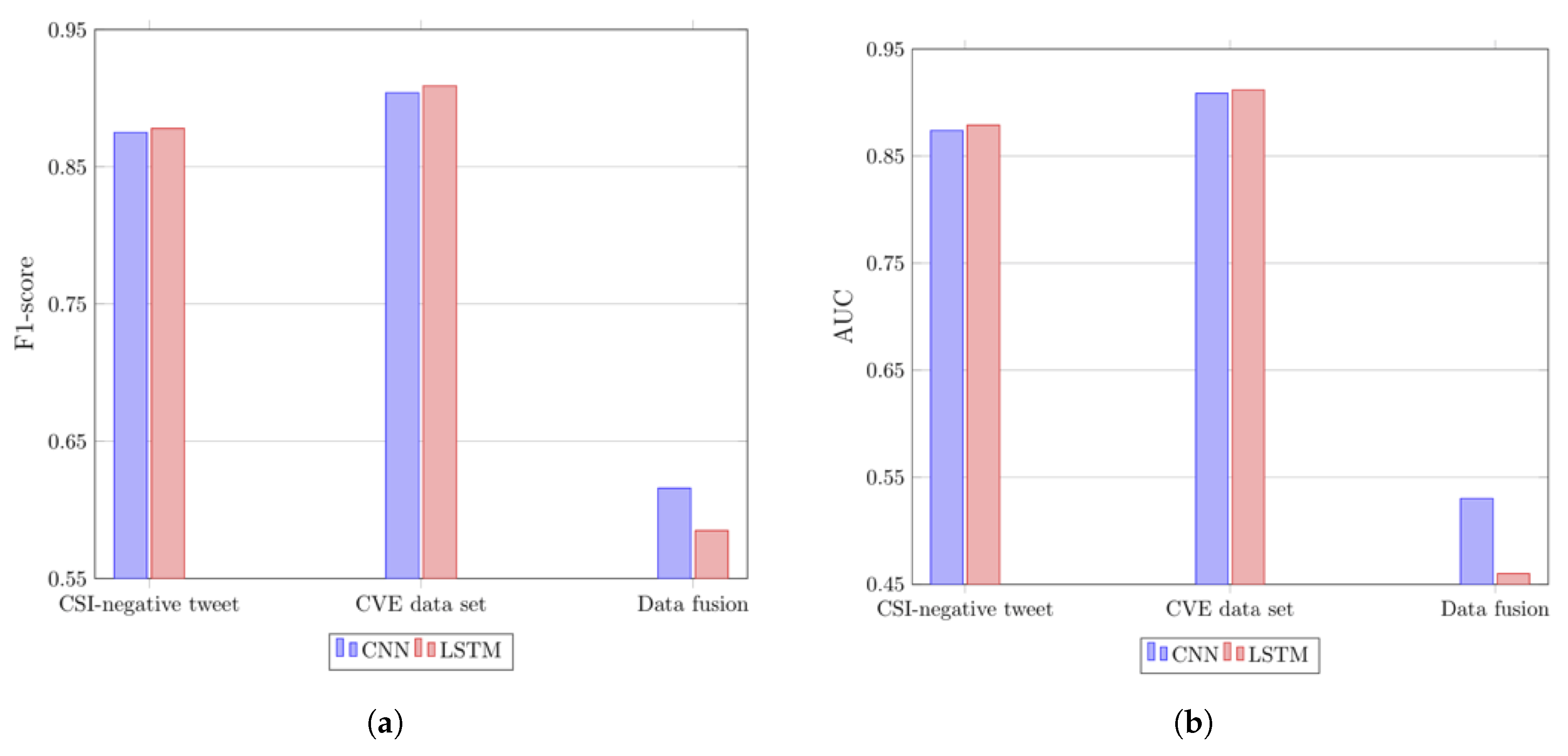
6.2. Evaluation Result
6.2.1. The Accuracy of the Baseline Models
6.2.2. The Accuracy of the Proposed Model
7. Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CSI | Cyber Security Intelligence |
| OSINT | Open Source Intelligence |
| HUMINT | Human Intelligence |
| CVE | Common Vulnerabilities and Exposures |
| NVD | National Vulnerability Database |
| IMDB | Internet Movie Database |
| CNN | Convolutional Neural Network |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| GCN | Graph Convolutional Network |
| NLP | Natural Language Processing |
