1. Introduction
Skin cancer is one of the most common cancers globally; melanoma causes the highest number of deaths annually. It is the most hazardous type of skin cancer that develops fast and spreads to other organs. The World Health Organization (WHO) has predicted nearly 7990 melanoma deaths in 2023, with an anticipated 97,610 new cases in the USA [
1]. In order to avoid adverse results from the advent, prompt detection and treatment are required.
With the improvements in computer technology, deep learning (DL)-based computer-aided applications have been used to assist the medical diagnosis process [
2]. Although several studies have proposed machine learning models to classify melanoma, most of them lack the generalizability of their solution to be employed in a practical situation [
3]. Additionally, automated melanoma detection using digitized dermoscopy pictures provides a significant potential use for DL techniques due to their ability to effectively extract and analyze intricate patterns and features present in the images, leading to improved accuracy and reliability in diagnosis. Deep neural networks (DNNs), which can handle complicated problems, are becoming common in medical applications. However, the black-box nature of the algorithm’s decision-making process challenges these models’ trustworthiness. This can be addressed by explainable artificial intelligence (XAI), which is an evolving area of research [
4,
5]. XAI aims to bridge the gap between the complex functioning of DNNs and the need for understandable and trustworthy models, allowing stakeholders to comprehend and interpret the reasoning behind the algorithm’s predictions. By incorporating XAI techniques, such as generating visual heatmaps or feature importance measures, the inner workings of DNNs can be elucidated, enabling medical professionals and researchers to gain insights and build confidence in the model’s outputs.
This study presents a computational model for melanoma identification using a deep learning model with transfer learning and XAI. We use melanoma and nevus images from the HAM10000 dataset [
6], which contains dermoscopic and clinical images. These two skin cancer types have a severe impact, and the appearance of both skin lesions is mostly similar; thus, they may not be distinguished accurately in cancer diagnosis by humans. The main focus of this study is to achieve high performance in skin image classification and show the model’s explainability to increase the trustworthiness of the proposed solution. Initially, different convolutional neural networks based on Xception, ResNet50, VGG16, Inception, and MobileNetv2 are used with modifications as the classification models. The explainable heatmaps are based on gradient-weighted class activation mapping (Grad-CAM) [
7] and Grad-CAM++ [
8]. Moreover, as a novel contribution, we segment the images based on U2-Net and train saliency mask-guided vision transformer (SM-ViT) model for melanoma detection. SM-ViT uses a salient object identification module that includes an off-the-shelf saliency detector to build a salient mask that is likely focused on the foreground object regions of an image for discrimination [
9]. Then the saliency mask is used in salient mask-guided encoder (SMGE), which is similar to ViT, to improve the standard self-attention mechanism’s ability to discriminate between more distinct tokens [
10]. Further, the proposed model is developed as a web application, which can be used as a support tool in real clinical settings. The proposed approach can assist dermatologists as a support model for identifying melanoma.
The major contributions of this work are as follows:
- 1.
Apply extensive data augmentation to address the imbalanced datasets;
- 2.
Train the U2-Net model using the ISIC 2017 Task1 dataset to generate the segmentation masks to separate the foreground object from the background in an image;
- 3.
Comparative study for different CNNs and ViT-based models for the melanoma and nevus skin cancer classification;
- 4.
Identify the performances by utilizing different hyperparameter tuning;
- 5.
Enhance the performance of ViT in fine-grained visual categorization (FGVC) using SM-VIT;
- 6.
Provide integrability to fine-tune on top of a ViT-based backbone that leverages the standard self-attention mechanism;
- 7.
Improve the trustworthiness of the system using explainability methods such as Grad-CAM and Grad-CAM++ heat maps;
- 8.
Qualitative and quantitative model evaluation using intersection over union (IOU) and skin cancer feature masks dataset (ISIC 2018 TASK 2);
- 9.
Develop a web application to use the proposed model as a support tool.
