Exploring Malware Behavior of Webpages Using Machine Learning Technique: An Empirical Study



Abstract
:1. Introduction
- We identify the most targeted features of malware attack in three datasets namely, phishing, botnet and honeypot using a machine learning technique. We identify the most vulnerable features that are common to these three datasets. We also identify legitimate, phishy, and suspicious behavior in these features.
- We compare maliciousness in two available datasets and applications to identify maliciousness in custom-built honeypot infrastructure. Identification is achieved with the accuracy of the number of occurrences for the selected features.
- We discuss the difference between Google index and page rank in identifying malware behavior, which is a significant achievement of this research along with identification of malware behavior on webpages.
- We provide two recommendations for best practices that add scientific rigor to the identification of future malware.
2. Literature Review
2.1. Identifying Malware Behavior in Webpages
2.2. Classification and Machine Learning to Identify Malware Behavior
2.3. Feature Selection in Malware Websites
2.4. Malware Behavior of Webpages
2.5. Malware Behavior of Honeypot
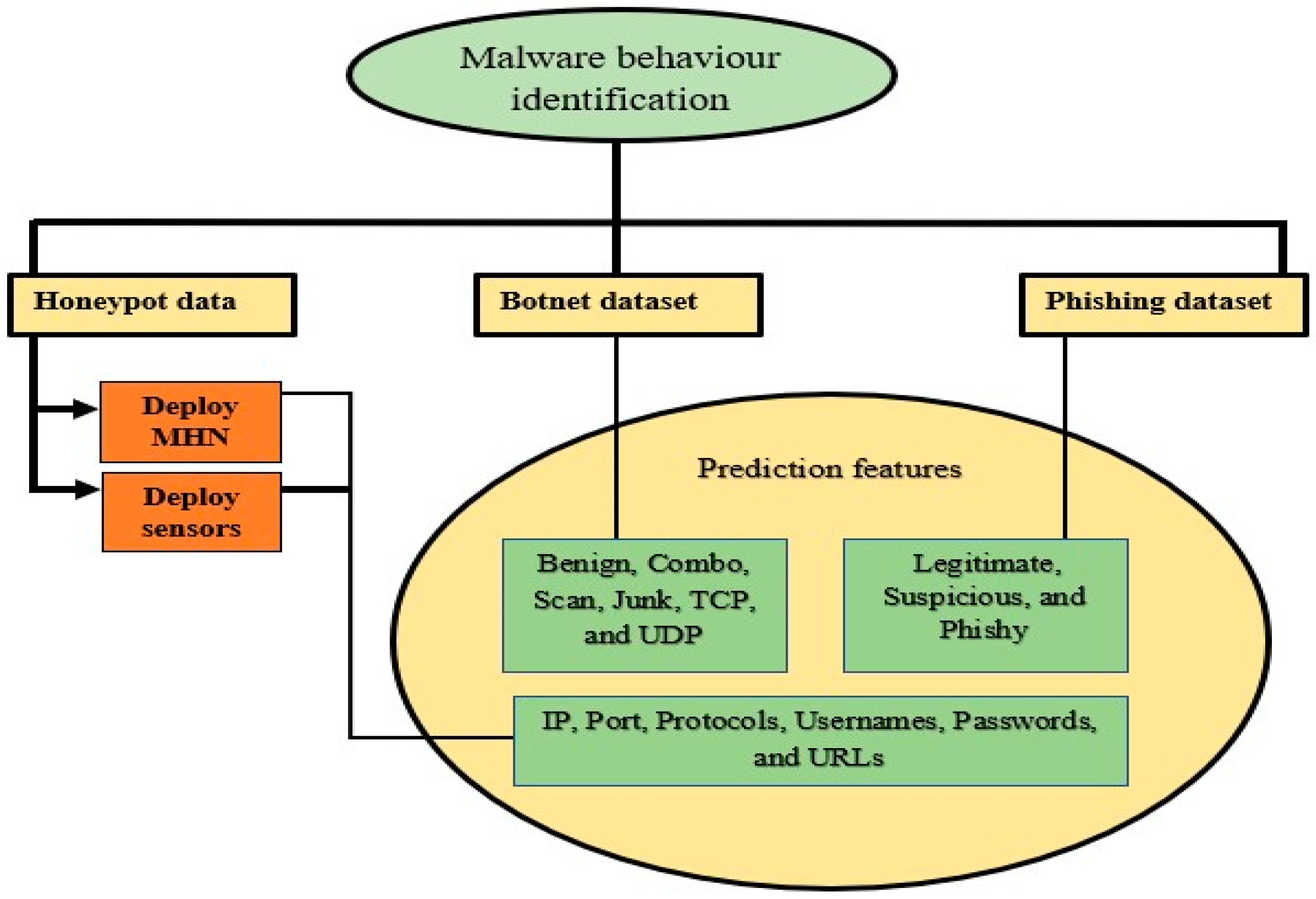
3. Materials and Methods
3.1. Identify the Problem
3.2. Data Collection
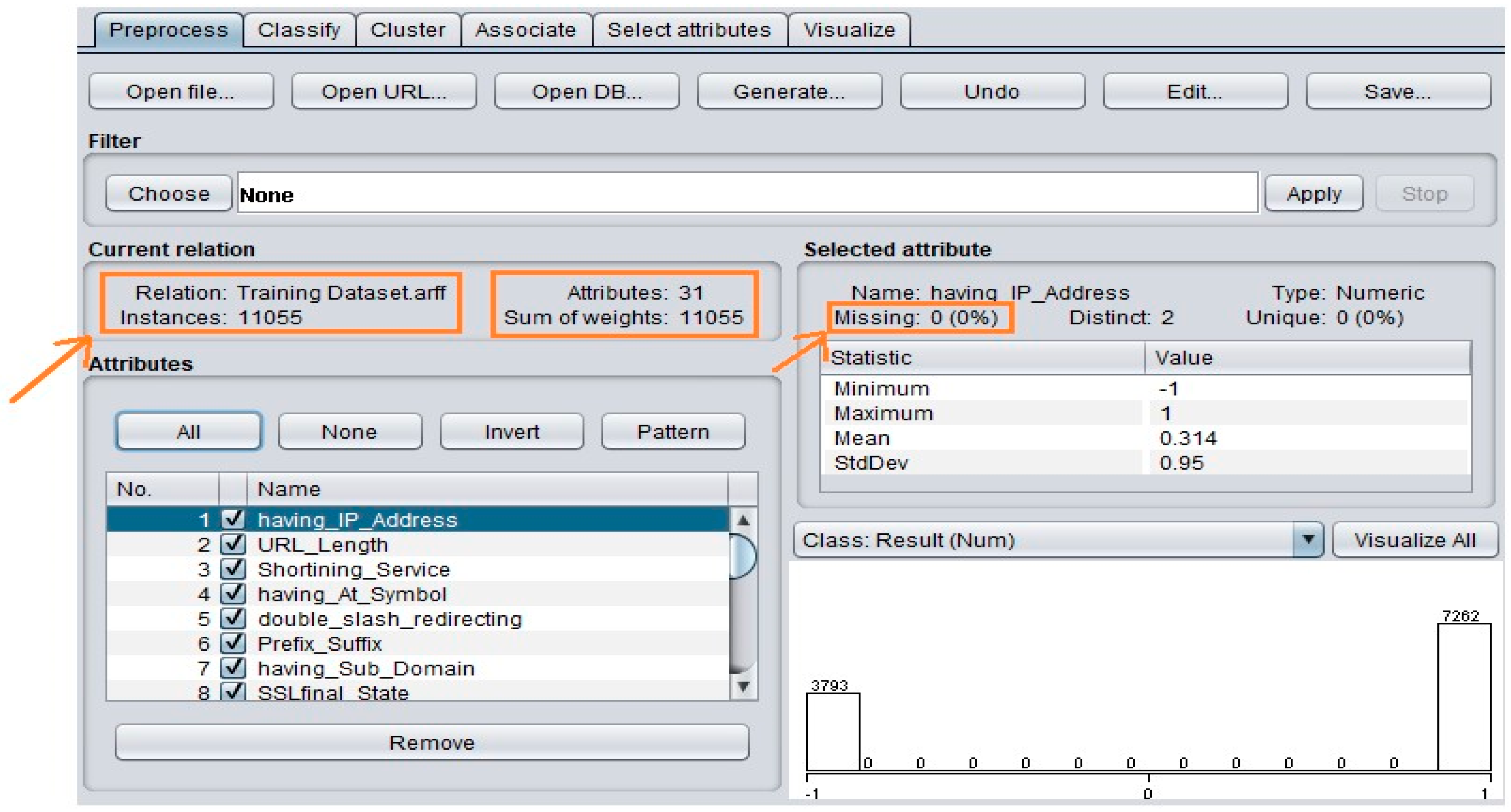
3.3. Data Description
3.4. Data Preprocessing
3.5. Data Analysis
- Identify malware behavior through feature selection.
- Determine influential features that have been targeted by attackers.
- Generate similarities between the properties of malicious webpages to identify the common target of exploitation.
- Predict malware vulnerability of specific features.
3.6. Research Design
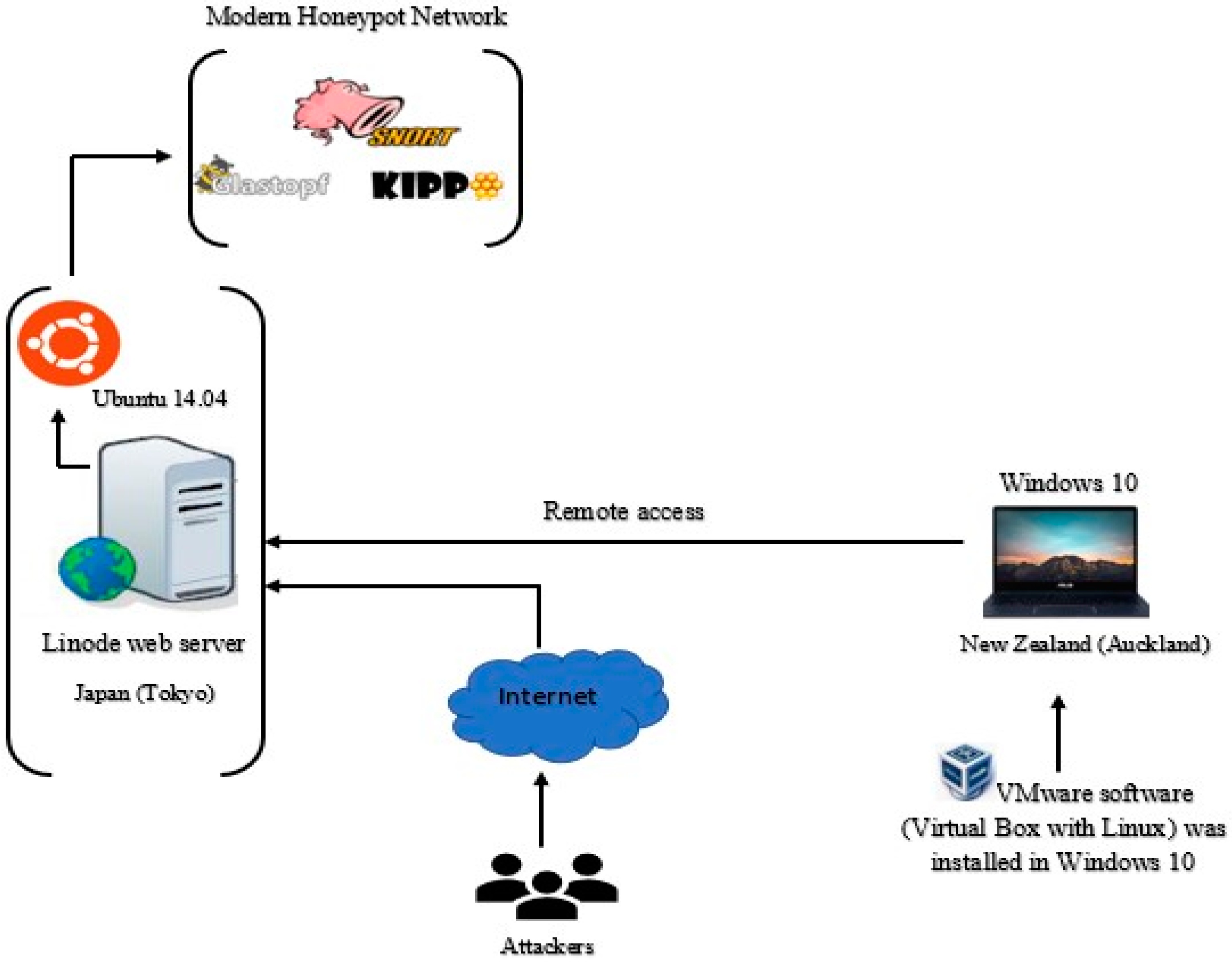
3.6.1. Honeypot Deployment Method
3.6.2. Feature Selection
3.6.3. Identification of Malware Behavior
3.6.4. Predicting Malware Attacks
4. Results
4.1. Malware Behavior in the Phishing Dataset
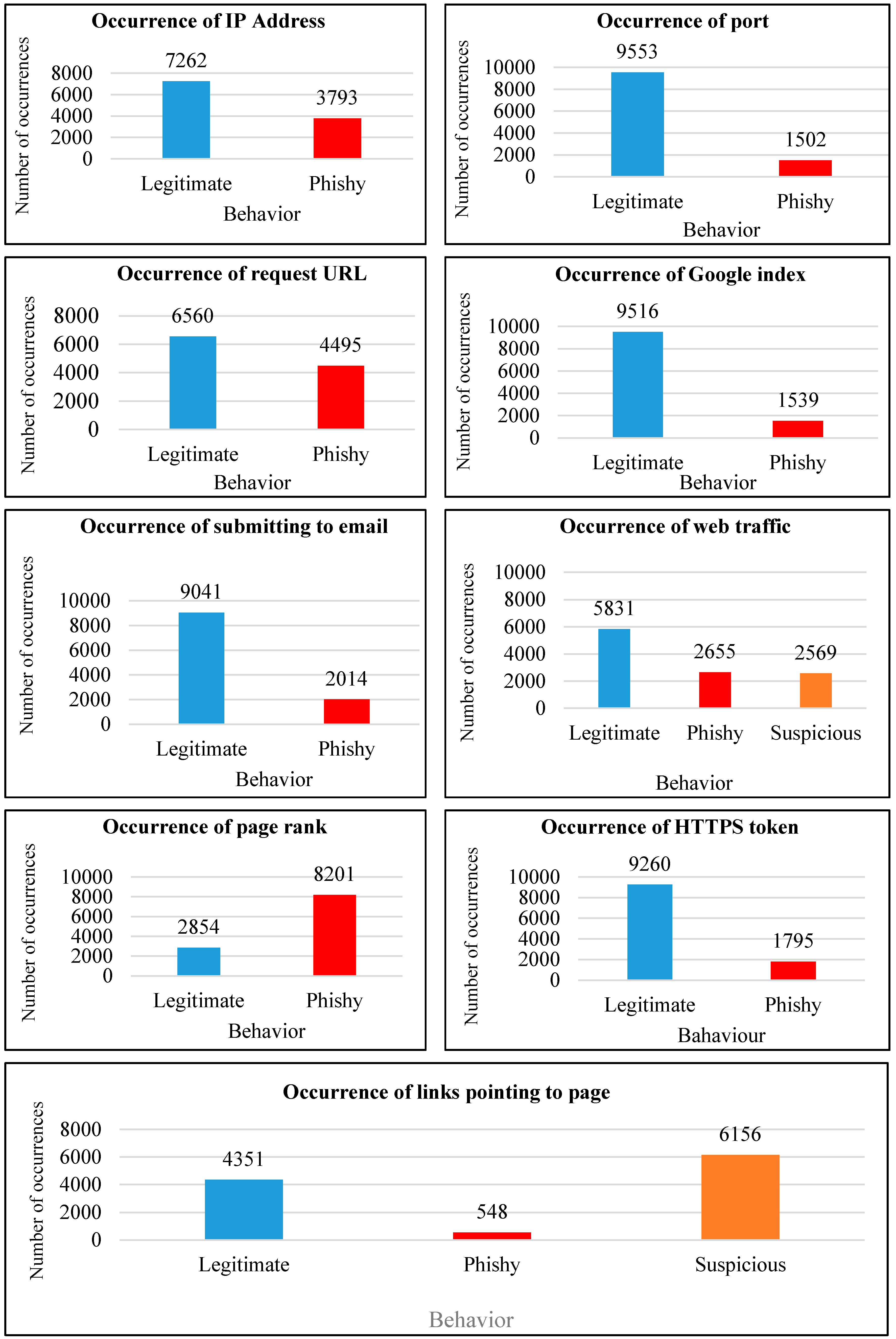