| RNN | Recurrent Neural Network |
| LSTM | Long Short Term Memory |
| SVM | Support Vector Machine |
| MLP | Multi-Layer Perceptron |
| k-NN | k Nearest Neighbor |
| LDA | Latent Dirichlet Allocation |
| ReLu | Rectified Linear Unit |
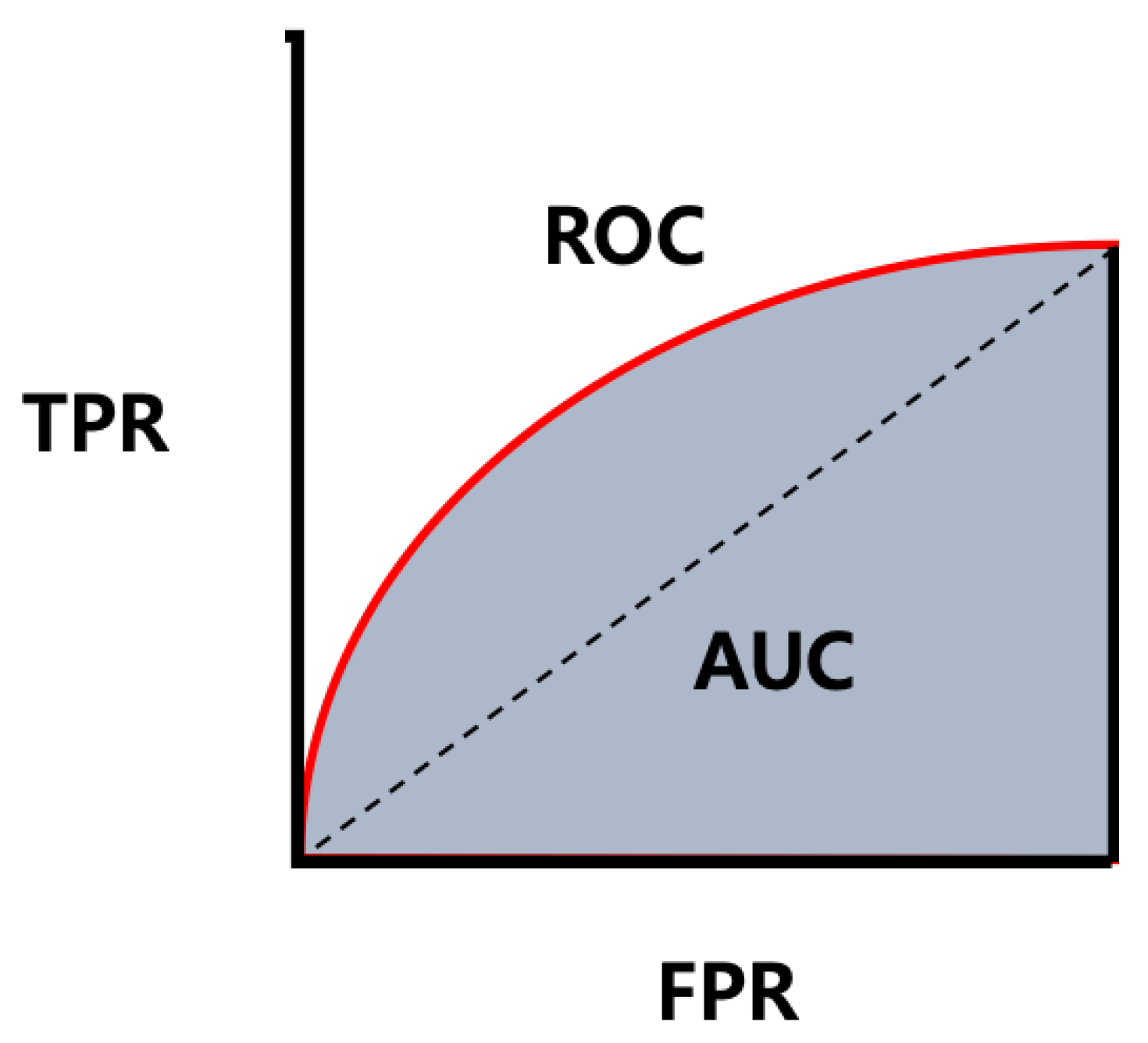
| ROC | Receiver Operating Characteristic |
| AUC | Area Under the Curve |
| BiLSTM | Bidirectional Long Short Term Memory |
| DDoS | Distributed Denial of Service |
References
- Twitter by Numbers: Stats, Demographics & Fun Facts. Available online: https://www.omnicoreagency.com/twitter-statistics/ (accessed on 14 July 2020).
