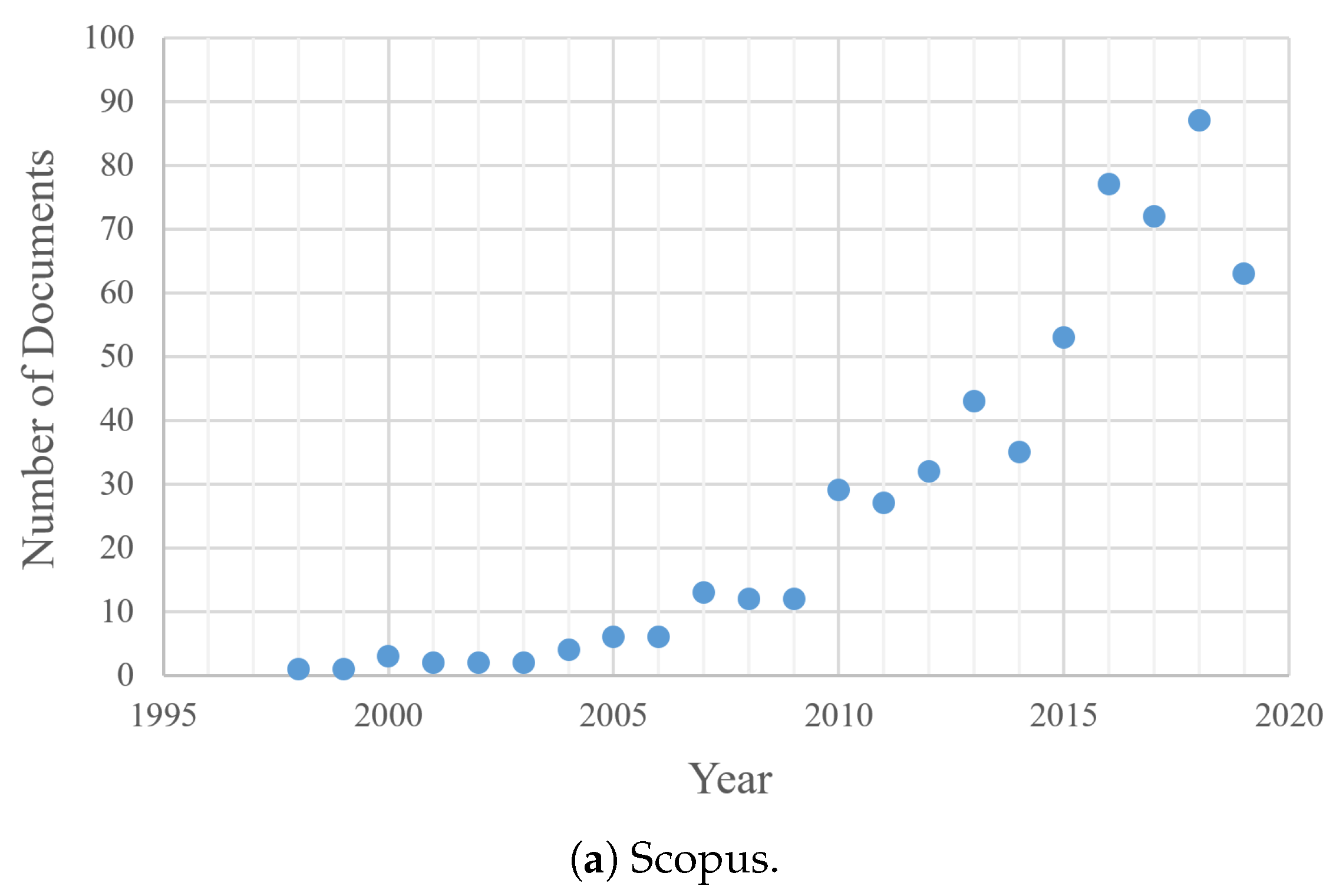
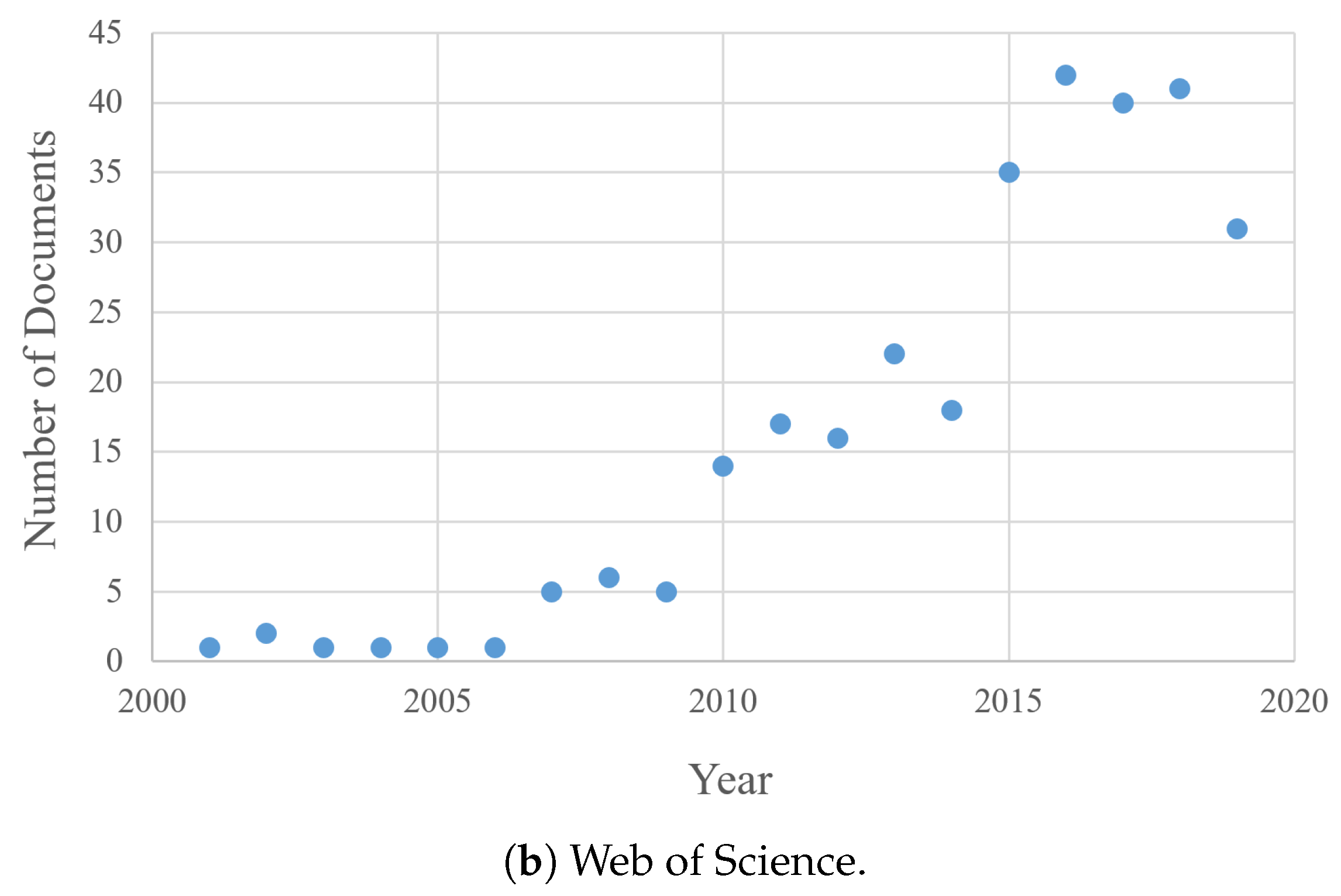
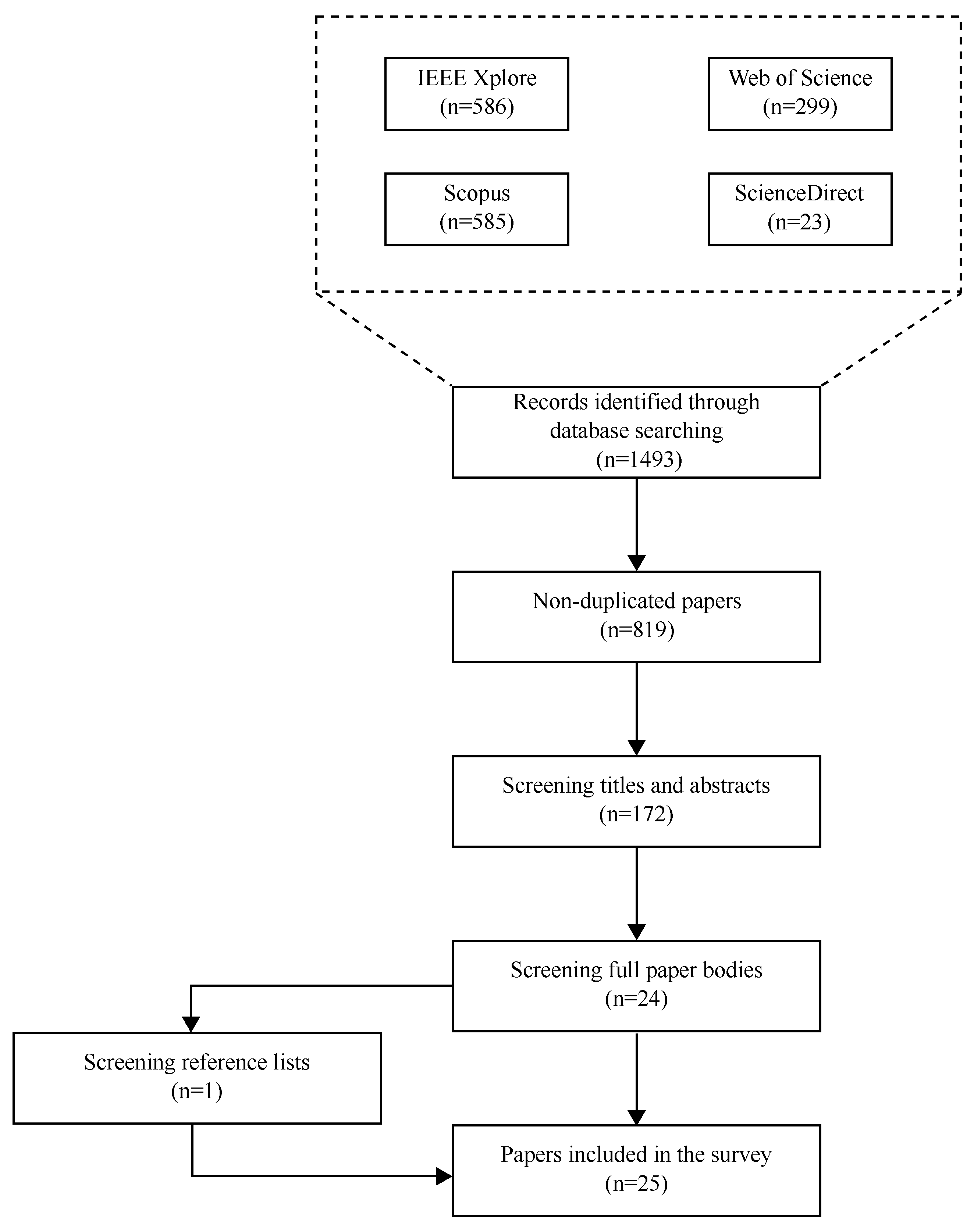
4.1. Temporal Redundancy
Regarding temporal redundancy methods, solutions found in the literature are based on packet retransmission schemes. For instance, the work of Jonsson et al. [
6] focuses on increasing MAC protocol reliability for platooning applications. Time is divided into periodic transmission cycles, called superframes, each one including both contention-based phases (CBPs) and contention-free phases (CFPs). Applications with hard real-time constraints utilize the CFPs to transmit information. These CFPs rely on a polling-based mechanism administered by a master vehicle that applies a time division multiple access (TDMA) scheme for nodes’ transmissions. Each transmission corresponds to a specific time slot, which are ordered according to the earliest deadline first (EDF) policy and a real-time automatic repeat request (ARQ) scheme. This ARQ scheme allows the retransmission of packets to not be well received and they can still be transmitted before their deadline expires. The performance evaluation of the protocol demonstrates a reduction in message error rate by several orders of magnitude when compared to the case without retransmissions.
Despite the improved reliability provided by the proposed solution, this retransmission scheme requires some modifications to the transport layer of vehicular communications protocol stack, in order to be implemented. This non-compliance with the standards encompasses the addition of a real-time polling-based layer on top IEEE 802.11p MAC, as well as the implementation of the transport layer retransmission scheme over a service channel exclusively dedicated to platooning communications. Another disadvantage is the fact that in highly congested scenarios, the retransmission scheme can lead to some bandwidth reduction for each transmitter, however, the real-time scheduling algorithm (EDF) guarantees the optimization of channel use. Furthermore, nothing is referred about the possibility of master failure, the one responsible for coordinating all the communications in the platoon, and how the proposed scheme reacts to that event. Finally, it should be also pointed out that the evaluation of this work was only performed in a simulation environment, very similarly to a numerical analysis, in which the network parameters were kept very static.
Following a similar approach, Böhm and Kunert [
9] propose a retransmission scheme based on the data age of previously received messages. The framework targets intra-platooning communications but also communication between different platoons (inter-platooning). A dedicated service channel is used for intra-platooning communications, while vehicles in distinct platoons exchange information through the control channel. The platoon leader or master is responsible for periodically disseminating beacon messages to all the other vehicles in the platoon. Then during a collection phase, vehicles transmit status updates, which may or may not be well received by the master. In case of unsuccessfully decoded packets, the leader vehicle initiates a retransmission phase by sending individual polling messages to the other nodes, that immediately attempt to retransmit the failed messages. After that, a control phase begins which is used by the master to coordinate the other platoon members based on the retrieved status information. During this window, control packets are transmitted individually to each regular vehicle. In the end, another retransmission phase begins based on acknowledgements returned by the receiving nodes. Moreover, retransmission opportunities are assigned to the nodes, according to the data age of the messages received by the leader vehicle, which keeps a table with the reception time of the latest status update and acknowledgement frames. From this record, higher transmission priorities are allocated to vehicles with older successfully transmitted messages.