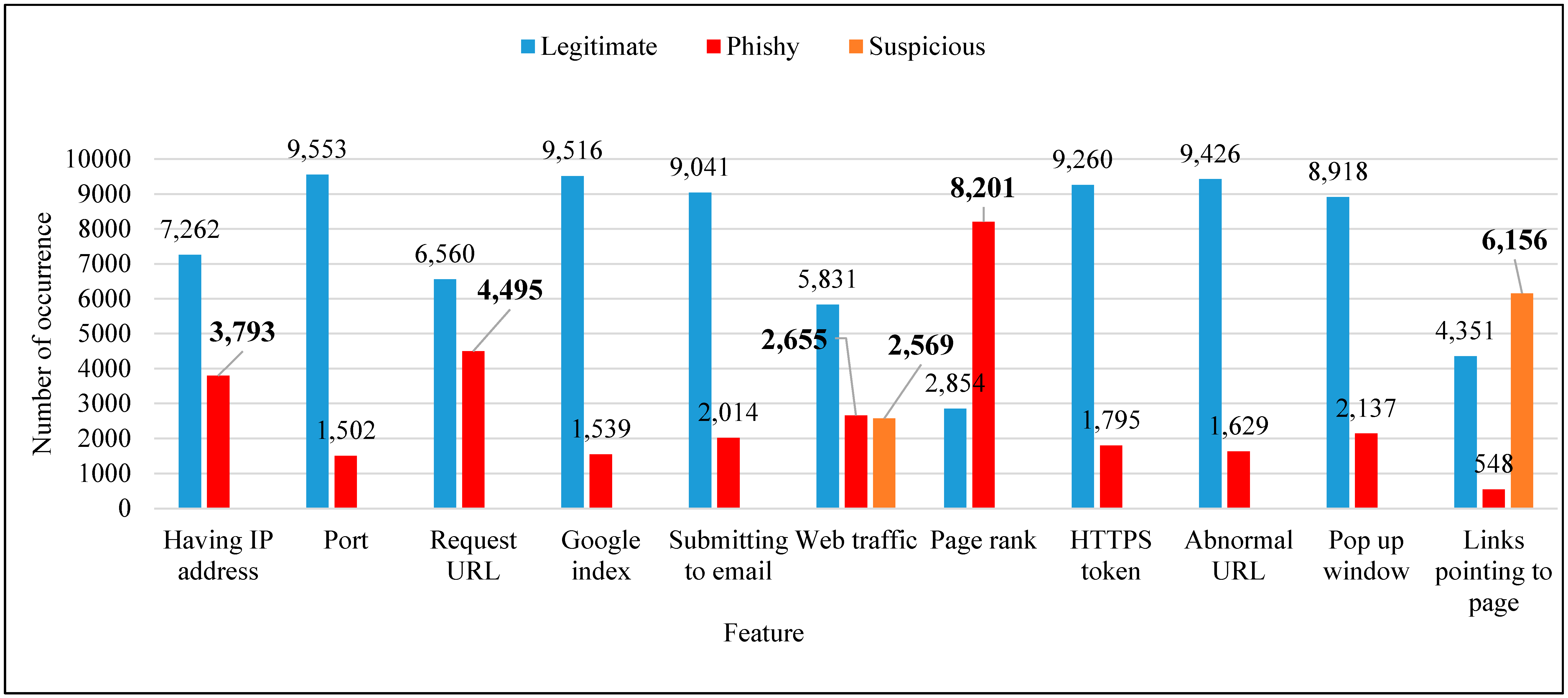
- Having IP address: the nature of IP addresses is based on the URL—if the IP address exists in the URL instead of the domain name, this typically means there has been an attempt to hijack or steal personal information; otherwise, the webpage would be considered legitimate. In the phishing dataset, the results show that the number of URLs that did not have an IP address (or it was masked) was 7262 among the total behaviors, considered legitimate as they returned 1. Only 3793 URLs had an IP address and were classified as phishy, returning −1 as a result
- Port: The number of malicious attacks through legitimate port browsing was 9553, but there were still 1502 cases of phishy behavior. In this case, if a port is compromised, all hosted IPs are affected. If the IP address is affected, then only specific webpages associated with that IP are affected, while the port remains safe. Malicious attacks on port are less common compared to IP address manipulation.