- Han, B.; Cook, P.; Baldwin, T. Text-based twitter user geolocation prediction. J. Artif. Intell. Res. 2014, 49, 451–500. [Google Scholar] [CrossRef]
- Conover, M.D.; Gonçalves, B.; Ratkiewicz, J.; Flammini, A.; Menczer, F. Predicting the political alignment of twitter users. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 192–199. [Google Scholar]
- Wang, X.; Gerber, M.S.; Brown, D.E. Automatic crime prediction using events extracted from twitter posts. In International Conference on Social Computing, Behavioral-Cultural Modeling, and Prediction; Springer: Berlin/Heidelberg, Germany, 2012; pp. 231–238. [Google Scholar]
- Ramage, D.; Dumais, S.; Liebling, D. Characterizing microblogs with topic models. In Proceedings of the Fourth International AAAI Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- What Is Cyber Security? Available online: https://www.kaspersky.com/resource-center/definitions/what-is-cyber-security (accessed on 31 August 2020).
- Campiolo, R.; Santos, L.A.F.; Batista, D.M.; Gerosa, M.A. Evaluating the utilization of Twitter messages as a source of security alerts. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, Coimbra, Portugal, 18–22 March 2013; pp. 942–943. [Google Scholar]
- Sabottke, C.; Suciu, O.; Dumitraș, T. Vulnerability disclosure in the age of social media: Exploiting twitter for predicting real-world exploits. In Proceedings of the 24th USENIX Security Symposium (USENIX Security 15), Washington, DC, USA, 12–14 August 2015; pp. 1041–1056. [Google Scholar]
- Arora, S.; Liang, Y.; Ma, T. A simple but tough-to-beat baseline for sentence embeddings. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Ritter, A.; Wright, E.; Casey, W.; Mitchell, T. Weakly supervised extraction of computer security events from twitter. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 896–905. [Google Scholar]
- Le, B.D.; Wang, G.; Nasim, M.; Babar, M.A. Gathering cyber threat intelligence from Twitter using novelty classification. In Proceedings of the 2019 International Conference on Cyberworlds (CW), Kyoto, Japan, 2–4 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 316–323. [Google Scholar]
- Chambers, N.; Fry, B.; McMasters, J. Detecting denial-of-service attacks from social media text: Applying nlp to computer security. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 1626–1635. [Google Scholar]
- Dionísio, N.; Alves, F.; Ferreira, P.M.; Bessani, A. Cyberthreat detection from twitter using deep neural networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Jindal, N.; Liu, B. Review spam detection. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 1189–1190. [Google Scholar]
- Bijalwan, V.; Kumar, V.; Kumari, P.; Pascual, J. KNN based machine learning approach for text and document mining. Int. J. Database Theory Appl. 2014, 7, 61–70. [Google Scholar] [CrossRef]
- Haddoud, M.; Mokhtari, A.; Lecroq, T.; Abdeddaïm, S. Combining supervised term-weighting metrics for SVM text classification with extended term representation. Knowl. Inf. Syst. 2016, 49, 909–931. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Lai, S.; Liu, K.; He, S.; Zhao, J. How to generate a good word embedding. IEEE Intell. Syst. 2016, 31, 5–14. [Google Scholar] [CrossRef]
- Joachims, T. A Probabilistic Analysis of the Rocchio Algorithm with TFIDF for Text Categorization; Technical Report; Carnegie-Mellon Univ Pittsburgh pa Dept of Computer Science: Pittsburgh, PA, USA, 1996. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 2, 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Qin, B.; Liu, T. Contradiction detection with contradiction-specific word embedding. Algorithms 2017, 10, 59. [Google Scholar] [CrossRef]
