
Two-Level Dynamic Programming-Enabled Non-Metric Data Aggregation Technique for the Internet of Things

 ,
,
Abstract
:1. Introduction
- Dense deployment of member devices, which can overlap in their data collection.
- Proximity of neighboring devices, especially those residing in close vicinity, which may inadvertently capture and transmit similar data.
- Introduction of a novel data aggregation approach for IoT networks, utilizing a two-tier and dynamic programming-based non-metric method, to refine every captured data value.
- Development of an in-node or local data aggregation model, which refines captured data values by addressing both noise and duplicate data issues before transmitting the data.
- A server-enabled aggregation model, i.e., the longest common subsequence-based model, where data values received from multiple source devices are further refined, and where duplicate data values are discarded.
2. Literature Review
- Duplicate data values captured by those devices or modules that are deployed in neighborhoods.
- Outliers or noisy data values generated by the respective embedded sensors due to malfunctioning.
3. Proposed Aggregation Methodology
- Detection and correction of false data values captured by the respective embedded sensor module deployed near the phenomenon.
- Minimizing (or, if not possible, eliminating) the ratio of duplicate data values in the entire database, which is carried out either through in-node processing or server-level data aggregation and fusion.
3.1. Proposed In-Node Data Aggregation: A Smart Approach
| Algorithm 1: Proposed Device-Oriented Data Aggregation Algorithm |
 |
3.2. Dynamic Programming-Enabled Non-Metric-Based Data Aggregation: Server Level
| Algorithm 2: Dynamic programming-enabled data aggregation algorithm for IoT infrastructure. |
 |
4. Performance Evaluation
4.1. Evaluation Metrics
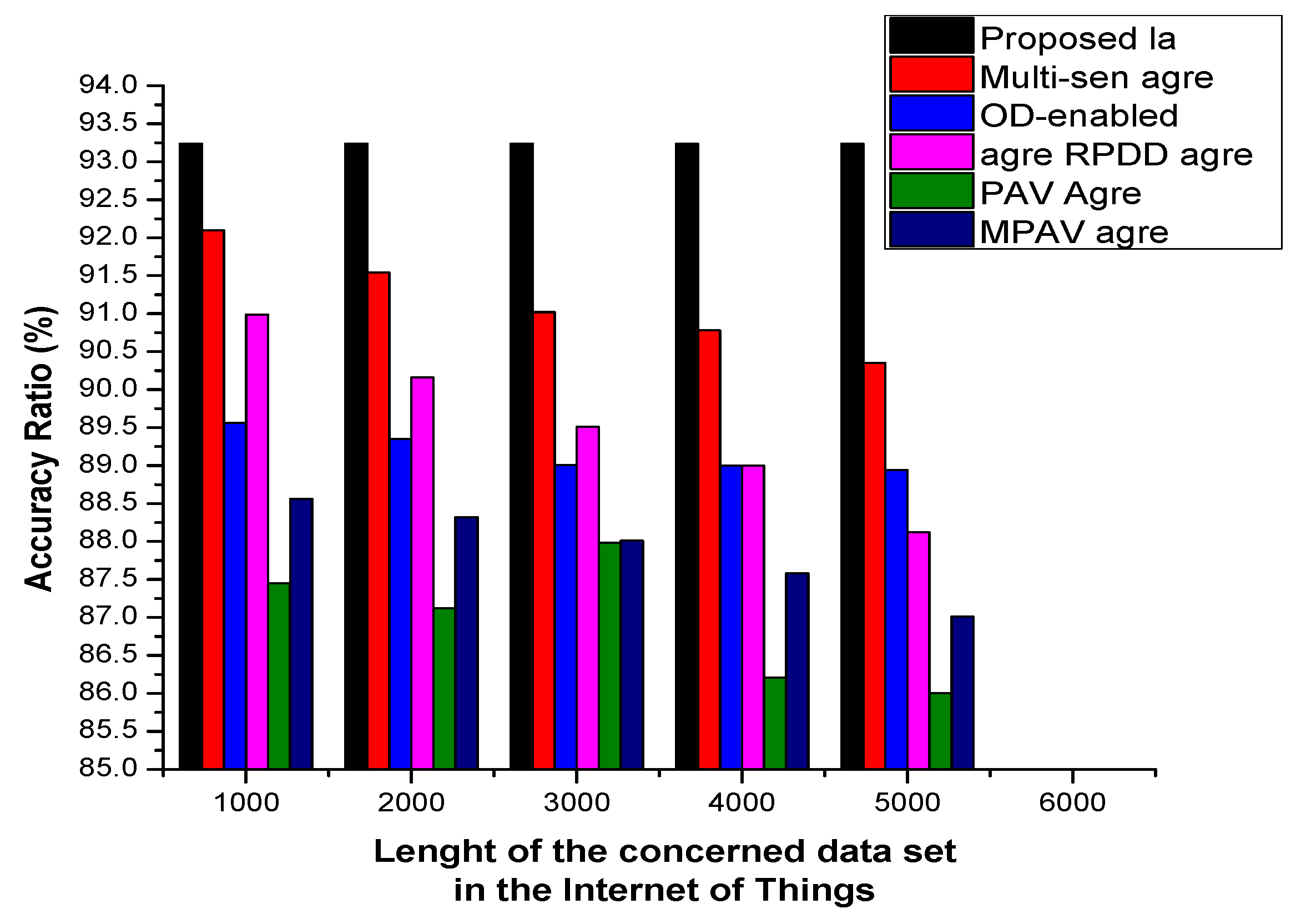
4.1.1. Accuracy and Precision Ratio Metric: In-Node Aggregation
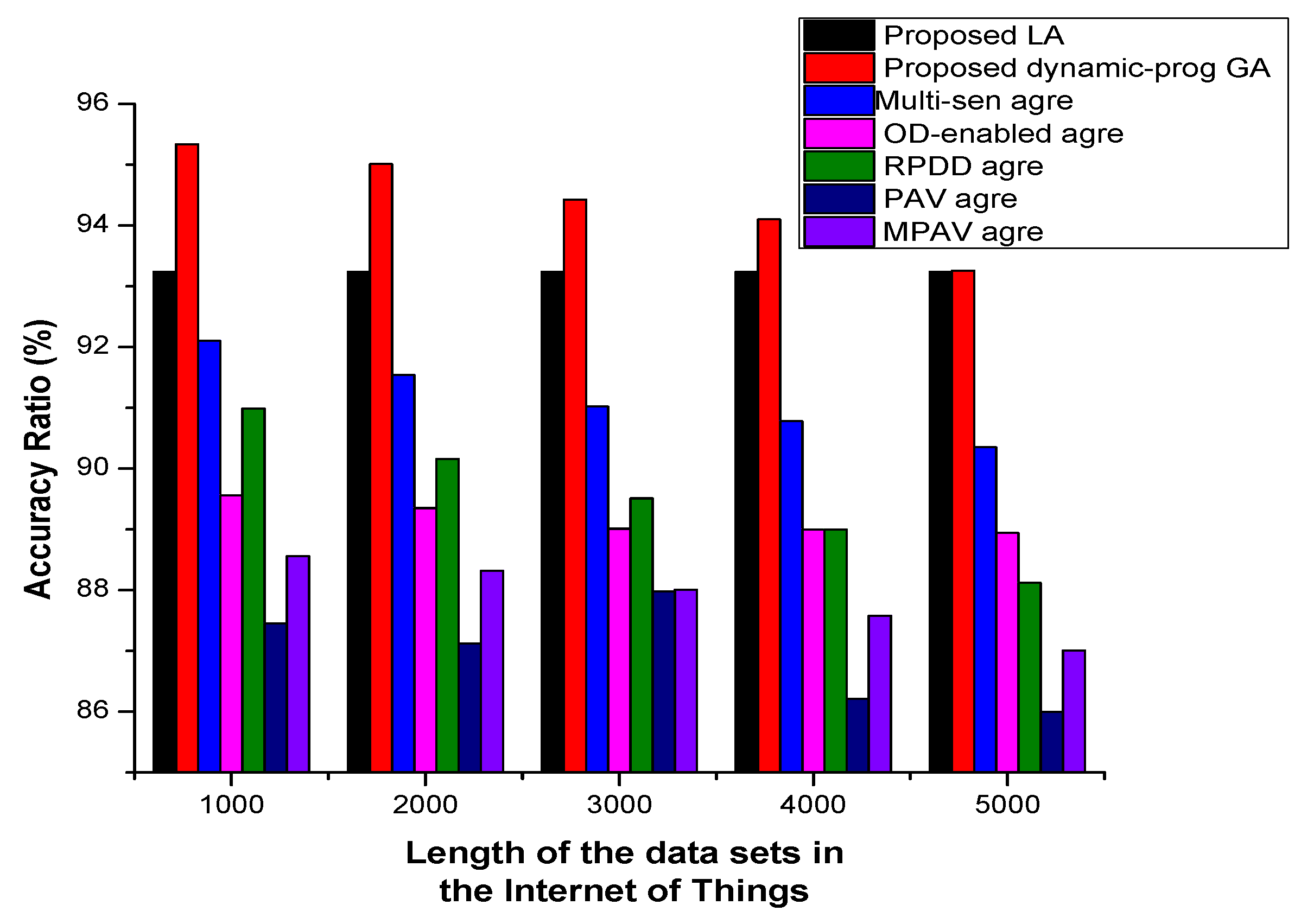
4.1.2. Accuracy and Precision Ratio Metric: Dynamic Programming-Enabled Data Aggregation
