1. Introduction
Navigation technology is becoming increasingly important in different aspects of daily life. Positioning and navigation technologies for outdoor environments has dramatically developed, a typical example is the Global Positioning System (GPS) [
1,
2]. In densely populated commercial or public places, there is a growing demand for the location navigation, environment awareness and real-time monitoring of people. Moreover, the indoor positioning technology should provide sufficiently accurate location services to the users.
Integration of the Inertial Navigation System (INS) and the GPS is widely utilized to accurately determine the position and the attitude of the moving objects. The GPS has the advantages of providing absolute positioning with long-time stability and mid-level precision. The INS, on the other hand, has a good short-term accuracy and does not rely on any external sources for determining the position, velocity and attitude. However, the INS is prone to severe drift errors, especially when dealing with the commercial-grade systems [
3]. Additionally, the GPS could suffer from signal blockage, interference and multipath. This could result in extended periods of GPS signal outage, which occurs in urban canyons, forests and indoors. What’s worse, the positioning error of GPS would sharply increase especially in indoors. Therefore, a vision system to aid the INS is proposed to enhance the overall solution in such situations and keeping the cost to a minimum level [
4,
5]. The visual positioning is based on the image sequence to achieve the positioning. The feature points are extracted and matched to the acquired image sequence, and the matched feature points are then utilized to solve the transformation relationship of different frame images, and so the motion parameters are estimated. It is also possible to set up the landmarks [
6] and measure their information in advance, and then obtain the vehicular position through the vehicle matching landmarks to achieve the purpose of precisely navigation. In the literature, some works that focus on the INS [
7,
8,
9] and vision had been done.
Martinelli A. [
7] proposed a monocular vision and inertial navigation fusion algorithm to determine the motion parameters of a vehicle moving in 3D unknown environment. The measurement data of the monocular and inertial sensors in a short time interval were fused and estimated. The algorithm outputs the vehicular velocity and attitude, as well as the absolute scale and the deviation that affect the inertial measurement. To reduce the positioning error of the aircraft and loosely couple the monocular vision and inertial sensors positioning data, an integrated Extended Kalman Filter (EKF) method was presented in [
8]. The positioning data of the inertial navigation system is used to compensation the result of visual location. In [
9], aiming at the pose estimation problem of small unmanned aerial vehicles with GPS unavailability, a monocular camera with low-cost Inertial Measurement Unit (IMU) installed on a drone was presented, and the fusion is completed by EKF for navigation.
Recently, Deep Artificial Neural Networks (DANNs) have promoted significant breakthroughs in pattern recognition and machine learning [
10]. Furthermore, Convolutional Neural Networks (CNNs) have been successfully applied to a variety of recognition and classification tasks [
11,
12,
13,
14]. Compared to the standard feed forward neural networks with similarly sized layers, CNNs have much fewer connections and parameters. Hence, they are much easier to be trained [
15]. Deep learning methods allow machines to be fed with raw data and then facilitate automatic discovery of the representations required for detection and classification; in particular, they enable a model to work in an end-to-end manner [
16]. Nowadays, there are some works serve for robot navigation based on deep learning [
17,
18,
19]. They apply the neural network process raw sensors’ data to complete the navigation and obstacle avoidance tasks. Current object recognition methods are strongly dependent on deep learning and large datasets and there are many techniques for preventing overfitting during model training, such as early stopping and dropping out. Therefore, the deep learning is indispensable in image classification.
Tai et al. [
18] proposed an indoor obstacle avoidance solution based on deep network and sensors data. Their robot decisions show a high similarity with human decisions.
Zhu et al. [
19] presented an indoor navigation method based on visual input. Their robot can successfully search for the given target and learn the relationships between actions and environment. They applied deep learning and reinforcement learning technique avoiding the feature matching process during navigating.
Hussein et al. [
20] demonstrated the reinforcement learning based navigation method employ DCNNs and learn directly from the raw visual input. The model they trained can successfully learn the navigation policy from visual input while learning from experience. Through the combination with vision system, the navigation robot could enhance the positioning accuracy while carrying our target recognition, target tracking and target detection tasks.
