Data Quality and Trust: Review of Challenges and Opportunities for Data Sharing in IoT



Abstract
:1. Introduction
2. Data Quality in Shared IoT Data
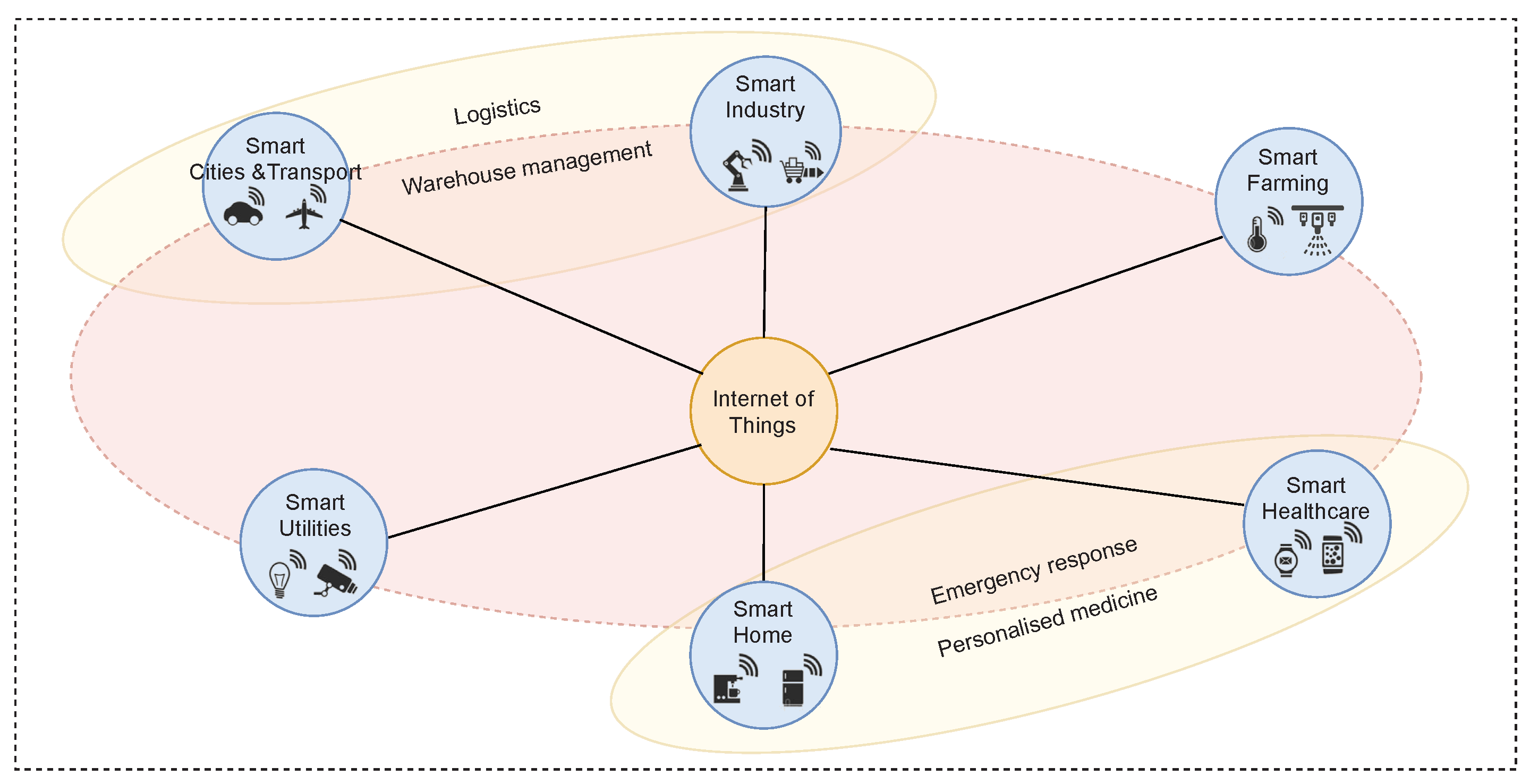
2.1. Data-Shared IoT
- Smart Cities and Transport: Also referred to as intelligent transportation. This incorporates the use of sensors embedded in the vehicles or mobile devices, and devices installed in the city. Applications of this nature span from simple street lighting control, accident prevention, parking and traffic management to more sophisticated applications such as autonomous driving. Applications in this domain must adjust to dynamic environments. Data producers must communicate with each other and exchange information, and be robust to intermittent connectivity [6]. Furthermore, these applications produce large amounts of data and are highly time-sensitive, so any network delays affect the data integrity.
- Smart Utilities: This involves the use of information and communication technology to deliver public services. The most common example is smart grids. It includes classical power grid, renewable energy, monitoring and control of generation to transmission and distribution networks, and integration into smart homes. Data here is heterogeneous, and most of the applications require it to be near real time. Since such networks are widely distributed and deployed in difficult and inaccessible areas, they also suffer intermittent connectivity loss. With the integration of homes with smart meters and buildings, availability and completeness are a concern. Sometimes, decisions are made on incomplete data.
- Smart Industry: This can involve using RFID tags for product tracking, the use of sensors to monitor machinery, and the performance of equipment and sensors to monitor product quality. Poor maintenance and other resource constraints can lead to inaccurate and missing values. Sensors are also affected by limited battery life and replacement difficulty as they are deployed in inaccessible environments. Data must be real-time as responsive actuation is critical for efficiency.