4.1.3. Refinement Ratio: Device-Level Data Aggregation
4.1.4. Refinement Ratio: Dynamic Programming-Enabled Server-Based Data Aggregation
4.1.5. Computational OR Processing Time Metric
4.1.6. Drop Ratio of Outliers or Noisy Data Value
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pramanik, S. An Effective Secured Privacy-Protecting Data Aggregation Method in IoT. In Achieving Full Realization and Mitigating the Challenges of the Internet of Things; IGI Global: Hershey, PA, USA, 2022; pp. 186–217. [Google Scholar]
- Singh, R.; Dwivedi, A.D.; Srivastava, G.; Chatterjee, P.; Lin, J.C.W. A privacy preserving internet of things smart healthcare financial system. IEEE Internet Things J. 2023, 10, 18452–18460. [Google Scholar] [CrossRef]
- Nabil, Y.; ElSawy, H.; Al-Dharrab, S.; Mostafa, H.; Attia, H. Data aggregation in regular large-scale IoT networks: Granularity, reliability, and delay tradeoffs. IEEE Internet Things J. 2022, 9, 17767–17784. [Google Scholar] [CrossRef]
- Ahmed, A.; Abdullah, S.; Bukhsh, M.; Ahmad, I.; Mushtaq, Z. An energy-efficient data aggregation mechanism for IoT secured by blockchain. IEEE Access 2022, 10, 11404–11419. [Google Scholar] [CrossRef]
- Tariq, U.U.; Ali, H.; Liu, L.; Panneerselvam, J.; Zhai, X. Energy-efficient static task scheduling on VFI-based NoC-HMPSoCs for intelligent edge devices in cyber-physical systems. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–22. [Google Scholar] [CrossRef]
- Tariq, U.U.; Ali, H.; Liu, L.; Hardy, J.; Kazim, M.; Ahmed, W. Energy-aware scheduling of streaming applications on edge-devices in IoT-based healthcare. IEEE Trans. Green Commun. Netw. 2021, 5, 803–815. [Google Scholar] [CrossRef]
- Ali, H.; Tariq, U.U.; Hardy, J.; Zhai, X.; Lu, L.; Zheng, Y.; Bensaali, F.; Amira, A.; Fatema, K.; Antonopoulos, N. A survey on system level energy optimisation for MPSoCs in IoT and consumer electronics. Comput. Sci. Rev. 2021, 41, 100416. [Google Scholar] [CrossRef]