This paper is structured as follows:
Section 2 states the literature related to melanoma classification.
Section 3,
Section 4 and
Section 5 describe the methodology, results, and the usability study, respectively.
Section 6 discusses the study contribution together with the comparison with the existing studies, and
Section 7 concludes the paper.
3. Methodology
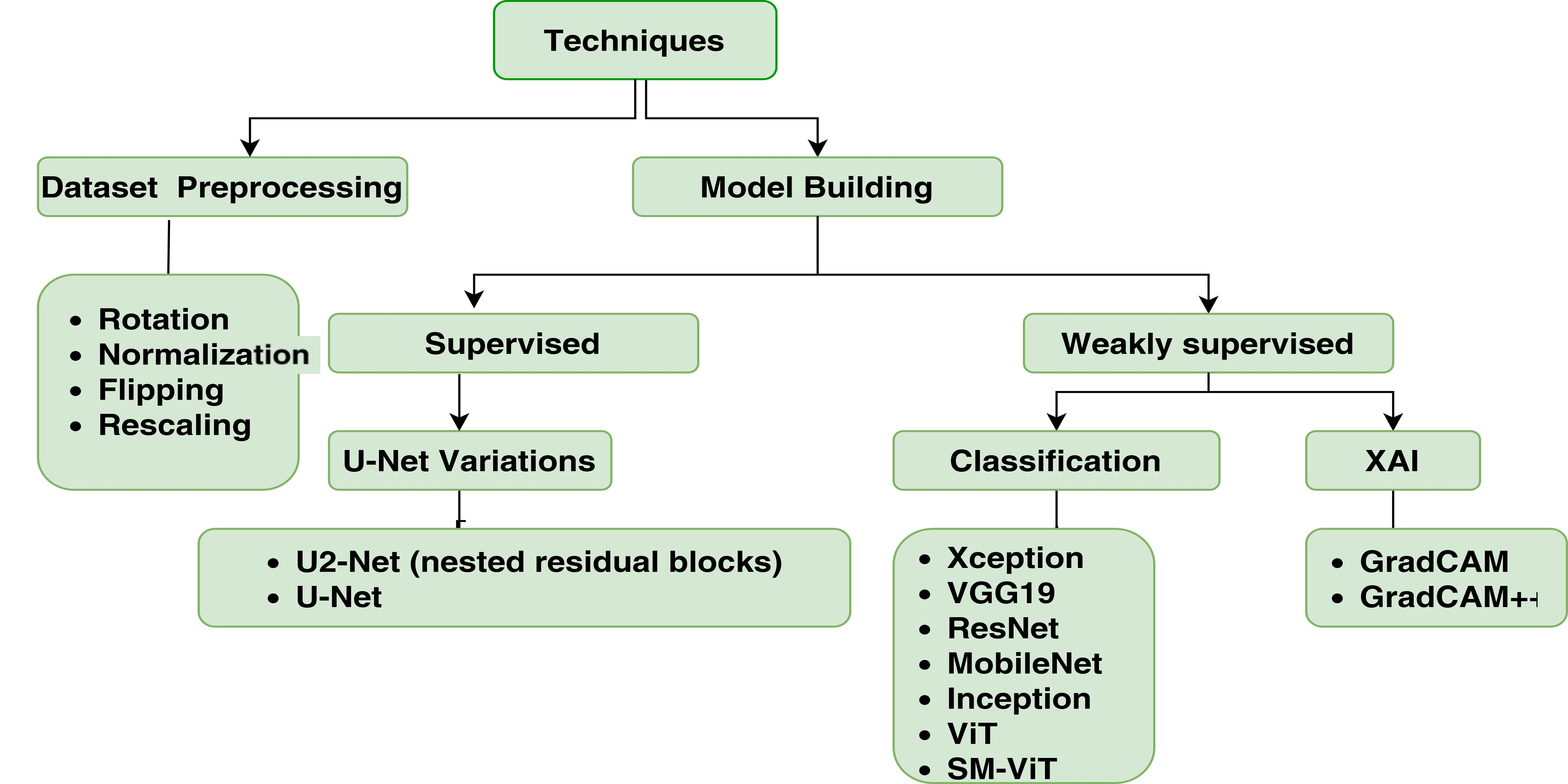
3.1. Model Design
This study is designed with two main approaches, namely, CNN-based and ViT-based melanoma classification. The CNN models play a vital role in medical image classification due to their ability to automatically learn features, handle spatial variability, reduce parameterization, and adapt to various types of imaging data [
18,
19,
20,
21]. The ViT models are one of the evolving DL models, which exhibit efficiency and accuracy over CNNs with large datasets [
10]. The inherent utilization of a self-attention mechanism in ViT models captures the relationships between the different regions of an input image. This self-attention mechanism enables the generation of attention maps that contribute to their superior predictive capabilities. Considering the visual information processing, CNN models consist of convolutional layers that apply spatial filters across the input, enabling them to capture local patterns and spatial hierarchies effectively. In contrast, ViT models rely on self-attention mechanisms, where each input patch attends to all other patches, allowing for the modeling of long-range dependencies and capturing global context information [
10,
21]. The DL approaches and techniques considered for this study are shown in
Figure 1 and
Figure 2 shows the high-level view of the process.
The model is trained using the HAM10000 [
6]. In the ViT-based approach, a mask-guided ViT is used for the segmentation as a novel contribution. In order to perform the explainability, ISIC 2018 task 2 dataset is used as it has attribute masks to evaluate the Grad-CAM and Grad-CAM++ heat maps. We employed a mask-guided approach, leveraging ViT technology to enhance self-attention mechanisms for the precise identification of melanoma skin cancer. Our strategy involved integrating U2-Net-generated masks alongside traditional self-attention mechanisms. In the context of CNN models, we also applied a masked-guided technique to curate datasets, effectively eliminating extraneous regions from skin images, thereby improving the accuracy of our skin cancer detection system. This innovative approach allowed us to focus attention where it matters most, ultimately enhancing the diagnostic capabilities of our model.
3.2. Dataset
This study uses a widely used public dataset for melanoma identification, the HAM10000 dataset [
6], which contains over 10,000 images of skin lesions, including Nevi and malignant melanoma. Each image is accompanied by clinical metadata, including diagnosis, age, and sex. This dataset contains 7 categories of skin lesions. Nevus lesions [Nevi] (6705), dermatofibroma (115), malignant skin tumors [Melanoma] (1113), benign keratosis (1099), basal cell carcinoma (514), actinic keratosis (327), and vascular lesions (142) are those categories.
Figure 3 shows a sample image from each class in HAM10000 dataset. We observed that certain images share identical HAM IDs, and their lesion structures exhibit congruence, leading to duplicate data. Therefore, we performed a comprehensive comparative study with the entire dataset as well as removing the duplicate images in the original dataset. We extracted 614 nevus or Nevi images (not cancer) and 614 malignant melanoma lesion images (skin tumors), which is a particularly challenging clinical task by removing any duplicates [
17]. That dataset was used to feed the U2-Net [
22] model and obtained the segmentation masks. This HAM10000 dataset is used to train our CNN-based models and ViT base model.
The International Skin Imaging Collaboration (ISIC) has released several public datasets for melanoma identification. We also used the ISIC 2018 task 2 dataset [
23] to evaluate our explainability methods, as it contains attribute masks. This dataset contains 2594 images and 12,970 corresponding ground truth response masks (5 for each image). Those dermoscopic attribute masks contain dermoscopic attributes such as pigment network, negative network, streaks, milia-like cysts, and globules, as shown in
Figure 4. Furthermore, we used ISIC 2017 dataset [
23] to generate the correct segmentation mask corresponding to image lesions by training the U2-Net model.
Figure 5 shows the sample image and its segmentation mask in the ISIC 2017 dataset.