- Smart Farming: Smart farming or precision agriculture is the use of information and communication technology in farming practices such as machinery, equipment and the use of sensors [7]. The main challenge to data in this category is that the sensors used can have variable precision, ambiguities, and poor interoperability [8].
- Smart Healthcare: The use of IoT in the health sector has seen the development of new applications in this sector. Wearables are used to monitor patients, drug delivery systems, personalized treatments based on activity, and tele-based healthcare solutions. Data from this category can be noisy and erroneous as it comes mostly from heterogeneous devices that suffer from battery and accuracy issues. The privacy of the users is a significant concern.
- Smart Home: This involves integrating sensors and actuators into traditional home appliances such as washing machines, light bulbs, and doors to give them the ability to communicate over a network. This helps the homeowner to monitor, manage, and optimize the energy consumption of their home. Data in this domain must be anonymized to protect the privacy of the user. This adds a processing overhead [9] which can cause delays and, in turn, compromise the integrity of the data.
2.2. Data Quality and Data Quality Dimensions (DQDs)
2.2.1. Data Quality
- Intrinsic: This category examines quality properties in the data itself. For example, data quality may be looked at in terms of how a sensed point deviates from an actual point (anomaly detection) or how a particular data point differs from the rest of the data. Efrat et al. [21] proposed a technique that leverages multivariate analysis to ensure data quality of dendrometer sensor networks. Using statistical techniques, defective sensors are identified by comparing a sensor’s readings to an expected reading from a similar, healthy sensors network. Tsai et al. [22] proposed a system to detect abnormal sensors that uses machine learning techniques. This is achieved by training a Bayesian model to predict the values of sensor nodes by comparing them to other correlated sensors. This can detect abnormal sensors in real time.
