A Deep Learning Model for Snoring Detection and Vibration Notification Using a Smart Wearable Gadget

Abstract
:1. Introduction
- About 75% of people who snore suffer from disrupted breathing during sleep for short periods—known as obstructive sleep apnea (OSA) [3]. Severe sleep apnea carries a significant risk of early death, but even mild to moderate sleep disorders can be related to heart disease, diabetes, reduced sexual function, obesity, gastroesophageal reflux disease, arrhythmia (irregular heart rhythm), headache, nocturia (wake at night several times to urinate) and stroke [4]. The proposed gadget will notify the snorer by vibration and compel them to sleep on their side. Moreover, the logged snoring data can be used to diagnose and monitor OSA and other diseases by the physicians, as discussed in [5,6,7,8].
- Snoring interferes with sleep quality and the sleep quantity of the individual who snores and anyone who shares the same sleeping space. Poor quality and insufficient sleep reduce memory, thinking skills, and the ability to manage conflict. Lack of sleep can make a person irritable, short-tempered, and depressed [9]. The proposed gadget will reduce snoring, increase sleep quality, and facilitate better mental health.
- In the United States, insufficient sleep and sleep disorders account for $411 billion in economic losses and represent 2.28% of the country’s gross domestic product (GDP) annually [10]. This device can improve sleep quality and reduce economic loss.
2. Materials and Methods
2.1. Deep Learning Model for Snoring Detection
2.1.1. Dataset Generation
2.1.2. Feature Extraction
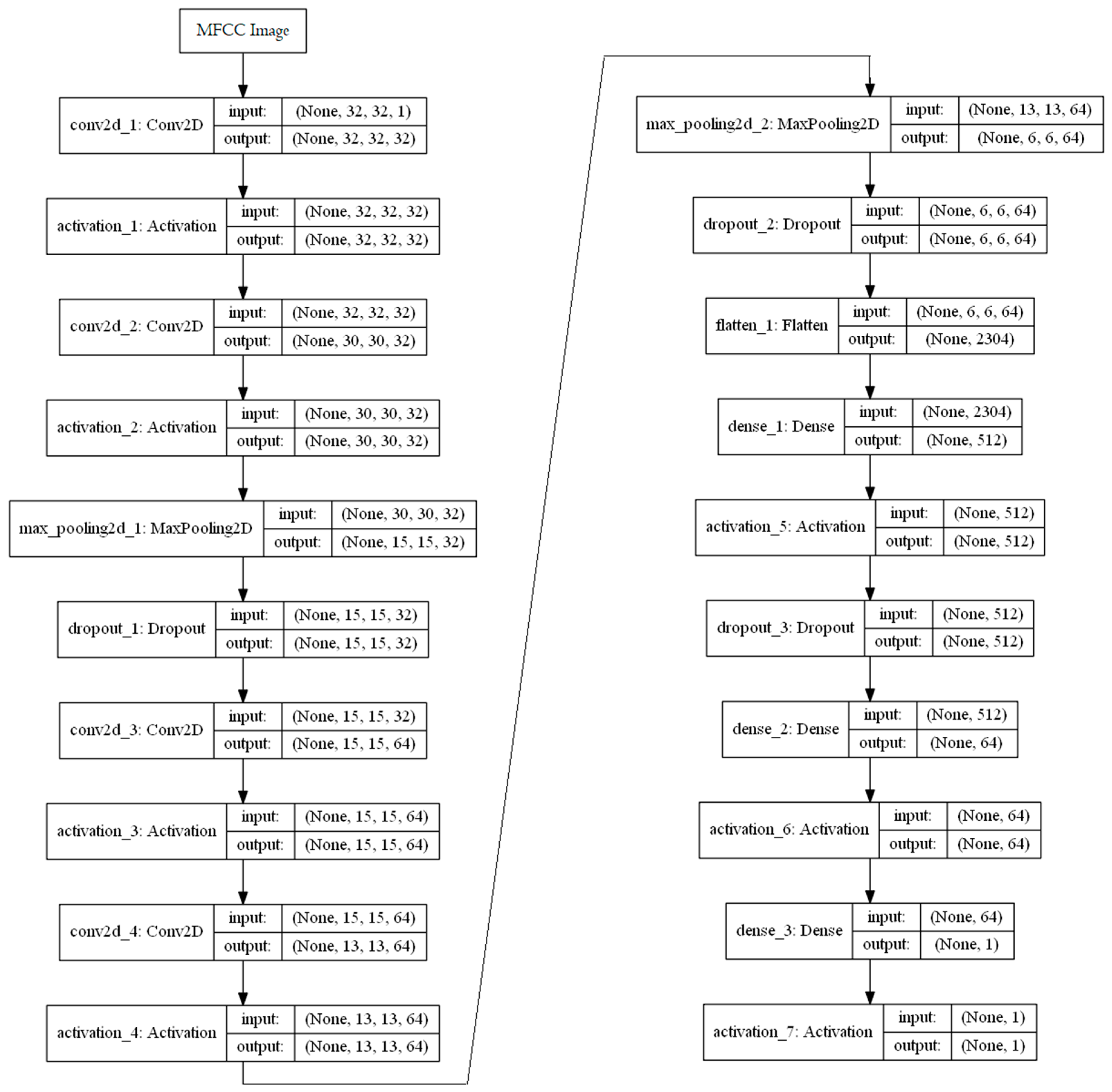
2.1.3. Convolutional Neural Network Architecture
- MFCC Image: The MFCC image is a tensor of size (32, 32, 1). The data type of the image pixel is converted to floating-point. To normalize the pixel values, the mean and the standard deviation of the training dataset is calculated and saved in a file. Then from all images of the dataset, the mean is subtracted from each pixel value and then each pixel value is divided by the standard deviation.
- Convolutional Layer: A 2-D convolutional layer applies sliding convolutional filters to the input. The layer convolves the input by moving the filters along the input vertically and horizontally and computing the dot product of the weights and the input and then adding a bias term [37]. In the proposed model, four convolutional layers are used having filter sizes of 3 × 3. The filters are initialized with random values and they are learnable network parameters. For instance, in Figure 3, in the conv2d_1 layer, there are 32 filters of size 3 × 3 with padding— thus they produce 32 output layers having the same height and width of the input layer. In the proposed model, conv2d_1 and conv2d_3 use padding to make the output size as same as the input size; whereas conv2d_2 and conv2d_4 do not use padding.