The proposed solution introduces some tweaks at the MAC and transport layers in relation to the standard protocols and requires a significant amount of overhead, with acknowledgment messages, retransmissions packets and individual polling messages, in order to improve the packet delivery ratio, making the available bandwidth smaller for other applications or in case of channel saturation. Moreover, the authors do not take into account the problem of having the platoon coordinator as a single point of failure, holding the table with data age of messages from each vehicle. The protocol evaluation demonstrated the feasibility of the proposed scheme and the ability to maintain a stable data age value for the platoons. Additionally, the simulation analysis compares the proposed protocol with the standard approach and other retransmission schemes, but lacks a close-to-real-world scenario evaluation.
The work of Savic et al. [
12] targets a distinct application, in this case, the collision avoidance problem of fully autonomous cars at road intersections. An algorithm for distributed intersection crossing is proposed, being able to cope with an unknown and large number of communications failures. A priority for intersection crossing is assigned to each one of the vehicles based on current position estimates and the cars’ dynamics. Three types of packets are exchanged: periodic heartbeat messages and ’ENTER’ and ’EXIT’ messages immediately before and after crossing the intersection, respectively. In case of receive-omission failures, the ’ENTER’ or ’EXIT’ packets are retransmitted and the model assumes that at least one heartbeat (’HB’) message is received before the intersection crossing (IC) algorithm starts and that vehicles eventually succeed to receive the ’ENTER’ and ’EXIT’ messages. The numerical results show only a slight increase of the crossing delay in the presence of communications failures.