- Liu, P.; Qiu, X.; Huang, X. Learning context-sensitive word embeddings with neural tensor skip-gram model. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Bruni, E.; Boleda, G.; Baroni, M.; Tran, N.K. Distributional semantics in technicolor. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju, Korea, 8–14 July 2012; Volume 1, pp. 136–145. [Google Scholar]
- Luo, Y.; Tang, J.; Yan, J.; Xu, C.; Chen, Z. Pre-Trained Multi-View Word Embedding Using Two-Side Neural Network; AAAI: Menlo Park, CA, USA, 2014; pp. 1982–1988. [Google Scholar]
- Zhang, Y.; Roller, S.; Wallace, B. MGNC-CNN: A simple approach to exploiting multiple word embeddings for sentence classification. arXiv 2016, arXiv:1603.00968. [Google Scholar]
- Ren, F.; Deng, J. Background knowledge based multi-stream neural network for text classification. Appl. Sci. 2018, 8, 2472. [Google Scholar] [CrossRef] [Green Version]
- Annane, A.; Bellahsene, Z.; Azouaou, F.; Jonquet, C. Building an effective and efficient background knowledge resource to enhance ontology matching. J. Web Semant. 2018, 51, 51–68. [Google Scholar] [CrossRef] [Green Version]
- Li, C. Text Classification Based on Background Knowledge. Ph.D. Thesis, Department Advance Technology Science Information, Alcorn State University, Alcorn, MS, USA, 2017. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Xu, H.; Dong, M.; Zhu, D.; Kotov, A.; Carcone, A.I.; Naar-King, S. Text classification with topic-based word embedding and convolutional neural networks. In Proceedings of the 7th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Seattle, WA, USA, 20–23 October 2016; pp. 88–97. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Hu, Y.; Yi, Y.; Yang, T.; Pan, Q. Short text classification with a convolutional neural networks based method. In Proceedings of the 2018 15th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 18–21 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1432–1435. [Google Scholar]
- Liu, Y.; Ji, L.; Huang, R.; Ming, T.; Gao, C.; Zhang, J. An attention-gated convolutional neural network for sentence classification. Intell. Data Anal. 2019, 23, 1091–1107. [Google Scholar] [CrossRef] [Green Version]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Wang, J.H.; Liu, T.W.; Luo, X.; Wang, L. An LSTM approach to short text sentiment classification with word embeddings. In Proceedings of the 30th Conference on Computational Linguistics and Speech Processing (ROCLING 2018), Hsinchu, Taiwan, 4–5 October 2018; pp. 214–223. [Google Scholar]
- Ding, Z.; Xia, R.; Yu, J.; Li, X.; Yang, J. Densely connected bidirectional lstm with applications to sentence classification. In CCF International Conference on Natural Language Processing and Chinese Computing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 278–287. [Google Scholar]
- Sriram, B.; Fuhry, D.; Demir, E.; Ferhatosmanoglu, H.; Demirbas, M. Short text classification in twitter to improve information filtering. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Geneva, Switzerland, 19–23 July 2010; pp. 841–842. [Google Scholar]
- Alsmadi, I.; Hoon, G.K. Term weighting scheme for short-text classification: Twitter corpuses. Neural Comput. Appl. 2019, 31, 3819–3831. [Google Scholar] [CrossRef]
- Zhou, C.; Sun, C.; Liu, Z.; Lau, F. A C-LSTM neural network for text classification. arXiv 2015, arXiv:1511.08630. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7370–7377. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2017; pp. 3856–3866. [Google Scholar]
- Yang, M.; Zhao, W.; Ye, J.; Lei, Z.; Zhao, Z.; Zhang, S. Investigating capsule networks with dynamic routing for text classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3110–3119. [Google Scholar]