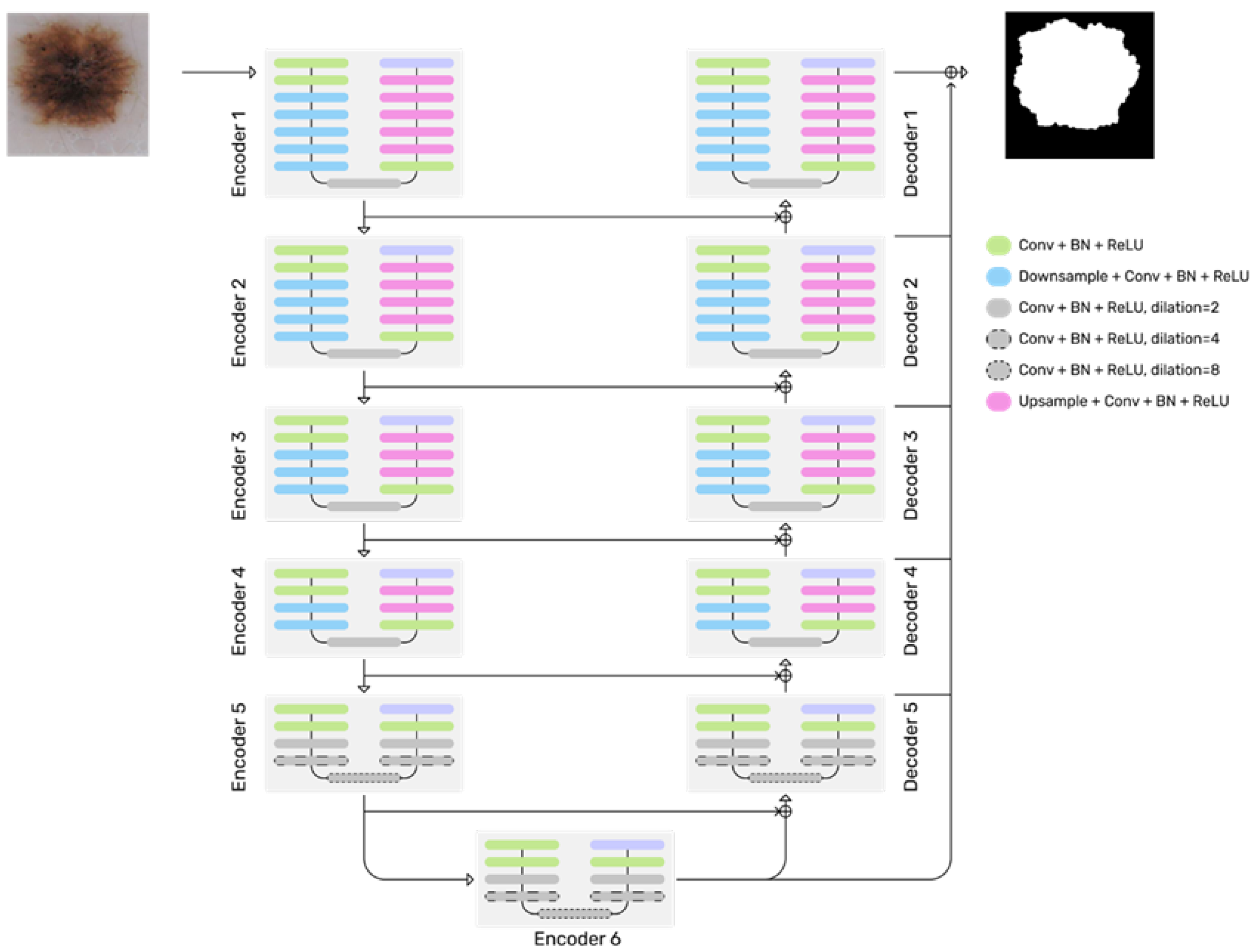
3.3. U2-Net Based Segmentation Model
The U2-Net model was proposed by Qin et al. [
22], which is a deep nested U-structure for salient object detection (SOD). The U2-Net architecture exhibits a two-level nested U-structure, which captures contextual information at varying scales by leveraging the fusion of receptive fields with different sizes within the residual U-blocks (RSU) architecture. Thus, the model captures more fine-grained details and produces accurate segmentation masks. It is specifically designed to separate the foreground object from the background in an image. This mechanism enables the model to encode a comprehensive understanding of the image content. Moreover, the U2-Net architecture achieves increased depth while minimizing the computational cost by incorporating pooling operations within the RSU blocks. This design choice enhances the model’s capacity without imposing a significant computational burden. Notably, the U2-Net architecture stands out by enabling end-to-end training without relying on pre-trained backbones from image classification. This model has shown competitive performance in both qualitative and quantitative evaluations [
24].
U2-Net is a two-level nested U-structure, as shown in
Figure 6. Its top level is a big U-structure consisting of 11 stages. Each stage consists of a well-configured RSU (bottom-level U-structure). Hence, the nested U-structure enables the extraction of intra-stage multi-scale features and aggregation of inter-stage multi-level features more efficiently. The U2-Net mainly consists of three parts: (1) six-stage encoder, (2) five-stage decoder, and (3) saliency map fusion module attached to the decoder stages and the last encoder stage.
The U2-Net architecture uses RSUs of varying heights, (L) in its encoder stages (En) to capture different scales of information in the input feature maps. The En5 and En6 stages use dilated versions of the RSU-4 block to avoid further down-sampling of the low-resolution feature maps. The decoder stages (De) have similar structures to their corresponding encoder stages, with De5 using the dilated RSU-4F block. The saliency map fusion module generates saliency probability maps by first generating six side output saliency probability maps from different stages of the network and then upsampling and fusing them with a concatenation operation followed by a 1 × 1 convolution layer and Sigmoid function to generate the final saliency probability map. The corresponding pseudocode is given in Algorithm 1. Accordingly, the generated masks from the segmentation process are used for the classification pipelines.
| Algorithm 1: Proposed segmentation module training pipeline |
![Electronics 13 00680 i001]() |
3.4. CNN-Based Classification
We performed a comparative study utilizing different CNN-based models and with two different variations in the HAM10000 dataset. Initially, we tried with all the melanoma and Nevi lesion images in the dataset. Since, there are duplicate images, we removed the duplication of melanoma images and Nevi images to maintain the class balance between melanoma and Nevi lesion images from the dataset. Next, we obtained all melanoma images and the same number of Nevi images from the non-duplication image set and then we split it into training, validation, and testing according to 80:10:10 ratio.
Table 1 shows the image count of before and after removing duplicates.
Table 2 summarizes the number of original images used for the training, testing and validation datasets.
Next, we applied two pipelines. As the first pipeline, we incorporated the U2-Net model to generate segmentation masks of the raw images and apply those masks to the original image (mask-guided experiment). The second pipeline is performed without applying segmentation masks to the original images (non-mask-guided experiment). In order to use the U2-Net model, we have used a pre-trained U2-Net model, which is trained with ISIC 2017 challenge datasets. It contains lesion segmentation data, including the original image, paired with the expert manual tracing of the lesion boundaries in the form of a binary mask. We used these binary images as the label for each image and used “epoch_num = 20 batch_size_train = 32 batch_size_val = 1” parameters for the training. After generating segmentation masks using the trained U2-Net model, we applied those masks to the respective images. A sample image input and generated masks after going through the U2-Net model are shown in
Figure 6, as the input and output images.
Figure 7 shows a sample image input, generated masks from the U2-Net model, and an image obtained after applying the segmentation mask.
In DL model training, it is important to have a balanced image count in each of the classes in the dataset that is considered for model building. Having equally represented classes helps to avoid biased predictions, improves the generalizability for unseen data, stable model training, effective pattern learning, and supports reliable evaluation. Data imbalance issues can be addressed by data augmentation or a specially designed loss function, based on the nature of the dataset. Data augmentation techniques help to increase the number of data records in each class and have a balanced dataset. Different transformations can be applied to increase the diversity of the training data, which supports regularization and generalization. This leads to preventing overfitting and obtaining a robust model for input variations. Moreover, when there is a limited amount of training data, data augmentation helps the model to improve feature learning and extract more meaningful and generalized features; thus, improves the model performance.