The limitations of the proposed model include the omission of transmitter faults, messages with erroneous content and the assumptions of receiving at least one ’HB’ packet prior to the initialization of the IC algorithm and the eventual successful reception of the sent ’ENTER’ and ’EXIT’ messages. An advantage of this solution is the fact that there is no centralized entity to control the intersection crossing, avoiding single point of failures in the system. Regarding the evaluation process, the numerical analysis is very limited since it only considers two vehicles and consecutive receive-omission failures. Further testing with a high number of vehicles and with more arbitrary conditions in common traffic simulators and real-world implementations is necessary, in order to better evaluate the proposed algorithm.
Sawade et al. [
15] propose a protocol for cooperative maneuvers under adverse conditions. The proposed solution relies on bidirectional stateful communication, i.e., an established session link connecting two or more participants on a collaborative driving maneuver. A synchronization layer is added on top of the bi-directional negotiation of collaborative maneuvers, through the utilization of the Turquois algorithm for attaining distributed consensus under byzantine conditions. Participants must send heartbeat periodic messages in order to keep the session open. Once a predefined number of consecutive missed messages from a vehicle, the session is called unstable and can be terminated. Once in a session, any vehicle broadcasts the current session state in a hashed value. The session state must be consensual across the party of vehicles, so each bit of the hash is individually synchronized between stations. A parameter is used to control the robustness of the sessions against packet loss. This factor is a tradeoff between packets lost consecutively before a failure state is requested and the assurance of consensus among vehicles.
This work adds missing capabilities to the existing vehicular communications standards, through the integration of a collaborative maneuver protocol in the ETSI ITS-G5 protocol stack. The proposal has the advantage of introducing new features on the message-layer only, thus being backwards-compatible to current standard implementations. The main drawback of the work, however, is on the evaluation part, since only simulation results are provided for the specific case of a platoon with just two vehicles. Nevertheless, the conducted experiments show that a session would be stable 99% of the time for reasonable tradeoff values and environments with less than 20% of packet loss.
Nguyen et al. [
17] also propose a protocol that encompasses the retransmission of safety messages that failed to broadcast. The protocol takes into account the presence of hidden nodes and their effect on communications faults. The proposed multi-channel MAC scheme (RAM) divides the control channel cycle in three main intervals: the safety interval, the response interval and the contention-based interval. Any collided safety packets can be retransmitted in the contention-based interval. Whenever a vehicle does not receive any safety packet within a time window from its neighbours, it will request an RSU to send one. The RSUs behave as a central authority inside a given area, being responsible for managing the duration of each cycle, tracking the exchanged messages and adverting the vehicles what packets were successfully received. Based on vehicle density and data traffic conditions, the RSU optimizes the length of the contention-based interval, by also taking into consideration the hidden terminal problem. A Markov chain model is used to analyze the reliability of the real-time transmission of safety packets and to provide information for the computation of the optimized control channel intervals. Simulation results show the improved performance of the proposed RAM protocol in terms of packet delivery ratio in comparison with two other related works.
Despite the increased reliability in the transmission of safety packets, the proposed RAM scheme cannot be directly applied using current vehicular communications equipment, since it requires some modifications to the standard MAC layer, due to the division of the control channel interval into three distinct phases: one congestion-based period (as the standard MAC protocol operates) and two congestion-free intervals. The protocol also introduces some additional overhead in the communications, as a result of the need to transmit acknowledgment messages and retransmission packets. Moreover, the solution has the drawback of assuming that vehicles are distributed along a straight line, in order to simplify the hidden terminal problem, which is typically not the case in real world conditions, where several roads interconnect with a lot of physical obstacles in the middle, either in urban or highway environments. The simulation results lack the implementation in standard traffic and network simulators software and the diversity of simulated traffic environments.
4.2. Spatial Redundancy
In [
7], Matthiesen et al. investigate the utilization of replicated application services in dynamic clusters of vehicles. The goal is to increase the reliability and availability of safety-critical applications in ad-hoc vehicular networks. The example of a distributed shared memory, which supports the operation of a stateful road-traffic information service, is presented in this work. Several metrics are analysed and evaluated for different cluster dimensions, such as data consistency, response time and application availability. A Replication Manager is employed in order to achieve stable clusters, by selecting replicas with good communication metrics that minimize service response time and reconfiguration overhead in case of faulty behaviour. These faults can be due for instance to excessive delay or high packet loss, which may affect timeliness and correctness of the service, thus leading to inconsistent application states.
The proposed fault-tolerant model has the advantage of not requiring any changes in the protocol stack, since the replication model is fully deployed at the application layer. On the other hand, however, overhead of replica selection and exchanging servers in case of failure is not taken into account and may have a significant impact in real-world operation, due to the topology changes and very dynamic environments in which vehicular networks operate. The model also does not consider network congestion scenarios, where the proposed solution may not operate as expected. With simulation results or real test-case measurements, these last points could be better evaluated, not being limited to the the numerical analysis provided to validate only some parameters of the replication service.
