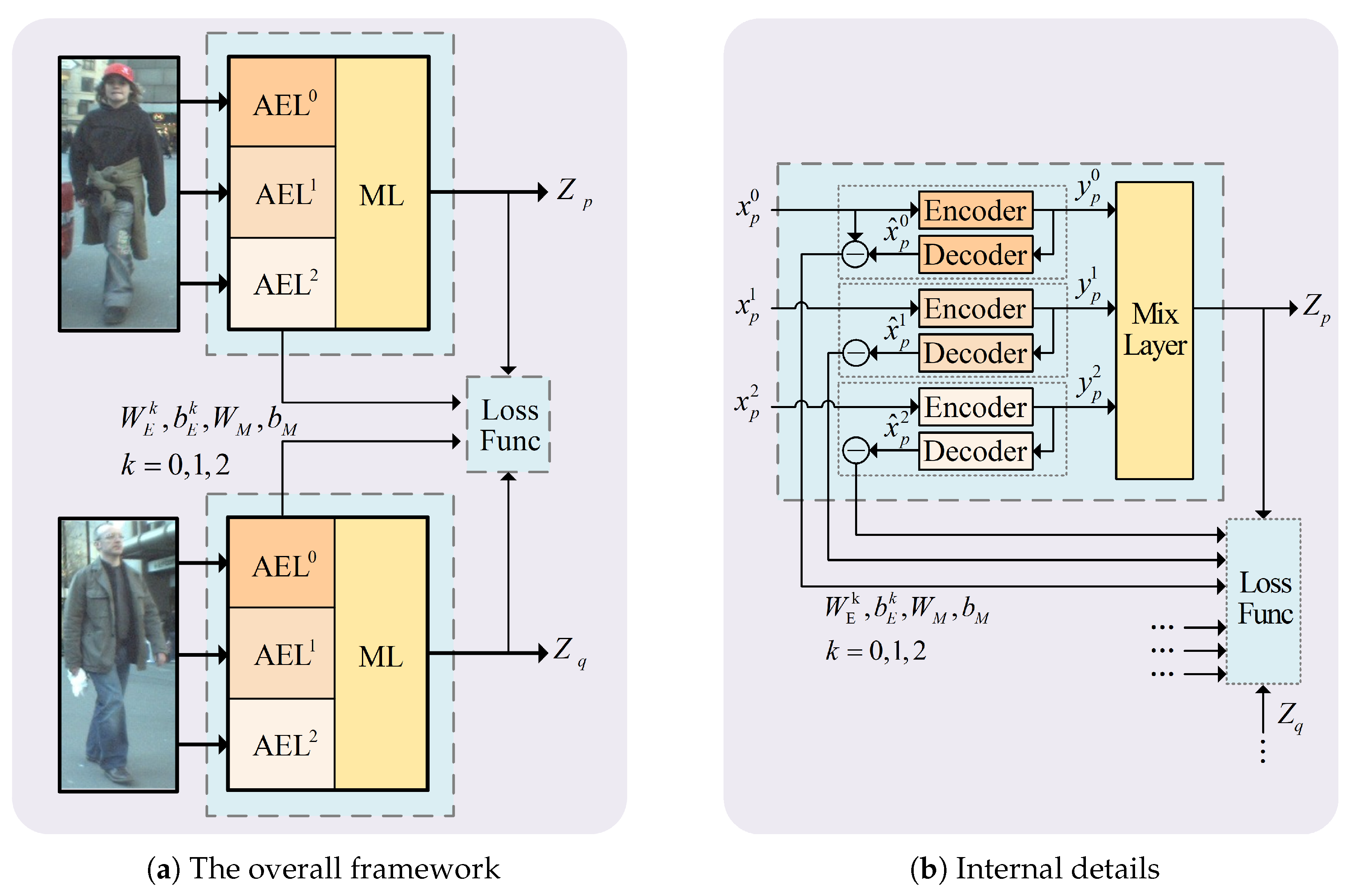
4.1. Overall Framework
Based on SNAC, a tracking framework following TBD was established to solve the MOT problem. A TBD scheme can be described as solving an MAP problem by:
where
is the set of given detection responses and
is the set of trajectories. In the framework, tracklets were first generated. Because a tracklet is an ordered combination of detection responses, it is able to extract higher order features to better describe relations between objects. Then, the problem can be converted into a more reliable tracklet association as follows:
where
is the set of all tracklets.
The whole framework is shown in
Figure 3. First of all, the inputs were checked, and deformity detection responses were deleted, such as too large or small bounding boxes. SNAC was proposed to extract discriminative appearance features for detection responses. The online SNAC incremental learning method mentioned above was used to generate reliable tracklets. The next step was to generate tracking results through tracklet association. Similar to detection association based on the learning method, SNAC was improved to extract a new discriminative composite feature PAN for the tracklet instead of using traditional handcrafted methods. To enhance tracklet association, the tracklet growing module was embedded to make tracklets as extended as possible. With the discriminative PAN feature, tracklet association was converted to a linear programming problem that was solved by an efficient greedy iterative algorithm, and the final trajectories were achieved. For real-time tracking, the whole tracking process was carried out in sliding time windows.