- Request URL: Based on the previous two analyses, it may be concluded that malware occurrence through ports is relatively infrequent (1502 times) while ‘request URL’ has a strong influence on malware behavior, representing more than 40% of 11,055 web hits. In this study’s experiments, the results classified 6560 URLs as legitimate and 4495 as phishy.
- Google index: Based on the previous three analyses, it is clear that the number of occurrences of malware attacks through Google index and through ports is nearly similar (37 more occurrences for Google index, which is the difference between them). In this study’s experiments, 9516 of the URLs were shown to be legitimate, while 1539 of the results were phishy.
- Submitting to email: Malicious behavior using the feature ‘submitting to email’ led to more legitimate results (9041) than phishy (2014) (total number of hits—11,055). Compared with other features, such as having IP address and request URL, the number of phishy sites was lower, but it was higher than malicious attacks through ports.
- Web traffic: The nature of this feature is based on the number of visitors to the webpage. In the phishing dataset, the number of webpages with malicious traffic was less than the number of legitimate webpages. The interesting finding in this feature was that suspicious never indicates whether it is legitimate or phishy. However, from this feature, the number of legitimate webpages for browsing was only 50% of the total number of hits (11,055), which provides a clue that malicious behavior may be closely related to web traffic.
- Page rank: Compared with all other features in the phishing dataset, page rank provided the ability to discover the highest rate of phishy webpages, with 8201 hits, while Google index detected 1539. However, the legitimate webpages were low with 2854 hits, which was less than any other feature. This clearly shows that the higher ranked webpage may not be always safe as we think, while Google indexed pages are safer than ordinary pages ranked in web browsing.
- HTTPS token: Similar to previous results, HTTPS token resulted in very similar rates (almost 9200) as legitimate webpage of features such as port, Google index and submitting to email. Turning to phishy results, these numbered 1795.
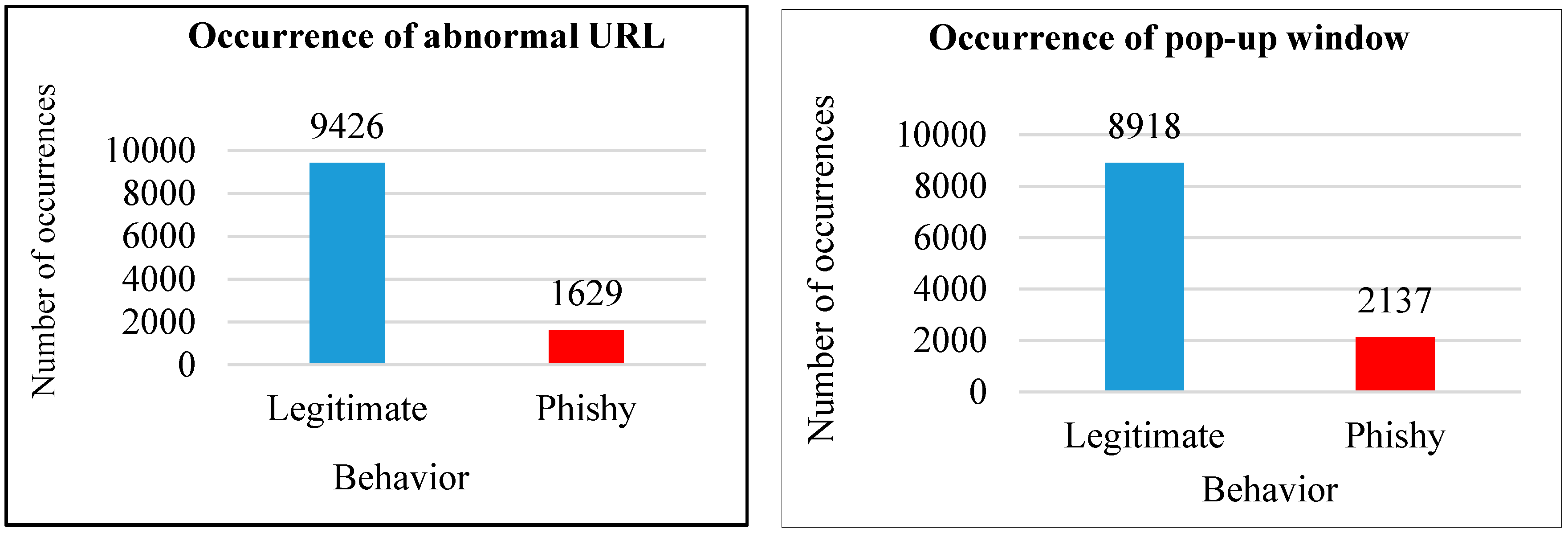
- Abnormal URL: The nature of this feature is based on the identity of URL. If a URL included the host name, it was considered legitimate; otherwise, it was considered phishy. The number of abnormal URLs that were legitimate was 9426, which is one of the features that has a high number of occurrences compared to some previous features; thus, this is a strange result that requires further study. Only 1629 hits were phishy, which also needs further investigation; however, this study was limited to identifying the malware behavior of webpages.
- Pop-up window: The function of pop-up windows in webpages is to ask users for some credentials. In the current data, 8918 webpages were found that did not use pop-up windows, which classified them as legitimate, whereas 2137 were phishy. Some pop-ups are based on adware, which is a next-generation malware, meaning that information regarding the suspiciousness of this feature was not present in this dataset.