- Activation Layer: The convolutional layers and the dense layers (except the last dense layer) are followed by a nonlinear activation function—the rectified linear unit (ReLU) [38]. A ReLU layer performs a threshold operation on each element, where any value less than zero is set to zero.
- Max Pooling Layer: A max-pooling layer performs down-sampling by dividing the input into rectangular pooling regions and computing the maximum of each region [39]. In the proposed model, the dimensions of the pooling region are set to 2 × 2.
- Dropout Layer: A dropout layer randomly sets input elements to zero with a given probability. This operation effectively changes the underlying network architecture between iterations and helps prevent the network from overfitting [40]. No learning takes place in this layer. In the proposed network architecture, three dropout layers are used to prevent overfitting of training data within a few epochs. The dropout probabilities for layers 1–3 are 0.25, 0.25, and 0.50, namely.
- Flatten Layer: A flatten layer collapses the spatial dimensions of the input and make it a single column vector. In this model, the flatten layer converts the (6, 6, 64) tensor to a one-dimensional vector of size 2304.
- Loss Function and Optimizer: The last fully connected layer, dense layer 3, combines the features to classify the images. Therefore, the output size of the last dense layer is set to one for binary classification and it is followed by the Sigmoid [43] score function. A loss function quantifies the agreement between the predicted scores and the ground truth labels and an optimizer tries to reach the global minima where the loss function attains the least possible value for the network parameters. In the proposed model, the binary_crossentropy loss is calculated and RMSprop [44] optimizer is used.
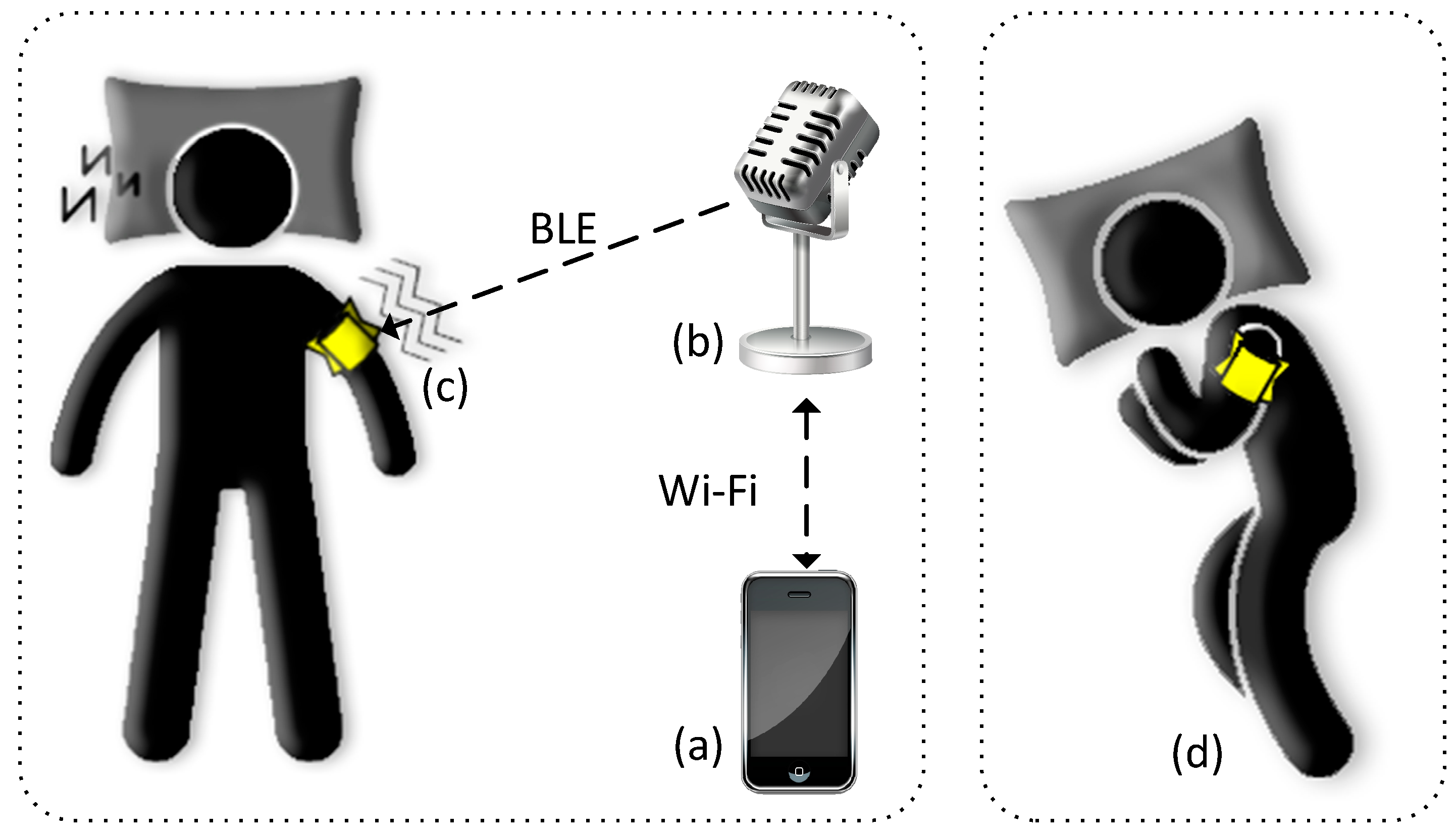
2.2. Prototype System Architecture
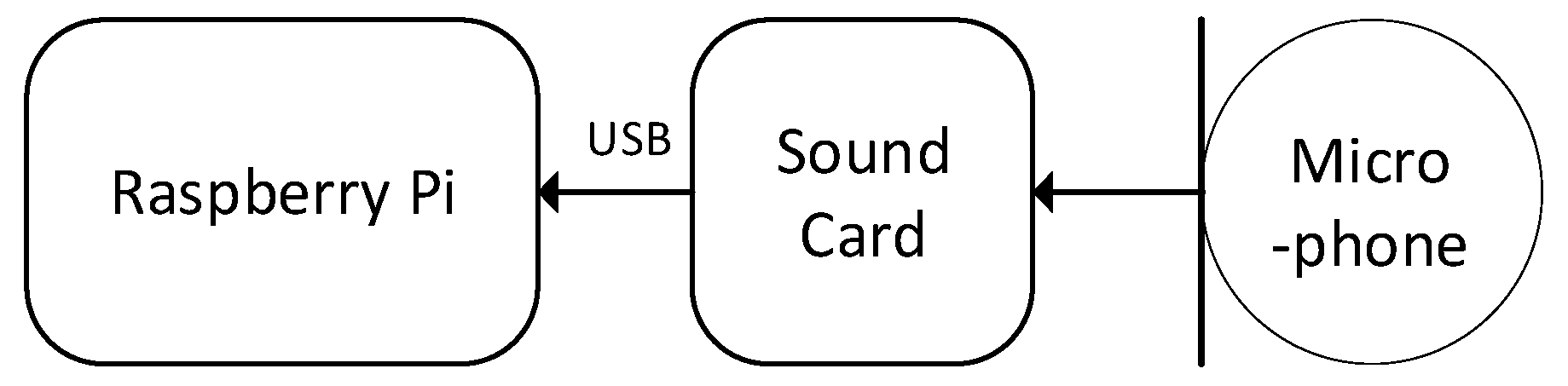
2.2.1. Listener Module
2.2.1.1. Hardware
2.2.1.2. Firmware
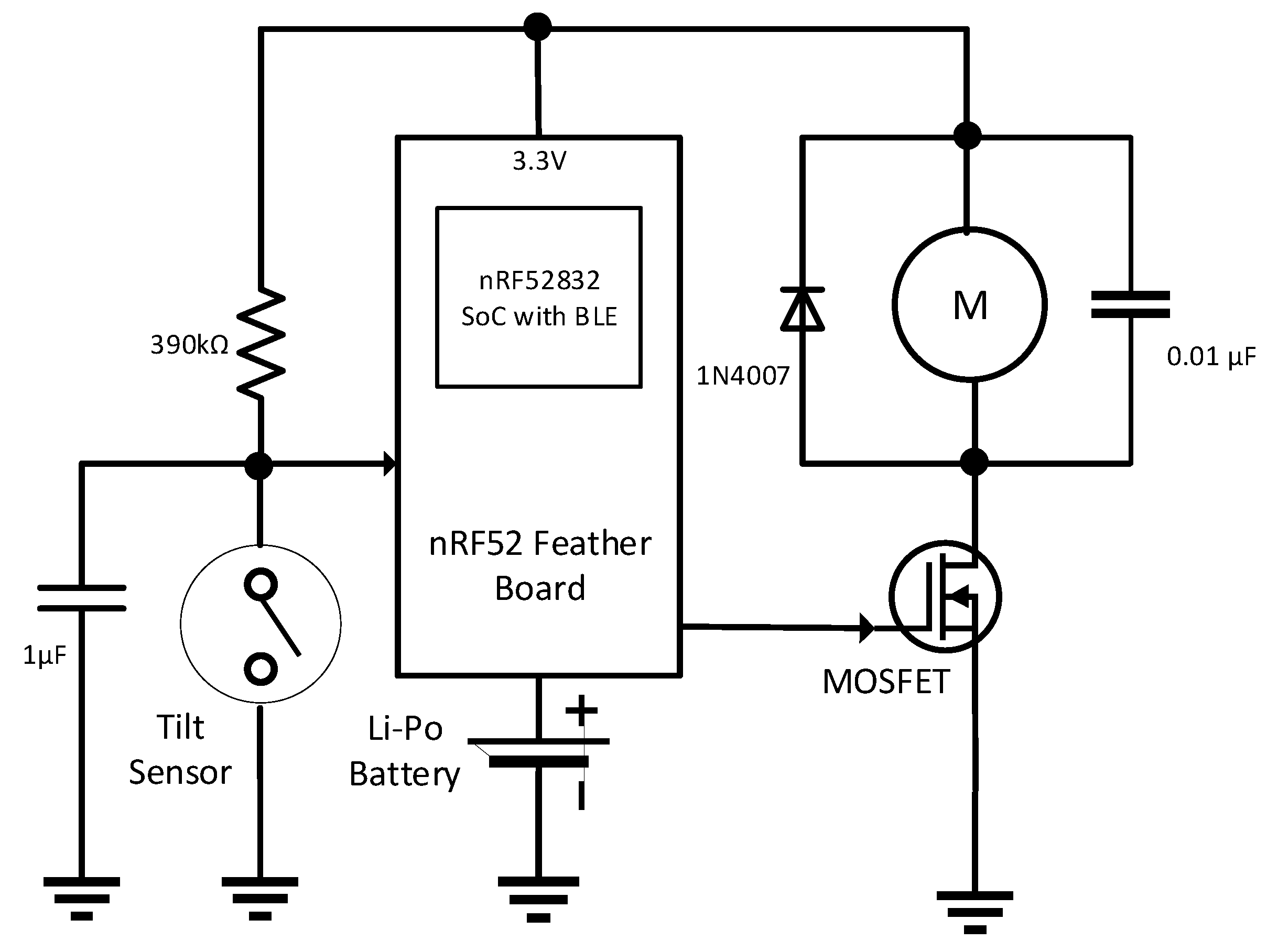
2.2.2. Wearable Gadget
2.2.2.1. Hardware
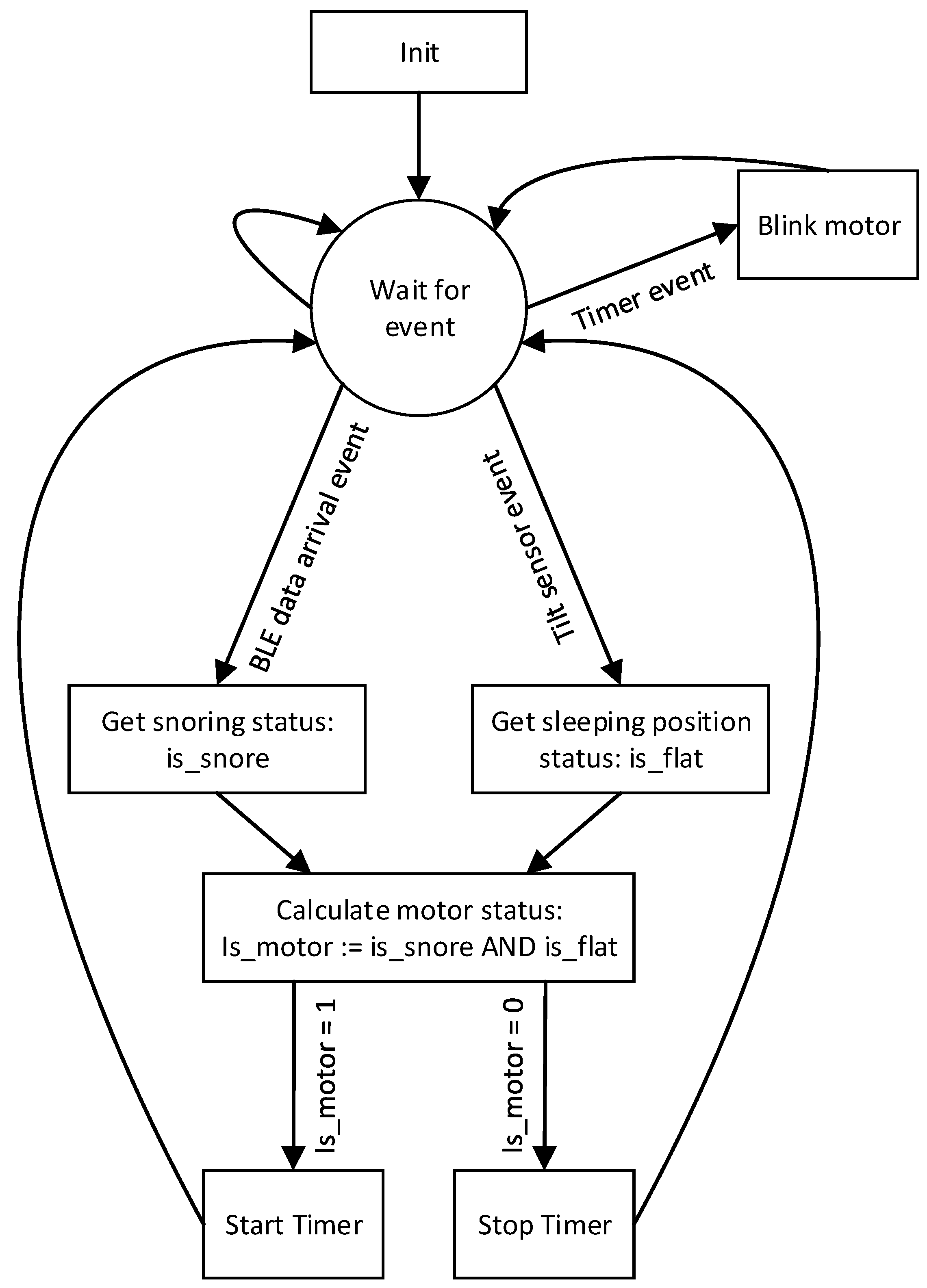
2.2.2.2. Firmware
- The frequency of the RTOS tick interrupt (referred to as configTICK_RATE_HZ) was reduced from 1024 Hz to 4 Hz to reduce power. This change caused 200 µA current reduction. The tick interrupt is used to measure time. Therefore, a higher tick frequency means the timer can measure time to a higher resolution. The RTOS scheduler will share processor time between tasks of the same priority by switching between the tasks during each RTOS tick. A high tick rate frequency will therefore also have the effect of reducing the ’time slice’ given to each task [59]. The system clock of the microcontroller (referred to as SystemCoreClock) is 64 MHz and it is not changed. Thus, the microcontroller executes instructions at a high speed without sacrificing the performance.
- No floating-point numbers were used because the floating-point unit (FPU) consumes significant power. To take the microcontroller in low power mode, the exception flags and the pending FPU interrupts were cleared [60].
- The DC/DC converter of the microcontroller is enabled instead of low dropout (LDO) regulator [61].
- The advertising BLE connection interval was set to 20 ms and the transmission power level was set to 0 dB to balance between power consumption and performance. We did an experiment by reducing the transmission power level to -30 dB—however, no significant reduction of current consumption was noticed, but created a problem during connection.