4.2. Previous-Appearance-Next Feature of the Tracklet
A tracklet
is an ordered sequence of detection responses that represents a moving object with a short time from frame
–
. To describe
, appearance and motion are indispensable. They are often assumed to be independent of each other in several studies [
12,
21,
36]. Only by weighted summation can they express the similarity between two tracklets. To increase the flexibility and discrimination, a composite previous-appearance-next (PAN) feature was proposed. The new feature combined appearance and motion for the tracklet, and it was extracted jointly by an improved SNAC.
Taking
and
as examples, as shown in
Figure 4b,
is from frame
–
and
. To calculate the similarity between
and
, it is better to use the tail part of
and the head part of
rather than using their whole information.
is the last element of tracklet
, and
is the first element of
. The PAN(
) vector integrated the appearance, previous, and next stage motions of
to express the tail part composite feature of tracklet
. Correspondingly, the PAN(
) vector was defined for the head part composite feature of
. The next stage motion of tail
and the previous of head
were computed by estimation methods.
The SNAC for detection response was revised to extract PAN(.) vectors of tracklets. The new structure is shown in
Figure 4a. The previous and next stage motions were used as additional inputs to the mix-layer. The first layer of the new SNAC was same as the old SNAC.
and
are the previous and next motion vectors of
, respectively. As shown in
Figure 4b,
represents the
and
axes displacements of
from
to
. For the next-stage motion vector,
, the estimation of
in frame
was computed first, and then,
of
was calculated.
Since and are two-dimensional vectors that include displacements with x and y directions and the output of each auto-encoder in the first layer of SNAC is a 100-dimension feature vector, they are totally different in type and cannot work together simply. Meanwhile, the existence of detection noises makes the deterministic motion descriptions inaccurate. A distribution description method was proposed to represent the motion instead of specific values. Assuming following the Gaussian distribution, the axis displacement, of for instance, is described by , where is set by pre-training. is for y displacement, as well. The distribution description was given by sample vectors of and , and its length was taken to be equal to that of the appearance vector. For in MOT, the motion feature is as important as appearance. The distribution description for can also be obtained. Then, they were merged with the three outputs of the first layer to form one mixed vector for the second-layer training.
Then, SNAC(
) was trained to extract the tail PAN(
) feature. Training samples of SNAC(
) were also collected online. Similar to [
11], elements in
are positive samples. Tracklets that overlap with
in time are positive samples. The parameters of the first layer were inherited from the corresponding detection SNAC. After training the SNAC(
), discriminative local composite features can be extracted to distinguish
from other subsequent tracklets.
As shown in
Figure 4b, similarities between tracklet
and
were computed. After training, PAN
and PAN
, as shown by the blue dashed circle areas in the figure, were extracted. Then, forward similarity was achieved as follows:
To get a reliable similarity, the backward relationship was also computed, as shown in Equation (
12).
The final similarity was given by:
where
g is the probability function for the distance of feature vectors, as defined in Equation (
7).
4.3. Tracklet Growing
If the frame gap between and was small, variations in the appearance and motion from – were not obvious, and the PAN could work well. Otherwise, the long-term frame gap brought a large variety of appearances, and motions may reduce the performance. PAN considers more local elements of the tracklet to enhance the performance. In order to make tracklet association more reliable, it is effective to reduce the time interval in the sliding windows as much as possible. Therefore, the tracklet growing process was used to extend the tracklet by estimated bounding boxes, which were missing from the detection. It contained forward and backward growth.
To forward the extended tracklet
, the center position
in frame
was first estimated by quadratic fitting. Then, the optimal estimation bounding box was searched as follows:
where
C is the candidate bounding boxes set, center positions x and y are sampled according to the distribution of
, and the size is equal to
.
denotes the color histogram of detection
. The goal was to find the most similar estimation. If the optimal estimation
was found, a conflict process was also required to avoid false alarms. If the overlap between
and an existing
exceeded the threshold, the forward growth of
stopped. Otherwise,
was updated to
with
and the growing process continued to frame
. The backward extension was similar to the forward process. For the isolated tracklets, random sampling was used to form the candidate estimations. After these missing detection compensation processes, tracklets were extended to improve the discrimination performance of PAN, and more reliable associations could be made.
4.4. Tracklet Association in Sliding Windows
Tracklet association was the last module in MOT to generate the final trajectories of objects. The main task was to link tracklets belonging to the same objects into a complete trajectory based on similarities among tracklets. Solutions such as min-cost networks, energy minimization, successive shortest paths, and the Hungary algorithm are widely used to generate tracking results. Global optimization is an ideal scheme because the previous judgments will be revised to achieve the overall optimal results. In cases where it is difficult to distinguish objects, this dynamic scheme can achieve better tracking performance than a greedy strategy. Similar to tracking by learning feature extraction method [
15], network flows methods were no longer used to get the tracking result. The MAP problem shown in Equation (
10) was directly mapped to a generalized linear assignment:
To solve problem Equation (
15), the similarity
between tracklets was used; this is equal to linking probabilities mainly based on PAN features.
was computed by Equation (
13). However, PAN features cannot be extracted from tracklets with lengths of less than two elements. For this particular case,
degenerated into the traditional weighted combination of appearance and motion.
is the association indicator, where 1 indicates connection and 0 means disconnection. The constraints guaranteed the uniqueness of association. As the better discriminative PAN, the similarity matrix
was normalized, and Equation (
15) was solved by a greedy iterative algorithm.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}