In this study, a new integrated positioning system including inertial navigation and Machine Learning Enhanced Visual Data (MLEVD) is proposed. Specifically, the 3D Reduced Inertial Sensor System (3D-RISS) based inertial navigation could reduce the costs and maintain a high accuracy rate. The monocular vision oversees the supplement of the positioning requirements of the vehicle. Moreover, in the application of CNNs, a particular class of neural networks that shows a promising performance in object recognition, is utilized to enhance the speed of processor. During the first phase of our approach, the model extracts the landmarks from the visual scene that is input using the camera. Then, the CNN outputs the prediction of the current road or building information by a multi-label classifier. Furthermore, the position of the vehicle can be obtained by template matching with landmarks that are pre-setup and the corresponding size and position are also computed. After that, the EKF method is utilized for the fusion of the location signals from both the neural network model and the inertial sensors to calculate the current position of the vehicle. Finally, the feasibility of the algorithm is verified through the outdoor and indoor experiments. Results show that the proposed approach could effectively reduce the accumulated error of the INS with time while maintaining the positioning error within a few meters for outdoor experiments and less than 1 m for indoor experiments.
2. Formulation
2.1. Convolution Neural Network
The CNNs are similar to the ordinary neural networks. The convolution is performed at the convolutional layers to extract features from local neighborhood on feature maps in the previous layer. It is the core block of a convolutional network. Among the layers of neural network, we use the Rectified Linear Units (ReLUs) [
21] as the activation function to train the model with gradient descent method. One advantage of the ReLUs is that they don’t require the normalization of input to avoid saturating. CNN is a hierarchical network for feature extraction with back-propagating the gradients of errors. Convolution, non-linear activation and pooling are three main operations of the featured hierarchy.
The convolution operation takes the weighted sum of pixel values in a receptive field. Equation (1) shows its mathematical expression:
where
is the pixel value at coordinate
of
—the output feature map,
is the convolution kernel,
is the input and
is related bias vector. The non-linear activation, ReLUs
, is applied after convolution. ReLUs has the piece-wise linear property.
The pooling layer summarizes the outputs of adjacent neurons in the same kernel map. During our training, we applied the overlapping pooling which produces an output of equivalent dimensions as the input. It takes the maximum or average value in an image batch to enhance the robustness of the network. The stride parameter exists in the pooling layer and convolution layer. It is several moving steps over pixels of convolution.
The last layer is an output layer that is chosen based on the task. For binary classification tasks, there are only two neurons needed to compose the output layer. On the other hand, for a multi-label classification tasks, the neurons of output layer are designed based on the actual number of categories. Normally, the output layer is a standard fully connected layer.
To reduce the test errors, there are some works that combine the predictions of many models [
22,
23]. However, for an object recognition task, it is expense to train many models and combine their results. Therefore, we adopt the dropout technique. The dropout is a technique that randomly disconnects the neurons from the current layer to the next layer. This random disconnecting helps the network to reduce the overfitting because no single neuron in the layer will be responsible for predicting a certain class, object, edge or corner. In this research work, 25% dropout rate is adopted to avoid the overfitting.
2.2. Visual System
2.2.1. Camera Calibration and Correction of Distorted Image
Camera calibration is a procedure for estimating the intrinsic parameters
K and radial distortion parameters
P of a given camera. It is usually finished by taking several images of a checkerboard from different angles and different distances. From these images, and given the size of a checkerboard square, the intrinsic parameters can be estimated. Using these parameters can achieve the purpose of correcting the distortion of the picture. The method is described with details in the literatures [
24,
25,
26].
The checkerboard of camera calibration is shown in
Figure 1. The side length of each square is 4 cm. After calibration
K and
P are solved as:
The distortion can be corrected by tuning the parameters of
K and
P.
Figure 2 shows the comparison between the original image and the correcting distortion image. It can be demonstrated that the straight lines in the picture become no longer curved after correcting distortion especially at the edges of the image.
2.2.2. Template Matching
Images are extracted from the video stream captured by a camera on-board the vehicle. For each image, a smaller scanning block with several pixels (width and height), are swept from the top left corner to the bottom right corner. The similarity between the part of the image within the scanning block and a predetermined landmark from the pre-captured image is computed. When a good match is searched, the pixel location of the landmark in the extracted image is recorded. This pixel location is then compared with the pixel location of the landmark in the original pre-captured image. Given that the two-pixel locations are within a distance threshold, we determine our position as the original pre-captured known image position. There are six methods for the determination: matching by difference of squares, normalizing the difference of squares, determining the correlation, normalizing the correlation, calculating the correlation coefficient and normalizing the correlation coefficient [
27].
Each matching method could provide a decision area of the same size as the template and determine the position of the area. Next, we determine whether the results of the six methods are consistent.