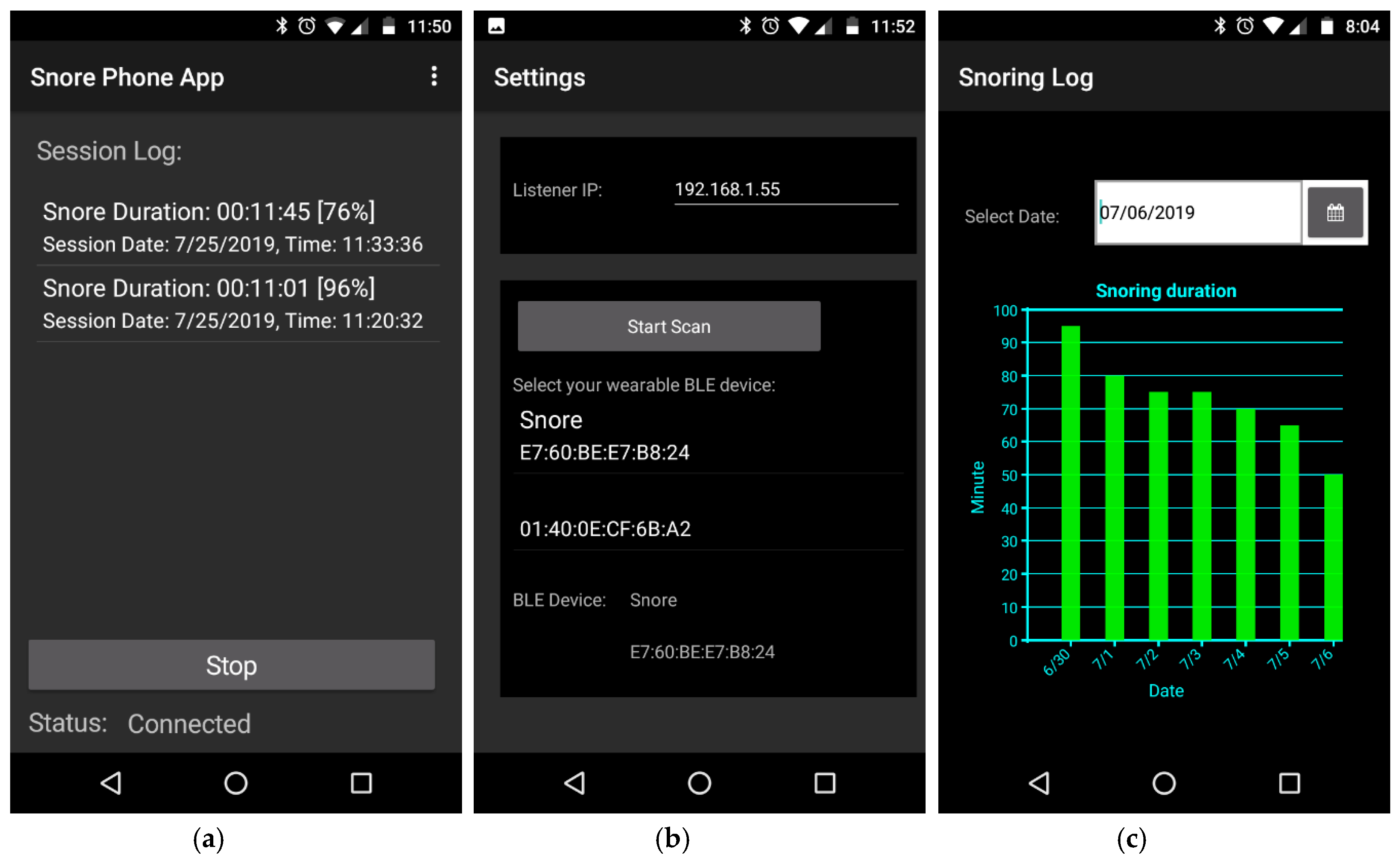
2.2.3. Smartphone App
3. Results
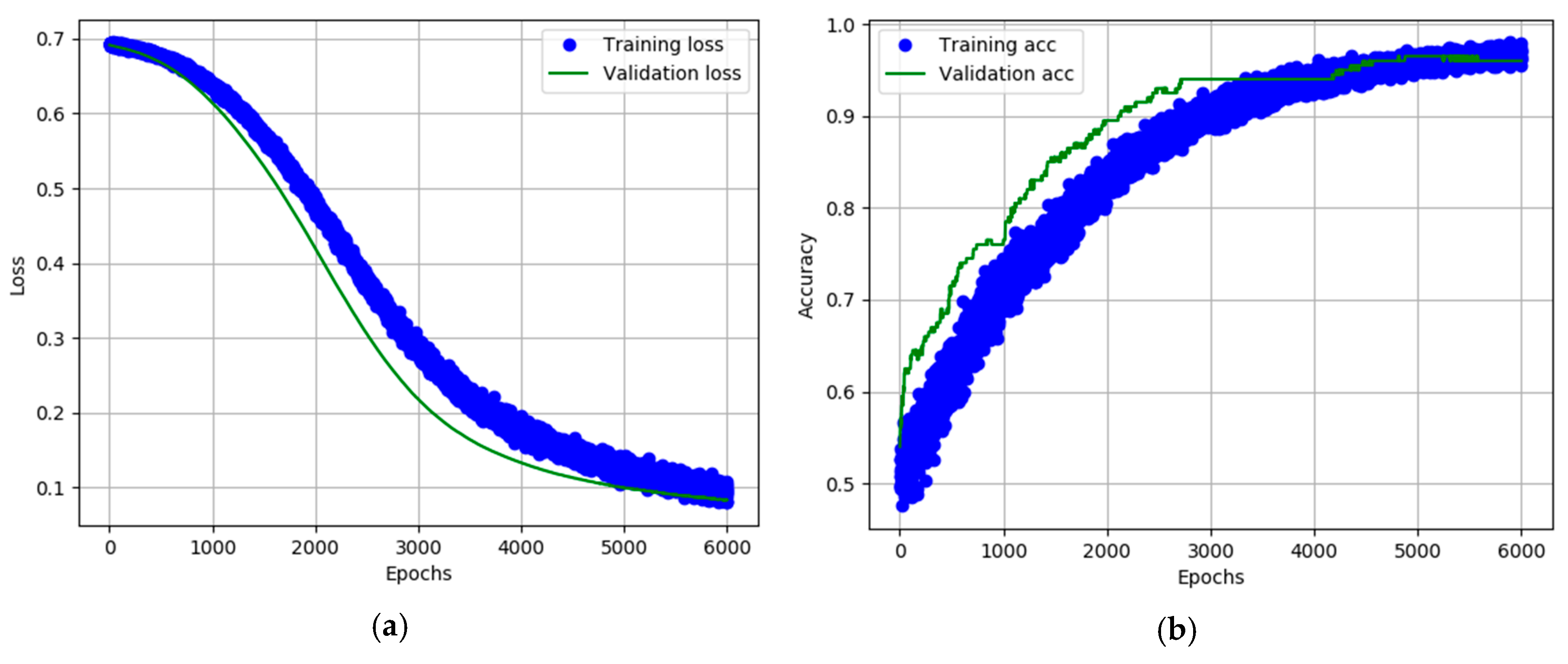
3.1. Snoring Detection Deep Learning Model Results
3.2. Prototype System Results
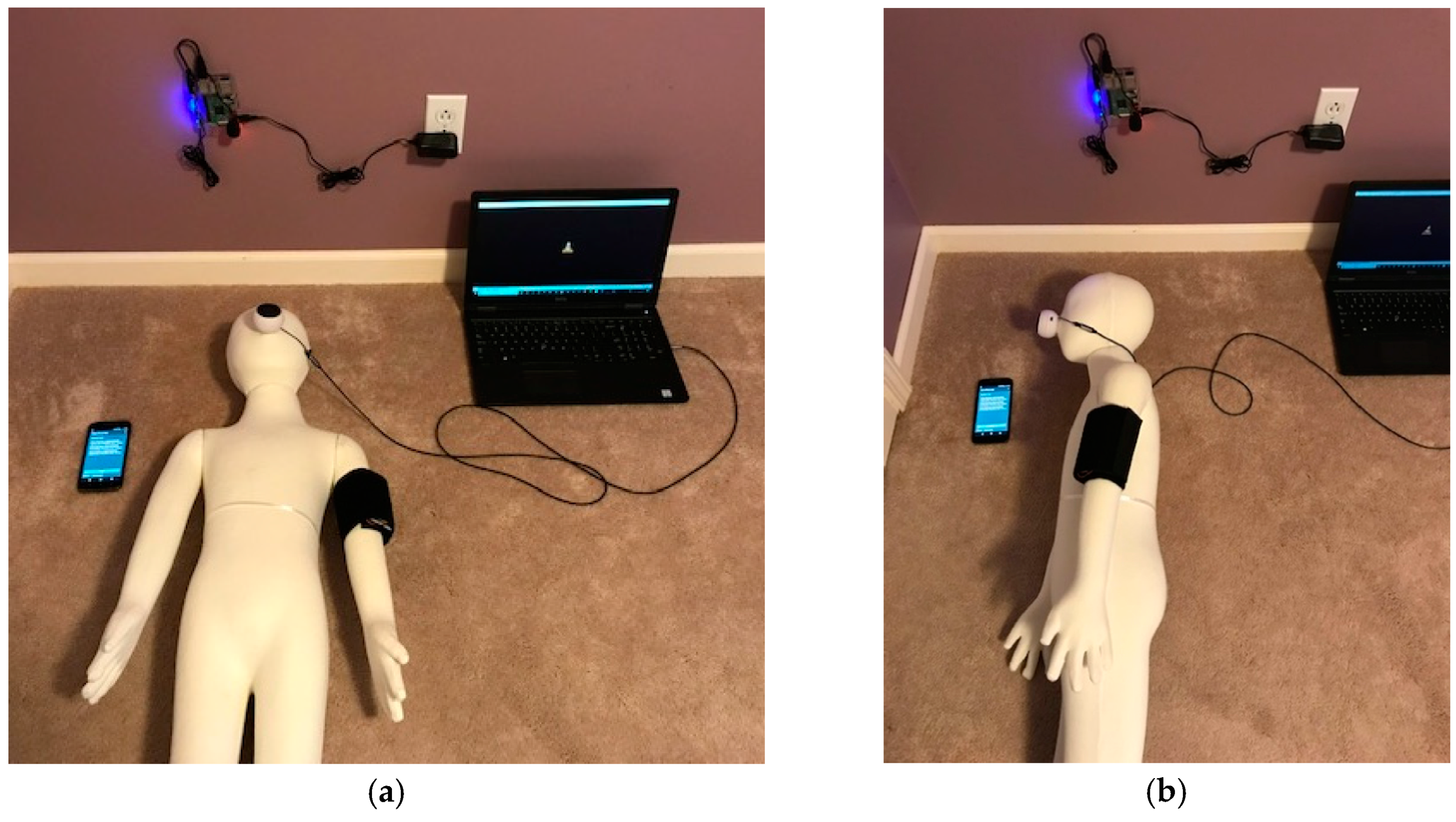
3.3. Experimental Setup and Results
3.4. Comparison with Other Works
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mineo, L. Good Genes Are Nice, But Joy Is Better. The Harvard Gazette. Available online: https://news.harvard.edu/gazette/story/2017/04/over-nearly-80-years-harvard-study-has-been-showing-how-to-live-a-healthy-and-happy-life/ (accessed on 6 August 2019).
- Snoring—Overview and Facts. Available online: http://sleepeducation.org/essentials-in-sleep/snoring/overview-and-facts (accessed on 6 August 2019).
- Melone, L. 7 Easy Fixes for Snoring. Available online: https://www.webmd.com/sleep-disorders/features/easy-snoring-remedies#1 (accessed on 6 August 2019).
- Vann, M.R. 11 Health Risks of Snoring. Available online: https://www.everydayhealth.com/news/eleven-health-risks-snoring/ (accessed on 6 August 2019).
- Lee, G.S.; Lee, L.A.; Wang, C.Y.; Chen, N.H.; Fang, T.J.; Huang, C.G.; Cheng, W.N.; Li, H.Y. The Frequency and Energy of Snoring Sounds Are Associated with Common Carotid Artery Intima-Media Thickness in Obstructive Sleep Apnea Patients. Sci. Rep. 2016, 6, 30559. [Google Scholar] [CrossRef]