As the next step, we applied augmentation operations, such as flipping, rotation, and rescaling. The aforementioned augmentations were selected based on their ability to preserve the structural integrity of the lesions during the training process. It was imperative to avoid cropping and shifting operations that could potentially compromise the lesion structure, leading to erroneous training outcomes. By employing the chosen augmentations, we aimed to mitigate the risk of introducing distortions that could negatively impact the accuracy and reliability of the training procedure. We resize all images into 224 × 224 scale, to ease the training process. In our second experiment, we followed all the above processes except mask generating and applying masks stages.
Subsequent to the aforementioned pre-processing steps, the dataset was utilized within the framework of a CNN model. The adoption of the transfer learning technique supported to obtain high results with the limited size of the dataset [
21]. In order to leverage the knowledge gained from larger datasets, we employed pre-trained models, specifically Xception [
25], ResNet50 [
26], VGG16 [
27], InceptionV3 [
3], and MobileNet [
20]. These models were subjected to extensive experimentation to achieve optimized and accurate results. All base models are pre-trained using the ImageNet dataset, which contains a large number of annotated images belonging to objects in the world.
In our comparative study, we experimented with the original models as well as modifying the CNN architectures to obtain better results. This helps to justify the architectural changes we proposed in this study provides better results than the base models. The experiments were performed for both mask-guided and non-mask-guided pipelines.
We modified the original base model by adding a global average pooling layer (GAP), a dense layer, and a dropout layer. The GAP layer supports the implementation of the explainability approaches. Moreover, we applied regularization methods, such as early stopping callbacks, to avoid overfitting the model. This study utilized the Bayesian hyperparameter tuner [
28], to train our CNN models, facilitating the discovery of optimized parameters and resulting in optimized models. The considered parameter ranges are presented in
Table 3. This hyperparameter tuning supports in refining the performance of CNN models by systematically exploring the parameter space and identifying the configurations that yield superior results. Furthermore, we retrained only some of the lower batch-normalization layers by unfreezing from its base model, during the training process.
We identified the high-performing models using the Bayesian hyperparameter tuner.
Table 4 shows the hyperparameters used for those top models, namely, Xception, ResNet50, and VGG16. Moreover, the supplementary results of the mask-guided technique, without eliminating the duplicates are presented in
Section 4 and have shown that the models trained without duplicate images have given high results. Furthermore, our explainability methods were employed on the trained models subsequent to the optimization process. We applied XAI techniques only for the models with high performance. In this case, models obtained from mask-guided experiments are used for explainability methods, as described in
Section 3.6. This section elucidated the techniques and approaches employed to gain insights into the decision-making processes of the trained models. The above mentioned process is stated in Algorithm 2.
| Algorithm 2: Proposed CNN-based classification and explainability pipeline |
![Electronics 13 00680 i002]() |
3.5. ViT-Based Classification
The ViT architecture, initially designed for less fine-grained problems, is supposed to capture both global and local information, which makes it spend a noticeable part of its attention performance on the background patches [
10,
21,
29]. This property makes vanilla ViT perform worse on FGVC tasks, since they usually require finding the most distinguishable patches, which are mostly the foreground ones. In order to resolve this issue, we used salient mask-guided vision transformer (SM-ViT), which embedded information from a saliency detector into the self-attention mechanism. The overall architecture of our SM-ViT is illustrated in
Figure 8.
In the proposed design, we used the ViT model as the backbone for the classification. Here, a ViT B/16 model pre-trained on the ImageNet-21K dataset [
30], with 224 × 224 images and with no overlapping patches. For the saliency detection module, a U2-Net model pre-trained on the ISIC 2017 Task 1 dataset, is used with constant weights. Following common data augmentation techniques, unless stated otherwise, the image processing procedure is as follows: for the saliency module, as recommended by the authors [
22], the input images are resized to 320 × 320, and no other augmentations are applied. The pseudocode of the ViT-based classification is shown in Algorithm 3.
For our SM-ViT, the images are resized to 224 × 224 for the HAM1000 dataset. Next, random horizontal flipping and color jittering techniques are applied only for the training process. All our models are trained with the standard SGD (stochastic gradient descent) optimizer with a momentum set to 0.9 and with a learning rate of 0.03, all with cosine annealing for the optimizer scheduler. The batch size is set to 32 for all datasets. Pre-trained with 224 × 224 images, ViTB/16 weights are loaded from the original ViT [
10] resources.
Initially, we utilize a salient object detection (SOD) module for saliency extraction. Our method employs a popular deep saliency model, U2-Net pre-trained on a mid-scale dataset for salient object detection. Here, the nested U-shaped architecture predicts saliency based on rich multi-scale features at relatively low computation and memory costs. First, an input image is passed through the SOD module set up in a test mode, which further generates the final non-binary saliency probability map. In the next phase, the model output is normalized to be within the values [0…1] and then converted into a binary mask by applying a threshold dα on each mask’s pixel, where dα is a pixel’s intensity threshold. We used a threshold of 0.8 [
22]. Finally, the resulting binary mask and a bounding box for the found salient object(s) (in the form of the minimum and maximum 2D coordinates of the positively thresholded pixels) are extracted and saved.
| Algorithm 3: Proposed ViT-based classification and explainability pipeline |
![Electronics 13 00680 i003]() |
An important note is that our solution also takes into account the cases when a mask is not found or is corrupted, and, if so, the initial probability map is first refined again using a threshold dα = 0.2, which allows more pixels to be considered positive. If the mask is not restored even after refining, its values are automatically set as positive for the central 80% of the image pixels. The extracted binary mask and bounding box are further passed into our SMGE. The core module of SM-ViT is our novel salient mask-guided encoder (SMGE), which is a ViT-like encoder modified to be able to receive and process saliency information. Its main purpose is to increase the class token attention scores for the image tokens containing foreground regions. Initially, an image, cropped according to the extracted in the SOD module bounding box, in the form of patches is projected into linear embeddings, and a position embedding is added to it. Next, instead of the standard ViT encoder, our SMGE takes its place functioning as an improved self-attention mechanism.
In order to understand the intuition behind our idea, we need to emphasize that the manner in which attention is obtained in the vanilla ViT encoder (Equation (
1)) makes the background and foreground patches equally important and does not discriminate valuable for FGVC problems salient regions of the main object(s) in an image. Taking this issue into account, our solution is to increase attention scores for the patches that include a part of the main (salient) object in them. However, due to the nature of the self-attention mechanism and the non-linearity used in it, one can not simply increase the final attention values themselves since it will break the major assumptions of the algorithm [
10]. Therefore, we modified the attention scores calculated before the soft argmax function (also known as softmax), according to the saliency mask provided by the salient object detection module. For this purpose, the binary mask is first flattened into a 1D vector and a value for the class token is prepended to it, therefore that, similar to Equation (
1), the size of the resulting mask matches the number of tokens (Np + 1), as in Equation (
2), where
is always positive since the attention of the class token to itself is considered favorable. Further, a conventional attention score matrix
is calculated in each head as in Equation (
3).