The work of Cambruzzi et al. [
10] proposes a failure detection scheme based on a protocol that detects both link and system failures. It employs a heartbeat mechanism in which all roadside units and vehicles transmit a beacon message periodically to their single-hop neighbours. When a beacon packet reaches its destination, the receiving node adds or updates its neighbours’ list with the received information together with a timestamp of the packet. If no message is received from that neighbour during a predefined time interval, the node is considered to be faulty and is inserted into a list of suspects. The algorithm uses adaptive timeouts in order to cope with the dynamic conditions of vehicular communication networks. In this model, only two types of faults are assumed. Those caused by a system crash and the ones caused by a vehicle exiting the road. Malicious or Byzantine faults are not considered in this study.
The fault model considered in the design of this failure detection scheme is very limited, since it only takes into account two type of faults, namely crash-faults (in case of equipment crash) and exit-faults (when a vehicle exits the road). For instance, babbling idiot failures are not analysed, which restricts the validity of the proposed model. Moreover, the impact of the exchange of tables, with the list of neighbours and their perceived status, in the communications overhead is neither discussed nor analysed. Finally, the simulation experiments consider only a simplified scenario with a straight road segment where all vehicles move in the same direction. In practice, this scenario may only happen in very few cases and, therefore, more complex environments should be evaluated, since the model depends significantly on the variation of network topology and link stability.
Based on a similar failure detection mechanism, Abrougui et al. [
13] introduce a fault-tolerance location-based service discovery protocol for vehicular networks. This protocol handles the discovery procedure of different types of both safety and infotainment services and it was designed to perform well even in the presence of service provider failures, communication link failures and roadside units failures. The proposal relies on a cluster-based infrastructure, where roadside units are clustered around service providers, the congested areas of the vehicular network and the intermittent areas to improve the connectivity of the network. The proposed fault-tolerance mechanisms were introduced at the network level, in order to cope with several types of failures in the connection between the service provider and the service requester. Essentially, in case of link or system failure, an algorithm is employed to designate alternative nodes that will supply or forward the information missed in the faulty nodes/links. Simulation results showed an improvement in the success rate of discovery queries of approximately 50% and 30%, in case of a roadside router and link failure scenarios, respectively, when compared with a simplified version of the protocol without fault tolerance techniques.
However, this fault-tolerance scheme presents some disadvantages, such as the fact that the routing protocol is based on a non-standard solution (CLA-S), which requires some modifications in the protocol stack. Additionally, it introduces overhead in the communications protocol, by requiring mechanisms such as the leader election for the roadside routers. Despite the fact that the proposed fault detection mechanism is also able to detect intermittent failures, only permanent ones are considered in the simulation experiments. Moreover, no measurements of the time to recover from failures, e.g., including failure detection time and leader reelection phase, are presented.
Chang and Wang [
16] propose a fault-tolerant protocol for a reliable broadcast of alert messages in vehicular ad-hoc networks. The goal of this protocol is to reduce the total number of messages needed to disseminate the alert message along the road. The proposed method designates the two farthest vehicles in the radio range of the source vehicle to act as candidate relay nodes of the message to be broadcast. This selection is performed by the source vehicle and it is based on the GPS coordinates provided by all vehicles in the transmission range. If the farthest vehicle from the source node does not transmit the safety message within a maximum time interval, the sub-farthest will assume that there was a system failure and will disseminate the intended message. The results show that the penetration rate of the fault-tolerant scheme is very satisfactory even for low traffic densities, providing advantages in relation to the simple flooding method in terms of transmission delay and total number of messages exchanged in the wireless medium.
The proposed protocol has the limitation of being specifically designed for network topologies typically found in the highway scenarios. For instance, in urban environments with a lot of road intersections, it could be important to disseminate warning messages in different directions. In such context, this solution with only one farthest and one sub-farthest vehicles can no longer be applied. In addition to this, the protocol requires some modifications both to the standard MAC and transport layers, which means that it cannot be directly deployed using commercial off-the-shelf (COTS) components. Furthermore, the simulation experiments could include not only the testing of natural communications link limitations, but also communications faults and equipment crashes, in order to broaden the scope of the fault model analysis.
The work of Gérard Le Lann [
18] deals with omission failures originated by a transient fault in the transmitter, receiver or in the communications channel. High reliability and strict timeliness properties are achieved through group dissemination protocols so that every message can be delivered to a given set of vehicles within a worst-case deadline. A Zebra protocol suite which comprises geocast, convergecast, multicast and the Altruistic protocol is employed to guarantee the timely delivery of messages. The proposed fault-tolerant strategy relies on the spatial redundancy provided by the multiple copies of information kept in the different vehicles. This approach would typically lead to high overhead, however, the notion of proxy sets is introduced in order to limit the scope size of the global dissemination protocol.
The proposed scheme has the main drawbacks of not considering permanent failures, i.e., equipment crashes, but only transient faults, and the fact that it specifically targets platooning applications, not being designed as a more generic solution for other safety-critical vehicular applications. It also requires changes to the standard protocol stack, namely at the MAC, routing and transport layers, by employing a suite of protocols (Zebra), specifically designed for time-critical single hop multipoint communications. Besides, it needs a more thoughtful evaluation, since neither simulation nor real test-case experiments were conducted.