- Links pointing to page: This feature refers to links pointing to a specific URL (i.e., page or subpage). There were 4351 webpages classified as legitimate and only 548 as phishy, which was the lowest rate among all features. However, suspicious webpages recorded the highest rate for this feature (6156) compared to the web traffic feature, which had only 2569.
4.2. Malware Behavior in the Botnet Dataset
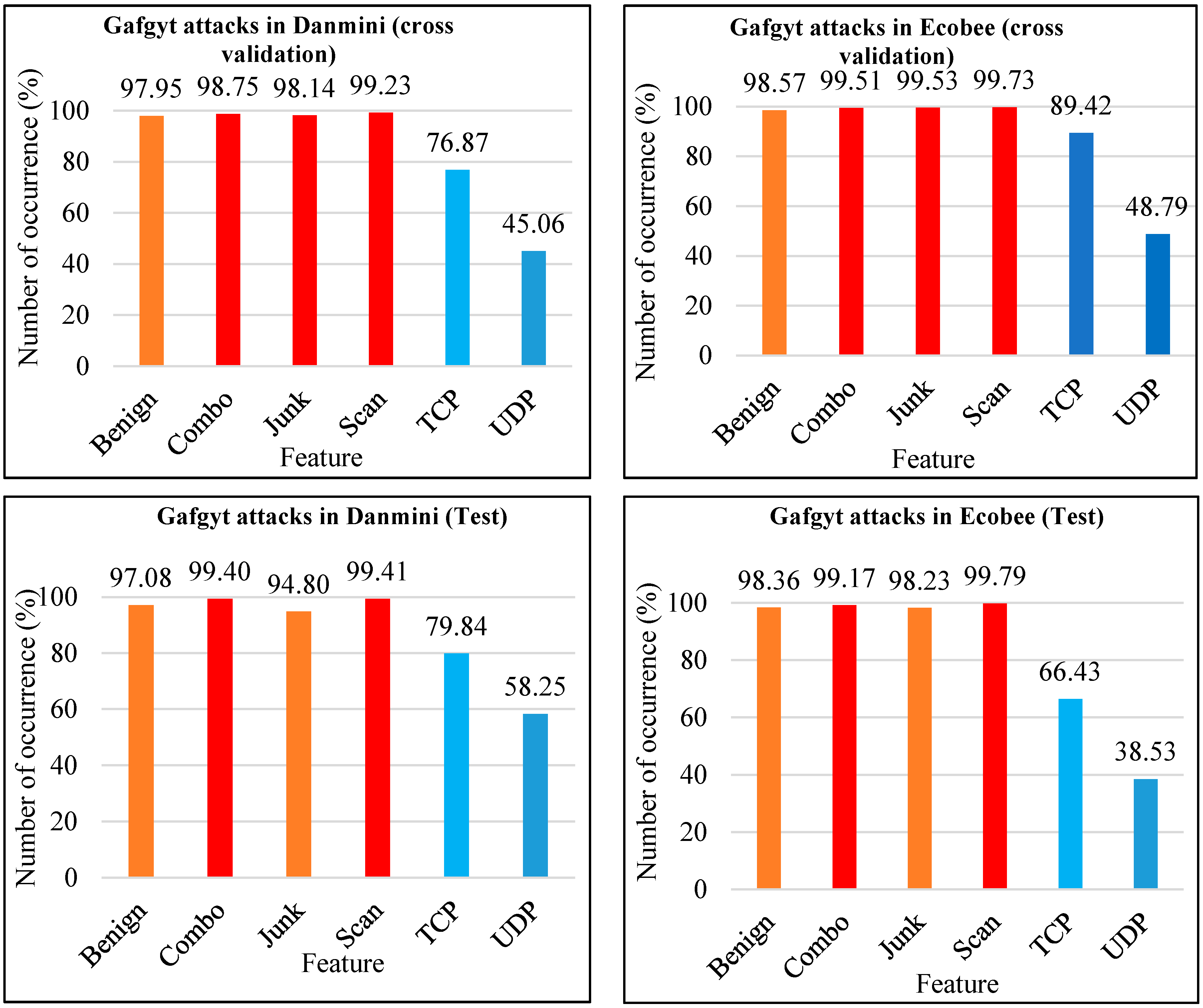
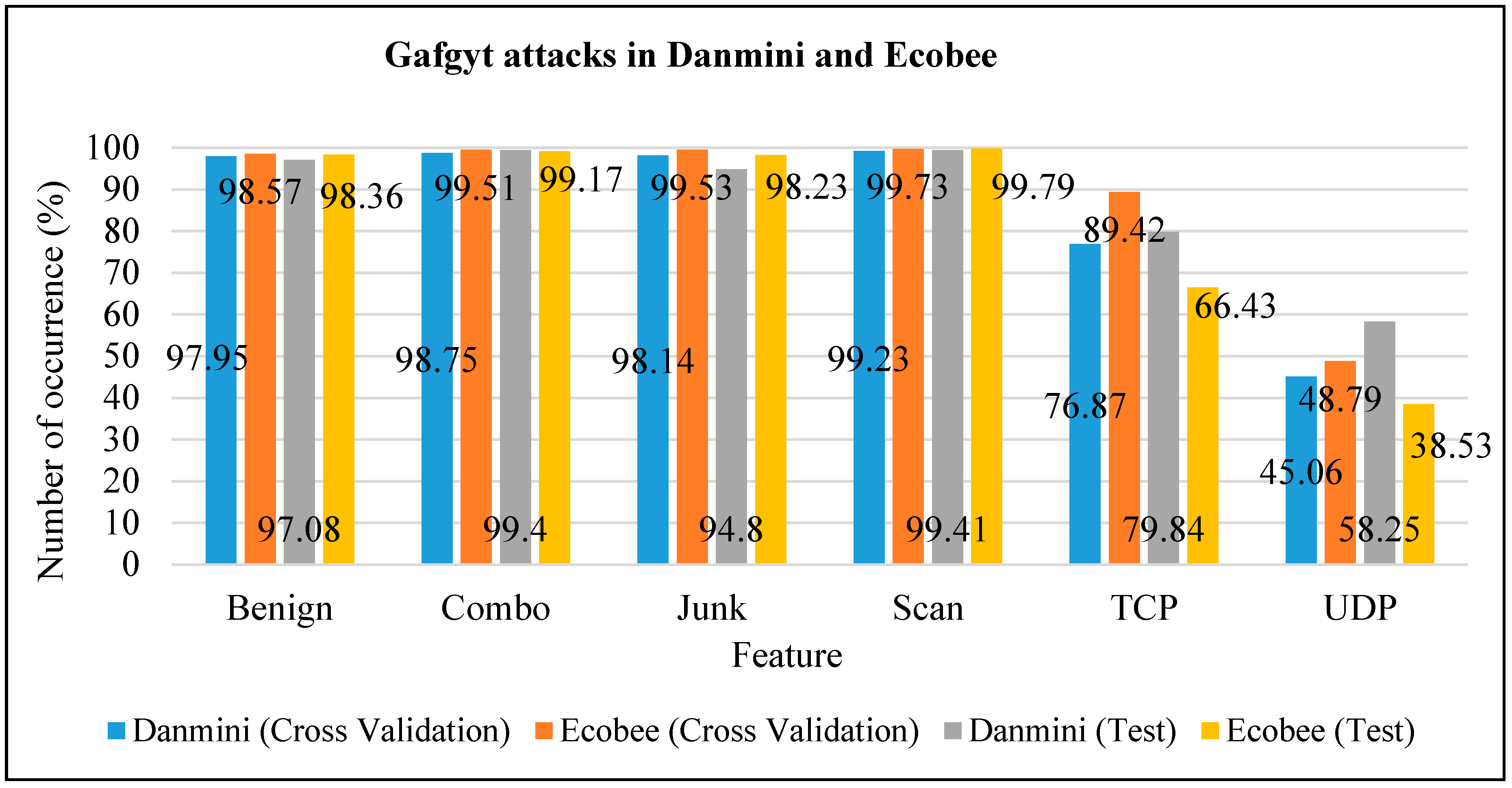
- Gafgyt attacks in Danmini (10-fold cross-validation analysis): The scan feature had the highest number of occurrences (99.23%) compared with other features; it had slightly more than combo and junk, which had 98.75% and 98.14%, respectively. Malware occurrence through benign was less than the scan feature, with a difference of around 2%. With regard to the TCP feature, it was less than benign, with almost 77%. UDP was much lower than all the other features, with only around 45%.