- Tariq, U.U.; Ali, H.; Liu, L.; Panneerselvam, J.; Hardy, J. Energy-efficient scheduling of streaming applications in VFI-NoC-HMPSoC based edge devices. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 9991–10007. [Google Scholar] [CrossRef]
- Aujla, G.S.; Jindal, A. A decoupled blockchain approach for edge-envisioned IoT-based healthcare monitoring. IEEE J. Sel. Areas Commun. 2020, 39, 491–499. [Google Scholar] [CrossRef]
- Shirvani, M.H.; Masdari, M. A survey study on trust-based security in Internet of Things: Challenges and issues. Internet Things 2022, 21, 100640. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, H.; Peng, M.; Guan, J.; Xu, J.; Wang, Y. DeePGA: A privacy-preserving data aggregation game in crowdsensing via deep reinforcement learning. IEEE Internet Things J. 2019, 7, 4113–4127. [Google Scholar] [CrossRef]
- Beliakov, G.; James, S.; Kolesárová, A.; Mesiar, R. Cardinality-limiting extended pre-aggregation functions. Inf. Fusion 2021, 76, 66–74. [Google Scholar] [CrossRef]
- Che, C.; Wang, H.; Ni, X.; Lin, R. Hybrid multimodal fusion with deep learning for rolling bearing fault diagnosis. Measurement 2021, 173, 108655. [Google Scholar] [CrossRef]
- Homaei, M.H.; Salwana, E.; Shamshirband, S. An enhanced distributed data aggregation method in the Internet of Things. Sensors 2019, 19, 3173. [Google Scholar] [CrossRef] [PubMed]
- Fitzgerald, E.; Pióro, M.; Tomaszwski, A. Energy-optimal data aggregation and dissemination for the Internet of Things. IEEE Internet Things J. 2018, 5, 955–969. [Google Scholar] [CrossRef]
- Islam, M.M.; Nooruddin, S.; Karray, F.; Muhammad, G. Multi-level feature fusion for multimodal human activity recognition in Internet of Healthcare Things. Inf. Fusion 2023, 94, 17–31. [Google Scholar] [CrossRef]
- Singh, S.; Kumar, D. Energy-efficient secure data fusion scheme for IoT based healthcare system. Future Gener. Comput. Syst. 2023, 143, 15–29. [Google Scholar] [CrossRef]
- Brüser, C.; Kortelainen, J.M.; Winter, S.; Tenhunen, M.; Pärkkä, J.; Leonhardt, S. Improvement of force-sensor-based heart rate estimation using multichannel data fusion. IEEE J. Biomed. Health Inform. 2014, 19, 227–235. [Google Scholar] [CrossRef] [PubMed]