Sanderson and Pitt [
19] propose an adaptation of the
Paxos algorithm [
31] to implement consensus formation in self-organizing vehicular networks. The proposed algorithm (
IPcon) handles institutionalized consensus in spite of faults occurring in the dynamic clusters of vehicles. The protocol tolerates faults caused by nodes that fail by permanently stopping or later restarting, delayed, lost or duplicated messages, however, malicious vehicles and corrupted packets are not considered. The evaluation of the algorithm demonstrates the resilience against role failures (nodes may play four different roles in the
IPcon protocol) and cluster fragmentation and aggregation.
One of the limitations of the proposed solution is that it does not take into account all faults in the value domain, e.g., corrupted message content. Moreover, the communications overhead of the consensus algorithm (IPCon) may have some negative impact on the timeliness of safety-critical applications running on top of vehicular networks. Similarly, the leader election and conflict resolution processes could also consume a considerable amount of time to be executed. Practical evaluation regarding these time measurements should be carried out, in order to assess the validity of the proposed scheme under dynamic real-world scenarios.
A fault detection protocol is introduced in [
20] by Aljeri et al. in order to mitigate communications problems in vehicular networks. Fault diagnosis is performed by comparing the output messages from a group of vehicles. This way, it is possible to identify faulty vehicular nodes. The process is initiated by an RSU, which attributes the same task to a group of vehicles. Then, the results are computed by each node and the answers are transmitted back to the initiator. If the results are identical, it is assumed that there are no faults in the network. On the other hand, if different results are yielded, faulty road components can be detected. Additionally, a more efficient implementation of the protocol is proposed that relies on regional RSUs, which decreases the total number of packets transmitted and the diagnosis latency of this method.
The proposed fault detection mechanism implies additional network resource usage, in order to identify faulty nodes. The tasks assigned to pairs of vehicles, with the goal of verifying disagreements and diagnosing faults, introduce some communications rounds and consume processing time. It is not a transparent solution that takes advantage of the messages already exchanged inside the vehicular network. Additionally, it is assumed that two faulty vehicles always give different outputs, which may not always be the case, e.g., in common failure mode. Another drawback relies on the fact that the fault detection scheme only targets networks where roadside units are present. There is no alternative framework devised for communications solely among clusters of vehicles, or for the specific case when there is a permanent failure in the gateway node, which behaves as a single point of failure in the network.
In [
21], Casimiro et al. develop a kernel-based architecture (KARYON) for safety-critical coordination in vehicular systems. Besides dealing with sensor faults and real-time properties of the wireless communications (e.g., self-stabilizing protocol), the proposed architecture also introduces extra components to the standard MAC layer. According to the followed subsystem isolation, the authors assume in the fault model that communication components can experience crash or timing faults, however, data cannot be corrupted, i.e., faults may occur in the time domain, but not in the value one. In addition to the standard MAC layer, two extra elements are introduced: the mediator Layer (MLA) and the Channel Control Layer. For example, the MLA is responsible for node failure detection and membership and control of temporary network partitions. On the other hand, the channel control layer supervises the channel state and enhances the network resilience by taking advantage of the diversity of radio channels available for vehicular communications purposes.
The main disadvantage of the devised architecture is the need for introducing several changes in the protocol stack, especially at the MAC layer level, so that some extra functionalities that are not present in current COTS components become available. As already mentioned, in the communications modules of the system, not all types of faults are covered, since crash or timing faults are tolerated, but not data corrupted messages. Finally, no evaluation is performed in this publication, that is part of the future work, so there is no way to validate the performance of the proposed fault-tolerant solution.
The work of Worrall et al. [
22] deals not only with the complete loss of radio communications but also with partial degradation of the wireless link. In some cases, the communications performance is affected in an intermittent way or behaves poorly after a certain distance, due e.g., to damages in the external cables, antennas or connector. The proposed method utilizes data gathered during normal operation so that the antenna behaviour can be modelled and used in future fault detection. This model is derived by analysing and learning the properties of wireless communications in a fleet of vehicles, taking into account parameters such as relative orientation, bearing and range between vehicles. The detailed knowledge about the communications performance is then utilized to detect partial antennas faults or permanent link failures, which are identified by observing when the RF communications deviate from the expected operation. Additional computational resources are required in order to allow online execution of the mathematical model and appropriate comparison with the run-time results of the antenna performance.
The proposed fault detection mechanism is not suitable for a large number of vehicular communications applications, which are based on broadcast messages, since this solution is specifically designed for point-to-point radio links. The scheme only covers faults in the physical air interface, namely cable and antenna performance degradation, not detecting any time and value issues in the exchanged messages. Furthermore, the real test case results show that the settling time for statistically detecting healthy antenna behaviour may be relatively long, which may be critical in constantly changing network topologies with frequent communications links disruption.