- Alencar, A.M.; da Silva, D.G.V.; Oliveira, C.B.; Vieira, A.P.; Moriya, H.T.; Lorenzi-Filho, G. Dynamics of snoring sounds and its connection with obstructive sleep apnea. Phys. A Stat. Mech. Its Appl. 2013, 392, 271–277. [Google Scholar] [CrossRef]
- Smith, D.L.; Gozal, D.; Hunter, S.J.; Gozal, L.K. Frequency of snoring, rather than apnea–hypopnea index, predicts both cognitive and behavioral problems in young children. Sleep Med. 2017, 34, 170–178. [Google Scholar] [CrossRef] [PubMed]
- Yunus, F.M.; Khan, S.; Mitra, D.K.; Mistry, S.K.; Afsana, K.; Rahman, M. Relationship of sleep pattern and snoring with chronic disease: Findings from a nationwide population-based survey. Sleep Health 2018, 4, 40–48. [Google Scholar] [CrossRef] [PubMed]
- Breus, M.J. How to Keep Snoring from Hurting Your Relationship. Available online: https://www.psychologytoday.com/us/blog/sleep-newzzz/201412/how-keep-snoring-hurting-your-relationship (accessed on 6 August 2019).
- Why Sleep Matters: Quantifying the Economic Costs of Insufficient Sleep. Available online: https://www.rand.org/randeurope/research/projects/the-value-of-the-sleep-economy.html (accessed on 6 August 2019).