- Yang, L.; Li, C.; Ding, Q.; Li, L. Combining lexical and semantic features for short text classification. Procedia Comput. Sci. 2013, 22, 78–86. [Google Scholar] [CrossRef] [Green Version]
- Qureshi, M.A.; Greene, D. EVE: Explainable vector based embedding technique using Wikipedia. J. Intell. Inf. Syst. 2019, 53, 137–165. [Google Scholar] [CrossRef] [Green Version]
- Ren, F.; Li, C. Hybrid Chinese text classification approach using general knowledge from Baidu Baike. IEEJ Trans. Electr. Electron. Eng. 2016, 11, 488–498. [Google Scholar] [CrossRef]
- Zong, S.; Ritter, A.; Mueller, G.; Wright, E. Analyzing the perceived severity of cybersecurity threats reported on social media. arXiv 2019, arXiv:1902.10680. [Google Scholar]
- Le Sceller, Q.; Karbab, E.B.; Debbabi, M.; Iqbal, F. Sonar: Automatic detection of cyber security events over the twitter stream. In Proceedings of the 12th International Conference on Availability, Reliability and Security, Reggio Calabria, Italy, 29 August–2 September 2017; pp. 1–11. [Google Scholar]
- Petrović, S.; Osborne, M.; Lavrenko, V. Streaming first story detection with application to twitter. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 181–189. [Google Scholar]
- Alves, F.; Bettini, A.; Ferreira, P.M.; Bessani, A. Processing tweets for cybersecurity threat awareness. arXiv 2019, arXiv:1904.02072. [Google Scholar]
- Dong, X.; Qian, L.; Huang, L. Short-term load forecasting in smart grid: A combined CNN and K-means clustering approach. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Korea, 13–16 February 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 119–125. [Google Scholar]
- Steele, R.D. Open source intelligence: What is it? why is it important to the military? Am. Intell. J. 1996, 8, 457–470. [Google Scholar]
- Merity, S.; Xiong, C.; Bradbury, J.; Socher, R. Pointer sentinel mixture models. arXiv 2016, arXiv:1609.07843. [Google Scholar]
- Aphinyanaphongs, Y.; Lulejian, A.; Brown, D.P.; Bonneau, R.; Krebs, P. Text classification for automatic detection of e-cigarette use and use for smoking cessation from twitter: A feasibility pilot. Pac. Symp. Biocomput. 2016, 21, 480–491. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [Green Version]
- Musicant, D.R.; Kumar, V.; Ozgur, A. Optimizing F-Measure with Support Vector Machines. In Proceedings of the FLAIRS Conference, St. Augustine, FL, USA, 12–14 May 2003; pp. 356–360. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [Green Version]
- Narkhede, S. Understanding AUC-ROC Curve. Available online: https://towardsdatascience.com/understanding-auc-roc-curve-68b2303cc9c5 (accessed on 4 August 2020).
- El-Deeb, R.; Al-Zoghby, A.M.; Elmougy, S. Multi-corpus-based model for measuring the semantic relatedness in short texts (SRST). Arab. J. Sci. Eng. 2018, 43, 7933–7943. [Google Scholar] [CrossRef]
- Sarker, A.; Gonzalez, G. Portable automatic text classification for adverse drug reaction detection via multi-corpus training. J. Biomed. Inform. 2015, 53, 196–207. [Google Scholar] [CrossRef] [PubMed] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Classifiers | Data Sets | Background Knowledge | Multiple Word Embedding |
|---|---|---|---|---|
| Ritter et al. [10] | Weakly supervised learning | Tweets containing “DDoS” | N/A | X |
| Chambers et al. [12] | Basic neural network | Tweets written on attack day | N/A | X |
| Zong et al. [51] | Logistic regression | Tweets filtered by keywords | N/A | X |
| Le Sceller et al. [52] | First story detection | Streaming Tweets | N/A | X |
| Dionísio et al. [13] | SVM, MLP, CNN, BiLSTM | Tweets filtered by keywords | N/A | X |