Next, the maximum value
among the attention scores of the class token to each patch is found for each head. These values are further used to modify the attention scores of the class token by increasing the unmasked by m ones with a portion of the largest found value
, which is calculated for every head.
is a row in the matrix of attention scores
belonging to the class token,
is a coefficient controlling the portion of the maximum value to be added, and
. Finally, as in Equation (
4), the rows of the resulting attention score matrix
, including the modified values in its
row, are converted into probability distributions using a nonlinear function.
Eventually, similar to the multi-layer vanilla ViT encoder, the presented algorithm is further repeated at each SMGE’s layer until the classification head, where the standard final categorization is performed based on the class token aggregating the information from the “highlighted” regions throughout SMGE. To summarize, our simple yet efficient salient mask-guided encoder changes the vanilla ViT encoder by modifying its standard attention mechanism’s algorithm (in Equation (
1)) with Equations (
2)–(
4). Therefore, relative to the vanilla ViT encoder, our SMGE only adds pure mathematical steps, does not require extra training parameters, and is not resource-costly.
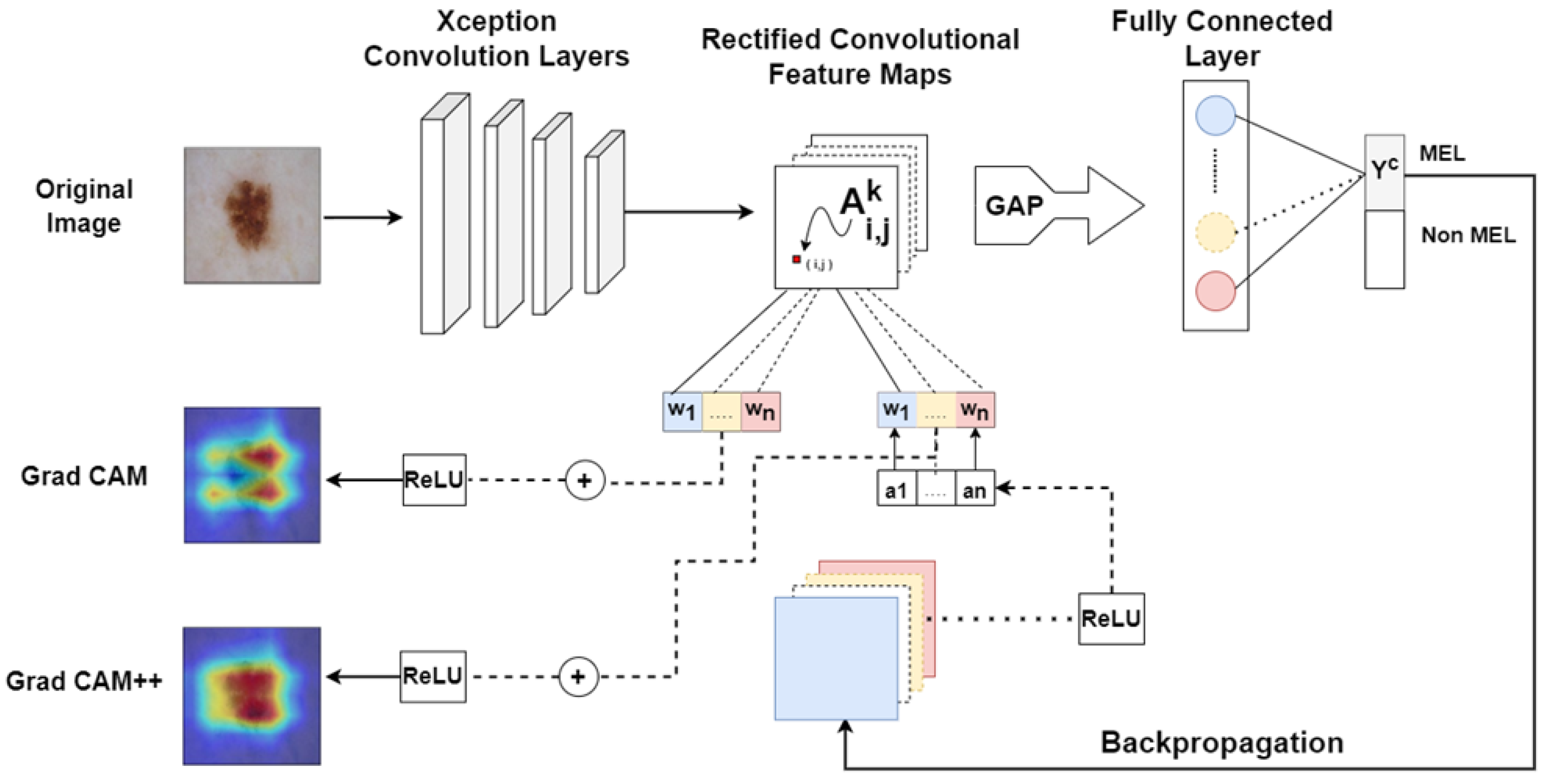
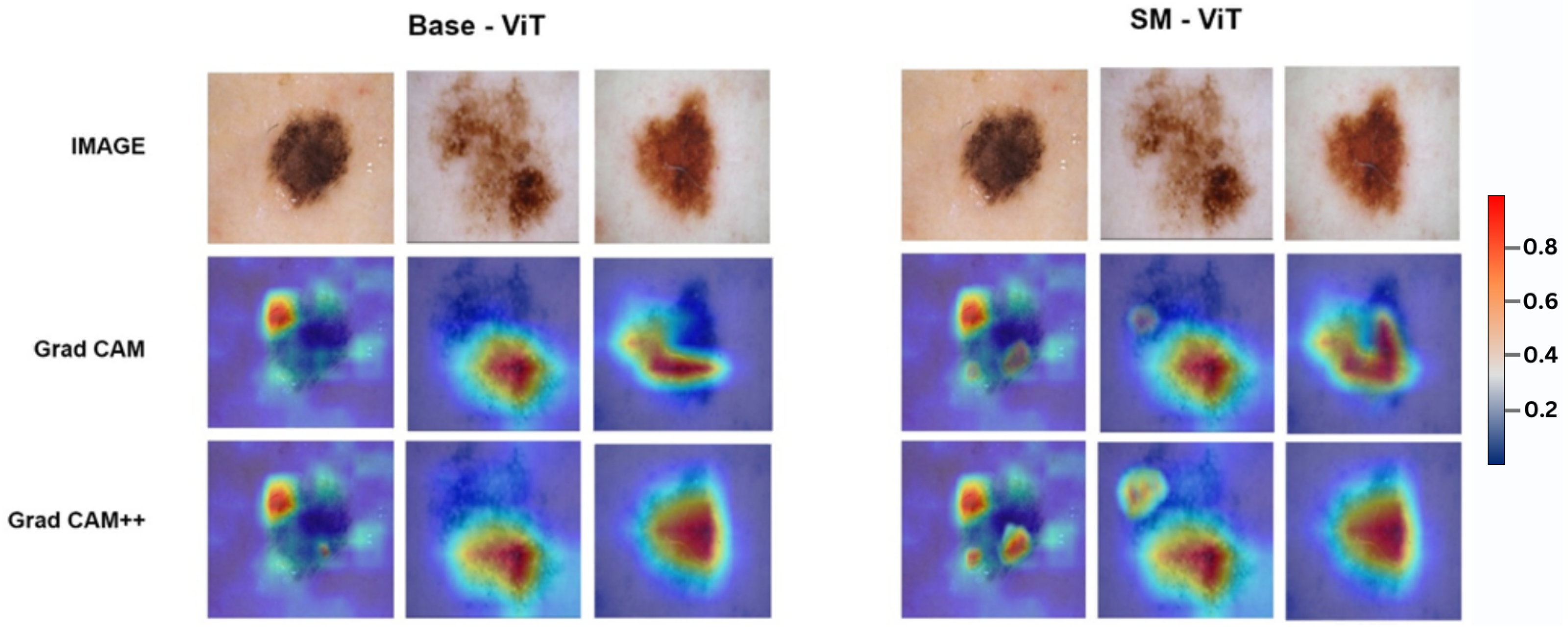
3.6. Explainability
With the increasing development of real-world applications using DL models, it is important to build trust and transparency of the results to the user. XAI techniques support understanding the regions-of-interests of the input that cause to predict the results. In this study, we applied both Grad-CAM and Grad-CAM++, as novel contributions to the domain of dermatology. It helps to identify the gradient of the most dominant feature maps of the final convolution layer in the trained model as the explainability approach of the solution [
21]. Here, we applied the XAI techniques only for the mask-guided models presented in this study, which are identified as high-performance models.
The CAM, Grad-CAM, and Grad-CAM++ are considered as the series of CAM explainability techniques. The explainability prowess of the CAM is limited to only CNNs, which have GAP at the penultimate layer, which is a fully connected hidden layer. Furthermore, CAM requires retraining multiple linear classifiers after training the base model. The Grad-CAM technique addresses this issue by introducing a backpropagation concept. It also considers a GAP of the partial derivatives to solve the weight independent from the position of a particular activation map. Even though Grad-CAM is better than CAM, Grad-CAM heatmaps cannot localize the entire region of the object. Grad-CAM++ is used to address this using a weighted combination of the positive partial derivatives of the last convolutional layer feature maps. Compared to Grad-CAM, the Grad-CAM++ technique gives more highlighted heatmaps even though related features are bounded to a limited pixel area [
8].
The explainability model consists of a series of convolutional layers, rectified convolutional feature maps, and fully connected layers, as shown in
Figure 9. After the last convolution layer, we applied the GAP for all feature maps to obtain a single scalar for each map. The class scores for a given class are found using the combination of those single scores of each activation map with the multiplication of the weights at the fully connected layer. Consequently, in the Grad-CAM, backpropagation is applied until the last convolution layer to find the weights for each feature map using the global average pool of the partial derivative. We applied the ReLu activation function to combine the positive partial derivatives of the final convolutional layer feature maps corresponding to a particular class score as gradient weights to produce visual explanations of the model predictions, considering the object localization [