- Gafgyt attacks in Ecobee (10-fold cross-validation analysis): With Ecobee, the feature results for attacks were similar to those in Danmini, with only minor differences. The highest three rates of occurrence were in scan, junk and combo, with 99.73%, 99.53% and 99.51%, respectively. While benign in Ecobee is more frequent than in Danmini, the difference was only 1%. The TCP rate in Ecobee was higher than that in Danmini, at around 89%. UDP remained the lowest rate, as seen in Danmini.
- Gafgyt attacks in Danmini (test analysis): The scan feature had the highest rate among all features, which was more than combo and benign, that had 99.40%, and 97.08%, respectively. It is clear that malware occurrence through combo was slightly similar to scan feature, with a slight difference of only 0.01%. With regard to the TCP feature, it was less frequent than junk with around 80%. UDP was much less frequent than all previous features, with only around 58%.
- Gafgyt attacks in Ecobee (test analysis): With Ecobee, the feature results for attacks were similar to those in Danmini, with only minor differences. The highest rates were for scan and combo: 99.79% and 99.17%, respectively; benign in Ecobee was more frequent than that in Danmini, but with a difference of only 1%. Malware occurrence through junk was slightly similar to that through the benign feature, with a small difference of only around 0.13%. The TCP rate in Ecobee was less than that of reported in Danmini, at around 66%. UDP was again the lowest rate, as in Danmini.
4.3. Malware Behavior in the Honeypot Dataset
- Port: At the beginning of the period, the examined ports in Snort were 5060, which was the most significant port receiving attacks and port 1433, which was the largest segment from November 2017 to January 2018. Port 23 was used by attackers for remote access for the purposes of secret espionage or to damage the system. It was targeted 20 times in October 2017, but target rates declined over the subsequent three months (2 hits in total), and then, increased again to 2 hits in February 2018. Another result of note was in relation to port 22, which is used for remote login; also, some Trojans use this port if there is any vulnerability. In October 2017, port 22 received 41 attacks; this figure rose to 53 attacks in November 2017. It is apparent from the pie charts that attacks reduced significantly to 2 hits and 1 hit, in December 2017 and January 2018, respectively. At the end of the period, in February 2018, the number of attacks rose to 22 hits for the month. In summary, the results show that all the ports discussed in this section experienced a decrease in number of attacks in December 2017 and January 2018 by 50, 84, 18, 51 hits, in ports 5060, 1433, 23, 22, respectively. The number of attacks then rose again in February 2018.
- Protocol: The attack rates on the TCP showed a steady but significant rise over the period from October 2017 to November 2017, while the number of attacks on UDP experienced a downward trend from October 2017 to December 2017. There was no evidence of ICMP attack throughout the period, except in November 2017. The TCP experienced a reduction in the number of attacks by 256 and 270 hits in December 2017 and January 2018, respectively. The UDP also experienced a reduction in the number of attacks by 110 and 109 hits in December 2017 and January 2018, respectively; it then experienced an increased trend in February 2018. In October 2017, the number of attacks on the TCP and UDP were 257 and 172, respectively. The TCP attack rate increased to 303 hits during November 2017, but the UDP rate decreased to 114 hits in that month. Both December 2017 and January 2018 experienced a sharp decrease down to 33 hits for the TCP and 5 hits for the UDP. At the end of the period, the TCP and UDP rates showed a gradual increase and reached 185 hits and 234 hits, respectively. ICMP protocol registered only 12 hits, and that was in November 2017.
- Kippo examines the top passwords, usernames, and it was used to study the behavior of the top attackers.
- Top passwords: These show the rate of use of the most common passwords employed by attackers in unauthorized access attempts. Overall, hackers aimed to obtain privileges to login to a victim’s machine by using the brute force method. This technique works by using a random group of passwords. Usually, this approach can achieve access if system administrators use default or weak passwords. The most used (660 attempts) password attempt was ‘123456’, while the least used was ‘qwerty’, with 164 attempts.
- Top usernames: This provides a summary of the top 10 usernames employed by adversaries attempting to gain access to a vulnerable server. The most substantial rate (3000 times) of username attempts was for ‘root’, while ‘test’ had the lowest rate (102 attempts).
- Top usernames/passwords: This section shows that Kippo did a good job of revealing brute force attacks by attackers and reporting hacking attempts; it shows that the most common combination of usernames/passwords used by attackers was ‘admin: admin’, which was employed 99 times. The combinations ‘admin:1111’, ‘root:1234’ and ‘admin:1234’ were used in only 63 attempts by attackers.
- Top attackers:Table 3 shows the top 10 attacker IP addresses detected by the Kippo honeypot, and the frequencies of those attacks.