| Le et al. [11] | Centroid, One-class SVM, CNN, LSTM | Streaming Tweets | CVE descriptions | X |
| Alves et al. [54] | SVM, MLP | Tweets filtered by accounts and keywords | N/A | X |
| Types | Sources | Data Set Name | Usage | Data Size |
|---|---|---|---|---|
| Curated data | Recorded Future | RF Keyword Set | Filtering | 639 keywords |
| RF Account Set | Filtering | 130 accounts | ||
| OSINT | CSI-Positive Tweet Data Set | Embedding, Training, Testing | 100,000 tweets | |
| CSI-Negative Tweet Data Set | Embedding, Training, Testing | 100,000 tweets | ||
| Background knowledge | NVD | CVE Data Set | Embedding | 134,166 identifiers |
| Wikipedia | Wikitext Data Set | Embedding | 28,475 articles |
| Data Sets | Target Accounts | Number of Tweets | Usage |
|---|---|---|---|
| CSI-positive tweet data set | 100 accounts | 70,000 | Training |
| 30 accounts | 30,000 | Testing | |
| CSI-negative tweet data set | Random accounts | 70,000 | Training |
| Random accounts | 30,000 | Testing |
| Embedding Model | Corpus | Measurement | Precision | Recall | F1-Score | AUC | |
|---|---|---|---|---|---|---|---|
| Learning Model | |||||||
| CSI-positive embedding | CSI-positive tweet data set | CNN | 0.535 | 0.853 | 0.658 | 0.557 | |
| LSTM | 0.526 | 0.865 | 0.654 | 0.543 | |||
| CVE data set | CNN | 0.958 | 0.856 | 0.904 | 0.909 | ||
| LSTM | 0.952 | 0.869 | 0.909 | 0.912 | |||
| CSI-negative embedding | CSI-negative tweet data set | CNN | 0.890 | 0.860 | 0.875 | 0.874 | |
| LSTM | 0.887 | 0.870 | 0.878 | 0.879 | |||
| Wikitext data set | CNN | 0.907 | 0.851 | 0.878 | 0.882 | ||
| LSTM | 0.905 | 0.867 | 0.886 | 0.888 | |||
| Corpus | Measurement | TP | FN | FP | TN | |
|---|---|---|---|---|---|---|
| Learning Model | ||||||
| CSI-positive tweet data set | CNN | 25,597 | 4403 | 22,204 | 7796 | |
| LSTM | 25,954 | 4046 | 23,396 | 6604 | ||
| CVE data set | CNN | 25,674 | 4326 | 1129 | 28,871 | |
| LSTM | 26,056 | 3943 | 1301 | 28,699 | ||
| CSI-negative tweet data set | CNN | 25,799 | 4201 | 3177 | 26,823 | |
| LSTM | 26,098 | 3902 | 3330 | 26,670 | ||
| Wikitext data set | CNN | 25,528 | 4472 | 2623 | 27,377 | |
| LSTM | 25,987 | 4013 | 2729 | 27,271 | ||
| Corpus | Measurement | Precision | Recall | F1-Score | AUC | |
|---|---|---|---|---|---|---|
| Classifier | ||||||
| Fusion of CVE data set and CSI-negative tweet | CNN | 0.957 | 0.912 | 0.934 | 0.935 | |
| LSTM | 0.955 | 0.911 | 0.932 | 0.934 | ||
| Fusion of CVE data set and Wikitext data set | CNN | 0.894 | 0.923 | 0.925 | 0.925 | |
| LSTM | 0.949 | 0.902 | 0.925 | 0.927 | ||
| Corpus | Measurement | TP | FN | FP | TN | |
|---|---|---|---|---|---|---|
| Classifier | ||||||
| Fusion of CVE data set and CSI-negative tweet | CNN | 27,354 | 2646 | 1231 | 28,769 | |
| LSTM | 27,316 | 2684 | 1284 | 28,716 | ||
| Fusion of CVE data set and Wikitext data set | CNN | 26,830 | 3170 | 1305 | 28,695 | |
| LSTM | 27,072 | 2928 | 1453 | 28,547 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, H.-S.; Kwon, H.-Y.; Ryu, S.-J. A New Text Classification Model Based on Contrastive Word Embedding for Detecting Cybersecurity Intelligence in Twitter. Electronics 2020, 9, 1527. https://doi.org/10.3390/electronics9091527
Shin H-S, Kwon H-Y, Ryu S-J. A New Text Classification Model Based on Contrastive Word Embedding for Detecting Cybersecurity Intelligence in Twitter. Electronics. 2020; 9(9):1527. https://doi.org/10.3390/electronics9091527
Chicago/Turabian StyleShin, Han-Sub, Hyuk-Yoon Kwon, and Seung-Jin Ryu. 2020. "A New Text Classification Model Based on Contrastive Word Embedding for Detecting Cybersecurity Intelligence in Twitter" Electronics 9, no. 9: 1527. https://doi.org/10.3390/electronics9091527