
Hybrid Spatial-Channel Attention Mechanism for Cross-Age Face Recognition

Abstract
:1. Introduction

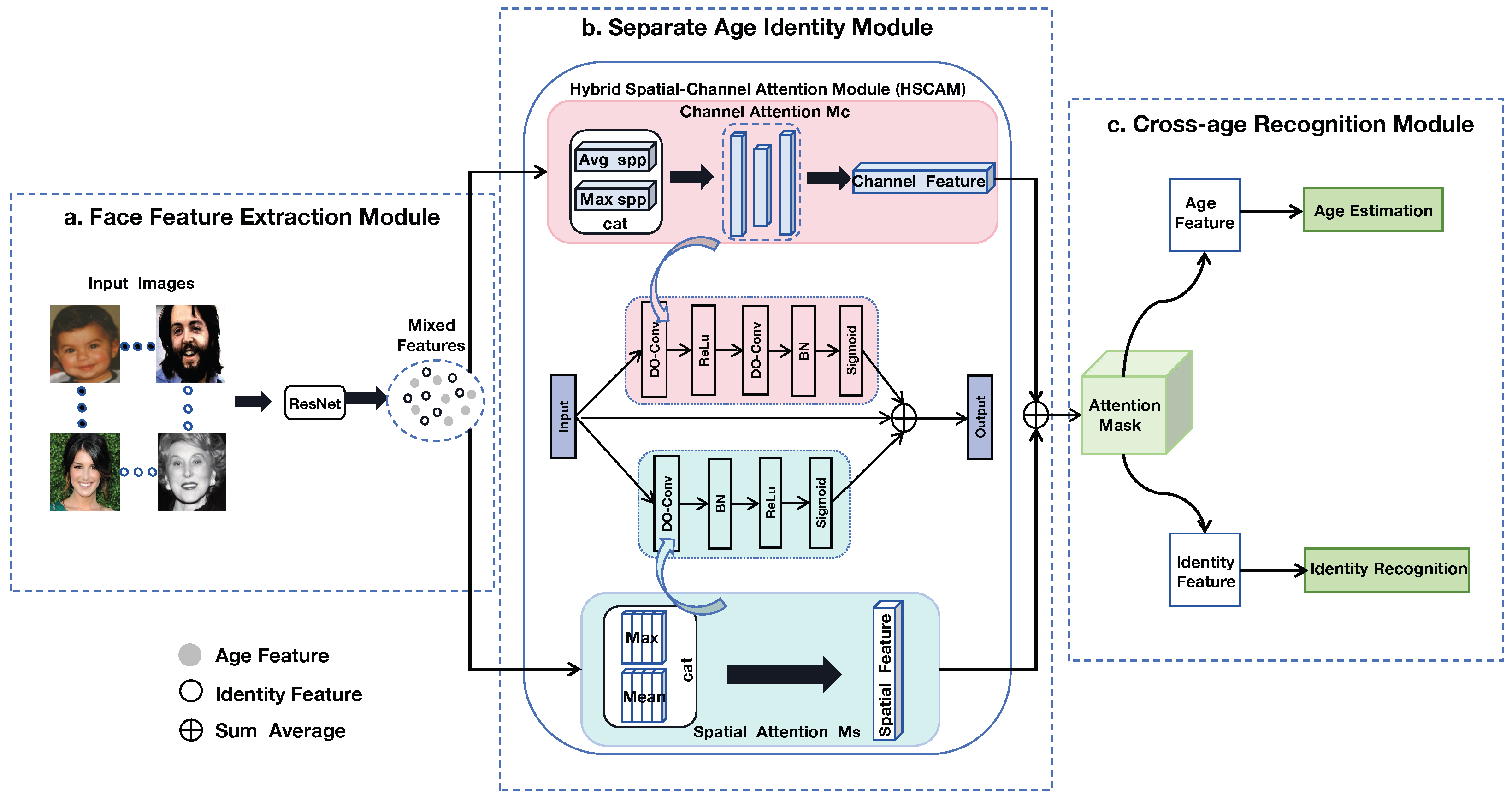
- In this work, we propose a new deep-face recognition framework that incorporates a novel Hybrid Spatial-Channel Attention Module (HSCAM) for better facial feature representation to enhance cross-age face recognition performance.