5. Discussion
5.1. Malware Behavior in the Phishing Dataset
5.2. Malware Behavior in the Botnet Dataset
5.3. Malware Behavior in the Honeypot Dataset
6. Recommendations and Future Work
- (i)
- Identify malware behavior in web pages: Generally speaking, webpages ranked in the Google index are less prone to malicious behavior; malicious attack through ports is very infrequent. Our findings reported in this paper suggest that if a port is secured and the site is Google indexed, malicious attack from websites can be minimized. Thus, it is recommended that website providers and vendors should identify malware behavior in web pages on a regular basis to make web browsing safe and reliable.
- (ii)
- Analyze malicious behavior of attackers: It is important for vendors such as antivirus providers to analyze the main risky features of malicious behavior on a regular basis in order to identify attackers against webpages. Build appropriate rules and guidelines to avoid them and secure end users over the internet.
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rieck, K.; Trinius, P.; Willems, C.; Holz, T. Automatic analysis of malware behavior using machine learning. J. Comput. Secur. 2011, 19, 639–668. [Google Scholar] [CrossRef]
- Symantic. Internet Security Threat Report; Thycotic: Waterloo, Belgium, 2017. [Google Scholar]
- AV-TEST. Security Report 2017/18: The Independent IT-Security Institute; AV-TEST: Magdeburg, Germany, 2018. [Google Scholar]
- Yousaf, S.; Iqbal, U.; Farooqi, S.; Ahmad, R.; Shafiq, Z.; Zaffar, F. Malware slums: Measurement and analysis of malware on traffic exchanges. In Proceedings of the 2016 46th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Toulouse, France, 28 June–1 July 2016. [Google Scholar]
- Ranjith, G.; Vijayachandra, J.; Prathusha, B.; Sagarika, P. Design and implementation of a defense system from TCP injection attacks. Indian J. Sci. Technol. 2016, 9, 40. [Google Scholar] [CrossRef] [Green Version]
- Canali, D.; Balzarotti, D.; Francillon, A. The role of web hosting providers in detecting compromised websites. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 177–188. [Google Scholar]
- Ceccato, M.; Tonella, P.; Basile, C.; Coppens, B.; De Sutter, B.; Falcarin, P.; Torchiano, M. How professional hackers understand protected code while performing attack tasks. In Proceedings of the 2017 IEEE/ACM 25th International Conference on Program Comprehension (ICPC), Buenos Aires, Argentina, 22–23 May 2017; pp. 154–164. [Google Scholar]
- Batten, L.; Li, G. Applications and Techniques in Information Security. In Proceedings of the 6th International Conference (ATIS), Cairns, QLD, Australia, 26–28 October 2016; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- McAfee. McAfee Labs Threats Report; McAfee: Santa Clara, CA, USA, 2018. [Google Scholar]
- Fleshman, W.; Raff, E.; Zak, R.; McLean, M.; Nicholas, C. Static malware detection & subterfuge: Quantifying the robustness of machine learning and current anti-virus. arXiv 2018, arXiv:1806.04773. [Google Scholar]
- Mangialardo, R.J.; Duarte, J.C. Integrating static and dynamic malware analysis using machine learning. IEEE Lat. Am. Trans. 2015, 13, 3080–3087. [Google Scholar] [CrossRef]
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. Intelligent rule-based phishing websites classification. IET Inf. Secur. 2014, 8, 153–160. [Google Scholar] [CrossRef] [Green Version]
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. Predicting phishing websites based on self-structuring neural network. Neural Comput. Appl. 2014, 25, 443–458. [Google Scholar] [CrossRef] [Green Version]
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. An assessment of features related to phishing websites using an automated technique. In Proceedings of the 2012 International Conference for Internet Technology and Secured Transactions, London, UK, 10–12 December 2012; pp. 492–497. [Google Scholar]
- Meidan, Y.; Bohadana, M.; Mathov, Y.; Mirsky, Y.; Shabtai, A.; Breitenbacher, D.; Elovici, Y. N-BaIoT—Network-Based Detection of IoT Botnet Attacks Using Deep Autoencoders. IEEE Pervasive Comput. 2018, 17, 12–22. [Google Scholar] [CrossRef] [Green Version]
- Shah, M.J. Modern honey network. Int. J. Res. Advent Technol. 2016, 4, 156–162. [Google Scholar]
- Altaher, A. Phishing websites classification using hybrid SVM and KNN approach. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 6. [Google Scholar] [CrossRef]
- Bahnsen, A.C.; Bohorquez, E.C.; Villegas, S.; Vargas, J.; González, F.A. Classifying phishing URLs using recurrent neural networks. In Proceedings of the 2017 APWG Symposium on Electronic Crime Research (eCrime), Scottsdale, AZ, USA, 25–27 April 2017; pp. 1–8. [Google Scholar]
- Dunham, K. Mobile Malware Attacks and Defense; Syngress: Amsterdam, The Netherlands, 2008. [Google Scholar]
- Khonji, M.; Iraqi, Y.; Jones, A. Phishing detection: A literature survey. IEEE Commun. Surv. Tutor. 2013, 15, 2091–2121. [Google Scholar] [CrossRef]
- Abu-Nimeh, S.; Nappa, D.; Wang, X.; Nair, S. A comparison of machine learning techniques for phishing detection. In Proceedings of the Anti-Phishing Working Groups 2nd Annual Ecrime Researchers Summit, Pittsburgh, PA, USA, 4–5 October 2007; pp. 60–69. [Google Scholar]
- Basnet, R.B.; Doleck, T. Towards developing a tool to detect phishing URLs: A machine learning approach. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence & Communication Technology, Ghaziabad, India, 13–14 February 2015; pp. 220–223. [Google Scholar]
- Al-Garadi, M.A.; Mohamed, A.; Al-Ali, A.; Du, X.; Guizani, M. A survey of machine and deep learning methods for Internet of Things (IoT) security. arXiv 2018, arXiv:1807.11023. [Google Scholar]
- Hoang, X.D.; Nguyen, Q.C. Botnet detection based on machine learning techniques using DNS query data. Future Internet 2018, 10, 43. [Google Scholar] [CrossRef] [Green Version]
- Kumara, A.; Jaidhar, C. Automated multi-level malware detection system based on reconstructed semantic view of executables using machine learning techniques at VMM. Future Gener. Comput. Syst. 2018, 79, 431–446. [Google Scholar]
- Katzir, Z.; Elovici, Y. Quantifying the resilience of machine learning classifiers used for cyber security. Expert Syst. Appl. 2018, 92, 419–429. [Google Scholar] [CrossRef]
- Basnet, R.B.; Sung, A.H.; Liu, Q. Feature selection for improved phishing detection. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Dalian, China, 9–12 June 2012; pp. 252–261. [Google Scholar]
- Basnet, R.B.; Sung, A.H.; Liu, Q. Learning to detect phishing URLs. Int. J. Res. Eng. Technol. 2014, 3, 11–24. [Google Scholar]
- AV-TEST. AV-TEST the Independent IT-Security Institute; AV-TEST: Magdeburg, Germany, 2017. [Google Scholar]
- Cert, N.Z. Unauthorised Access. Available online: https://www.cert.govt.nz/businessesand-individuals/explore/unauthorised-access/?topic=unauthorised-access (accessed on 30 September 2017).