Once the trajectory commences, the top left corner (, ) of the best cross correlation match R(, ) is determined for each method. The best match for the landmark position from each method is (, ), where m = 1, 2, 3, 4, 5, 6.
Next, the distance between the landmark locations in pixels as determined from each method is computed (
;
i = 1, 2, 3, 4, 5, 6;
j = 1, 2, 3, 4, 5, 6;
i ≠
j):
If ≤ α, then the results of method i and method j are taken to be the same. Let S be the number of elements in that satisfy the condition ≤ α. For a small α, if S is large, we can conclude that the matching algorithm is precise. If S = 15, the results of all methods are the same. Within the extracted image sequences captured by the vehicle camera, the image with the largest S is taken to be the correctly matched image. However, if S is too small, we conclude that there is no match.
2.2.3. Landmark Chosen
First, the characteristics of the driving recorder are measured. Because the linearity of the image size and distance recorded by the driving recorder is low, the proportional relationship between the distance from the camera to the landmark and the size of the landmark is a fixed value in one image.
The landmark is chosen as in
Figure 3. The image size is 1920 × 1080. The coordinates of the upper left corner are (0, 0) while those of the lower right corner are (1920, 1080). The red box in the image is the set landmark. The real size is 1.2 m × 1.2 m. The size of the landmark in the image is 432 × 432. The distance between the landmark and the camera is 6 m. When the distance is 7 m, the size of the landmark in the image is 379 × 379 and so on. The proportional relationship is shown in
Table 1. Through this ratio, the size of pixels on the picture can be obtained for the landmarks of different sizes at different distances. Both the coordinate location and the size of every landmark are previously measured by GPS receiver and ruler respectively.
The landmarks are usually limited to the middle of the image, and they are generally set at the end of the straight road, it is considered that the signpost position is directly in front of the carrier and the experimental error is within an acceptable range. If the area is out of a fixed region of the picture, this matching is judged as invalid. If the area becomes smaller, the higher positioning accuracy would reach and the matched landmarks are less and less. For the same landmark, at least one template with a size can be successfully matched to obtain the position information. The coordinate of the landmark is (