- Contextual: This looks at quality properties that must be considered within the context of the task at hand. For example, it must be relevant, timely, and appropriate in terms of quantity. This property of data quality has previously been neglected. Faniel et al. [23] emphasize the importance of the context of the data. Contextual information describes the set of interrelated environmental conditions where data is produced. For example, where and how sensors were placed onto the specimen will significantly affect the resulting data quality. To the best of our knowledge, no solutions have considered contextual information inclusion while assessing data quality.
- Representational: This looks at computer systems that store the information. They must ensure that the data is easy to manipulate and understand. Fatimah et al. [18] developed a data quality assessment solution by applying sampling techniques to big-data sets. To reduce computational resources when assessing data quality of big-data sets, they show the importance of sampling in such scenarios. Their results indicate that the samples’ mean quality score is representative of the original data. Much of this category’s work has widely been studied in database management systems [11,12,13].
- Accessibility: This looks at data quality challenges that are as a result of the way users access data system. For example, it could from insecure, unregistered network where new packets can be introduced into the data thus affecting its quality. This was traditionally a problem in database management systems and is been widely studied there [13].
2.2.2. DQD
2.3. The Challenges of Data Quality in Shared IoT
3. Trust and Data Quality
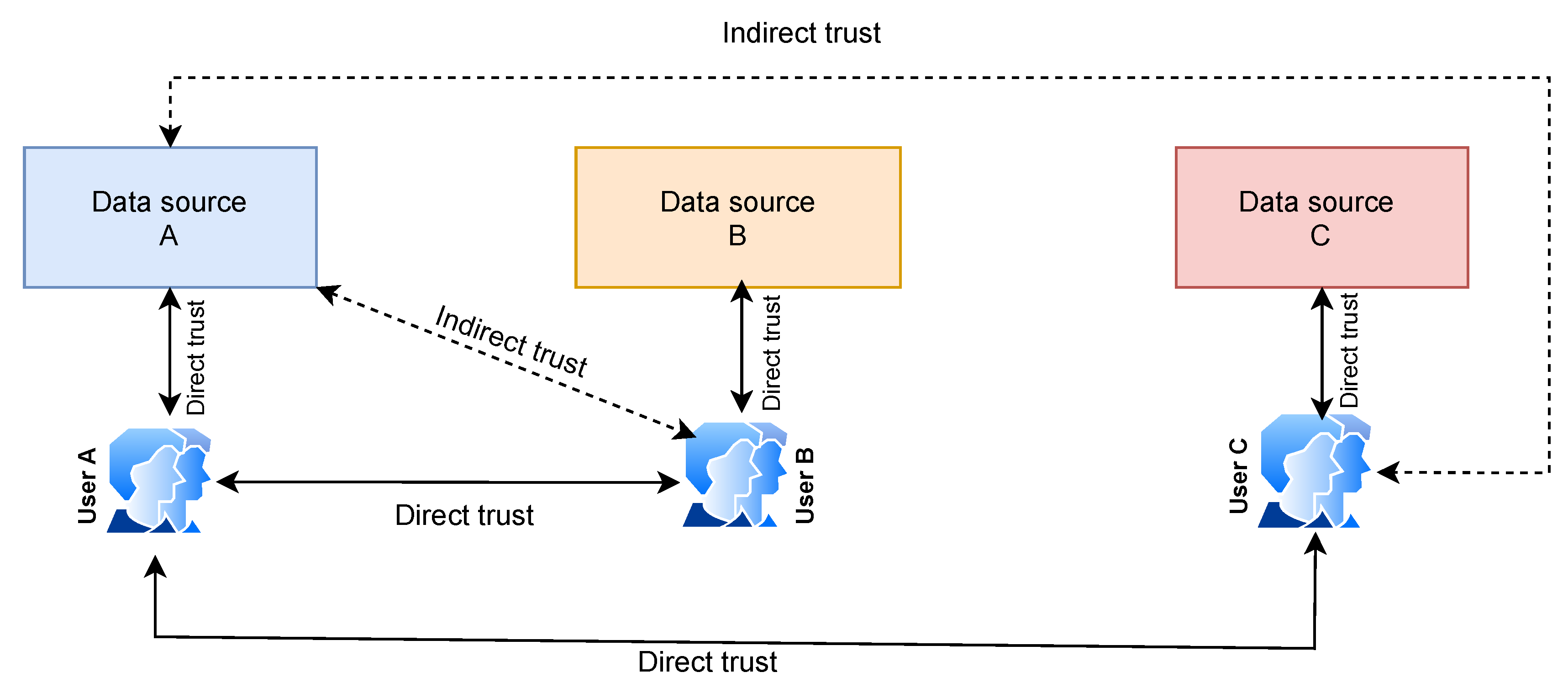
3.1. Trust Definition
3.2. Properties of Trust
3.2.1. Propagative
3.2.2. Dynamic
3.2.3. Subjective
3.2.4. Context-Dependent
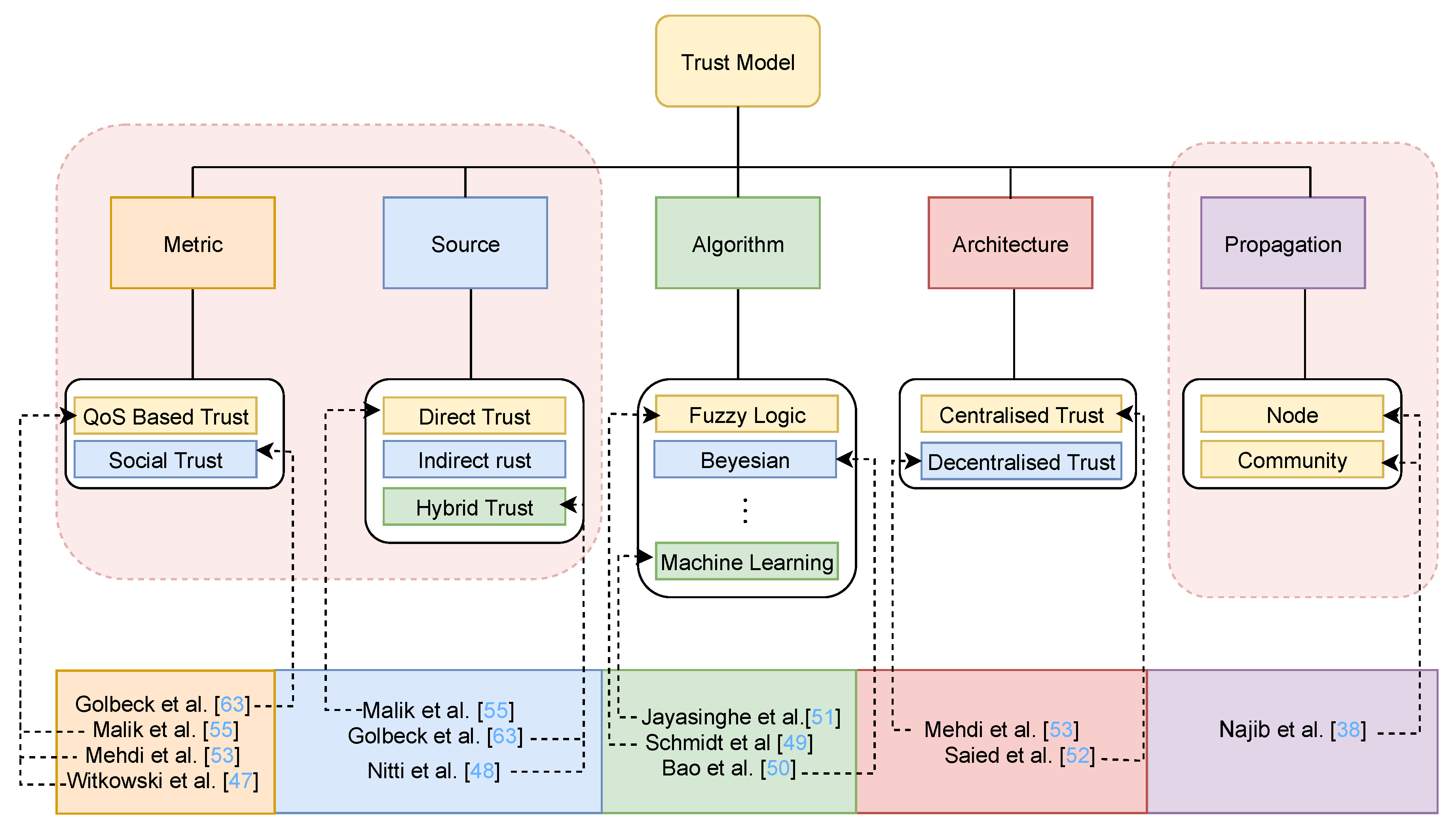
3.3. Components of Trust Model
3.3.1. Metric
3.3.2. Source
3.3.3. Algorithm
3.3.4. Architecture
3.3.5. Propagation
3.4. Trust as a Measure of Data Quality in Various Computing Domains
3.4.1. Multi-Agent Systems
3.4.2. Web Services
3.4.3. Social Networks

3.4.4. P2P Networks
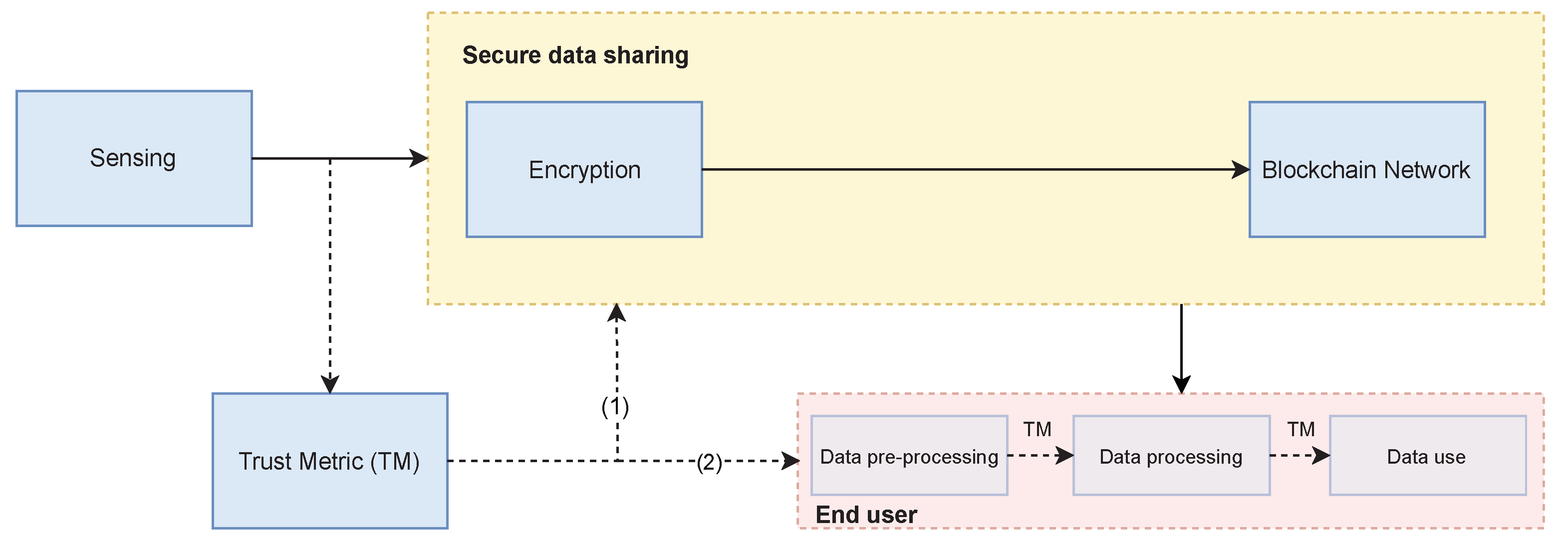
4. Secure Data Sharing with Trust
4.1. Secure Data Sharing in IoT
4.2. Opportunities Trust Brings to Data-Shared IoT