- Pandey, A.; Saini, J.R. Attacks & defense mechanisms for TCP/IP based protocols. Int. J. Eng. Innov. Res. 2014, 3, 17. [Google Scholar]
- Li, X.; Wang, J.; Zhang, X. Botnet detection technology based on DNS. Future Internet 2017, 9, 55. [Google Scholar] [CrossRef] [Green Version]
- Cabaj, K.; Gawkowski, P. HoneyPot systems in practice. Przegląd Elektrotechniczny 2015, 91, 63–67. [Google Scholar] [CrossRef] [Green Version]
- Kaur, S.; Kaur, H. Client honeypot based malware program detection embedded into web pages. Int. J. Eng. Res. Appl. 2013, 3, 849–854. [Google Scholar]
- Ramesh, G.; Gupta, J.; Gamya, P. Identification of phishing webpages and its target domains by analyzing the feign relationship. J. Inf. Secur. Appl. 2017, 35, 75–84. [Google Scholar] [CrossRef]
- Perez, C.; Lemercier, M.; Birregah, B.; Corpel, A. SPOT 1.0: Scoring suspicious profiles on twitter. In Proceedings of the International Conference on Advances in Social Networks Analysis and Mining Advances in Social Networks Analysis and Mining (ASONAM), Kaohsiung, Taiwan, 25–27 July 2011; pp. 377–381. [Google Scholar]
- Angrishi, K. Turning internet of things (iot) into internet of vulnerabilities (iov): Iot botnets. arXiv 2017, arXiv:1702.03681. [Google Scholar]
- Singhal, S.; Jena, M. A study on WEKA tool for data preprocessing, classification and clustering. Int. J. Innov. Technol. Explor. Eng. 2013, 2, 250–253. [Google Scholar]
- Boehm, H.-J. How to miscompile programs with “Benign” data races. In Proceedings of the Usenix Conference on Hot Topic in Parallelism, HotPar, San Jose, CA, USA, 26 May 2011. [Google Scholar]
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An ensemble of autoencoders for online network intrusion detection. arXiv 2018, arXiv:1802.09089. [Google Scholar]
- Rehman, R.U. Intrusion Detection Systems with Snort: Advanced IDS Techniques Using Snort, Apache, MySQL, PHP, and ACID; Prentice Hall Professional: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Mphago, B.; Bagwasi, O.; Phofuetsile, B.; Hlomani, H. Deception in dynamic web application honeypots: Case of glastopf. In Proceedings of the International Conference on Security and Management (SAM), Las Vegas, NV, USA, 8 December 2015; p. 104. [Google Scholar]
- Intel. McAfee AntiVirus for Education; Intel: Santa Clara, CA, USA, 2017. [Google Scholar]
- Kelsey, T.; Lyon, B. Introduction to Search Engine Optimization: A Guide for Absolute Beginners; Apress: New York, NY, USA, 2017. [Google Scholar]
- Pochat, V.L.; Van Goethem, T.; Joosen, W. Rigging research results by manipulating top websites rankings. arXiv 2018, arXiv:1806.01156v2. [Google Scholar]
- Evans, M.P. Analysing Google rankings through search engine optimization data. Internet Res. 2007, 17, 21–37. [Google Scholar] [CrossRef] [Green Version]
- Kheir, N.; Tran, F.; Caron, P.; Deschamps, N. Mentor: Positive DNS reputation to skim-off benign domains in botnet C&C blacklists. In Proceedings of the IFIP International Information Security Conference, Marrakesh, Morocco, 2–4 June 2014; pp. 1–14. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier Type | Time | Accuracy | True Positive | False Positive | ROC Area |
|---|---|---|---|---|---|
| Decision stump | 0.05 | 73.0167 | 0.730 | 0.404 | 0.757 |
| Hoeffding tree | 0.83 | 85.9060 | 0.859 | 0.190 | 0.910 |
| J48 | 1.08 | 88.6296 | 0.886 | 0.145 | 0.949 |
| RF | 11.17 | 88.6024 | 0.886 | 0.147 | 0.949 |
| Random tree | 0.20 | 88.2225 | 0.882 | 0.146 | 0.938 |
| REPTree | 0.92 | 87.8697 | 0.879 | 0.153 | 0.946 |
| Dataset Source 1 | ||
| Phishing websites (UCI) | Percentage of attacks (10-fold cross-validation) | Percentage of attacks (test) |
| Training dataset (Bagging) | 97% | 96% |
| Dataset Source 2 | ||
| Detection of IoT botnet attacks N BaIoT (UCI) | Percentage of attacks (10-fold cross-validation) | Percentage of attacks (test) |
| Gafgyt attacks Danmini (bagging) | 86% | 88% |
| Gafgyt attacks Ecobee (bagging) | 89% | 83% |
| Dataset Source 3 | ||
| Honeypot | Percentage of attacks | |
| Snort (IDS) | 25% | Average 35% |
| Kippo (used to find the brute force attacks) | 74% | |
| Glastopf (web application honeypot sensor) | 6% |
| IP Address | Number of Attacks |
|---|---|
| 177.39.121.252 | 8512 |
| 184.106.219.63 | 7532 |
| 186.251.208.49 | 3423 |
| 112.78.4.85 | 3311 |
| 185.25.122.3 | 1580 |
| 193.70.40.191 | 1408 |
| 51.254.123.147 | 1047 |
| 176.53.0.87 | 931 |
| 185.165.29.198 | 873 |
| 183.192.189.133 | 774 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alwaghid, A.F.; Sarkar, N.I. Exploring Malware Behavior of Webpages Using Machine Learning Technique: An Empirical Study. Electronics 2020, 9, 1033. https://doi.org/10.3390/electronics9061033
Alwaghid AF, Sarkar NI. Exploring Malware Behavior of Webpages Using Machine Learning Technique: An Empirical Study. Electronics. 2020; 9(6):1033. https://doi.org/10.3390/electronics9061033
Chicago/Turabian StyleAlwaghid, Alhanoof Faiz, and Nurul I. Sarkar. 2020. "Exploring Malware Behavior of Webpages Using Machine Learning Technique: An Empirical Study" Electronics 9, no. 6: 1033. https://doi.org/10.3390/electronics9061033