- SnoreRx. Available online: https://www.snorerx.com/ (accessed on 6 August 2019).
- ZQuiet. Available online: https://zquiet.com/ (accessed on 6 August 2019).
- Good Morning Snore Solution. Available online: https://goodmorningsnoresolution.com/ (accessed on 6 August 2019).
- VitalSleep Anti-Snoring Mouthpiece. Available online: https://www.vitalsleep.com/anti-snoring-device-by-vital-sleep.html (accessed on 6 August 2019).
- Theravent. Available online: https://www.theraventsnoring.com (accessed on 6 August 2019).
- Smartnora. Available online: https://www.smartnora.com/ (accessed on 6 August 2019).
- SnoreLab. Available online: https://www.snorelab.com (accessed on 6 August 2019).
- Agrawal, S.; Stone, P.; McGuinness, K.; Morris, J.; Camilleri, A.E. Sound frequency analysis and the site of snoring in natural and induced sleep. Clin. Otolaryngol. Allied Sci. 2002, 27, 162–166. [Google Scholar] [CrossRef] [PubMed]
- Shiomi, F.K.; Pisa, I.T.; Campos, C.J.R. Computerized analysis of snoring in Sleep Apnea Syndrome. Braz. J. Otorhinolaryngol. 2011, 77, 488–498. [Google Scholar] [CrossRef] [PubMed]
- Pevernagie, D.; Aarts, R.M.; De Meyer, M. The acoustics of snoring. Sleep Med. Rev. 2009, 14, 131–144. [Google Scholar] [CrossRef] [PubMed]
- Calabrese, B.; Pucci, F.; Sturniolo, M.; Guzzi, P.H.; Veltri, P.; Gambardella, A.; Cannataro, M. A System for the Analysis of Snore Signals. Procedia Comput. Sci. 2011, 4, 1101–1108. [Google Scholar] [CrossRef] [Green Version]
- Al-Mardini, M.; Aloul, F.; Sagahyroon, A.; Al-Husseini, L. Classifying obstructive sleep apnea using smartphones. J. Biomed. Inform. 2014, 52, 251–259. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koo, S.K.; Kwon, S.B.; Moon, J.S.; Lee, S.H.; Lee, H.B.; Lee, S.J. Comparison of snoring sounds between natural and drug-induced sleep recorded using a smartphone. Auris Nasus Larynx 2018, 45, 777–782. [Google Scholar] [PubMed]
- Markandeya, M.N.; Abeyratne, U.R.; Hukins, C. Characterisation of upper airway obstructions using wide-band snoring sounds. Biomed. Signal Process. Control 2018, 46, 201–211. [Google Scholar] [CrossRef]
- Hara, H.; Tsutsumi, M.; Tarumoto, S.; Shiga, T.; Yamashita, H. Validation of a new snoring detection device based on a hysteresis extraction algorithm. Auris Nasus Larynx 2017, 44, 576–582. [Google Scholar] [CrossRef] [PubMed]
- Nonaka, R.; Emoto, T.; Abeyratne, U.R.; Jinnouchi, O.; Kawata, I.; Ohnishi, H.; Akutagawa, M.; Konaka, S.; Kinouchi, Y. Automatic snore sound extraction from sleep sound recordings via auditory image modeling. Biomed. Signal Process. Control 2016, 27, 7–14. [Google Scholar] [CrossRef]
- Snoring Sounds. Available online: https://www.soundsnap.com/tags/snoring (accessed on 6 August 2019).
- Breathing and Snoring Sound Effects. Available online: https://www.zapsplat.com/sound-effect-category/breathing-and-snoring (accessed on 6 August 2019).
- People Snoring Sound Effects. Available online: https://www.fesliyanstudios.com/royalty-free-sound-effects-download/people-snoring-189 (accessed on 6 August 2019).
- 10 Minutes Snoring Sound. Available online: https://www.youtube.com/watch?v=1deTKPX1j8c (accessed on 6 August 2019).
- Actual Sound of a Man Snoring. Available online: https://www.youtube.com/watch?v=SOxwffK0xUc (accessed on 6 August 2019).
- WavePad Audio Editing Software. Available online: https://www.nch.com.au/wavepad/index.html (accessed on 6 August 2019).
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef] [Green Version]
- Fayek, H. Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cepstral Coefficients (MFCCs) and What’s In-Between. Available online: https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html (accessed on 6 August 2019).
- Mohamed, A. Deep Neural Network Acoustic Models for ASR. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2014. Available online: https://tspace.library.utoronto.ca/bitstream/1807/44123/1/Mohamed_Abdel-rahman_201406_PhD_thesis.pdf (accessed on 6 August 2019).
- SpeechPy. Available online: https://speechpy.readthedocs.io/en/latest/intro/introductions.html (accessed on 6 August 2019).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Vinod, N.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Nagi, J.; Ducatelle, F.; di Caro, G.A.; Ciresan, D.; Meier, U.; Giusti, A.; Nagi, F.; Schmidhuber, J.; Gambardella, L.M. Max-Pooling Convolutional Neural Networks for Vision-based Hand Gesture Recognition. In Proceedings of the IEEE International Conference on Signal and Image Processing Applications (ICSIPA2011), Kuala Lumpur, Malaysia, 16–18 November 2011. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Xavier, G.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1026–1034. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- A Look at Gradient Descent and RMSprop Optimizers. Available online: https://towardsdatascience.com/a-look-at-gradient-descent-and-rmsprop-optimizers-f77d483ef08b (accessed on 6 August 2019).
- Raspberry, Pi. Available online: https://www.raspberrypi.org (accessed on 6 August 2019).
- USB Lavalier Lapel Microphon. Available online: https://www.amazon.com/Lavalier-Microphone-Cardioid-Condenser-K053/dp/B077VNGVL2 (accessed on 6 August 2019).
- DC Power Supply. Available online: https://www.sparkfun.com/products/13831 (accessed on 6 August 2019).
- How to Give Your Raspberry Pi a Static IP Address. Available online: https://thepihut.com/blogs/raspberry-pi-tutorials/how-to-give-your-raspberry-pi-a-static-ip-address-update (accessed on 6 August 2019).