Platooning applications constitute a particular use case scenario of vehicular communications. Ploeg et al. [
23] address the problem of faulty links in a platoon of vehicles. A safe distance between the members of the platoon is continuously computed by taking into consideration the availability of sensor data and the communications link performance. This safe distance is employed by the cooperative adaptive cruise control (CACC) system according to a graceful degradation scheme that adjusts the settings of CACC to keep as much functionality as possible, even in the presence of faults, but always guaranteeing string stability in the platoon. Moreover, two different network topologies can be applied, depending on the time delay of the communications link. If this delay exceeds a predefined threshold value, the platoon service switches from a one-vehicle look-ahead topology to a two-vehicle look-ahead configuration. This fault-tolerance strategy can only be applied if the delay time is not excessively large, otherwise, wireless communications should not be employed in order to preserve string stability.
The described fault-tolerant scheme targets only a particular application, i.e., vehicle platooning, being tied to a concrete network topology and thus not very useful to other use case scenarios. The fault model only takes into account large delay values that may affect the timeliness of the communications links, not considering faults in the value domain of the transmitted packets. Additionally, only numerical results are provided, which makes it difficult to evaluate the performance of the system under real environments with adverse conditions.
In [
24], Fathollahnejad et al. propose a synchronous group formation (GF) algorithm to enhance self-organizing vehicular applications under the presence of an unbounded number of asymmetric communication failures. The main goal of the GF algorithm is to achieve agreement, or at least to reduce the probability of unsafe disagreement, on the membership of a cooperative ITS application, e.g., virtual traffic light (VTL) systems. A decision mechanism is employed by each member node (vehicle) to identify the other nodes in the group at each moment in time. The mechanism relies on the utilization of an extra component, designated as
oracle. These
oracles are local devices present in each node and are responsible for detecting the remaining participants in the group. The obtained simulation results show that when the local
oracles provide a correct estimate of the group formation, only safe disagreement scenarios may occur. However, when the
oracles underestimate the total number of nodes, unsafe disagreement situations may happen and the likelihood of such scenarios increases with the probability of receive omissions in the communications channel.
This work excludes process failures, only dealing with faults in the communications links and more specifically just receive omissions faults, so faults in the value domain are also outside of the scope of the fault model. Moreover, communications overhead for leader election, leader handover or VTL group formation protocol is not discussed and analysed, and the leader election and leader handover mechanism are not yet designed, being part of future work. Finally, the evaluation section only presents numerical results, there are no experiments conducted in more realistic traffic/network simulation or test case environments.
Bhoi and Khilar [
25] introduce a fault-tolerant routing protocol for vehicular ad-hoc communications in urban environments. A fault detection technique is used by the vehicle itself to detect if its own operation is fault free or not. If a faulty behaviour is identified, the on-board unit (OBU) does not participate any longer in the routing process. The fault detection mechanism targets soft faults, i.e., erroneous behaviour in the OBU devices causing the generation of incorrect data for a long period of time. This may be caused by high noise affecting the node’s operation, making it still able to compute, send and receive information. However, beaconing data transmitted by the vehicle cannot be considered valid, being that this information (position, speed, etc.) is indispensable for hop selection in the routing algorithm. For that reason, these nodes are automatically excluded from the routing process by self-detecting these soft faults, through the analysis of the RSSI values from the received messages and the location coordinates provided by the neighbouring nodes. The proposed protocol provides good results in terms of end-to-end delay, path length and false alarm rate.
The proposed routing protocol just takes into account faults in the value domain, e.g., incorrect data in the position or speed information, not considering the possibility of nodes introducing timing faults, such as large delay values. It is also assumed that the faulty vehicles always provide incorrect data and only by accident the information may be correct. This simplifies the fault detection mechanism but could be a not very realistic situation, since nodes may present intermittent faults that only arise in some occasions. The overhead of exchanging decision messages regarding the state (soft faulty or fault free) of neighbouring vehicles is neither discussed nor analysed. Furthermore, despite the decentralized fault detection scheme, the routing and path value calculation algorithm depends on RSU nodes, which are single points of failure in this forwarding scheme.
The work of Mourad Elhadef [
26] suggests the utilization of a primary-backup approach for the design of a fault-tolerant intersection control algorithm. The VTL system is based on a centralized solution, with an RSU controller responsible for coordinating all traffic crossing the intersection. The controller manages the vehicles approaching the site, by granting or denying access to the intersection, in order to guarantee safety, liveliness and fairness, while at the same time maximizing traffic throughput. Both the primary and the backup controllers are constantly synchronizing with each other, so that the backup unit can always be kept updated with all the necessary traffic information. Only permanent crash failures are considered in the fault model. Whenever the main controller stops sending and receiving messages (a keep alive timer is used to detect if the primary node is down), the backup unit takes control of the intersection.
This fault-tolerant intersection control algorithm has the drawback of not dealing with intermittent faults and message errors in the value domain, by only considering permanent crash failures. Besides that, it focus on a specific application (intersection management), while a more generic solution could be devised with the same primary-backup approach for master nodes of vehicular networks that rely on centralized or hybrid architectures. Furthermore, no evaluation of the proposed scheme is carried out, namely in terms of recovery delay after primary replica failure.