8]. Subsequently, the linear combination of the derived weights is added through the ReLu activation to obtain positive correlations and generate the Grad-CAM heatmap.
Moreover, we applied Grad-CAM++ as a comparison study. Here, a similar backpropagation is applied until the last convolution layer to find the weights, which are derived by taking the positive partial derivatives w.r.t each feature maps using the ReLu activation function and multiplying by pixel-wise weight
. Finally, the model uses ReLu to obtain the heatmap visualization as of the Grad-CAM. In this process, for a particular skin image, the CNN model first extracts the convolutional feature maps
. The final score
for a particular class c, is expressed as a linear combination of its global average pooled final convolutional layer feature maps using Equation (
5) [
8]. Here,
is the weight for a particular feature map
of class c, as given in Equation (
6). It is the positive gradient weighted average of the gradients with positive partial derivatives w.r.t. each pixel in an activation map
,
with the ReLu function ([
8]). The pixel-wise weights
for a specific class c and the locations (i, j) of a specific activation map k are determined as stated in Equation (
7). Here, the activation map
is iterated over by (i, j) and (a, b).
3.7. Implementation Details
Overall architecture with salient object detection (SOD) module and salient mask-guided encoder (SMGE) have been implemented and currently optimizing the parameter to improve the accuracy. All our experiments are conducted on a single NVIDIA RTX 2000 GPU using the PyTorch deep learning framework and the APEX utility, and all the results are stated. The used DL platforms, libraries and tools are as follows.
TensorFlow: provides the core framework for building and training DL models. We used these libraries to implement the CNNs for classifying melanoma skin cancer images;
Keras: simplifies the process of building and training these models and places as a high-level API built on top of TensorFlow. We used CNN architectures such as ResNet50, VGG16, and Xception, which can be conveniently implemented in Keras with pre-trained weights, facilitating transfer learning;
PyTorch: as another widely used framework for building and training DL model and supports tasks, such as data loading and pre-processing, model training, and implementing model architecture. The associated dynamic computational graph and efficient memory usage, enables large-scale DL tasks. We have used this library to develop ViT based approach;
Scikit-learn (sklearn): is a Python library that supports classification tasks and interoperates with the Python numerical and scientific libraries NumPy and SciPy. We used Scikit-learn during the model evaluation process;
NumPy: is a Python library that supports large scale, multi-dimensional arrays and matrices. This enables high-level mathematical functions to operate on these arrays. We used NumPy for numerical operations, manipulating arrays for data preprocessing, and integration with other libraries like TensorFlow and PyTorch;
Matplotlib: is a plotting library in Python and its numerical mathematics extension NumPy. It provides an object-oriented API for embedding plots into applications using general-purpose GUI toolkits. We used Matplotlib for visualizing data, plotting the training history of models, or displaying the heatmaps generated by Grad-CAM and Grad-CAM++.