- Dafna, E.; Tarasiuk, A.; Zigel, Y. Automatic Detection of Whole Night Snoring Events Using Non-Contact Microphone. PLoS ONE 2013, 8, e84139. [Google Scholar] [CrossRef] [PubMed]
- Mesquita, J.; Solà-Soler, J.; Fiz, J.A.; Morera, J.; Jané, R. All night analysis of time interval between snores in subjects with sleep apnea hypopnea syndrome. Med. Biol. Eng. Comput. 2012, 50, 373–381. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- nRF52832 SoC. Available online: https://www.nordicsemi.com/Products/Low-power-short-range-wireless/nRF52832 (accessed on 6 August 2019).
- Adafruit Feather nRF52 Bluefruit LE—nRF52832. Available online: https://www.adafruit.com/product/3406 (accessed on 6 August 2019).
- Lithium Ion Polymer Battery—3.7v 500mAh. Available online: https://www.adafruit.com/product/1578 (accessed on 6 August 2019).
- Tilt Sensor. Available online: https://www.sparkfun.com/products/10289 (accessed on 6 August 2019).
- Vibration Motor. Available online: https://www.amazon.com/tatoko-12000RPM-Wired-Phone-Vibration/dp/B07L5V5GYG (accessed on 6 August 2019).
- MOSFET N-CH 30V 24A. Available online: https://www.digikey.com/product-detail/en/infineon-technologies/IRL2703PBF/IRL2703PBF-ND/811700 (accessed on 6 August 2019).
- Davidson, R.; Townsend, K.; Wang, C.; Cufí, C. Getting Started with Bluetooth Low Energy Tools and Techniques for Low-Power Networking; O’Reilly Media: Sevastopol, CA, USA, 2014. [Google Scholar]
- S132 SoftDevice. Available online: https://www.nordicsemi.com/Software-and-Tools/Software/S132 (accessed on 6 August 2019).
- Free RTOS Customization. Available online: https://www.freertos.org/a00110.html (accessed on 6 August 2019).
- Floating Point Unit (FPU) of nrf52. Available online: https://infocenter.nordicsemi.com/index.jsp?topic=%2Fcom.nordic.infocenter.sdk5.v12.0.0%2Fhardware_driver_fpu.html&cp=4_0_9_2_4 (accessed on 6 August 2019).
- Optimizing Power on nRF52 Designs. Available online: https://devzone.nordicsemi.com/nordic/nordic-blog/b/blog/posts/optimizing-power-on-nrf52-designs (accessed on 6 August 2019).
- Raspberry Pi IP Address. Available online: https://www.raspberrypi.org/documentation/remote-access/ip-address.md (accessed on 6 August 2019).
- Keras: The Python Deep Learning library. Available online: https://keras.io (accessed on 6 August 2019).
- Romero, H.E.; Ma, N.; Brown, G.J.; Beeston, A.V.; Hasan, M. Deep Learning Features for Robust Detection of Acoustic Events in Sleep-disordered Breathing. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 810–814. [Google Scholar]
- Emoto, T.; Abeyratne, U.R.; Kawano, K.; Okada, T.; Jinnouchi, O.; Kawata, I. Detection of sleep breathing sound based on artificial neural network analysis. Biomed. Signal Process. Control 2018, 41, 81–89. [Google Scholar] [CrossRef]
- Arsenali, B.; van Dijk, J.; Ouweltjes, O.; den Brinker, B.; Pevernagie, D.; Krijn, R.; van Gilst, M.; Overeem, S. Recurrent Neural Network for Classification of Snoring and Non-Snoring Sound Events. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17–21 July 2018; pp. 328–331. [Google Scholar]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.S.; Asari, V.K. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- Rosebrock, A. ImageNet: VGGNet, ResNet, Inception, and Xception with Keras. Available online: https://www.pyimagesearch.com/2017/03/20/imagenet-vggnet-resnet-inception-xception-keras/ (accessed on 20 August 2019).
- Chollet, F. Deep Learning with Python, 1st ed.; Manning Publications: Shelter Airland, NY, USA, 2017; p. 60. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | Current Consumption (µA) |
|---|---|
| Advertising | ~195 |
| Idle | 240 |
| Generating vibration | 635 |
| Snoring Detection | Snoring Detection Accuracy | Snoring Prevention | Obstruct Any Natural Body Function? | Data Logging in Smartphone | |
|---|---|---|---|---|---|
| Mechanical devices [11,12,13,14] | No | N/A | Mechanical device on mouth moving the lower jaw slightly forward to maintain an open airway | Yes, Mouth | No |
| Theravent [15] | No | N/A | Strip on nose creates pressure in the airway to reduce vibration. | Yes, Nose | No |
| Smart Nora [16] | Yes | -- 1 | Hardware placed under the pillow starts to move to stimulates the throat muscles for breathing | No | No |
| SnoreLab [17] | Yes | -- 1 | No | No | Yes |
| R. Nonaka, et. al. [26] | Yes, using logistic regression classifier with auditory image modeling features | 97.30% | No | No | No |
| E. Dafna, et. al [49] | Yes, AdaBoost classifier with 34 time and spectral features | 98.40% | No | No | No |
| H. Romero, et. al. [64] | Yes, using deep learning with bottleneck features. | 91.11% | No | No | No |
| T. Emoto, et. al. [65] | Yes, deep neural network | 75.10% | No | No | No |
| B. Arsenali, et. al. [66] | Yes, Recurrent Neural Network with MFCC feature | 95.00% | No | No | No |
| Proposed | Yes, CNN based deep learning with MFCC feature | 96.00% | Vibration on arm until sleep on the side | No | Yes |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, T. A Deep Learning Model for Snoring Detection and Vibration Notification Using a Smart Wearable Gadget. Electronics 2019, 8, 987. https://doi.org/10.3390/electronics8090987
Khan T. A Deep Learning Model for Snoring Detection and Vibration Notification Using a Smart Wearable Gadget. Electronics. 2019; 8(9):987. https://doi.org/10.3390/electronics8090987
Chicago/Turabian StyleKhan, Tareq. 2019. "A Deep Learning Model for Snoring Detection and Vibration Notification Using a Smart Wearable Gadget" Electronics 8, no. 9: 987. https://doi.org/10.3390/electronics8090987