- Trust is personalizable: Trust, in its nature, is subjective. Any actor over time can develop their own trust score from the same process depending on the use-case and importance they attach to, or evaluate the out of, the process. This would then allow each data agent/consumer to re-customize its trust metric by assigning different weights to the features of the metric.As highlighted in Section 2.3, each application has a unique description of data quality; this would mean that we can define one generic trust model that can be adjusted differently for each application and use-case. This can be achieved in several ways, for example, a data consumer can define their own weights to the model, or they can choose different parameters to the model. In other words, each data consumer defines what data quality is to them.
- Trust is dynamic: Trust can increase or decrease with new experiences (usage or interactions). This would allow a data stream/data provider to define a generic metric which provides an innovative way to allow it to build trust over time. This can achieve the following benefits: (1) the evaluation of a data source is not based on an instantaneous metric. It takes into account both past and current events. (2) In application area such as autonomous vehicles, the time between getting the shared data and acting on it is very minimal. However, with a trust-based approach, once a data source has attained a certain level of trust, data quality assessments processes can be run during off-peak times.This is the same property of trust that used in [1] to define an experience score to evaluate data quality without a gold standard using trust. They compare their results to a known metric (statistical measure of dependence between variables) and they conclude that this property of trust can be used to create a metric that can be used in cases without a gold standard.
- Trust is propagative: Once a data source has attained a certain level of trust, we can exploit two factors of that trust: (1) if the quality needs of the application changes, for example, data source moved into a new use-case, i.e., agri-tech data source moving from disease prediction to product delivery chain, where we can infer a certain level of trust without the need to redefine a new metric. (2) if we have a new data source with the same properties, we can infer a certain level of trust without the need to redefine a new metric.This property has been successfully used to propagate trust between nodes and agent. The same property can be used to propagate a trust score across the different stages of the big-data cycle so as to have a single score at the end the is representative of the stages.