- The proposed HSCAM significantly benefits cross-age face recognition by decomposing the hybrid face features with both spatial and channel attention mechanisms to eliminate the age variations on the recognition performance. Moreover, it integrates various pooling strategies when performing those attention mechanisms, which enables the preservation of complete information within original features, further boosting recognition accuracy with more distinctive face representations.
- Extensive experiments on three benchmark datasets demonstrate the superiority of the proposed method in improving the accuracy of cross-age face recognition in the testing phase. These results further validate the effectiveness of the HSCAM.
2. Related Works
2.1. General AIFR Methods
2.2. Multi-Task Learning-Based AIFR Methods
3. Proposed Method
3.1. Overall Framework
3.2. Face Feature Extraction
3.3. Age Identity Separation
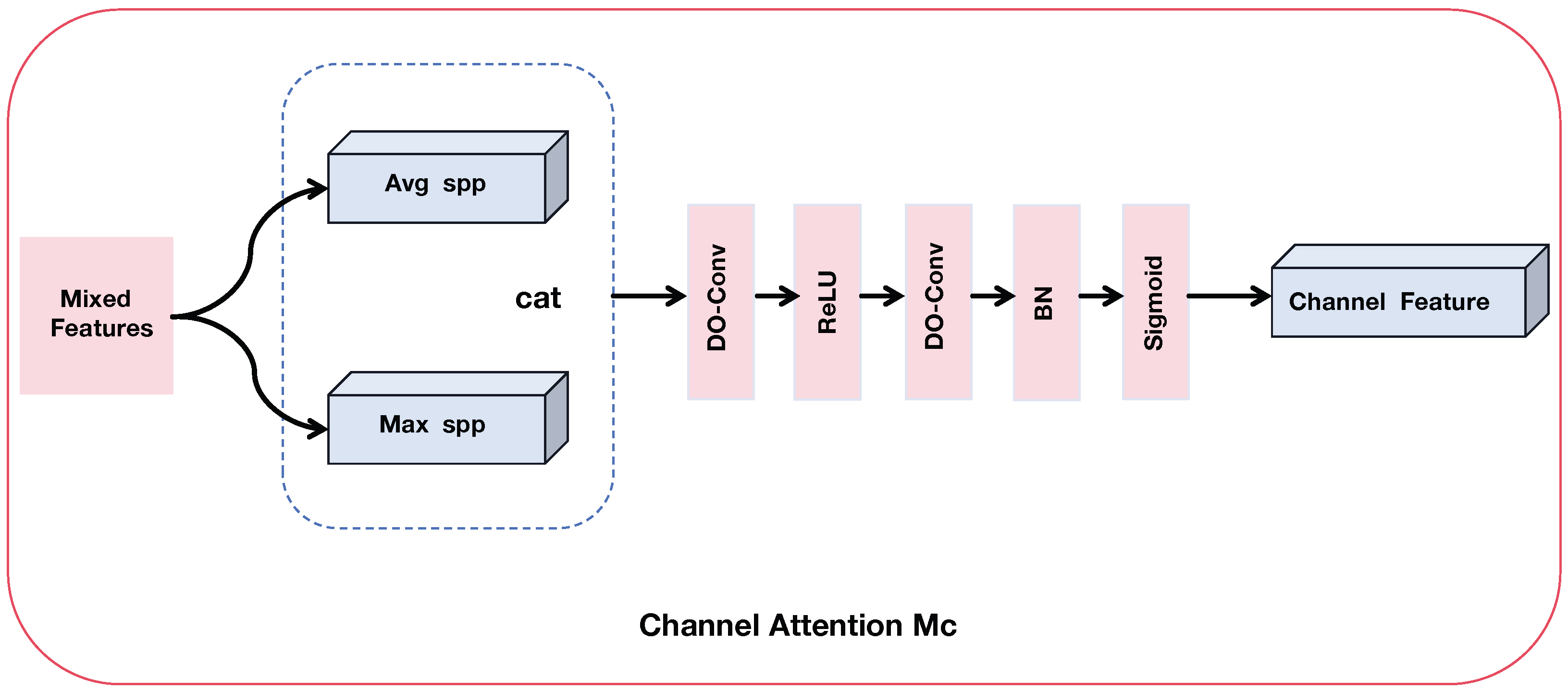
3.3.1. Hybrid Channel Attention
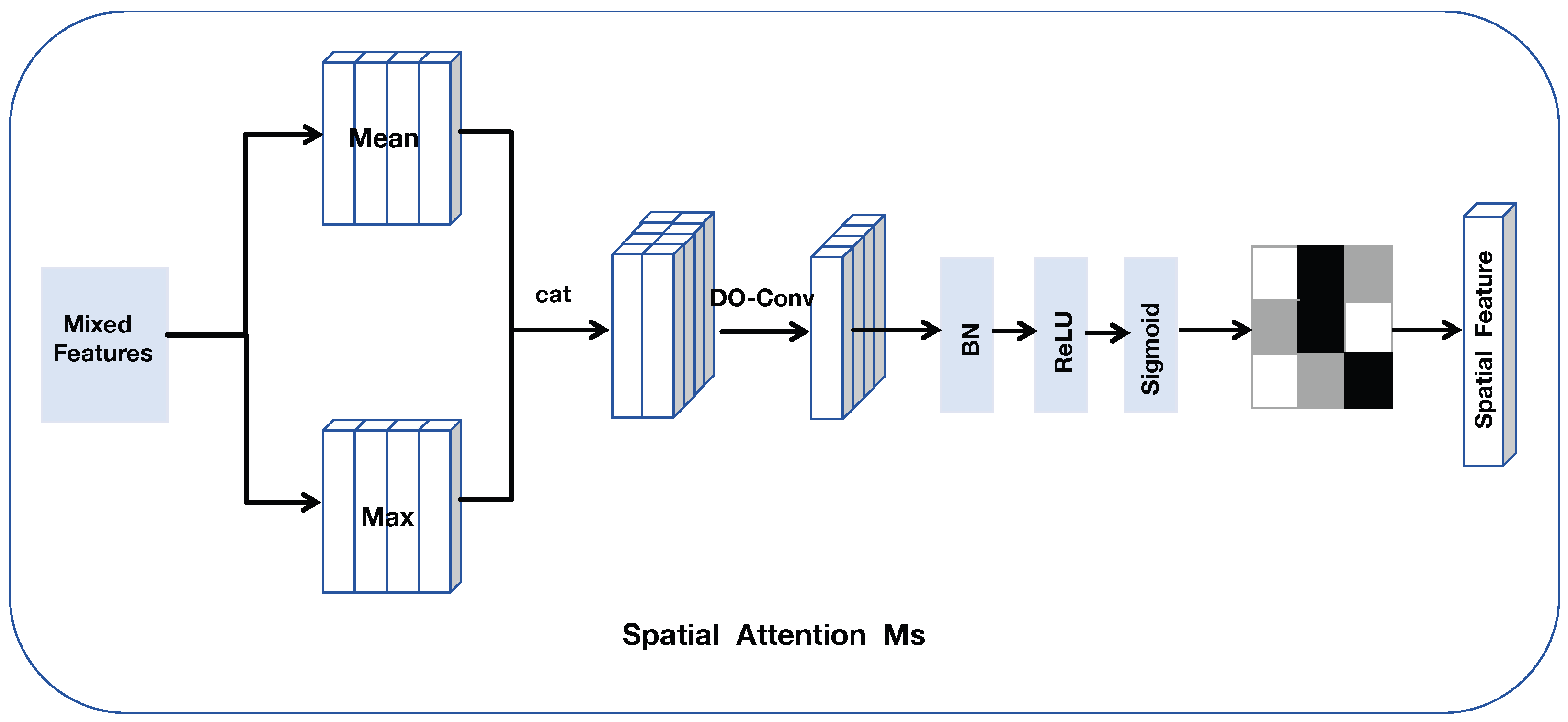
3.3.2. Hybrid Spatial Attention
3.3.3. Hybrid Spatial-Channel Attention Module
3.4. Cross-Age Recognition
3.4.1. Age Estimation Task
3.4.2. Identity Recognition Task
4. Experiments and Results
4.1. Experimental Details
4.1.1. Data Preparation
4.1.2. Training Settings
4.2. Comparison Results
4.2.1. Experiments on CACD-VS Dataset
4.2.2. Experiments on AgeDB-30 Dataset
4.2.3. Experiments on FGNET Dataset
4.3. Ablation Study
4.3.1. Analysis on Attention Module Settings
- 1.
- Baseline: The hybrid features were decomposed into age- and identity-related information, and then directly used for identity recognition without any attention mechanism components;
- 2.