6. Discussion
The main aim of this study was to propose a model and develop a solution for the identification of melanoma skin cancer images. We investigated the effectiveness of mask-guided DL methods for melanoma diagnosis. Two main approaches, namely, the CNN-based approach and the ViT-based approach, were explored with the HAM10000 dataset in this research. Additionally, explainability methods, namely, Grad-CAM++ and Grad-CAM were utilized to provide interpretable results. The proposed models were developed and deployed as prototype to support the clinical diagnosis process.
In the CNN-based approach, the Xception model was selected as it demonstrated superior accuracy compared to other CNN models, such as ResNet50, VGG16, Inception, and MobileNet. This performance advantage can be attributed to the utilization of depth-wise separable convolutions in Xception, which enables more efficient and effective feature learning. The ability of Xception to capture fine-grained patterns and variations in melanoma images enhances its accuracy for skin cancer classification. The larger network capacity of Xception, with its increased layers and parameters, allows it to learn more complex representations and capture a wider range of features relevant to melanoma diagnosis. Consequently, the increased capacity contributes to a higher accuracy by enabling the model to detect intricate patterns and variations in the data.
On the other hand, the ViT-based approach introduced the SM-ViT model, which achieved a higher accuracy than the baseline ViT model. The incorporation of saliency masks in the SM-ViT model facilitated the extraction of distinct information within the ViT encoder layers. This enhanced discriminability of self-attention characteristics led to an increased accuracy compared to the basic ViT model. The utilization of saliency masks played a crucial role in capturing and highlighting relevant features for melanoma diagnosis, thereby improving the performance of the ViT-based approach.
Moreover, this study enables a better model learning process by extracting the appropriate lesion areas from adjacent healthy skin regions. For instance, several related studies have used raw images for model training without extracting the lesion area from the image. Thus, the learning process can be interrupted by noises, such as hair in the image and other healthy skin obstacles. In this study, we addressed this challenge by using mask-guided CNN and ViT models, which result in a high performance during melanoma identification.
In terms of explainability, Grad-CAM++ and Grad-CAM methods were employed to visualize and interpret the predictions of the models [
31]. The study found that Grad-CAM++ yielded more explainable results. Grad-CAM++ provided accurate and interpretable explanations by highlighting prediction-related areas equally, even when they were limited to a small number of pixels. The incorporation of curvature and higher-order variations in gradients in Grad-CAM++ improved the localization accuracy, contributing to its superior performance in providing explainability compared to other methods. Therefore, this study addressed the existing issue of XAI that prevents highlighting small pixel areas in the melanoma lesion structure, which is limited to a small number of pixels, by using Grad-CAM++ technique. Here, the Grad-CAM++ explainability method highlights supportive areas of the prediction even though it is in a small lesion area, compared to Grad-CAM method.
This study used the HAM10000 dataset, which has seven lesions, where the number of images in each class is not balanced.
Table 12 shows a summary of the previous studies that have used the HAM10000 dataset and the results of our proposed solution.
Although several studies have utilized this dataset, they have used different lesions from this dataset and have applied various pre-processing and optimization techniques. For example, some studies have used all the classes [
32,
33], four classes [