), the azimuth of the landmark is
, and the distance between the landmark and the carrier is
d. Therefore, the coordinate of the carrier, (
,
), is given by
where
R is the radius of the Earth.
For landmarks that are not easy to be computed directly, their locations can be calculated by other point locations that is easy-to-computed using Equations (3) and (4), such as the landmarks in indoor environment.
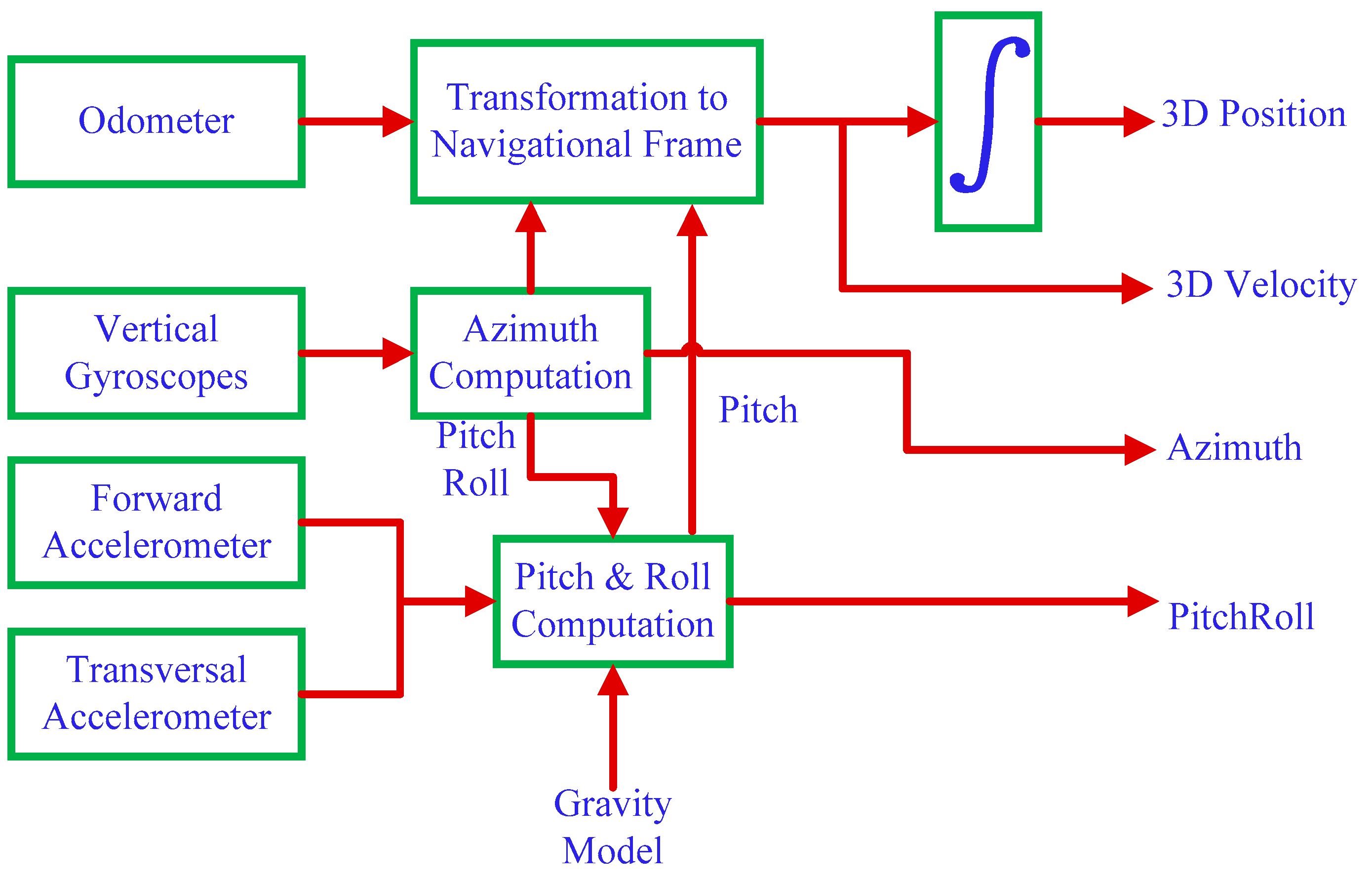
2.3. 3D-RISS Mechanization
The IMU mechanization is performed using a 3D-RISS, which employs an odometer, a uniaxial gyroscope and a dual-axial accelerometer. It has been shown [
28,
29,
30] that the 3D-RISS algorithm outperforms the conventional method of complete mechanization that uses tri-axial gyroscopes and accelerometers. The dead-reckoning position estimation from the 3D-RISS mechanization is then integrated with the vision data using an EKF [
31,
32,
33]. The detailed results of the integration are presented in the next section.
During the 3D-RISS mechanization process, the pitch angle of the vehicle is calculated using the forward accelerometer output information. The pitch angle
p is calculated as
where
is the forward accelerometer measurement,
aod is the odometer rate of change of velocity and
g is the acceleration due to gravity.
The schematic diagram of 3D-RISS mechanization is shown in
Figure 4.
The roll angle of the moving vehicle
r is calculated using the transversal accelerometer information
, the azimuth gyroscope measurement
and the odometer velocity information
.
The azimuth angle
is given by
where
ωie is the Earth rotation rate,
is east velocity,
φ is the latitude,
h is the altitude of the vehicle and
is the normal radius of curvature of the Earth’s ellipsoid.
Then, the local-level frame velocity is given by
where
,
, and
denote the East, North and Upward velocities respectively, which are transformed from the vehicle’s speed along the forward direction
v.
The 3D position is then obtained by
where,
,
, and
are the Altitude, Latitude and Longitude calculated by 3D-RISS, respectively.
R is the meridian radius of curvature of the Earth’s ellipsoid.