- SA + Channel avg: The hybrid spatial attention (i.e., SA) mechanism was kept unchanged, and the hybrid channel attention mechanism was tested by eliminating the splicing of max pooling and average pooling in the channel dimension and only performing the max pooling operation;
- 3.
- SA + Channel max: Similar to the second setting, but only the global average pooling operation was performed;
- 4.
- CA + Spatial mean: The hybrid channel attention (i.e., CA) mechanism was kept unchanged, and the effectiveness of the hybrid max-pooling and mean-pooling modules was tested by canceling the splicing of max-pooling and mean-pooling in the channel dimension and only performing max-pooling operations;
- 5.
- CA + Spatial max: Similar to the fourth setting, but only max-pooling operations were carried out to verify the difference in the effect of splicing the max-pooling and the mean-pooling with the effect obtained from separate pooling operations;
- 6.
- Baseline + DO-Conv: A normal conv layer was replaced with a DO-Conv layer without using any attention mechanism model;
- 7.
- Baseline + CA’+ SA’: Among them, CA’: CA (; SA’: SA (). ∧ denotes the splicing role. The traditional conv layer was not replaced with a DO-Conv layer, and the attention of the hybrid channel space was kept unchanged for the experiment;
- 8.
- Ours: The traditional conv layer was replaced with a DO-Conv layer along the HSCAM that was used to evaluate the three face validation sets.
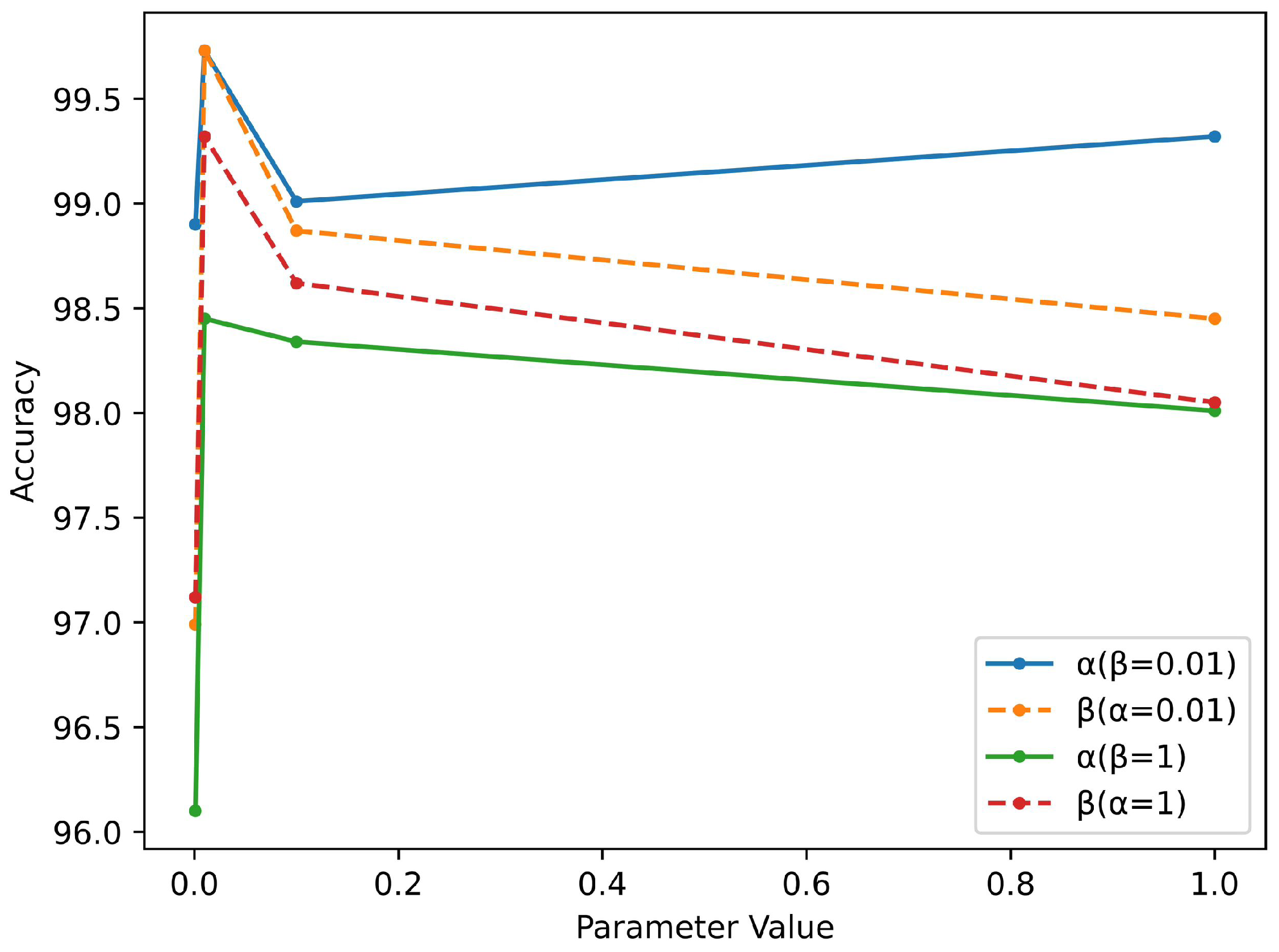
4.3.2. Analysis on Hyperparameter Settings
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Li, S.Z.; Lu, J. Face recognition using the nearest feature line method. IEEE Trans. Neural Netw. 1999, 10, 439–443. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Wu, G.; Hu, J.; Xu, S.; Zhang, S.; Liu, Y. Cityuplaces: A new dataset for efficient vision-based recognition. J. Real Time Image Process. 2023, 20, 109. [Google Scholar] [CrossRef]
- Shakeel, M.S.; Lam, K.M. Deep-feature encoding-based discriminative model for age-invariant face recognition. Pattern Recognit. 2019, 93, 442–457. [Google Scholar] [CrossRef]
- Kong, Y.; Zhang, K.; Zhang, L.; Wu, G. Deep facial attribute analysis. Front. Neurosci. 2023, 17, 1280831. [Google Scholar] [CrossRef]
- Sun, Y.; Chen, Y.; Wang, X.; Tang, X. Deep learning face representation by joint identification-verification. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar] [CrossRef]
- Dhamija, A.; Dubey, R. An approach to enhance performance of age invariant face recognition. J. Intell. Fuzzy Syst. 2022, 43, 2347–2362. [Google Scholar] [CrossRef]
- Zhao, J.; Yan, S.; Feng, J. Towards age-invariant face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 474–487. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Cheng, Y.; Cheng, Y.; Yang, Y.; Zhao, F.; Li, J.; Liu, H.; Yan, S.; Feng, J. Look across elapse: Disentangled representation learning and photorealistic cross-age face synthesis for age-invariant face recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9251–9258. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Chen, B.C.; Chen, C.S.; Hsu, W.H. Face recognition and retrieval using cross-age reference coding with cross-age celebrity dataset. IEEE Trans. Multimed. 2015, 17, 804–815. [Google Scholar] [CrossRef]