34] in the dataset, as well as some studies that have used melanoma and nevus classes only [
3]. Accordingly, some studies have performed the classification after removing the duplicates in the HAM10000 dataset [
17,
35]. Some of the studies endure issues, such as insufficient training data [
36,
37] and biased models [
35]. Moreover, some of the existing studies have not been validated on datasets from different domains [
34,
38]. Hence, considering the specificity of the medical images, there can be high variance in the results.
The results of our study demonstrate the effectiveness of the mask-guided deep learning method for melanoma diagnosis. Both the CNN-based approach using the Xception model and the ViT-based approach using the SM-ViT model achieved a high accuracy in melanoma classification. The integration of segmentation masks generated by the U2-Net model proved to be beneficial for enhancing the accuracy of both approaches. Additionally, the adoption of Grad-CAM++ for its explainability provided valuable insights into the models’ decision-making processes and improved the interpretability of the results.
Table 12.
Comparison with previous studies that used HAM10000.
Table 12.
Comparison with previous studies that used HAM10000.
| Study | XAI Method | Classifier | Accuracy |
|---|
| 2019 [3] | CAM, Grad-CAM | Inception | 88% |
| 2020 [18] | Integrated gradient | ResNet18 | 64% |
| 2020 [39] | - | MobileNet | 81.24% |
| 2020 [37] | - | EfficientNet | 90.0% |
| 2020 [38] | - | CNN-based | 92.90% |
| 2020 [40] | - | ResNet + Inception | 92.83% |
| 2020 [35] | - | ResNet50 Ensemble | 93% |
| 2020 [41] | - | Seg + CNN | 95% |
| 2021 [32] | CAM | CNN-based | 74% |
| 2021 [36] | - | CNN Ensemble | 88% |
| 2021 [34] | - | CNN, Autoencoder | 92.5% |
| 2021 [42] | Soft Attention | ResNet + Inception | 93.4% |
| 2022 [33] | SHAP, Grad-CAM | Seg + CNN | 90.6% |
| 2023 [13] | Grad-CAM, Grad-CAM++ | Xception | 90.24% |
| 2023 [43] | Attention Map | ViT | 94.1% |
| Our study | | SM-ViT | 92.79% |
| Mask-guided | Grad-CAM | VGG16 | 97.37% |
| and without | Grad-CAM++ | ResNet50 | 98.18% |
| duplicates | | Xception | 98.37% |
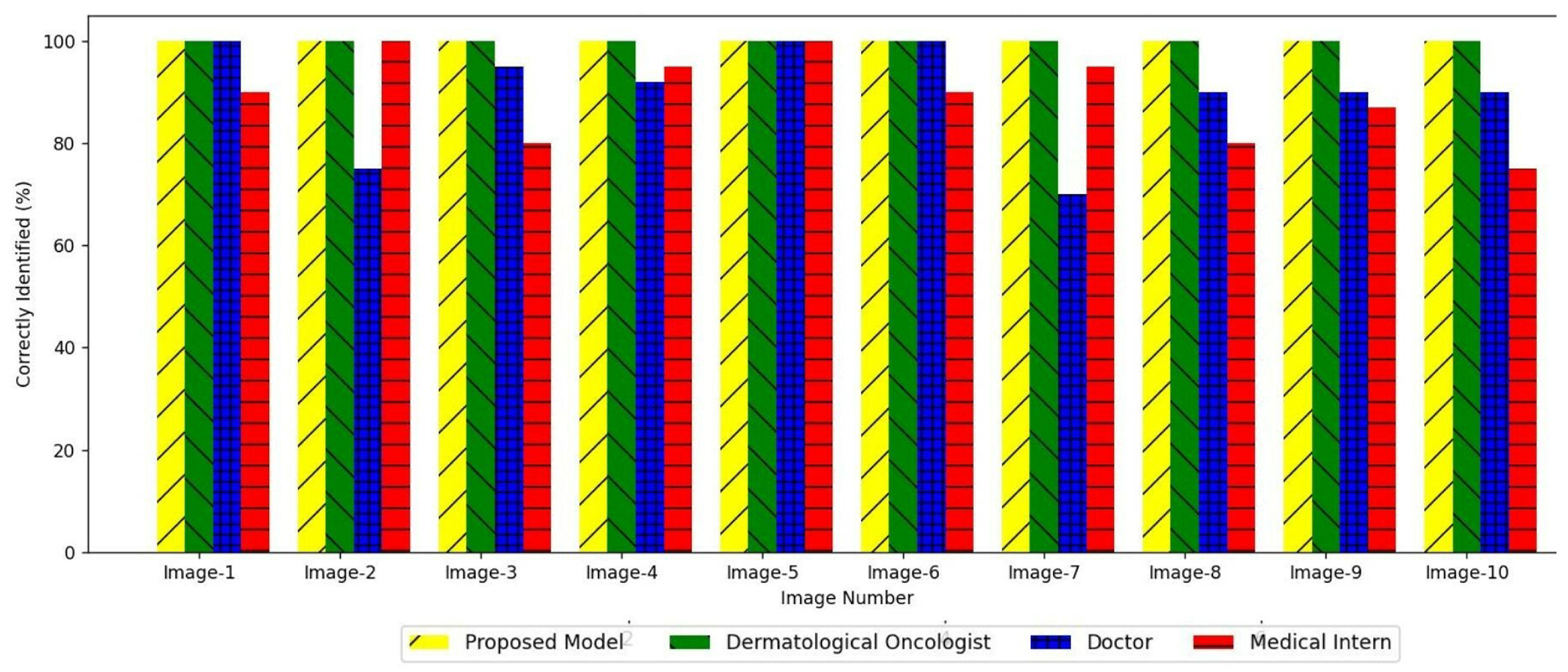
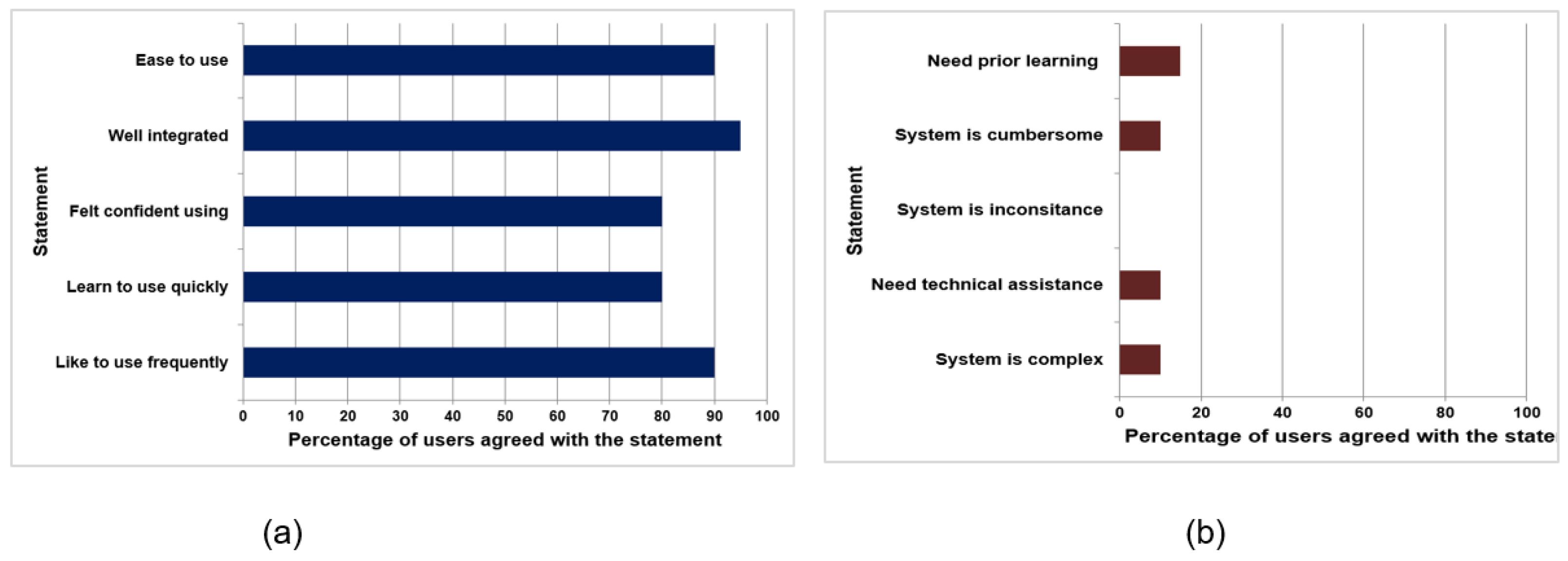
These findings have significant implications for the field of dermatology and medical image analysis. The mask-guided deep learning method presented in this study has the potential to assist dermatologists in accurately diagnosing melanoma, thereby improving patient outcomes. The CNN-based and ViT-based approaches offer alternative options for melanoma diagnosis, catering to different preferences and computational requirements. Moreover, the utilization of Grad-CAM++ for its explainability can enhance the trustworthiness and acceptance of deep learning models in the medical domain since it more accurately localizes features in a given skin image.
This study can be extended with several future research directions. The evaluation of the proposed solution can be expanded by considering larger and more diverse datasets. Thus, multi-class classification can be tried out over binary classification to identify more skin cancer types. The use of diverse datasets considering different populations and skin types would further validate the utility and help to increase the generalizability of the proposed solution. Additionally, different possible techniques can be used to increase the accuracy of the ViT model. For instance, the union of attribute masks can be used instead of the segmentation masks for each classification. Further improvements can be made by exploring different network architectures, incorporating additional data augmentation techniques, and considering ensemble models to achieve a higher accuracy and robustness in melanoma diagnosis. Furthermore, it can be deployed in the real-world clinical setting for further model validation with expert feedback.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





