5. Open Challenges and Future Directions
- End-to-end data quality assessment: How do we define a data quality assessment framework where all the data quality factors present in the data cycle are represented? Taleb et al. [14] recognizes the need to assess data quality onset (data inception stage) and throughout all the stages of the big-data model. Currently, DQDs are defined for specific stages of the big-data model. For example, data processing is not considered to affect data quality.Factors that affect data quality in shared IoT exist throughout the big-data cycle. For example, during data generation, data quality may be affect by sensor fault, or environmental factors, during data transfer and pre-processing, network outages may impact data quality, and factors such as privacy preservation processing affect data quality during storage and use. There is a need to evaluate data quality at each stage, store such scores or add them as metadata, combine them into a single metric that can be advertised to data consumers in real time.Understanding data quality manifestations at each stage helps us not only to solve data quality challenges but could also inform the usability of tool used at such stages. For example, data quality score at the data generation stage could be used to automatically recalibrate sensors (decrease in quality score over time could be correlated with calibration errors), or data quality scores during modeling can be used to tune automatically tune machine learning models.Challenge 1: Develop a framework to intrinsically assess data quality in shared IoT data systems from data inception to data use. Calculating quality, storing, processing the quality, and advertising the quality.RQ1: How can we calculate data quality at each stage of the IoT chain and combine these different scores into a single metric that can be used to represent data quality in the overall chainRQ2: How can we define an efficient data structure that can store and advertise data quality to the end-user application given that IoT applications are mostly resource-constrained applications.RQ3: How can we define an open framework where we can securely pass and advertise data quality scores to guarantee that data is only transferred to authorized partners.
- The feedback loop between various data collection phases: Data quality assessment is not an isolated calculation between source and consumer, but is affected by all stages and processes in the big-data model chain. The need for end-to-end data assessment is presented above. How the effect of each stage is calculated and represented in the DQD context where no gold-standard reference is available remains a challenge. Result-driven study or comparison is used to calculate or heuristically determine if certain processing or data presents sufficient quality to be used in a given application, i.e., If the application is a prediction model, the accuracy of the model provides proof that the data and data processing is fit for purpose, or otherwise. Furthermore, if better prediction is achieved with one data set over another, this dataset presents higher quality data for the given application. This is equally so if one process, over another, in the data model chain achieves better end result predictions. These insights can be made if the result of the application is measurable, is measured, and is made available to the previous stages in the data model chain. Such feedback is useful for consumers and third-party data service providers. Data consumers of similar applications can build trust and develop applicable data characteristics to curate quality data within the stared data pool. Third-party data service providers can learn the needs of a given application space to develop more beneficial services. This presents a challenge within the framework for data quality management.Challenge 2: Develop a mechanism for feedback of longitudinal result-driven quality standards on used data and processes and apply such learning to the data.RQ4: How may an application result be characterized within the DQD framework?RQ5: Portioning of the feedback result to data or intermediate stages of processing, i.e., Is the result driven by quality of the data or quality imparted through intermediate stages in the data model chain.
- Highly mobile and time-sensitive applications (transport, health): In domain areas such as autonomous vehicles, communications devices are very mobile, and applications should take data assessment actions in real time. As these devices change the working environments, so does the resulting applications of the shared data. For example, consider a smart car moving point from to point . At point , the smart might share its data with a smart city application whose goal is to determine congestion in the city. However, at point , it might share its data with another smart car for a collision avoidance application. To estimate data quality, we would have to define new DQDs as each application has different data quality needs, and data quality is highly subjective. This is a complex and time-consuming process.Challenge 3: Develop an assessment framework where a change in data properties does not require us to define new DQDs and to represent data quality in a general manner throughout the big-data model yet allow subjective handling.RQ6: How might data quality be represented in a general manner throughout the big-data model yet allow subjective handling.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Byabazaire, J.; O’Hare, G.; Delaney, D. Using Trust as a Measure to Derive Data Quality in Data Shared IoT Deployments. In Proceedings of the 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020; pp. 1–9. [Google Scholar]
- Adi, E.; Anwar, A.; Baig, Z.; Zeadally, S. Machine learning and data analytics for the IoT. Neural Comput. Appl. 2020, 32, 16205–16233. [Google Scholar] [CrossRef]
- Keßler, C.; De Groot, R.T.A. Trust as a Proxy Measure for the Quality of Volunteered Geographic Information in the Case of Openstreetmap; Lecture Notes in Geoinformation and Cartography; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Singh, S.; Bawa, S. A privacy, trust and policy based authorization framework for services in distributed environments. Int. J. Comput. Sci. 2007, 2, 85–92. [Google Scholar]
- Byabazaire, J.; O’Hare, G.; Delaney, D. Data Quality and Trust: A Perception from Shared Data in IoT. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Xu, H.; Lin, J.; Yu, W. Smart transportation systems: Architecture, enabling technologies, and open issues. In SpringerBriefs in Computer Science; Springer: Singapore, 2017. [Google Scholar]
- Tzounis, A.; Katsoulas, N.; Bartzanas, T.; Kittas, C. Internet of Things in agriculture, recent advances and future challenges. Biosyst. Eng. 2017, 164, 31–48. [Google Scholar] [CrossRef]
- Pivoto, D.; Waquil, P.D.; Talamini, E.; Finocchio, C.P.S.; Dalla Corte, V.F.; de Vargas Mores, G. Scientific development of smart farming technologies and their application in Brazil. Inf. Process. Agric. 2018, 5, 21–32. [Google Scholar] [CrossRef]
- Potiguara Carvalho, A.; Potiguara Carvalho, F.; Dias Canedo, E.; Potiguara Carvalho, P.H. Big Data, Anonymisation and Governance to Personal Data Protection; ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2020. [Google Scholar]
- Okafor, N.U.; Delaney, D. Considerations for system design in IoT-based autonomous ecological sensing. Procedia Comput. Sci. 2019, 155, 258–267. [Google Scholar] [CrossRef]
- Yeh, P.Z.; Puri, C.A. An efficient and robust approach for discovering data quality rules. In Proceedings of the 2010 22nd IEEE International Conference on Tools with Artificial Intelligence (ICTAI), Arras, France, 27–29 October 2010. [Google Scholar]
- Chiang, F.; Miller, R.J. Discovering data quality rules. Proc. VLDB Endow. 2008, 155, 1166–1177. [Google Scholar] [CrossRef]
- Fan, W. Data Quality: Theory and Practice; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). 2012. Available online: https://www.springer.com/series/558 (accessed on 7 December 2020).