- Gong, D.; Li, Z.; Lin, D.; Liu, J.; Tang, X. Hidden factor analysis for age invariant face recognition. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2872–2879. [Google Scholar]
- Wen, Y.; Li, Z.; Qiao, Y. Latent factor guided convolutional neural networks for age-invariant face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4893–4901. [Google Scholar]
- Wang, Y.; Gong, D.; Zhou, Z.; Ji, X.; Wang, H.; Li, Z.; Liu, W.; Zhang, T. Orthogonal deep features decomposition for age-invariant face recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2018; pp. 738–753. [Google Scholar]
- Gibertoni, G.; Borghi, G.; Rovati, L. Vision-Based Eye Image Classification for Ophthalmic Measurement Systems. Sensors 2022, 23, 386. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Gong, D.; Li, Z.; Liu, W. Decorrelated adversarial learning for age-invariant face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3527–3536. [Google Scholar]
- Xie, J.C.; Pun, C.M.; Lam, K.M. Implicit and explicit feature purification for age-invariant facial representation learning. IEEE Trans. Inf. Forensics Secur. 2022, 17, 399–412. [Google Scholar] [CrossRef]
- Hoo, S.C.; Ibrahim, H.; Suandi, S.A.; Ng, T.F. LCAM: Low-Complexity Attention Module for Lightweight Face Recognition Networks. Mathematics 2023, 11, 1694. [Google Scholar] [CrossRef]
- Truong, T.D.; Duong, C.N.; Quach, K.G.; Le, N.; Bui, T.D.; Luu, K. LIAAD: Lightweight attentive angular distillation for large-scale age-invariant face recognition. Neurocomputing 2023, 543, 126198. [Google Scholar] [CrossRef]
- Wang, Z.; He, K.; Fu, Y.; Feng, R.; Jiang, Y.G.; Xue, X. Multi-task deep neural network for joint face recognition and facial attribute prediction. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017; pp. 365–374. [Google Scholar]
- Wu, Y.; Du, L.; Hu, H. Parallel multi-path age distinguish network for cross-age face recognition. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 3482–3492. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, J.; Shan, H. When age-invariant face recognition meets face age synthesis: A multi-task learning framework. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7282–7291. [Google Scholar]
- Hou, X.; Li, Y.; Wang, S. Disentangled representation for age-invariant face recognition: A mutual information minimization perspective. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 3692–3701. [Google Scholar]
- Dahan, E.; Keller, Y. Age-Invariant Face Embedding using the Wasserstein Distance. arXiv 2023, arXiv:2305.02745. [Google Scholar]
- Wang, H.; Sanchez, V.; Li, C.T. Cross-Age Contrastive Learning for Age-Invariant Face Recognition. arXiv 2023, arXiv:2312.11195. [Google Scholar]
- Ermao, L.; Min, Z. Review of Cross-Age Face Recognition in Discriminative Models. In Proceedings of the 2023 8th International Conference on Image, Vision and Computing (ICIVC), Dalian, China, 27–29 July 2023; pp. 124–130. [Google Scholar] [CrossRef]