An RSU-backup replication scheme is proposed by Almeida et al. [
27] in the scope of a fault-tolerant infrastructure-based architecture for vehicular networks. In this framework, the RSUs behave as the masters of the network, controlling time slot scheduling of the OBUs and admission control policies. They have a crucial role in the network operation, acting as single point of failure, and therefore, any fault affecting these nodes may cause a disruption in the time-sensitive communications for safety-critical applications. The work introduces a full replication scheme, where a backup node executes the exact same processes as the primary fail-silent replica. This parallel operation allows the system to perform a very fast recovery procedure in case of failure of the primary node. As a result, the real-time communications protocol does not suffer any discontinuity even in the presence of network faults, thus enhancing the overall dependability of vehicular system.
The replication mechanism proposed in this work consists in a cross-layer approach, since it requires the duplication of the entire RSU node from the physical up to the application layer. Unfortunately, there is no cost-benefit analysis for this solution, since the complete replication of hardware and software parts is expensive and could be compared against other possibilities, such as the option for non fail-silent RSUs and the use of backup ones operating in another channel frequency. Moreover, the deterministic MAC protocol that is on the basis of this architecture also needs some changes to the standard vehicular communications protocols, so the solution cannot be seamlessly implemented on COTS components. Finally, the fault-tolerant system was only tested in a controlled laboratory environment. Some testing in close-to-real world scenarios could give an improved understanding of system’s reliability under the presence of hardware, software or communications channel faults.
In [
28], Medani et al. develop a time synchronization strategy for the nodes of vehicular networks. Clock synchronization is essential to support the correct operation of safety-critical applications in road traffic environments (e.g., for event causality, medium access control or security purposes). The proposed method, named Offset Table Robust Broadcasting, attains high accuracy and presents fault-tolerant capabilities so that every node is aware of neighbouring clock times and is able to synchronize its communications with other nodes. The clock offsets among several nodes are computed using a round-trip time mechanism and acknowledgement messages are exchanged to ensure that the offset table delivery reaches all nodes.
In order to achieve higher clock synchronization, the proposed scheme introduces some communications overhead, both for the transporter node selection and cluster formation but also for the entire synchronization process that involves collecting timing information, calculate offsets table and disseminate the computed data. Additionally, it requires the modification of the clock synchronization source in the node, which may be sometimes difficult to implement in COTS components. Finally, it would be interesting to perform some field trials evaluation, in order to have real GPS errors and uncertainties in the synchronization process.
A multipath routing protocol is proposed by Devangavi et al. [
29], in order to enhance reliability and fault tolerance. Multiple paths are computed from source to the destination node based on Bezier curves. These curves are traced by the parent RSU according to the geographical location of the different nodes in the network on a multi-hop coverage area. The calculation of these paths is also based on several parameters, such as the available bandwidth in the network, the data size to be transmitted and the distances from source to destination. The distinct paths are then prioritized and utilized to forward the information to the destination vehicle, introducing a flexible degree of redundancy in message transmission. The proposed solution was evaluated taking as example the city of Bangalore and the simulation results obtained in NS-2 proved the superior performance of the protocol in comparison with other solutions in the literature and with respect to transmission time and packet delivery ratio.
The proposed protocol is based on a centralized architecture, where RSU nodes are responsible for multipath finding process and network management tasks. However, these nodes are single point failures that in case of permanent crash, disrupt network operation. Furthermore, it is assumed that every vehicle is always connected to at least one RSU, which limits the applicability of the proposed solution in real-world scenarios. It should also be noted that a prioritized path list must be computed for every source-destination pair of vehicles involved in message exchange, which introduces a significant amount of communications overhead that is not evaluated in the simulation experiments.
In [
30], Younes et al. propose the FT-PR protocol, a fault-tolerant path recommendation system. In this work, vehicles within a reporting area are responsible for disseminating the traffic characteristics of a road segment. The process is cumulative, since a road segment can have multiple reporting areas. Transmitting vehicles gather information on surrounding clusters and a report is completed as soon as it encompasses the entire road segment. Road-side units (RSUs), assumed to be located at each road intersection, exchange information with each other and calculate the best road segments for specific destinations. RSUs start broadcasting destinations and the best turn towards them. From this part forward, the process is iterative, vehicles entering a road segment receive the path recommendation information and may progress towards the road network. Different techniques are used to improve the robustness of the system, For instance, in order to enhance the traffic collection phase, vehicles can request updates by disseminating vehicles missing in the report description. Furthermore, in case of an RSU error, the nearby RSUs can assume their roles and transmit their information. Additionally a vehicle can retransmit messages from an RSU, in order to increase the RSU communication radius.
The main contribution of this work consists in the designation of redundant routing paths for multi-hop communications, in order to compensate for RSU failures. The solution does not address the issue of a vehicle reaching a specific RSU node, e.g., one responsible for a safety-critical task, such as controlling a road intersection. If the destination RSU is faulty, no redundant node is available to perform the expected task. Another drawback of the proposed protocol is that the selection of a cluster head for each reported area, a constantly dynamic process, may introduce a significant amount of overhead, which may be critical in terms of delay. Nothing is mentioned in the article about how this selection process is conducted. In terms of results, by using FT-PR protocol, vehicles were able to obtain the optimal path even if 40% of installed RSUs failed to process or forward the advertisement messages. However, the obtained simulation metrics are not generic and were only evaluated for specific layout scenarios. More realistic situations should be considered for further analysis.






{kind=link}
{kind=link}
{kind=link}