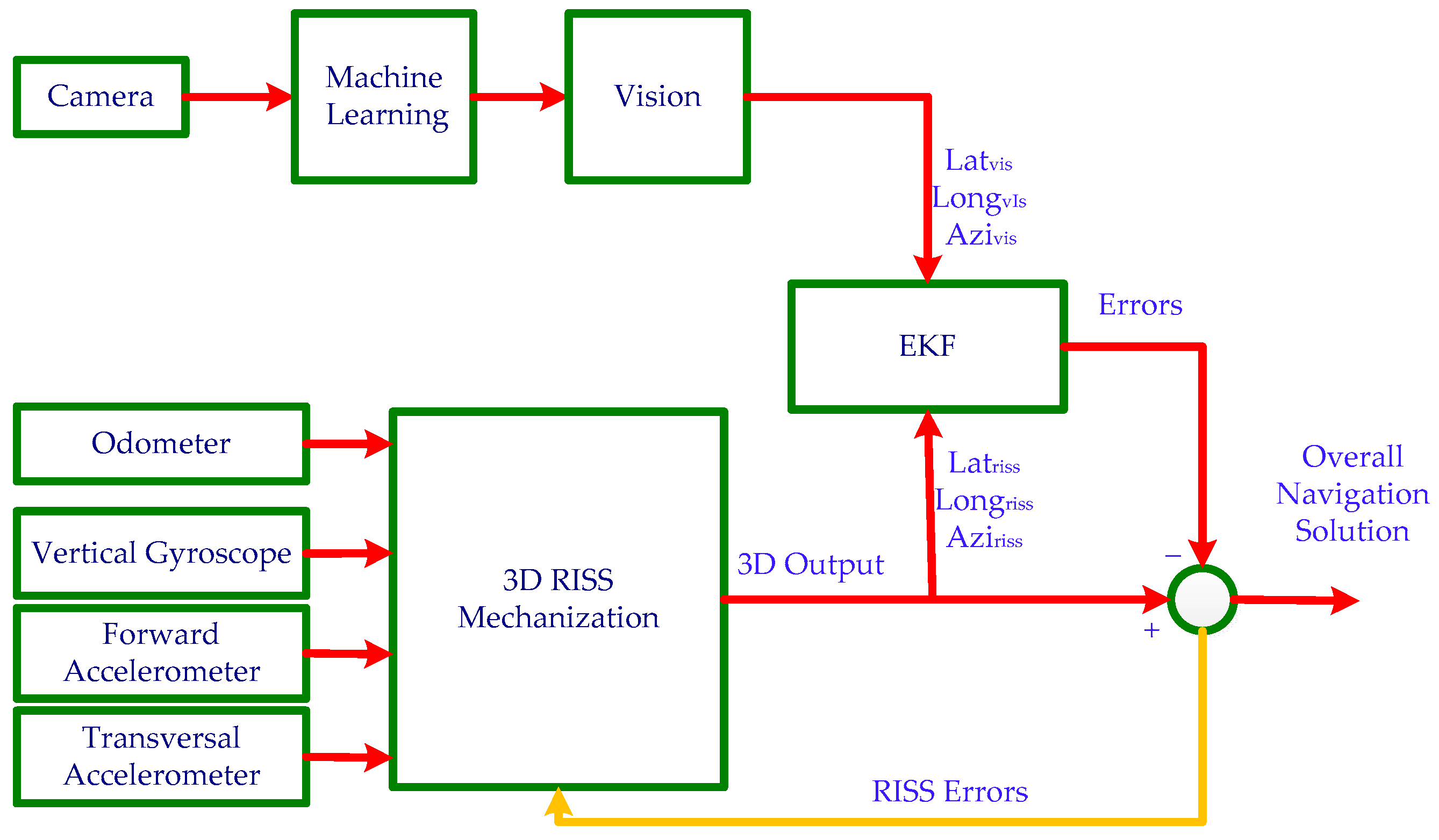
2.4. Kalman Filter Design of 3D-RISS/MLEVD Integration
The block diagram of the 3D-RISS/MLEVD integrated navigation system is shown in
Figure 5.
Through template matching, the camera can acquire the absolute Latitude, Longitude and azimuth angle of the robot when it passes the landmarks. The 3D-RISS algorithm calculates the robot position, velocity and orientation based on the IMU and odometer data. A Kalman filter integrates this information with the position and azimuth update from the camera.
The error state vector of the Kalman filter is defined as
where
is the Latitude error,
is the Longitude error,
is the Altitude error,
is the East velocity error,
is the North velocity error,
is the Upward velocity error,
is the azimuth error,
is the error in acceleration derived from odometer measurements and
is the error due to the gyroscope bias.
The motion Equations (8) and (9) are linearized by Taylor’s series expansion and only the first-order terms are retained [
34,
35]. The state transition matrix
F is formulated below.
Fab identifies each non-zero element in matrix
F, where the subscript
a denotes the row and
b denotes the column of the matrix.
The drift error of the gyroscope and the error in the acceleration, which occurs because of the odometer, are modeled by first-order Gauss–Markov processes as given below [
36]:
where
β and
σ are the reciprocal of the correlation time and the standard deviation of the respective errors.
The overall system dynamic matrix
F is given by
The measurement model that relates the 3D-RISS system estimate to the vision-based solution is given by
where
H that relates the system state vector to the observations, is given by
and
Z can be written as
where
Latvis,
Longvis, and
Azivis are the Latitude, Longitude and azimuth determined by the vision, while
Latriss,
Longriss, and
Aziriss are the Latitude, Longitude and azimuth estimated by the 3D-RISS.