- Taleb, I.; Serhani, M.A.; Dssouli, R. Big Data Quality: A Survey. In Proceedings of the 2018 IEEE International Congress on Big Data (BigData Congress), San Francisco, CA, USA, 2–7 July 2018; pp. 166–173. [Google Scholar]
- Kandel, S.; Heer, J.; Plaisant, C.; Kennedy, J.; Van Ham, F.; Riche, N.H.; Weaver, C.; Lee, B.; Brodbeck, D.; Buono, P. Research directions in data wrangling: Visualizations and transformations for usable and credible data. Inf. Vis. 2011, 10, 271–288. [Google Scholar] [CrossRef] [Green Version]
- Karkouch, A.; Mousannif, H.; Al Moatassime, H.; Noel, T. Data quality in internet of things: A state-of-the-art survey. J. Netw. Comput. Appl. 2016, 73, 57–81. [Google Scholar] [CrossRef]
- Chen, M.; Song, M.; Han, J.; Haihong, E. Survey on data quality. In Proceedings of the 2012 World Congress on Information and Communication Technologies (WICT 2012), Trivandrum, India, 30 October–2 November 2012. [Google Scholar]
- Sidi, F.; Shariat Panahy, P.H.; Affendey, L.S.; Jabar, M.A.; Ibrahim, H.; Mustapha, A. Data quality: A survey of data quality dimensions. In Proceedings of the 2012 International Conference on Information Retrieval and Knowledge Management (CAMP’12), Kuala Lumpur, Malaysia, 13–15 March 2012. [Google Scholar]
- Heravizadeh, M.; Mendling, J.; Rosemann, M. Dimensions of Business Processes Quality (QoBP); Lecture Notes in Business Information Processing; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Wang, R.Y.; Strong, D.M. Beyond accuracy: What data quality means to data consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Vilenski, E.; Bak, P.; Rosenblatt, J.D. Multivariate anomaly detection for ensuring data quality of dendrometer sensor networks. Comput. Electron. Agric. 2019, 162, 412–421. [Google Scholar] [CrossRef]
- Tsai, F.K.; Chen, C.C.; Chen, T.F.; Lin, T.J. Sensor Abnormal Detection and Recovery Using Machine Learning for IoT Sensing Systems. In Proceedings of the 2019 IEEE 6th International Conference on Industrial Engineering and Applications (ICIEA), Tokyo, Japan, 12–15 April 2019; pp. 501–505. [Google Scholar]
- Faniel, I.M.; Jacobsen, T.E. Reusing scientific data: How earthquake engineering researchers assess the reusability of colleagues’ data. Comput. Support. Coop. Work. 2010, 19, 355–375. [Google Scholar] [CrossRef]
- Lee, Y.W.; Strong, D.M.; Kahn, B.K.; Wang, R.Y. AIMQ: A methodology for information quality assessment. Inf. Manag. 2002, 40, 133–146. [Google Scholar] [CrossRef]
- Baqa, H.; Truong, N.B.; Crespi, N.; Lee, G.M.; Le Gall, F. Quality of Information as an indicator of Trust in the Internet of Things. In Proceedings of the 2018 17th IEEE International Conference On Trust, Security And Privacy In Computing And Communications/ 12th IEEE International Conference On Big Data Science And Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 204–211. [Google Scholar]
- Juddoo, S. Overview of data quality challenges in the context of Big Data. In Proceedings of the 2015 International Conference on Computing, Communication and Security (ICCCS 2015), Pamplemousses, Mauritius, 4–5 December 2015. [Google Scholar]
- Redman, T. Data Quality: Management and Technology; Bantam Books, Inc.: New York, NY, USA, 1992. [Google Scholar]
- Pipino, L.L.; Lee, Y.W.; Wang, R.Y. Data quality assessment. Commun. ACM 2002, 45, 211–218. [Google Scholar] [CrossRef]
- Blake, R.; Mangiameli, P. The effects and interactions of data quality and problem complexity on classification. J. Data Inf. Qual. 2011, 2, 1–28. [Google Scholar] [CrossRef]
- Even, A.; Shankaranarayanan, G. Utility-driven configuration of data quality in data repositories. Int. J. Inf. Qual. 2007, 1, 22–40. [Google Scholar] [CrossRef]
- Amicis, F.D.; Barone, D.; Batini, C. An analytical framework to analyze dependencies among data quality dimensions. In Proceedings of the 2006 International Conference on Information Quality (ICIQ 2006), Cambridge, MA, USA, 10–12 November 2006. [Google Scholar]
- Yan, Z.; Zhang, P.; Vasilakos, A.V. A survey on trust management for Internet of Things. J. Netw. Comput. Appl. 2014, 42, 120–134. [Google Scholar] [CrossRef]
- Artz, D.; Gil, Y. A survey of trust in computer science and the semantic web. J. Web Semant. 2007, 5, 58–71. [Google Scholar] [CrossRef] [Green Version]
- Hardin, R. Trust: A Sociological Theory, Piotr Sztompka; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Molm, L.D.; Takahashi, N.; Peterson, G. Risk and trust in social exchange: An experimental test of a classical proposition. Am. J. Sociol. 2000, 105, 1396–1427. [Google Scholar] [CrossRef]
- Huang, F. Building social trust: A human-capital approach. J. Inst. Theor. Econ. (JITE)/Z. Gesamte Staatswiss. 2007, 163, 552–573. [Google Scholar] [CrossRef]
- Najib, W.; Sulistyo, S.; Widyawan. Survey on trust calculation methods in internet of things. Procedia Comput. Sci. 2019, 161, 1300–1307. [Google Scholar] [CrossRef]
- Mui, L. Computational Models of Trust and Reputation: Agents, Evolutionary Games, and Social Networks. Soc. Netw. 2002. Available online: https://dspace.mit.edu/handle/1721.1/87343 (accessed on 7 December 2020).