- Deb, D.; Zhang, J.; Jain, A.K. Advfaces: Adversarial face synthesis. In Proceedings of the 2020 IEEE International Joint Conference on Biometrics (IJCB), Houston, TX, USA, 28 September–1 October 2020; IEEE: New York, NY, USA, 2020; pp. 1–10. [Google Scholar]
- Yan, C.; Meng, L.; Li, L.; Zhang, J.; Wang, Z.; Yin, J.; Zhang, J.; Sun, Y.; Zheng, B. Age-invariant face recognition by multi-feature fusionand decomposition with self-attention. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 1–18. [Google Scholar] [CrossRef]
- Ren, X.; Wang, J.; Li, S. MAM: Multiple Attention Mechanism Neural Networks for Cross-Age Face Recognition. Wirel. Commun. Mob. Comput. 2022, 2022, 8546029. [Google Scholar] [CrossRef]
- Du, L.; Hu, H. Cross-age identity difference analysis model based on image pairs for age invariant face verification. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2675–2685. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics (JMLR Workshop and Conference Proceedings), Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Babbar, S.; Dewan, N.; Shangle, K.; Kulshrestha, S.; Patel, S. Cross-age face recognition using deep residual networks. In Proceedings of the 2019 Fifth International Conference on Image Information Processing (ICIIP), Shimla, India, 15–17 November 2019; IEEE: New York, NY, USA, 2019; pp. 257–262. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Fang, S.; Wu, G.; Liu, Y.; Feng, X.; Kong, Y. Dual enhanced semantic hashing for fast image retrieval. Multimed. Tools Appl. 2024, 1–20. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Bieder, F.; Sandkühler, R.; Cattin, P.C. Comparison of methods generalizing max-and average-pooling. arXiv 2021, arXiv:2103.01746. [Google Scholar]
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Cao, J.; Li, Y.; Sun, M.; Chen, Y.; Lischinski, D.; Cohen-Or, D.; Chen, B.; Tu, C. Do-conv: Depthwise over-parameterized convolutional layer. IEEE Trans. Image Process. 2022, 31, 3726–3736. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zheng, T.; Deng, W.; Hu, J. Age estimation guided convolutional neural network for age-invariant face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1–9. [Google Scholar]
- Barron, J.T. A general and adaptive robust loss function. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4331–4339. [Google Scholar]
- Zhang, Z.; Song, Y.; Qi, H. Age progression/regression by conditional adversarial autoencoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5810–5818. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Wang, H.; Sanchez, V.; Li, C.T. Age-oriented face synthesis with conditional discriminator pool and adversarial triplet loss. IEEE Trans. Image Process. 2021, 30, 5413–5425. [Google Scholar] [CrossRef] [PubMed]
- Moschoglou, S.; Papaioannou, A.; Sagonas, C.; Deng, J.; Kotsia, I.; Zafeiriou, S. Agedb: The first manually collected, in-the-wild age database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 51–59. [Google Scholar]