After the complete system model and measurement model are established, the EKF error state vector and covariance matrix are utilized to implement the prediction step. When a landmark is detected, the Kalman gain is calculated and the error state vector is updated accordingly.
4. Conclusions
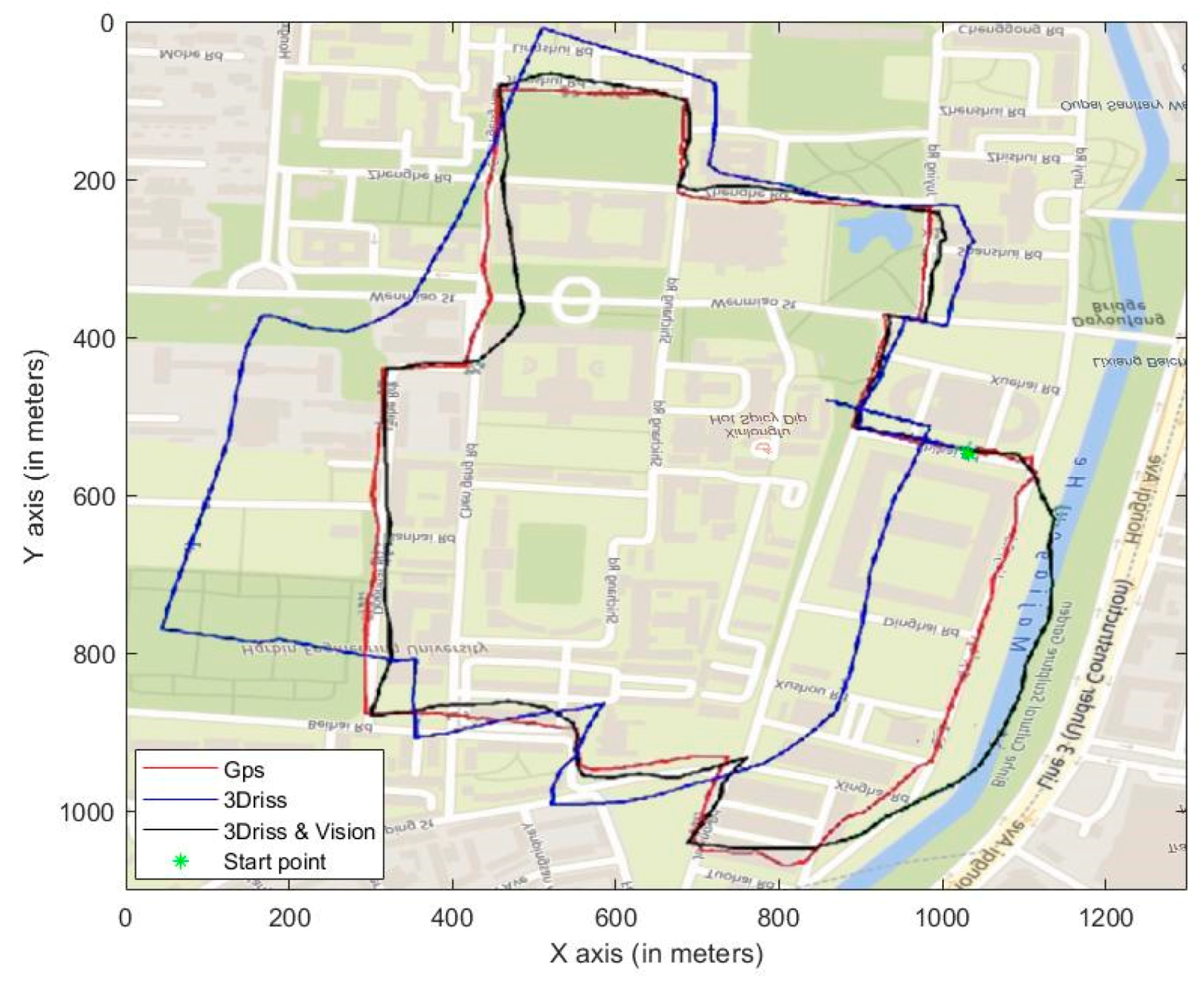
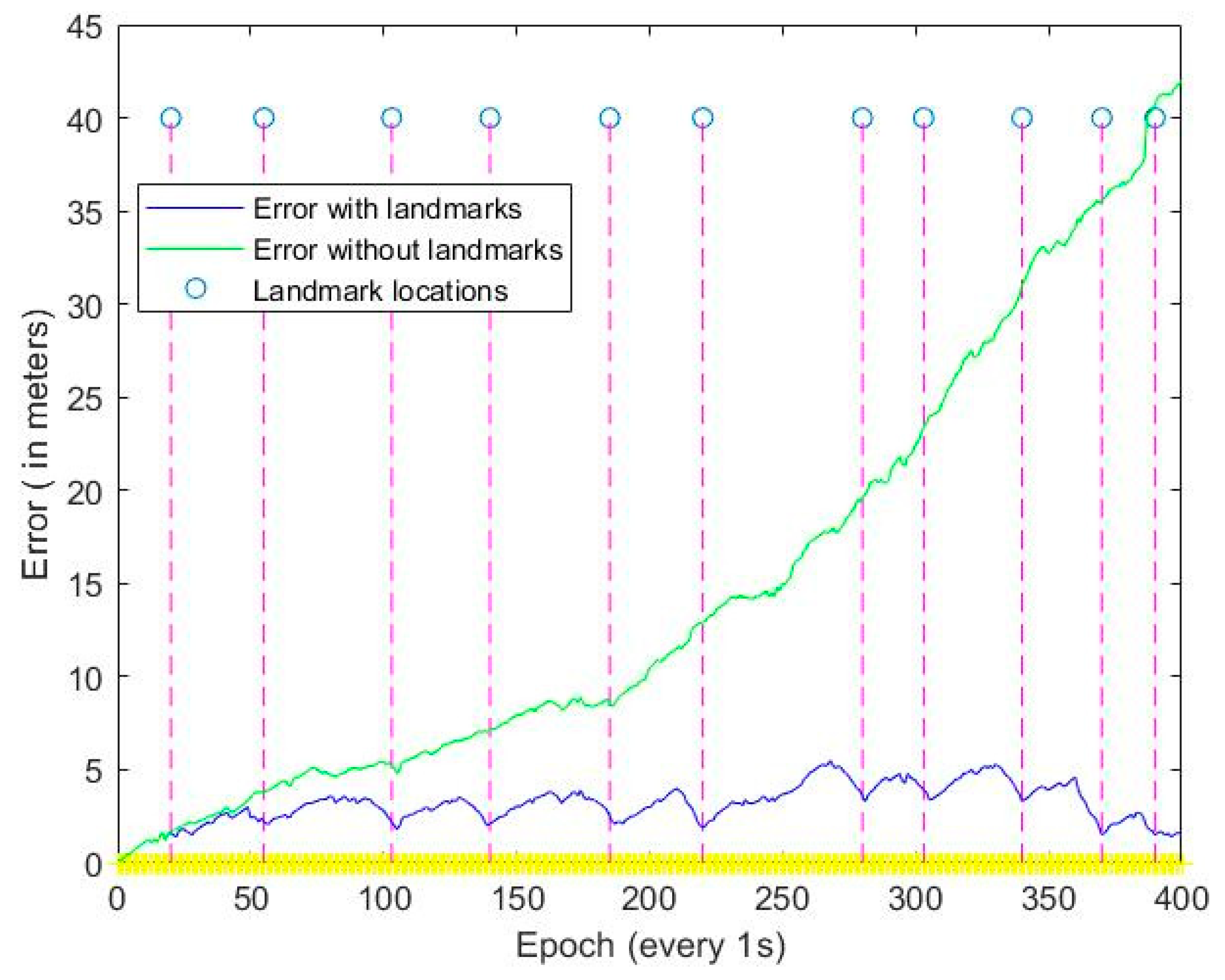
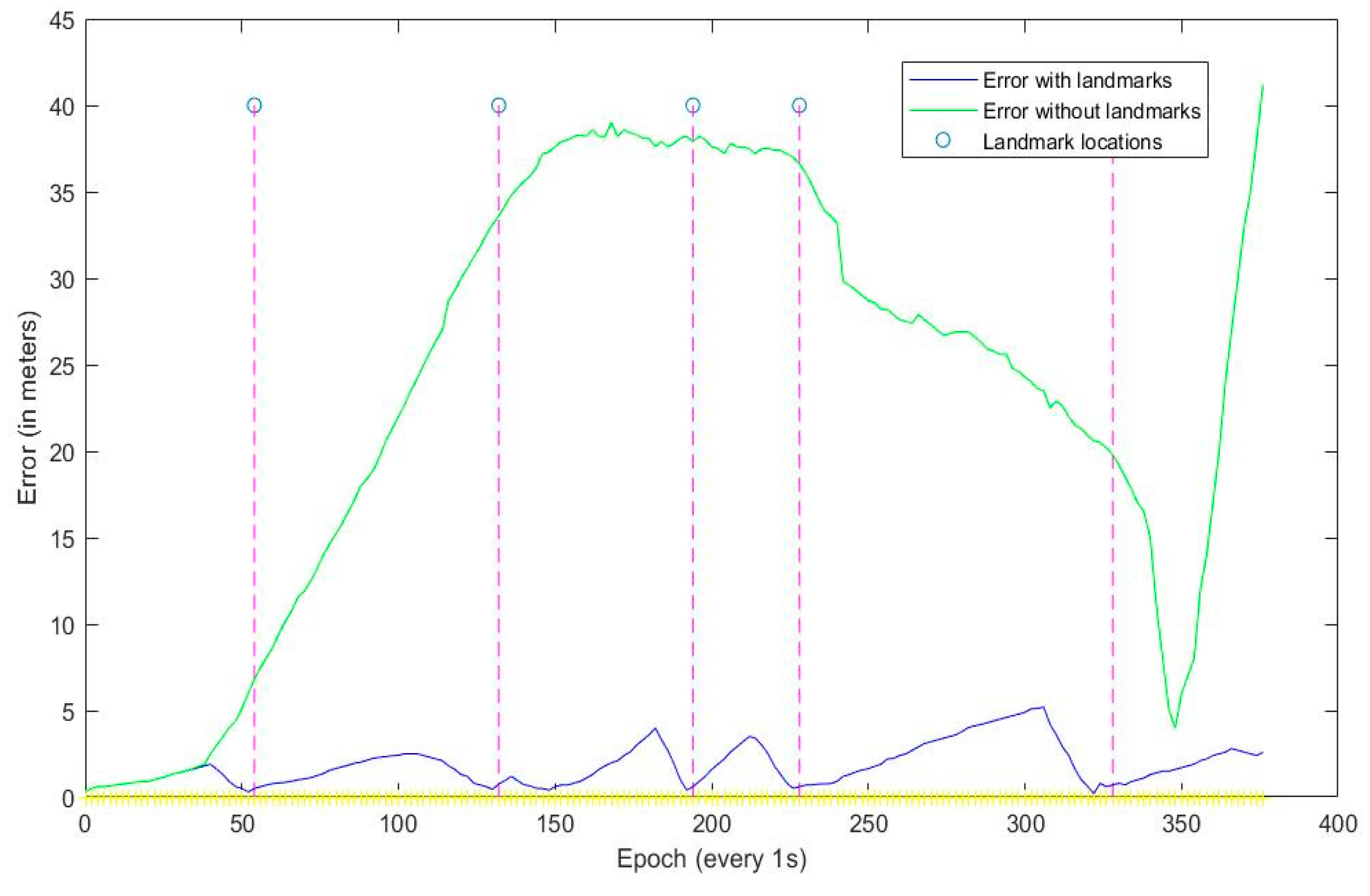
By using landmarks at known positions, a feasible and accurate vehicular navigation solution was proposed for challenging the situations where GPS signal is not available over extended periods of time. Specifically, the template matching technology was utilized to detect the presence of the landmarks, and every time a landmark was detected, the location and azimuth angle of the vehicle was fed into an EKF. By using this method, over most of an indoor trajectory, the vehicular position was accurately estimated to be within the range of the map. This study revealed that the proposed integration of the 3D-RISS/MLEVD could provide the accurate location information. Moreover, the proposed 3D-RISS/MLEVD vehicular navigation technology was conducted by an outdoor experiment the high-precision GPS positioning only used as a benchmark.
Results showed that the trajectory provided by the visual/inertial integrated navigation system is closer to the referenced GPS trajectory than the trajectory provided by inertial navigation alone. Through the indoor experiment, a set of low-cost and low-precision INS with visual can achieve the precision of high-precision INS in challenging environments such as in outdoor satellite signal outage occasions or in indoor environment. By incorporating machine learning, the system could capture the landmark information more quickly and accurately, which increases its potential for real-time positioning application. The advantages of this system are low-cost, high-accuracy and suitable for environments without GPS and simple operation. However, one of its disadvantages is that it needs a lot of preliminary work such as setting landmarks and getting their information. Another disadvantage is the light intensity sometimes would influence the visual positioning effect, which could be compensated by collecting large amounts of data under different lighting conditions.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}