- Moreland, D.; Nepal, S.; Hwang, H.; Zic, J. A snapshot of trusted personal devices applicable to transaction processing. Pers. Ubiquitous Comput. 2010, 14, 347–361. [Google Scholar] [CrossRef]
- Sherchan, W.; Nepal, S.; Paris, C. A survey of trust in social networks. ACM Comput. Surv. 2013, 45, 1–33. [Google Scholar] [CrossRef]
- Gray, E.; Seigneur, J.M.; Chen, Y.; Jensen, C. Trust Propagation in Small Worlds; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Yu, B.; Singh, M.P. An evidential model of distributed reputation management. In Proceedings of the International Conference on Autonomous Agents, Bologna, Italy, 15–19 July 2002. [Google Scholar]
- Richardson, M.; Agrawal, R.; Domingos, P. Trust Management for the Semantic Web; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Jøsang, A.; Gray, E.; Kinateder, M. Analysing Topologies of Transitive Trust. In Proceedings of the First International Workshop on Formal Aspects in Security and Trust (FAST2003), Pisa, Italy, 8 September 2003. [Google Scholar]
- Wishart, R.; Robinson, R.; Indulska, J.; Jøsang, A. SuperstringRep: Reputation-enhanced service discovery. In Conferences in Research and Practice in Information Technology Series; 2005; Available online: https://dl.acm.org/doi/pdf/10.5555/1082161.1082167 (accessed on 7 December 2020).
- Rousseau, D.M.; Sitkin, S.B.; Burt, R.S.; Camerer, C. Not so different after all: A cross-discipline view of trust. Acad. Manag. Rev. 1998, 23, 393–404. [Google Scholar] [CrossRef] [Green Version]
- Mark, W.; Alexander, A.; Jeremy, P. Experiments in Building Experiential Trust in a Society of Objective-Trust Based Agents; Lecture Notes in Artificial Intelligence (Subseries of Lecture Notes in Computer Science); Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Nitti, M.; Girau, R.; Atzori, L.; Iera, A.; Morabito, G. A subjective model for trustworthiness evaluation in the social Internet of Things. In Proceedings of the IEEE International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Sydney, NSW, Australia, 9–12 September 2012. [Google Scholar]
- Schmidt, S.; Steele, R.; Dillon, T.S.; Chang, E. Fuzzy trust evaluation and credibility development in multi-agent systems. Appl. Soft Comput. J. 2007, 7, 492–505. [Google Scholar] [CrossRef]
- Bao, F.; Chen, I.R.; Guo, J. Scalable, adaptive and survivable trust management for community of interest based internet of things systems. In Proceedings of the 2013 11th International Symposium on Autonomous Decentralized Systems (ISADS 2013), Mexico City, Mexico, 6–8 March 2013. [Google Scholar]
- Jayasinghe, U.; Lee, G.M.; Um, T.W.; Shi, Q. Machine Learning Based Trust Computational Model for IoT Services. IEEE Trans. Sustain. Comput. 2018, 4, 39–52. [Google Scholar] [CrossRef]
- Ben Saied, Y.; Olivereau, A.; Zeghlache, D.; Laurent, M. Trust management system design for the Internet of Things: A context-aware and multi-service approach. Comput. Secur. 2013, 39, 351–365. [Google Scholar] [CrossRef]
- Mehdi, M.; Bouguila, N.; Bentahar, J. Probabilistic approach for QoS-aware recommender system for trustworthy web service selection. Appl. Intell. 2014, 41, 503–524. [Google Scholar] [CrossRef]
- Guha, R.V. Search Result Ranking Based on Trust. US Patent 8,818,995, 26 August 2014. [Google Scholar]
- Malik, Z.; Akbar, I.; Bouguettaya, A. Web Services Reputation Assessment Using a Hidden Markov Model; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Gao, Y.; Li, X.; Li, J.; Gao, Y.; Yu, P.S. Info-Trust: A Multi-Criteria and Adaptive Trustworthiness Calculation Mechanism for Information Sources. IEEE Access 2019, 7, 13999–14012. [Google Scholar] [CrossRef]
- Ramchurn, S.D.; Huynh, D.; Jennings, N.R. Trust in Multi-Agent Systems. Knowl. Eng. Rev. 2004, 19, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Durfee, E.H. Planning in distributed artificial intelligence. Found. Distrib. Artif. Intell. 1996, 231–245. Available online: https://dl.acm.org/doi/10.5555/239297.239314 (accessed on 7 December 2020).