- Nithyashri, J.; Kulanthaivel, G. Classification of human age based on Neural Network using FG-NET Aging database and Wavelets. In Proceedings of the 2012 Fourth International Conference on Advanced Computing (ICoAC), Chennai, India, 13–15 December 2012; IEEE: New York, NY, USA, 2012; pp. 1–5. [Google Scholar]
- Guo, Y.; Zhang, L.; Hu, Y.; He, X.; Gao, J. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 87–102. [Google Scholar]
- Dong, Y.; Zhen, L.; Liao, S.; Li, S.Z. Learning face representation from scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Chen, X.; Lau, H.Y. The identity-level angular triplet loss for cross-age face recognition. Appl. Intell. 2022, 52, 6330–6339. [Google Scholar] [CrossRef]
- Boutros, F.; Siebke, P.; Klemt, M.; Damer, N.; Kirchbuchner, F.; Kuijper, A. Pocketnet: Extreme lightweight face recognition network using neural architecture search and multistep knowledge distillation. IEEE Access 2022, 10, 46823–46833. [Google Scholar] [CrossRef]
- Fu, Y.; Hospedales, T.M.; Xiang, T.; Xiong, J.; Gong, S.; Wang, Y.; Yao, Y. Robust subjective visual property prediction from crowdsourced pairwise labels. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 563–577. [Google Scholar] [CrossRef] [PubMed]
- Kemelmacher-Shlizerman, I.; Seitz, S.M.; Miller, D.; Brossard, E. The megaface benchmark: 1 million faces for recognition at scale. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4873–4882. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy (%) | Improvement (%) |
|---|---|---|
| LF-CNN [14] | 98.50 | 1.27 |
| OE-CNN [15] | 99.20 | 0.57 |
| DAL [17] | 99.40 | 0.37 |
| WMI-AI [25] | 99.57 | 0.20 |
| MTLFace [23] | 99.55 | 0.22 |
| PMADN [22] | 99.20 | 0.57 |
| Ours | 99.77 | - |
| Method | Accuracy (%) | Improvement (%) |
|---|---|---|
| MT-MIM [24] | 96.10 | 1.67 |
| MTLFace [23] | 96.23 | 1.54 |
| IEFP [18] | 95.82 | 1.95 |
| PocketNet [52] | 96.78 | 0.99 |
| LCAM [19] | 93.70 | 4.07 |
| Ours | 97.77 | - |
| Method | Accuracy (%) | Improvement (%) |
|---|---|---|
| OE-CNN [15] | 58.18 | 11.41 |
| DAL [17] | 57.92 | 11.67 |
| MTLFace [23] | 57.18 | 12.41 |
| LIAAD [20] | 60.11 | 9.48 |
| CACon [26] | 64.37 | 5.22 |
| Ours | 69.59 | - |
| Network Settings | CACD-VS [12] | AgeDB-30 [47] | FGNET [48] |
|---|---|---|---|
| Baseline | 88.38 | 92.56 | 50.20 |
| SA + Channel avg | 93.25 | 91.82 | 63.94 |
| SA + Channel max | 90.89 | 93.65 | 55.98 |
| CA + Spatial mean | 92.79 | 95.02 | 62.22 |
| CA + Spatial max | 94.68 | 94.38 | 60.52 |
| Baseline + DO-Conv | 95.02 | 95.19 | 62.35 |
| Baseline + CA’ + SA’ | 97.66 | 96.94 | 65.26 |
| Ours | 99.77 | 97.77 | 69.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, W.; Wu, G. Hybrid Spatial-Channel Attention Mechanism for Cross-Age Face Recognition. Electronics 2024, 13, 1257. https://doi.org/10.3390/electronics13071257
An W, Wu G. Hybrid Spatial-Channel Attention Mechanism for Cross-Age Face Recognition. Electronics. 2024; 13(7):1257. https://doi.org/10.3390/electronics13071257
Chicago/Turabian StyleAn, Wenxin, and Gengshen Wu. 2024. "Hybrid Spatial-Channel Attention Mechanism for Cross-Age Face Recognition" Electronics 13, no. 7: 1257. https://doi.org/10.3390/electronics13071257