- Abbasian Dehkordi, S.; Farajzadeh, K.; Rezazadeh, J.; Farahbakhsh, R.; Sandrasegaran, K.; Abbasian Dehkordi, M. A survey on data aggregation techniques in IoT sensor networks. Wirel. Netw. 2020, 26, 1243–1263. [Google Scholar] [CrossRef]
- Syed, A.S.; Sierra-Sosa, D.; Kumar, A.; Elmaghraby, A. IoT in smart cities: A survey of technologies, practices and challenges. Smart Cities 2021, 4, 429–475. [Google Scholar] [CrossRef]
- Song, J.; Liu, Y.; Shao, J.; Tang, C. A dynamic membership data aggregation (DMDA) protocol for smart grid. IEEE Syst. J. 2019, 14, 900–908. [Google Scholar] [CrossRef]
- Saleem, A.; Khan, A.; Malik, S.U.R.; Pervaiz, H.; Malik, H.; Alam, M.; Jindal, A. FESDA: Fog-enabled secure data aggregation in smart grid IoT network. IEEE Internet Things J. 2019, 7, 6132–6142. [Google Scholar] [CrossRef]
- Khan, R.; Zakarya, M.; Tan, Z.; Usman, M.; Jan, M.A.; Khan, M. PFARS: Enhancing throughput and lifetime of heterogeneous WSNs through power-aware fusion, aggregation, and routing scheme. Int. J. Commun. Syst. 2019, 32, e4144. [Google Scholar] [CrossRef]
- Fang, J.; Hou, H.; Bi, Z.; Jin, D.; Han, L.; Yang, J.; Dai, S. Data fusion in forecasting medical demands based on spectrum of post-earthquake diseases. J. Ind. Inf. Integr. 2021, 24, 100235. [Google Scholar] [CrossRef]
- Pradhan, S.; Sinha, E.; Sharma, K. Data Fusion by Truncation in Wireless Sensor Network. In Advanced Computational and Communication Paradigms; Springer: Berlin/Heidelberg, Germany, 2018; pp. 544–551. [Google Scholar]
- Mohseni, M.; Amirghafouri, F.; Pourghebleh, B. CEDAR: A cluster-based energy-aware data aggregation routing protocol in the internet of things using capuchin search algorithm and fuzzy logic. Peer Peer Netw. Appl. 2023, 16, 189–209. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, Y.; Wu, J.; Chen, B. LVPDA: A lightweight and verifiable privacy-preserving data aggregation scheme for edge-enabled IoT. IEEE Internet Things J. 2020, 7, 4016–4027. [Google Scholar] [CrossRef]