- Papazoglou, M. Web Services: Principles and Technology; Pearson Education: Upper Saddle River, NJ, USA, 2008. [Google Scholar]
- Wang, Y.; Vassileva, J. A review on trust and reputation for web service selection. In Proceedings of the International Conference on Distributed Computing Systems, Atlanta, GA, USA, 5–8 June 2017. [Google Scholar]
- Maximilien, E.M.; Singh, M.P. Toward autonomic Web services trust and selection. In Proceedings of the Second International Conference on Service Oriented Computing (ICSOC’04), New York, NY, USA, 15–19 November 2004. [Google Scholar]
- Boyd, D.M.; Ellison, N.B. Social network sites: Definition, history, and scholarship. J. Comput. Mediat. Commun. 2007, 13, 210–230. [Google Scholar] [CrossRef] [Green Version]
- Golbeck, J. Combining Provenance with Trust in Social Networks for Semantic Web Content Filtering; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Schollmeier, R. A definition of peer-to-peer networking for the classification of peer-to-peer architectures and applications. In Proceedings of the 1st International Conference on Peer-to-Peer Computing (P2P 2001), Linkoping, Sweden, 27–29 August 2001. [Google Scholar]
- Tang, Y.B.; Wang, H.M.; Dou, W. Trust based incentive in P2P network. In Proceedings of the IEEE International Conference on E-Commerce Technology for Dynamic E-Business (CEC-East 2004), Beijing, China, 13–15 September 2004. [Google Scholar]
- Jernigan, S.; Ransbotham, S.A.M.; Kiron, D. Data Sharing and Analytics Drive Success with IoT. MIT Sloan Manag. Rev. 2016. Available online: https://sloanreview.mit.edu/projects/data-sharing-and-analytics-drive-success-with-internet-of-things/ (accessed on 7 December 2020).
- Feldman, L.; Patel, D.; Ortmann, L.; Robinson, K.; Popovic, T. Educating for the future: Another important benefit of data sharing. Lancet 2012, 379, 1877–1878. [Google Scholar] [CrossRef]
- Geoghegan, S. The latest on data sharing and secure cloud computing. Law. Order 2012, 24–26. [Google Scholar]
- Shafagh, H.; Burkhalter, L.; Hithnawi, A.; Duquennoy, S. Towards blockchain-based auditable storage and sharing of iot data. In Proceedings of the CCSW 2017–Proceedings of the 2017 Cloud Computing Security Workshop, co-located with CCS 2017, Dallas, TX, USA, 3 November 2017. [Google Scholar] [CrossRef] [Green Version]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System; Technical Report; Satoshi Nakamoto Institute, 2008; Available online: https://bitcoin.org/bitcoin.pdf (accessed on 7 December 2020).
- Makhdoom, I.; Zhou, I.; Abolhasan, M.; Lipman, J.; Ni, W. PrivySharing: A blockchain-based framework for privacy-preserving and secure data sharing in smart cities. Comput. Secur. 2020, 88, 101653. [Google Scholar] [CrossRef]
- Liu, C.H.; Lin, Q.; Wen, S. Blockchain-enabled data collection and sharing for industrial iot with deep reinforcement learning. IEEE Trans. Ind. Inform. 2019, 15, 3516–3526. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DQD | Definitions |
|---|---|
| Accuracy | The extent to which data is certified error-free, correct or flawless |
| Believability | The extent to which data is regarded as true and credible |
| Objectivity | The extent to which data is unbiased, unprejudiced, and impartial |
| Reputation | The extent to which data is highly regarded in terms of its source or content |
| Appropriate amount of data | The extent to which the volume of data is appropriate for the task at hand |
| Completeness | The extent to which data is not missing and of sufficient breadth and depth for the task at hand |
| Relevancy | The extent to which data is applicable and helpful for the task at hand |
| Timeliness | The extent to which the data is sufficiently up to date for task at hand |
| Value-Added | The extent to which data is beneficial and provides advantages from its use |
| Concise Representation | The extent to which data is compactly represented |
| Ease of Manipulation | The extent to which data is easy to manipulate and apply to different tasks |
| Interpretability | The extent to which data is in appropriate languages, symbols, and units, and the definitions are clear |
| Representational consistency | The extent to which data is presented in the same format |
| Accessibility | The extent to which data is available, or easily and quickly retrievable |
| Access Security | The extent to which access to data is restricted appropriately to maintain its security |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Byabazaire, J.; O’Hare, G.; Delaney, D. Data Quality and Trust: Review of Challenges and Opportunities for Data Sharing in IoT. Electronics 2020, 9, 2083. https://doi.org/10.3390/electronics9122083
Byabazaire J, O’Hare G, Delaney D. Data Quality and Trust: Review of Challenges and Opportunities for Data Sharing in IoT. Electronics. 2020; 9(12):2083. https://doi.org/10.3390/electronics9122083
Chicago/Turabian StyleByabazaire, John, Gregory O’Hare, and Declan Delaney. 2020. "Data Quality and Trust: Review of Challenges and Opportunities for Data Sharing in IoT" Electronics 9, no. 12: 2083. https://doi.org/10.3390/electronics9122083