- Haseeb, K.; Islam, N.; Saba, T.; Rehman, A.; Mehmood, Z. LSDAR: A light-weight structure based data aggregation routing protocol with secure internet of things integrated next-generation sensor networks. Sustain. Cities Soc. 2020, 54, 101995. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Assumed Values |
|---|---|
| Coverage area where IoT is deployed | 1000 m × 1000 m |
| Active devices | Approximately 97, 194, 288, 386 |
| Server | 4, 8, 16, 24 |
| Edge module | 1 |
| Initial or on-board power (Ei) | 1150, 2300, 6600, 13,000 mAh |
| Residual energy (Er) | Ei—Econs |
| Power required for the packet transmission () | 91.4 mW |
| Power required for the packet receiving () | 59.1 mW |
| Coverage area () | 500 m |
| () | 0 |
| Beacon length | 70 to 100 bytes |
| Back-off timer | random |
| Signal-to-noise ratio (SNR) p | 10 dB |
| Channel Delay () | 10 ms |
| Power consumption (idle mode) | 1.27 mW |
| Power consumption (sleep mode) | 15.4 μW |
| Energy consumed by transceiver () | 1 mW |
| Coverage area of the transmitter () | 500 m |
| Power Threshold for reception () | 1024 bits |
| Packet Size () | 128 bytes |
| Distance between server and devices | 300 m |
| Sampling interval | 10 s |
| Typologies checked | Static and Random |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jan, S.R.; Ghaleb, B.; Tariq, U.U.; Ali, H.; Sabrina, F.; Liu, L. Two-Level Dynamic Programming-Enabled Non-Metric Data Aggregation Technique for the Internet of Things. Electronics 2024, 13, 1651. https://doi.org/10.3390/electronics13091651
Jan SR, Ghaleb B, Tariq UU, Ali H, Sabrina F, Liu L. Two-Level Dynamic Programming-Enabled Non-Metric Data Aggregation Technique for the Internet of Things. Electronics. 2024; 13(9):1651. https://doi.org/10.3390/electronics13091651
Chicago/Turabian StyleJan, Syed Roohullah, Baraq Ghaleb, Umair Ullah Tariq, Haider Ali, Fariza Sabrina, and Lu Liu. 2024. "Two-Level Dynamic Programming-Enabled Non-Metric Data Aggregation Technique for the Internet of Things" Electronics 13, no. 9: 1651. https://doi.org/10.3390/electronics13091651